(论文速读)Funnel-Transformer: 过滤掉顺序冗余的高效语言处理
论文题目:Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing(过滤掉顺序冗余的高效语言处理)
会议:NeurIPS 2020
摘要:随着语言预训练的成功,人们迫切希望开发出更高效、具有良好可扩展性的体系结构,以更低的成本利用大量的未标记数据。为了提高效率,我们研究了在维护全长令牌级表示时经常被忽视的冗余,特别是对于只需要序列的单向量表示的任务。基于这种直觉,我们提出了Funnel-Transformer,它将隐藏状态序列逐渐压缩为更短的序列,从而降低了计算成本。更重要的是,通过将从长度减少中节省的FLOPs重新投资于构建更深或更宽的模型,我们进一步提高了模型的容量。此外,为了按照通用预训练目标的要求执行令牌级预测,漏斗转换器能够通过解码器从减少的隐藏序列中恢复每个令牌的深度表示。从经验上看,在具有相当或更少的FLOPs的情况下,Funnel-Transformer在各种序列级预测任务(包括文本分类、语言理解和阅读理解)上优于标准Transformer。
代码和预训练模型:https://github.com/laiguokun/Funnel-Transformer
Funnel-Transformer详解——通过序列压缩实现高效语言处理
引言
在NLP领域,Transformer模型通过大规模预训练取得了巨大成功。然而,预训练和微调这些模型的计算成本极其高昂,这极大地限制了它们的应用范围。今天要介绍的这篇论文提出了Funnel-Transformer(F-TFM),一种通过逐层压缩序列长度来提高效率的创新架构。
一、为什么需要Funnel-Transformer?
1.1 标准Transformer的冗余问题
标准Transformer有一个被忽视的特点:它在所有层都维持完整长度的token-level表示。
让我们思考一个问题:对于文本分类任务,我们最终只需要一个向量来表示整个句子,为什么要在每一层都维持512个token的完整表示呢?
论文指出,这就像在图像识别中,我们不会在网络的每一层都保持原始图像的分辨率。CNN通过逐层降低空间分辨率来提取更高级的特征。同样的思路也应该适用于序列处理。
1.2 计算复杂度分析
对于一个处理长度为T、隐藏维度为D的序列的Transformer层,其复杂度为:
- Self-Attention: O(T²D)
- Feed-Forward: O(TD²)
当序列长度减半时,计算复杂度会超线性下降(因为T²项)。这意味着:
- 用1个全长layer的FLOPs可以换来第m个block中的2^(m-1)个压缩层
- 例如:B6-6-6(18层)的FLOPs仅相当于6 + 6/2 + 6/4 = 10.5个全长层
二、Funnel-Transformer的核心设计
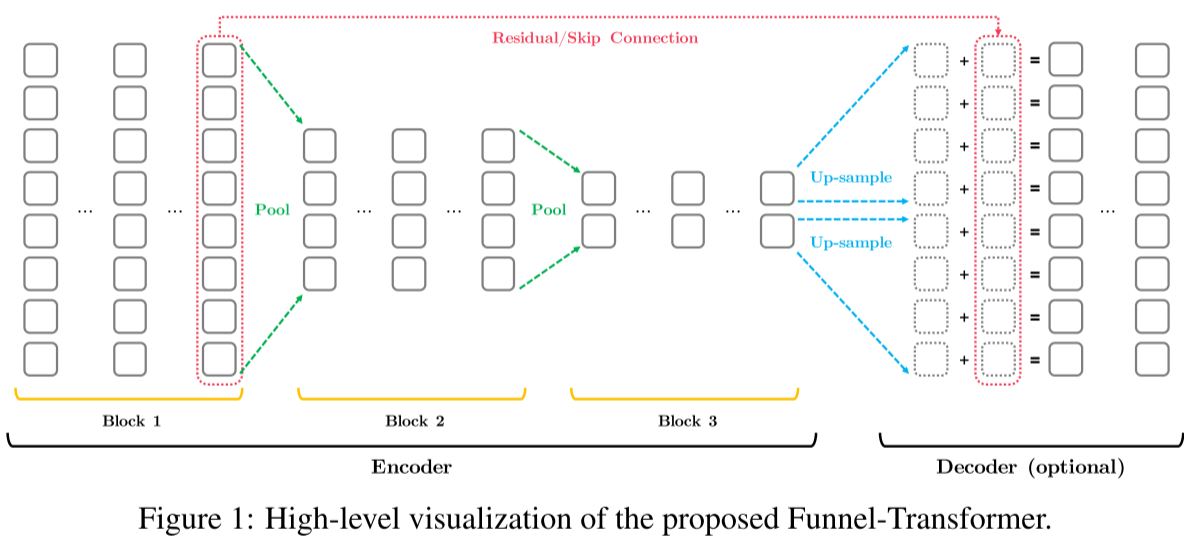
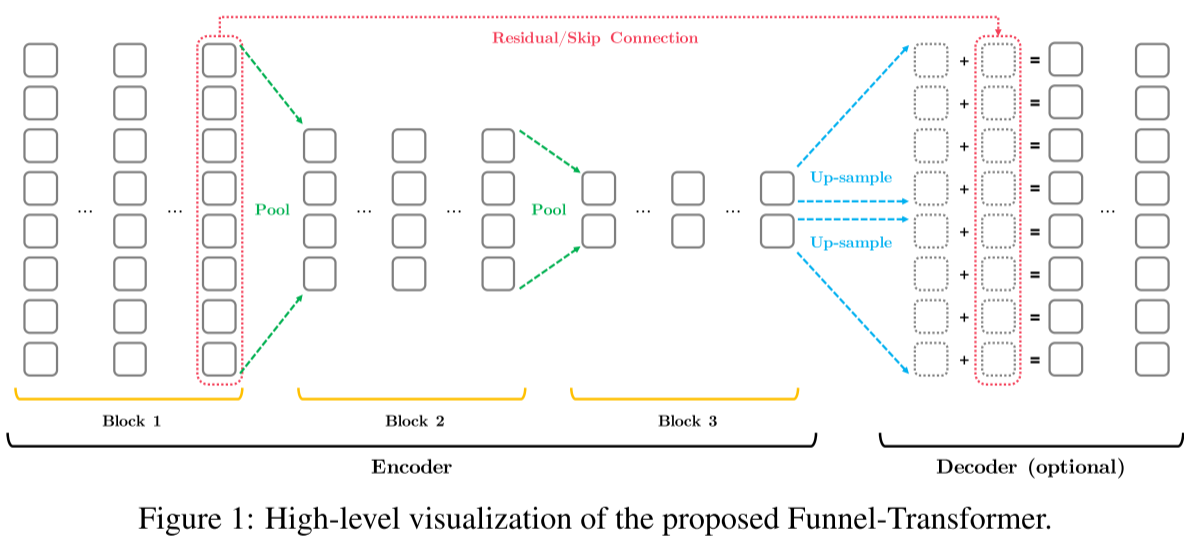
2.1 整体架构
Funnel-Transformer由两部分组成:
-
编码器(Encoder):逐渐压缩序列长度
- 由多个block组成(如B6-6-6有3个block,每个6层)
- Block之间通过pooling将序列长度减半
- 形成一个"漏斗"形状(因此得名)
-
解码器(Decoder):恢复token-level表示(仅在需要时使用)
- 通过up-sampling恢复全长序列
- 与低层特征建立skip connection
- 用于预训练或序列标注等token-level任务
2.2 关键创新:Pool-Query-Only设计
这是论文最重要的技术创新之一。
标准做法:对隐藏状态h进行pooling得到h',然后在attention中使用:
S-Attn(Q=h', KV=h') # 简单但压缩能力有限
Funnel-Transformer的做法:
S-Attn(Q=h', KV=h) # 只有query被pool,key和value保持未压缩
为什么这样更好?
- 压缩不仅由pooling操作决定,还由attention的加权求和决定
- Attention相当于一个线性压缩层,将T个基向量组合成T'个"压缩基"
- 计算开销最小,但表达能力大大增强
具体实现:使用stride=2, window=2的mean pooling,每次将序列长度减半。
2.3 解码器设计
对于需要token-level预测的任务(如MLM预训练),解码器的工作流程:
-
Up-sampling:将编码器输出h^M直接重复2^(M-1)次
h^up_i = h^M_{i//2^(M-1)} -
Skip Connection:与第一个block的输出h^1相加
g = h^1 + h^up -
深度融合:再堆叠2层Transformer进行特征融合
这个设计的优点:
- 简单高效(单次大倍率up-sampling,而非多次小倍率)
- 保留了低层的细粒度信息
- 便于优化(残差连接)
2.4 实现细节
分离[cls] token:
- 预训练中通常用[cls]的hidden state表示整个序列
- Pooling时单独处理[cls],不参与pooling操作
- 避免破坏这个特殊结构
相对位置编码:
- 使用Transformer-XL的relative positional attention
- 论文发现这对F-TFM至关重要(见消融实验)
- 因为pooling可能破坏绝对位置信息
三、实验结果详解
3.1 Base规模对比(与标准Transformer公平比较)
论文在相同数据集(Wikipedia + BookCorpus)上预训练100万步,batch size 256。
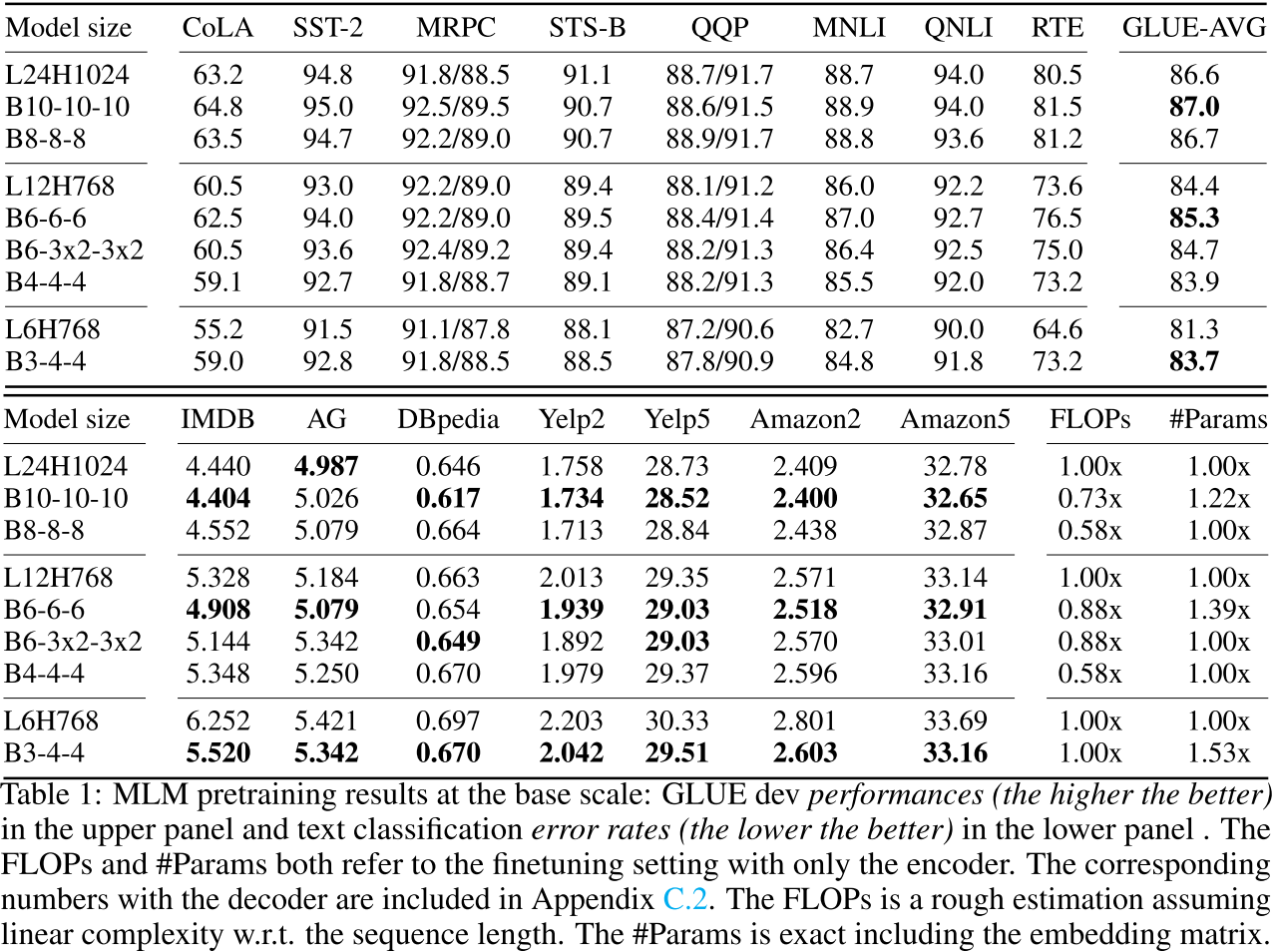
GLUE Benchmark结果的关键观察:
- B6-6-6用更少FLOPs达到更好性能:平均提升0.9分,FLOPs减少12%
- B6-3x2-3x2通过参数共享保持了相同参数量,性能与baseline相当
- 在大多数任务上都有提升,尤其是RTE(+2.9)
文本分类结果(错误率,越低越好):
| 模型 | IMDB | Yelp-2 | Yelp-5 | Amazon-5 |
|---|---|---|---|---|
| L12H768 | 5.328 | 2.013 | 29.35 | 33.14 |
| B6-6-6 | 4.908 | 1.939 | 29.03 | 32.91 |
在所有文本分类任务上都有明显提升!
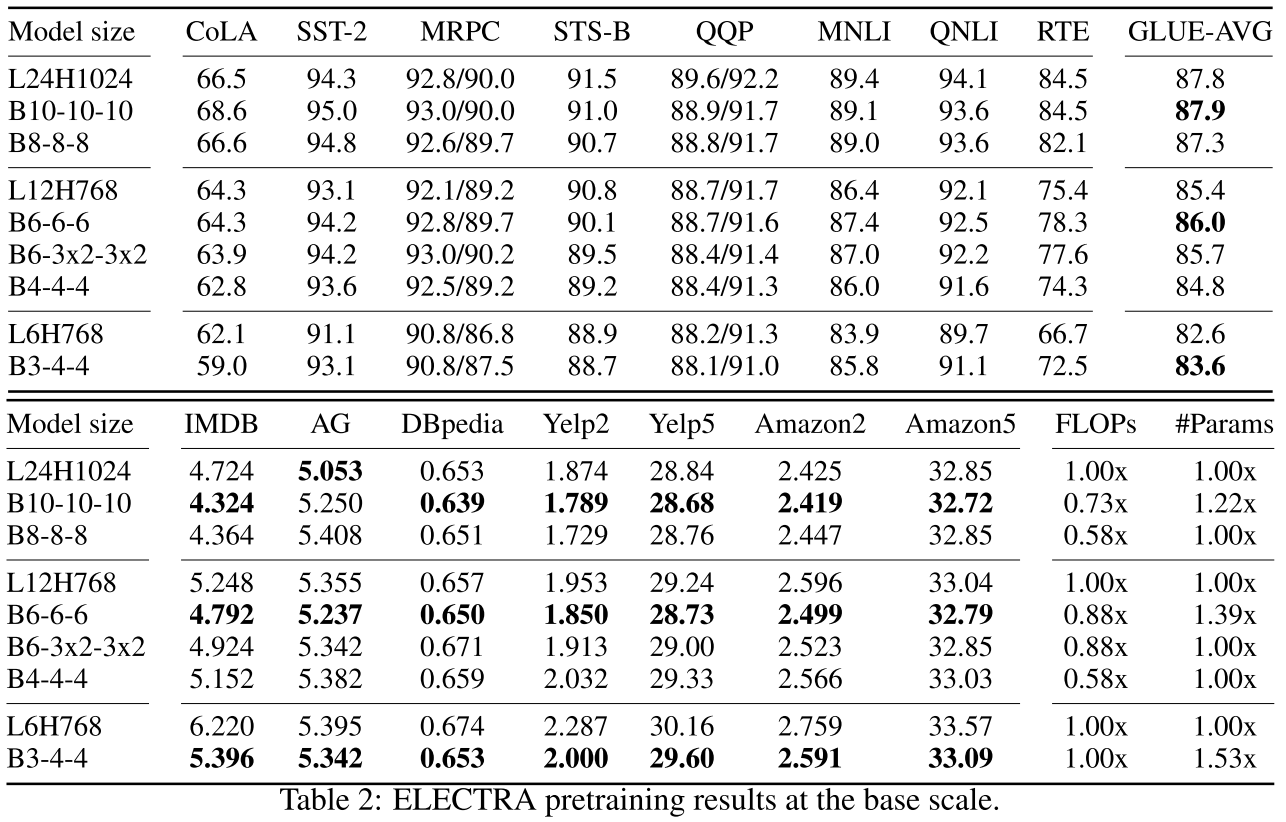
使用ELECTRA目标的结果趋势类似,证明了方法的通用性。
3.2 Large规模结果(与SOTA对比)
在更大规模上(5个数据集,batch size 8192,50万步),F-TFM的优势更加明显。
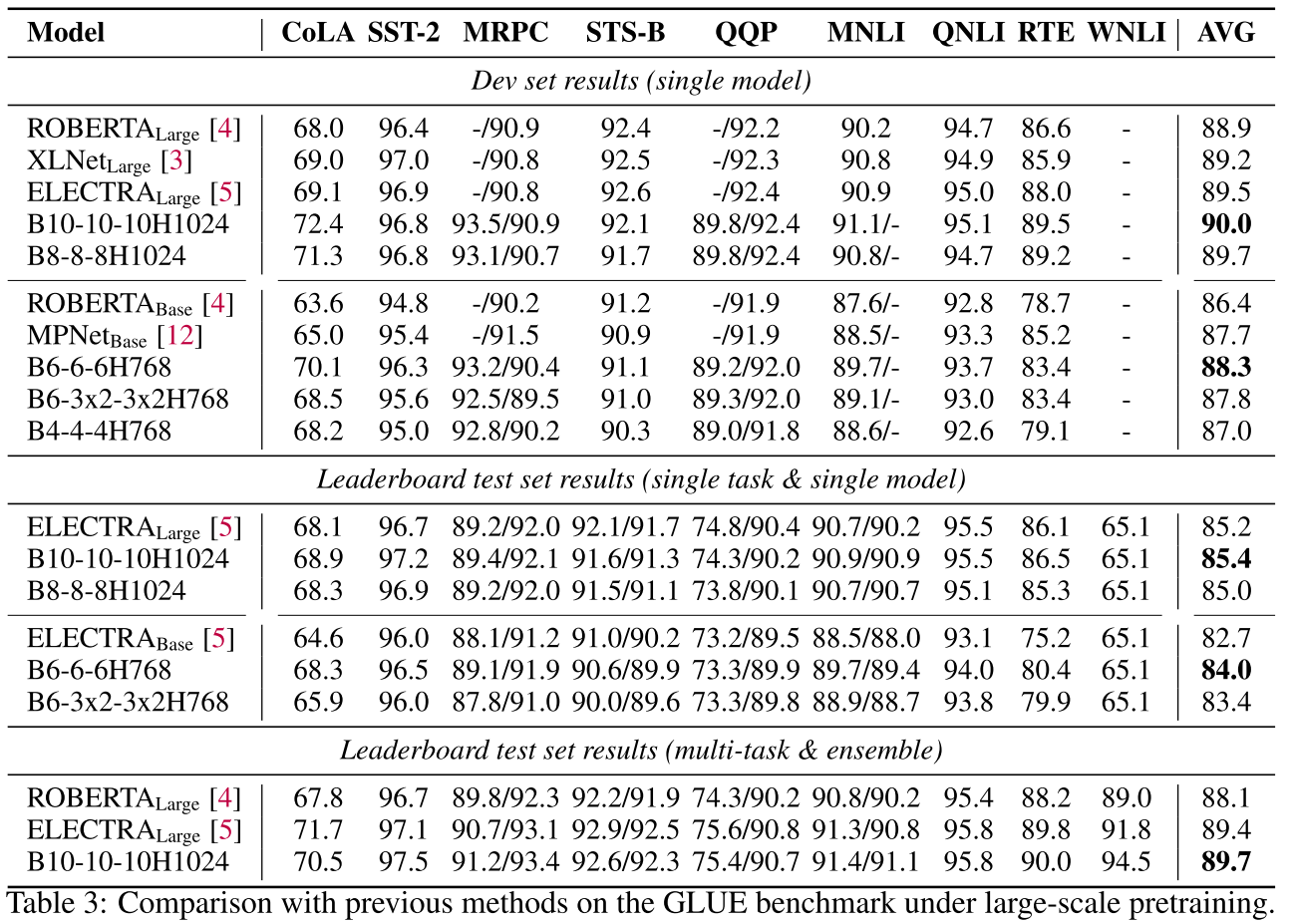
Dev Set单模型结果:
| 模型 | CoLA | SST-2 | MNLI | QNLI | RTE | 平均 |
|---|---|---|---|---|---|---|
| ELECTRA-Large | 69.1 | 96.9 | 90.9 | 95.0 | 88.0 | 89.5 |
| B10-10-10H1024 | 72.4 | 96.8 | 91.1 | 95.1 | 89.5 | 90.0 |
| RoBERTa-Base | 63.6 | 94.8 | 87.6 | 92.8 | 78.7 | 86.4 |
| B6-6-6H768 | 70.1 | 96.3 | 89.7 | 93.7 | 83.4 | 88.3 |
惊人的发现:
- B10-10-10超越ELECTRA-Large 0.5分
- B6-6-6(base模型)超越RoBERTa-Base 1.9分
- CoLA任务提升尤其显著(+6.5和+6.5)
Test Set排行榜结果(单任务单模型):
| 模型 | 平均分 |
|---|---|
| ELECTRA-Large | 85.2 |
| B10-10-10H1024 | 85.4 |
| ELECTRA-Base | 82.7 |
| B6-6-6H768 | 84.0 |
F-TFM在官方排行榜上也取得了最佳结果!
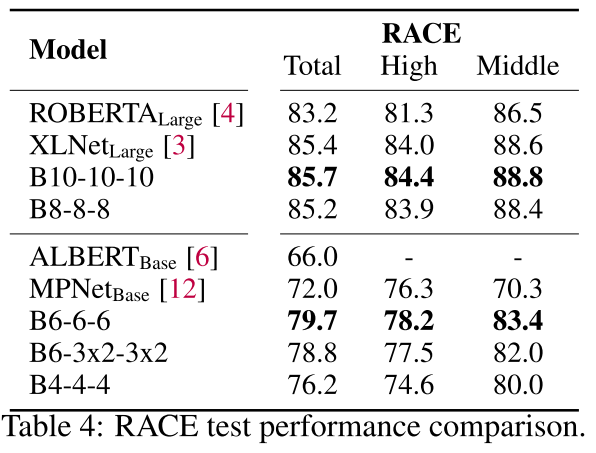
RACE测试集性能:
| 模型 | Total | High | Middle |
|---|---|---|---|
| XLNet-Large | 85.4 | 84.0 | 88.6 |
| B10-10-10 | 85.7 | 84.4 | 88.8 |
| MPNet-Base | 72.0 | 76.3 | 70.3 |
| B6-6-6 | 79.7 | 78.2 | 83.4 |
在需要复杂推理的长文本任务上,F-TFM依然表现出色,B6-6-6比MPNet-Base提升了7.7分!
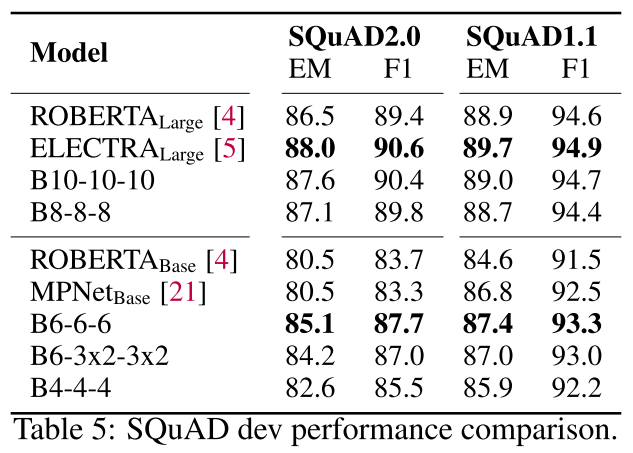
SQuAD 2.0 Dev Set:
| 模型 | EM | F1 |
|---|---|---|
| ELECTRA-Large | 88.0 | 90.6 |
| B10-10-10 | 87.6 | 90.4 |
| RoBERTa-Base | 80.5 | 83.7 |
| B6-6-6 | 85.1 | 87.7 |
虽然在token-level任务上F-TFM的优势略小(因为需要详细的token信息),但base模型依然大幅超越baseline(+4.6 EM,+4.0 F1)。
3.3 实际运行速度
理论FLOPs的减少能转化为实际加速吗?论文在GPU和TPU上都做了测试。
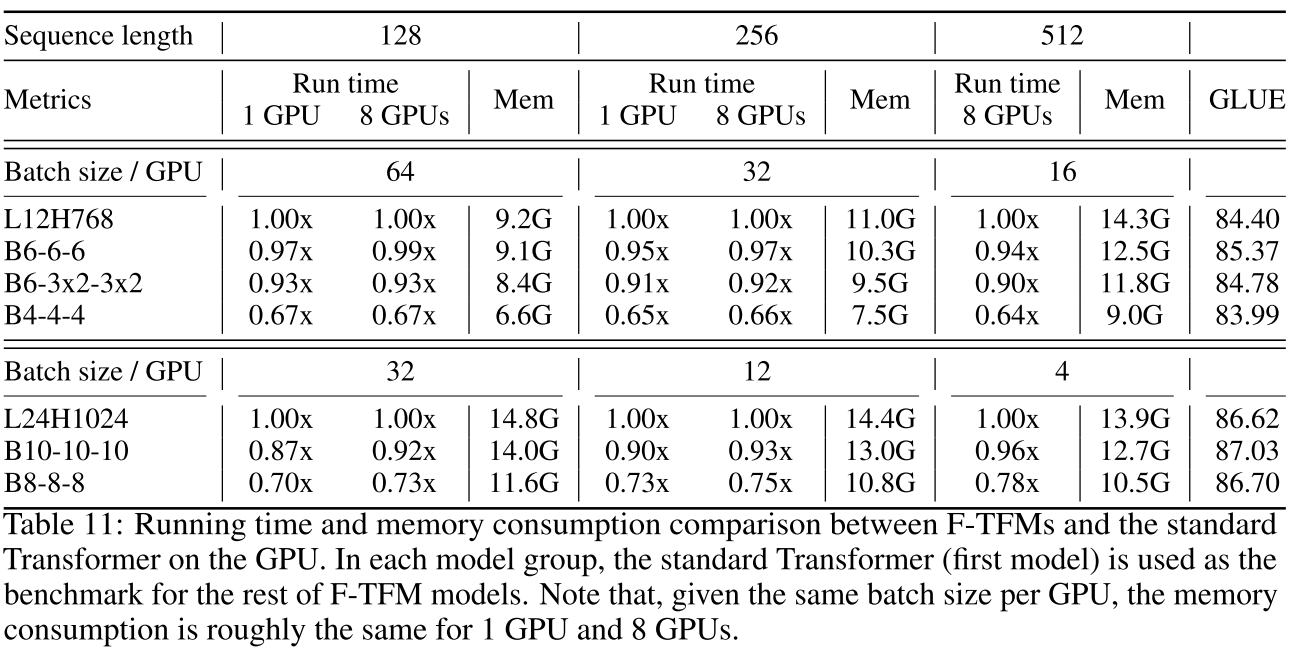
GPU (V100) 上的加速(序列长度512):
| 模型 | 运行时间 | 内存占用 | GLUE分数 |
|---|---|---|---|
| L12H768 | 1.00x | 14.3G | 84.40 |
| B6-6-6 | 0.94x | 12.5G | 85.37 |
| B4-4-4 | 0.64x | 9.0G | 83.99 |
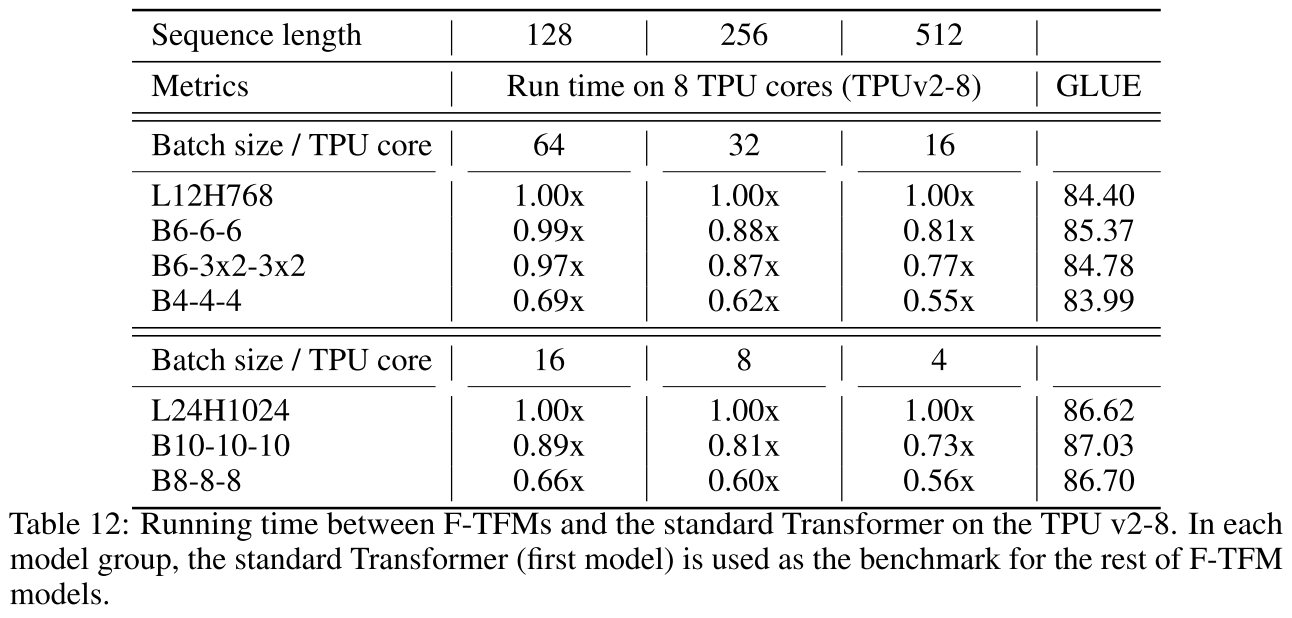
TPU (v2-8) 上的加速:
| 模型 | 序列128 | 序列256 | 序列512 |
|---|---|---|---|
| L12H768 | 1.00x | 1.00x | 1.00x |
| B6-6-6 | 0.99x | 0.88x | 0.81x |
| B4-4-4 | 0.69x | 0.62x | 0.55x |
观察:
- 序列越长,加速效果越明显(符合超线性复杂度减少)
- TPU上的加速比GPU更显著(序列512时,B6-6-6快19%)
- 内存占用全面降低
- B6-6-6同时实现了加速和性能提升
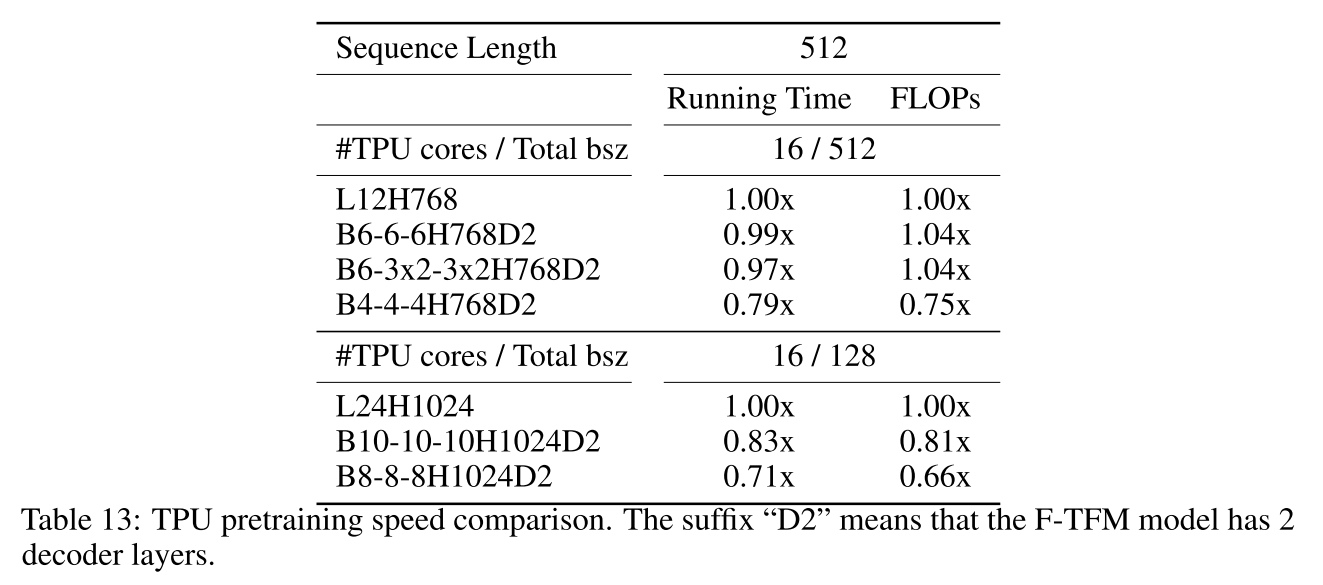
即使加上解码器,预训练阶段依然有明显加速(B10-10-10快17%)。
3.4 消融实验
论文做了详尽的消融研究来验证各个设计的重要性。
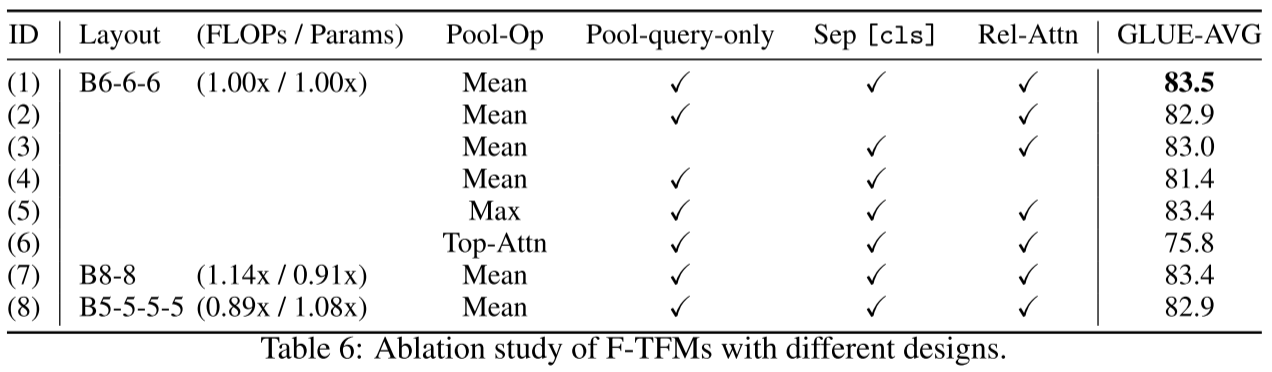
关键设计的贡献(GLUE平均分):
| ID | 配置 | Pool操作 | Pool-query-only | 分离[cls] | 相对Attn | GLUE |
|---|---|---|---|---|---|---|
| (1) | B6-6-6 (完整) | Mean | ✓ | ✓ | ✓ | 83.5 |
| (2) | 去掉Pool-query-only | Mean | ✗ | ✓ | ✓ | 82.9 (-0.6) |
| (3) | 去掉分离[cls] | Mean | ✓ | ✗ | ✓ | 83.0 (-0.5) |
| (4) | 去掉相对Attn | Mean | ✓ | ✓ | ✗ | 81.4 (-2.1) |
| (5) | Max pooling | Max | ✓ | ✓ | ✓ | 83.4 (-0.1) |
| (6) | Attention-based | Top-Attn | ✓ | ✓ | ✓ | 75.8 (-7.7) |
重要发现:
- 相对位置编码最关键(-2.1分):Pooling会破坏绝对位置信息
- Pool-query-only很重要(-0.6分):使压缩更具表达力
- Mean和Max pooling性能相近,都远优于attention-based选择
- 分离[cls]也有帮助(-0.5分)
Block布局设计:
| 配置 | FLOPs | 参数 | GLUE |
|---|---|---|---|
| B8-8 (2-block) | 1.14x | 0.91x | 83.4 |
| B6-6-6 (3-block) | 1.00x | 1.00x | 83.5 |
| B5-5-5-5 (4-block) | 0.89x | 1.08x | 82.9 |
3-block设计是最优选择,在FLOPs/性能权衡上最好。
四、深入理解
4.1 为什么Funnel-Transformer有效?
-
消除序列冗余:
- 序列级任务不需要维持完整token信息
- 类似CNN的分层特征提取思想
- 符合语言学中"词→短语→句子"的层次结构
-
深度换长度的策略:
- 节省的FLOPs投入到更深的网络
- 更深的网络有更强的表达能力
- 在压缩块中,每个token都能"看到"更多全局信息
-
Pool-query-only的妙用:
- 让attention参与压缩过程
- 比固定的pooling策略更灵活
- 最小开销获得最大收益
4.2 适用场景
最适合的任务:
- ✅ 文本分类
- ✅ 句子对匹配(NLI)
- ✅ 阅读理解(选择题形式)
- ✅ 语义相似度
次优但仍可用:
- ⚠️ 抽取式问答(SQuAD)
- ⚠️ 序列标注
不太适合:
- ❌ 生成任务(需要详细token信息)
4.3 与其他方法的对比
| 方法 | 核心思想 | 优势 | 劣势 |
|---|---|---|---|
| Funnel-TFM | 压缩序列长度 | 直接减少计算,可训练性强 | Token-level任务稍弱 |
| Sparse Attention | 稀疏化attention | 保持全长表示 | 实现复杂,硬件不友好 |
| Knowledge Distillation | 蒸馏到小模型 | 模型小 | 需要大模型teacher |
| Pruning/Quantization | 压缩权重 | 推理快 | 训练阶段无益 |
Funnel-Transformer的独特优势在于训练和推理都高效,且无需依赖其他大模型。
五、实现建议
如果你想使用Funnel-Transformer,这里有一些实践建议:
5.1 模型配置选择
对于序列级任务:
- Base规模:推荐B6-6-6H768(性能最佳)
- Large规模:推荐B10-10-10H1024
- 如果内存受限:使用B6-3x2-3x2H768(参数共享版本)
- 如果需要极致速度:使用B4-4-4H768
对于token-level任务:
- 使用带decoder的版本
- 可能需要调整decoder层数(默认2层)
5.2 超参数
论文提供的关键超参数:
- Pooling: Stride=2, Window=2的mean pooling
- Decoder layers: 2层
- Position encoding: Transformer-XL的relative attention(必须!)
- [cls] token: 要单独处理
5.3 训练技巧
-
预训练:
- 可以使用MLM或ELECTRA目标
- ELECTRA通常效果稍好
- 超大模型(>24层)可能需要降低学习率避免不稳定
-
微调:
- 序列级任务直接去掉decoder
- 学习率搜索范围:{1e-5, 2e-5, 3e-5}
- 使用layer-wise learning rate decay(如0.75)
六、总结与展望
主要贡献
- 识别了被忽视的冗余:全长序列表示在序列级任务中存在冗余
- 提出了高效架构:通过压缩序列长度并再投资节省的FLOPs
- 验证了有效性:在多个benchmark上取得SOTA或接近SOTA的结果
- 实现了真正的加速:不仅是理论FLOPs,实际运行时间也明显减少
适用性分析
优势场景:
- 序列分类、匹配、排序等任务
- 资源受限的环境
- 需要处理大量数据的应用
- 长序列处理(压缩效果更明显)
局限性:
- Token-level任务性能略有下降
- 需要相对位置编码(对已有模型的迁移有要求)
- Block布局设计仍需探索
未来方向
论文提出了几个值得探索的方向:
-
更好的压缩方案:
- 动态决定压缩率
- 任务自适应的pooling策略
- 可学习的压缩函数
-
Block布局优化:
- 自动搜索最优布局
- 任务特定的布局设计
-
与其他技术结合:
- 知识蒸馏 + Funnel-TFM
- 量化 + Funnel-TFM
- 可能实现更大的效率提升
-
扩展到其他领域:
- 视频理解(时间维度压缩)
- 多模态模型
- 图结构数据
结语
Funnel-Transformer提供了一个简单而有效的思路:不是所有层都需要维持全长序列。通过借鉴CNN的分层抽象思想,它成功地在保持甚至提升性能的同时显著降低了计算成本。
这篇论文的启发意义在于:在追求更大模型的同时,我们也应该思考如何更聪明地使用计算资源。有时候,架构层面的创新比单纯堆砌参数更有价值。
对于实践者来说,Funnel-Transformer提供了一个即插即用的高效替代方案。无论是在学术研究还是工业应用中,它都值得一试,特别是在处理序列级任务和长序列场景时。
希望这篇详细的介绍能帮助你理解Funnel-Transformer的设计思想和实现细节。如果你在实践中有任何问题,欢迎交流讨论!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)