图形学渲染:蒙特卡洛路径追踪实现中的方法、系统设计与 AI 协同工程
实现代码:https://github.com/Shadow-Dream/Monte-Carlo-Path-Tracing
本文由 GPT & Nano Banana 完成,分享一套蒙特卡洛路径追踪实现。该系统在统一的配置与运行时模型下,整合了多种执行后端(torch、cuda、optix、cpp、open3d_embree),同时保留了对真实场景、透明与 cutout 材质以及可选神经后处理链路的支持。文章围绕四个方面展开:渲染方法、系统架构与工程实现、实验设置与按场景分析,以及将该渲染器演化为可交付版本的 AI 协同工作流。

1. 背景
蒙特卡洛路径追踪是物理真实感离线渲染中最常见、也最基础的方法之一。它的优势在于概念上的统一性:同一套光传输估计器可以同时覆盖漫反射多次反弹、高光传输、折射、颜色串扰以及复杂的间接光照。它的弱点也同样明显:高方差、实现复杂度以及大量边界条件问题,都会在真实工程里迅速放大。如果估计器设计、执行路径与外层工程结构没有对齐,最终结果往往既慢又不稳。
在教学型小例子里,路径追踪经常被写成一个简洁的递归函数;而在真实系统中,问题远不止于“递归追光线”本身。工程实现还必须同时处理:
-
不同后端之间的执行特性差异
-
可复现的实验组织方式
-
面向真实资产的场景加载
-
透明材质与 cutout 材质的稳定性
-
原始结果与后处理结果之间清晰的产物归属关系
-
既适合调试,又适合最终交付的结果组织方式
当前项目正是围绕这一类更大的工程问题展开的。这里的渲染器不仅仅是一份算法实现,而是一套在统一蒙特卡洛语义下支持多执行后端、多实验流程与多种交付形式的可配置渲染平台。
2. 渲染方法
2.1 渲染目标
对于表面点 x x x 和出射方向 ω o ω_o ωo,渲染器估计的是出射辐亮度 L o ( x , ω o ) L_o(x, ω_o) Lo(x,ωo),其核心目标由渲染方程给出:
L o ( x , ω o ) = L e ( x , ω o ) + ∫ Ω + f r ( x , ω i , ω o ) L i ( x , ω i ) ∣ n x ⋅ ω i ∣ d ω i L_o(x, \omega_o) = L_e(x, \omega_o) + \int_{\Omega^+} f_r(x, \omega_i, \omega_o)\, L_i(x, \omega_i)\, |n_x \cdot \omega_i| \, d\omega_i Lo(x,ωo)=Le(x,ωo)+∫Ω+fr(x,ωi,ωo)Li(x,ωi)∣nx⋅ωi∣dωi
其中:
-
L e L_e Le 为自发光项
-
f r f_r fr 为 BRDF
-
L i L_i Li 为入射辐亮度
-
n x n_x nx 为表面法线
-
Ω + Ω^+ Ω+ 为半球积分域
在真实场景中,这一积分通常无法解析求解,因此系统采用蒙特卡洛采样进行估计。单个像素的最终结果,是多条随机路径样本的平均值。
2.2 单样本路径流程
对一个像素的一个样本,概念上的处理流程可以概括为:
-
从相机生成主光线
-
与场景求交
-
还原局部材质与几何信息
-
若命中发光体则累积自发光
-
使用 NEE 采样直接光
-
采样一条继续传播的方向
-
更新 throughput 与 PDF 相关量
-
根据终止条件结束或继续路径
这一高层流程在不同后端之间保持不变。变化的是这些步骤在执行时被怎样组织与加速。
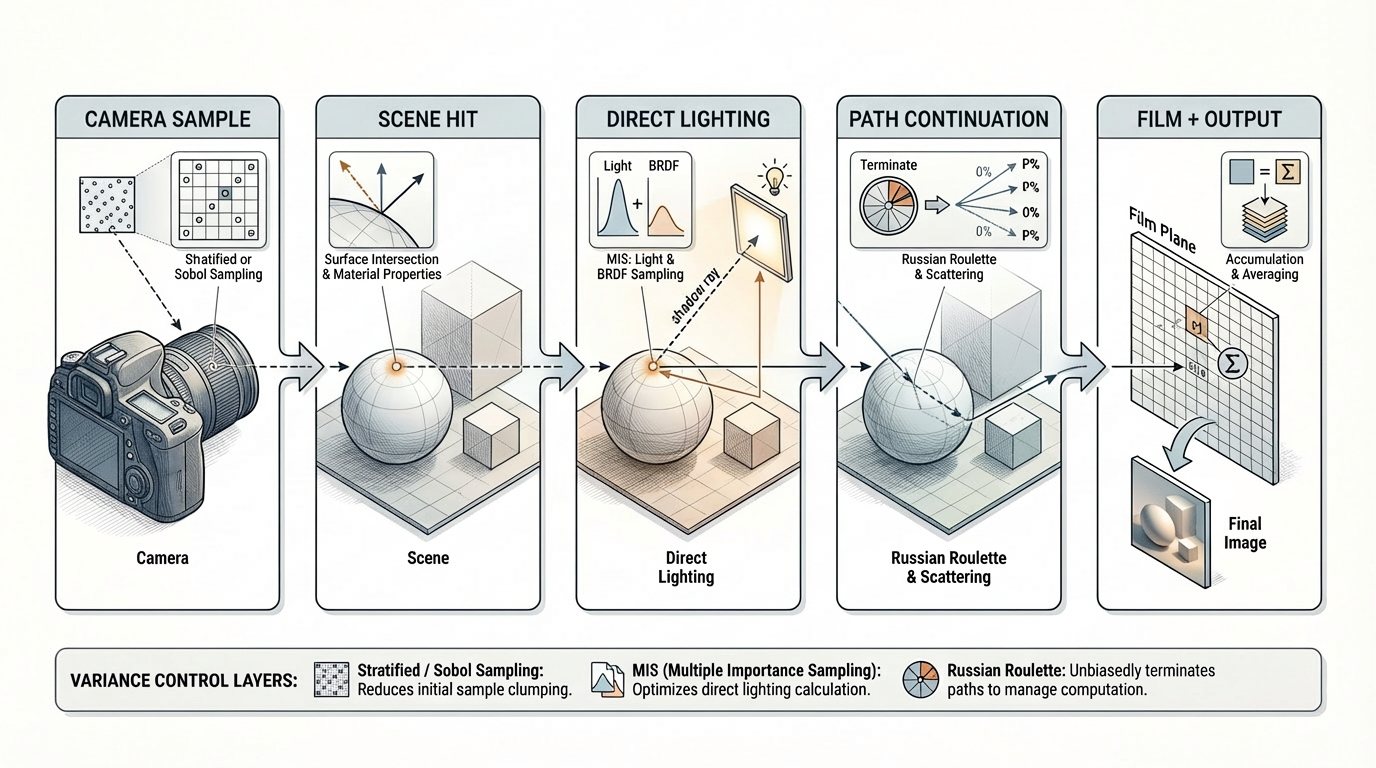
2.3 直接光与 MIS
渲染器使用 下一事件估计(NEE) 来降低直接光部分的方差。对于每个适合做直接光采样的 bounce,系统会:
-
直接采样发光体
-
做可见性判断
-
评估 BRDF 与几何项
-
将直接光贡献加回结果中
由于 BRDF 采样与光源采样都可能命中同一个传输事件,因此系统进一步使用 多重重要性采样(MIS) 来组合它们,从而在以下场景中保持较低方差:
-
小光源或高亮光源
-
光滑或高光材质
-
漫反射与镜面成分混合的场景
2.4 Russian Roulette 与 Throughput 控制
随着路径深度增加,单条路径的代价持续上升,而其贡献通常持续下降。为了限制无界路径长度带来的成本,系统在可配置深度之后引入 Russian roulette。被保留的路径会按存活概率重加权,从而在维持估计器正确性的同时降低平均计算量。
2.5 透明、折射与 Cutout 材质
在真实渲染器里,许多最常见的错误并不来自“主干路径追踪公式”,而来自透明与遮罩材质等边界情况。
透明 / 折射传输
透明材质需要正确处理:
-
反射 / 透射分支或权重
-
折射事件中的 throughput 更新
-
防止自相交的光线偏移
Alpha Cutout 行为
诸如叶片、贴图卡片和稀疏遮罩几何这类 cutout 材质,对实现的鲁棒性要求非常高。一个渲染器在大多数场景里“看起来差不多正确”,仍然可能在 foliage 场景中出现完全错误的结果。因此,本项目把 alpha-cutout 的行为视为核心设计问题,而不是事后修补的显示细节。
2.6 采样策略
系统支持多种实用采样策略:
-
伪随机采样
-
分层采样
-
Sobol / QMC 采样
-
在启用时的自适应采样
这些采样方式并不是彼此独立的“小技巧”,而是整个方差控制策略的一部分。
2.7 Recursive 与 Wavefront 执行方式
系统同时支持两种主要执行组织方式:
-
递归风格路径追踪
-
基于队列的 wavefront 风格执行
两者的估计目标相同,不同之处主要在于执行结构。这个区别在工程上非常重要:GPU 后端通常更受益于 queue-oriented 的 wavefront 组织,而 CPU 路径则往往更适合保持控制流的直接性。
3. 系统与实现
3.1 统一入口与配置模型
渲染器以 main.py 作为唯一公开入口。系统行为主要通过以下方式驱动:
-
configs/中的默认配置文件 -
命令行
key=value覆盖项 -
后端预设(backend presets)中定义的执行默认值
这里最重要的设计决策是:切换后端并不会创建“另一套渲染器程序”。相反,它是在同一个共享运行时契约下,切换具体实现。
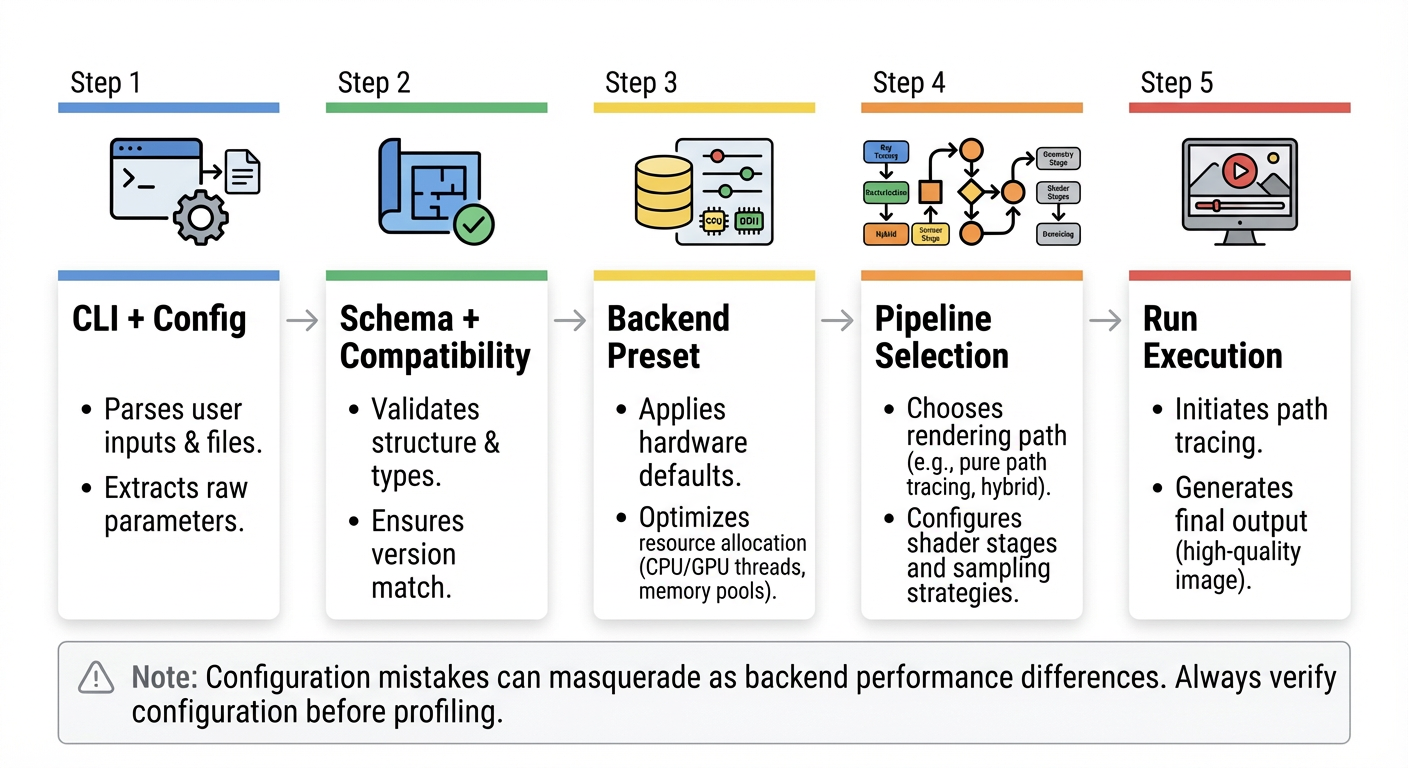
3.2 Pipeline → Step → Module 架构
项目采用三层结构组织。
Pipeline
Pipeline 决定整个运行生命周期。主要包括:
-
单次渲染 pipeline
-
并行渲染 pipeline
Step
Step 将运行拆分为清晰的阶段:
-
场景加载
-
加速结构准备
-
运行时初始化
-
渲染
-
输出写入
-
后处理 / 去噪
-
并行 dispatch / combine / timing
Module
Module 负责具体功能实现,例如:
-
场景解析
-
BVH 与求交
-
光照与 BRDF 计算
-
采样
-
Film 输出与后处理
-
并行辅助组件
这种分层使得系统既能保持可配置性,又不至于把所有责任都堆进核心路径追踪代码里。
3.3 Builders、Factories 与后端预设
Builder / Factory 层负责解析与构造运行时所需对象,包括:
-
场景加载器
-
求交器
-
Film 包装器
-
采样器
-
渲染 pipeline
-
后处理路径
后端预设在这里尤为关键。它们携带诸如:
-
batch_size -
spp_block_size -
直接 / 间接光实现选择
-
wavefront 相关开关
living-room 的纠正复跑已经证明,这些预设并不是“无关紧要的调参”。一旦错误覆盖了这些后端默认值,最终看到的性能排序就可能被配置错误而不是后端本身主导。
3.4 场景加载与归一化
场景加载不仅仅是读入几何体。它还要负责:
-
材质加载
-
纹理加载
-
opacity / cutout 贴图解释
-
相机设置
-
发光体提取
-
必要时的场景归一化
这对 living-room 与 sponza-converted 这类真实场景尤其重要,因为纹理与坐标系统的一点误读,就可能直接把最终图像推向错误结果。
3.5 加速与求交
加速层支持多种具体路径:
-
Python / torch 侧 BVH 逻辑
-
CUDA 辅助实现
-
OptiX intersector
-
C++ intersector
-
Open3D / Embree 路径
这也是项目受益于模块化设计的主要原因之一:高层渲染流程可以保持不变,而底层求交与加速实现可以切换。
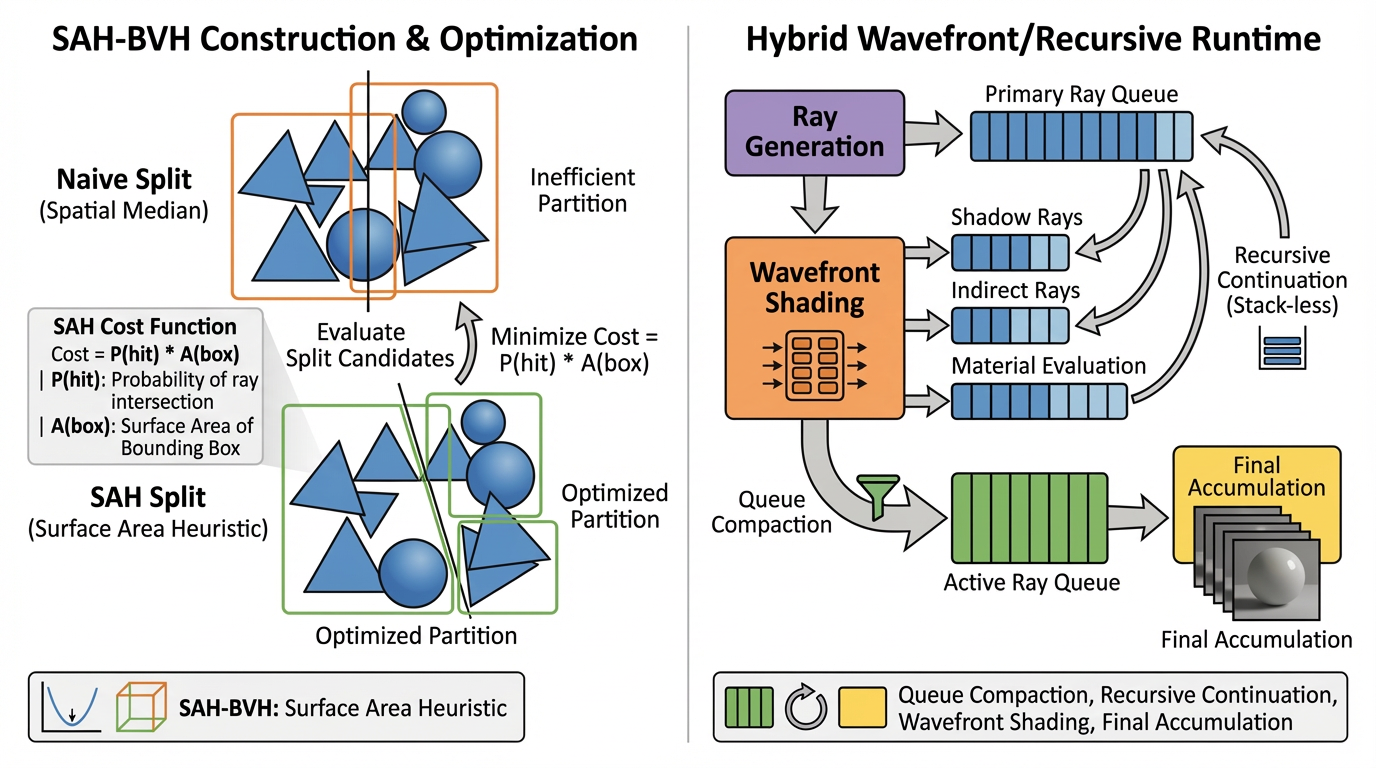
这一实现中的加速主要体现在两个层面。第一层是 SAH-BVH 构建:与朴素空间划分不同,它通过代价估计优先选择能够降低期望遍历开销的层次划分。第二层是 Wavefront / Recursive 混合执行结构:在传输语义上保持递归式的路径追踪表达,但在实际执行时允许使用更适合 GPU 调度的 wavefront 队列组织,从而兼顾表达清晰度与并行效率。
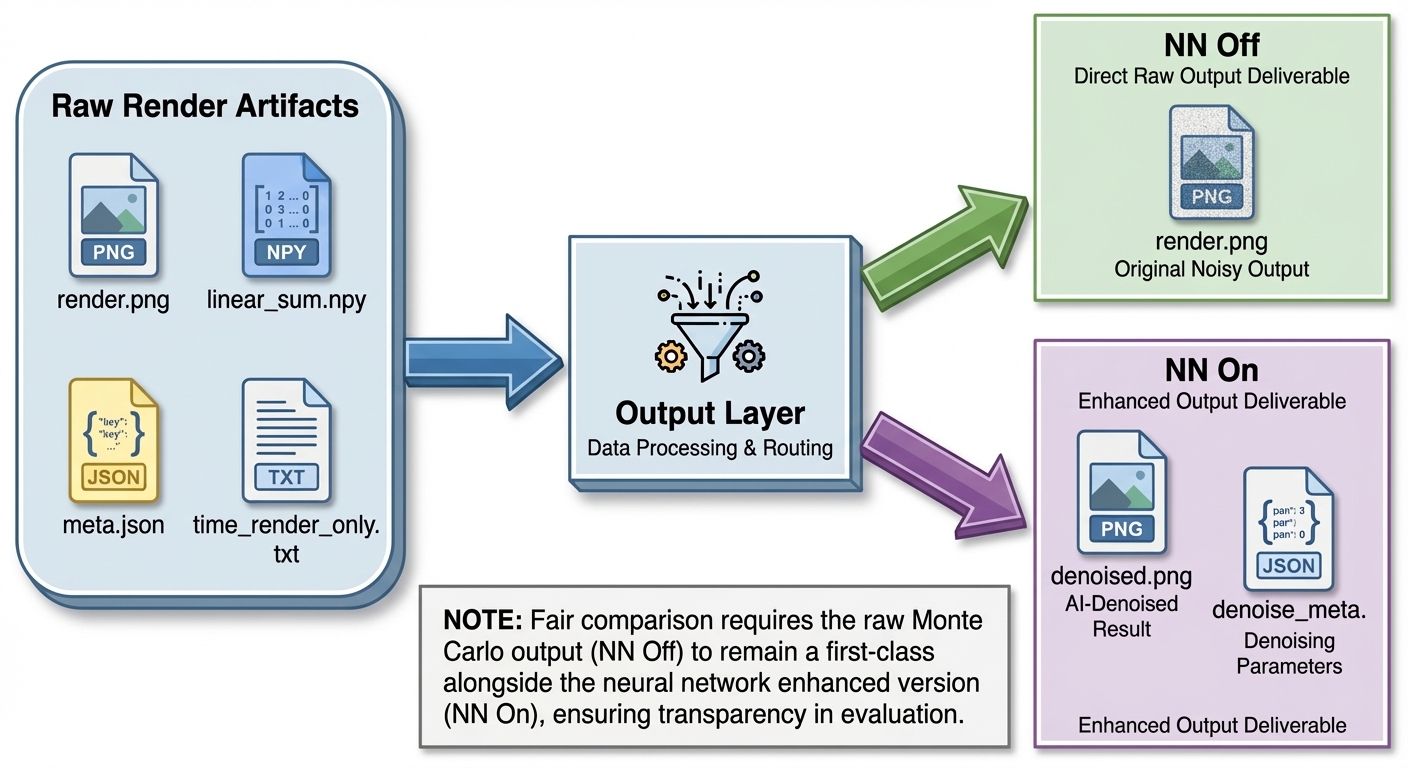
3.6 输出归属与后处理分离
当前版本的一条核心工程原则是:原始渲染产物与后处理产物必须分开管理。
原始输出通常包括:
-
render.png -
linear_sum.npy -
meta.json -
time_render_only.txt
神经 / 去噪输出则额外包括:
-
denoised.png -
denoised_linear.npy -
denoise_meta.json -
time_denoise_only.txt
这一拆分使 NN Off 与 NN On 的比较变得公平,因为后处理明确位于同一份原始渲染结果之后,而不是替代原始结果。
3.7 SPP 并行渲染
SPP 并行执行被实现为一种 pipeline 变体,而不是独立渲染器。其基本流程是:
-
将总 SPP 切分到多个 worker
-
启动多个子任务
-
合并线性输出
-
写出最终结果
-
必要时在合并层面统一做一次后处理
这样做的好处是:外层产物契约可以保持稳定,而并行吞吐能力可以作为调度层扩展被加入系统。
4. 实验设置
4.1 硬件与运行背景
本文实验基于仓库中已验证的历史结果包,以及对 living-room 的纠正 GPU 复跑结果。这里的目标不是给出一个“完全独立于机器”的绝对时间表,而是在受控环境下分析不同后端在不同场景中的相对行为。
4.2 后端分组
实验中区分两大设备族:
-
GPU:
torch、cuda、optix -
CPU:
openmp、cpp
在图中,当分成 GPU / CPU 两张图能明显提升可读性时,会优先采用分图展示。
4.3 场景集合
本文主要覆盖四个场景:
-
living-room -
veach-mis -
cornell-box -
sponza
它们分别强调了不同的几何复杂度、光照结构与材质敏感性。
4.4 结果报告规则
全文统一使用如下术语:
-
NN Off = 原始渲染输出
-
NN On = 基于同一份原始结果得到的后处理 / 去噪输出
-
render-only = 核心渲染耗时
-
wall = 对应该产物的总墙钟时间
缺失结果会被显式展示,而不会被隐式省略。
5. 分场景结果分析
5.1 living-room
本节中的 GPU 结果已根据叶片 alpha-cutout 修复后的纠正复跑更新;CPU 图仍引用早期版本中已验证的 CPU 结果包。
GPU 总览

CPU 总览

ROI 分析

100 spp 时间摘要
| 后端 | 原始 wall | 原始 wall/spp | 神经 wall | 神经 wall/spp |
|---|---|---|---|---|
| Torch | 25.58 s | 0.2558 | 25.71 s | 0.2571 |
| CUDA | 25.20 s | 0.2520 | 25.34 s | 0.2534 |
| OptiX | 14.17 s | 0.1417 | 14.30 s | 0.1430 |
| OpenMP | 37.16 s | 0.3716 | 37.61 s | 0.3761 |
| C++ | 753.91 s | 7.5391 | 770.43 s | 7.7043 |
GPU Render-Only 摘要
| SPP | Torch | CUDA | OptiX |
|---|---|---|---|
| 100 | 20.51 s | 20.02 s | 8.54 s |
| 1000 | 186.34 s | 156.35 s | 105.90 s |
| 10000 | 1806.94 s | 1553.81 s | 854.74 s |
分析
living-room 是全文中对 masked foliage 与 alpha-cutout 最敏感的场景。纠正后的 GPU 复跑让一个关键结论变得非常明确:在 100 / 1000 / 10000 spp 下,三条 GPU 路径都已经恢复了正确的叶片透明轮廓,先前那种发白、发实的 foliage 回归现象不再存在。
修正后的速度排序同样值得强调。在当前正确配置下,OptiX 在三个代表性 SPP 档位上都保持最快,CUDA 稳定第二,Torch 第三。这个结果很好地说明:渲染报告必须把“后端行为”和“配置错误”分开分析。此前出现过的“高 SPP 下 CUDA 反超 OptiX”的故事,并不是稳定的后端结论,而是慢配置覆盖导致的假象。
在这个场景中,神经后处理的价值主要体现在轻量但明显的去噪作用上。其额外代价相对于核心渲染时间极小,因此它更改变的是观感,而不是吞吐排序。
5.2 veach-mis
GPU 总览

CPU 总览

ROI 分析

100 spp 时间摘要
| 后端 | 原始 wall | 原始 wall/spp | 神经 wall | 神经 wall/spp |
|---|---|---|---|---|
| Torch | 6.39 s | 0.0639 | 6.64 s | 0.0664 |
| CUDA | 5.53 s | 0.0553 | 6.19 s | 0.0619 |
| OptiX | 5.03 s | 0.0503 | 5.43 s | 0.0543 |
| OpenMP | 17.42 s | 0.1742 | 17.71 s | 0.1771 |
| C++ | 164.69 s | 1.6469 | 165.29 s | 1.6529 |
分析
更新后的 veach-mis 分析不再关注球体边缘,而是聚焦在黑色反射平面上的红色反光区域。这块区域比普通边缘裁剪更有信息量,因为它同时反映了弱色光泄漏、低样本噪声分布以及反射形状收敛过程。
100 / 1000 / 10000 spp 的三列对比使收敛趋势非常直观。无论在 GPU 组别还是 CPU 组别里,最终的红色反射结构都高度一致;差别主要在于各后端达到这一结构的速度。OptiX 在这个场景中保持最快,这与其在几何查询主导型负载下的表现一致。
5.3 cornell-box
GPU 总览

CPU 总览

ROI 分析

100 spp 时间摘要
| 后端 | 原始 wall | 原始 wall/spp | 神经 wall | 神经 wall/spp |
|---|---|---|---|---|
| Torch | 9.15 s | 0.0915 | 9.26 s | 0.0926 |
| CUDA | 8.08 s | 0.0808 | 8.75 s | 0.0875 |
| OptiX | 6.23 s | 0.0623 | 8.04 s | 0.0804 |
| OpenMP | 23.58 s | 0.2358 | 22.17 s | 0.2217 |
| C++ | 314.19 s | 3.1419 | 315.90 s | 3.1590 |
分析
cornell-box 在结构上最规整,因此非常适合观察“实现是否稳定”而不是“场景是否复杂”。当前总览图采用了等比例 letterbox 显示,因此方形图像不会再被压扁到横向单元格中。这个细节本身很重要:如果文档展示时就把图像形变了,读者很容易误判不同后端之间的差异。
新的 ROI 面板聚焦在兔子眼睛与面颊高光区域,并使用 100 / 1000 / 10000 spp 三列对比。这个 ROI 同时能反映轮廓稳定性与局部高光结构,因此非常适合用来比较不同后端在高频细节上的收敛过程。总体趋势依旧清晰:OptiX 在此场景中保持最稳定的性能领先,而 CPU 路径虽然更慢,但几何和亮度语义保持一致。
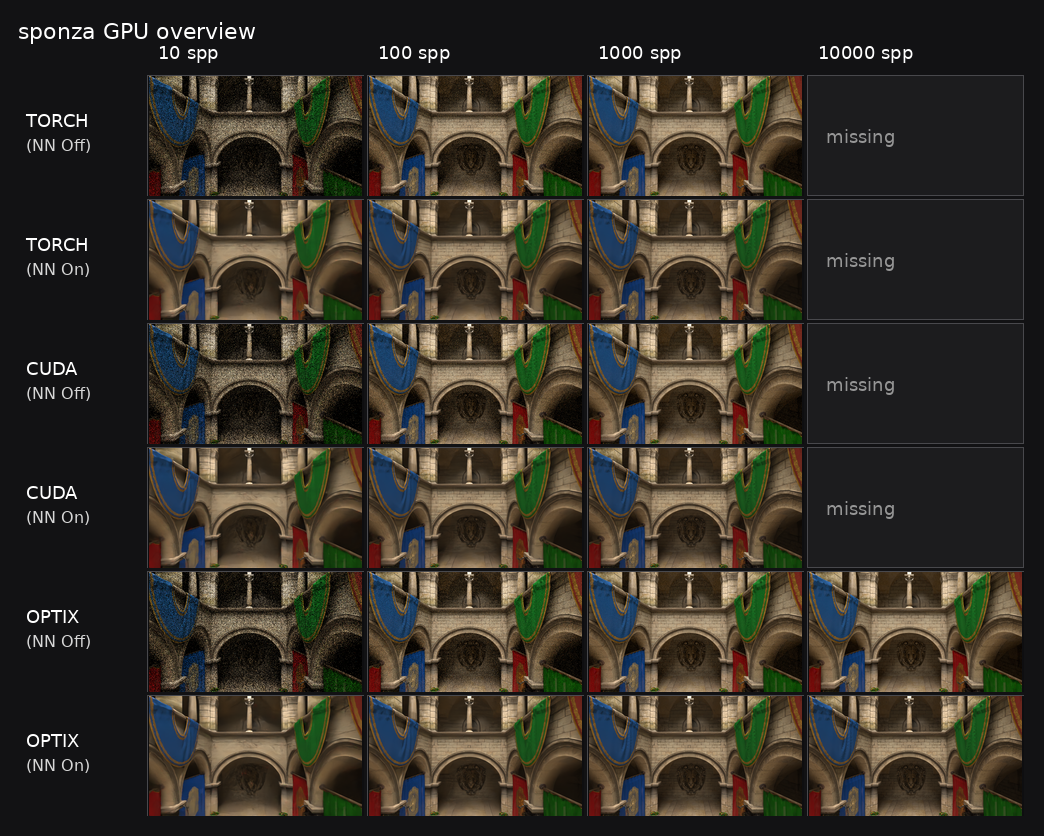
5.4 sponza
sponza 仍然是覆盖最不完整的场景。当前仓库已经为已有的 GPU neural_off 结果补齐了 neural_on,但 sponza-converted 仍缺失完整的 CPU 验证结果,而且历史补充集里仍缺 torch/cuda @ 10000 spp 的原始 GPU 成品。
GPU 总览
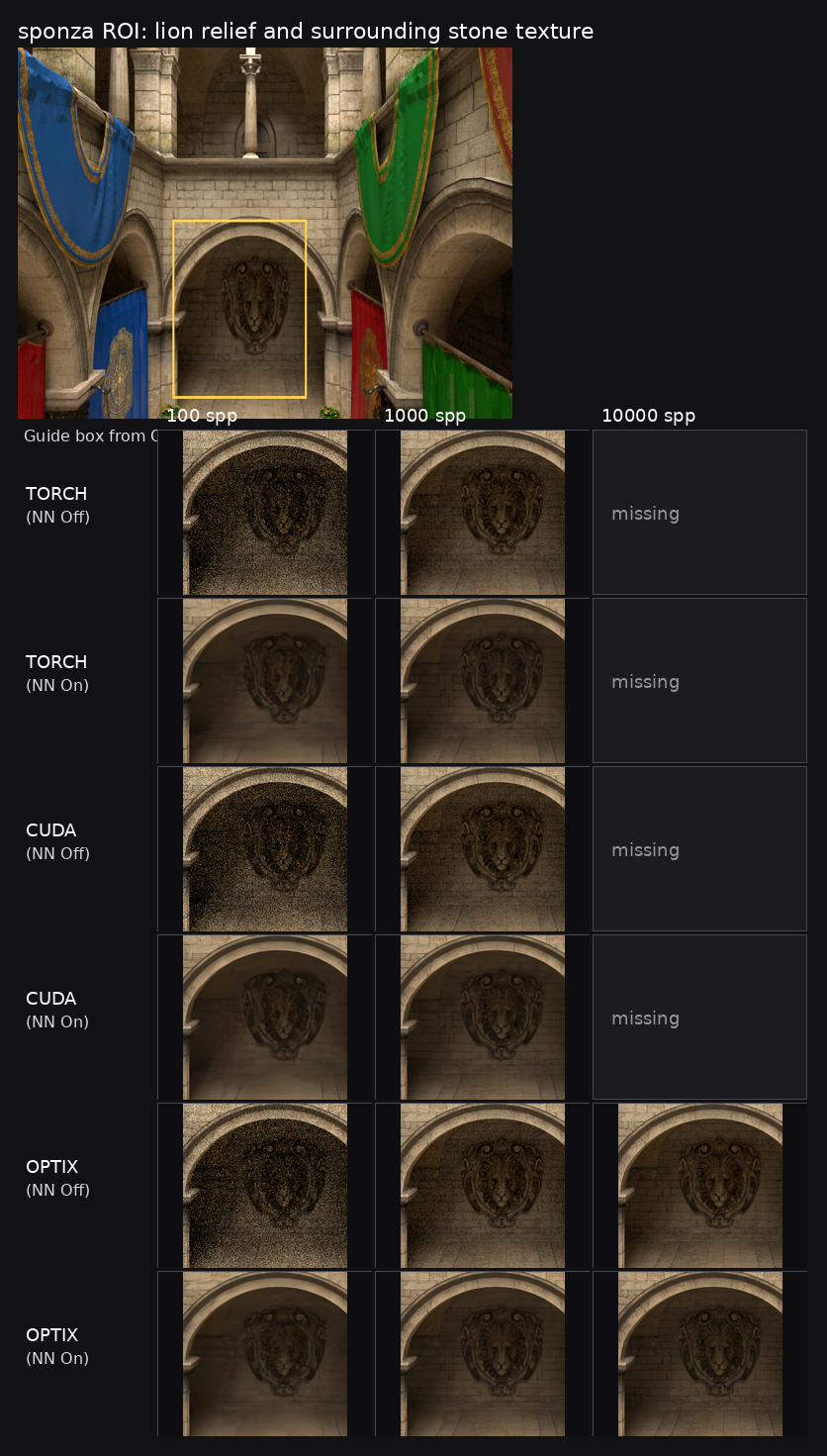
ROI 分析
100 spp 时间摘要
| 后端 | 原始 wall | 原始 wall/spp | 神经 wall | 神经 wall/spp |
|---|---|---|---|---|
| Torch | 110.25 s | 1.1025 | 110.38 s | 1.1038 |
| CUDA | 85.85 s | 0.8585 | 85.97 s | 0.8597 |
| OptiX | 10.71 s | 0.1071 | 10.83 s | 0.1083 |
| OpenMP | — | — | — | — |
| C++ | — | — | — | — |
分析
sponza 更强调大面积纹理、重复几何与空间频率变化,因此本节 ROI 选在中央狮面浮雕及其周围石材纹理区域,从而同时考察高频纹理噪声与结构衰减。
6. 跨场景讨论
当前结果集中,有几个趋势相当稳定。
第一,OptiX 是最稳定、最一致的高性能后端。在多个场景中,它都表现出最低或接近最低的 wall time,尤其是在几何查询主导的场景里优势非常直接。
第二,CUDA 依然是一条很强的 GPU 路径。在修正后的 living-room 复跑中,它仍然明显快于 Torch;但在正确配置下,它并没有在高 SPP 条件下超过 OptiX。
第三,Torch 仍然具有重要价值。它更适合作为原型验证、调试与算法试验路径,虽然在大场景和高 SPP 下运行成本更高,但其语义上与高性能后端保持一致。
第四,CPU 路径的主要价值不是吞吐,而是结构参考。即便它们远慢于 GPU 路径,它们仍然在验证几何一致性、检查结果语义以及提供对照上扮演重要角色。
最后,神经后处理的收益高度依赖场景。在 living-room 中,它在 foliage 和亮墙过渡区域上的轻量去噪最明显;在 cornell-box 中,它更接近一种轻量 polish。关键点在于:它主要改变的是图像观感,而不是后端性能排序本身。
7. AI 协同工程组织
整个工作流自然分化出若干角色:
-
director:维护长时上下文、协调任务并汇报结果 -
algorithm engineer:分析方法质量、瓶颈和下一步方向 -
prototype / validation:实现修改、运行实验并验证输出 -
sync / port:将已验证的改动同步到相邻路径或版本 -
document manager:维护文档、上下文与项目状态 -
architect:检查代码是否仍符合预期架构与设计原则
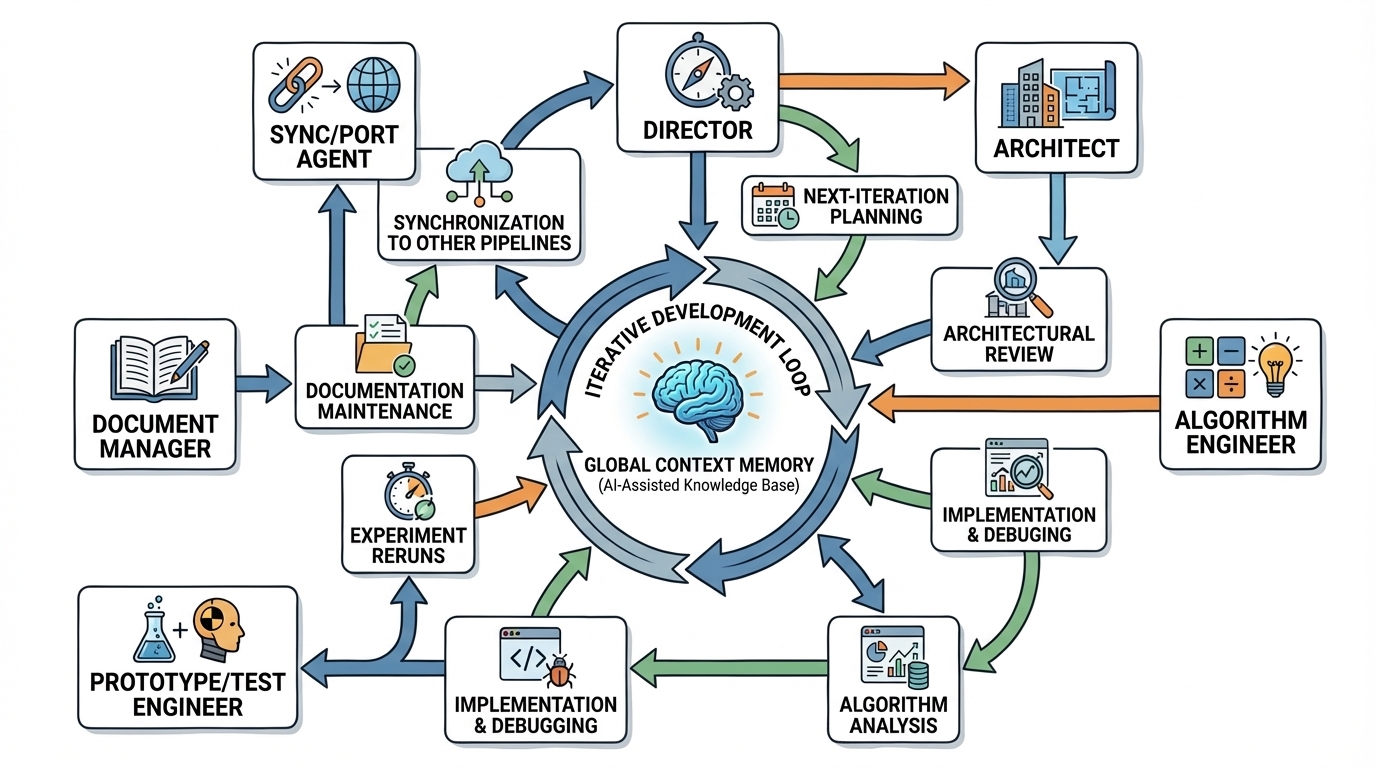
这张图强调的是编程迭代工作流,而不是后期单纯的文档润色流程。它展示了:持久上下文、算法诊断、实现与调试、实验复跑、同步移植、文档维护以及架构审查如何共同构成一个闭环。
对于本文档本身,工作流又额外引入了三类全篇级审稿视角:
-
配图与视觉一致性审稿
-
可交付性 / 最终版本质量审稿
-
可读性与技术深度审稿

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)