【AI大模型前沿】腾讯 Youtu-LLM:轻量级语言模型的高性能突破
系列篇章💥
目录
前言
随着人工智能技术的飞速发展,大语言模型(LLM)在各个领域展现出巨大的潜力。然而,传统的大型语言模型往往面临着参数规模庞大、计算资源消耗高、部署困难等问题。腾讯 Youtu 团队开源的 Youtu-LLM,以其轻量级的架构和强大的智能体能力,为这些问题提供了一种创新的解决方案。
一、项目概述
Youtu-LLM 是腾讯 Youtu 团队开源的轻量级语言模型,参数规模为 19.6 亿。它专为智能体任务设计,具备强大的“原生智能体能力”,在多项任务中超越同规模甚至更大模型。模型采用紧凑架构和 128K 长上下文窗口,支持长程任务处理,并针对 STEM 领域优化词表,提升推理效率。
二、核心功能
(一)强大的智能体能力
Youtu-LLM 拥有原生智能体能力,能够自主规划和执行复杂任务。它可以在多轮交互中根据反馈调整策略,适合处理需要多步骤推理和决策的任务,如自动化研究和复杂问题解决。
(二)高效推理与长上下文支持
该模型采用紧凑架构,支持 128K 上下文窗口,适合长程任务处理。这使得它在处理复杂代码修复、多跳问答等需要长文本理解和生成的任务中表现出色,同时保持高效的推理速度。
(三)优化的 STEM 词表
Youtu-LLM 针对 STEM 领域进行了优化,其 128K 词表设计提升了数学和代码等专业领域的推理效率。这使得模型在处理技术文档、代码生成和数学推理任务时更加高效。
(四)系统性预训练课程
模型从零开始预训练,分为常识阶段、STEM 聚焦阶段和智能体中训阶段。这种分阶段的预训练方式逐步提升模型的推理和规划能力,使其在多种任务中表现出色。
(五)高质量智能体轨迹数据
Youtu-LLM 引入大量高质量的智能体轨迹数据,涵盖数学推理、代码修复和深度研究等场景。这些数据强化了模型在智能体任务中的表现,使其能够更好地处理复杂的多步骤任务。
(六)开源与灵活部署
Youtu-LLM 全面开源,支持 Base 和 Instruct 版本,并提供微调工具。这使得开发者可以根据需求进行定制化开发,并在资源受限的场景中灵活部署。
三、技术揭秘
(一)紧凑架构与长上下文
Youtu-LLM 采用了先进的 Dense MLA 架构,支持 128K 的长上下文窗口。这种架构设计不仅能够高效处理长文本任务,如复杂代码修复和多跳问答,还能在保持轻量级参数规模的同时,提供强大的推理能力。
(二)优化的分词器设计
针对 STEM 领域的特殊需求,Youtu-LLM 设计了 128K 的优化词表。这种设计显著提升了在数学、代码等专业领域的 token 压缩率和推理效率,使得模型在处理技术性任务时表现更为出色。
(三)三阶段预训练课程
Youtu-LLM 采用独特的三阶段预训练课程:常识学习、STEM 聚焦和智能体中训。这种分阶段的训练方式逐步提升模型的推理和规划能力,使其能够更好地适应复杂任务。
(四)智能体轨迹合成
模型引入了大量高质量的智能体轨迹数据,涵盖数学推理、代码修复和深度研究等场景。这些数据强化了模型在智能体任务中的表现,使其能够更好地处理复杂的多步骤任务。
(五)创新的训练范式
Youtu-LLM 通过“常识 → STEM → 智能体”的课程式训练,让模型逐步内化规划、执行和反思的能力。这种创新的训练范式实现了轻量级模型的高性能表现,使其在智能体任务中表现优异。
四、性能表现
在常识、STEM、编码和长上下文维度上对基座模型和指令模型进行评估。Youtu-LLM 2B 基座模型在通用能力上显著优于同尺寸基线,并与更大的 Qwen3-4B 基座模型表现相当。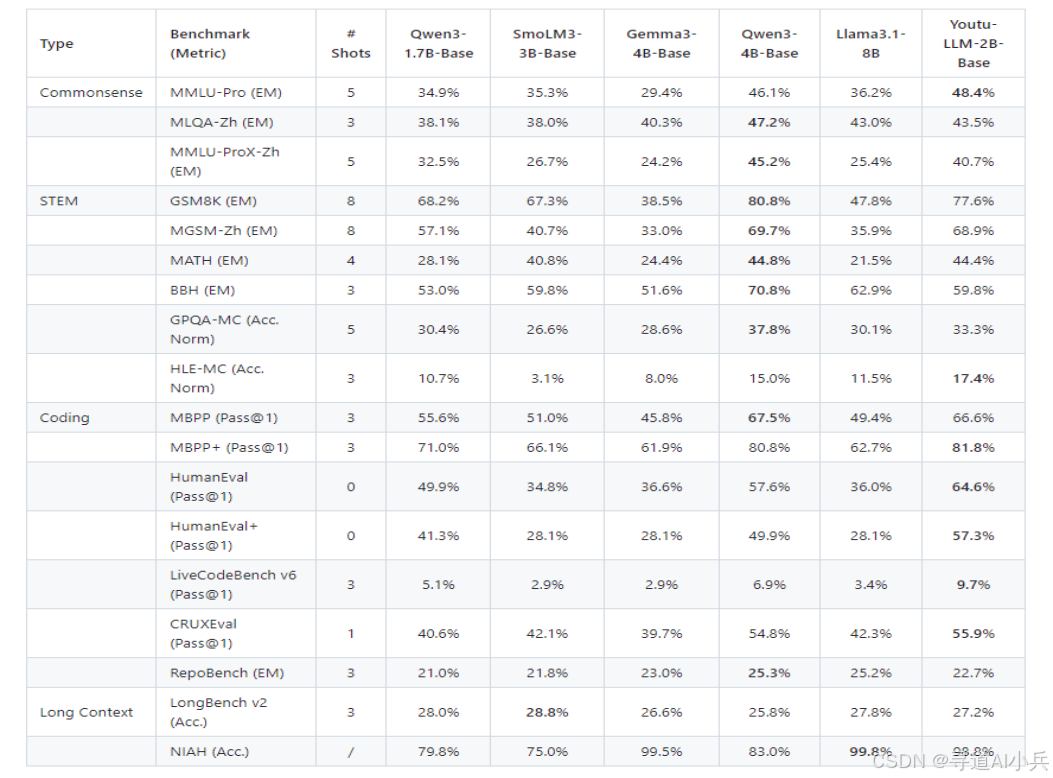
五、应用场景
(一)代码助手
Youtu-LLM 能够深度理解复杂代码库的结构,快速定位并修复代码中的错误。它还可以根据项目规范自动生成高质量的代码片段,极大地提高了软件开发的效率。无论是初学者还是资深开发者,都可以借助 Youtu-LLM 完成代码优化、自动化测试等任务,提升软件工程的整体质量。
(二)研究助手
在学术研究和文献综述中,Youtu-LLM 能够支持多跳问答和深度知识推理。它可以整合大量文献信息,自动生成研究报告,辅助学术写作。这使得研究人员能够更高效地进行知识探索和论文撰写,提升研究效率。
(三)通用智能体
Youtu-LLM 可以作为个人 AI 助手,自动化处理日常任务。它能够实现多工具协同工作,分解并执行复杂的任务序列。例如,它可以自动安排日程、处理邮件、执行数据整理等工作,成为用户生活和工作中的得力助手。
(四)边缘部署
由于参数量较小,Youtu-LLM 特别适合在消费级 GPU、移动端和边缘设备上运行。它能够提供低延迟、低成本的推理服务,尤其适用于隐私敏感场景的本地部署。例如,在智能家居、智能医疗等场景中,Youtu-LLM 可以实现高效的数据处理和隐私保护。
(五)多跳推理与总结
Youtu-LLM 能够解决需要多步推理的复杂问题,如深度关联分析和因果推理。它能够从大量信息中提取关键内容,生成简洁准确的总结。这使得它在处理复杂信息和知识密集型任务时表现出色,例如企业知识库问答和深度市场分析。
(六)知识密集型任务
Youtu-LLM 高效处理依赖大量结构化知识的问题,如企业知识库问答和技术文档深度解析。它能够快速理解并提取关键信息,为用户提供精准的答案和解决方案。这使得它在企业内部知识管理、技术文档支持等场景中具有广泛的应用前景。
六、快速使用
(一)环境准备
确保你的开发环境已安装 Python(推荐 Python 3.8 及以上版本)和 PyTorch 框架。此外,还需要安装一些依赖库,如 transformers 和 accelerate。可以通过以下命令安装:
pip install "transformers>=4.56.0,<=4.57.1" torch accelerate
(二)推理示例
以下示例展示了如何加载模型、启用推理模式,并使用 re 模块从输出中解析"思考过程"和"最终答案"。
import re
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. Configure Model
model_id = "tencent/Youtu-LLM-2B"
# 2. Initialize Tokenizer and Model
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
trust_remote_code=True
)
# 3. Construct Dialogue Input
prompt = "Hello"
messages = [{"role": "user", "content": prompt}]
# Use apply_chat_template to construct input; set enable_thinking=True to activate Reasoning Mode
input_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([input_text], return_tensors="pt").to(model.device)
print("Input prepared. Starting generation...")
# 4. Generate Response
outputs = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=True,
temperature=1.0,
top_k=20,
top_p=0.95,
repetition_penalty=1.05
)
print("Generation complete!")
# 5. Parse Results
full_response = tokenizer.decode(outputs[0], skip_special_tokens=True)
def parse_reasoning(text):
"""Extract thought process within <think> tags and the subsequent answer content"""
thought_pattern = r"<think>(.*?)</think>"
match = re.search(thought_pattern, text, re.DOTALL)
if match:
thought = match.group(1).strip()
answer = text.split("</think>")[-1].strip()
else:
thought = "(No explicit thought process generated)"
answer = text
return thought, answer
thought, final_answer = parse_reasoning(full_response)
print(f"\n{'='*20} Thought Process {'='*20}\n{thought}")
print(f"\n{'='*20} Final Answer {'='*20}\n{final_answer}")
七、结语
Youtu-LLM 以其轻量级的架构和强大的性能,为大语言模型的应用和部署提供了新的思路。它不仅在智能体任务中表现出色,还在多个领域展现了广泛的应用潜力。希望本文的介绍能够帮助读者更好地了解 Youtu-LLM,并在实践中探索其更多可能。
八、项目地址
- 项目官网:https://youtu-tip.com/#llm
- Github 仓库:https://github.com/TencentCloudADP/youtu-tip/tree/master/youtu-llm

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)