
AI Agent开发教程:9. Agent框架

每次都要处理对话历史、管理工具调用、实现记忆系统、处理错误重试……这些都是通用需求,为什么要反复造轮子?
这就是Agent框架存在的意义。
2025年底,LangChain在其《State of Agent Engineering》(链接:https://www.langchain.com/state-of-agent-engineering)报告中披露:超过半数的企业已经把Agent部署到了生产环境,而在这些生产系统中,大部分使用了成熟的Agent框架。
更有意思的是,2025-2026年出现了一个明显的趋势:每个大厂都推出了自己的Agent框架。OpenAI发布了Agents SDK,Google推出了ADK(Agent Development Kit),Anthropic发布了Claude Agent SDK(专为代码执行类Agent设计),微软有Semantic Kernel和AG2(原AutoGen的社区分支),连HuggingFace也推出了Smolagents。
这说明Agent开发已经从"探索阶段"全面进入了"工程化阶段"。框架的作用不再只是"方便开发",而是"保证质量、提升效率、降低成本"。
由于篇幅原因,本篇文章分为上下两篇:
-
上篇(本文):2026年框架格局全景 + LangChain/LangGraph详解
-
下篇:CrewAI、AutoGPT等框架 + 框架选择指南
2026年的Agent框架格局
先看一张全景图。根据2026年2月的统计数据,主流Agent框架的生态是这样的:
说明:本文主要介绍开源框架,这些框架代码公开、社区活跃、可自由使用和修改。商业/闭源框架会在后面单独简要介绍。
第一梯队:通用Agent开发框架(构建Agent的SDK)
这类框架是用来写Agent代码的核心SDK,适合大部分开发场景。
|
框架 |
GitHub星标 |
核心特点 |
最适合的场景 |
|---|---|---|---|
| LangChain + LangGraph |
128K + 25K |
生态最完整,图结构编排 |
快速原型开发、复杂工作流、状态机 |
| CrewAI |
44.8K |
多Agent协作,角色分工 |
团队协作场景、复杂项目 |
| Smolagents |
25.7K |
HuggingFace出品,代码优先 |
开源模型集成 |
| PydanticAI |
15K |
类型安全,像FastAPI |
Python开发者友好、结构化输出 |
| AG2 |
4.2K |
AutoGen社区版,对话驱动 |
企业级多Agent系统 |
注意:2024年11月,原微软AutoGen项目演变为社区驱动的AG2项目,采用Apache 2.0开源协议。微软同时发布了新的
microsoft/agent-framework作为企业级方案。
第二梯队:专用Agent框架(特定场景优化)
这类框架针对特定场景深度优化,在各自领域比通用框架更强。
|
框架 |
GitHub星标 |
核心特点 |
最适合的场景 |
|---|---|---|---|
| browser-use |
79K |
浏览器自动化,让AI操作网页 |
Web操作、表单填写、数据抓取 |
| mem0 |
48K |
轻量级Agent记忆层 |
为任意Agent添加长期记忆 |
| LlamaIndex |
47.2K |
专注数据处理和RAG |
知识库问答、文档分析 |
| Letta |
21.2K |
原MemGPT,长期记忆优先 |
需要跨会话记忆的Agent |
第三梯队:Agent基础设施(运行时/工具平台)
这类不是用来写Agent的SDK,而是Agent的运行环境和工具生态。
|
框架 |
GitHub星标 |
核心特点 |
最适合的场景 |
|---|---|---|---|
| Agno (AgentOS) |
38.2K |
Agent运行时、隔离、治理、追踪 |
生产级Agent部署和管理 |
| Composio |
27.2K |
1000+工具集成、统一认证、沙箱 |
快速接入外部服务(Gmail/Slack/GitHub等) |
第四梯队:自主Agent / 实验性项目
这类框架探索完全自主的Agent,给一个目标让Agent自己规划执行。Stars很高但生产环境需谨慎。
|
框架 |
GitHub星标 |
核心特点 |
最适合的场景 |
|---|---|---|---|
| AutoGPT |
182K |
已转型为可视化平台 |
长时间自主任务、探索性研究 |
| BabyAGI |
22.1K |
任务分解循环 |
简单的自主任务 |
商业/闭源框架(简要介绍)
除了开源框架,各大AI厂商也推出了自己的Agent SDK,通常与其云服务深度绑定:
|
框架 |
厂商 |
核心特点 |
适用场景 |
|---|---|---|---|
| Agents SDK |
OpenAI |
与GPT模型深度集成,内置代码解释器、文件检索等工具 |
已使用OpenAI API的项目,追求开箱即用 |
| ADK (Agent Development Kit) |
|
支持Gemini模型,图结构编排,与Google Cloud集成 |
Google生态用户,需要多模态能力 |
| Claude Agent SDK |
Anthropic |
专为代码执行类Agent设计,强调安全性和可控性 |
代码生成、自动化编程场景 |
| Semantic Kernel |
Microsoft |
企业级SDK,支持C#/Python/Java,与Azure集成 |
企业级应用,多语言团队 |
| Bedrock Agents |
AWS |
托管服务,与AWS生态(S3、Lambda等)无缝集成 |
AWS用户,需要serverless部署 |
商业框架的优势:
-
与自家模型深度优化,调用更简单
-
通常提供托管服务,无需自己部署基础设施
-
企业级支持和SLA保障
商业框架的局限:
-
通常绑定特定模型或云服务,迁移成本高
-
定制灵活度不如开源框架
-
需要付费,成本可能较高
本文的选择:考虑到学习目的和通用性,后续章节将聚焦开源框架的详细讲解。掌握开源框架后,商业框架的使用会非常简单——它们的核心概念是相通的。
一个关键趋势:2026年的框架都在往图结构编排方向走。LangGraph、Google ADK都采用了有向图来管理Agent的状态和流程,这比2024年流行的"链式调用"更灵活、更可控。
另一个爆发点:浏览器自动化Agent。browser-use在2025年底爆火,短短几个月从0涨到79K stars。原因很简单——让AI像人一样操作网页是最直接、最有商业价值的应用场景。
与此同时,基于Agent技术的产品也在爆发,如OpenClaw(23万+ stars)等,标志着Agent正在从开发框架走向终端用户产品。
技术细节:OpenClaw 底层使用的是 Pi (pi-mono) 这个轻量级 Agent 运行时引擎,由 Mario Zechner 开发。Pi 专注于 Agent 循环执行、工具调用流式处理和 RPC 通信,是专门为 OpenClaw 设计的。后面会单独介绍OpenClaw的Agent 运行时引擎 Pi。
LangChain:最该先学的框架

为什么先讲LangChain?因为它是目前生态最完整、用户最多、资料最丰富的框架。128K的GitHub星标不是白来的。
LangChain的三大优势:
-
工具集成丰富:内置了几百个工具集成,从搜索引擎到数据库到API,开箱即用
-
文档和社区完善:遇到问题基本都能搜到解决方案
-
学习曲线友好:概念清晰,从简单到复杂都能覆盖
快速上手
# 安装核心库(建议升级到最新版)
pip install --upgrade langchain langchain-core
# 安装Ollama集成(必需)
pip install langchain-ollama
# 注意:本文使用LangChain 1.0+的新版API
# 如果遇到导入错误,请确保版本正确:pip list | grep langchain
一个最简单的例子
先看一个完整的例子,然后我们拆开讲。这个Agent能做两件事:计算数学题、搜索信息(模拟)。
创建 examples/09_langchain_ollama.py:
"""
LangChain Agent示例 - 使用Ollama
前面我们自己写了Agent,现在看看用框架有多简单
注意:需要先安装 langchain-ollama: pip install langchain-ollama
"""
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain_core.tools import tool
# 使用@tool装饰器定义工具(推荐方式)
@tool
def calculator(expression: str) -> str:
"""用于数学计算。输入应该是数学表达式,如'2+2'或'10*5'"""
try:
result = eval(expression)
returnf"计算结果: {result}"
except Exception as e:
returnf"计算错误: {str(e)}"
@tool
def search_web(query: str) -> str:
"""用于搜索信息。输入应该是搜索查询"""
returnf"搜索'{query}'的结果: [AI Agent在2026年已广泛应用,57%企业已部署到生产环境]"
# 初始化Ollama LLM
print("初始化Ollama...")
llm = ChatOllama(
model="qwen3:latest",
base_url="http://localhost:11434",
temperature=0
)
print("✅ Ollama初始化完成\n")
# 创建工具列表
tools = [calculator, search_web]
# 使用新版API创建Agent (自动配置工具调用循环)
print("创建Agent...")
agent = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个有帮助的AI助手。使用提供的工具来准确回答问题。"
)
print("✅ Agent创建完成\n")
# 使用示例
if __name__ == "__main__":
print("="*60)
print("LangChain Agent示例")
print("="*60)
# 测试1: 数学计算
print("\n测试1: 数学计算")
print("-"*60)
result1 = agent.invoke({
"messages": [{"role": "user", "content": "计算 (25 + 17) * 3"}]
})
# 获取最后一条消息
final_message = result1["messages"][-1]
print(f"\n✅ 结果: {final_message.content}")
# 测试2: 搜索
print("\n" + "="*60)
print("测试2: 搜索")
print("-"*60)
result2 = agent.invoke({
"messages": [{"role": "user", "content": "搜索AI Agent的最新发展"}]
})
# 获取最后一条消息
final_message = result2["messages"][-1]
print(f"\n✅ 结果: {final_message.content}")
print("\n" + "="*60)
print("测试完成!")
print("="*60)
这段代码做了什么?
-
定义工具:使用
@tool装饰器定义工具,比传统的Tool类更简洁 -
初始化LLM:使用
ChatOllama连接本地Ollama服务(比Ollama更轻量,启动更快) -
创建Agent:使用
create_agent()一行代码创建完整的Agent,返回一个LangGraph图对象,自动配置工具调用循环 -
执行任务:调用
invoke()并传入消息格式,框架自动处理工具调用、状态管理
对比一下:如果自己写,这些逻辑至少要50行代码。用LangChain,核心逻辑不到15行。
带记忆的Agent
上一篇我们花了很大篇幅讲记忆系统。在LangChain的新版API里,记忆功能通过checkpointer实现:
"""
LangChain带记忆的Agent - 记住用户说过的话
"""
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from langchain_core.tools import tool
from langgraph.checkpoint.memory import MemorySaver
# 定义工具(同上)
@tool
def calculator(expression: str) -> str:
"""用于数学计算"""
try:
returnf"计算结果: {eval(expression)}"
except Exception as e:
returnf"计算错误: {str(e)}"
# 初始化LLM
llm = ChatOllama(model="qwen3:latest", base_url="http://localhost:11434")
# 创建带记忆的Agent(使用checkpointer)
memory = MemorySaver()
agent_with_memory = create_agent(
model=llm,
tools=[calculator],
checkpointer=memory, # 添加记忆功能
system_prompt="你是一个有帮助的AI助手。"
)
# 使用示例
if __name__ == "__main__":
print("\n带记忆的对话:")
# 配置会话ID(同一个thread_id的对话会共享记忆)
config = {"configurable": {"thread_id": "conversation-1"}}
# 对话1
result1 = agent_with_memory.invoke({
"messages": [{"role": "user", "content": "我叫小明"}]
}, config)
print(f"回复1: {result1['messages'][-1].content}")
# 对话2(Agent会记住之前的对话)
result2 = agent_with_memory.invoke({
"messages": [{"role": "user", "content": "我的名字是什么?"}]
}, config)
print(f"回复2: {result2['messages'][-1].content}")
关键点:
-
使用
MemorySaver()作为 checkpointer 来保存对话状态 -
通过
thread_id区分不同的对话会话 -
同一个
thread_id的对话会自动共享历史记忆
LangGraph:复杂工作流的利器

前面我们用的 create_agent() 其实底层就是用 LangGraph 实现的。LangGraph 是 LangChain 生态中专门用于构建复杂状态机和工作流的框架。
为什么需要 LangGraph?
简单的 Agent 用 create_agent() 就够了,但当你需要:
-
明确控制 Agent 的执行流程
-
实现条件分支(if-else 逻辑)
-
多个 Agent 按特定顺序协作
-
人工审核节点(human-in-the-loop)
这时候就需要 LangGraph 了。它让你用图结构来编排 Agent 的行为。
一个简单的审批工作流
假设我们要实现一个需要人工审批的 Agent:先让 Agent 生成方案,然后人工审批,通过后才执行。
"""
LangGraph 审批工作流示例
演示如何用图结构控制 Agent 流程
"""
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, AIMessage
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.checkpoint.memory import MemorySaver
# 定义 Agent 节点
def agent_node(state: MessagesState):
"""Agent 生成方案"""
llm = ChatOllama(model="qwen3:latest", base_url="http://localhost:11434")
# 获取用户请求
user_message = state["messages"][-1].content
# 生成方案
response = llm.invoke([
{"role": "system", "content": "你是一个助手,为用户生成解决方案。"},
{"role": "user", "content": user_message}
])
return {"messages": [AIMessage(content=f"方案:{response.content}")]}
def approval_node(state: MessagesState):
"""人工审批节点"""
print("\n" + "="*60)
print("等待审批...")
print("方案内容:", state["messages"][-1].content)
print("="*60)
# 模拟人工审批(实际应用中这里会暂停等待用户输入)
approval = input("是否批准?(y/n): ")
if approval.lower() == 'y':
return {"messages": [AIMessage(content="✅ 方案已批准,开始执行")]}
else:
return {"messages": [AIMessage(content="❌ 方案被拒绝,请重新生成")]}
def should_continue(state: MessagesState) -> str:
"""决定下一步:批准则结束,拒绝则重新生成"""
last_message = state["messages"][-1].content
if"已批准"in last_message:
return"end"
else:
return"regenerate"
# 构建工作流图
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("agent", agent_node)
workflow.add_node("approval", approval_node)
# 定义流程
workflow.add_edge(START, "agent") # 开始 → Agent生成方案
workflow.add_edge("agent", "approval") # Agent → 审批
workflow.add_conditional_edges(
"approval", # 审批后的分支
should_continue,
{
"end": END, # 批准 → 结束
"regenerate": "agent" # 拒绝 → 重新生成
}
)
# 编译图
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
# 使用示例
if __name__ == "__main__":
print("LangGraph 审批工作流示例")
print("="*60)
config = {"configurable": {"thread_id": "workflow-1"}}
# 发起请求
result = app.invoke({
"messages": [HumanMessage(content="帮我制定一个学习Python的计划")]
}, config)
print("\n最终结果:")
for msg in result["messages"]:
print(f"{msg.__class__.__name__}: {msg.content}")
这个例子展示了什么?
-
图结构:用节点(agent、approval)和边(箭头)定义流程
-
条件分支:
add_conditional_edges实现 if-else 逻辑 -
循环流程:拒绝后可以回到 agent 节点重新生成
-
状态管理:
MessagesState自动管理消息历史
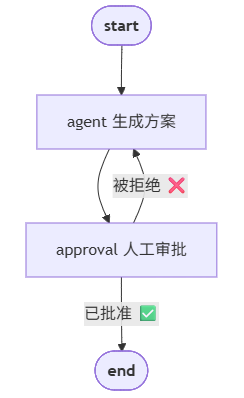
什么时候用 LangGraph?
-
✅ 需要多个 Agent 按特定顺序执行
-
✅ 需要条件分支和循环
-
✅ 需要人工审核节点
-
✅ 需要精确控制每一步的执行逻辑
-
❌ 简单的工具调用(用 create_agent 更简单)
本篇小结
本篇我们了解了2026年Agent框架的四大类型:
-
通用SDK:LangChain、CrewAI、AG2等,用于编写Agent代码
-
专用框架:browser-use、LlamaIndex、Letta,针对特定场景优化
-
基础设施:Agno、Composio,提供运行时和工具生态
-
实验性项目:AutoGPT、BabyAGI,探索自主Agent
也简要介绍了目前商业Agent框架。
并详细学习了LangChain生态:
-
LangChain:最该先学的框架,生态完整、上手友好
-
LangGraph:复杂工作流的利器,用图结构编排Agent行为
下篇:我们将继续学习CrewAI(多Agent协作)、AutoGPT(自主规划),以及最重要的——如何选择适合你的框架。
📚 本篇相关资源
LangChain 生态
-
LangChain 官方文档(https://python.langchain.com/)
-
LangChain GitHub (https://github.com/langchain-ai/langchain)
-
LangGraph 官方文档(https://langchain-ai.github.io/langgraph/)
-
LangGraph GitHub (https://github.com/langchain-ai/langgraph)
-
LangSmith 平台 (https://smith.langchain.com/)
最后
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取