【CSDN星图AI实战】Kimi-VL-A3B-Thinking 多模态模型实测与部署指南
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋

作为一名深耕 AI 开发多年的实践者,同时也是 CSDN 星图 AI 的资深用户,我最近在该平台上体验了一款令人印象深刻的多模态模型——Kimi-VL-A3B-Thinking。这款开源混合专家(MoE)视觉语言模型,凭借仅 2.8B 激活参数实现旗舰级性能的表现,让我看到了多模态 AI 轻量化的新可能。
本文将结合一手实测经验,分享该模型的核心特性、部署流程与使用心得,帮助开发者在 CSDN 星图 AI 生态中快速上手这一先进工具。
一、模型概览:小参数,大能量
在大模型追求轻量化与高效化的趋势下,Kimi-VL-A3B-Thinking 为多模态领域提供了一个极具竞争力的解决方案。
1.1 MoE 架构:效率与性能的平衡点
Kimi-VL 采用混合专家(Mixture-of-Experts)架构,这是其实现高效推理的核心设计:
- 稀疏激活:处理每个 token 时仅激活部分专家模块,大幅降低计算开销
- 参数效率:总参数量 3B,激活参数仅 2.8B,却能媲美更大规模模型的性能
- 知识容量:保留大容量模型的知识存储能力,避免"小模型"常见的知识瓶颈
1.2 多模态能力矩阵
| 能力维度 | 具体表现 | 对标水平 |
|---|---|---|
| 代理任务 | OSWorld 等场景达到 SOTA | 比肩旗舰模型 |
| 视觉理解 | 大学级图像/视频理解、OCR | 超越 GPT-4o |
| 复杂推理 | 数学推理、多图联合理解 | 领先同规模模型 |
| 综合性能 | 与 Qwen2.5-VL-7B、Gemma-3-12B-IT 竞争 | 高效 VLM 第一梯队 |
1.3 长上下文与高分辨率:突破体验瓶颈
128K 扩展上下文窗口
- LongVideoBench 得分:64.5
- MMLongBench-Doc 得分:35.1
原生分辨率视觉编码 MoonViT
- InfoVQA 得分:83.2
- ScreenSpot-Pro 得分:34.5
这意味着 Kimi-VL 能够"看清"超高分辨率图像的细节,同时"记住"长文档或视频的全局信息。
1.4 Kimi-VL-Thinking:让模型"会思考"
基于基础模型,Kimi-VL-Thinking 通过长链式思维(Chain-of-Thought)监督微调 + 强化学习训练,展现出卓越的深度推理能力:
| 评测基准 | 得分 |
|---|---|
| MMMU | 61.7 |
| MathVision | 36.8 |
| MathVista | 71.3 |
值得注意的是,这些成绩是在仅 2.8B 激活参数的轻量 footprint 下取得的。
1.5 架构设计:三组件协同
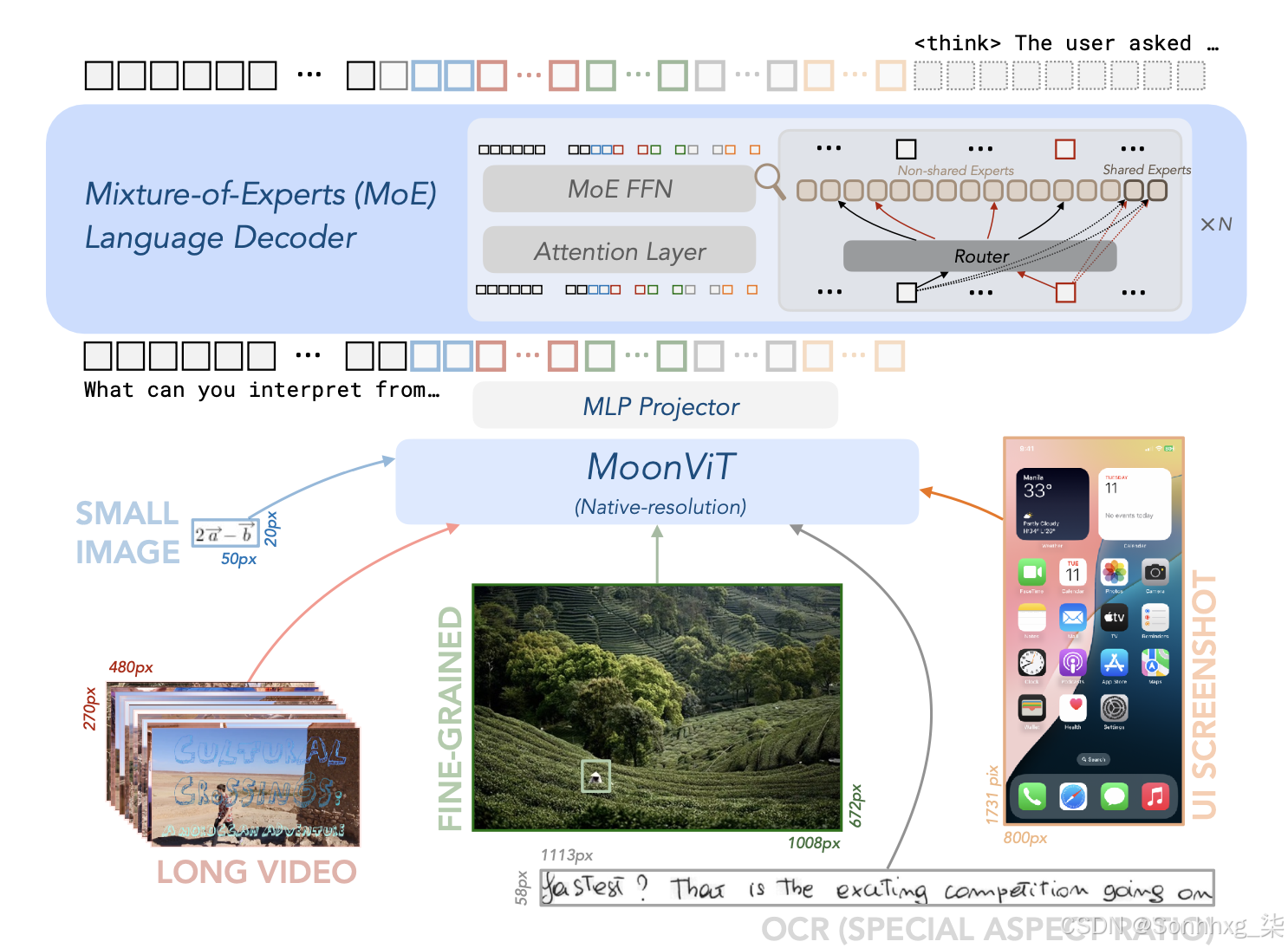
┌─────────────────┐ ┌─────────────┐ ┌─────────────────┐
│ MoE 语言模型 │ ←── │ MLP 投影器 │ ←── │ MoonViT 视觉编码 │
│ (高效参数利用) │ │ (特征融合) │ │ (原生分辨率处理) │
└─────────────────┘ └─────────────┘ └─────────────────┘
二、环境准备:零配置开箱即用
本次实测基于 CSDN 星图 AI 专属镜像,核心优势:
- ✅ 预装完整依赖,无需手动配置
- ✅ 模型文件内置,跳过下载等待
- ✅ 一键启动脚本,降低使用门槛
⚠️ 使用声明:镜像资源仅限个人学习研究,禁止商业用途。
硬件建议:确保 GPU 显存满足模型加载需求,网络连接正常即可。
三、部署流程:两步上线
3.1:验证服务状态
通过 CSDN 星图 AI 的 WebShell 进入终端,执行:
cat /root/workspace/llm.log预期输出:模型加载完成、服务端口启动成功的日志信息。
若未正常启动,可尝试重启镜像或检查环境配置。
3.2:启动模型服务(备用)
如镜像未自动启动服务,执行内置启动脚本即可。脚本已针对 GPU 显存利用率优化,确保稳定运行。
/opt/miniconda3/bin/vllm serve --served-model-name Kimi-VL-A3B-Thinking --max-num-seqs 16 --max-model-len 8192 --gpu_memory_utilization 0.95 --model /root/ai-models/moonshotai/Kimi-VL-A3B-Thinking --port 8000 --host 0.0.0.0 --trust_remote_code --allowed-local-media-path /root/workspace四、交互体验:可视化与代码双模式
4.1 Chainlit 可视化界面(推荐新手)
镜像内置 Chainlit 快捷启动命令,执行后将生成前端访问链接:
特点:零代码、即时交互、多模态输入友好
适用:快速验证、效果演示、非技术用户
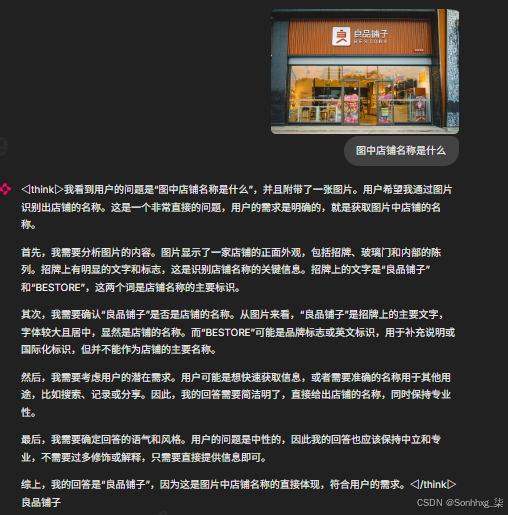
实测案例:上传一张店铺招牌图片,提问"图中店铺名称是什么"——模型秒级响应,准确识别文字信息,展现了扎实的 OCR + 视觉理解能力。

4.2 代码调用(开发者进阶)
如需批量处理或集成到业务系统,可参考镜像中的代码示例:
# Copyright 2026 The sonhhxg0529 Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import time
import chainlit as cl
from chainlit.input_widget import TextInput,Tags,Slider,Select,Switch
import asyncio
import aiohttp
from openai import AsyncClient
from opentelemetry.instrumentation.auto_instrumentation import initialize
# 创建图片保存目录
os.makedirs("uploads", exist_ok=True)
openai_client = AsyncClient(api_key=os.environ.get("OPENAI_API_KEY","EMPTY"),
base_url=os.environ.get("OPENAI_API_BASE","http://localhost:8000/v1"))
async def save_image_locally(image_path, filename):
"""将图片保存到本地"""
import shutil
try:
# 复制文件到uploads目录
dest_path = os.path.join("/root/workspace", filename)
shutil.copy2(image_path, dest_path)
return dest_path
except Exception as e:
print(f"保存图片失败: {e}")
return None
@cl.on_chat_start
async def start():
settings = await cl.ChatSettings(
[
Select(
id = "Model",
label = "模型",
values= ["Kimi-VL-A3B-Thinking"],
initial_index=0
),
Slider(
id = "Temperature",
label = "温度",
initial=0.7,
min=0,
max=1,
step=0.05
),
Slider(
id="Top_p",
label="Top_p",
initial=0.9,
min=0,
max=1,
step=0.05
),
Switch(id="Streaming",label="是否流式输出",initial=True),
Tags(id="StopSequence",label="停止序列",initial=["Answer:"]),
TextInput(id="AgentName",label="代理名称",initial="AI")
]
).send()
model_value = settings["Model"]
cl.user_session.set("model_value",model_value)
temperature_value = settings["Temperature"]
cl.user_session.set("temperature_value", temperature_value)
is_streaming = settings["Streaming"]
cl.user_session.set("is_streaming", is_streaming)
top_p = settings["Top_p"]
cl.user_session.set("top_p", top_p)
cl.user_session.set(
"message_history",
[
{
"role": "system",
"content": "You are a useful AI assistant!",
}
],
)
async def llm_answer():
message_history = cl.user_session.get("message_history")
model_name = cl.user_session.get("model_value")
temperature_value = cl.user_session.get("temperature_value")
is_streaming = cl.user_session.get("is_streaming")
top_p = cl.user_session.get("top_p")
msg = cl.Message(content="",created_at="qwen")
settings = {
"temperature": temperature_value,
"max_tokens": 512,
"top_p": top_p,
"frequency_penalty": 0,
"presence_penalty": 0,
}
stream = await openai_client.chat.completions.create(
model=model_name,
messages=message_history,
stream=True,
**settings,
)
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
message_history.append({"role": "assistant", "content": msg.content})
await msg.send()
@cl.on_message
async def main(message:cl.Message):
message_history = cl.user_session.get("message_history")
# 处理包含图片的消息
if message.elements:
content = []
# 添加文本内容
if message.content:
content.append({"type": "text", "text": message.content})
print(message.elements)
# 处理图片
for element in message.elements:
if element.type == "image":
# 生成唯一的文件名
filename = f"{int(time.time())}_{getattr(element, 'name', 'image')}"
# 保存图片到本地
local_path = await save_image_locally(getattr(element, 'path', ''), filename)
if local_path:
# 使用本地路径的URL
content.append({"type": "image_url", "image_url": {"url": f"file://{os.path.abspath(local_path)}"}})
else:
# 如果保存失败,使用原始URL
content.append({"type": "image_url", "image_url": {"url": getattr(element, 'url', '')}})
print(content)
message_history.append({"role": "user", "content": content})
else:
# 普通文本消息
message_history.append({"role": "user", "content": message.content})
print(message_history)
await llm_answer()五、核心优势:为什么值得尝试?
| 优势 | 说明 |
|---|---|
| 极致效率 | 2.8B 激活参数实现旗舰性能,推理成本大幅降低 |
| 多模态全能 | 视觉理解、OCR、数学推理、长文档处理一站式覆盖 |
| 长上下文 | 128K 窗口支持视频、长文档等复杂场景 |
| 高分辨率 | MoonViT 原生处理超高分辨率图像,细节不丢失 |
| 深度推理 | Thinking 版本具备 CoT 能力,复杂问题拆解清晰 |
| 部署极简 | CSDN 星图 AI 镜像两步启动,零配置负担 |
| 开源自由 | 可二次开发、微调,适配垂直场景 |
六、结语
Kimi-VL-A3B-Thinking 代表了多模态大模型"轻量化却不失能力"的新方向。MoE 架构带来的效率优势,叠加 MoonViT 的视觉编码能力与 Thinking 模式的深度推理,使其在 3B 参数级别展现出越级竞争力。
本次基于 CSDN 星图 AI 镜像的实测体验流畅高效,从部署到调用全程无卡点,也印证了该平台在 AI 工具整合方面的成熟度。建议对多模态应用感兴趣的开发者亲自上手,感受这款"小而强"模型的实际表现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)