【LSTM回归预测】基于融合正余弦和柯西变异的麻雀优化算法SCSSA-CNN-BiLSTM双向长短期记忆网络预测模型附Matlab实现
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
🔥 内容介绍
一、背景
(一)预测任务的复杂性与挑战
在众多领域,如金融市场预测、电力负荷预测、气象预测等,准确的预测对于决策制定、资源分配和风险评估至关重要。然而,这些领域的数据往往具有高度的复杂性和不确定性,包含非线性、非平稳以及长期依赖等特征。例如,金融市场受宏观经济环境、政策变化、投资者情绪等多种因素影响,其数据表现出复杂的波动模式;电力负荷受季节、天气、时间等因素影响,呈现出明显的周期性和随机性。传统的预测方法难以有效捕捉这些复杂特征,导致预测精度有限。
(二)现有模型的局限性
长短期记忆网络(LSTM)及其变体双向长短期记忆网络(BiLSTM)在处理时间序列数据方面表现出色,能够有效捕捉数据中的长期依赖关系。卷积神经网络(CNN)则擅长提取数据的局部特征。将 CNN 与 BiLSTM 相结合(CNN - BiLSTM),可以同时利用两者的优势,在许多预测任务中取得较好的效果。然而,CNN - BiLSTM 模型的性能高度依赖于其超参数的设置,如 LSTM 层的隐藏单元数量、CNN 的卷积核大小和数量等。手动调整这些超参数不仅耗时费力,而且很难找到全局最优解,从而限制了模型的预测性能。
(三)智能优化算法的优势
智能优化算法能够在解空间中自动搜索最优解,为解决超参数优化问题提供了有效途径。麻雀优化算法(SSA)是一种新兴的智能优化算法,模拟了麻雀觅食和反捕食行为。然而,标准的 SSA 在搜索后期容易陷入局部最优,收敛速度较慢。通过融合正余弦和柯西变异策略对 SSA 进行改进(SCSSA),可以增强其全局搜索能力和跳出局部最优的能力,从而更有效地搜索 CNN - BiLSTM 模型的最优超参数,提高模型的预测性能。
二、原理
(一)CNN - BiLSTM 模型
-
CNN 原理:CNN 通过卷积层、池化层和全连接层对数据进行特征提取和分类。卷积层使用卷积核在数据上滑动,通过卷积操作提取数据的局部特征。例如,在处理时间序列数据时,卷积核可以捕捉相邻时间步之间的局部模式。池化层则对卷积层的输出进行下采样,减少数据维度,同时保留主要特征。常见的池化方式有最大池化和平均池化。全连接层将池化层的输出进行全连接,得到最终的预测结果。
-
BiLSTM 原理:BiLSTM 由两个方向相反的 LSTM 组成,一个按顺序处理输入序列(正向 LSTM),另一个按逆序处理输入序列(反向 LSTM)。正向 LSTM 捕捉序列从开始到结束的信息,反向 LSTM 捕捉序列从结束到开始的信息。然后,将两个 LSTM 的输出进行拼接,作为 BiLSTM 的最终输出。这种架构能够更全面地捕捉时间序列中的长期依赖关系,对于预测具有复杂时间依赖的数据非常有效。在 CNN - BiLSTM 模型中,先通过 CNN 提取数据的局部特征,然后将这些特征输入到 BiLSTM 中,进一步捕捉时间序列信息,从而进行预测。
(二)融合正余弦和柯西变异的麻雀优化算法(SCSSA)
-
麻雀优化算法基础:SSA 模拟了麻雀的觅食和反捕食行为。在觅食过程中,麻雀分为发现者和追随者。发现者负责寻找食物源,它们在解空间中进行广泛搜索。追随者则跟随发现者获取食物,同时警惕捕食者。当有麻雀发现危险时,会发出警报,所有麻雀会调整位置以避免被捕食。通过这种行为,麻雀群体逐渐找到最优解(即最佳食物源)。
-
正余弦变异策略:正余弦变异策略是在麻雀位置更新过程中引入正余弦函数。具体来说,对于每个麻雀的位置更新,利用正余弦函数的周期性和振荡性,使麻雀在搜索过程中能够以不同的步长和方向进行探索。这种变异方式可以增加搜索的多样性,帮助算法跳出局部最优解。例如,在标准 SSA 的位置更新公式基础上,加入正余弦变异项:
-

-
三)SCSSA - CNN - BiLSTM 预测模型流程
-
数据收集与预处理:收集与预测任务相关的时间序列数据,并进行预处理。预处理步骤包括数据清洗(去除异常值、填补缺失值)、归一化(将数据映射到相同的尺度范围)等。对于一些具有季节性或周期性的数据,可能还需要进行季节性分解等操作,以更好地提取数据特征。
-
模型初始化:随机初始化 CNN - BiLSTM 模型的超参数,如 CNN 的卷积核大小、数量,LSTM 层的隐藏单元数量,学习率等。同时,初始化 SCSSA 的参数,如麻雀数量、最大迭代次数等。
-
SCSSA 优化超参数:将 CNN - BiLSTM 模型的超参数编码为麻雀的位置。对于每只麻雀(即一组超参数),使用对应的超参数构建 CNN - BiLSTM 模型,并在训练数据上进行训练和验证。计算模型在验证集上的预测误差(如均方误差、平均绝对误差等)作为适应度值。SCSSA 根据麻雀的适应度值,通过融合正余弦和柯西变异的更新策略,不断调整麻雀的位置(即超参数),以找到最优的超参数组合。
-
模型训练与预测:使用优化后的超参数重新构建 CNN - BiLSTM 模型,并在全部训练数据上进行训练。训练完成后,将测试数据输入到训练好的模型中进行预测。通过评估指标(如均方根误差、平均绝对百分比误差等)对预测结果进行评估,以衡量模型的预测性能。
⛳️ 运行结果
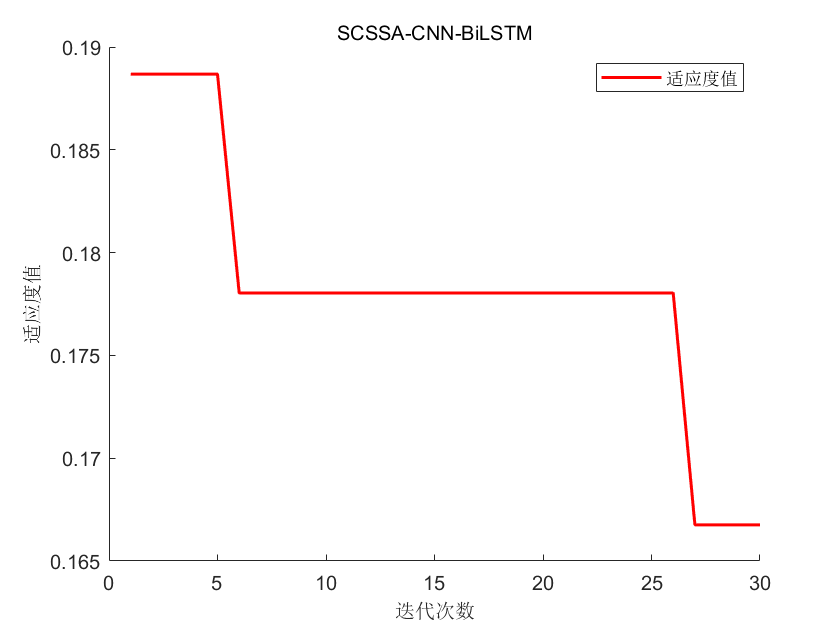
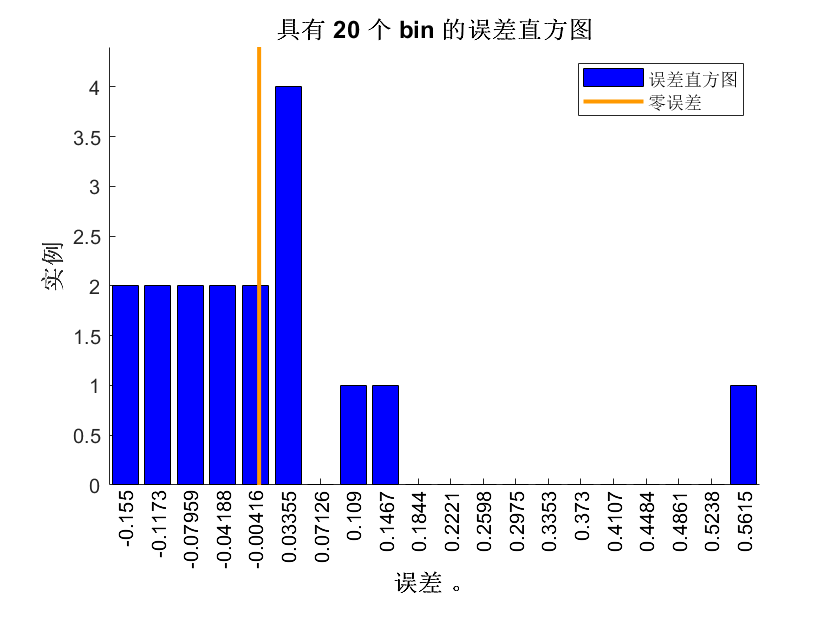
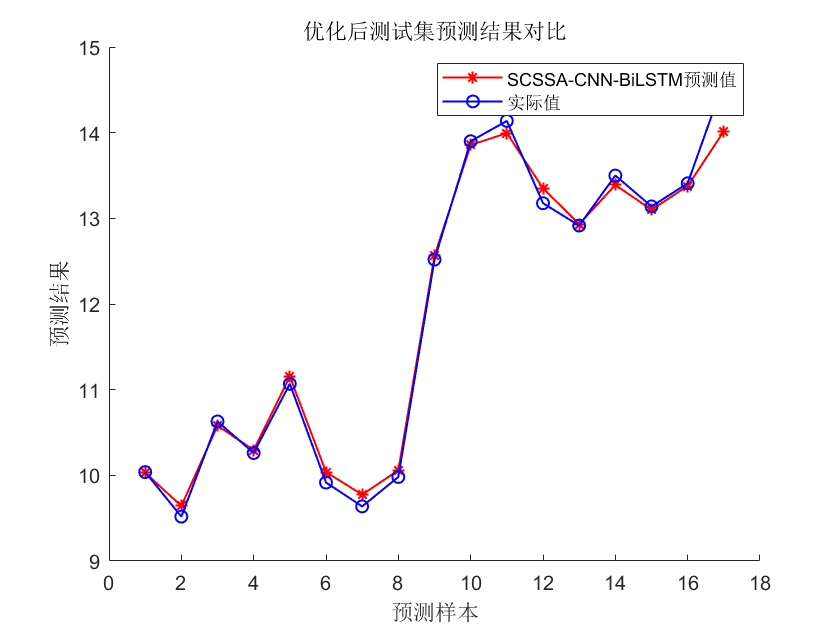
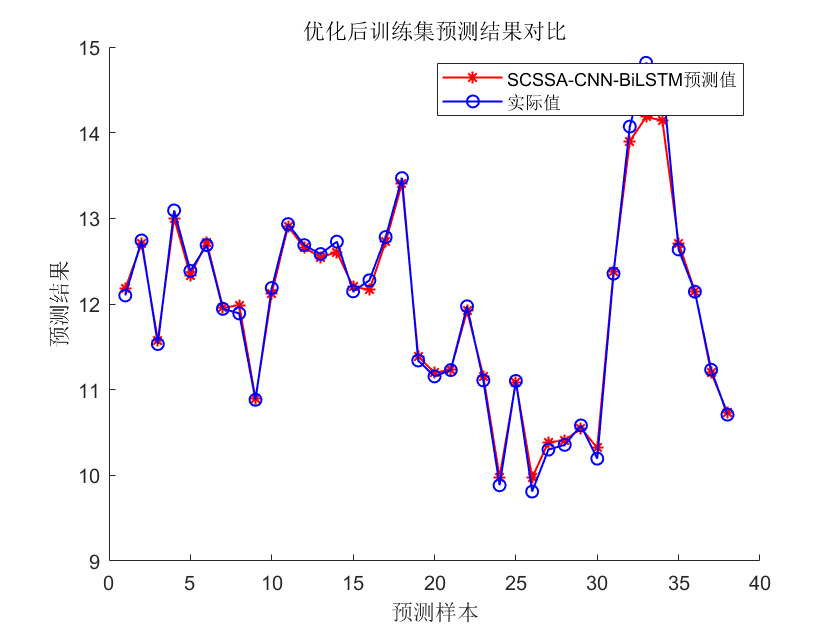
📣 部分代码
function [in,out]=data_process(data,num)
% 采用1-num作为输入 第num+1作为输出
n=length(data)-num;
for i=1:n
x(i,:)=data(i:i+num);
end
in=x(:,1:end-1);
out=x(:,end);
🔗 参考文献
🍅往期回顾扫扫下方二维码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)