新手小白从零开始亲手搭建基于RAG的王者荣耀装备系统问答机器人!
🎮 王者荣耀RAG问答机器人:从零到部署全记录(附完整代码)
本文详细记录了基于RAG架构的《王者荣耀》装备问答机器人的开发过程,涵盖技术选型、核心模块实现、优化技巧以及踩过的所有坑,希望对正在学习RAG的同学有所帮助。
1. 项目背景
作为一个《王者荣耀》老玩家,我经常需要查询装备属性和出装思路。官方资料分散,网上攻略又良莠不齐,于是萌生了自己做一个智能问答机器人的想法。正好最近在深入学习RAG(检索增强生成),决定拿这个项目练手。
项目目标:用户用自然语言提问,系统从装备知识库中检索最相关信息,再由大模型生成准确答案。
2. 技术栈
| 组件 | 选型 | 说明 |
|---|---|---|
| 前端框架 | Streamlit | 快速搭建交互界面,支持聊天组件 |
| RAG框架 | LangChain | 链式调用、检索器封装 |
| 嵌入模型 | paraphrase-multilingual-MiniLM-L12-v2 |
轻量多语言,384维 |
| 重排序模型 | BAAI/bge-reranker-base |
交叉编码器,提升排序精度 |
| 大语言模型 | DeepSeek Chat | 通过OpenAI兼容接口调用,性价比高 |
| 向量数据库 | FAISS (CPU版) | 本地索引持久化,避免重复构建 |
| 基础库 | PyTorch, Sentence-Transformers | 模型加载与推理 |
3. 系统架构
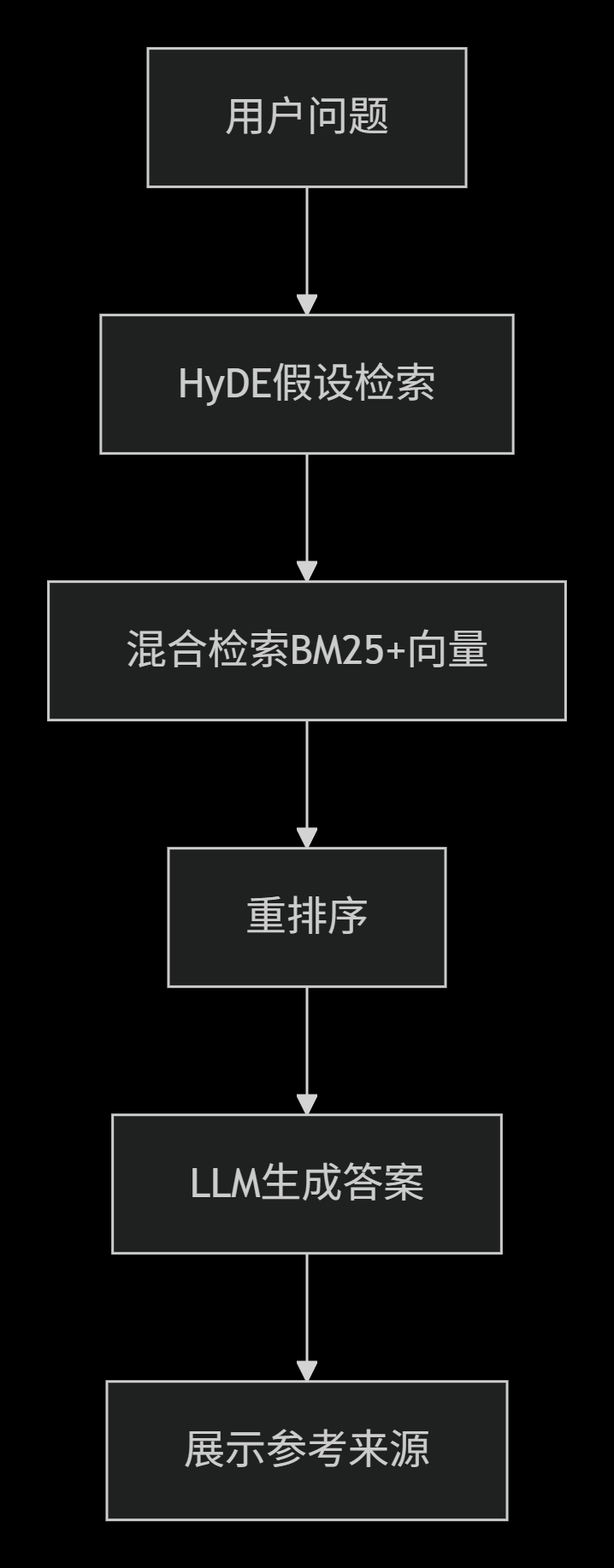
整体流程:
- 用户输入问题
- HyDE模块生成假设性回答
- 混合检索(BM25 + 向量)召回候选文档
- 重排序模块对候选文档重新打分
- 将Top-K文档与问题拼接成Prompt
- 大模型生成最终答案
- 返回答案并附上参考来源
系统流程图
4. 核心模块实现
4.1 文档加载与分割
知识库是一系列.txt文件,每个文件包含多个装备条目,用--------------------------------------------------分隔。
# utils.py
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
def load_and_split_documents(chunk_size=500, chunk_overlap=0):
loader = DirectoryLoader(
KNOWLEDGE_PATH,
glob="**/*.txt",
loader_cls=TextLoader,
loader_kwargs={'encoding': 'utf-8'}
)
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
separators=[
"\n--------------------------------------------------\n", # 装备分隔符
"\n\n", "\n", "。", "!", "?", ";", " ", ""
],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = splitter.split_documents(documents)
return chunks
难点:一开始用默认的\n\n分割,导致装备描述被切得七零八落,检索时常返回不完整的属性。解决方案是优先按装备间的分隔符切分,保证每个chunk包含一个完整装备。
4.2 嵌入与向量库
使用HuggingFaceEmbeddings加载模型,并用FAISS构建索引。为了加速,加入了索引持久化功能。
# utils.py
def load_or_create_vectorstore(chunks):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
embedding = HuggingFaceEmbeddings(
model_name=EMBEDDING_MODEL,
model_kwargs={'device': device},
encode_kwargs={'normalize_embeddings': True, 'batch_size': 32}
)
index_file = os.path.join(FAISS_INDEX_PATH, "index.faiss")
if os.path.exists(index_file):
vectorstore = FAISS.load_local(
FAISS_INDEX_PATH,
embedding,
allow_dangerous_deserialization=True
)
else:
vectorstore = FAISS.from_documents(chunks, embedding)
os.makedirs(FAISS_INDEX_PATH, exist_ok=True)
vectorstore.save_local(FAISS_INDEX_PATH)
return vectorstore, embedding
踩坑:本地索引维度必须与当前嵌入模型一致。切换模型后若忘记删除旧索引,会报错assert d == self.d。后来在代码中加入异常处理,加载失败时自动删除并重建。
4.3 HyDE检索器
HyDE(Hypothetical Document Embeddings)先用LLM生成一个“假设答案”,再用该答案去检索,能有效解决用户提问过于简短的问题。
# retrievers.py
class HyDERetriever(BaseRetriever):
llm: Any = Field(description="大语言模型")
vectorstore: Any = Field(description="向量库")
base_retriever: Any = Field(description="基础检索器")
base_kwargs: Optional[dict] = Field(default=None)
def __init__(self, llm, vectorstore, base_kwargs=None, **kwargs):
base = vectorstore.as_retriever(**(base_kwargs or {}))
super().__init__(llm=llm, vectorstore=vectorstore, base_retriever=base, base_kwargs=base_kwargs, **kwargs)
def _get_relevant_documents(self, query, run_manager):
hyde_prompt = f"请根据问题生成一段假设性回答(只输出内容):\n问题:{query}\n假设回答:"
hyp = self.llm.invoke(hyde_prompt)
hyp = hyp.content if hasattr(hyp, 'content') else hyp
run_manager.on_text(f"HyDE假设回答:\n{hyp}\n", color="yellow")
return self.base_retriever.invoke(hyp)
优化点:如果LLM调用失败,回退到原始查询,保证系统鲁棒性。
4.4 混合检索
结合BM25(关键词)和向量检索(语义),用EnsembleRetriever加权融合。
# app.py
bm25 = BM25Retriever.from_documents(chunks)
bm25.k = TOP_K
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": TOP_K})
ensemble = EnsembleRetriever(
retrievers=[bm25, vector_retriever],
weights=[0.3, 0.7]
)
权重设置:BM25占0.3,向量占0.7,既保证装备名精确匹配,又兼顾语义泛化。
4.5 重排序检索器(惰性加载)
重排序模型较大,为了节省内存,采用惰性加载,仅在第一次查询时加载模型。
# retrievers.py
class RerankRetriever(BaseRetriever):
base: Any = Field(description="基础检索器")
reranker: Optional[Any] = Field(default=None)
model_name: str = Field(description="重排序模型名称")
device: str = Field(description="运行设备")
initial_k: int = Field(default=20)
final_k: int = Field(default=5)
def __init__(self, base, model_name="BAAI/bge-reranker-base", initial_k=20, final_k=5, **kwargs):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
super().__init__(base=base, reranker=None, model_name=model_name,
device=device, initial_k=initial_k, final_k=final_k, **kwargs)
def _get_relevant_documents(self, query, run_manager):
if self.reranker is None:
self.reranker = CrossEncoder(self.model_name, device=self.device)
candidates = self.base.invoke(query) or []
if not candidates:
return []
pairs = [(query, doc.page_content) for doc in candidates]
scores = list(self.reranker.predict(pairs))
scored = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
# 阈值过滤
from config import THRESHOLD
if scored and scored[0][1] < THRESHOLD:
return []
return [doc for doc, _ in scored[:self.final_k]]
阈值过滤:当最相关文档得分低于0.5时,认为无相关文档,返回空列表。这能有效避免在用户问“你好”时胡乱返回文档。
4.6 提示模板与问答链
# app.py
prompt = PromptTemplate.from_template("""你是一名王者荣耀装备专家,基于以下信息回答问题,若不知道则说不知道。
信息:
{context}
问题:{question}
回答:""")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=rerank_retriever,
return_source_documents=True,
verbose=False,
chain_type_kwargs={"prompt": prompt}
)
4.7 界面与参考来源显示
# app.py 聊天界面部分
if src := result.get('source_documents'):
answer += "\n\n📚 **参考资料**:"
for i, doc in enumerate(src[:TOP_K]):
name_match = re.search(r'【装备名称】(.*?)(\n|$)', doc.page_content)
preview = name_match.group(1).strip() if name_match else doc.page_content[:60].replace('\n', ' ') + "..."
answer += f"\n{i+1}. {preview}"
5. 部署与优化
5.1 本地部署到阿里云服务器
- 服务器配置:4核8G,Ubuntu 22.04
- 环境:Python 3.10 + 虚拟环境
- 依赖:requirements.txt(注意用
faiss-cpu而非faiss-gpu) - 使用
systemd管理应用,开机自启 - Nginx反向代理+域名(可选)
5.2 性能优化
问题:重排序模型在CPU上较慢,每次查询耗时3-5秒。
解决方案:
- 减小候选集:
INITIAL_K从30降到10,重排序计算量减少2/3。 - 添加查询缓存:对相同问题缓存检索结果,第二次直接返回。
- 权衡:暂时保留重排序,但未来可考虑换用更小的重排序模型(如
bge-reranker-base已是最优)。
缓存实现(在RerankRetriever中):
from functools import lru_cache
class RerankRetriever(BaseRetriever):
def _get_relevant_documents(self, query, run_manager):
return self._cached_get_relevant_documents(query)
@lru_cache(maxsize=128)
def _cached_get_relevant_documents(self, query):
# 原逻辑(去掉run_manager)
6. 遇到的难点与解决方案
6.1 LangChain模块迁移导致导入错误
现象:from langchain.retrievers import BM25Retriever报错。
原因:LangChain将社区组件移到langchain_community,主包只保留核心。
解决:按照DeprecationWarning提示,改为from langchain_community.retrievers import BM25Retriever,同时安装rank_bm25。
6.2 模型下载与SSL错误
现象:在本地运行时,HuggingFaceEmbeddings报Cannot send a request, as the client has been closed或SSL证书错误。
原因:国内网络访问Hugging Face不稳定,加上系统证书问题。
解决:
- 设置镜像:
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' - 强制离线:
os.environ['HF_HUB_OFFLINE'] = '1' - 在
HuggingFaceEmbeddings中加model_kwargs={'local_files_only': True}(注意新版API改为通过model_kwargs传递)
6.3 FAISS维度不匹配
现象:切换嵌入模型后,报AssertionError: assert d == self.d。
原因:旧索引的向量维度与新模型不一致。
解决:删除faiss_index文件夹,让程序重建;并在load_or_create_vectorstore中添加异常处理,自动删除并重建。
try:
vectorstore = FAISS.load_local(FAISS_INDEX_PATH, embedding)
except Exception:
shutil.rmtree(FAISS_INDEX_PATH, ignore_errors=True)
vectorstore = FAISS.from_documents(chunks, embedding)
vectorstore.save_local(FAISS_INDEX_PATH)
6.4 内存不足(本地与云端)
现象:在Streamlit Cloud免费版(1GB)上部署时,应用崩溃。
原因:同时加载嵌入模型和重排序模型,内存超限。
解决:
- 改用更小的重排序模型
bge-reranker-base(440MB) - 实现惰性加载,仅在第一次查询时加载重排序模型
- 最终迁移到阿里云4核8G服务器,内存无忧
6.5 回答速度慢
现象:在4核8G服务器上,每次回答仍需3-5秒。
原因:重排序在CPU上逐条计算分数。
解决:
- 减小
INITIAL_K(从30→10) - 添加查询缓存(见上文)
- 考虑未来用GPU实例加速
7. 效果展示
7.1 正常问答
用户:博学者之怒的属性是什么?
机器人:
博学者之怒的属性为:+210法术攻击,被动效果提升30%法术攻击。
📚 参考资料:
1. 博学者之怒
2. 虚无法杖
3. 梦魇之牙
7.2 寒暄处理
用户:你好
机器人:你好!我是王者荣耀装备专家,有什么关于装备的问题可以问我?
(无参考文档)
7.3 参考来源展示
每次回答都会附上被引用的文档片段,用户可追溯信息来源,增强可信度。
8. 总结与展望
通过这个项目,我完整实践了RAG系统的构建流程,深入理解了以下技术点:
- HyDE:提升短查询的召回率
- 混合检索:兼顾关键词匹配与语义相似度
- 重排序:大幅提高最终答案质量
- 阈值过滤:降低幻觉,提升系统鲁棒性
- 模块化设计:便于扩展和维护
遇到的每一个坑都让我对LangChain、FAISS、模型部署有了更深刻的认识。
未来计划:
- 扩展知识库:加入英雄、铭文、玩法攻略
- 多轮对话:利用对话历史进行上下文检索
- 评估体系:接入RAGAS框架,量化系统效果
- 性能优化:引入模型量化、更高效的检索算法
9. 项目源码
GitHub仓库:https://github.com/fsm050923/WZRY_RAG_demo
(内有完整代码、安装说明、配置文件)
在线demo:
http://8.140.220.116:8501

写在最后:RAG技术正在快速发展,但工程落地依然充满细节。希望我的分享能帮助到同样在路上的你。如果有任何问题,欢迎在评论区留言交流!
本文原创,转载请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)