(论文速读)BigBird - 让Transformer处理长序列
论文题目:Big Bird: Transformers for Longer Sequences(长序列Transformers)
会议:NIPS2020
摘要:基于变换的模型,如BERT,是NLP中最成功的深度学习模型之一。不幸的是,它们的核心限制之一是由于它们的全注意力机制,对序列长度的二次依赖(主要是在内存方面)。为了解决这个问题,我们提出了BIGBIRD,一个稀疏的注意力机制,将这种二次依赖减少到线性。我们证明了BIGBIRD是序列函数的通用逼近器,并且是图灵完备的,从而保留了二次型全注意力模型的这些性质。在此过程中,我们的理论分析揭示了拥有O(1)个全局令牌(例如CLS)的一些好处,这些令牌作为稀疏注意机制的一部分关注整个序列。所提出的稀疏注意可以处理长度为以前使用类似硬件可能的8倍的序列。由于处理更长的上下文的能力,BIGBIRD大大提高了各种NLP任务(如问答和摘要)的性能。我们还提出了基因组学数据的新应用。
BigBird - 让Transformer处理长序列的突破性工作
引言:Transformer的"续航"难题
自从BERT横空出世以来,基于Transformer的模型在NLP领域可谓所向披靡。然而,这些模型有一个"致命弱点"——它们只能处理相对较短的文本。
为什么会这样?原因在于Transformer的核心机制——全注意力(full attention)。在这种机制下,每个token都要和序列中的所有其他tokens计算注意力,导致计算和内存需求随序列长度呈二次增长(O(n²))。实际应用中,这意味着BERT只能处理512个tokens左右的文本,超过这个长度就会爆显存。
但很多实际任务需要更长的上下文:
- 📄 文档级问答和摘要
- 📚 长文档分类
- 🧬 基因组序列分析(DNA序列动辄成千上万个碱基对)
Google Research的这篇BigBird论文就是为了解决这个问题而生的。它不仅提出了一个巧妙的稀疏注意力机制,还提供了严谨的理论证明,并在多个任务上刷新了SOTA记录。
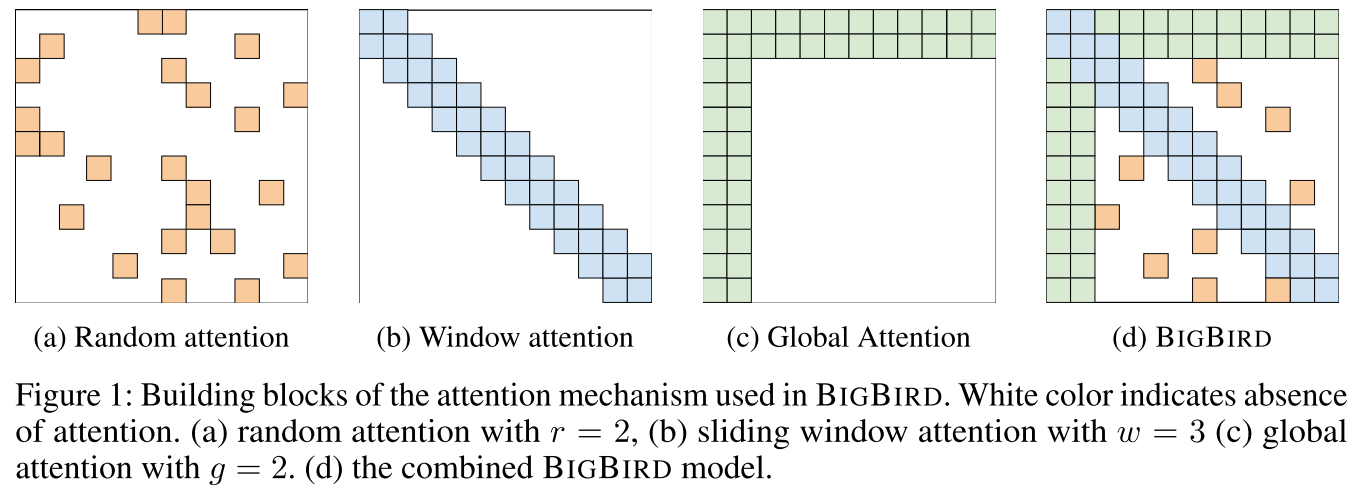
一、问题的本质:为什么全注意力这么"贵"?
让我们先理解一下Transformer的计算瓶颈在哪里。
1.1 全注意力的复杂度
在标准的Transformer中,对于长度为n的序列:
- 内积运算数量:n × n = O(n²)
- 内存占用:需要存储n×n的注意力矩阵
这意味着序列长度翻倍,计算量和内存需求都会增长4倍!
用常规硬件(比如单张GPU),这限制了输入长度在512 tokens左右。对于很多任务来说,这远远不够:
- 一篇学术论文通常有几千个tokens
- 一个DNA序列片段可能有上万个碱基对
- 法律文档、新闻文章都经常超过这个长度
1.2 之前的尝试
研究者们尝试了两个方向来解决这个问题:
方向一:绕过长度限制
- 使用滑动窗口
- 先用其他方法(如TF-IDF)选择相关片段,再喂给Transformer
- 代表工作:SpanBERT, ORQA, REALM
- 问题:需要复杂的工程设计,训练困难
方向二:减少注意力计算
- 使用各种稀疏注意力模式
- 代表工作:Sparse Transformer(O(n√n)),Reformer(O(n log n))
- 问题:大多是启发式方法,缺乏理论保证,在多个基准上表现不如原始Transformer
BigBird属于第二个方向,但它的特别之处在于既保证了理论上的完备性,又实现了实际的高性能。
二、BigBird的核心设计:三位一体的稀疏注意力
BigBird的稀疏注意力机制由三个关键组件组成,每个都有其理论依据和实际作用。
2.1 组件一:随机注意力(Random Attention)
核心思想:每个query随机关注r个keys
理论依据:
- 来自图论中的Erdős-Rényi随机图模型
- 即使边数只有O(n),随机图中任意两节点间的最短路径也只有O(log n)
- 随机图是"扩展图",可以在多个方面近似完全图
实际作用:确保信息能在序列中快速传播,即使两个token相距很远
2.2 组件二:窗口注意力(Window Local Attention)
核心思想:每个token关注其左右各w/2个邻近tokens
理论依据:
- NLP和生物信息学中的数据都表现出强烈的局部性(locality)
- Clark等人的研究表明,邻近tokens之间的注意力在NLP任务中极其重要
- 语言学理论(如转换生成语法)也强调局部性
实际作用:捕捉局部语境信息,这对理解语言至关重要
2.3 组件三:全局注意力(Global Attention)
核心思想:g个特殊tokens关注整个序列,也被所有tokens关注
理论依据:
- 这是作者理论分析的关键发现
- 全局tokens充当"信息枢纽",协调全局信息流动
- 理论证明表明,全局tokens对保持表达能力至关重要
两种实现方式:
- BigBird-ITC(Internal Transformer Construction):让现有的某些tokens(如前128个)成为全局tokens
- BigBird-ETC(Extended Transformer Construction):添加额外的全局tokens,如CLS token
实际作用:存储和传播全局信息,补偿稀疏注意力的不足
2.4 为什么这样设计有效?
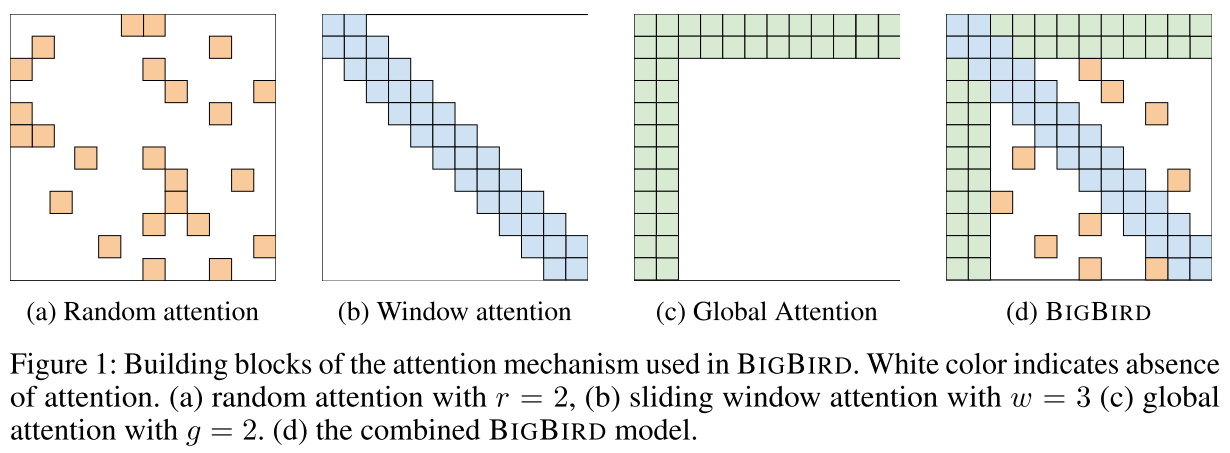
论文通过初步实验(表1)验证了每个组件的必要性:
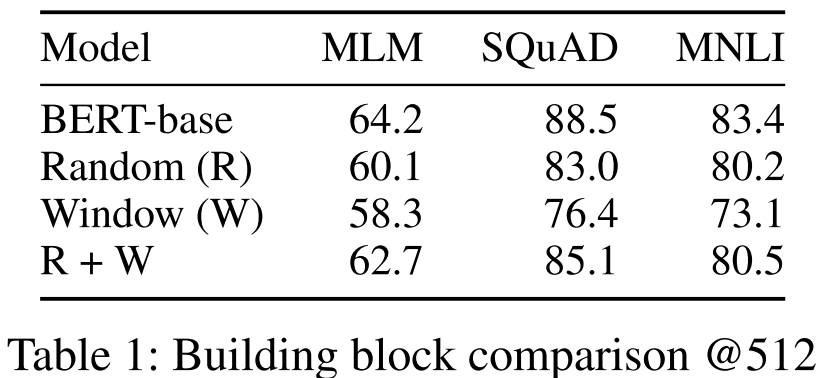
- 只用随机注意力(R):MLM BPC=60.1,SQuAD=83.0
- 只用窗口注意力(W):MLM BPC=58.3,SQuAD=76.4
- 两者结合(R+W):MLM BPC=62.7,SQuAD=85.1
- 完整BigBird(R+W+G):性能接近全注意力的BERT-base
这说明三个组件缺一不可,相辅相成。
三、理论保证:不仅实用,还很"正统"
BigBird最令人印象深刻的不仅是工程实现,更在于其严谨的理论基础。这部分可能有些抽象,但我尽量用简单的语言解释。
3.1 通用近似性(Universal Approximation)
核心结论(定理1):BigBird可以近似任何连续的序列到序列函数。
这是什么意思?简单说就是:理论上,BigBird可以表达任何Transformer能表达的东西,即使它只用了O(n)个内积而不是O(n²)。
证明思路(超级简化版):
- 任何连续函数可以用分段常数函数近似
- 关键创新:设计"上下文映射"(contextual mapping)
- 为序列中的每个位置创建唯一编码
- 这个编码包含了整个序列的信息
- 利用选择性移位算子(selective shift operator)
- 只对特定范围的值进行移位
- 通过多层迭代,最终每个token都获得全局信息
- 全局tokens在这里起到关键作用:它们充当"信息中转站"
3.2 图灵完备性(Turing Completeness)
核心结论(定理3):BigBird可以模拟任何图灵机。
这比通用近似性更强——它说明BigBird在原理上可以执行任何可计算的算法!
关键挑战:
- Pérez等人证明了全注意力Transformer是图灵完备的
- 他们的证明中,关键步骤需要"回溯历史"找到特定的符号
- 全注意力可以一步完成,但稀疏注意力怎么办?
BigBird的解决方案:
- 利用max运算的结合律:min{...min{min{a,b},c},...,z}
- 通过多个"中间步骤"逐步聚合信息
- 稀疏图的特殊设计确保每个节点最终能访问到需要的历史信息
3.3 下界
论文也诚实地指出了稀疏注意力的局限性。
任务1:给定n个单位向量,为每个向量找到距离它最远的向量。
结果(命题1):
- 全注意力:可以在1层内解决(直接算所有内积)
- 稀疏注意力(O(n)边):需要Ω(√n)层
这基于正交向量猜想(OVC),一个复杂度理论中的经典假设。
启示:稀疏注意力不是万能的,某些需要全局比较的任务确实需要更多层数。
四、高效实现:如何让GPU/TPU"喜欢"稀疏计算
理论很美好,但硬件是现实的。GPU/TPU擅长的是密集矩阵运算,而不是稀疏的、跳跃的访问。
BigBird的解决方案是**块稀疏(Block-Sparse)**策略。
4.1 核心思想
不在单个token级别定义稀疏性,而是在token块级别:
- 将序列分成若干块(每块b个tokens)
- 在块级别定义注意力模式
- 每个query块关注某几个key块
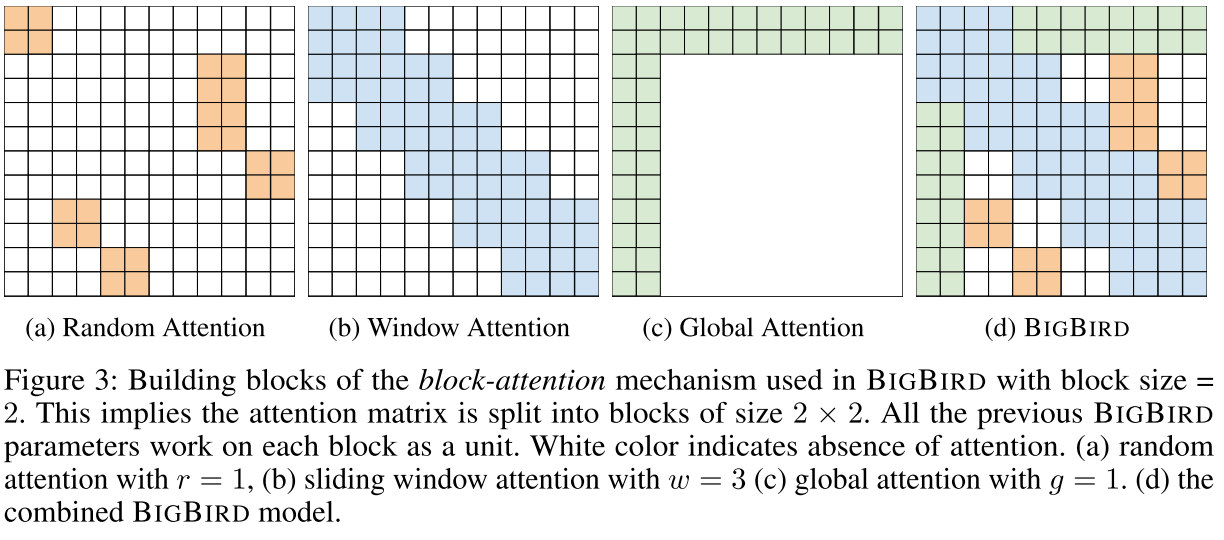
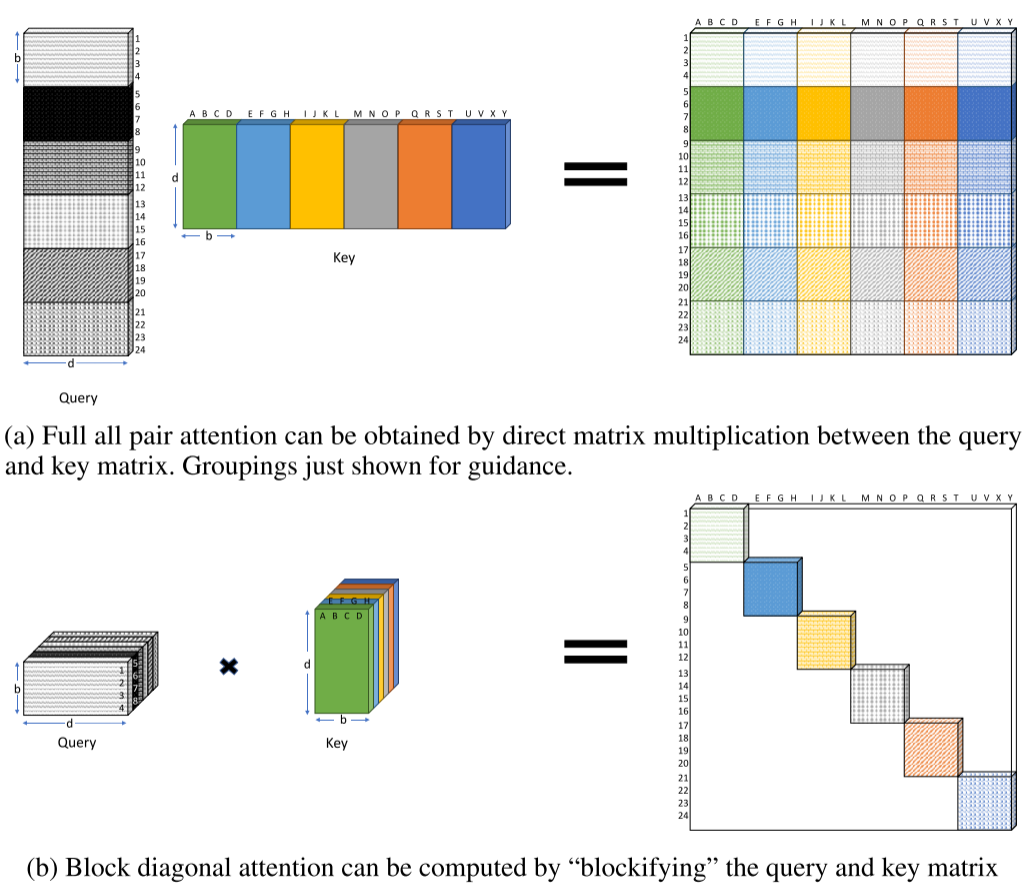
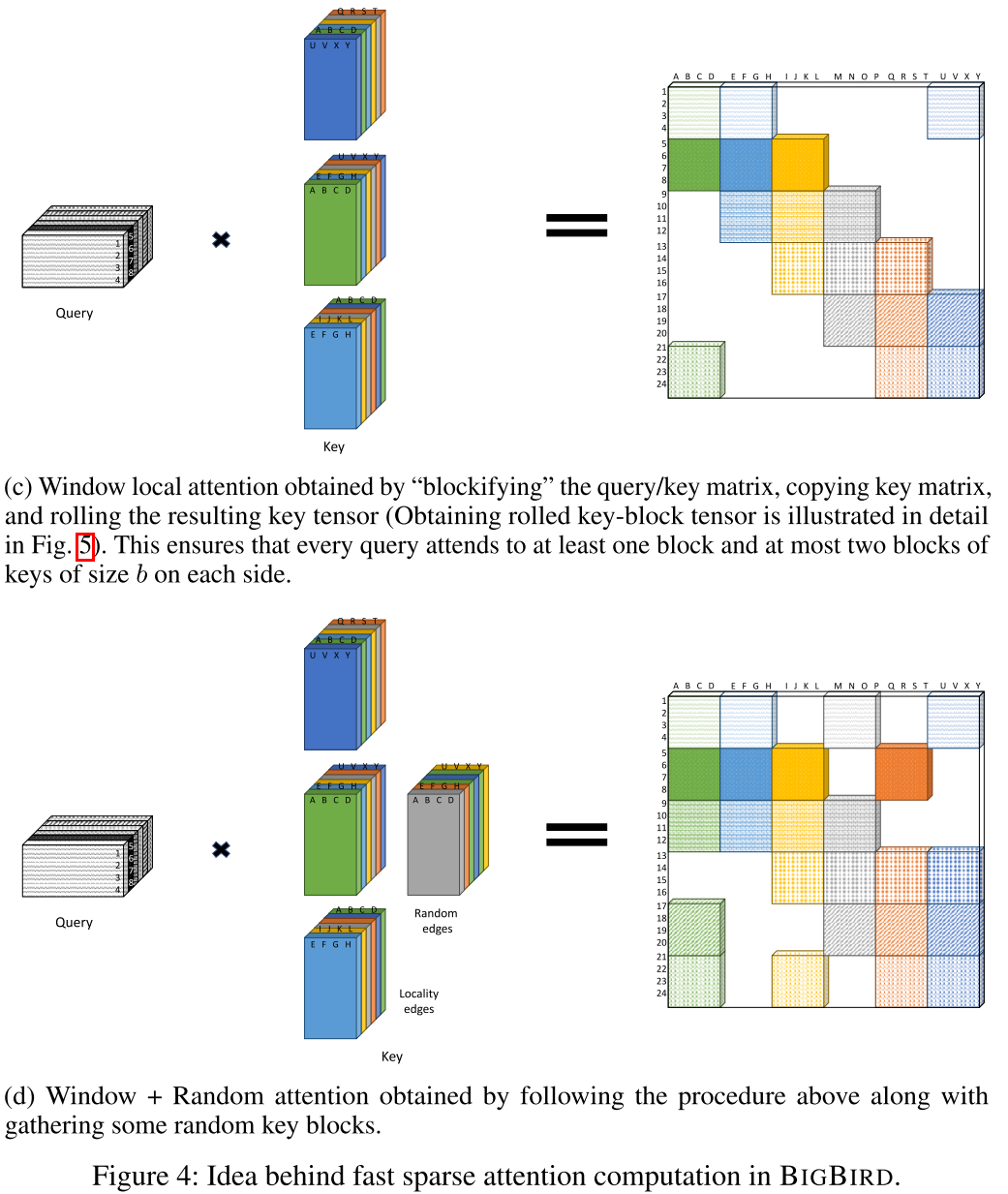
4.2 实现技巧
(1) 块对角注意力
- 将query和key矩阵重塑为块张量
- 直接相乘得到块对角部分
- 复杂度从O(n²d)降到O(nbd)
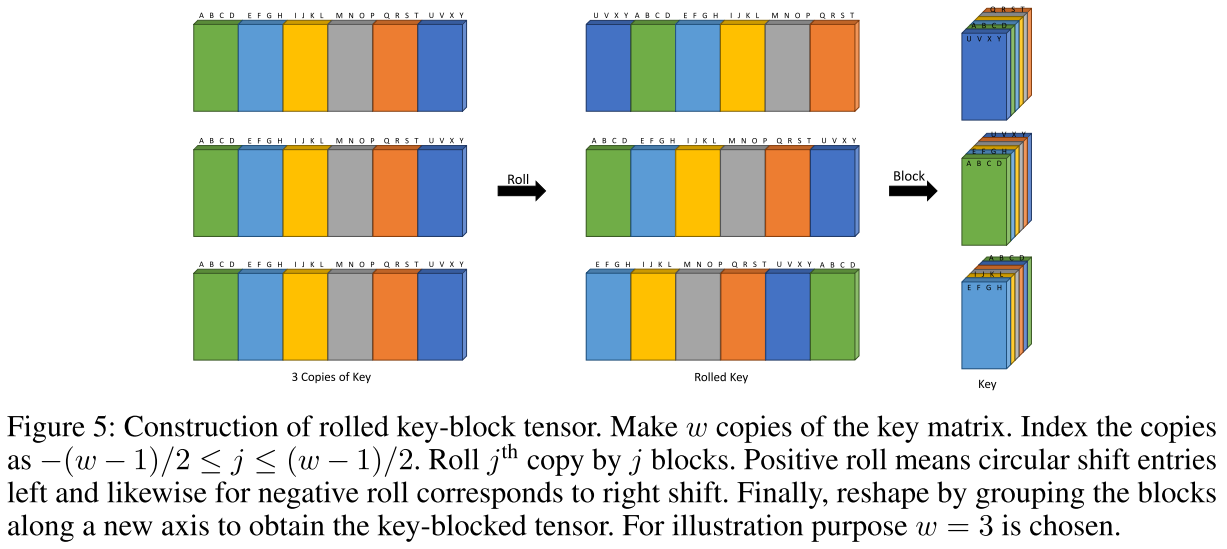
(2) 窗口注意力
- 制作w份key矩阵
- 每份进行不同程度的"滚动"(rolling/circular shift)
- 一次密集运算得到窗口注意力
(3) 随机注意力
- 由于r很小(实验中r=3),直接用gather操作
- 虽然gather效率不高,但量很少所以可以接受
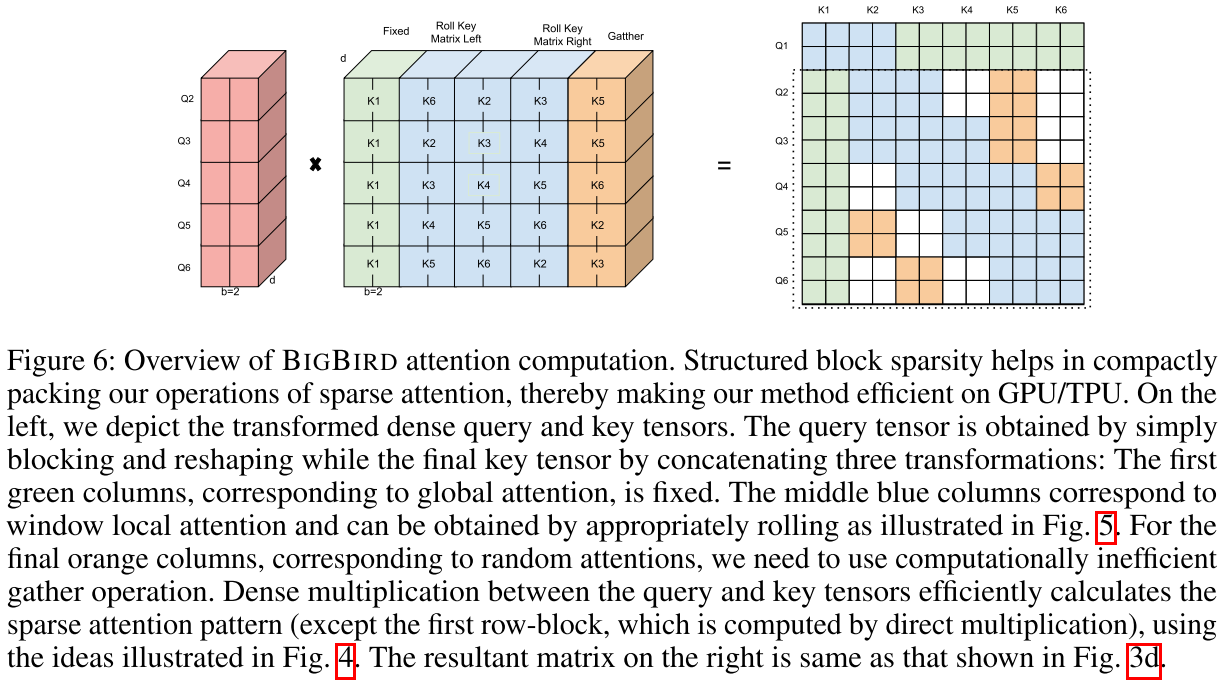
(4) 整体流程 最终,所有三种注意力可以通过一次密集矩阵乘法计算:
- Query块:⌈n/b⌉ × b × d
- Key块:⌈n/b⌉ × (g+w+r)b × d
- 输出:⌈n/b⌉ × b × (g+w+r)b
五、实验结果
BigBird在NLP和基因组学两个领域都取得了令人瞩目的成果。
5.1 预训练与MLM
设置:
- 数据:Books, CC-News, Stories, Wikipedia
- 序列长度:4096(是BERT的8倍!)
- 从RoBERTa检查点warm-start
结果(表10):
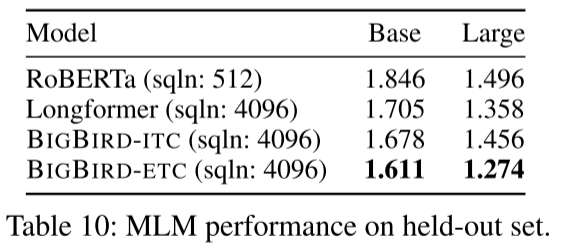
BigBird-ETC在预测masked tokens上表现最佳:
- Base模型:BPC = 1.611(RoBERTa: 1.846)
- Large模型:BPC = 1.274(RoBERTa: 1.496)
更长的上下文确实带来了更好的语言理解!
5.2 问答任务:刷新多项SOTA
测试了四个挑战性QA数据集:
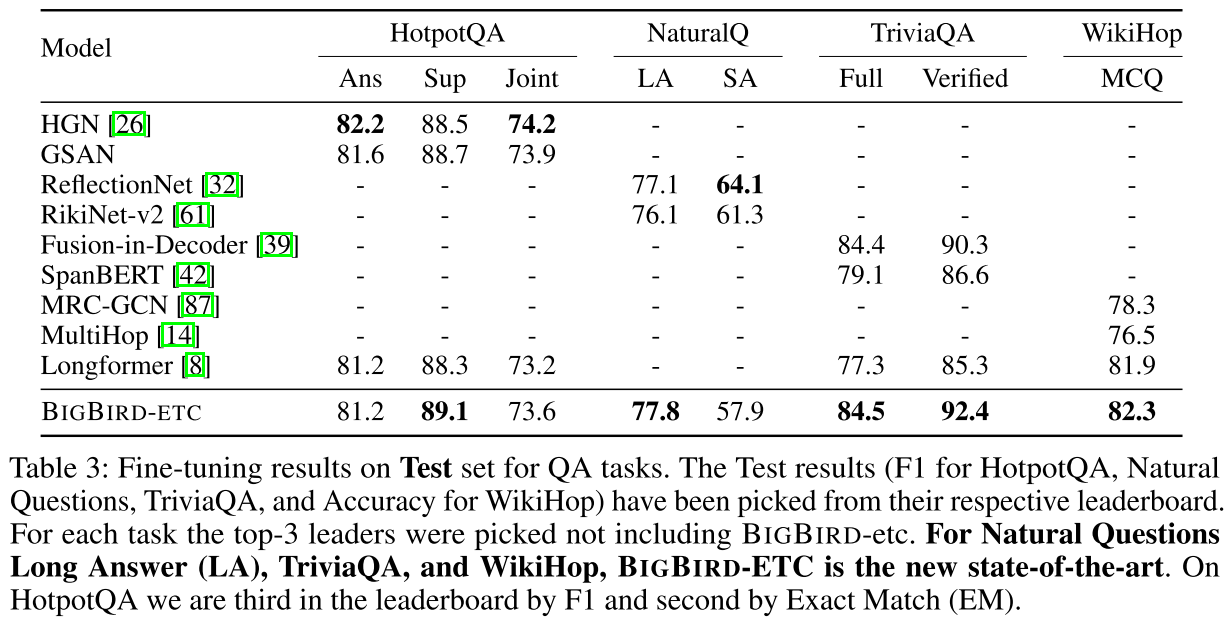
(1) Natural Questions
- Long Answer: 77.8 F1(SOTA)
- Short Answer: 57.9 F1(SOTA)
- 超越了ReflectionNet (77.1) 和 RikiNet-v2 (76.1)
(2) TriviaQA
- Verified: 92.4 F1(SOTA)
- Full: 84.5 F1(SOTA)
- 大幅超越SpanBERT (86.6) 和 Longformer (85.3)
(3) WikiHop
- 82.3%准确率(SOTA)
- 超越MRC-GCN (78.3) 和 MultiHop (76.5)
(4) HotpotQA
- Answer F1: 81.2(排名第3)
- Supporting Facts: 89.1 F1(排名第2)
关键发现:
- 更长的上下文让模型可以利用更多证据
- BigBird-ETC(带额外全局tokens)通常优于BigBird-ITC
- 单模型就能达到很多ensemble方法的性能
5.3 文档分类:长文档的优势
在5个不同长度和内容的数据集上测试:
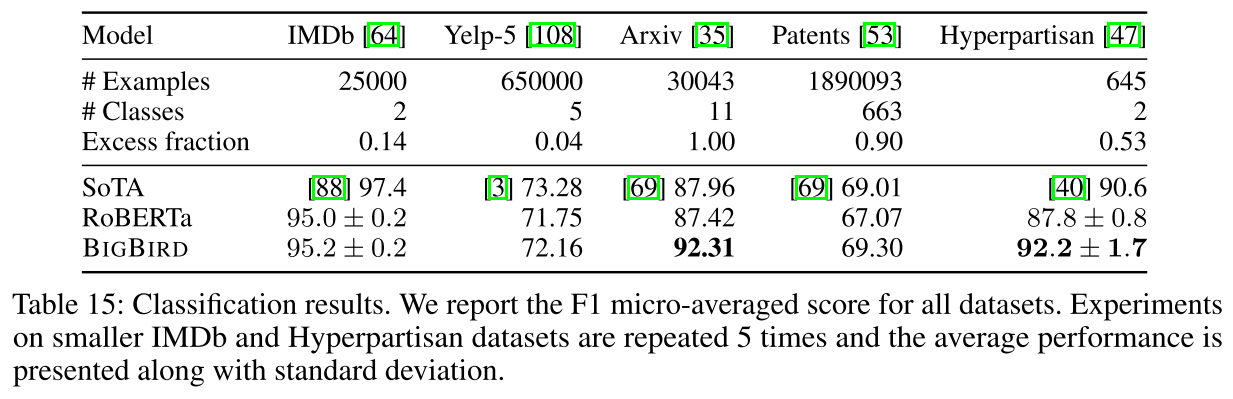
Arxiv论文分类:
- 92.31% F1(SOTA,提升5个百分点!)
- 这个数据集100%的样本超过512 tokens
- 说明长上下文在这里至关重要
Patents专利分类:
- 69.30% F1
- 相比RoBERTa有提升,但未超越SoTA
- 可能因为训练数据量很大(189万样本)
Hyperpartisan新闻检测:
- 92.2% F1(比RoBERTa的87.8%显著提升)
发现的模式:
- 文档越长、训练样本越少,BigBird的优势越明显
- 这符合"长上下文带来额外信息"的直觉
5.4 文档摘要:长文档的大幅提升
在三个长文档摘要数据集上测试:
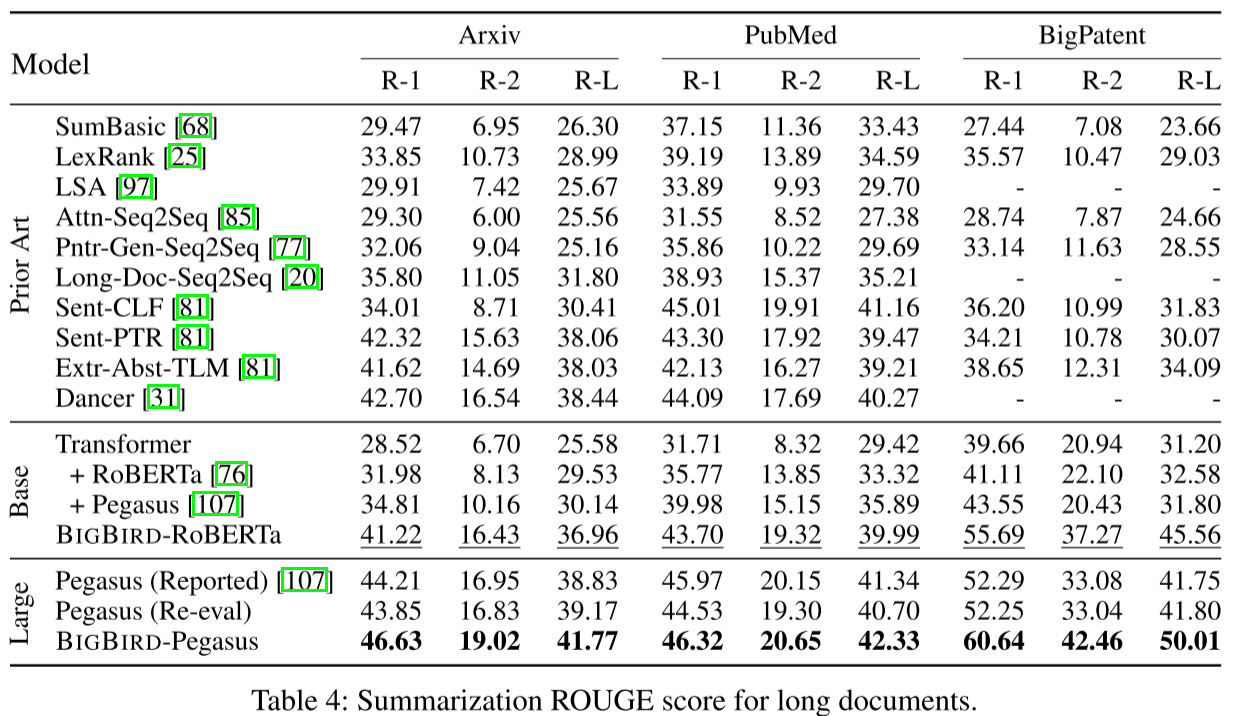
BigPatent(专利摘要):
- Large模型:
- ROUGE-1: 60.64(Pegasus: 52.29,提升8个点!)
- ROUGE-2: 42.46(Pegasus: 33.08,提升9个点!)
- ROUGE-L: 50.01(Pegasus: 41.75,提升8个点!)
- 这个数据集故意将关键信息分散在文档各处,长上下文是关键
Arxiv论文摘要:
- Large模型:
- ROUGE-1: 46.63(Pegasus: 44.21)
- ROUGE-2: 19.02(Pegasus: 16.95)
- ROUGE-L: 41.77(Pegasus: 38.83)
PubMed医学论文摘要:
- Large模型:
- ROUGE-1: 46.32(Pegasus: 45.97)
- ROUGE-2: 20.65(Pegasus: 20.15)
- ROUGE-L: 42.33(Pegasus: 41.34)
实现细节:
- 只在encoder使用稀疏注意力
- Decoder仍使用全注意力(因为输出通常较短)
- 从Pegasus预训练检查点warm-start
5.5 基因组学:开拓新领域
BigBird在基因组学上的应用是论文的一大亮点,展示了注意力机制在NLP之外的潜力。
预训练设置:
- 数据:人类参考基因组GRCh37
- Tokenization:使用BPE,32K词汇表,每个token约8.78个碱基对
- 任务:MLM + NSP
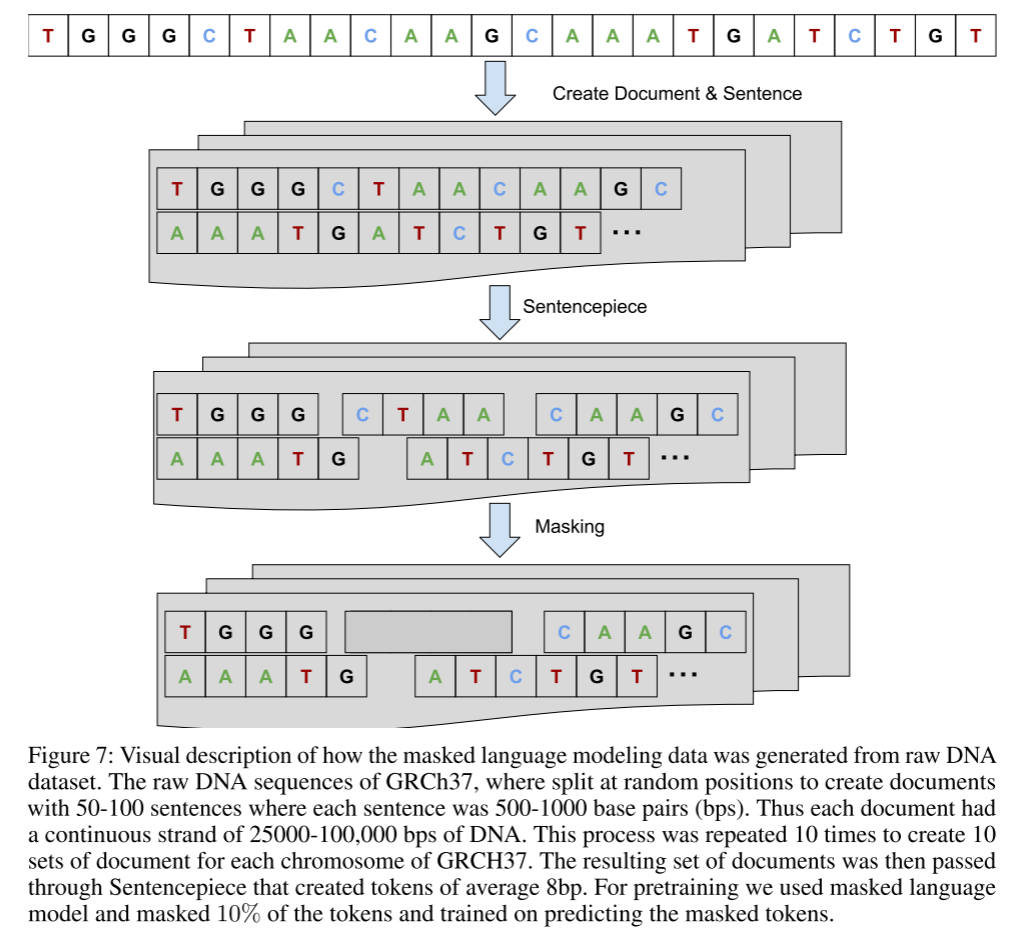
(1) 启动子区域预测
任务:识别DNA序列中的启动子区域(基因转录起始的关键位置)

结果:
- F1 = 99.9%
- 相比之前SOTA(DeePromoter的95.6%)有显著提升
- 近乎完美的性能!
(2) 染色质特征预测
任务:预测非编码DNA区域的919个染色质特征
- 690个转录因子(TF)结合位点
- 125个DNase敏感性(DHS)特征
- 104个组蛋白修饰(HM)特征

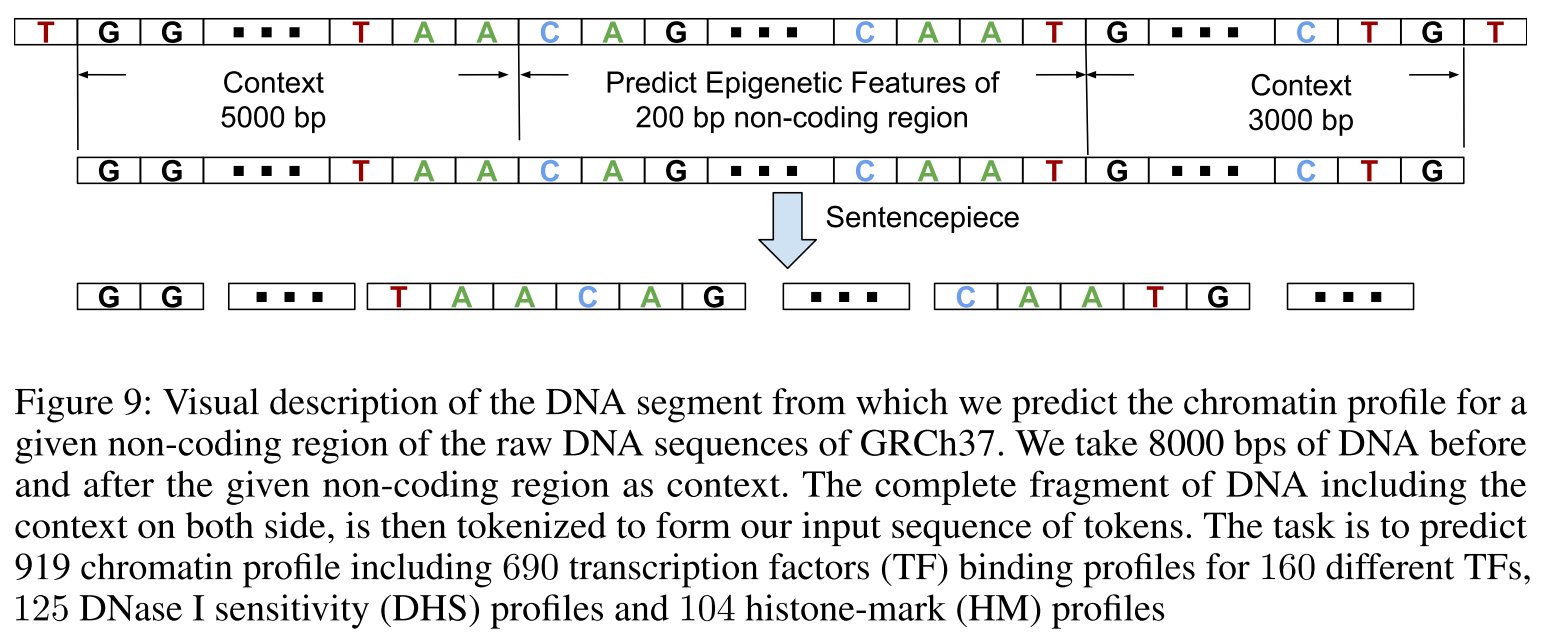
结果:
- TF: 96.1 AUC(DeepSea: 95.8)
- HM: 88.7 AUC(DeepSea: 85.6,显著提升!)
- DHS: 92.1 AUC(DeepSea: 92.3)
重要发现:
- 组蛋白修饰(HM)的提升最大,这类特征已知有更长程的相关性
- 更长的上下文(±8000 bp)对理解DNA功能很关键
5.6 GLUE基准:保持竞争力
虽然GLUE任务的序列普遍较短,但BigBird仍保持了竞争力:
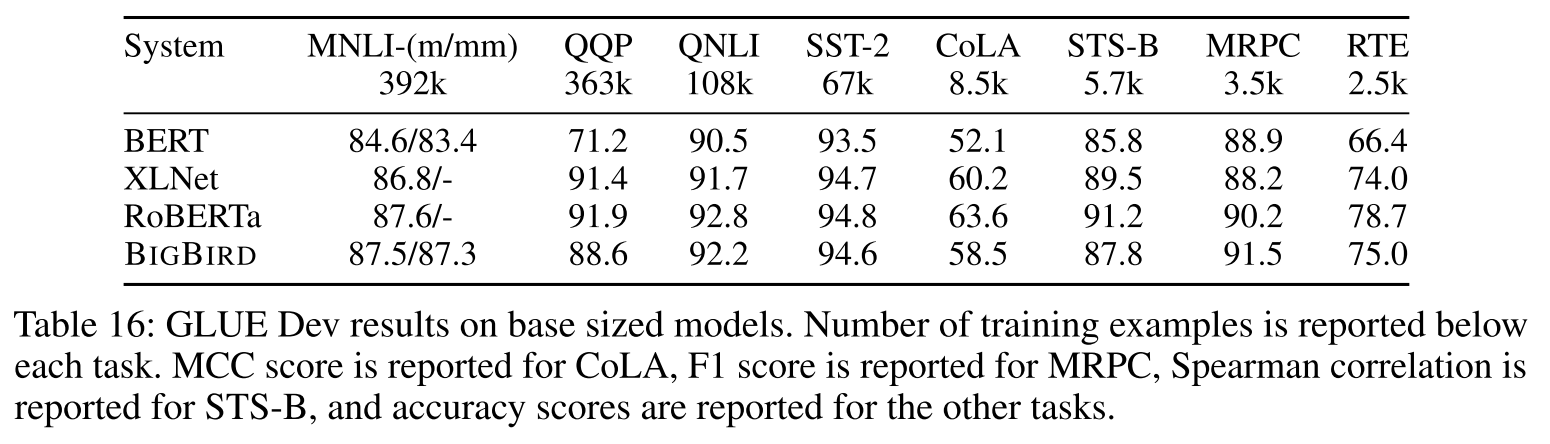
- 在8个任务上与BERT、XLNet、RoBERTa相当
- 说明稀疏注意力在短序列上也没有明显劣势
六、消融实验与分析
6.1 组件重要性
【已在前文提到Table 1】
实验表明:
- 只有随机或只有窗口都不够
- 三个组件组合才能接近全注意力性能
6.2 序列长度的影响
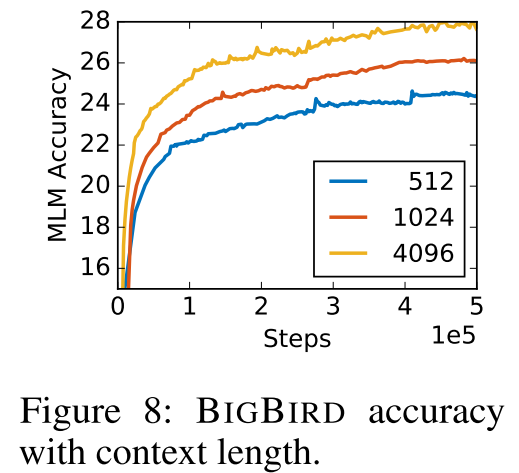
在DNA预训练中测试512, 1024, 4096三种长度:
- 更长的序列带来更高的最终准确率
- 更长的序列带来更快的收敛速度
- 说明长上下文确实提供了更多有用信息
6.3 ITC vs ETC
在QA任务上,BigBird-ETC(带额外全局tokens)通常优于BigBird-ITC:
- ETC在Natural Questions Long Answer上有明显优势
- ETC可以更灵活地设计全局tokens(如每个段落一个)
但ITC也有其价值:
- 实现更简单
- 在某些任务上性能相当
七、与同期工作的比较
7.1 Longformer
Longformer也是2020年提出的长序列Transformer,同样使用了窗口+全局注意力。
主要区别:
- BigBird多了随机注意力组件
- BigBird-ETC使用了相对位置编码,更适合结构化输入
- BigBird训练全局tokens时使用了CPC loss
性能对比:
- 在QA任务上,BigBird全面优于Longformer
- 例如在TriviaQA上,BigBird (84.5) vs Longformer (77.3)
7.2 理论优势
相比其他稀疏Transformer(Sparse Transformer, Reformer等):
- BigBird提供了严格的理论证明(通用近似性、图灵完备性)
- 其他工作大多是启发式设计,缺乏理论保证
- BigBird在实际任务上也更稳定、更versatile
八、局限与未来方向
8.1 承认的局限
论文诚实地指出:
- 某些需要全局比较的任务,稀疏注意力需要更多层(命题1)
- 不是所有任务都能从长上下文中受益(如IMDb情感分析)
8.2 实现细节
- 块大小b的选择需要权衡(实验中b=64或84)
- 随机注意力需要gather操作,有一定开销
- 预训练成本仍然不小(8×8 TPUv3)
8.3 未来方向
- 探索自适应稀疏性(根据任务动态调整r, w, g)
- 研究稀疏注意力在更多模态上的应用(视觉、音频)
- 改进块稀疏的实现,进一步提升效率
九、关键要点总结
-
问题:Transformer的全注意力机制对序列长度有O(n²)复杂度,限制了长文本处理
-
方案:BigBird稀疏注意力 = 随机 + 窗口 + 全局
- 复杂度降到O(n)
- 可处理8x更长的序列(4096 tokens)
-
理论:不仅实用,还有严格证明
- 通用近似器(定理1)
- 图灵完备(定理3)
- 下界分析(命题1)
-
实现:块稀疏策略适配GPU/TPU
-
结果:多项SOTA
- NLP:QA、摘要、分类任务全面提升
- 基因组学:开拓新应用,启动子预测达99.9%
-
影响:
- 证明了稀疏注意力的可行性和必要性
- 为长序列建模提供了实用且理论完备的解决方案
- 启发了后续工作(如FlashAttention, Linformer等)
结语
BigBird不仅是一个工程上的成功,更是一个理论与实践完美结合的典范。它告诉我们:
- 复杂问题可以有简洁优雅的解决方案
- 理论保证和实际性能可以兼得
- 跨领域的思想(图论、复杂度理论)可以带来突破
对于想要处理长文本的研究者和工程师,BigBird提供了一个可靠的基线和宝贵的洞察。对于理论研究者,它展示了如何为神经网络架构提供严格的数学基础。
这篇论文发表于2020年,但其影响深远,启发了后续大量关于高效Transformer的研究。在大模型时代,如何高效处理更长的上下文仍是核心挑战,BigBird的思想至今仍有重要参考价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)