百万级企业表格的AI分析,BRTR掀翻了多模态RAG的路子
BRTR的成功验证了 "检索即推理" 的新范式——对于结构化数据,让LLM主动探索比被动接受上下文更有效。这不仅是电子表格领域的突破,也为处理数据库、知识图谱等结构化数据提供了新思路。
企业里的Excel表格动辄包含数百万单元格、跨表引用和嵌入式图表,但现有AI方案在处理这类复杂表格时面临三大痛点:
- 单次检索的局限:传统RAG只检索一次就生成答案,容易遗漏关键信息
- 数据压缩失真:把表格压缩后喂给大模型,会丢失跨表关联和视觉信息
- 上下文窗口爆炸:直接塞入完整表格会超出模型处理上限
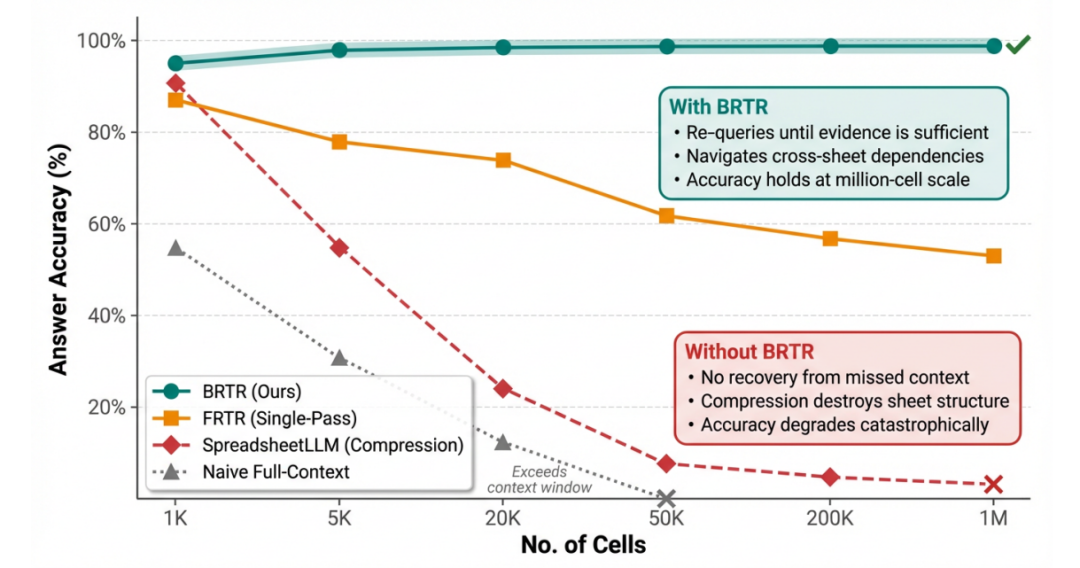
如图所示,随着表格规模增长,单次检索和压缩方法的准确率急剧下降,而暴力全量输入在5万单元格处就触发了上下文上限。
BRTR框架
BRTR(Beyond Rows to Reasoning)是一个多模态智能体框架,核心创新是 用"迭代式工具调用"替代"单次检索" 。
工作原理
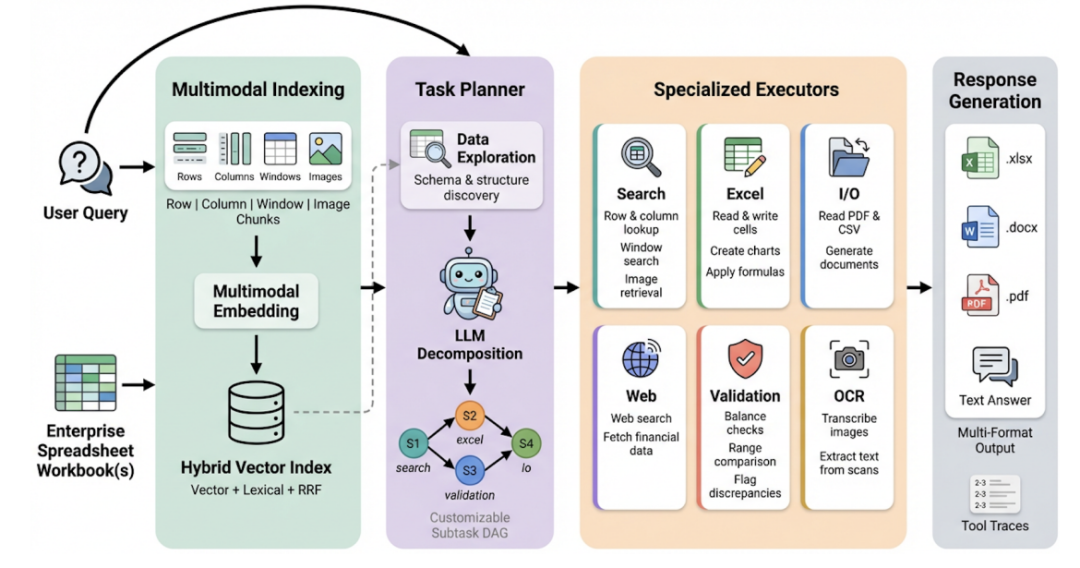
整个流程分为四个阶段:
- 多模态索引:将表格切分为行、列、窗口、图片四种块,用向量数据库存储
- 智能体规划:把复杂任务拆解为依赖图,并行执行独立子任务
- 迭代检索循环:LLM可以多次调用搜索工具(search_rows/columns/windows/images),根据中间结果 refinement 查询
- 多格式输出:支持生成分析结论、修改表格、创建图表等
关键设计:
- 上下文预算机制:每次只保留最新检索的图片,旧图片仅保留元数据,防止token爆炸
- 混合检索:结合向量相似度搜索(Dense)和关键词匹配(BM25),用RRF算法融合结果
实验亮点
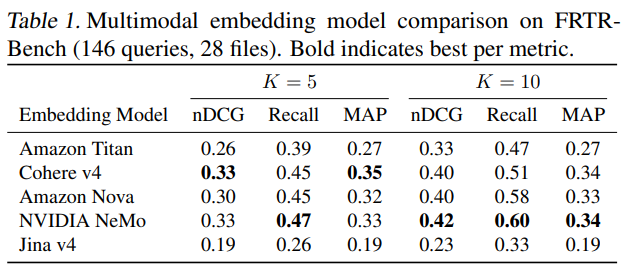
1. 嵌入模型选型
测试了5款多模态嵌入模型,NVIDIA NeMo Retriever 1B在表格数据上表现最佳(Recall@10达0.60),成为后续实验的默认选择。
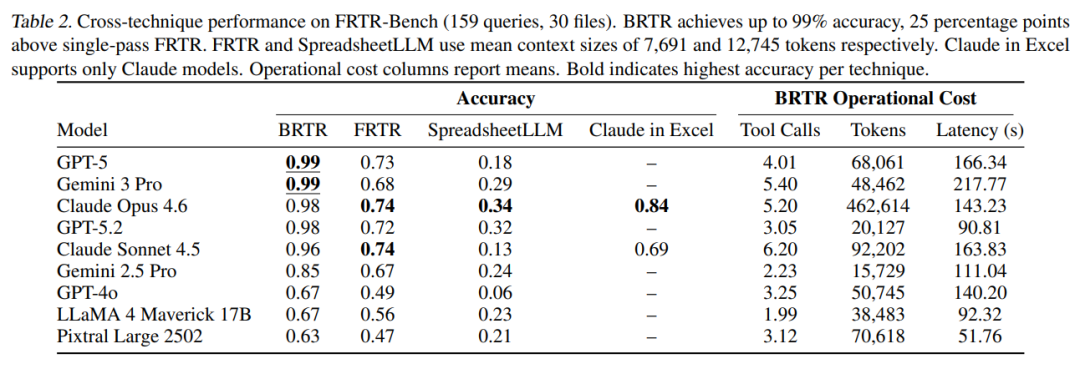
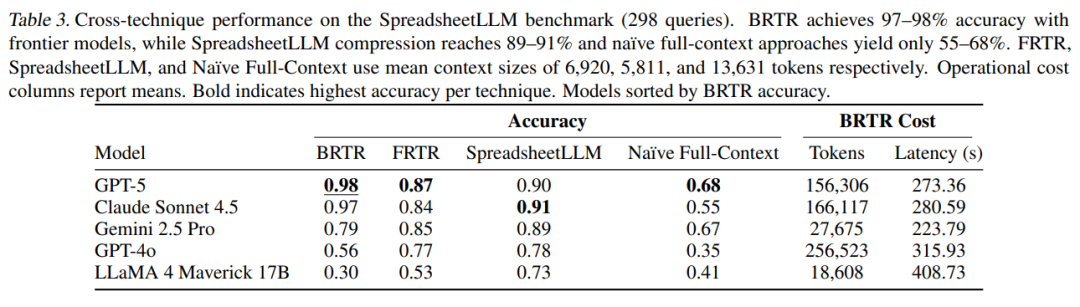
2. 主实验结果
在三个权威基准测试中,BRTR均创下新SOTA:
|
基准测试 |
BRTR最佳成绩 |
相比前代提升 |
|
FRTR-Bench |
99% (GPT-5) |
+25个百分点 |
|
SpreadsheetLLM |
98% (GPT-5) |
+7个百分点 |
|
FINCH |
95% (Claude Opus 4.6) |
+32个百分点 |
特别值得注意的是,在FRTR-Bench的23道需要解读嵌入式图片的题目中,BRTR仅错2题(均为OCR误读),而单次检索方法仅得65分。
3. 消融实验(表5、图4)
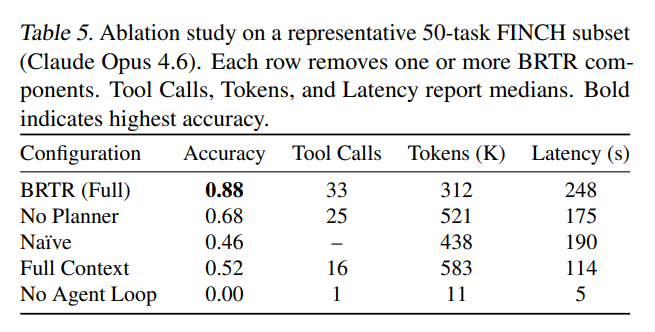
验证各组件贡献:
- 移除规划器:准确率从88%跌至68%,且token消耗增加40%
- 移除智能体循环:准确率直接归零,证明多轮推理不可或缺
- 全量上下文:准确率仅52%,且20%任务因超长无法完成
方案优势总结
- 准确率突破:在复杂企业级表格场景下,首次将准确率推近99%
- 可解释性:所有操作通过工具调用显式记录,满足审计要求
- 成本可控:GPT-5.2在保持98%准确率的同时,token消耗最低(仅20K/查询)
- 多模态支持:统一处理表格数据、图表、PDF、网页等异构信息
启发与思考
BRTR的成功验证了 "检索即推理" 的新范式——对于结构化数据,让LLM主动探索比被动接受上下文更有效。这不仅是电子表格领域的突破,也为处理数据库、知识图谱等结构化数据提供了新思路。
Beyond Rows to Reasoning: Agentic Retrieval for Multimodal Spreadsheet Understanding and Editing
https://arxiv.org/pdf/2603.06503
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)