OpenClaw一周“造富神话“背后:AI时代没有魔法棒
就像2025年初的DeepSeek一样,OpenClaw在2026年初席卷中国互联网,一时之间“养虾”成风。在“AI+”的确定性未来面前,抓住行业“风口”、避免被甩出技术潮流,似乎是一种普遍焦虑。
但比去年DeepSeek国产大模型爆火更加疯狂的是,OpenClaw这个外来和尚,几天之内就完成了从付费安装到付费卸载的造富神话,甚至连官方都出现从“深圳速度”到齐发安全警示的戏谑式逆转。

DeepSeek、OpenClaw所代表的大模型、智能体都是当下“AI+”落地的关键技术,它们也许在某些稍纵即逝的流量窗口期能给极少数个人带来短暂“暴富”的机会,但无法真正回应市场的深层焦虑。
业界一个隐秘的期望是:如何将这些技术变成企业和组织“点石成金”的魔法棒?
没有魔法棒,只有“笨功夫”
我们在《Palantir研究总结3:商业的魔法》一文中探讨过这个问题,我们当前对数据的认识尚不全面。而硅谷首屈一指的Palantir,也是从金融、军事场景定制场景起步,在漫长时间里花无数“笨功夫”一步步深挖数据矿产,最终才沉淀为标准化的Foundry平台;全球首富马斯克的SpaceX也是从“猎鹰9-星链”、“星舰-太空算力”一个一个闭环向外拓展。
今天我们所看见的所谓硅谷AI“神话”,其实都是一步一个脚印循着产业数字化的基本规律而来。
这个规律,简单来说就是抓住两点:
一是实体场景本身的作业链全链;二是这条作业链的数字化演进路径。
实体场景与数字化技术结合,其核心的价值交叉点在数据分析环节——也就是让数据转化为知识、洞察的这个过程。而实体场景的数字化演进,关键就在于让这个环节的价值最大化:
一方面,通过数字孪生建模与实时采集监测,将全链路作业搬入数字空间,让数据汇聚,在此基础上通过IT技术进行处理分析(过去依靠大数据、现在有了高智能的AI)。
另一方面,让基于数据生成的知识、洞察成为整个系统的决策中枢,反向驱动场景运行,形成数据→知识/洞察→决策→执行→新数据的增强回路,让数据闭环。
所谓的数字化转型,说一千道一万,根本上就是这两件事。在这样一个体系里,AI是个放大器和加速器:将同样一堆数据里的价值深度榨取,发现人脑无法发现(或无法快速发现)的关联;将依赖人工传递的断点彻底通过数据关联打通,促使决策行动周期从天压缩到秒。
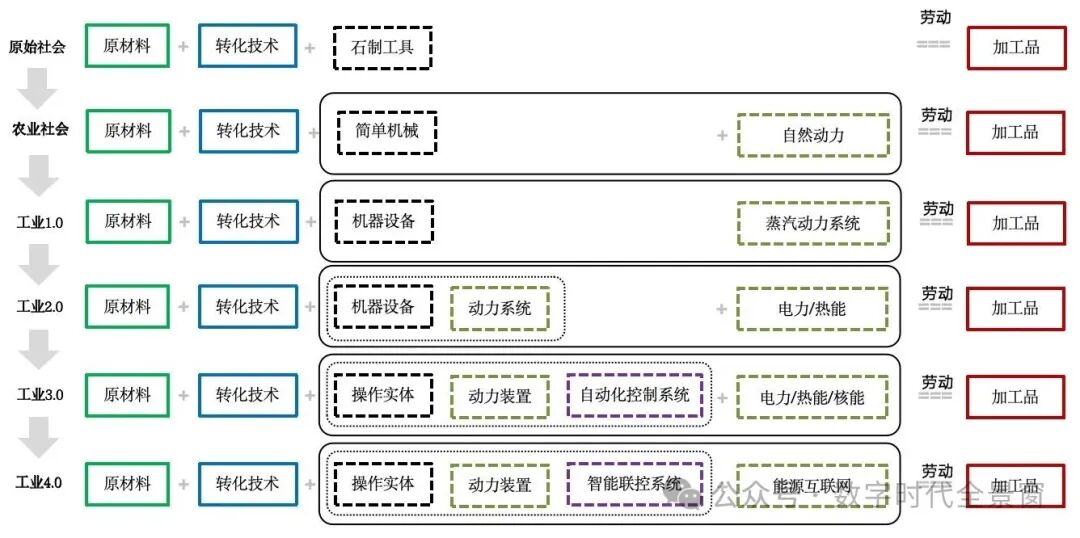
这两件事其实也是整个工业化从1.0到4.0的缩影:
-
工业1.0和2.0,就是用机器代替人工(机械化)和将生产过程分解为标准化工序,形成电力驱动的大规模流水线(电气化)。这也是数字化得以启动的“骨架”和“肌肉”。
-
工业3.0在工业2.0基础上开始搭建“感知神经”,实现部分环节上线和上网,让数据流动起来(信息化)。
-
工业4.0进一步组装“大脑”,将实体场景全链路在线上闭环,并嵌入AI能力,实现自主驱动(智能化)。
每一次变革都伴随作业链本身的技术演进,以及数字化从地基到顶层建筑的层层搭建。工业1.0到4.0这四个阶段环环相扣、缺一不可:
只有人力没有机器,工业数字化建模没有触点;
有机器但机器作业流程没有标准,谈不上控制;
流程有标准但信息没有数字化,无法通过数据架构实现汇聚与协同;
信息数字化了但没有AI,复杂决策难以自动化,全链路优化闭环也就难以实现。
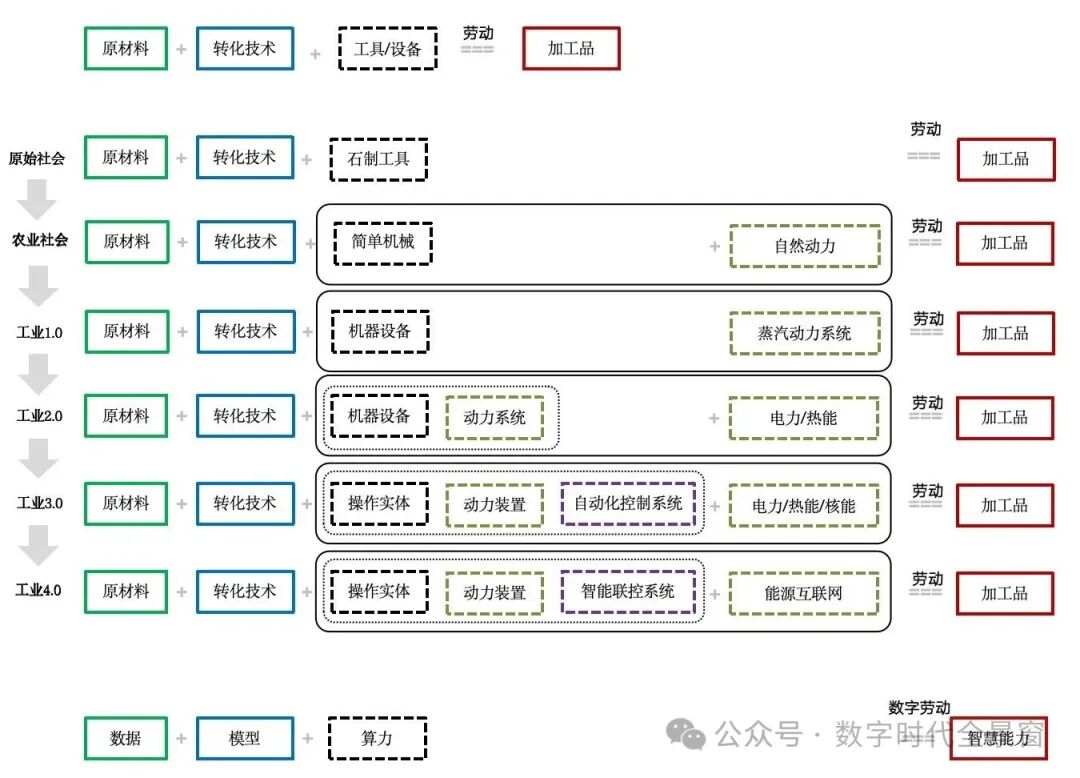
当我们把工业品或类工业品的生产过程拆解成如下这个公式时,会更容易理解:

一切工业生产概莫能外。以酿酒、炼铁为例:
-
原材料、转化技术构成实体场景本身的作业链。这部分的内核可能相对稳定(比如酿酒技术从古到今都是粮食加酵母,炼铁始终都是矿石加还原反应),只是会随着原材料范畴拓展、提取方式进化以及转化技术(酿造和冶炼工艺)的升级而更丰富。
-
数字化演进的主要承载落在设备这个要素上。从石头木块到简单机械,再到复杂机械、自动化产线,设备一步步复杂化、模块化——操作部分、传动系统、控制系统、能源供给部分各自演进,最终形成“通用硬件+操作系统+软件”的工厂级/企业级协同架构。
-
在这个过程中,人的劳动越来越机械化,机械的劳动越来越“人”化(智能化)。公式中的每一个要素都在发生联动变化:设备升级改变人的操作方式,倒逼组织模式调整,又反过来对设备及工艺流程提出新需求;原材料和转化技术的突破驱动整个系统进入下一轮迭代……
我们为什么容易产生“一步登天”的幻想?
国内对于工业化的认识往往是碎片化和不连贯的,这就导致我们在产业智能化、工业4.0、“AI+”上很容易产生“一步登天”、靠移植单个技术解决所有系统性问题的幻想。这种认知偏差主要源于两点:
一、对“跨越式发展”的误解
我国过往“几十年实现西方几百年的工业化成就”,很容易被理解成“跨越式演进”,仿佛我们是直接跳过某些阶段一步到位。
事实上,这个过程本质上是用更先进的组织方式、更高效的社会动员、更集中的资源调配,将工业化必经的每一个阶段——机械化、电气化、自动化、信息化——都压缩在更短的时间窗口内完成,而非真正跳过了任何一个环节。
相当于用百米跑的速度完成了马拉松。但每个阶段该啃的硬骨头,一块都没少啃。
我们的工业化第一阶段(53-76),是从0到1完整补全工业1.0的必修课,将一个一穷二白的农业国打造成强悍的工业国,并快速向工业2.0升级和前瞻性布局工业3.0。
所以五、六十年代会有工业、农业、国防、科学技术的现代化这个口号:
-
工业现代化与农业现代化,核心就是机械化——用机器替代人力,用能源动力替代畜力,让工业和农业生产摆脱对体力的依赖;
-
国防现代化,是工业能力在军事领域的延伸;
-
科学技术现代化,则是为后续向工业2.0、3.0跃迁埋下的种子。


1974年动工、1978年建成投产的武钢“一米七轧机工程”,引入多级计算机控制系统,实现了从坯料设定、厚度控制到生产跟踪的全线自动化。这是我国完成工业1.0、向工业2.0升级并开始接触工业3.0技术的标志性事件。
在这期间,为工业3.0铺路的基础性研究也陆续取得突破。
计算机
1970-1974年:成都电讯工程学院研制成功930保密通讯专用计算机(930工程),采用ECL高速集成电路,为我国战术保密通讯提供技术支持。
1973年,北京大学、“738厂”、石油勘探局等联合研制成功中国第一台每秒运算100万次的大型集成电路计算机,并运行了我国第一个多道运行操作系统。
1974年起,我国多个小型计算机研制成功,包括清华牵头研制的DJS-130、中科院电工所研制的XDJ-73,以及华东师大研发的我国首台具备容错功能的工业控制计算机DJS-112等。这些小型机随后被快速投入系列工业自动化实践。
集成电路与存储器
1972年,四川永川半导体研究所(现电子工业部24所)研制成功中国第一块PMOS型大规模集成电路。
1975年,北京大学王阳元教授等人设计出中国第一批三种类型的1K DRAM动态随机存储器,比英特尔晚5年,比韩国、中国台湾早5年。
1975年,上海无线电十四厂成功开发出1024位移位存储器,集成度达8820个元器件,达到国外同期水平。
70年代末,陆续研制出256位和1024位ECL高速随机存储器,后者达到国际同期先进水平;可生产NMOS 256位和4096位、PMOS 1024位随机存储器。
半导体制造设备
70年代中后期,中科院上海冶金所在制造集成电路所需的离子注入技术领域取得重要突破。
从60年代到70年代,光刻机的技术研发路径十分清晰:
1966年,中科院研制出65型接触式光刻机,比美国第一台光刻机只晚4年,与日本基本同步,比韩国、台湾早10年。
1969年,109厂与丹东精密仪器厂合作研制成功全自动步进重复照相机,这是光刻机早期雏形的重要突破。
1971年,清华大学研制出分步重复照相机,成为后续分步投影光刻机的重要基础。
1972年,武汉无线电元件三厂编写《光刻掩模版的制造》,标志中国芯片光刻工艺研究正式起步。
1974-1977年,中电科45所(原1445所)研制成功GK-3型半自动光刻机,可处理75毫米晶圆。
1975年,中科院109厂工程师原锡铎设计大面积光刻机图纸,哈尔滨量具刃具厂承担研制任务。
1977年,江苏吴县召开全国光刻机座谈会,42家单位67人参加,制定技术发展计划。
1978年,1445所开发GK-4型光刻机;清华大学开始半自动接近式光刻机研究。
电子工业与通信技术
1970年代初,全国地方电子工业企业由1969年的1600多个增加到1970年的5200多个。
到70年代末,全国已建成四十多家集成电路工厂。
70年代,卫星通信设备和技术的研制开发获得进展,建立了多个卫星通信地面站。收音机、录音机等基本实现半导体化,中国电子产品基本过渡到半导体化技术阶段。
机床数控
1975年,齐齐哈尔第二机床厂成功研制我国第一台数控龙门铣。

1973年清华研制的自动照相排版机参加第33届中国出口商品交易会(图源清华大学官网)
总体来说,我国70年代,在工业3.0基础研究方面呈现起步早、发展快、自主化程度高、与世界差距可控、产业基础扎实等特征。但随后而来的模式转变,从自主创新为主转向全方位依赖进口,导致与国外的差距断崖式拉大,自主研发的节奏被打乱,产业根基被一点一点掏空。
2000年初重提自主创新后,陆续启动了一批科技专项。但直到2019年特朗普发起贸易战后,自主创新才真正重新成为一个普遍共识。某种程度上,今天我们在芯片、工业软件等领域的被动,都是在为80年代后的战略转向买单。
必须要客观看清楚前后的变化,才能真正理解:饭都是一口一口吃的,根本不存在第七个馒头吃饱了、前面6个馒头都白吃了这回事。
二、对技术演进连贯性的忽视
西方作为几次工业革命的发源地,尤其美国在主导性的前沿技术上一直是自主创新的发展策略,没有经历过像我们一样前后长达几十年的断崖式割裂周期,所以对技术演进脉络的认知是连贯的。
而我们因为后面几十年的节奏被打乱,对工业化的基本认识被“格式化”、被扭曲——即便2000年后开始重拾自主创新,但一直忙于在各个领域碎片式追赶,忙于把散落的系统重新拼装起来。因此,我们对工业化整个技术演进过程的理解,也是不连贯的。
从工业1.0到4.0,看起来前面主要是硬件技术主导、后面主要是软件技术主导。但软件并非从天而降,而是从硬件设备中逐步拆分出来的——控制模块从被控设备中分离,变成控制系统;逻辑模块从执行机构中抽象,变成算法。
此外,软件生产和硬件生产一样,也可以归结为“原材料+转化技术+设备+人类劳动”这样一个过程。只是软件生产的“原材料”是数据,“转化技术”是算法,“设备”则是算力资源,相应的人类劳动主要是脑力劳动。
理解了这个基本脉络,我们就不会把工业4.0看成“天降”,更不会把DeepSeek、OpenClaw看作放到沙漠里都能点石成金的魔法棒了。
即便要用好这个“魔法棒”,也需要先扎牢工业3.0的底盘——让数据采得上、流程控得住、系统连得通。没有这个底盘,AI再聪明也只是“空中楼阁”:
-
没有数字建模和采集监测,作业全链路无法上线,数据根本“聚不拢”——AI连“看”都看不到,谈何智能?
-
没有数据治理与处理分析,数据只是杂乱无章的符号,无法转化为可用的“知识”——AI再强,也只能在垃圾堆里刨食;
-
没有流程控制和系统互联,AI生成的洞察落不了地——分析得头头是道,设备却不听使唤,决策与行动之间横着一条人工鸿沟。
对于DeepSeek来说,如何将大模型应用到生产中,Palantir已经给出了答案,数据如何汇聚、如何闭环都非常清晰。之前的文章已经从各个维度分析过,无须赘述。
对于OpenClaw来说也是一样,本质上是如何将通用的智能体嵌入组织中进行生产实践的问题。同样需要打通数据孤岛,要有治理能力、规则围栏和安全边界的设计方案。但OpenClaw比大模型更进一层——它是一个能“动手”的智能体,这意味着它的失控代价更高。
因此,当前阶段的核心课题,可能更在于人机协同机制的磨合。在不清楚其自动化边界的情况下盲目引入,在真正驯化和驾驭它之前,可能要付出很高的试错成本。
这不是拒绝的理由,而是提醒:智能体并非“开箱即用”的神器,而是需要底盘支撑的活物。 数据底盘、工程底盘、组织底盘,缺一不可。
总结
即便是在可以无限放开想象力的AI时代,也不存在点石成金的魔法棒。工业化的路是要一步一步扎实走的,容不得半点儿侥幸。
当前国内还有大量企业处于工业2.0甚至更基础的阶段,这些企业面向工业4.0的跨越式转型,其实现路径并非跳过中间环节,而是基于工业4.0的现实认知,倒逼补齐工业3.0的关键建设,并把这个“补课周期”压缩到最短——让数据先汇得拢,让流程先控得住,让系统先连得通,在此基础之上,“AI+”才能真正落地,工业4.0转型也才能真正实现。
就像世界年轻时候,东方最闪耀那颗巨星做到的那样——用百米跑的速度完成马拉松,但每一步,都踩在实地上。
【推荐阅读】
【相关专题】
从空天地一体化全栈技术看,SpaceX收购xAI和布局太空算力,究竟意味着什么?
能源、芯片、超算、新能源汽车、机器人……特斯拉究竟是一家怎样的公司?(1)
能源、芯片、超算、新能源汽车、机器人……特斯拉究竟是一家怎样的公司?(2)
从本拉登、苏莱曼尼到哈梅内伊……别再误读Palantir了!
本文在网络公开资料研究基础上成文,限于个人认知,可能存在错漏,欢迎帮忙补充指正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)