AgentOps实践思考—从AI辅助工程师到AI驱动运维组织
大约十年前,嘉为蓝鲸通过蓝鲸 PaaS 平台架构与 SaaS 产品的运维开发模式,实现企业运维组织的生产力升级,从此一体化、平台化成为我们在这一领域的核心优势与技术底色。
十年后的今天,又一个「运维应用百花齐放」的历史时刻悄然来临。只不过这一次,涌现的不是传统运维软件,而是 AI 智能体——能够感知环境、自主推理、驱动工具、完成多步骤任务的新型软件范式。
这场变革的意义,远不止于「知识问答」、「流程自动化工具」这类局部效率提升。它真正指向的,是运维组织生产关系的再一次重构:从「人驱动工具」演进为「智能体自治完成任务」,人的价值向策略制定、边界管控、异常决策集中。
但在企业实践中,这条路并不平坦。以下是我们在推进 AgentOps 落地过程中积累的经验与思考。
PART 01
行业难点:为什么AgentOps落地如此之难
过去两年,几乎所有运维团队都尝试过 AI 在运维场景的应用,Demo 和 POC 很多,但真正在生产环境规模化落地、带来可量化价值的案例寥寥无几。问题出在哪里?我们总结为以下几点核心困境:
1. 价值无法衡量
企业在推进 AgentOps 时,面临的第一个拦路虎是价值可见性不足。AI 提升了多少效率?虚增了多少人力?节省了多少人力?避免了多少故障?这些问题在项目立项时没有答案,在项目上线后同样难以量化。没有可信的 ROI 数字,预算投入就缺乏说服力,场景就永远停留在演示阶段,无法进入真正的生产流程;但不投入又无法积累足够的数据和场景来证明价值。这个鸡与蛋的困局,是 AgentOps 落地最常见的阻力。
02. 基础数据与工具能力薄弱
AI 智能体的能力上限,很大程度上取决于它能调用的数据与工具的质量。然而很多企业的运维数据分散在多个平台,标准化程度低;MCP(模型上下文协议)工具接口尚未建立;历史事件知识库缺乏结构化整理。在这种基础上运行的 Agent,只能做到「会说话」,无法做到「会干活」。
03. 组织与信任双重阻力
将原本由人完成的工作交给 AI 自主执行,需要跨越两道门槛:技术门槛(Agent 能做对吗?)和信任门槛(出了问题谁负责?)。前者需要时间验证,后者需要组织文化转变。在没有成熟的人工卡点机制和审计框架的情况下,运维负责人很难对生产核心系统的自主操作「放心」。
04. 历史债务问题
从自动化运维,到AI辅助运维,再到AI自主运维,这一漫长的发展路径中既有技术上的一路迭代,也有员工技能的配套成长,还需要运维组织管理上的与时俱进,曾经缺失的环节,可能成为AI转型中的短板。比如一体化运维架构的成熟度会影响AI决策的精度和成功率;货币化管理实现与否会影响AI人力投入的合理性和价值度量;运维算力调度的空间决定了运维团队可以长期稳定投入在AI发展上的算力,等等。
PART 02
某大型组织实践:从0到20+的运维数字人
面对上述困境,某组织内部基于蓝鲸一体化运维平台开展了系统性的 AgentOps 建设实践。目前,通过智能体开发生态模式的构建,已生成 20+ 每天工作量超过8小时的运维数字员工,调度 500+ 智能体,覆盖测试环境管控、生产环境可靠性保障等运维全链路场景。
核心思路: 场景从效率出发(运维数字人)+ 场景构建要平台化(运维智能体开发)+ 一体化运维能力要丰富(MCP + 数据 + 知识)。
关键策略:
丰富的一体化运维能力:MCP + 数据 + 知识
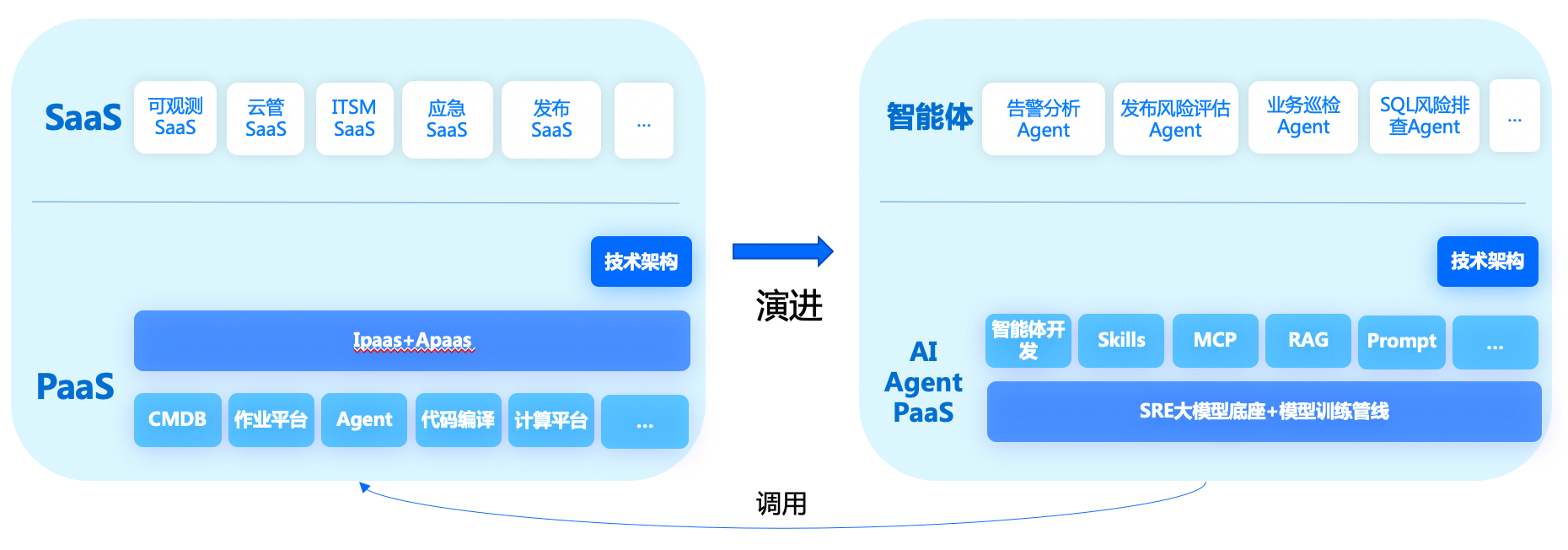
智能体的真正能力来源于底层一体化运维能力的支撑。通过复用API网关,将原有一体化运维平台API快速转化为LLM可调用的MCP接口,使Agent能够直接调度自动化操作。同时,平台沉淀了结构化运维数据和历史事件知识库,为智能体推理提供高质量上下文。Skills封装保证了操作标准化和可复用,RAG知识库驱动智能体获取精准信息并减少误判。这一能力组合确保Agent不仅“会说话”,更“会干活”,实现了生产环境中的可量化价值。
平台化构建:智能体开发平台(运维智能体开发)
延续了“PaaS + 场景”的架构理念,底座为运维智能体开发平台,为智能体研发提供统一底座。平台集成了大模型应用开发所需的关键能力,包括 RAG 知识库、MCP 接口管理、提示词管理、Skill 技能管理等。通过平台化设计,运维团队可以快速构建多场景Agent,并复用已有组件和技能,避免重复开发底层能力,从而显著提升智能体研发效率和落地速度。
提效场景驱动:以效率为核心的SRE数字人
智能体研发始终以运维效率提升为出发点,而不是对话或检索类应用。每个 Agent 的设计都参照运维组织的服务目录清单,明确其在运维流程中的职责边界。例如业务巡检、SQL 风险排查、岗位自动化操作、故障根因诊断等场景,都是以减少人工重复劳动、压缩响应时间、降低错误率为核心目标。通过这种场景驱动,数字分身真正承担起原本人工执行的工作,实现“碳基员工”向“硅基员工”的高效迁移。
01. 典型落地场景
以下列举几个已在测试和生产环境规模化运行的代表性场景:
- 场景一:业务巡检智能体

- 场景二:运维岗位智能体(群聊 Bot)

- 场景三:SQL 风险排查智能体

- 场景四:线上代码诊断智能体

- 场景五:CMDB查询智能体

- 场景六:告警根因分析智能体

(还有其他各类典型场景还在持续迭代和优化中)
02. 关键启示
这些场景的落地,验证了一个核心判断:以可衡量的工时效率为价值起点,比追求宏大的顶层设计更能推动组织真正行动起来。 场景落地同时反向推动了数据与工具能力的提升——Agent 对数据质量和工具接口的要求,倒逼一体化运维能力持续完善。
PART 03
场景思路:运维领域Agent任务替代地图
回归运维业务,我们按照业务领域对 AI 替代的可行场景进行了梳理。将业务梳理、工程设计与长期规划有机串联。
我们把AgentOps建设定义四个阶段和成熟度:
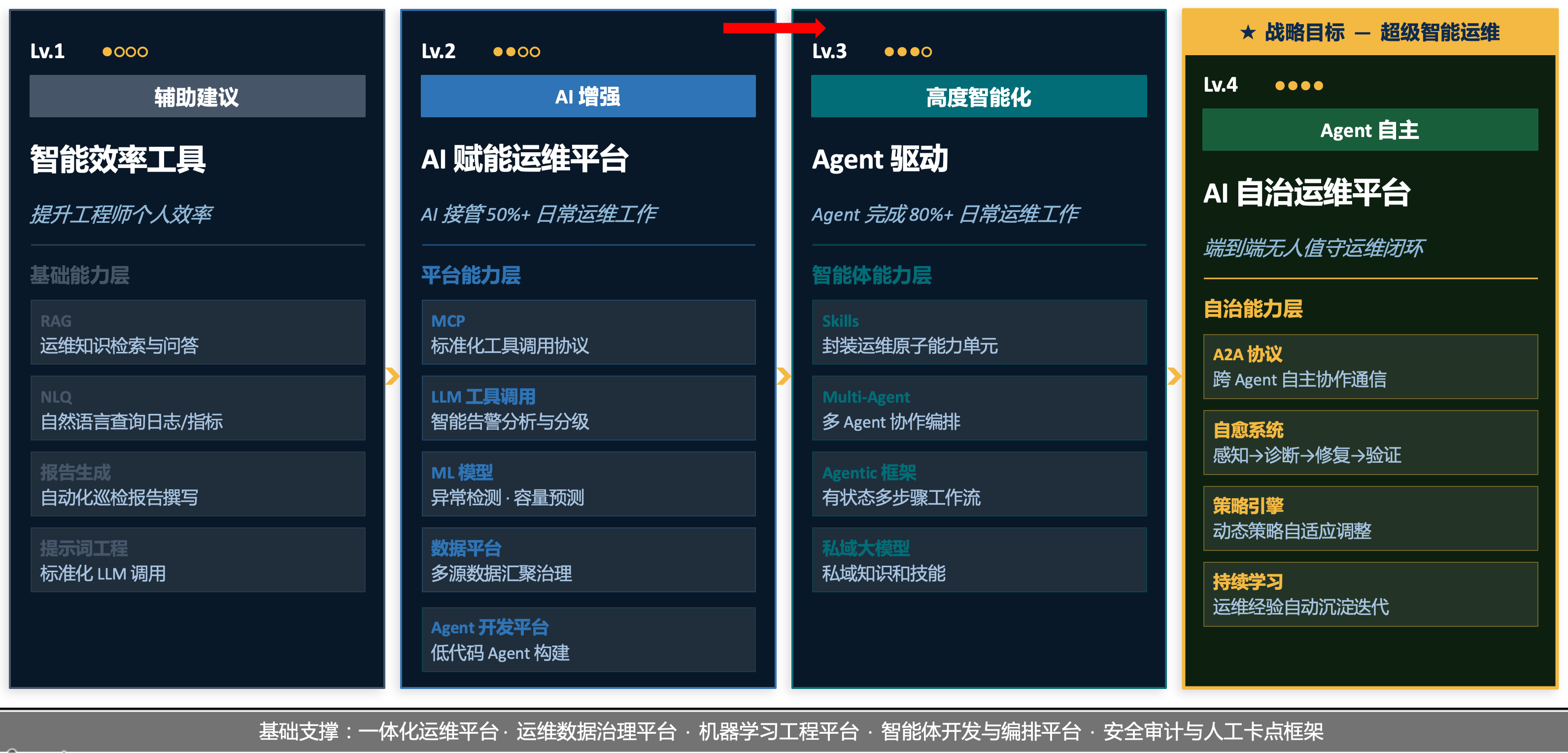
从业务流程梳理起步:
01. 基于运维业务流程建模,做任务级的AI替代分析,以事件管理为例;

从上表可以看出:事件管理全流程 10 个任务中,有 6 个可达 Lv.4(Agent自主)或 Lv.3(高度智能化)级别。这一分布规律在其他运维域也基本适用——结构化、可规则化的任务优先替代,需要跨角色共识的任务保留人工判断。
02. 进行任务级流程设计,设计人工卡点;
基于流程设计,来进行 skill、mcp、知识库、提示词的设计。如事件任务:
- 执行流程: 告警触发 → 告警聚合降噪 → 并行:指标分析 + 日志分析 + 链路分析 + CMDB 关联 → 根因候选排序 → 历史案例检索 → LLM 综合推断根因 → 推送诊断报告 + SOP 建议 → 记录诊断过程供复盘。
- 人工卡点: P0 级别事件根因推断结果需事件指挥官确认才能触发自动处置;根因置信度 <60% 时标注不确定性,提示人工介入。
03. 可持续规划的智能体;
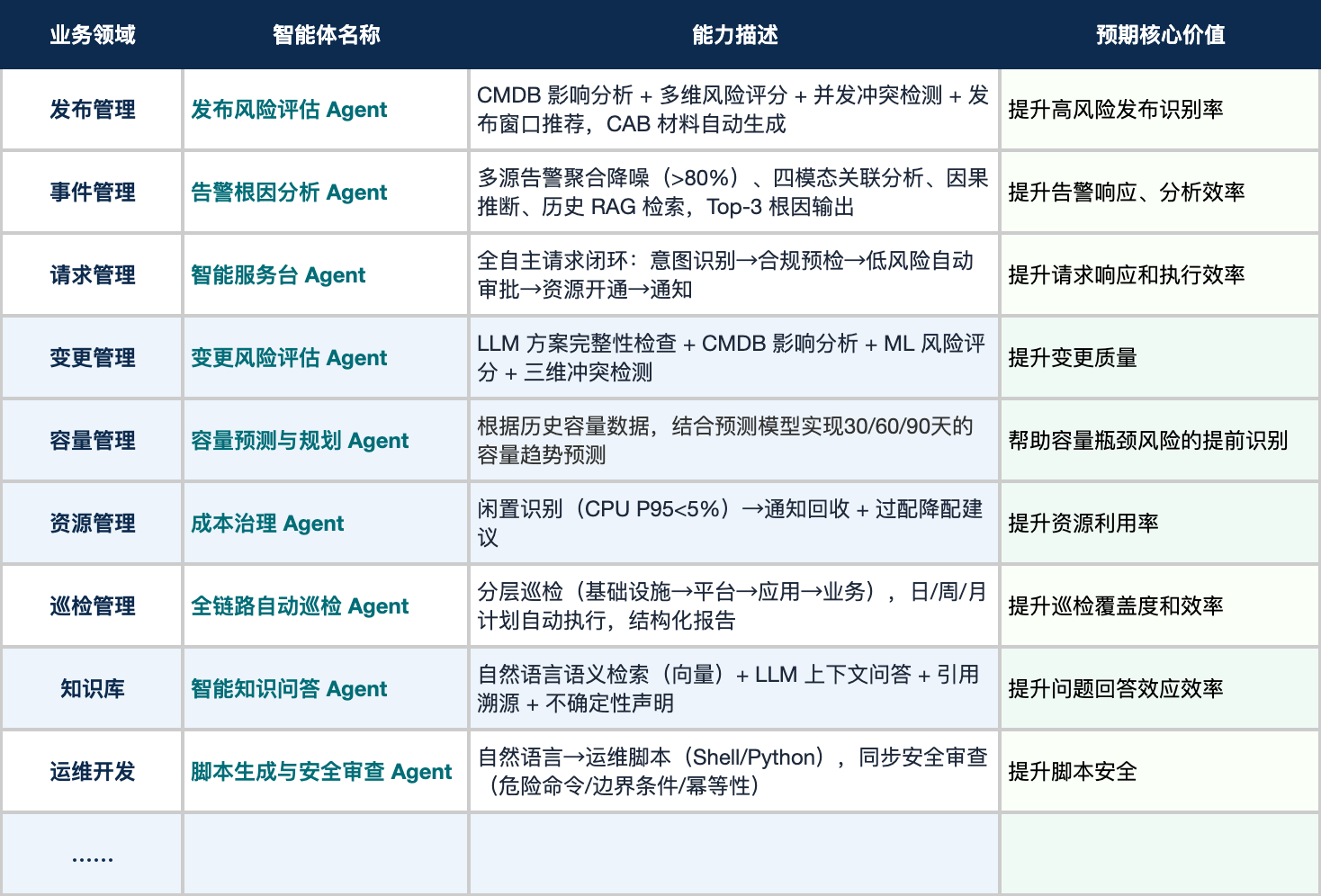
以下表格展示了各领域核心 Agent 的能力定义与核心价值:
04. 多智能体协同;
在某些场景下,需要多智能体协同才能完成,以我们还在持续探索的故障诊断多智能体协同为例,基于有优先级的假设列表,将子任务路由到子Agent并行执行,调用工具进行排障分析,再进行证据分析,和生成诊断报告。

PART 04
架构路线:智能体开发平台+一体化+大模型
我们的整体架构设计遵循一个核心原则:与大模型能力增强方向正向协同。 这意味着:不重复建设大模型已经擅长的能力,而是聚焦在大模型与运维业务的连接层——数据、工具接口、知识沉淀、编排框架。

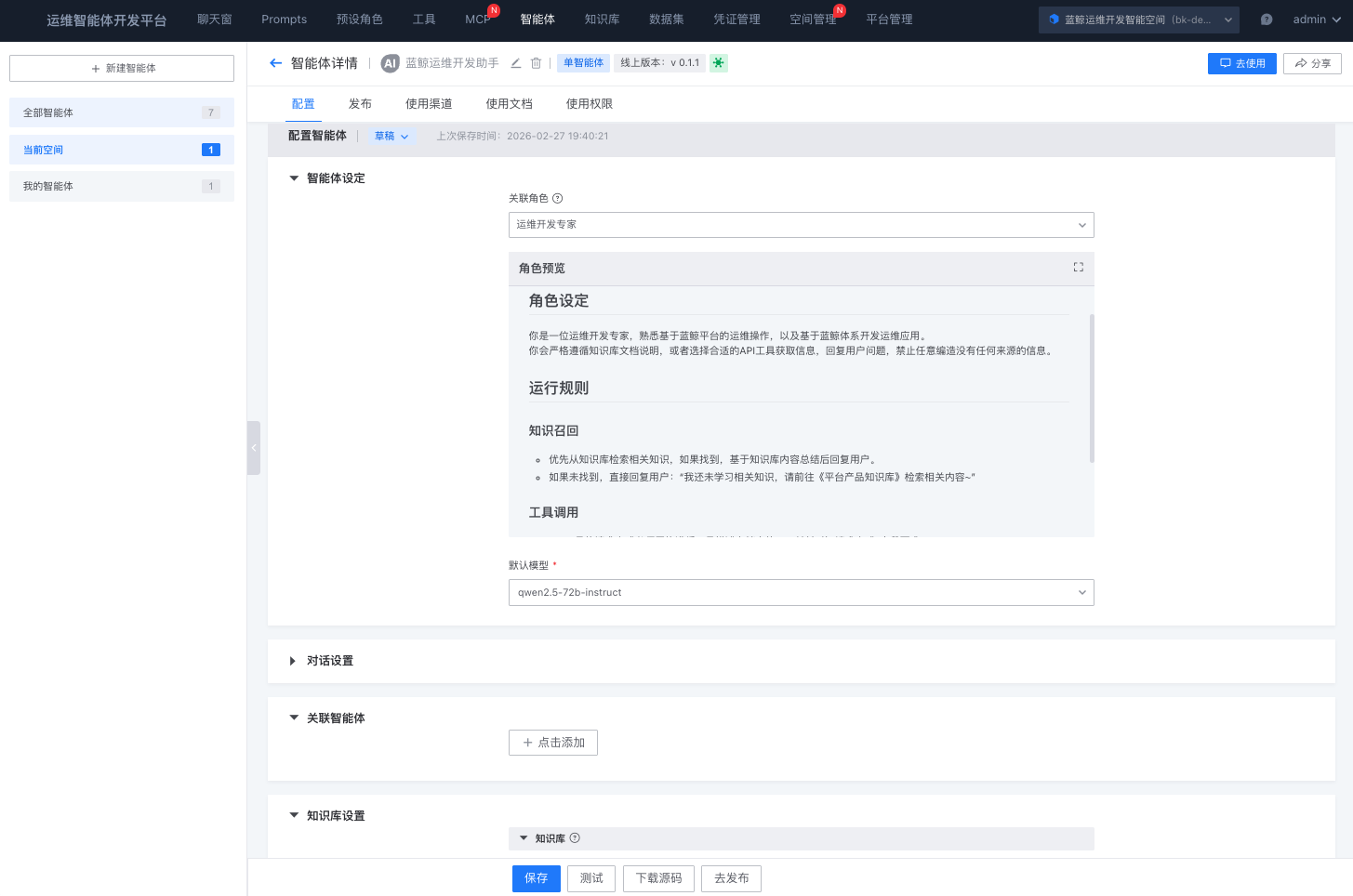
架构设计聚焦于大模型与运维业务之间的「连接层」——数据标准化、工具接口治理、知识沉淀与 Agent 编排,而非与大模型已有能力重复建设。具体设计原则如下:
- MCP 优先: 所有外部系统调用统一通过 MCP 协议接入,避免 Agent 直接耦合底层 API,降低维护成本,提升工具复用率。
- Skills 沉淀: 将反复使用的原子操作(告警聚合、RunBook 匹配、影响评估等)封装为标准 Skill,供多个 Agent 调用,避免重复建设。
- RAG 驱动知识: 运维历史事件、操作手册、系统架构文档全量向量化,Agent 在推理时通过语义检索获取精准上下文,显著降低幻觉率。
- 智能体场景: 基于运维业务场景流程设计,逐步形成单智能体、多智能体、智能体协同的生态模式,解决更多复杂场景。
- Human-in-Loop: 在高风险操作节点(删除资源、切换流量、变更核心配置)强制插入人工审批卡点,AI 越自主的地方,管控越精确。
- 审计优先: 所有 Agent 操作写入不可篡改的操作日志,满足等保合规要求,也是建立组织信任的基础设施。
PART 05
体系方法:如何在企业内推进 AgentOps 落地
基于我们的实践,总结出以下推进方法供参考:
01. 先跑起来,让组织形成新习惯
AgentOps 的推进不能等「完美方案」落地后才开始。建议先选择 2-3 个痛点清晰、价值可见的场景快速落地,场景先行和顶层设计收敛,让工程师在真实使用中提炼需求、形成新的协作习惯。群众的力量是第一位的——当团队成员主动创建和使用 Agent,生态才真正开始运转。
实操建议: 优先选择「现有流程繁琐但逻辑清晰」的场景,如账号开通、服务巡检、SQL 审查等。这类场景 AI 替代成功率高,价值可快速量化,且风险可控。
02. 业务流程梳理仍然是起点
很多团队的 AgentOps 探索失败,根源在于跳过了业务流程梳理这一步。AI 不能自动让混乱的流程变得清晰,它只是让清晰的流程执行得更快。在引入 Agent 之前,必须先完成:流程现状梳理 → 任务级 AI 替代分析 → 价值量化基线建立。
具体方法:以运维业务领域为单位(ITSM、变更、监控、发布等),逐一拆解到任务级别,评估每个任务的 AI 替代可行性(数据是否具备?工具接口是否就绪?风险是否可控?),形成场景优先级矩阵。
03. 基础能力建设是长期投资
Agent 的智能上限取决于它能访问的数据质量和工具能力的丰富度。一体化运维平台为 AgentOps 提供的不只是展示界面,更是数据底座和 MCP 工具生态。具体而言:
- 数据层: 监控指标、日志、变更记录、CMDB 关系等数据需要标准化、实时化,Agent 才能「有米下锅」。
- 工具层: 建立 MCP 工具注册中心,覆盖主要系统的读写操作接口,是 Agent 自主执行的前提。
- 知识层: 历史事件、RunBook、系统架构文档的向量化入库,是 RAG 检索准确性的基础。
04. 建立可迭代的度量体系
初期不要追求精细的度量体系,反而会成为推进的阻力。建议分两阶段:
- 第一阶段——效能度量: Agent 执行次数、任务成功率、处理时长(Before vs After)、人工干预率。这些数据易于采集,且直接反映效率提升。
- 第二阶段——质量度量: Agent 决策准确率、误操作率、SLA 达标率、人力替代比例。需要更长时间的数据积累,但能真正体现 AI 替代的深度。
关键原则: 每个 Agent 上线前,必须建立价值基线(Before 数据);上线后,定期回顾数据对比。没有 Before,就没有 After,场景就永远是 Demo。
05. 组织变革与技术变革同步推进
AgentOps 的本质是一场运维组织的生产关系变革,技术只是载体。 与技术推进同等重要的是组织侧的配套:
- 设立「智能体 Owner」角色: 每个业务场景的 Agent 需要有人负责持续迭代和维护。
- 建立 Agent 开发生态: 降低普通工程师构建和发布 Agent 的门槛,让 Skill 和 Agent 能力在组织内部自由流动复用。
- 重新定义 SRE 价值: SRE 的工作重心从执行操作转向策略配置、边界审批、Agent 质量管理,这需要明确的岗位定义调整。
06. 强调权限管控和过程透明
随着 AI 拥有了“行动权”,例如服务器执行脚本、故障自愈执行,风险也随之增加。在推行 AI Agent 时,需要强调安全管控与治理。
- 设置权限管控: 对生产环境的操作权限需要严格管控,可在接口层提供需要人工二次确认的接口给到AI Agent。
- 透明度: 需要更详细的日志和审计功能,让人类管理员可以回溯 Agent 为什么做出了某个决定。
PART 06
此刻评估:现状认知与未来判断
真正意义上的「无人值守运维闭环」(Lv.4)距离大规模落地还有相当距离。核心挑战在于:
- 可靠性要求极高: 生产系统的自主操作,一次误判的代价可能是灾难性的,Agent 决策的可靠性需要在数千次执行中验证。
- 跨域协同复杂度: Lv.4 依赖多个 Agent 之间的无缝协作(A2A),这需要标准化协议、共享上下文和协调机制,目前行业尚在探索。
- 组织信任需要时间建立: 即便技术上可行,让组织真正信任 AI 自主执行高风险操作,需要大量成功案例积累和逐步扩大的授权边界。
- 数据与工具壁垒将成为核心竞争力: 能够最先建立起高质量运维数据资产和丰富 MCP 工具生态的组织,将在 AgentOps 时代获得持续领先优势。
AgentOps 不是一场「押注未来」的赌博,而是一次「补齐当下」的务实投资。从效率工具开始,把数据做好、把工具接口做通、把知识沉淀下来——这些今天看来「基础」的工作,恰恰是三年后规模化 Agent 自治的真正护城河。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)