AI系统功能测试怎么做?从“正确性断言”到“上下文边界”的测试范式转移
关注 霍格沃兹测试学院公众号,回复「资料」, 领取人工智能测试开发技术合集
当 AI 应用真正落地到业务系统之后,很多测试工程师会突然发现一件事:
以前的测试方法,开始失灵了。
断言写不出来。 对错边界模糊。 输出无法精确匹配。
问题不是工具不够用,而是——测试对象变了。
本文围绕 AI 系统功能测试展开,从测试目标、能力边界、上下文限制、多轮一致性等角度,系统拆解 AI 功能测试的核心方法。
目录
-
为什么“正确性”不再是唯一目标
-
传统测试 vs AI 测试:目标差异的本质
-
AI 功能测试的真实工程场景拆解
-
上下文长度限制:最容易被忽视的功能风险
-
多轮对话状态一致性测试方法
-
行业专家视角:原测试框架需要补充什么
-
AI 功能测试的完整关注清单
一、为什么“正确性”不再是唯一目标
在传统系统中,测试的核心目标非常明确:
-
输入确定
-
规则明确
-
输出唯一
-
可以精确断言
测试追求的是:系统在已知规则下没有 bug。
但 AI 系统不是规则驱动,而是概率生成。
你让模型生成一份思维导图,它可能:
-
结构正确但内容重复
-
内容相关但层级混乱
-
语义正确但不可落地
这时你会发现:
它并没有“错”,但也不算“好”。
因此 AI 测试的核心目标从“正确性”,转向:
-
可接受性
-
风险可控
-
输出稳定
-
能力边界清晰
这是一种评估思维,而不是断言思维。
二、传统测试 vs AI 测试:目标差异的本质
1)传统测试的特点
-
明确需求文档
-
可精确断言
-
输出唯一
-
测试结果二值化(通过/不通过)
例如:页面背景色必须是红色,否则失败。
2)AI 测试的特点
-
需求通常是软性的
-
输出存在多种合理解
-
难以精确断言
-
需要综合评估
例如:
“生成正在下雪城市的思维导图”
满足生成不等于满足可用。
AI 测试关注的是:
-
是否覆盖关键维度
-
是否存在逻辑冲突
-
是否存在重复
-
是否偏离主题
这不是简单对错问题。
三、AI 功能测试的真实工程场景拆解
在视频案例中,构建了一个简易 AI 智能助手,用于模拟助学贷款网站的智能客服。
测试结果发现:
-
回答笨拙
-
内容冗余
-
无边界判定
-
无安全防护
-
角色容易偏离
这类场景型 AI 应用,与通用大模型应用(例如 豆包)是不同的。
通用模型追求泛化能力。
企业场景 AI 追求:
-
场景稳定性
-
输出可控
-
边界清晰
-
风险可控
测试策略必须差异化设计。
四、上下文长度限制:最容易被忽视的功能风险
这是 AI 功能测试中的核心点。
什么是上下文长度?
模型在一次对话中能“记住”的内容大小,通常以 token 计量。
超过长度后,早期内容会被截断。
典型测试场景
测试 AI 扮演某个角色:
-
第 3 轮对话:角色正常
-
第 20 轮对话:角色开始漂移
不是模型智商问题,而是上下文溢出。
在代码分析中的表现
-
小段代码分析正常
-
超大文件分析错误
这说明模型无法在窗口内完整理解结构。
因此功能测试必须包含:
-
不同规模输入测试
-
中文/英文混合测试
-
JSON 长文本测试
-
多文件拼接测试
测试的核心是找出:
模型能力边界。
学习资料
需要OpenClaw学习资料可以扫码进群领取!👇
五、多轮对话状态一致性测试
AI 系统是“有状态”的。
测试点包括:
-
角色是否持续
-
立场是否前后一致
-
是否产生逻辑冲突
-
是否遗忘前置设定
测试流程可抽象为:
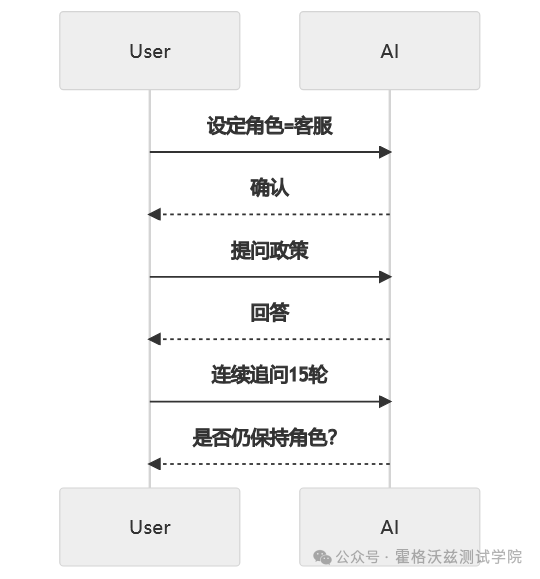
如果角色消失或立场变化,属于功能缺陷。
在传统系统中不会出现这种“遗忘”现象。
但在 AI 系统中,这是必须验证的功能项。
六、行业专家视角:还需要补充哪些关键测试维度?
如果站在行业实践角度,上述内容还需要补充以下关键点:
1)提示词攻击与越权测试
-
是否可以绕过角色限制?
-
是否可以诱导模型泄露系统 Prompt?
-
是否可被提示注入攻击?
这是 AI 系统特有的功能安全问题。
2)输出结构稳定性测试
对于 JSON 输出、函数调用模式:
-
字段是否稳定
-
类型是否变化
-
是否存在结构漂移
结构不稳定,会直接导致系统崩溃。
3)温度参数影响测试
不同 temperature 下输出差异是否可接受?
这属于生成波动性测试。
4)长上下文性能退化
在接近上下文极限时:
-
是否响应时间显著增加?
-
是否错误率上升?
这是功能与性能交叉测试点。
5)幻觉(Hallucination)控制能力
是否编造不存在的政策? 是否生成虚假数据?
这不是逻辑 bug,但属于严重功能风险。
七、AI 功能测试完整关注清单
功能测试不再只看“输出对不对”,而应关注:
-
上下文长度极限
-
多轮状态一致性
-
角色保持能力
-
场景边界控制
-
提示词攻击防护
-
输出结构稳定性
-
长输入容错能力
-
幻觉风险
-
温度波动影响
这是一套新的测试体系。
结语
当测试对象从“规则系统”变成“概率系统”,
测试工程师的角色也随之改变。
从:
验证结果是否正确
转向:
评估系统行为是否可控。
AI 功能测试,本质是在寻找:
模型的能力边界、稳定区间与风险极限。
这不是工具升级。
这是测试范式的转移。
而理解这个转移,是 AI 时代测试工程师的分水岭。
关于我们
霍格沃兹测试开发学社,隶属于 测吧(北京)科技有限公司,是一个面向软件测试爱好者的技术交流社区。
学社围绕现代软件测试工程体系展开,内容涵盖软件测试入门、自动化测试、性能测试、接口测试、测试开发、全栈测试,以及人工智能测试与 AI 在测试工程中的应用实践。
我们关注测试工程能力的系统化建设,包括 Python 自动化测试、Java 自动化测试、Web 与 App 自动化、持续集成与质量体系建设,同时探索 AI 驱动的测试设计、用例生成、自动化执行与质量分析方法,沉淀可复用、可落地的测试开发工程经验。
在技术社区与工程实践之外,学社还参与测试工程人才培养体系建设,面向高校提供测试实训平台与实践支持,组织开展 “火焰杯” 软件测试相关技术赛事,并探索以能力为导向的人才培养模式,包括高校学员先学习、就业后付款的实践路径。
同时,学社结合真实行业需求,为在职测试工程师与高潜学员提供名企大厂 1v1 私教服务,用于个性化能力提升与工程实践指导。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)