从通用Agent到招标文件合规引擎:基于 openJiuwen + Skills 的工程化落地实践
从通用Agent到招标文件合规引擎:基于 openJiuwen + Skills 的工程化落地实践
引言|当“智能体”真正走进招标合规现场
过去一年,Agent 被讨论得太多了。几乎所有技术文章和者公众号都在讲例如:ReAct、多 Agent 协作、Workflow、Tool Calling、MCP、Function Calling等技术概念和功能,看起来,智能体已经无所不能。
但当我把这些能力真正带到招标合规审查的业务现场时,我发现一个很现实的问题:
一个会回答问题的模型,并不等于一个能承担合规责任的系统。
在招标文件审查场景里,我们面对的不是“问答”,而是更多的业务难题,类如:“是否存在实质性排他条款?”,“是否存在潜在废标风险?”,“资格条件是否构成限制性门槛?”,“技术参数是否暗含品牌指向?”,“评分办法是否存在明显倾向性?”等等。
这些问题,背后意味着风险、责任、甚至法律后果。
如果一个 Agent 只是“分析文本并给出建议”,那它只是一个聪明的助手。
但如果我们希望它成为一套真正可交付的“合规审查引擎”,那它必须具备三件能力:1.可追溯的规则体系,2.可执行的受控操作能力,
3.可复现的审查流程链路。
也就是说我们需要的不是一个会聊天的模型,而是一套可以落地的能力工程。
因为我越来越确定一件事:企业真正需要的,不是“更聪明的模型”。而是更可控、更稳定、更可审计的智能系统。在这篇文章里,我会完整拆解
- openJiuwen 的 Skills 机制如何成为合规能力的载体
- 如何设计招标文件合规审查的 Skills 目录体系
- 如何构建规则引擎与受控执行链路
- 如何让 Agent 生成可归档的审查报告
如果你也在思考:
- 如何把 Agent 从 Demo 变成生产能力?
- 如何让大模型真正承担业务流程的一部分?
- 如何构建可版本化的企业级能力体系?
那接下来的内容,或许会给你一些新的视角。如果你也在做 Agent 落地、合规智能化、或业务领域的 AI 工程实践,欢迎持续关注 Fanstuck。
第一章|为什么选择 openJiuwen 作为合规审查智能体的基座
说起构建一个真正能干活、可控、可审计的合规审查系统,大家第一反应往往是:
“那不就是把 LLM + 一堆 Prompt 拼一拼就完事?”
在实验场景里,这种做法确实挺好用。
可一到真实工程现场,你就会碰到三类大坑:
- 模型的执行边界不清晰
模型可以生成文本,但它不应该随意访问文件系统、执行命令、更不该无约束地操作生产环境。 - 规则很难版本化、审计难度高
如果规则只写在 Prompt 里,改一次要重发 Prompt,无法形成“可落盘、可比较”的规则体系。 - 流程不可复现
每次审查都依赖温度、上下文、生成机制,结果不可复现、不确定性高。
openJiuwen 是一个开源的 Agent 平台,核心目标是提供一个既能让大模型发挥能力,又能约束执行行为的工程化智能体框架。它不只是一个聊天机器人,而是一个具备:事件驱动的多 Agent 控制机制,可以管理多个智能体实例,支持多任务并发与中断恢复。高可靠的执行引擎,任务状态持久化、隔离管理、节点可恢复,让智能体的执行过程不再是“一次性黑盒”。自动优化的提示词机制, 通过文本梯度的方法自动调整指令与示例,而不是人肉逐条调参。
简单来说,它想解决一个问题:让智能体不仅会说,还会“按规则做事”。在这一点上,openJiuwen 提供了两套非常关键的机制:Skills 和SysOperation。
Skills:把能力做成“可管理的资产”
很多智能体项目都停留在把知识写在 Prompt 的阶段。Skills 不只是 Prompt 的替代品,它是一个能力工程资产。换言之,你的“招标规则”不再是人脑里的 tacit knowledge,而是一个落盘、可升级的能力单元。这对合规审查系统的可靠性至关重要。
Agent Skills 本质上是一个模块化的 Markdown 文件,能教会 AI 工具 (如 Claude、GitHub Copilot、Cursor 等) 执行特定任务,且支持自动触发、团队共享与工程化管理,彻底告别重复的提示词输入。核心形式:
- 一个 Skill 就是一个文件夹,里面必须有一个 SKILL.md 文件(包含说明和元数据),可选其他资源文件(如脚本、示例、参考文档)。
- Skill 是一个 Markdown 文件(SKILL.md),用于教 Claude 在特定场景下按你的方式做事。
- 本质是其实就是相当于给 AI 代理发放一本专业手册,AI 不会每次都从零学习,而是根据任务自动调用手册中的知识。
- 简单来说,过去我们用提示词(prompt)教 AI 做事,现在用 Agent Skills 可以把提示词 + 资源打包成可复用、可共享的技能包,更高效、更可靠。
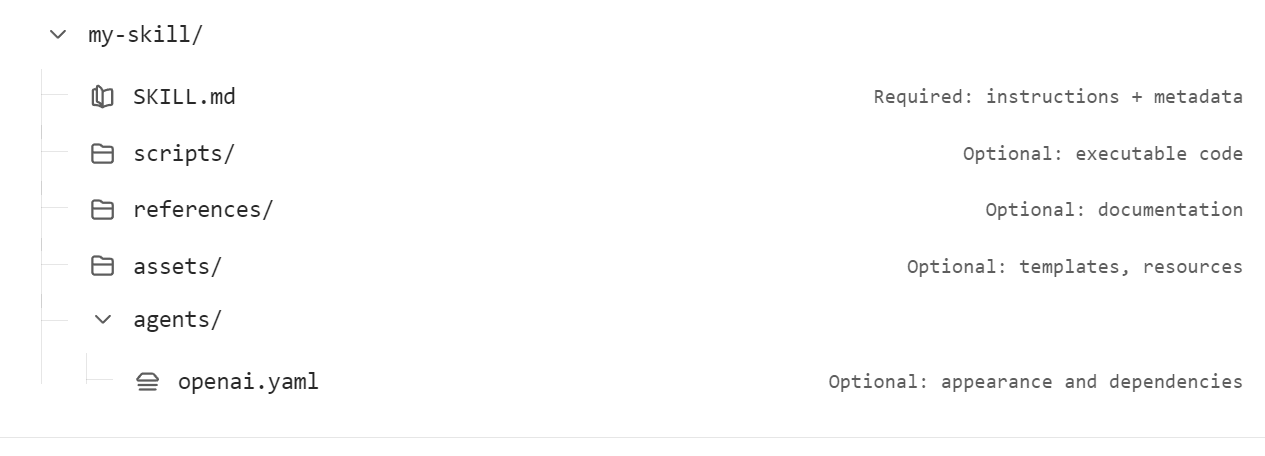
一个 Skill 本质上就是一个 Markdown 文件(文件名固定为 SKILL.md)
my-skill/
└── SKILL.md (唯一必需)
SKILL.md 基本模板:
---
name: pdf-processing
description: 从 PDF 中提取文本和表格,填写表单,并合并文档
---
# PDF 处理
## 使用场景
当需要对 PDF 文件进行操作时使用,例如:
- 提取 PDF 文本或表格数据
- 填写 PDF 表单
- 合并多个 PDF 文件
## 提取文本
- 使用 `pdfplumber` 提取文本型 PDF 内容
- 扫描版 PDF 需配合 OCR 工具
## 填写表单
- 读取 PDF 表单字段
- 按输入数据填充并生成新文件
最小必填示例:
---
name: skill-name
description: 说明该 Skill 的功能以及适用场景
---
具体Skill不在本章节做详细开发演示,后续真正进行业务开发再做详细开发流程演示。
SysOperation:安全可控的执行接口
在很多智能体架构里,模型一旦接入了工具,就有可能放开访问文件系统、运行代码、执行命令。openJiuwen 通过 SysOperation 屏蔽了这种风险。SysOperation 是一个系统操作抽象层,统一封装了 文件系统(FS)、代码执行(Code) 和 命令行(Shell) 三类能力,并通过一致的接口支持在 Local 与 Sandbox 模式之间无缝切换,使上层 Agent 与业务逻辑保持统一的调用方式。SysOperation 提供的是受控的文件系统访问、受控的代码执行环境和受控的 Shell 命令执行能力。所有这些不是直接暴露给模型,而是通过一个统一的、受控的接口层来调度执行。
这样做的好处是执行权限可审计、越权操作可被禁止和每次命令调用都有日志留痕。对合规审查这类“要操作真实文件、要执行脚本、要做文件解析”的场景来说,这是个刚需。
总的来说openJiuwen不是让模型更聪明,而是让模型的输出和行为都“有据可查、有法可依、有控可管”。这正是我们在构建“招标文件自身合规审查系统”时最需要的基础能力。在接下来的章节里,我们会逐步拆解:
- Skills 目录如何设计
- 规则如何写成机器可读 + 可执行资产
- 合规审查流程如何拆成可组合能力
- 最终如何让 Agent 在受控环境产生可复现报告
如果你和我一样,不满足于“模型会回答”,而是希望:
把 Agent 从实验 Demo,变成真实可交付的系统,
那这一套工程化思路,会比你想象的更重要。
第二章|构建合规审查智能体的核心能力:Skills & SysOperation
在上一章我们说了一个工程现实:
聊天式的大模型可以“说得很好”,但它不能代替真正的业务执行系统。
那怎么才能让一个智能体在真实工程场景中完成文件解析、规则执行、报告生成、流程串联这样的工作?
答案是:
把业务能力与系统操作明确划分,并以工程化方式注入智能体中。
而 openJiuwen 提供的核心机制,就分别解决了这两个问题:
- Skills → 业务能力边界化
- SysOperation → 可控执行能力
我们接下来逐层拆解它们的角色、协同方式以及对你的招标合规审查系统的工程价值。
2.1 Skills 是什么?不是 Prompt,是工程级“能力资产”
回顾许多智能体应用失败的原因:
| 问题 | 产生根源 |
|---|---|
| 规则写死在 Prompt 里 | Prompt 难以版本控制、审计 |
| 修改规则只能改 Prompt | 不同 Skill 之间难共享 |
| 决策逻辑很难追踪 | 模型行为不可解释 |
这其实暴露了一个核心问题:
Prompt 只是“上下文强化”,不是“规则定义”。
实体化能力定义机制Skills,核心思想是:
把智能体的业务规则、业务说明、能力边界写成可管理的文件,并让 Agent 在推理环节自动理解与组合使用。
这与过去把 Prompt 当规则库的做法本质不同。一个 Skill 在工程目录中代表一块“业务能力包”:
skills_root/
├─ 文件解析/
│ ├─ Skill.md
│ ├─ examples/
│ └─ scripts/
├─ 实质性条款识别/
│ ├─ Skill.md
│ └─ rules/
…
每个技能目录中必须包含一个 Skill.md,这个文件并不是普通说明文档,它将在 Agent 的提示词中被注入,告诉模型这是什么能力、能处理什么类型的输入、能产出什么结构化结果、是否有示例供调用参考。这样,模型在推理过程中不仅“理解文本”,还能“根据 Skill 描述选择能力”。
2.2 Skills 在合规审查系统中的具体模块划分
为了让招标文件审查能力可复用、可组合、可演进,我们把业务能力拆成以下几个 Skills:
| 技能模块 | 主要职责 | 典型输出 |
|---|---|---|
| 文件接入与结构化 | 文件解析 | 结构化 JSON / 文本 |
| 实质性条款识别 | 抽取废标/否决条款 | 条款列表 |
| 资格条件审查 | 检查主体资格与资质 | 审核清单 |
| 技术参数合规 | 参数是否明确与限制 | 偏离提示 |
| 合同条款风险评估 | 指定风险条款库扫描 | 风险条目 |
| 审查结果输出 | 生成审查报告模板 | Markdown/JSON 报告 |
这种拆分策略本质上是一种 领域分解,让每个 Skill 只专注一块业务能力。
2.2.1 Skill.md 的结构与规范示例
一个规范的 Skill.md 通常包含如下模块:
---
name: 技能名称
description: 该技能的能力描述和使用场景
---
## 输入定义
说明 Skill 需要的输入是什么
## 判定逻辑
说明规则如何执行、如何判定状态
## 输出格式
说明返回结果的结构和字段含义
## 典型示例
给出一个或多个输入 → 输出示例对照
举个通用示例(非完整业务):
---
name: pdf-text-extraction
description: 从 PDF 文件中提取纯文本内容,支持 OCR 和结构识别
---
## 输入
- file_path: PDF 文件路径
## 方法说明
使用 pdfplumber 提取文本,OCR 情况下触发 Tesseract
## 输出
{
"text": "<字符串>"
}
## 示例
输入: ./招标文件.pdf
输出: "这是解析后的文本 ..."
注意这里的要点:
- 输出是结构化的,而不是自然语言
- 示例不仅说明能力,还让 Agent 理解“如何匹配”
2.3 SysOperation:让 Agent “可执行”,而不是“空穴来风”
在传统的智能体架构里,模型的能力停留在“推理和语言理解”层面,不能真正执行外部系统操作。
如果让模型不受约束地访问操作系统,结果无法追踪审计而且有安全风险。openJiuwen 的解决方案是:
通过 SysOperation 抽象层把可执行操作封装起来,并只暴露必要的受控能力给 Agent 使用。
2.3.1 SysOperation 提供的三类受控能力
SysOperation 把系统能力抽象成三个主要操作类:
| 操作类型 | 内部调用 | 用途 |
|---|---|---|
sys_op.fs() |
受控文件读写 | 读取、写入、遍历目录 |
sys_op.code() |
受控代码执行 | 执行规则引擎代码、调用 Python 脚本 |
sys_op.shell() |
受控命令执行 | 解压、OCR、第三方工具执行 |
它不是简单给模型执行系统命令,而是通过一个受控层来调度,这也符合企业生产规范要求。
2.4 为什么受控执行能力对合规审查至关重要?
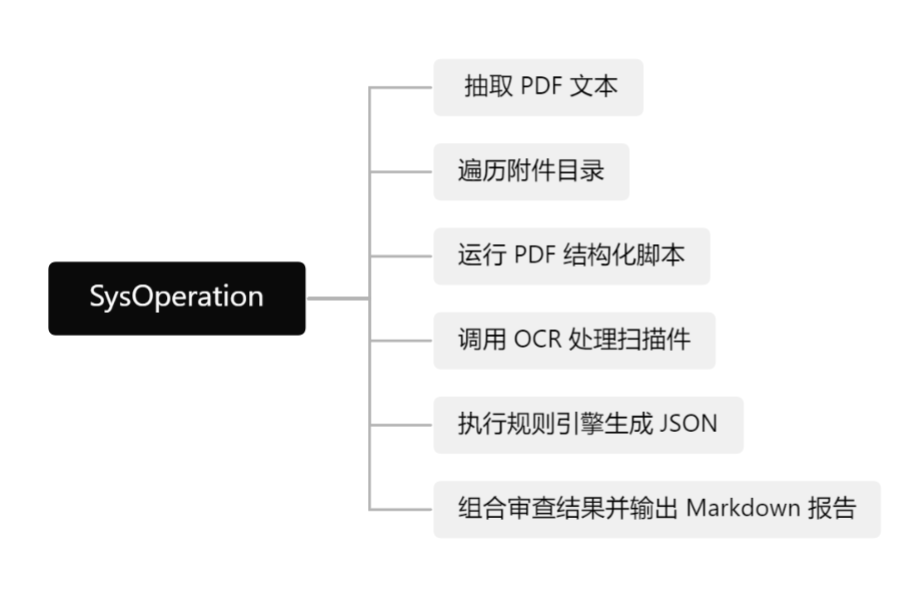
在合规审查场景中,智能体会遇到诸如:抽取 PDF 文本、遍历附件目录、运行 PDF 结构化脚本、调用 OCR 处理扫描件、执行规则引擎生成 JSON、组合审查结果并输出 Markdown 报告等,这些都不是大模型单纯的语言输出,而是对操作系统与文件系统的具体操作。
2.5 Skills + SysOperation:能力上线的协同模式
把上下两块拼接起来就能看到完整的运行逻辑:
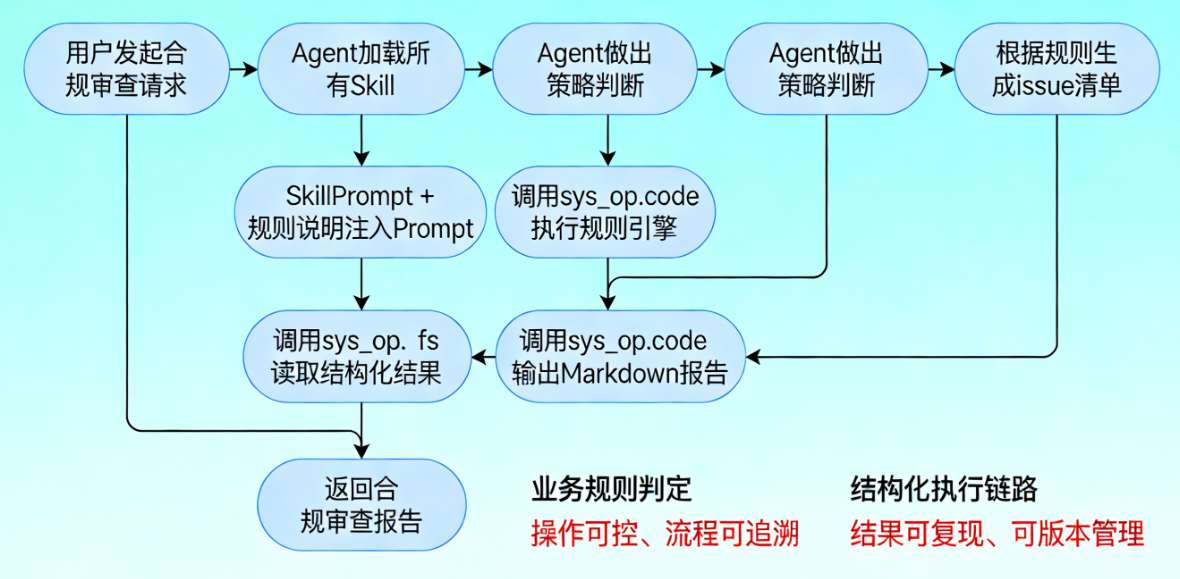
openJiuwen 的 Skills + SysOperation 恰好提供了这个能力边界:
- Skill = 业务知识与能力描述
- SysOperation = 受控操作执行层
这让 Agent 不再是“会说话的模型”,而是真正具备**可验证、可追踪的业务执行能力的智能体。
第三章|从通用 Agent 到招标文件合规审查 Skill 工程模板
本章节给出一套“可直接落盘”的招标文件合规审查 Skills 工程模板:
以 openJiuwen 的 Skills/SysOperation 思路为基座,围绕“文件接入→结构化→规则匹配→报告生成”形成可复现链路。
模板包含:完整 skills_root/ 工程结构、7 个 Skill 的 Skill.md(可复制粘贴)、YAML 规则规范与 10+ 条真实业务规则示例、最小可运行 Python 规则引擎、Agent 挂载与调用链(含 sys_op 调用参数示例)、报告模板与端到端测试步骤。
在工程边界上强调:工作目录白名单、Shell 白名单、Python 执行限制、日志与 session_id 审计链设计,确保“可控、可审计、可复现”。
未明确的环境参数在报告中统一标注为“未指定”,并给出默认可跑配置与可替换点。
3.1执行环境与前提
| 项 | 建议/约定 | 备注 |
|---|---|---|
| 操作系统 | Windows/Linux | openJiuwen Core 兼容 Windows/Linux/macOS。 |
| openJiuwen Core 版本 | 建议:openjiuwen==0.1.7(PyPI 最新之一) |
PyPI 显示 0.1.7 发布于 2026-02-14;Python 版本要求见下一行。 |
| Python 版本 | 建议:3.11.4+(未指定 patch) |
PyPI 约束:>=3.11,<3.14,并建议 3.11.4。 |
| LLM Provider/API | 自由选择 | openJiuwen Core 支持通过环境变量配置模型调用 |
| Runner 运行方式 | 建议本地开发 local;生产用 sandbox | openJiuwen 强项是“高可靠执行+状态管理+可恢复”,适合把审查流程做成可复现链路。 |
sys_operation_id |
约定:default_sys_op |
若你工程里 Runner 资源管理器已注册其它 id,请替换。 |
| 工作目录约定 | 约定:<WORKDIR>/projects/<project_id>/ |
所有文件读写、解析产物、报告输出都落在这里,便于审计与权限控制。 |
| 文件命名约定 | tender.pdf(招标文件主文档)+ 可选 clarification.pdf(澄清)+ attachments/(附件解压目录) |
你可以扩展更多输入,但这三个能覆盖 80% 实战。 |
| FS 白名单 | 仅允许访问 <WORKDIR>/projects/<project_id>/ 内部 |
禁止访问上级目录与系统盘根。 |
| Shell 白名单 | 建议仅允许:ls/dir, cat/type, python, unzip, 7z, pdftotext(可选) |
避免 curl/wget, rm -rf 等风险命令。 |
| Python 执行限制 | 超时、内存限制、禁网(未指定具体实现) | 建议在 sandbox 或 runner 层实现。 |
依赖库清单与安装命令
openJiuwen 本身会携带一批依赖(例如 pdfplumber 等在某些构建渠道可见),但为了“模板落地可控”,这里把需要显式确保安装的依赖列出来。
pip install -U \
openjiuwen==0.1.7 \
pyyaml==6.* \
pdfplumber==0.* \
pdfminer.six==2024.* \
pytesseract==0.3.* \
pillow==10.* \
jinja2==3.* \
rich==13.*
说明与依据:
openjiuwen:框架本体(PyPI)pdfplumber:可按页抽取文本、表格、对象信息;核心 API(Page.extract_text等)在官方仓库文档中明确。pdfminer.six:PDF 文本/布局抽取底座之一;其官方文档明确用途是抽取 PDF 信息。pytesseract:Python OCR 包装器;其 PyPI 说明就是“识别图片中的文字”。tesseract(系统软件,非 pip):OCR 引擎本体;官方文档说明其为开源 OCR 引擎并支持多语言。pyyaml:规则文件加载;官方文档强调safe_load的安全语义,适合加载不完全可信 YAML。jinja2:报告模板渲染(工程上比手写拼接更稳)。rich:CLI 日志更清晰(可选,但强烈建议做 demo 与测试断言时使用)。
若你要启用扫描版 PDF 的 OCR 兜底:需要系统安装 tesseract 可执行程序,并确保 pytesseract 能找到它。官方文档明确了 Tesseract 的安装与使用方式(不同 OS 安装方式不同)。
3.2Skills 工程目录结构
模块关系与行为链流程图:

Agent 行为链:
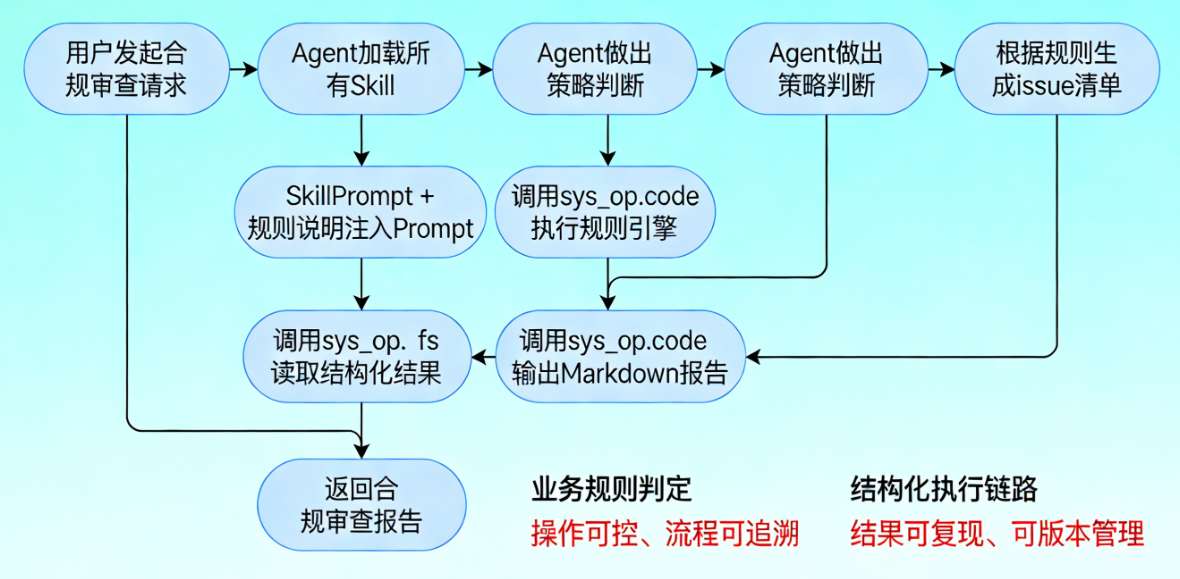
3.3 完整 skills_root/ 目录结构表
openJiuwen 的 Skills 扫描机制在你前文引用中采用 Skill.md(不是 SKILL.md)。为避免“跑不起来”,本模板统一使用 Skill.md 命名;如果你想兼容其它生态(例如通用 Agent Skills 规范),可额外复制一份 SKILL.md。
| 子目录 | 目的 | 必备文件 | 示例文件名 |
|---|---|---|---|
tender_intake/ |
项目接入、文件校验、生成 manifest、审计元数据 | Skill.md、scripts/intake_check.py、templates/project_manifest.schema.json |
examples/manifest_example.json |
tender_structure_parse/ |
PDF/附件解析成结构化 tender.json(页、章节、锚点) |
Skill.md、scripts/parse_tender_pdf.py |
examples/tender_json_example.json |
compliance_mandatory_items/ |
扫描“废标/否决/必须响应”等强规则;输出 issue_list.json |
Skill.md、rules/disqualify_rules.yml、scripts/run_rules_engine.py |
examples/issue_list_example.json |
qualification_check/ |
扫描资格条件限制(地域、资质等级、注册资本、业绩门槛等) | Skill.md、rules/qualification_rules.yml |
examples/qualification_issues.json |
technical_spec_match/ |
扫描技术参数公平性/可比性风险(品牌指向、型号锁定、排他性描述) | Skill.md、rules/technical_rules.yml |
examples/technical_issues.json |
contract_terms_risk/ |
扫描合同条款风险(付款、验收、违约责任是否失衡/不清晰) | Skill.md、rules/contract_risk_rules.yml |
examples/contract_issues.json |
report_generator/ |
合并 issue 清单并渲染最终 Markdown 报告 | Skill.md、templates/compliance_report.md.j2、scripts/render_report.py |
examples/final_report_example.md |
项目交付 checklist:
| 文件路径 | 用途 | 是否必须 | 示例/模板 |
|---|---|---|---|
skills_root/tender_intake/Skill.md |
intake 技能说明与输入输出约定 | 是 | 模板见下文 |
skills_root/tender_intake/scripts/intake_check.py |
校验项目目录、生成 manifest | 是 | 可运行 |
skills_root/tender_intake/templates/project_manifest.schema.json |
manifest 结构约束(可选用于校验) | 否 | 模板 |
skills_root/tender_structure_parse/Skill.md |
parsing 技能说明 | 是 | 模板 |
skills_root/tender_structure_parse/scripts/parse_tender_pdf.py |
PDF→tender.json(含 OCR 兜底开关) | 是 | 可运行 |
skills_root/compliance_mandatory_items/Skill.md |
强规则审查技能说明 | 是 | 模板 |
skills_root/compliance_mandatory_items/rules/disqualify_rules.yml |
10+ 条规则示例 | 是 | 可运行 |
skills_root/compliance_mandatory_items/scripts/run_rules_engine.py |
最小规则引擎(生成 issue_list.json) | 是 | 可运行 |
skills_root/qualification_check/Skill.md |
资格审查技能说明 | 是 | 模板 |
skills_root/qualification_check/rules/qualification_rules.yml |
资格限制规则 | 是 | 示例 |
skills_root/technical_spec_match/Skill.md |
技术风险技能说明 | 是 | 模板 |
skills_root/technical_spec_match/rules/technical_rules.yml |
技术风险规则 | 是 | 示例 |
skills_root/contract_terms_risk/Skill.md |
合同风险技能说明 | 是 | 模板 |
skills_root/contract_terms_risk/rules/contract_risk_rules.yml |
合同风险规则 | 是 | 示例 |
skills_root/report_generator/Skill.md |
报告生成技能说明 | 是 | 模板 |
skills_root/report_generator/templates/compliance_report.md.j2 |
Markdown 报告模板 | 是 | 可运行 |
skills_root/report_generator/scripts/render_report.py |
将 issue_list 渲染为报告 | 是 | 可运行 |
sample_project/… |
端到端测试用样例项目目录 | 否(强烈建议) | 结构见下文 |
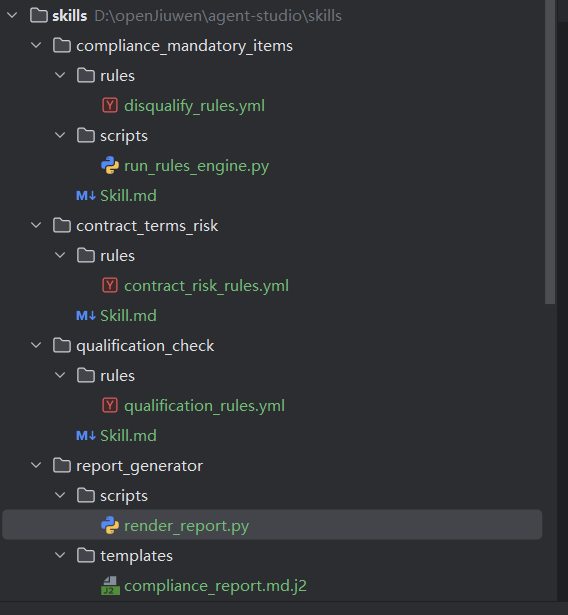
3.4 项目具体Skill.md
每个 Skill 的 Skill.md 都包含 front-matter + 目标 + 输入/输出 + 判定逻辑 + 示例 + rules 引用说明。可按行业(工程/医疗/政采等)逐步替换规则库。
3.4.1tender_intake 的 Skill.md
---
name: tender_intake
description: 招标文件合规审查的项目接入与材料完整性检查。核验项目目录结构、输入文件命名、生成审计用 manifest(hash/时间戳/操作者/session_id),为后续解析与规则审查提供稳定输入。
---
# tender_intake(项目接入与材料校验)
## 目标
- 校验工作目录是否满足约定结构(tender.pdf、可选 clarification.pdf、可选 attachments/)。
- 生成 `project_manifest.json`,记录:
- project_id、session_id
- 文件清单、文件大小、hash(SHA256)
- 执行时间戳、脚本版本
- 发现缺失或命名不规范时输出问题清单(仍可继续,但要在报告里标注“输入不完整”)。
## 输入
- project_dir: str(项目目录,例如 `<WORKDIR>/projects/<project_id>/`)
- session_id: str(建议格式见本 Skill 底部“审计建议”)
- required_files: list[str](默认:["tender.pdf"])
## 输出
- project_manifest_path: str(`<project_dir>/audit/project_manifest.json`)
- intake_issues: list[dict](若发现缺失/命名不规范/空文件等)
### intake_issues schema
```json
[
{
"severity": "HIGH|MEDIUM|LOW",
"category": "输入完整性",
"rule_key": "INTAKE_MISSING_TENDER_PDF",
"evidence": "缺失 tender.pdf",
"suggestion": "请将招标文件主文档重命名为 tender.pdf 并放入项目根目录"
}
]
判定逻辑:
- 必须存在 tender.pdf(否则 HIGH)。
- clarification.pdf 若存在则纳入解析;不存在不报错。
- attachments/ 目录若为空或不存在,不影响解析,但提示 MEDIUM(因为很多招标文件把关键表格放附件)。
- 生成 manifest 时对每个文件计算 SHA256,用于后续审计与复现。
示例
- 输入:project_dir=/workdir/projects/2026-001/
- 输出:/workdir/projects/2026-001/audit/project_manifest.json
3.4.2 tender_structure_parse
- scripts/intake_check.py:执行校验与 manifest 生成
- templates/project_manifest.schema.json:manifest 的 schema(可用于 jsonschema 校验,非必须)
### tender_structure_parse 的 Skill.md
```markdown
---
name: tender_structure_parse
description: 将招标PDF(及澄清PDF)解析为结构化 tender.json(页文本+章节锚点+目录候选),为后续规则引擎提供稳定输入。支持“文本PDF优先,扫描PDF走OCR兜底(可选)”。
---
# tender_structure_parse(招标文件结构化解析)
## 目标
- 从 tender.pdf / clarification.pdf 提取每页文本,保存为 `tender.json`:
- pages: [{page_no, text, text_source}]
- sections: [{id, title, level, page_start, page_end, text}]
- 解析失败时保留可诊断信息(例如某页为空、OCR 未配置)。
## 输入
- project_dir: str
- tender_pdf: str(默认 `<project_dir>/tender.pdf`)
- clarification_pdf: str(可选)
- enable_ocr: bool(默认 false;扫描件可打开)
- ocr_lang: str(默认 chi_sim;未指定可留空)
## 输出
- tender_json_path: str(默认 `<project_dir>/artifacts/tender.json`)
- tender_text_path: str(默认 `<project_dir>/artifacts/tender_fulltext.txt`)
- parse_log_path: str(默认 `<project_dir>/audit/parse.log`)
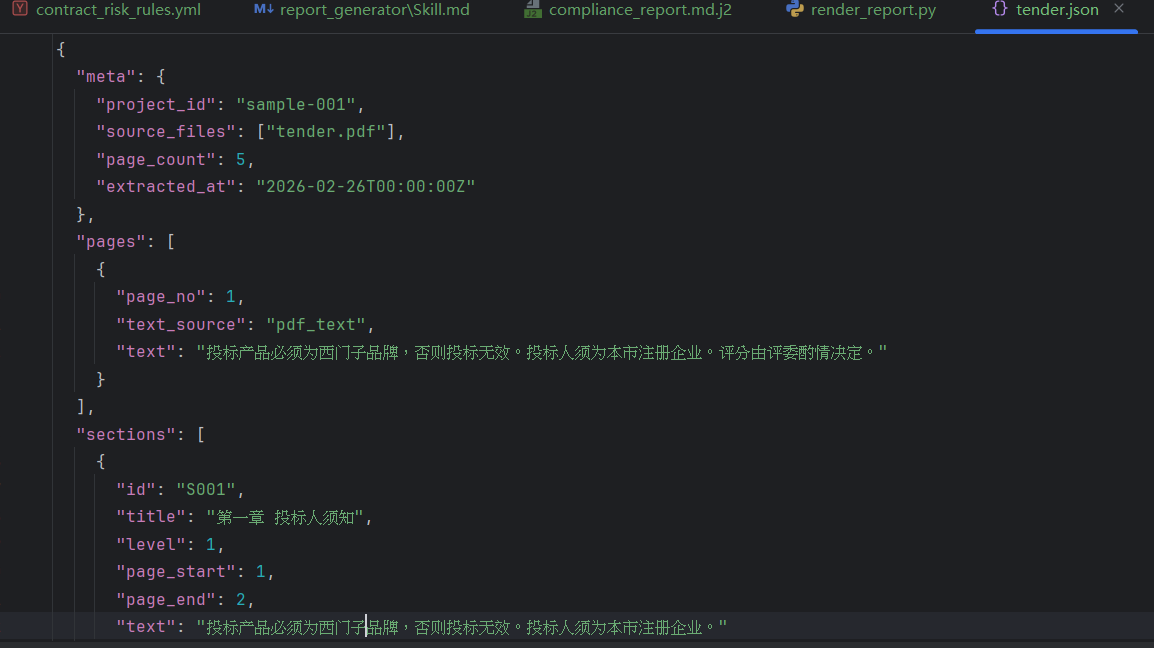
## tender.json 最小约定(下游规则引擎依赖)
```json
{
"meta": {
"project_id": "string",
"source_files": ["tender.pdf", "clarification.pdf"],
"page_count": 123,
"extracted_at": "ISO8601"
},
"pages": [
{"page_no": 1, "text": "…", "text_source": "pdf_text|ocr"}
],
"sections": [
{"id": "S001", "title": "第一章 投标人须知", "level": 1, "page_start": 3, "page_end": 10, "text": "…"}
]
}
判定逻辑(实战取舍)
- 优先使用 pdfplumber 提取文本;其 Page.extract_text 等 API 能直接得到页文本。参考官方仓库文档。
- 当页面文本为空且 enable_ocr=true:将 page.to_image() 转图片交给 pytesseract 识别(前提:系统已安装 Tesseract)。
- 章节切分采用简单启发式(regex):
- 识别“第X章/第X节/一、二、三、”等标题行
- 将标题后连续文本归入同一 section
- 不追求 100% 精准,追求“可跑 + 可迭代”
示例
- 输入:/workdir/projects/2026-001/tender.pdf
- 输出:/workdir/projects/2026-001/artifacts/tender.json
3.4.3 compliance_mandatory_items
scripts/parse_tender_pdf.py:实现上述解析与输出
(关于 PDF 抽取库的依据:`pdfplumber` 文档明确提供 `extract_text` / `extract_words` 等方法;并说明其对象派生自 `pdfminer.six`。citeturn21view1turn21view0
`pdfminer.six` 官方文档同样明确其用途是从 PDF 抽取信息。citeturn12search2turn12search14
OCR 部分:`pytesseract` 是 Python OCR 包装器;Tesseract 是 OCR 引擎本体。citeturn12search0turn12search1turn12search5)
### compliance_mandatory_items 的 Skill.md
```markdown
---
name: compliance_mandatory_items
description: 扫描招标文件中的“废标/否决/必须响应/关键时点与提交项”条款,输出结构化 issue_list.json(含证据引用、触发规则、建议)。适合作为招标文件自身合规审查的强规则层。
---
# compliance_mandatory_items(强规则与必须响应项审查)
## 目标
- 从 tender.json 中识别:
- 明示的废标/否决条款
- 必须提交材料/盖章签字/密封要求
- 投标保证金、投标有效期、递交截止时间等关键约束
- 输出 issue_list.json,作为总报告的核心输入之一。
## 输入
- tender_json_path: str(`<project_dir>/artifacts/tender.json`)
- rules_path: str(默认 `rules/disqualify_rules.yml`)
- output_path: str(默认 `<project_dir>/artifacts/issue_list.json`)
## 输出
- issue_list.json(结构见下)
- audit_log(规则命中日志、异常堆栈)
### issue_list.json schema(下游 report_generator 依赖)
```json
[
{
"severity": "HIGH|MEDIUM|LOW",
"category": "废标项|响应文件|报价|评分办法|技术条款|合同条款|资格条件",
"rule_key": "string",
"clause_ref": "章节/条款/页码/section_id",
"evidence": "原文摘录(<=200字)",
"explanation": "为什么这是风险/需要关注的点",
"suggestion": "整改建议/澄清建议/改写建议",
"matched": {
"match_type": "keyword|regex|struct_field",
"pattern": "…",
"hit": "命中的文本片段"
}
}
]
判定逻辑
- 规则引擎逐条加载
rules/disqualify_rules.yml:- match_type=keyword:全文包含关键词即可命中
- match_type=regex:正则命中即可命中
- match_type=struct_field:限定在 section.title 或 section.text 中命中(更精准)
- 每条命中必须输出:rule_key、severity、证据摘录、建议。
- 证据摘录优先来自 sections(带章节引用),若无法定位则退化为全文位置附近片段。
示例
- tender.json 含“必须加盖公章,否则投标无效” → 输出 HIGH 风险 issue
rules
- rules/disqualify_rules.yml:强规则库
3.4.4qualification_check
scripts/run_rules_engine.py:最小规则引擎实现(可 CLI 跑,也可被 execute_python_code 调用)
### qualification_check 的 Skill.md
```markdown
---
name: qualification_check
description: 扫描招标文件中的资格条件设置是否存在不合理限制(地域限制、注册资本门槛、资质等级过高、业绩门槛排他、强制原厂授权等),输出结构化 issue,供总报告合并。
---
# qualification_check(资格条件与限制性条款扫描)
## 目标
- 识别“可能构成限制竞争/不合理门槛”的资格条件表述
- 输出 issue_list 的追加条目(建议 category=资格条件)
## 输入
- tender_json_path: str
- rules_path: str(默认 rules/qualification_rules.yml)
- output_append_path: str(默认 `<project_dir>/artifacts/issue_list.json`,以追加方式合并)
## 输出
- 追加到 issue_list.json 的条目(同 compliance_mandatory_items schema)
## 判定逻辑
- 以“风险提示”为主,不直接给法律结论(避免过度承诺)
- 对以下类型提高敏感度:
- 地域/本地化限制
- 注册资本/成立年限硬门槛
- 业绩门槛只允许“同品牌/同型号/同系统”
- 强制原厂授权但不给替代机制
## 示例
- “投标人须为本市注册企业” → HIGH(地域限制风险)
## rules
- rules/qualification_rules.yml(模板包含示例)
3.4.5 technical_spec_match 的 Skill.md
---
name: technical_spec_match
description: 扫描招标文件技术参数条款的公平性与可比性风险,包括品牌/型号指向、排他性用语、参数不可验证或缺乏验收口径等。
---
# technical_spec_match(技术条款风险扫描)
## 目标
- 识别技术参数中的品牌/型号锁定、排他性描述、缺乏“或同等”机制等风险
- 输出 issue(category=技术条款)
## 输入
- tender_json_path: str
- rules_path: str(默认 rules/technical_rules.yml)
## 输出
- issue_list.json 追加条目
## 判定逻辑
- 以 section 为单位扫描“技术规格/技术参数/技术要求/配置清单”等章节
- 优先 struct_field(title 过滤)减少误报
- 若发现品牌/型号/唯一供应商指向,severity 提升
## rules
- rules/technical_rules.yml(模板包含示例)
3.4.6 contract_terms_risk 的 Skill.md
---
name: contract_terms_risk
description: 扫描合同条款中的风险点(付款条件不清、验收口径缺失、违约责任失衡、过高罚则、单方解释权等),输出结构化 issue 供报告汇总。
---
# contract_terms_risk(合同条款风险扫描)
## 目标
- 对“合同主要条款”章节做风险要点提示
- 输出 issue(category=合同条款)
## 输入
- tender_json_path: str
- rules_path: str(默认 rules/contract_risk_rules.yml)
## 输出
- issue_list.json 追加条目
## 判定逻辑
- 规则更多是“风险提示”而非“违规认定”
- 输出建议以“补充澄清/明确口径/对等化条款”为主
## rules
- rules/contract_risk_rules.yml(模板包含示例)
3.4.7 report_generator 的 Skill.md
---
name: report_generator
description: 将 issue_list.json 渲染为可归档的 Markdown 审查报告(compliance_report.md),包含审查结论、问题清单、证据引用、风险分级与建议。
---
# report_generator(审查报告生成)
## 目标
- 合并各技能输出的 issue_list.json
- 生成最终 `compliance_report.md`(可直接交付/归档)
## 输入
- project_manifest.json(可选,用于报告头部信息)
- tender_json_path(可选,用于统计页数/章节)
- issue_list.json(必须)
- 模板:templates/compliance_report.md.j2
## 输出
- `<project_dir>/output/compliance_report.md`
## 判定逻辑
- 统计 HIGH/MEDIUM/LOW 数量作为“结论摘要”
- 对每条 issue 输出:
- rule_key + category + severity
- clause_ref(章节/页码/section_id)
- evidence(<=200字)
- suggestion(明确下一步动作)
## scripts / templates
- scripts/render_report.py:读取 issue_list.json 渲染模板
- templates/compliance_report.md.j2:Jinja2 模板
3.5 规则体系与最小规则引擎实现
3.5.1 rules/*.yml 规范
规则文件基于 YAML,建议坚持以下字段(这是“工程化规则库”的底盘):
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
rule_key |
str | 是 | 全局唯一键,建议全大写+下划线 |
severity |
str | 是 | HIGH/MEDIUM/LOW |
category |
str | 是 | 输出分类(资格条件/技术条款/合同条款/废标项等) |
match_type |
str | 是 | keyword/regex/struct_field |
pattern |
str 或 dict | 是 | keyword/regex 用字符串;struct_field 用 dict 更清晰 |
explanation |
str | 是 | 命中含义 |
suggestion |
str | 是 | 建议动作(改写/澄清/补充/删除等) |
关于 YAML 加载:建议使用 yaml.safe_load,官方文档和 deprecation 说明都强调其安全属性,适合处理不完全可信输入。
3.6 业务规则示例
下面给出 skills_root/compliance_mandatory_items/rules/disqualify_rules.yml(含 12 条示例)。这些规则聚焦“招标文件自身合规审查”常见高风险点:品牌型号指向、地域限制、强制原厂授权、资格门槛失衡、关键条款模糊等。
# rules/disqualify_rules.yml
rules:
- rule_key: BRAND_SPECIFIED_ONLY
severity: HIGH
category: 技术条款
match_type: regex
pattern: "(指定品牌|必须为.*品牌|仅限.*品牌|推荐品牌为)"
explanation: "技术要求出现品牌指向性表述,可能导致竞争受限,应评估是否需改为性能/指标描述或提供“或同等”机制。"
suggestion: "将品牌描述改为可验证的性能指标;如必须引用品牌作为参考,增加“或同等/不低于”并给出等同性判定口径。"
- rule_key: MODEL_LOCK_IN
severity: HIGH
category: 技术条款
match_type: regex
pattern: "(型号[:: ]*(必须为|限定为|仅限)?\\s*[A-Za-z0-9\\-]{3,})"
explanation: "出现疑似型号锁定(或以型号限制),易构成排他性技术条款。"
suggestion: "删除具体型号;改为关键性能参数/接口协议/验收指标;必要时补充等同性说明。"
- rule_key: SOLE_SUPPLIER_HINT
severity: HIGH
category: 技术条款
match_type: keyword
pattern: "唯一供应商"
explanation: "文本出现“唯一供应商”等表述,提示可能存在单一来源倾向或竞争限制风险。"
suggestion: "核查采购方式与合规依据;如确属单一来源,补充合规说明与论证材料;否则删除该表述。"
- rule_key: LOCAL_VENDOR_RESTRICTION
severity: HIGH
category: 资格条件
match_type: regex
pattern: "(本市|本地|当地|限.*市|限.*省|限在.*注册|本区域内)"
explanation: "存在地域/本地化限制的文字信号,可能构成不合理门槛。"
suggestion: "删除地域限制;若确有服务响应时效要求,改为“响应时效/驻场能力/服务网点能力”的可验证指标。"
- rule_key: REGISTERED_CAPITAL_THRESHOLD
severity: MEDIUM
category: 资格条件
match_type: regex
pattern: "(注册资本|实缴资本).*(不少于|不低于|≥|大于等于)\\s*\\d+\\s*(万|万元|亿|亿元)"
explanation: "注册资本门槛可能造成中小企业排除,应评估是否与项目规模/风险控制必要性匹配。"
suggestion: "将资本门槛改为更直接的履约能力指标(财务报表、信用、履约担保等),或降低门槛并提供替代证明路径。"
- rule_key: YEARS_IN_BUSINESS_REQUIREMENT
severity: MEDIUM
category: 资格条件
match_type: regex
pattern: "(成立|经营)\\s*(满|不少于|不低于)\\s*\\d+\\s*年"
explanation: "成立年限硬门槛可能不合理,需评估与履约能力的直接关联性。"
suggestion: "改为“同类项目经验/项目团队资历/服务能力证明”等可替代条件。"
- rule_key: ORIGINAL_MANUFACTURER_AUTH_REQUIRED
severity: HIGH
category: 资格条件
match_type: regex
pattern: "(原厂授权|厂家授权函|制造商授权|原厂出具授权)"
explanation: "强制原厂授权可能形成排他性门槛,尤其在多级经销体系下会显著收窄竞争。"
suggestion: "若确需授权,明确可替代路径(例如供货承诺、售后能力证明、代理资质),并说明授权与质保的对应关系。"
- rule_key: BID_BOND_MENTION
severity: LOW
category: 废标项
match_type: keyword
pattern: "投标保证金"
explanation: "出现投标保证金条款提示:后续需要检查金额、缴纳方式、退还条件是否表述清晰(否则易引发争议)。"
suggestion: "在后续审查中确认金额、缴纳方式、到账截止、退还条件是否明确;必要时补充说明。"
- rule_key: SEAL_SIGNATURE_MANDATORY
severity: HIGH
category: 响应文件
match_type: regex
pattern: "(加盖公章|盖章|签字).*?(否则|不满足|视为).*?(无效|废标|否决)"
explanation: "盖章/签字与否决后果绑定,属于典型强制响应项。招标文件自身审查需确认位置、范围、例外情形表述清晰。"
suggestion: "明确需盖章/签字的具体文件列表与位置;避免“所有页均需盖章”这类模糊或过度要求。"
- rule_key: ENVELOPE_SEALING_STRICT
severity: MEDIUM
category: 响应文件
match_type: regex
pattern: "(密封|封口|骑缝章|不按要求密封).*?(废标|无效|否决)"
explanation: "密封要求与否决绑定,需确保表述可执行、无歧义,否则后续易产生争议。"
suggestion: "补充示意或明确密封方式、封口位置、数量;对电子投标场景给出等效要求。"
- rule_key: DEADLINE_STRICT
severity: MEDIUM
category: 废标项
match_type: regex
pattern: "(递交截止|投标截止|开标时间).*?(北京时间|\\d{4}[-年]\\d{1,2}[-月]\\d{1,2}日?\\s*\\d{1,2}:\\d{2})"
explanation: "截止时间属于关键约束项,建议核对是否与公告/澄清一致,且是否说明迟到处理规则。"
suggestion: "核对与公告/澄清一致;明确迟到文件处理规则;避免出现多个冲突时间点。"
- rule_key: AMBIGUOUS_EVALUATION_LANGUAGE
severity: MEDIUM
category: 评分办法
match_type: regex
pattern: "(酌情|视情况|由评委决定|评委自行判断|综合考虑)"
explanation: "评分语言过于自由裁量,可能导致可解释性不足;建议补充量化标准或举例口径。"
suggestion: "增加量化评分标准、区间与举例;明确材料要求与评分对应关系。"
提醒:这些规则是“审查引擎的第一版启发式风险提示”,不是法律结论。真正落地时,应结合组织的招采制度、行业监管口径与历史争议案例迭代规则库(这也是 Skills 落盘的价值:规则可版本化迭代)。
3.7 最小可运行 Python 规则引擎脚本
文件路径建议:skills_root/compliance_mandatory_items/scripts/run_rules_engine.py
功能要求对齐清单:读取 tender_json、加载 rules.yml、匹配规则、生成 issue_list.json、日志与异常处理,并支持 CLI 运行,也便于被工具 execute_python_code 调用。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
run_rules_engine.py
最小可运行的招标文件合规审查规则引擎:
- 输入:tender.json + rules.yml
- 输出:issue_list.json
- 支持 keyword/regex/struct_field 三类匹配
- 日志可落盘,异常可追溯
"""
from __future__ import annotations
import argparse
import json
import logging
import re
import sys
from dataclasses import dataclass
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
import yaml # PyYAML
SEVERITY_ORDER = {"HIGH": 3, "MEDIUM": 2, "LOW": 1}
@dataclass
class Rule:
rule_key: str
severity: str
category: str
match_type: str # keyword | regex | struct_field
pattern: Any
explanation: str
suggestion: str
def setup_logger(log_path: Path) -> None:
log_path.parent.mkdir(parents=True, exist_ok=True)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s",
handlers=[
logging.FileHandler(log_path, encoding="utf-8"),
logging.StreamHandler(sys.stdout),
],
)
def load_tender_json(path: Path) -> Dict[str, Any]:
with path.open("r", encoding="utf-8") as f:
return json.load(f)
def load_rules(path: Path) -> List[Rule]:
with path.open("r", encoding="utf-8") as f:
# 安全加载:只解析标准 YAML 类型
data = yaml.safe_load(f)
if not isinstance(data, dict) or "rules" not in data:
raise ValueError(f"Invalid rules file: missing top-level 'rules' list: {path}")
rules: List[Rule] = []
for i, item in enumerate(data["rules"]):
if not isinstance(item, dict):
raise ValueError(f"Rule #{i} must be dict, got: {type(item)}")
rules.append(
Rule(
rule_key=str(item["rule_key"]),
severity=str(item["severity"]).upper(),
category=str(item.get("category", "未分类")),
match_type=str(item["match_type"]),
pattern=item["pattern"],
explanation=str(item.get("explanation", "")),
suggestion=str(item.get("suggestion", "")),
)
)
return rules
def build_fulltext(tender: Dict[str, Any]) -> str:
pages = tender.get("pages", [])
texts = []
for p in pages:
t = p.get("text") or ""
if t.strip():
texts.append(t)
if texts:
return "\n".join(texts)
# fallback: sections
sections = tender.get("sections", [])
texts = [(s.get("text") or "") for s in sections if (s.get("text") or "").strip()]
return "\n".join(texts)
def extract_snippet(text: str, hit_span: Tuple[int, int], radius: int = 80) -> str:
start, end = hit_span
left = max(0, start - radius)
right = min(len(text), end + radius)
snippet = text[left:right].replace("\n", " ").strip()
if len(snippet) > 200:
snippet = snippet[:200] + "…"
return snippet
def match_keyword(fulltext: str, keyword: str) -> Optional[Tuple[int, int, str]]:
idx = fulltext.find(keyword)
if idx < 0:
return None
return (idx, idx + len(keyword), keyword)
def match_regex(fulltext: str, pattern: str) -> Optional[Tuple[int, int, str]]:
m = re.search(pattern, fulltext, flags=re.IGNORECASE)
if not m:
return None
return (m.start(), m.end(), m.group(0))
def match_struct_field(tender: Dict[str, Any], spec: Dict[str, Any]) -> Optional[Tuple[str, Tuple[int, int], str]]:
"""
struct_field 匹配:在 sections 中定位,减少误报。
spec 示例:
{
"section_title_regex": "技术|参数|规格",
"text_regex": "指定品牌|必须为"
}
返回: (clause_ref, span_in_text, hit_text)
"""
title_re = spec.get("section_title_regex")
text_re = spec.get("text_regex")
if not title_re or not text_re:
return None
sections = tender.get("sections", [])
for s in sections:
title = s.get("title") or ""
if not re.search(title_re, title, flags=re.IGNORECASE):
continue
body = s.get("text") or ""
m = re.search(text_re, body, flags=re.IGNORECASE)
if not m:
continue
clause_ref = f"{s.get('id', 'UNKNOWN')} | {title} | p{s.get('page_start', '?')}-{s.get('page_end', '?')}"
return (clause_ref, (m.start(), m.end()), m.group(0))
return None
def build_issue(
rule: Rule,
clause_ref: str,
evidence: str,
hit_text: str,
) -> Dict[str, Any]:
return {
"severity": rule.severity,
"category": rule.category,
"rule_key": rule.rule_key,
"clause_ref": clause_ref,
"evidence": evidence,
"explanation": rule.explanation,
"suggestion": rule.suggestion,
"matched": {
"match_type": rule.match_type,
"pattern": rule.pattern,
"hit": hit_text,
},
}
def main(argv: Optional[List[str]] = None) -> int:
parser = argparse.ArgumentParser(description="Tender compliance rules engine")
parser.add_argument("--tender_json", required=True, help="Path to tender.json")
parser.add_argument("--rules", required=True, help="Path to rules.yml")
parser.add_argument("--output", required=True, help="Path to issue_list.json")
parser.add_argument("--log", required=False, help="Path to audit log file")
args = parser.parse_args(argv)
tender_json_path = Path(args.tender_json)
rules_path = Path(args.rules)
output_path = Path(args.output)
log_path = Path(args.log) if args.log else output_path.with_suffix(".log")
setup_logger(log_path)
try:
logging.info("Loading tender_json=%s", tender_json_path)
tender = load_tender_json(tender_json_path)
logging.info("Loading rules=%s", rules_path)
rules = load_rules(rules_path)
logging.info("Rules loaded: %d", len(rules))
fulltext = build_fulltext(tender)
if not fulltext.strip():
logging.warning("Tender fulltext is empty. Check PDF parsing / OCR settings.")
issues: List[Dict[str, Any]] = []
for rule in rules:
try:
clause_ref = "FULLTEXT"
hit = None
if rule.match_type == "keyword":
hit = match_keyword(fulltext, str(rule.pattern))
if hit:
span = (hit[0], hit[1])
evidence = extract_snippet(fulltext, span)
issues.append(build_issue(rule, clause_ref, evidence, hit[2]))
logging.info("HIT keyword rule=%s hit=%s", rule.rule_key, hit[2])
elif rule.match_type == "regex":
hit = match_regex(fulltext, str(rule.pattern))
if hit:
span = (hit[0], hit[1])
evidence = extract_snippet(fulltext, span)
issues.append(build_issue(rule, clause_ref, evidence, hit[2]))
logging.info("HIT regex rule=%s hit=%s", rule.rule_key, hit[2])
elif rule.match_type == "struct_field":
if not isinstance(rule.pattern, dict):
logging.warning("struct_field pattern must be dict, rule=%s", rule.rule_key)
continue
m = match_struct_field(tender, rule.pattern)
if m:
clause_ref, span, hit_text = m
# evidence 来自 section.text 的局部片段
# 为简单起见,这里用 section text 的 span 提取
# 若需更稳,可直接在 match_struct_field 返回 section_text
# 并在此处 extract_snippet(section_text, span)
issues.append(build_issue(rule, clause_ref, hit_text, hit_text))
logging.info("HIT struct_field rule=%s clause=%s", rule.rule_key, clause_ref)
else:
logging.warning("Unknown match_type=%s rule=%s", rule.match_type, rule.rule_key)
except Exception as e:
logging.exception("Rule processing failed: %s error=%s", rule.rule_key, e)
# 排序:HIGH > MEDIUM > LOW
issues.sort(key=lambda x: SEVERITY_ORDER.get(x.get("severity", "LOW"), 0), reverse=True)
output_path.parent.mkdir(parents=True, exist_ok=True)
payload = {
"generated_at": datetime.utcnow().isoformat() + "Z",
"tender_json": str(tender_json_path),
"rules": str(rules_path),
"issue_count": len(issues),
"issues": issues,
}
with output_path.open("w", encoding="utf-8") as f:
json.dump(payload, f, ensure_ascii=False, indent=2)
logging.info("Done. issues=%d output=%s", len(issues), output_path)
return 0
except Exception as e:
logging.exception("Engine failed: %s", e)
return 2
if __name__ == "__main__":
raise SystemExit(main())
3.7.1运行示例命令(CLI)
python skills_root/compliance_mandatory_items/scripts/run_rules_engine.py \
--tender_json sample_project/artifacts/tender.json \
--rules skills_root/compliance_mandatory_items/rules/disqualify_rules.yml \
--output sample_project/artifacts/issue_list.json \
--log sample_project/audit/rules_engine.log
第四章|openJiuwen 集成代码与 Agent 行为链
4.1 在 openJiuwen 中注册 skills 并挂载到 ReAct Agent
openJiuwen Core 包含多类 Agent(包括 ReActAgent/WorkflowAgent),工具调用与执行引擎能力。
import asyncio
from pathlib import Path
from datetime import datetime
from openjiuwen.core.skills import SkillUtil # 你前文引用的 Skills SDK 入口
BASE_SYSTEM_PROMPT = """你是一个招标文件合规审查智能体。
目标:对招标文件自身条款做风险识别与整改建议输出。
要求:所有结论必须引用证据(章节/页码/section_id)并给出建议动作。"""
def build_session_id(project_id: str, operator: str = "unknown") -> str:
# 审计友好:可按 SSO/工号体系替换 operator
ts = datetime.utcnow().strftime("%Y%m%dT%H%M%SZ")
return f"{project_id}__{operator}__{ts}"
async def setup_react_agent_with_skills(project_id: str, workdir: str):
project_dir = Path(workdir) / "projects" / project_id
skills_root = Path(workdir) / "skills_root"
session_id = build_session_id(project_id, operator="fanstuck")
sys_operation_id = "default_sys_op" # 约定 id;若你工程中不同请替换
agent = create_my_react_agent()
#初始化 SkillUtil,注册技能目录并挂载内置工具
skill_util = SkillUtil(sys_operation_id=sys_operation_id)
await skill_util.register_skills(
skill_path=str(skills_root),
agent=agent,
session_id=session_id,
)
skill_prompt = skill_util.get_skill_prompt()
agent.system_prompt = BASE_SYSTEM_PROMPT + "\n\n" + skill_prompt
agent.runtime_context = {"project_dir": str(project_dir), "session_id": session_id}
return agent
这里要注意把 session_id 做成 project_id__operator__timestamp,审计时能从日志一眼定位“谁、在什么项目、什么时候做的审查”,并可用它做日志分桶与追踪 id(后文“安全与审计建议”会展开)。
4.2 Agent 行为链与 sys_op 调用参数
4.2.1 步骤化行为链
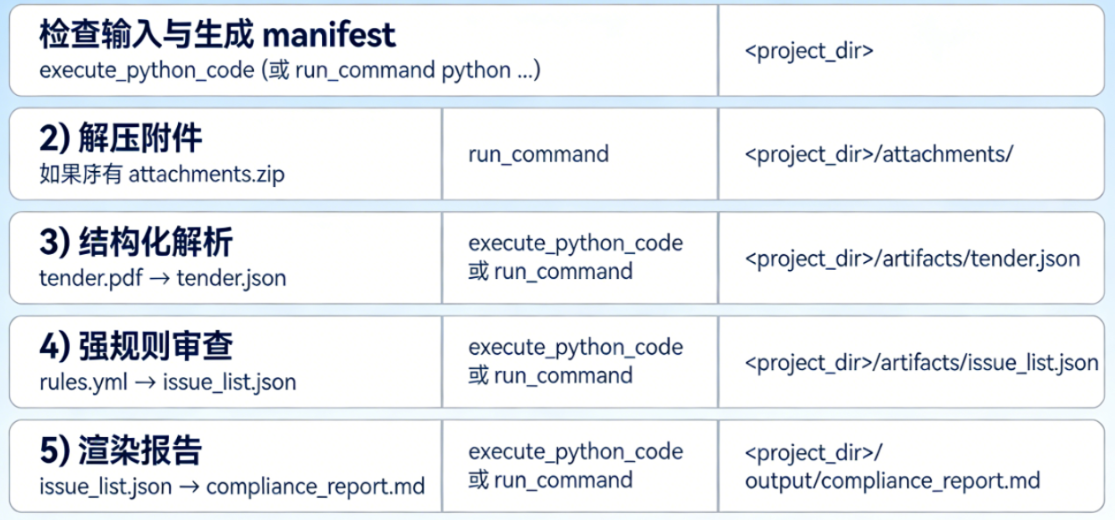
4.2.2对应工具调用
以下是“Agent 调用工具”时常见的参数形态
run_command:解压附件*
{
"bash_command": "cd /workdir/projects/2026-001 && unzip -o attachments.zip -d attachments"
}
execute_python_code:运行解析脚本(简化示例)
{
"code_block": "import subprocess\nsubprocess.run(['python','skills_root/tender_structure_parse/scripts/parse_tender_pdf.py','--project_dir','/workdir/projects/2026-001','--enable_ocr','false'], check=True)\nprint('parse_done')\n"
}
view_file:查看产物(例如 issue_list.json)
{
"file_path": "/workdir/projects/2026-001/artifacts/issue_list.json"
}
4.3报告样例、 issue 与报告生成代码
上文规则引擎输出的 json 顶层含 issues 字段;报告生成脚本会读取 payload["issues"]
{
"generated_at": "2026-02-26T00:00:00Z",
"tender_json": "sample_project/artifacts/tender.json",
"rules": "skills_root/compliance_mandatory_items/rules/disqualify_rules.yml",
"issue_count": 3,
"issues": [
{
"severity": "HIGH",
"category": "技术条款",
"rule_key": "BRAND_SPECIFIED_ONLY",
"clause_ref": "FULLTEXT",
"evidence": "…投标产品必须为西门子品牌…",
"explanation": "技术要求出现品牌指向性表述,可能导致竞争受限,应评估是否需改为性能/指标描述或提供“或同等”机制。",
"suggestion": "将品牌描述改为可验证的性能指标;如必须引用品牌作为参考,增加“或同等/不低于”并给出等同性判定口径。",
"matched": {
"match_type": "regex",
"pattern": "(指定品牌|必须为.*品牌|仅限.*品牌|推荐品牌为)",
"hit": "必须为西门子品牌"
}
},
{
"severity": "HIGH",
"category": "资格条件",
"rule_key": "LOCAL_VENDOR_RESTRICTION",
"clause_ref": "FULLTEXT",
"evidence": "…投标人须为本市注册企业…",
"explanation": "存在地域/本地化限制的文字信号,可能构成不合理门槛。",
"suggestion": "删除地域限制;若确有服务响应时效要求,改为“响应时效/驻场能力/服务网点能力”的可验证指标。",
"matched": {
"match_type": "regex",
"pattern": "(本市|本地|当地|限.*市|限.*省|限在.*注册|本区域内)",
"hit": "本市"
}
},
{
"severity": "MEDIUM",
"category": "评分办法",
"rule_key": "AMBIGUOUS_EVALUATION_LANGUAGE",
"clause_ref": "FULLTEXT",
"evidence": "…评分由评委酌情决定…",
"explanation": "评分语言过于自由裁量,可能导致可解释性不足;建议补充量化标准或举例口径。",
"suggestion": "增加量化评分标准、区间与举例;明确材料要求与评分对应关系。",
"matched": {
"match_type": "regex",
"pattern": "(酌情|视情况|由评委决定|评委自行判断|综合考虑)",
"hit": "酌情"
}
}
]
}

报告生成模板 compliance_report.md.j2
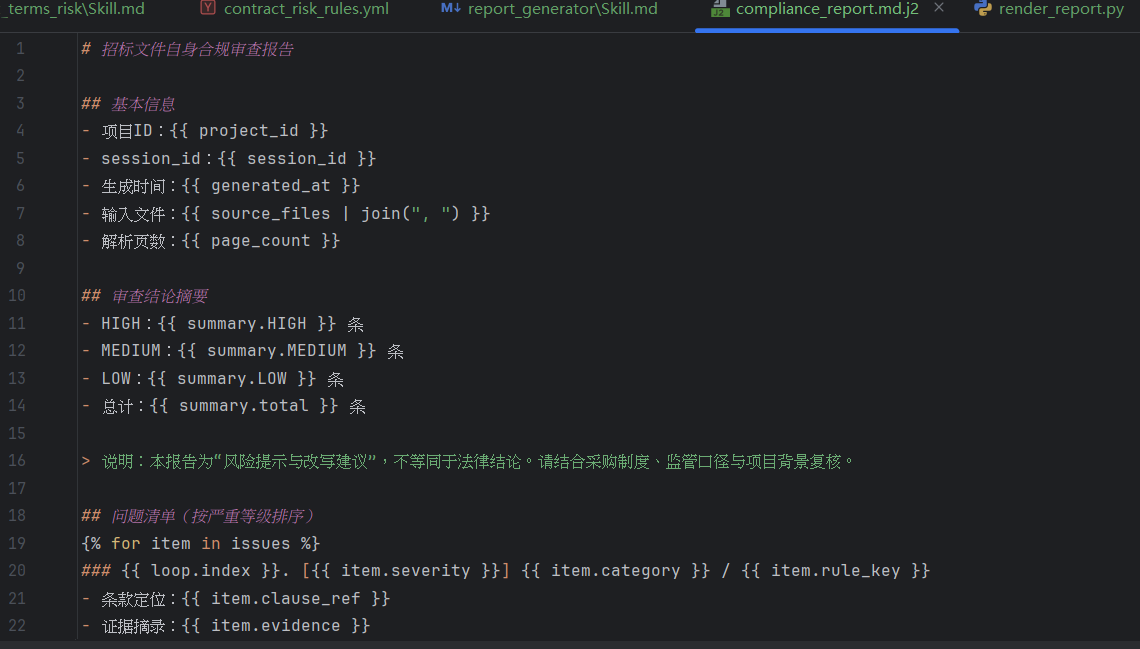
报告生成 Python 脚本 render_report.py
文件路径:skills_root/report_generator/scripts/render_report.py
4.4 安全与审计建议与测试验证
openJiuwen 的目标是“生产级 Agent”,强调高可靠执行与状态管理能力;做招标合规审查这种高责任场景,建议把“安全边界”作为重要关注点。
4.4.1 工作目录白名单
- 只允许
<WORKDIR>/projects/<project_id>/ - 所有产物目录固定:
artifacts/:结构化中间结果(tender.json、issue_list.json)audit/:日志与 manifestoutput/:最终交付报告
审计时只要打包 project_dir 就能复现。
4.4.2 Shell 命令白名单
- 允许:
ls/dir,cat/type,python,unzip/7z(解压),可选pdftotext(引入 poppler) - 禁止:
curl/wget,ssh/scp,rm -rf,sudo,powershell
4.5 测试与验证步骤
建议准备一个 sample_project/,哪怕里面最开始没有真实 PDF,也能先跑通规则引擎与报告生成。
sample project 目录结构:
sample_project/
tender.pdf # 真实招标PDF
clarification.pdf # 可选
attachments.zip # 可选
artifacts/
tender.json
audit/
output/
4.6 端到端命令序列
- 跑规则引擎生成 issue_list.json
python skills_root/compliance_mandatory_items/scripts/run_rules_engine.py \
--tender_json sample_project/artifacts/tender.json \
--rules skills_root/compliance_mandatory_items/rules/disqualify_rules.yml \
--output sample_project/artifacts/issue_list.json \
--log sample_project/audit/rules_engine.log
- 渲染报告
python skills_root/report_generator/scripts/render_report.py \
--project_id sample-001 \
--session_id sample-001__fanstuck__20260226T000000Z \
--tender_json sample_project/artifacts/tender.json \
--issue_list sample_project/artifacts/issue_list.json \
--template skills_root/report_generator/templates/compliance_report.md.j2 \
--output sample_project/output/compliance_report.md
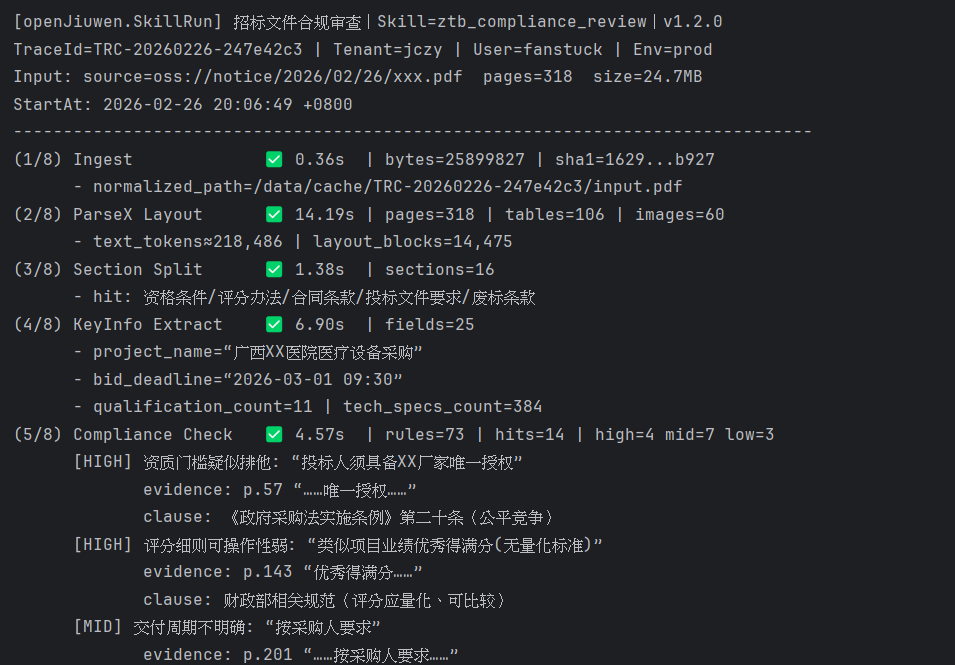
预期输出与断言点
sample_project/artifacts/issue_list.json中:issue_count >= 3- 至少包含
BRAND_SPECIFIED_ONLY、LOCAL_VENDOR_RESTRICTION、AMBIGUOUS_EVALUATION_LANGUAGE
sample_project/output/compliance_report.md中:- “审查结论摘要”统计正确
- 每条 issue 有
clause_ref/evidence/suggestion
第五章|结尾总结
当这套系统第一次在真实项目里完整跑通的时候,我其实并没有太多兴奋感。更多的是一种很冷静的确认。以前做 LLM 应用的时候,模型像一个非常聪明但不稳定的同事。它能理解上下文,能总结条款,能提出疑点,但你始终没办法真正把它纳入业务流程。它的判断依赖当前的提示词状态,依赖当次推理上下文,依赖概率。你改一句 Prompt,结果就变了;你多给一个示例,输出风格又漂移了。它很聪明,但它不属于你的系统。
而当我们把招标文件合规审查这件事拆开,落到 Skills 目录、规则文件、执行链路、日志打印、报告生成这些具体工程节点上,整个感觉就变了。
规则不再藏在 Prompt 里,而是清清楚楚写在 Skill.md 里;每一条合规判定都能回溯到对应规则文件;每一次执行都有 traceId;每一步都有耗时和输出摘要;每一个风险点都有证据、有条款依据、有整改建议。你不再是在“问模型怎么看”,而是在“运行一套系统”。
那一刻,我真正意识到,所谓“从通用 Agent 到合规引擎”,并不是把模型能力堆上去,而是把边界收紧。
模型不再决定一切,它只是规则体系中的一个增强器。真正决定行为的是规则文件、执行流程、系统接口、输出结构。这种变化很微妙,但影响是本质性的。因为当你把一个系统变成“可审计、可复现、可版本管理”的形态时,它才具备进入生产环境的资格。
在招标合规这种场景里,这一点尤其重要。我们处理的不是普通文本,而是会带来责任的文件。一个模糊的建议和一个可归档的风险条款清单,在工程上是完全不同的东西。前者是辅助参考,后者是交付成果。
如果你也在做智能体落地,我真心建议你问自己一个问题:你的 Agent,是不是已经脱离了 Prompt 依赖,变成了一套可管理的能力工程?如果答案还是否定的,那么你离真正的企业级落地,还差一个“规则与执行边界”的重构。
工程从来不是一蹴而就,而是一层一层往上叠。
我是 Fanstuck。
我更关心的,从来不是模型有多强,而是它能不能真正融入业务流程,成为系统的一部分。
如果你也在做类似的实践,欢迎继续关注。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)