一站式获取:模型训练常用数据集
coco2017

简介
12 万 + 图像,80 类目标,含检测、分割、关键点、字幕标注,覆盖日常场景。
应用
目标检测 / 实例分割 / 姿态估计 / 图像字幕,YOLO 系列、Mask R-CNN 等主流模型基准。
获取途径
ImageNet

简介
1400 万 + 图像,1000 类,图像分类领域最权威基准。
应用
图像分类预训练 / 微调、迁移学习、CNN 架构验证(ResNet/MobileNet 等)。
获取途径
XFUND

简介
多语言表单理解数据集,含中文 / 英文表单图像,标注文本框、内容、关系,用于文档智能。
应用
表单文本检测 / 识别、信息抽取、文档布局分析、OCR 后处理。
获取途径
CIFAR100

简介
CIFAR-10 的扩展版,含 60,000 张 32×32 彩色图像,100 个细分类别(归为 20 个超类),每类 600 张(500 训练 / 100 测试)。
应用
细粒度图像分类、轻量级 CNN 模型基准测试、算法快速验证。
获取途径
DA-2K

简介
Depth Anything V2 配套基准,1,000 张高分辨率图像,2,000 组稀疏相对深度对标注,覆盖室内 / 室外 / 透明 / 航拍等 8 类场景。
应用
单目相对深度估计、深度模型泛化性测试、自动驾驶环境感知。
获取途径
WFLW
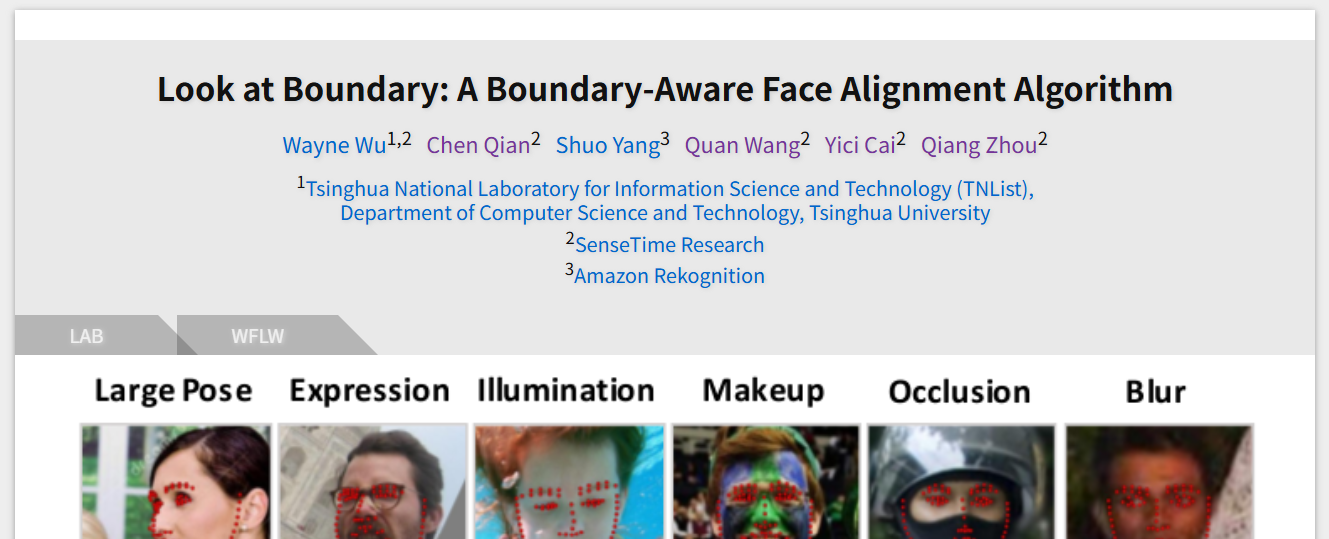
简介
10,000 张人脸图像(7,500 训练 / 2,500 测试),标注98 个关键点,含遮挡 / 姿态 / 妆容 / 光照 / 模糊 / 表情等属性。
应用
高精度人脸关键点检测、人脸对齐、表情识别、三维人脸重建。
获取途径
HPatches
简介
单应性补丁数据集,分 ** 光照变化(i_X)与视角变化(v_X)** 序列,用于局部描述符鲁棒性评估。
应用
局部特征描述符(SIFT/SURF/SuperPoint)评测、图像匹配、拼接、SLAM 特征提取。
获取途径
carvana
简介
Kaggle 竞赛数据集,10 万 + 张汽车多角度高清图,含像素级汽车掩码,每车 16 个视角。
应用
语义分割(UNet 等)、汽车实例分割、车辆检测与抠图。
获取途径
DOTAv1
简介
遥感图像旋转目标检测基准,含 15 类目标(飞机、舰船、车辆等),标注旋转框(OBB),覆盖多场景。
应用
遥感图像旋转目标检测、航空影像分析、军事 / 国土资源监测。
获取途径
KITTI15

简介
自动驾驶经典数据集,含立体图像、光流、视觉里程计、3D 检测标注,覆盖城市 / 乡村 / 高速场景。
应用
立体匹配、光流估计、3D 目标检测、SLAM、自动驾驶感知。
获取途径
CelebA-512

简介
CelebA 的高分辨率版本,约 20 万张名人面部图像,分辨率 512×512,含 40 + 属性标注(年龄、表情、遮挡等)。
应用
人脸属性识别、人脸生成、人脸编辑、人脸验证。
获取途径
Faces

简介
通用人脸图像数据集,含多姿态、光照、表情的人脸样本,用于基础人脸任务。
应用
人脸检测、人脸关键点定位、简单人脸识别。
获取途径
LFW
简介
13,000 + 张网络采集人脸图像,含 5,749 个身份,用于无约束场景人脸验证
应用
人脸识别 / 验证、人脸对齐、跨姿态 / 光照鲁棒性测试。
获取途径
Synthetic-Chinese-String-Dataset
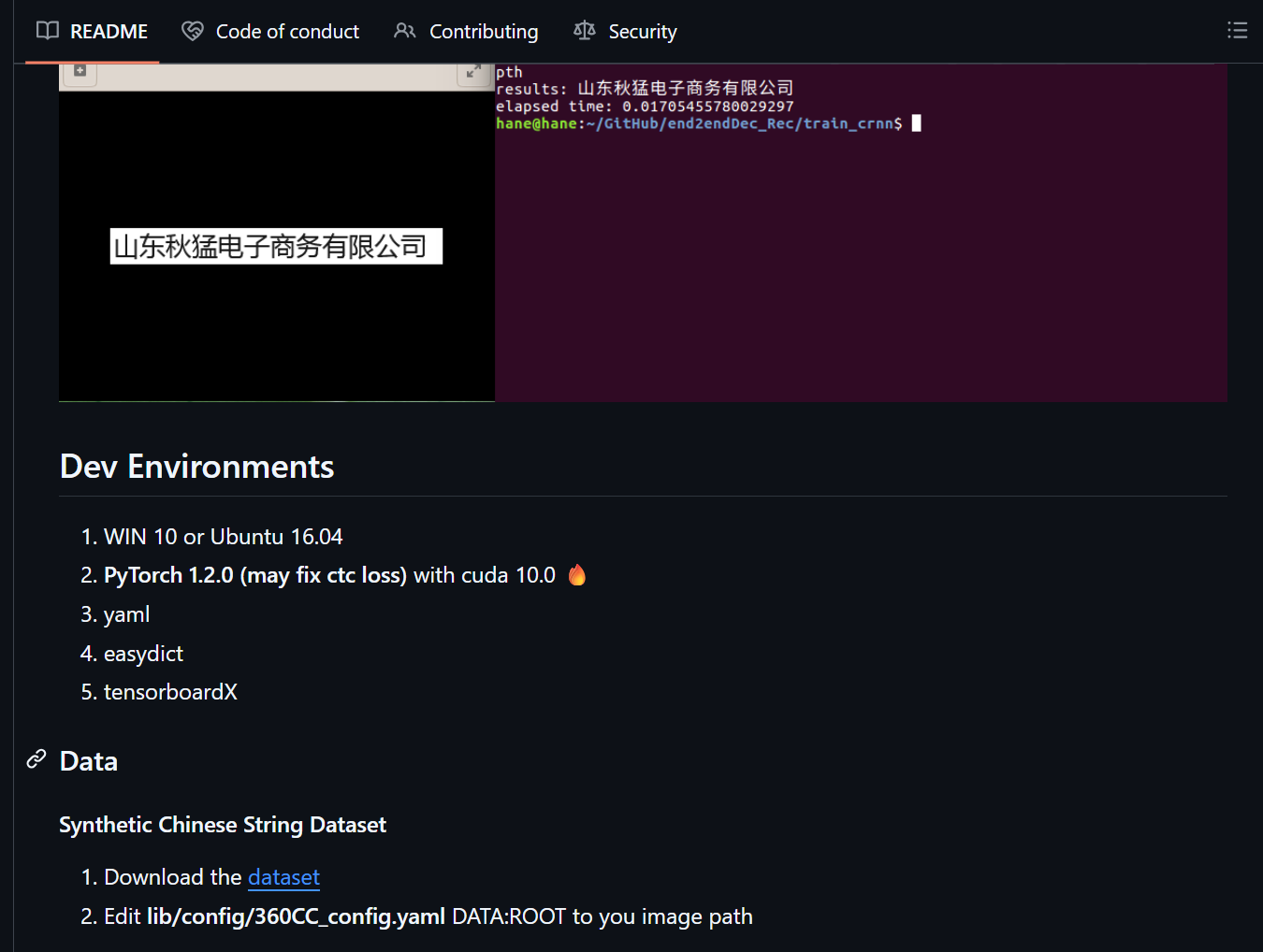
简介
合成中文文本行数据集,含多样字体、背景、扭曲,用于端到端中文文本识别。
应用
中文 OCR(CRNN 等)、文本行识别、手写 / 印刷体文本识别。
获取途径
Set5
简介
经典超分测试集,5 张高清自然图像(婴儿、鸟、蝴蝶、人像、女性),用于快速验证算法效果。
应用
单图像超分辨率(SISR)、图像重建、低清画质增强、算法基准对比。
获取途径
CrowDensity
简介
人群密度估计数据集,含密集 / 稀疏人群场景,标注密度图,用于公共安全与流量分析。
应用
人群计数 / 密度估计、视频监控、客流统计、拥挤预警。
获取途径
LJSpeech
简介
英文语音数据集,13,100 条语音片段(约 24 小时),由专业朗读者录制,含文本标注。
应用
文本转语音(TTS)、语音合成(FastSpeech2/Tacotron)、声码器训练。
获取途径

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)