大模型面试第三期:激活函数篇
在大模型(LLM)相关的算法面试中,Transformer 架构早已是老生常谈,但真正拉开候选人差距的,往往是对微观组件底层逻辑的深度理解。
为什么现在的开源顶流(如 LLaMA)纷纷抛弃经典的 ReLU + 标准 FFN,转而拥抱 SwiGLU?“神经元死亡”在几何和微积分层面到底意味着什么?看起来毫不起眼的偏置项(Bias)又是如何决定网络生死存亡的?
老规矩,先讲知识再出题。
1. 什么是激活函数
比如一个神经元正在接收来自其他神经元的信号。有些信号说“是”(正值),有些信号说“否”(负值)。神经元把这些信号加在一起得到一个总分(假设为)。
激活函数的作用就是根据这个总分 ,决定当前神经元要不要把信号传递给下一层,以及传递多强。
-
没有激活函数的情况: 别人给我多少,我就原封不动传给下一个人。这会导致整个网络无法进行复杂的思考。
-
有激活函数的情况: 设定一个规则。比如:“总分大于 0 我才传递,小于 0 我就闭嘴。”这就是最经典的激活函数逻辑。
在没有激活函数的情况下,无论神经网络有多少层,它本质上都只是在做简单的线性乘加运算(就像永远只在画直线)。激活函数的存在,为网络注入了非线性(Non-linearity),使其能够理解、学习并模拟现实世界中极其复杂的模式,比如人类语言的语法、逻辑甚至幽默感。
问题:
非线性怎么来的?
解答:
只要中间没有非线性激活函数,由于矩阵乘法的结合律,无数层网络在数学上都会“坍缩”成一层极其简单的线性层。它本质上只是一个高维的直线方程(),永远只能在空间里切出平直的面
每一层通过矩阵乘法提取出的特征空间,都被激活函数强行进行了“扭曲、折叠或切断”(比如 ReLU 直接把一部分空间砍成 0)。经过层层叠加扭曲,神经网络就具备了拟合现实世界中任意复杂曲线的能力(这在数学上被称为通用近似定理 Universal Approximation Theorem)。
2. 大模型中常见的激活函数
在大模型(如 GPT、LLaMA)的演进过程中,激活函数也在不断进化。以下是几个最具代表性的“决策官”:
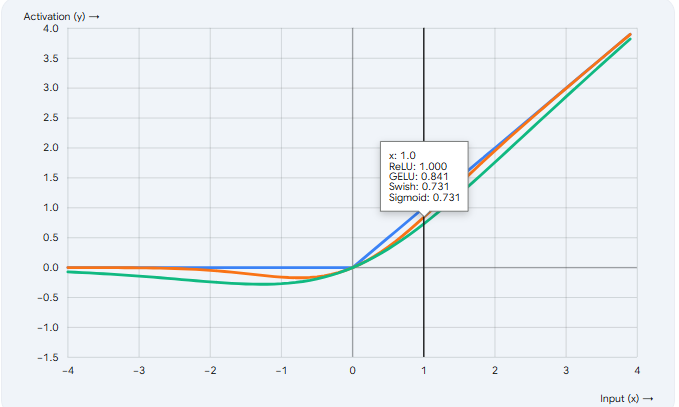
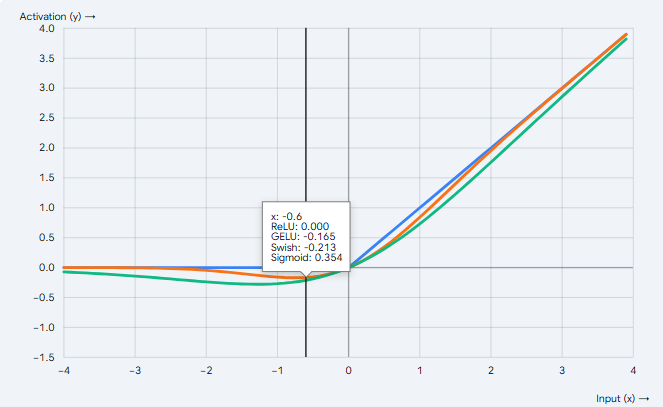
A. ReLU (Rectified Linear Unit - 线性整流函数)
-
公式:
-
工作原理: 如果输入
是正数,它就原样输出;如果是负数,直接变成 0(静音)。
-
实例: 假设神经元接收到的信号总分是
,ReLU 输出
,ReLU 直接输出
。
-
优缺点: 计算极快,是深度学习早期的最大功臣。但缺点是负数部分完全变成了死区(称为“神经元死亡”问题)。
B. GELU (Gaussian Error Linear Unit - 高斯误差线性单元)
-
公式:
(其中
是标准正态分布的累积分布函数)
-
工作原理: 这是 GPT 系列和 BERT 等大模型最爱用的激活函数。它不再像 ReLU 那样“一刀切”。当输入接近 0 的负数时,它不会立刻变成 0,而是保留一个非常微小的负值。它融合了概率论,给信号赋予了一定“随机通过”的可能性。
-
实例: 输入
时,ReLU 会输出
的值,保留了一点点微弱的负向信息。
C. Swish / SiLU (Sigmoid Linear Unit)
-
公式:
(其中
是 Sigmoid 函数)
-
工作原理: 图像形状和 GELU 非常相似,但在负数区域有一个明显的“小坑”(负值)。它是 Google 提出的,并且被 LLaMA、Mistral 等当前最火的开源大模型广泛采用(通常结合门控机制变成 SwiGLU)。它能让梯度流动得更平滑,模型学习效果更好。
问题:
1.写一下RELU的公式
2.写一下GELU的公式
3.写一下SiLU的公式
4.神经元死亡的原因是什么?
解答:
1.2.3看一下上面的公式对一下
4:
1. 学习率过大:
2. 初始化不当
看完了基础的几个激活函数,接下来进入大模型的FFN块
自注意力机制负责信息交流,而 FFN 块负责对每一个字词的特征进行独立的、深度的非线性加工和记忆提取。我们刚才讨论的激活函数,正是 FFN 块里的核心组件。
3. 经典 FFN
最经典的 FFN(在早期的 Transformer 和 GPT 结构中广泛使用)通常包含两个线性变换(矩阵乘法)和中间的一个激活函数。
它的标准数学公式如下:
这看起来有点抽象,我们可以把它拆解成三个通俗易懂的步骤:升维 -> 激活(筛选) -> 降维。
步骤一:升维拓展 (Up-projection)
-
公式:
-
解释: 假设输入的词向量
通常会把它“拉宽”到 4 倍(即 4096 维)。
-
目的: 就像把一张折叠的纸展开,升维能让模型有更大的空间去组合和表达各种复杂的特征。
步骤二:非线性激活 (Activation)
-
公式:
-
解释: 这就是上一轮我们讨论的 ReLU 或 GELU 出场的地方。它对刚才得到的 4096 维向量中的每一个数字进行处理。
-
目的: 剔除无用信息(比如 ReLU 把负数变成 0),引入非线性,让网络具备真正的“思考”能力,而不是单纯的线性叠加。
步骤三:降维还原 (Down-projection)
-
公式:
-
解释: 经过激活函数筛选后,第二个权重矩阵
会把这 4096 维的数据重新“压缩”回最初的 1024 维。
-
目的: 整理加工后的信息,保持维度一致,以便输出给大模型的下一层继续处理。
如下表,假设我们输入的X只有两个维度。[1,-2]

问题:
1.FFN的计算公式写一下
2.为什么要先升维度后又降维?
3.偏置B有什么用?
解答:
1:见上述公式。
2:先升维是为了利用高维空间的线性可分性(Cover定理)来解耦复杂的语义特征,同时高维隐藏层也充当了模型的记忆容量;后降维首先是为了满足 Transformer 中残差连接的维度一致性要求,其次是为了将高维提取出的精华特征进行信息压缩提纯,并控制下一层的计算成本。
3:偏置B允许神经元在超平面不被局限于原点切分数据。
4.GLU线性门控单元
1. 核心概念:什么是“门(Gate)”?
在神经网络中,所谓的“门”,本质上就是一个乘法器。
想象一条水管(数据流),我们在上面安装了一个阀门(门控)。
-
如果阀门的值是 0,水流被完全阻断(特征被抛弃)。
-
如果阀门的值是 1,水流畅通无阻(特征被完全保留)。
-
如果阀门的值是 0.5,水流减半(特征被削弱)。
在数学上,这就是通过一个输出值在 0 到 1 之间的函数(比如 Sigmoid 函数)来实现的。然后,把这个阀门的值与原始数据进行逐元素相乘(Element-wise Multiplication,符号为 )。
2. GLU 的内部计算流程
GLU 的精髓在于,它把同一个输入数据,兵分两路进行处理:
-
第一路:信息载体(Signal)
数据经过一个普通的线性变换(矩阵乘法)。这一步负责提取基础特征。
公式:
-
第二路:智能阀门(Gate)
数据经过另一个线性变换,然后额外通过一个 Sigmoid 激活函数。Sigmoid 会把所有数值压缩到 0 到 1 之间,形成一系列“开/关”信号。
公式:
-
汇合点:逐元素相乘
最后,把“信息载体”和“智能阀门”对应位置的数字乘起来。
GLU 完整公式:
为什么叫“线性”门控?
因为如果不看那个 Sigmoid 函数,这两路原本都只是简单的线性变换( 和
)。正是这个非线性的“门”,赋予了整个结构强大的表达能力。
3. 为什么 GLU 这么强?(优势分析)
-
动态的信息过滤: 传统的激活函数(如 ReLU)是“死”的,负数直接归零。而 GLU 的门控是通过网络自己学习出来的(由权重 V 决定)。模型可以根据当前的上下文,智能地决定打开或关闭某些维度的特征。
-
缓解梯度消失: 在大模型训练反向传播时,由于包含了直接的线性路径(
),梯度可以更容易地流过网络,使得训练极其庞大的模型变得更稳定。
GLU 线性门控 FFN:双线并行
而在使用了 GLU(比如目前最流行的 SwiGLU)的 FFN 中,输入信号 在刚进入 FFN 时,直接被“克隆”成了两份,分别走两条不同的路:
-
路径 A:信息载体路(内容)
输入信号
逻辑: “我负责把所有的特征都找出来,先不管有没有用。”
表示为:
-
路径 B:门控审核路(阀门)
输入信号
进行升维,并且立即穿过一个激活函数(比如 Swish)。这个激活函数会把数值转化为一系列代表“权重”或“开关”的信号。
逻辑: “我根据当前的上下文,判断哪些特征重要,哪些是废话。”
表示为:
-
汇合点:逐位相乘(相交)
将【路径 A】和【路径 B】得到的结果,在相同的位置上一个个乘起来(符号为
)。如果门控路给的权重是 0,信息路对应的特征就被抹除;如果给的是 1,特征就被完全保留。
逻辑: 内容和审核标准碰撞,留下真正有价值的信息。
表示为:
-
最终步:降维输出
最后,把相乘过滤后的精炼数据,再乘上矩阵
对比一下两者的数学表达,你就一眼能看出区别了(为了简洁,省略偏置项):
-
经典 FFN:
-
GLU-FFN (如 SwiGLU):
总结来说: GLU 结构就是多花了一个矩阵 的计算成本,换来了一个极其聪明的“动态特征筛选器”,这也正是 LLaMA 等现代大模型极其聪明的原因之一。
=========================================================
[ 输入向量 X ]
=========================================================
│ │
┌────────────┘ └────────────┐
│ │
(路径 A:信息载体) (路径 B:智能阀门)
▼ ▼
[ 矩阵 W1 ] [ 矩阵 V ]
(纯线性变换,升维) (纯线性变换,升维)
│ │
│ ▼
│ [ Swish 激活函数 ]
│ (将数值转化为动态权重开关)
│ │
└───────────────┐ ┌───────────────┘
▼ ▼
[ 逐位相乘 ⊗ ]
(将路径 B 的开关应用到路径 A 的信息上,
保留有用特征,抹除无用特征)
│
▼
[ 矩阵 W2 ]
(将过滤后的高维特征降维)
│
▼
=========================================================
[ 输出向量 Y ]
=========================================================问题:
1.写一下GLU线性门控的公式
2.写一下SWIGELU的公式
3.为什么GLU有用?
解答:
1.2:见上述公式
3:这里我展开讲一下
在深度学习中,增加任何计算量都是需要极强的理由的。GLU(门控线性单元)因为多了一条路径,意味着参数量和矩阵乘法的计算量直接增加了一半。
1. 特征级别的注意力
-
如果在句子“我吃了一个苹果”中,GLU 的门控网络会根据上下文计算出,此时“水果、食物、甜”相关的特征维度非常重要,于是把这些维度的门控值设为 0.9(放行);把“科技、手机、乔布斯”维度的门控设为 0.1(屏蔽)。
-
如果在句子“苹果发布了新手机”中,同一个 GLU 会把“科技”维度的门控调到 0.9,把“水果”维度关死。
2.乘法交互带来的更强的表达能力
在神经网络的基础理论中,绝大多数操作都是加法(线性组合):
加法在逻辑上代表着 “或(OR)” 的关系:只要 很大,或者
很大,结果就会很大。它们是独立贡献的。
但是,现实世界的逻辑往往是 “与(AND)” 的关系。比如,判断一个东西是不是“苹果公司”,必须是“科技企业”并且“标志是被咬了一口的苹果”。
GLU 的公式核心是逐元素相乘():
这种乘法操作,让模型可以极其轻松地捕捉到特征之间的交叉关系和条件依赖。它突破了单纯加法的限制,使得网络拟合复杂非线性逻辑的能力呈指数级上升。研究表明,带有乘法门控的网络,用更少的层数就能达到传统网络更深层的效果。
3. 缓解深层网络训练困难
大模型动辄几十层甚至上百层(比如 LLaMA-3 有 80 多个 Transformer 层)。网络越深,反向传播时“误差信号”就越容易在层层传递中衰减到 0(即梯度消失)。
我们再看一眼 GLU 的简略结构:
-
右边
是非线性的门控,梯度确实可能衰减。
-
但是左边
是一条纯线性的直通车
在反向传播求导时,这条纯线性路径保证了不管门控那边的梯度多微弱,总有一股强劲的梯度(误差信号)能够直接穿透 FFN,传回上一层。这极大地增加了训练百亿、千亿参数极深大模型时的数值稳定性。
GLU 之所以被大模型奉为圭臬,是因为它用一点额外的计算量,换来了动态筛选信息的能力、更高级的乘法逻辑推演,以及更稳定的底层训练基建。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)