大模型微调框架 LLaMA-Factory 实战指南
目录
一、前言
开源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用数据进行训练而来,其对于不同下游的使用场景和垂直领域的效果有待进一步提升,衍生出了微调训练相关的需求,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf)等全链路。但大模型训练对于显存和算力的要求较高,同时也需要下游开发者对大模型本身的技术有一定了解,具有一定的门槛。
LLaMA-Factory项目的目标是整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。同时借鉴 Stable Diffsion WebUI相关,本项目提供了基于gradio的网页版工作台,方便初学者可以迅速上手操作,开发出自己的第一个模型。
简单来说,LLaMA-Factory就像一个“大模型微调工具箱”,它将各种复杂的微调技术(如LoRA、QLoRA等)封装成易于使用的模块,并通过命令行界面(CLI)、网页界面(Web UI)和API等多种方式供用户调用。
框架对比:
| 框架/方式 | 特点 | 优势 | 劣势 |
|---|---|---|---|
| LLaMA-Factory | 统一框架,支持Web UI和CLI | 易用性极高,功能全面,覆盖从数据到部署全流程,迭代速度快 | 对于追求极致训练吞吐量的场景,速度可能略逊于高度优化的专用库 |
| Unsloth | 专注于LoRA训练加速 | 训练速度极快,显存优化出色 | 主要聚焦于LoRA,功能相对单一 |
| Axolotl | 配置驱动的强大框架 | 功能强大,灵活性高,社区活跃,YAML配置方式适合版本控制 | 学习曲线较陡峭,配置复杂,对新手不够友好 |
| 原生Hugging Face Trainer | 标准训练流程 | 灵活性最高,完全可控,适合研究自定义算法 | 需要编写大量代码,开发效率低,容易出错 |
二、安装部署
2.1 环境依赖
# 代码克隆
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 虚拟环境创建
conda create -n llama_factory python=3.12
# 依赖安装
conda activate llama_factory
cd LlamaFactory
pip install -e . && pip install -r requirements/metrics.txt -r requirements/deepspeed.txt
2.2 环境验证
执行:
llamafactory-cli version输出:

2.3 UI界面
执行:
llamafactory-cli webui服务启动,默认端口 7860

浏览器打开:
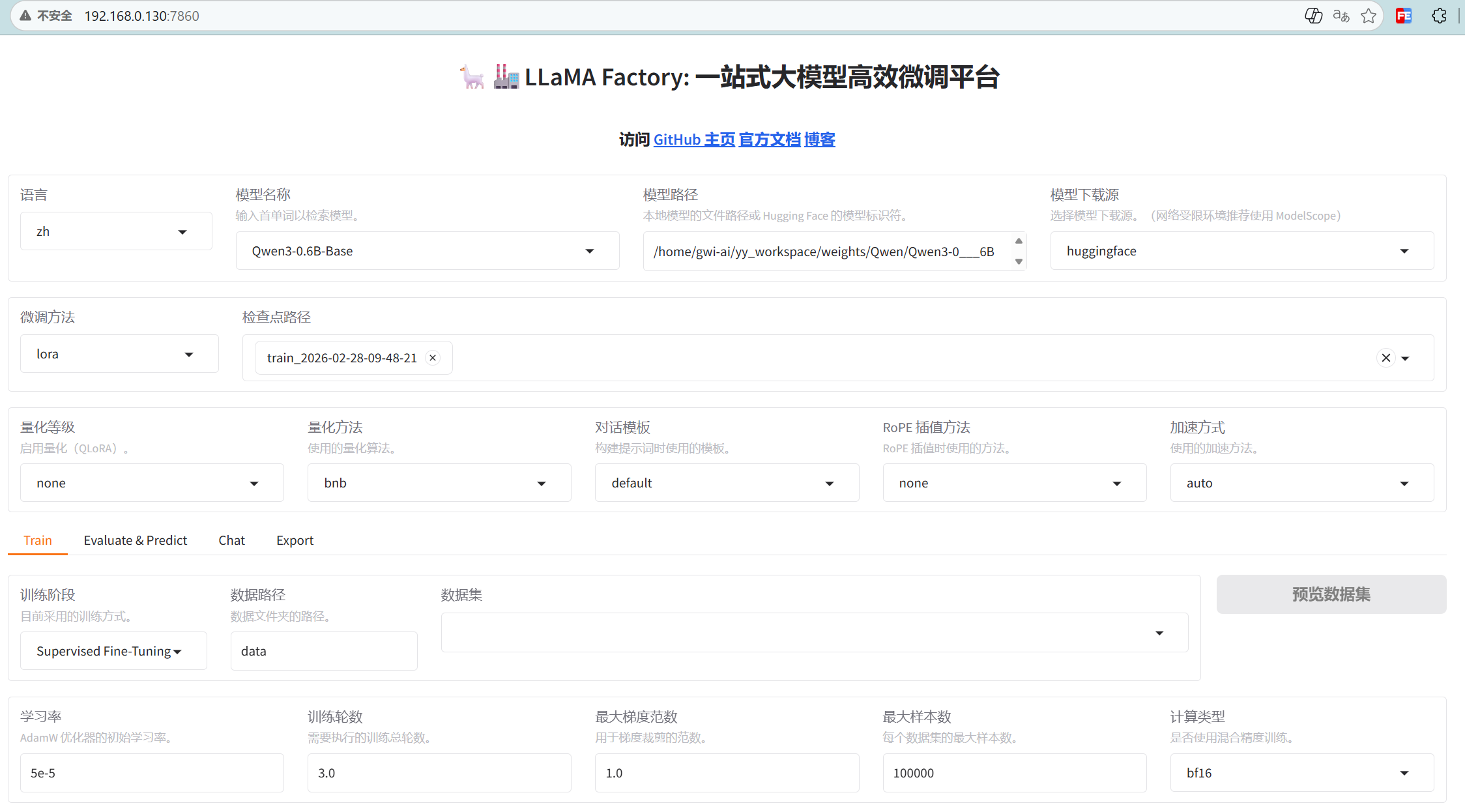
三、数据集说明
3.1 数据集格式
在LLaMA-Factory中,数据集主要围绕两种核心格式组织:Alpaca格式 和 ShareGPT格式 。框架通过这两种灵活的基础格式,结合不同的字段定义,来支持从文本指令到多模态数据的各类微调任务 。
| 特性 | Alpaca格式 | ShareGPT格式 |
|---|---|---|
| 设计哲学 | 以 “指令-输入-输出” 为核心,结构清晰,适合标准的单轮或多轮指令微调任务 。 | 以 “对话流” 为核心,通过from和value键记录每个发言角色和内容,能模拟更复杂的对话场景,如多角色对话、工具调用(Function Call) 。 |
| 适用场景 | 标准的指令微调(SFT)、预训练(Pre-training)、偏好训练(DPO/ORPO) 和 KTO 等 。 | 复杂多轮对话 和 智能体(Agent)任务(需使用工具)的微调 。 |
指令监督微调数据集 (Supervised Fine-Tuning, SFT)
这是最常用的微调方式,让模型学习根据指令给出回答。
Alpaca 格式示例:
[
{
"instruction": "计算这些物品的总费用。",
"input": "汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。",
"system": "你是一个有用的助手。", // 可选
"history": [ // 可选,用于多轮对话
["第一轮指令", "第一轮回答"]
]
}
]在训练时,instruction和input字段的内容会被拼接成完整的用户输入。
ShareGPT 格式示例:
[
{
"conversations": [
{
"from": "human",
"value": "你好,今天天气怎么样?"
},
{
"from": "gpt",
"value": "你好!今天天气晴朗,适合外出。"
}
],
"system": "你是一个友好的助手。", // 可选
"tools": "" // 可选,用于函数调用
}
]注意:human和observation必须出现在奇数位置,gpt和function必须出现在偶数位置。
3.2 数据集存放位置
默认数据路径为 data/,可以直接使用项目提供的示例数据进行测试。

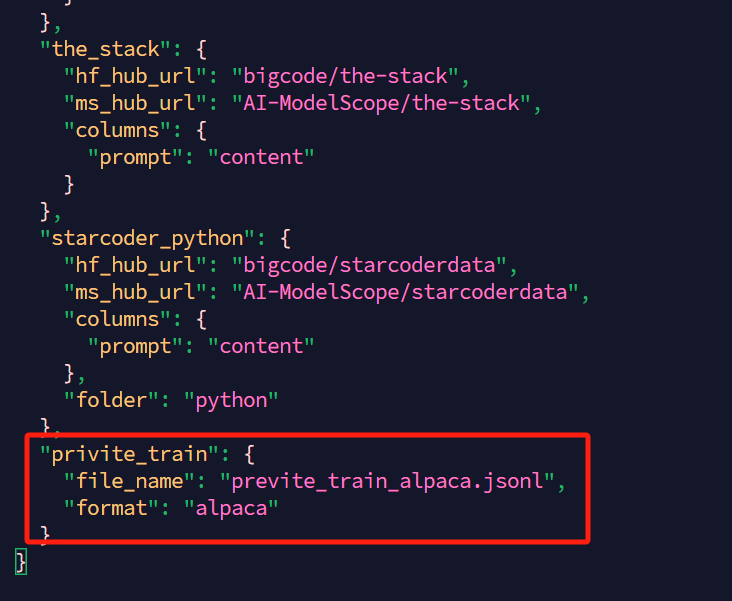
也可以使用自定义的数据集,如自定义数据集 previte_train_alpaca.jsonl,将自定义数据集放置在data 目录下,然后在dataset_info.json中进行添加。
"privite_train": {
"file_name": "previte_train_alpaca.jsonl",
"format": "alpaca"
}
四、微调
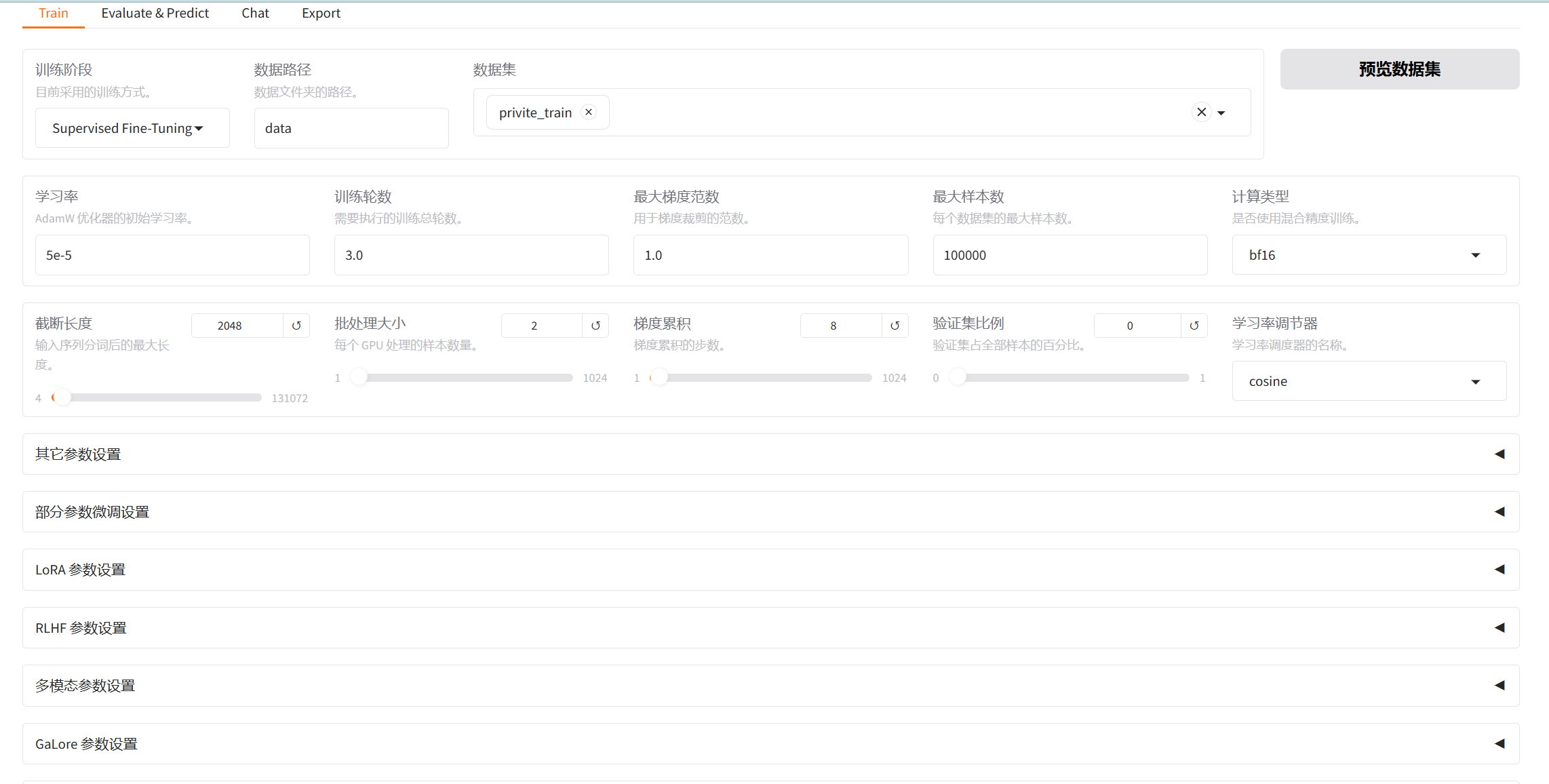
4.1 参数选择
进入UI界面,即可按自己的要求进行参数的配置。
可提前下载需要微调的基座模型,然后选择自己模型保存的路径。如果没有提前下载,就会从模型下载源进行下载。
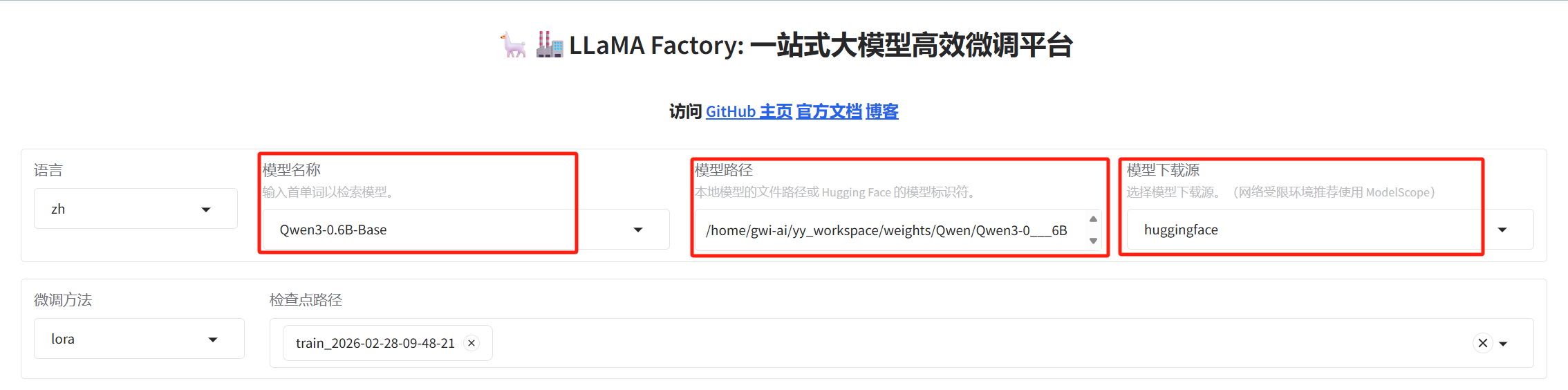
选择自定义的数据集:
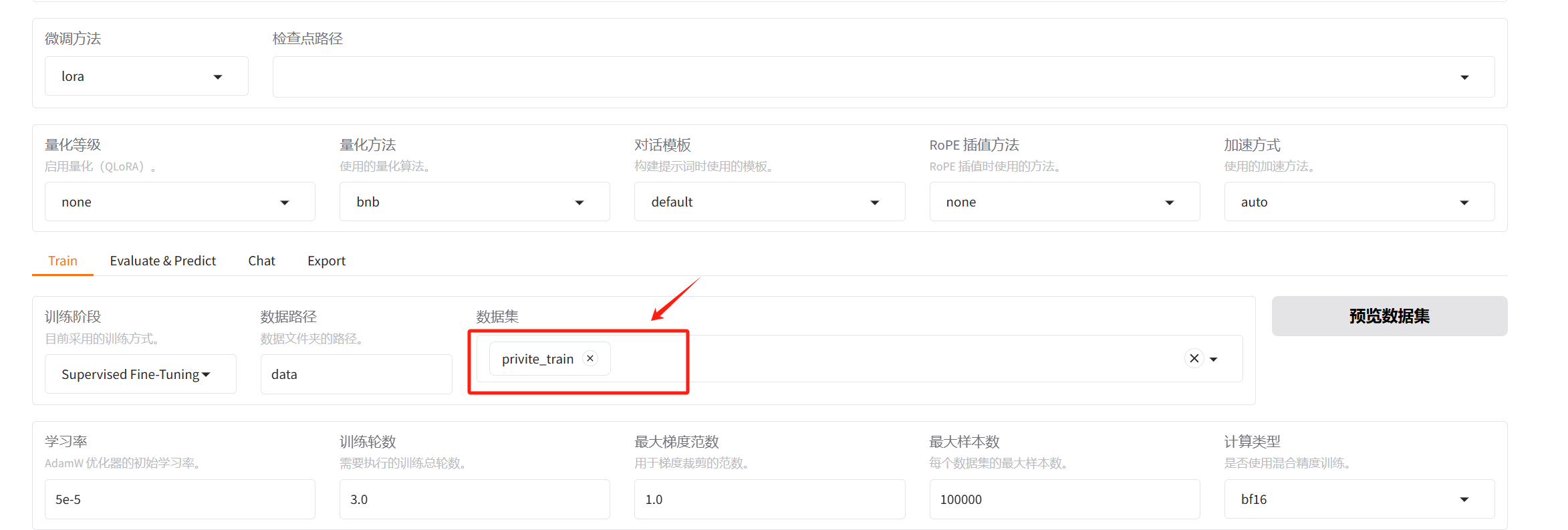
根据自己的要求配置微调参数:
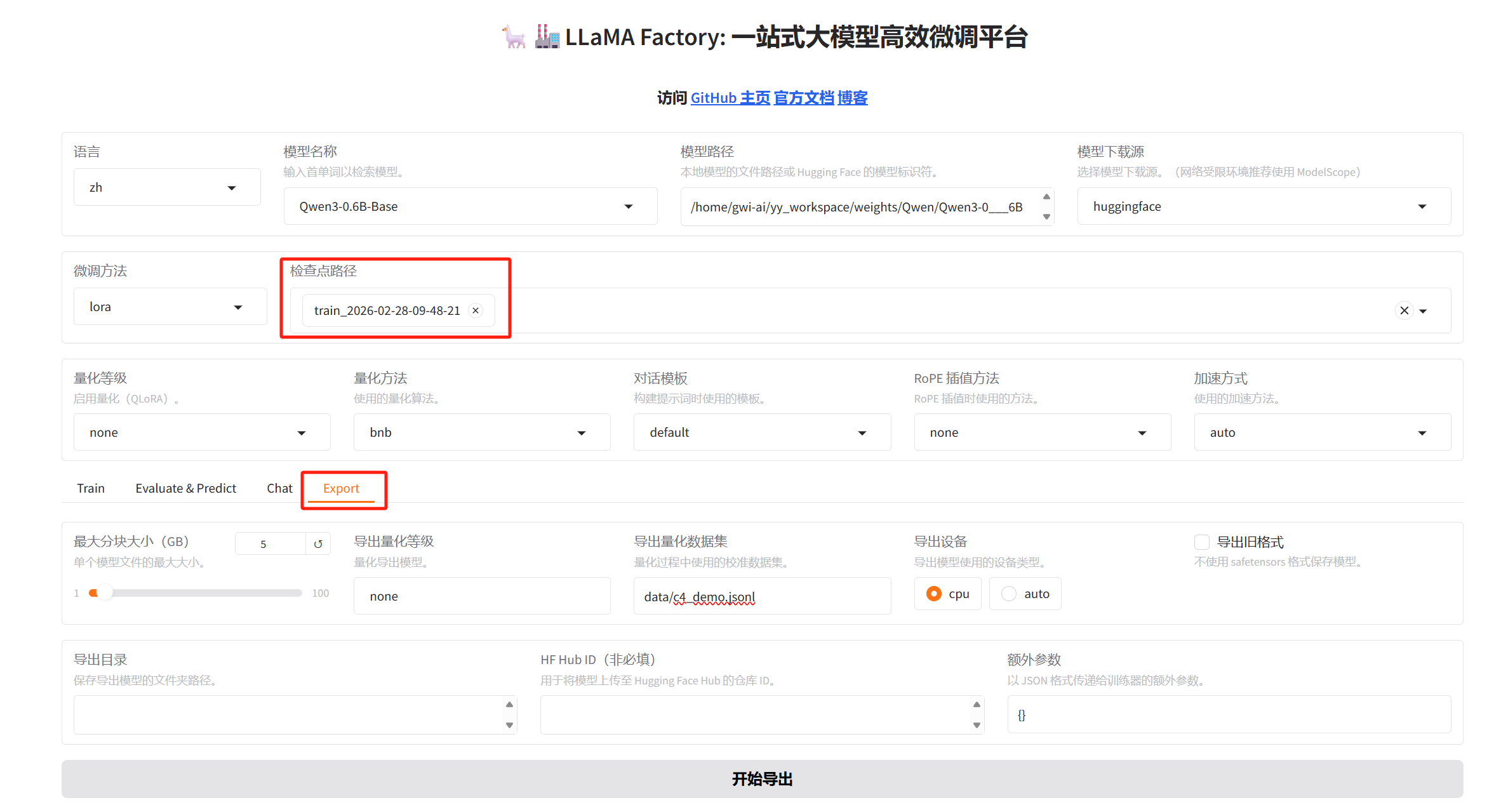
4.2 模型导出
选择微调保存的模型进行合并导出。
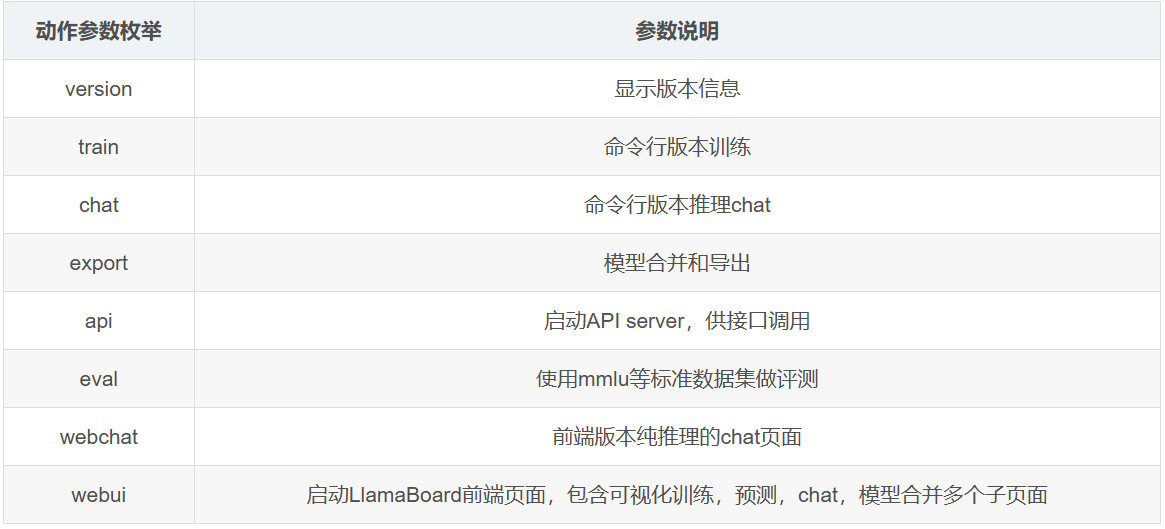
4.3 动作参数详解

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)