基于知识图谱的电力工程文档智能审查系统设计与实现【源码+文档】
摘 要
随着电力配网业扩工程项目数量的快速增长,传统的人工文档审查模式面临着效率低下、一致性差、专业要求高等诸多挑战。本文设计并实现了一个基于知识图谱和大语言模型的电力工程文档智能审查系统,旨在提升文档审查的自动化水平和准确性。系统采用多层架构设计,核心包括知识图谱构建模块、文档解析模块、智能审查代理和报告生成模块四个关键组件。
在知识图谱构建方面,系统通过结合基于规则的正则表达式匹配和基于深度学习的大语言模型增强提取技术,从电力工程技术导则中自动提取实体和关系,构建包含技术标准、设计规范、材料规格、施工要求、安全规定、质量标准等多类型实体的领域知识图谱。系统使用NetworkX构建多重有向图结构,支持复杂的实体关系建模,并通过GraphML和JSON双格式存储确保数据的持久化和可视化需求。
在文档智能解析层面,系统集成PyMuPDF和pdfplumber双引擎PDF解析技术,实现对电力工程文档的深度结构化提取,包括章节识别、表格提取和元数据解析。通过正则表达式模式匹配技术,系统能够准确识别多达七种不同的章节标题格式,自动构建文档的层次化结构树,为后续的语义分析奠定基础。
在智能审查核心算法方面,系统基于LangGraph构建了多节点工作流图,将文档审查任务分解为文档解析、关键点提取、知识图谱查询、合规性检查和改进建议生成五个串行节点。系统采用Sentence-BERT模型进行语义嵌入,实现了基于余弦相似度的高效语义检索,检索准确率显著优于传统关键词匹配方法。合规性检查模块通过设计专门的提示工程模板,引导大语言模型根据知识图谱中的标准要求对文档内容进行深度分析,自动识别不合规项、合规项并评估问题严重程度。
系统还实现了基于Flask的Web应用架构和基于SQLite的任务管理机制,支持多文档并发上传、异步任务处理和实时进度追踪。报告生成模块采用模板驱动的智能填充策略,通过大语言模型从多源文档中提取项目概况、项目规模、技术详情并进行跨文档一致性验证,最终生成符合行业规范的结构化审查报告。
关键词: 知识图谱,大语言模型,文档智能审查,LangGraph,语义检索,电力工程
Abstract
With the rapid growth in the number of power distribution network expansion projects, traditional manual document review processes face numerous challenges including low efficiency, poor consistency, and high professional requirements. This paper designs and implements an intelligent power engineering document review system based on knowledge graphs and large language models, aiming to enhance the automation level and accuracy of document review. The system adopts a multi-layer architecture design, with four core components: knowledge graph construction module, document parsing module, intelligent review agent, and report generation module.
In knowledge graph construction, the system combines rule-based regular expression matching with deep learning-based large language model enhanced extraction techniques to automatically extract entities and relationships from power engineering technical guidelines. It constructs a domain knowledge graph containing multiple entity types including technical standards, design specifications, material specifications, construction requirements, safety regulations, and quality standards. The system uses NetworkX to build a multi-directed graph structure, supporting complex entity relationship modeling, and ensures data persistence and visualization requirements through dual-format storage in GraphML and JSON.
In intelligent document parsing, the system integrates dual-engine PDF parsing technology with PyMuPDF and pdfplumber to achieve deep structured extraction of power engineering documents, including chapter recognition, table extraction, and metadata parsing. Through regular expression pattern matching technology, the system can accurately identify up to seven different chapter title formats and automatically construct a hierarchical document structure tree, laying the foundation for subsequent semantic analysis.
In the core intelligent review algorithm, the system builds a multi-node workflow graph based on LangGraph, decomposing the document review task into five serial nodes: document parsing, key point extraction, knowledge graph query, compliance checking, and improvement suggestion generation. The system employs the Sentence-BERT model for semantic embedding, implementing efficient semantic retrieval based on cosine similarity, with retrieval accuracy significantly superior to traditional keyword matching methods. The compliance checking module designs specialized prompt engineering templates to guide large language models in conducting in-depth analysis of document content based on standard requirements in the knowledge graph, automatically identifying non-compliant items, compliant items, and assessing issue severity.
The system also implements a Flask-based web application architecture and SQLite-based task management mechanism, supporting concurrent multi-document upload, asynchronous task processing, and real-time progress tracking. The report generation module adopts a template-driven intelligent filling strategy, using large language models to extract project overviews, project scale, technical details from multi-source documents, and perform cross-document consistency verification, ultimately generating structured review reports compliant with industry standards.
Keywords: Knowledge Graph, Large Language Model, Intelligent Document Review, LangGraph, Semantic Retrieval, Power Engineering
目 录
第一章 绪论
1.1 研究背景和意义
随着中国电力行业的快速发展和城市化进程的持续推进,配电网络建设规模不断扩大,电力配网业扩工程项目数量呈现爆发式增长态势。在电力工程项目实施过程中,技术文档的审查工作扮演着至关重要的角色,其审查质量直接关系到工程的安全性、合规性和经济性。传统的电力工程文档审查主要依赖人工方式进行,审查人员需要根据多达数百页的技术导则和行业规范,逐项核对设计说明书、材料清册、供电方案审核单等多类文档的合规性。这种审查模式存在诸多局限性。
首先是效率问题。一个典型的配网业扩工程项目涉及的文档页数通常在数十到数百页之间,人工审查一个项目往往需要数小时甚至数天时间。随着项目数量的增加,审查人员的工作负荷呈线性甚至指数级增长,难以满足日益增长的工程审查需求。其次是一致性问题。不同审查人员由于专业背景、工作经验和理解偏差的差异,对同一技术标准的解读和执行可能存在差异,导致审查结果的一致性难以保证。这种不一致性不仅影响审查质量,也可能引发工程后续实施中的纠纷。再次是准确性问题。技术导则和行业规范内容庞杂,涉及电气设计、材料规格、施工要求、安全规定、质量标准等多个维度,审查人员需要在短时间内检索大量规范条文,容易出现遗漏或误判。
更为关键的是知识管理问题。电力工程领域的技术标准和规范不断更新迭代,新的技术要求和设计规范层出不穷。传统的纸质文档和电子文档管理方式难以实现知识的结构化组织和高效检索,审查人员需要花费大量时间在文档中定位相关条款,知识复用率低。此外,专业审查人员的培养周期长,新入职人员往往需要数年时间才能熟练掌握各类技术规范,人才培养成本高。
在这样的背景下,将人工智能技术应用于电力工程文档审查领域具有重要的理论意义和实际价值。从理论角度看,电力工程文档审查问题为知识图谱构建、自然语言处理和智能推理等人工智能技术提供了典型的应用场景。电力工程领域具有知识密集、规则明确、逻辑严密的特点,技术导则中蕴含的实体关系和约束规则可以很好地映射为知识图谱的图结构,为知识表示和推理研究提供了理想的实验平台。同时,文档审查任务涉及文本理解、信息抽取、语义匹配、一致性检查等多个自然语言处理子任务,为多模态智能系统的构建提供了研究价值。
从实践角度看,智能化的文档审查系统能够显著提升审查效率,将原本需要数小时的审查过程缩短至数分钟,极大地减轻了审查人员的工作负担。系统基于统一的知识图谱和审查规则进行判断,能够确保审查标准的一致性,避免人为因素导致的判断偏差。通过将领域知识结构化存储在知识图谱中,系统能够快速检索相关技术规范,减少人工查阅文档的时间成本,提高知识复用效率。对于技术标准的更新,只需更新知识图谱即可同步到所有审查任务,实现知识的集中管理和快速迭代。更重要的是,智能审查系统能够生成详细的审查报告,记录每一项检查结果和判断依据,实现审查过程的可追溯性,为工程质量管理提供了有力支撑。
本研究针对电力配网业扩工程文档审查的实际需求,设计并实现了一个基于知识图谱和大语言模型的智能审查系统,旨在解决传统人工审查模式面临的效率、一致性和准确性问题,为电力行业的数字化转型和智能化升级提供技术支撑和实践经验。
1.2 国内外研究现状
知识图谱技术自2012年Google提出以来,在学术界和工业界都得到了广泛的关注和应用。在垂直领域知识图谱构建方面,研究者们进行了大量探索。Chen等人提出了一种面向医疗领域的知识图谱构建方法,通过结合规则匹配和深度学习技术从医疗文献中自动抽取疾病、症状、药物等实体及其关系,构建了包含数百万实体的医疗知识图谱[4]。该研究表明,领域知识图谱的构建需要充分考虑领域特征,结合多种技术手段才能达到较好的效果。Wang等人针对法律领域提出了基于BERT的法律实体识别和关系抽取方法,通过预训练语言模型捕获法律文本的语义特征,显著提升了法律知识图谱的构建质量[5]。这些研究为本文在电力工程领域构建知识图谱提供了方法论指导。
在文档智能处理方面,PDF文档的结构化提取一直是研究热点。Li等人提出了LayoutLM模型,通过联合学习文本、布局和图像信息,实现了对复杂文档的深度理解[6]。该模型在表格检测、表单理解等任务上取得了显著性能提升。Xu等人进一步提出了LayoutLMv3,引入了统一的文本图像多模态预训练框架,在文档问答、信息抽取等任务上达到了最先进水平[7]。这些研究成果为本文的PDF文档解析模块提供了技术参考,但电力工程文档具有其特殊性,需要针对性地设计章节识别和结构化提取策略。
语义检索技术是知识图谱应用的关键环节。Reimers和Gurevych提出的Sentence-BERT模型通过改进BERT的训练方式,使其能够生成高质量的句子嵌入向量,显著提升了语义相似度计算的效率和准确性[8]。该模型在语义搜索、文本聚类等任务上表现优异,已成为主流的语义嵌入方法。Karpukhin等人提出的DPR(Dense Passage Retrieval)方法将检索问题建模为向量空间中的最近邻搜索,在开放域问答任务上取得了突破性进展[9]。本研究借鉴这些语义检索技术,设计了基于余弦相似度的知识图谱查询机制。
大语言模型的快速发展为智能文档处理带来了新的机遇。OpenAI推出的GPT系列模型展现了强大的自然语言理解和生成能力,在多个自然语言处理任务上达到或超过了人类水平。Brown等人通过GPT-3模型展示了大规模预训练语言模型的少样本学习能力,无需针对特定任务进行微调即可完成多种复杂任务[1]。Meta公司开源的LLaMA模型以及阿里云推出的通义千问模型等,为研究者提供了更多选择。这些大语言模型在文本分类、信息抽取、文本生成等任务上表现出色,为本研究的关键点提取、合规性检查和报告生成等模块提供了技术基础。
在工作流编排和智能体构建方面,LangChain和LangGraph框架的出现为复杂AI应用的开发提供了便利。LangChain提供了一套完整的工具链,支持大语言模型与外部数据源、工具的集成,简化了LLM应用的开发流程[2]。LangGraph进一步扩展了LangChain的能力,引入了状态图的概念,使得复杂的多步骤推理和决策过程可以通过图结构直观地表达和执行[3]。Chase在其关于LangGraph的论文中详细阐述了状态机驱动的AI工作流设计模式,为本研究的智能审查代理提供了架构设计思路[3]。
在电力工程领域的智能化应用方面,国内外也有一些研究工作。Zhang等人提出了基于深度学习的电力设备故障诊断方法,通过分析传感器数据实现故障的自动识别[10]。Liu等人研究了电力系统运行数据的知识图谱构建方法,用于辅助电网调度决策[11]。然而,针对电力工程文档智能审查的研究相对较少。国家电网公司发布的《配网工程数字化管理平台建设指南》中提出了文档智能审查的需求,但尚未见到成熟的技术方案公开发表[12]。国内一些电力设计院开始尝试将OCR和规则匹配技术应用于图纸审查,但由于缺乏系统的知识表示和推理能力,效果有限。
综合国内外研究现状可以看出,知识图谱、大语言模型和智能工作流编排等技术已相对成熟,为本研究提供了坚实的技术基础。然而,这些技术在电力工程文档审查领域的系统性应用仍处于探索阶段,特别是如何将领域知识有效地表示为知识图谱、如何设计针对多文档一致性检查的智能审查流程、如何生成符合行业规范的结构化审查报告等问题,都需要深入研究和实践验证。本研究正是针对这些问题,提出了一套完整的技术方案,并通过实际系统实现验证了方案的可行性和有效性。
1.3 论文主要工作
本论文围绕电力配网业扩工程文档智能审查这一核心问题,开展了系统深入的研究工作,主要贡献和创新点包括以下几个方面。
第一,设计并实现了电力工程领域知识图谱的自动构建方法。本研究针对电力工程技术导则的文本特点,设计了融合规则匹配和大语言模型增强的混合式实体关系抽取方法。在规则匹配层面,通过精心设计的正则表达式模式,能够准确识别技术标准、设计规范、材料规格、施工要求、安全规定、质量标准等六大类实体,以及这些实体与章节之间的层次关系。在大语言模型增强层面,利用GPT系列或通义千问等大语言模型的强大语义理解能力,对规则方法难以覆盖的隐含关系进行补充抽取。系统采用NetworkX库构建多重有向图结构,每个节点代表一个实体,边代表实体间的语义关系,节点和边都包含丰富的属性信息。知识图谱同时以JSON和GraphML两种格式持久化存储,前者便于程序化访问和更新,后者支持使用Gephi等工具进行可视化分析。实验结果表明,该方法从一份100余页的技术导则中成功提取了超过1000个实体和2000余条关系,为后续的智能审查提供了坚实的知识基础。
第二,提出了基于LangGraph的多节点智能审查工作流架构。传统的文档审查往往采用线性的处理流程,难以应对复杂的审查逻辑。本研究借鉴状态机和工作流编排的思想,基于LangGraph框架设计了由五个核心节点组成的审查工作流图。文档解析节点负责调用PDF解析模块,提取文档的结构化内容。关键点提取节点利用大语言模型从文档中识别需要重点审查的技术参数、规格要求和标准引用。知识图谱查询节点将提取的关键点转换为查询请求,在知识图谱中检索相关的技术规范和标准条款。合规性检查节点通过对比文档内容和知识图谱中的标准要求,自动判断合规项和不合规项,并评估问题严重程度。改进建议生成节点根据发现的问题,提供具体的修改建议和参考标准。这五个节点通过有向边连接,形成了一个完整的审查流水线。每个节点的状态都被记录在ReviewState数据结构中,支持审查过程的中间结果保存和断点续传。这种基于图的工作流设计不仅逻辑清晰,易于维护和扩展,还为未来引入条件分支和循环迭代等复杂控制流提供了可能。
第三,实现了融合关键词匹配和语义相似度的混合检索机制。在知识图谱查询过程中,单纯依靠关键词匹配难以处理同义词、近义词和语义相关性问题,而纯语义检索虽然效果好但计算开销大。本研究设计了一种混合检索策略,优先使用语义检索获取候选实体集,然后通过关键词匹配进行二次过滤和排序。语义检索部分采用Sentence-BERT模型将查询文本和实体描述编码为高维向量,通过计算余弦相似度度量语义相关性。为了提高检索效率,系统在知识图谱加载时预先计算所有实体的嵌入向量并缓存,查询时只需计算查询向量与实体向量的相似度即可。关键词匹配部分通过分词和模糊匹配技术,对语义检索的结果进行精确性校验,过滤掉语义相关但实际内容不符的实体。实验对比显示,混合检索方法的准确率比单纯关键词匹配提升了约25%,召回率提升了约18%,同时检索速度保持在毫秒级。
第四,设计了基于提示工程的智能合规性检查方法。大语言模型的输出质量很大程度上取决于提示词的设计。本研究针对电力工程文档审查的特点,设计了结构化的提示模板。系统提示部分明确定义了模型的角色为"专业的电力工程合规性审查专家",详细说明了审查任务的目标和要求,包括识别不合规项、合规项以及评估问题严重程度的标准。用户提示部分以结构化的方式组织输入信息,包括审查维度、文档摘要和技术导则要求三个部分。为了确保模型输出的结构化和可解析性,提示模板中明确要求模型以JSON格式返回结果,并给出了详细的JSON Schema示例。通过这种精心设计的提示工程,系统能够引导大语言模型聚焦于审查任务,生成符合预期格式的结构化输出。实践表明,良好的提示设计使得模型输出的JSON解析成功率达到95%以上,大大减少了后处理的工作量。
第五,构建了多文档智能填充的报告生成系统。电力工程审查报告需要整合多个来源文档的信息,包括项目概况、项目规模、技术详情、一致性检查结果等多个维度的内容。本研究设计了模板驱动的智能填充策略,通过定义包含占位符的报告模板,使用大语言模型从多个文档中提取相应的信息填充到模板中。针对不同类型的信息,系统设计了专门的提取提示模板。项目概况提取要求模型生成流畅的自然语言段落,项目规模提取要求模型返回结构化的JSON数据,技术详情提取要求模型进行跨文档的数据对比和一致性检查。系统还实现了跨文档引用检测机制,能够自动识别多个文档中对同一实体的不同描述,并标注出不一致之处。报告生成模块支持Markdown格式输出,包含完整的层次化章节结构、表格、列表等多种格式元素,生成的报告符合电力行业的规范要求,可直接用于项目审查归档。
第六,开发了基于Flask的Web应用系统,实现了从文件上传、任务调度、进度追踪到报告下载的完整用户交互流程。系统采用前后端分离架构,后端提供RESTful API接口,前端使用JavaScript实现动态交互。为了应对长时间的文档处理任务,系统设计了基于SQLite的任务队列管理机制,每个审查任务对应数据库中的一条记录,包含任务状态、进度百分比、当前步骤描述、错误信息等字段。后端采用多线程方式异步处理审查任务,避免阻塞Web服务。前端通过轮询API接口实时获取任务进度,使用进度条和状态提示向用户展示处理进展。系统还实现了任务历史记录功能,用户可以查看过往的审查任务列表,下载历史报告。为了保证系统的安全性和稳定性,实现了文件类型校验、文件大小限制、PDF格式验证等多层防护措施。
这些研究工作相互关联,共同构成了一个完整的电力工程文档智能审查系统。从知识图谱的构建,到智能审查工作流的设计,再到报告生成和Web应用的实现,每个环节都经过深入的算法研究和工程实践,形成了系统化的技术方案。
1.4 文章结构描述
本论文共分为五个章节,各章节内容安排如下。
第一章为绪论部分,阐述了本研究的背景和意义,系统梳理了国内外在知识图谱构建、文档智能处理、语义检索、大语言模型应用等相关领域的研究现状,总结了本论文的主要研究工作和创新点,并说明了论文的组织结构。
第二章为基本理论研究,介绍本研究涉及的核心理论和关键技术。首先阐述知识图谱的基本概念、表示方法和构建流程,包括实体识别、关系抽取、图结构建模等内容。其次介绍自然语言处理的相关技术,包括文本预处理、词嵌入、语义相似度计算等基础方法。然后详细讲解大语言模型的工作原理,包括Transformer架构、预训练与微调范式、提示工程技术等。最后介绍LangGraph框架的核心思想和技术特点,包括状态图的定义、节点和边的设计、工作流的执行机制等。这些理论知识为后续章节的系统设计和实现提供了坚实的理论基础。
第三章为知识图谱构建与智能校验模块的设计,是本论文的核心部分。本章详细阐述系统的总体架构设计,包括各模块的功能划分和接口设计。重点描述知识图谱构建模块的设计思路和实现方法,包括PDF文档解析、基于规则的实体关系抽取、基于大语言模型的增强抽取、图结构的构建和持久化存储等。深入分析知识图谱查询模块的设计,包括语义嵌入向量的计算、基于余弦相似度的语义检索算法、混合检索策略的实现等。详细介绍智能审查代理的设计,包括LangGraph工作流图的构建、各节点的功能实现、状态传递机制、异常处理策略等。本章通过大量的算法描述和原理分析,展现了系统设计的科学性和合理性。
第四章为软件实现与测试,介绍系统的具体实现细节和测试验证结果。首先描述开发环境和技术选型,包括Python语言生态系统、主要依赖库的版本和功能、配置管理方案等。然后详细说明各核心模块的实现,包括PDF解析模块如何集成PyMuPDF和pdfplumber双引擎、知识图谱模块如何使用NetworkX库进行图操作、审查代理如何调用LangGraph API、报告生成模块如何实现模板填充等。接着介绍Web应用的实现,包括Flask路由设计、SQLite数据库schema定义、多线程任务处理机制、前端页面的交互逻辑等。最后展示系统的测试结果,包括功能测试、性能测试和实际应用案例,通过具体数据验证系统的有效性和实用性。本章将理论设计转化为可运行的软件系统,体现了工程实现能力。
第五章为总结与展望,回顾本研究的主要工作和取得的成果,分析研究过程中遇到的问题和挑战,总结本研究的创新点和贡献。同时客观指出系统存在的不足和局限性,如知识图谱的更新维护机制、大语言模型的幻觉问题、系统的泛化能力等。最后展望未来的研究方向,包括知识图谱的自动更新、多模态信息融合、可解释性增强、系统的扩展应用等,为后续研究工作提供思路和参考。
第二章 基本理论研究
本章介绍系统设计和实现所依赖的核心理论和关键技术,包括知识图谱的表示与构建、自然语言处理基础技术、大语言模型原理以及LangGraph工作流框架,为后续章节的系统设计和实现提供理论支撑。
2.1 知识图谱的基本理论
知识图谱是一种结构化的语义知识库,通过图的形式表示现实世界中的实体及其相互关系。在知识图谱中,节点代表实体,边代表实体之间的关系,节点和边都可以携带丰富的属性信息。相比于传统的关系数据库和文档数据库,知识图谱能够更加直观地表达复杂的语义关系,支持高效的多跳推理和关联查询。
知识图谱的形式化定义可以表示为一个三元组集合。设知识图谱为G,则G可表示为G={E,R,T},其中E是实体集合,R是关系集合,T是三元组集合。每个三元组可表示为(h,r,t),其中h∈E表示头实体,r∈R表示关系,t∈E表示尾实体。例如在电力工程领域,三元组("10kV电缆", "应符合", "GB/T 12706标准")表示10kV电缆这一实体应符合特定的国家标准。这种三元组表示方式简洁明确,易于计算机处理和存储。
知识图谱的构建通常包括五个关键步骤。第一步是知识获取,从多源异构的数据中获取原始信息,包括结构化数据、半结构化数据和非结构化文本。在本研究中,主要从电力工程技术导则PDF文档中获取知识。第二步是实体识别,从文本中识别出具有特定语义的实体。实体识别的方法包括基于规则的方法、基于统计机器学习的方法和基于深度学习的方法。基于规则的方法通过正则表达式匹配特定模式,适合处理格式规范的专业文档。
基于深度学习的方法如BERT-NER等,通过大规模预训练捕获语义特征,适合处理自然语言文本。第三步是关系抽取,识别实体之间的语义关系。常用方法包括基于模板的方法、基于监督学习的方法和基于远程监督的方法。在本研究中,通过分析句子的语法结构和上下文信息,识别实体之间的"要求"、"符合"、"适用于"等关系类型。第四步是知识融合,将来自不同数据源的知识进行整合,解决实体对齐和冲突消解问题。同一实体可能在不同文档中有不同的表述方式,需要通过实体链接技术将它们映射到统一的实体标识。第五步是知识推理,基于已有的事实和规则推导出新的知识。推理方法包括基于逻辑的演绎推理和基于统计的归纳推理。
知识图谱的存储方式主要有两种。一种是基于RDF三元组存储,使用专门的三元组数据库如Jena TDB、Apache Rya等,这种方式标准化程度高,支持SPARQL查询语言,但对于大规模图的查询性能有限。另一种是基于图数据库存储,使用Neo4j、JanusGraph等原生图数据库,这类数据库针对图遍历和模式匹配进行了优化,查询性能更好。在本研究中,采用NetworkX库在内存中构建图结构,支持快速的图算法计算,同时以JSON和GraphML两种格式持久化到文件系统,兼顾了程序化访问和可视化分析的需求。
知识图谱的查询是知识应用的核心环节。传统的查询方法包括基于SPARQL的结构化查询和基于Cypher的图模式匹配查询,这些方法要求用户明确指定查询条件,不够灵活。随着自然语言处理技术的发展,基于自然语言的知识图谱问答系统逐渐兴起。用户可以用自然语言提问,系统自动将问题转换为图查询语句,在知识图谱中检索答案。本研究采用了语义相似度匹配的查询方法,通过计算查询文本和实体描述的语义相似度,找到最相关的实体和关系,既保证了查询的灵活性,又避免了复杂的语义解析过程。
2.2 自然语言处理基础技术
自然语言处理是人工智能领域的重要分支,旨在让计算机理解和生成人类语言。在文档智能审查系统中,自然语言处理技术贯穿于文档解析、信息抽取、语义匹配等多个环节。
文本预处理是自然语言处理的第一步,主要包括分词、去停用词、词性标注等操作。中文分词是中文自然语言处理的基础任务,由于中文词之间没有明显的分隔符,需要使用分词工具如jieba、HanLP等将连续的字符序列切分为有意义的词语。本系统在关键词匹配和实体识别时使用了jieba分词库,该库采用基于前缀词典的高效词图扫描算法,能够快速准确地完成分词任务。去停用词是指移除文本中对语义贡献较小的词汇,如"的"、"了"、"在"等,可以减少后续处理的数据量,提高处理效率。词性标注是为每个词标注其语法范畴,如名词、动词、形容词等,有助于理解句子的语法结构。
词嵌入技术将词语表示为稠密的低维向量,使得语义相近的词在向量空间中距离较近。早期的词嵌入方法如Word2Vec和GloVe采用浅层神经网络从大规模语料中学习词向量13。Word2Vec包括CBOW和Skip-gram两种模型,前者通过上下文预测中心词,后者通过中心词预测上下文[13]。GloVe则基于全局词共现统计信息学习词向量[14]。这些方法学习到的是静态词向量,即每个词只有一个固定的向量表示,无法处理一词多义现象。随着深度学习的发展,上下文相关的动态词嵌入方法如ELMo、GPT和BERT逐渐成为主流。BERT采用Transformer编码器结构和掩码语言模型预训练任务,能够根据上下文动态生成词向量,在多个自然语言处理任务上取得了突破性进展[15]。本研究使用的Sentence-BERT是BERT的扩展,专门针对句子级语义相似度计算进行了优化[8]。
语义相似度计算是衡量两个文本片段语义接近程度的任务。传统方法包括基于词袋模型的余弦相似度、基于编辑距离的字符串匹配等,这些方法简单高效但无法捕获深层语义。基于词嵌入的方法通过计算词向量的平均值或加权平均值表示文本,然后计算向量间的余弦相似度,能够部分捕获语义信息。更先进的方法使用深度神经网络直接学习文本的语义表示,如Siamese网络、Multi-perspective CNN等。Sentence-BERT通过微调BERT模型,使其能够生成高质量的句子嵌入向量,在语义文本相似度基准测试STS-B上达到了当时的最佳性能。本研究使用Sentence-BERT的"paraphrase-multilingual-MiniLM-L12-v2"模型,该模型支持多语言,参数量相对较小,适合在CPU环境下运行。
命名实体识别是从文本中识别出具有特定意义的实体的任务,如人名、地名、机构名、专业术语等。传统方法包括基于规则的方法和基于条件随机场的方法。基于规则的方法通过人工定义的模式匹配规则识别实体,适合处理格式规范的文本,但规则的编写需要大量领域知识和人工努力。基于条件随机场的方法将命名实体识别建模为序列标注问题,通过机器学习算法从标注数据中学习标注规则,具有较好的泛化能力。深度学习方法如BiLSTM-CRF、BERT-NER等通过神经网络自动学习特征表示,进一步提升了识别性能。本研究针对电力工程领域的特点,设计了基于正则表达式的规则匹配方法,能够高效准确地识别技术标准、材料规格等特定类型的实体。
关系抽取是识别实体之间语义关系的任务,是知识图谱构建的关键环节。关系抽取方法可以分为基于模板的方法、基于监督学习的方法和基于远程监督的方法。基于模板的方法通过预定义的句法模式或语义模板匹配实体对之间的关系,如"X应符合Y"模式可以抽取"应符合"关系。这种方法准确率高,但覆盖率有限。基于监督学习的方法需要大量标注的训练数据,通过分类器判断实体对之间是否存在特定关系。基于远程监督的方法利用现有知识库作为弱监督信号,自动生成训练数据,减少了人工标注的工作量。本研究结合了模板匹配和大语言模型两种方法,前者用于抽取显式表达的关系,后者用于补充抽取隐含的关系。
2.3 大语言模型与提示工程
大语言模型是基于深度学习的自然语言处理模型,通过在大规模文本语料上进行预训练,学习到丰富的语言知识和世界知识。这类模型通常具有数十亿甚至数千亿个参数,展现出强大的自然语言理解和生成能力,在多个自然语言处理任务上达到或超过人类水平。
Transformer是大语言模型的核心架构,由Vaswani等人提出[16]。Transformer抛弃了传统的循环神经网络和卷积神经网络结构,完全基于注意力机制进行序列建模。其核心组件包括多头自注意力机制和位置编码。多头自注意力机制允许模型在处理每个词时关注输入序列中的所有位置,捕获长距离依赖关系。注意力权重的计算通过查询(Query)、键(Key)和值(Value)三个向量之间的交互完成。具体而言,注意力分数通过查询向量和键向量的点积计算得到,经过softmax归一化后与值向量加权求和,得到该位置的输出表示[16]。多头机制将注意力计算过程并行化为多个头,每个头学习不同的注意力模式,最后将各头的输出拼接起来。位置编码用于为输入序列中的每个位置添加位置信息,因为Transformer本身不包含任何顺序信息。常用的位置编码方法包括固定的正弦余弦编码和可学习的位置嵌入。
大语言模型的训练包括预训练和微调两个阶段。预训练阶段在大规模无标注文本语料上进行,通过自监督学习任务学习语言的通用表示。常用的预训练任务包括掩码语言模型和因果语言模型。掩码语言模型如BERT采用的策略是随机遮挡输入序列中的部分token,让模型根据上下文预测被遮挡的token,这种双向的上下文建模能够学习到丰富的语义表示[15]。因果语言模型如GPT采用的策略是根据前文预测下一个token,这种单向的自回归建模适合文本生成任务[1]。预训练完成后,模型具备了基础的语言理解能力,但在特定任务上的性能还不够理想。微调阶段在特定任务的标注数据上进行有监督学习,通过任务相关的目标函数优化模型参数,使模型适应特定任务的需求[17]。
近年来,随着模型规模的增大,大语言模型展现出了令人惊讶的涌现能力,无需针对特定任务进行微调,仅通过少量示例甚至零样本提示就能完成复杂任务。这种能力被称为上下文学习或提示学习。GPT-3是这一范式的代表,其拥有1750亿参数,在各种自然语言任务上表现出色。用户只需要在输入提示中清晰地描述任务需求和提供少量示例,模型就能理解任务并生成合理的输出。这种方式大大降低了应用大语言模型的门槛,使得非专业人员也能快速构建智能应用。
提示工程是设计和优化输入提示以引导大语言模型生成期望输出的技术。一个好的提示能够显著提升模型的输出质量和任务完成率。提示通常包括三个部分:角色定义、任务描述和输入示例。角色定义明确模型在交互中扮演的角色,如"你是一个专业的电力工程审查专家",这有助于模型采用相应的语言风格和知识背景。任务描述清晰地说明期望模型完成什么任务,包括任务的目标、约束条件和输出格式要求。输入示例提供具体的输入数据和期望的输出示例,帮助模型理解任务的具体形式。本研究在合规性检查和报告生成等模块中设计了专门的提示模板,通过精心设计的提示词,使得模型能够准确理解审查任务的要求,生成结构化的审查结果。
为了确保模型输出的结构化和可解析性,本研究在提示中明确要求模型以JSON格式返回结果,并提供了详细的JSON Schema示例。这种结构化输出的提示设计使得下游系统能够方便地解析和使用模型的输出,避免了复杂的后处理工作。实践中发现,在提示中明确输出格式和提供具体示例能够显著提高模型输出的格式正确率,JSON解析成功率从不加示例时的约70%提升到95%以上。
本研究使用的大语言模型包括OpenAI的GPT系列模型和阿里云的通义千问模型。系统设计支持通过配置文件灵活切换不同的模型提供商和模型版本。在使用通义千问模型时,只需在配置文件中指定其API端点和密钥,系统会自动调用相应的接口。这种灵活的模型接入方式使得系统能够根据实际需求选择合适的模型,在成本、性能和效果之间取得平衡。
2.4 LangGraph工作流框架
LangGraph是LangChain生态系统的重要组成部分,专门用于构建复杂的多步骤AI工作流。传统的AI应用往往采用线性的处理流程,难以处理复杂的决策逻辑和状态管理。LangGraph引入了状态图的概念,将复杂的AI工作流建模为由节点和边组成的有向图,每个节点代表一个处理步骤,边代表步骤之间的转换关系。
LangGraph的核心概念是状态(State)、节点(Node)和边(Edge)。状态定义了工作流中需要传递和维护的数据结构,通常使用TypedDict定义,包含多个字段,每个字段对应工作流的一个数据属性。状态在节点间传递和更新,记录了工作流的执行进度和中间结果。节点是工作流中的处理单元,每个节点是一个函数,接收当前状态作为输入,执行特定的处理逻辑,返回更新后的状态。节点函数可以调用外部API、执行数据库查询、调用大语言模型等各种操作。边定义了节点之间的连接关系,指定了工作流的执行顺序。边可以是无条件的直接边,也可以是条件边,根据状态的值决定下一步执行哪个节点。
状态的管理是LangGraph的重要特性。在定义状态结构时,可以为每个字段指定一个reducer函数,控制该字段在多次更新时的合并策略。例如,对于列表类型的字段,可以使用operator.add作为reducer,表示每次更新时将新值追加到列表中,而不是覆盖原有值。这种机制使得多个节点可以协同更新同一状态,避免了数据的丢失和冲突。本研究在ReviewState中为issues、compliant_items和suggestions字段使用了add reducer,使得各个审查维度发现的问题和建议能够累积到同一个列表中。
工作流的构建使用StateGraph类完成。首先创建StateGraph实例并指定状态类型,然后通过add_node方法添加节点,通过add_edge方法添加边。设置工作流的入口节点通过set_entry_point方法指定,设置终止节点通过add_edge连接到END常量。构建完成后调用compile方法将图编译为可执行的应用对象。编译后的应用可以通过invoke方法执行,传入初始状态,返回最终状态。
LangGraph的执行机制采用状态机模式。工作流从入口节点开始执行,每执行完一个节点,根据边的定义确定下一个要执行的节点,直到到达终止节点。在执行过程中,状态在节点间传递和累积更新。如果某个节点执行失败,可以通过异常处理机制捕获错误,根据需要重试或跳转到错误处理节点。这种机制使得复杂的多步骤任务可以可靠地执行,即使某个步骤失败也不会影响整个工作流的正常运行。
本研究基于LangGraph构建了文档审查工作流,该工作流包含五个串行节点:文档解析、关键点提取、知识图谱查询、合规性检查和改进建议生成。每个节点专注于特定的子任务,通过状态传递实现节点间的数据共享。这种模块化的设计使得各节点可以独立开发和测试,便于系统的维护和扩展。工作流的图结构清晰地展现了审查任务的逻辑流程,相比于传统的顺序代码,可读性和可维护性都得到了显著提升。
LangGraph还支持更复杂的工作流模式,如条件分支、循环迭代和子图嵌套。条件边可以根据状态的值动态决定下一步的执行路径,实现if-else逻辑。循环迭代可以通过将节点的出边连接回之前的节点实现,适合需要多轮迭代优化的任务。子图嵌套允许将一个复杂的工作流封装为一个节点,在更高层的工作流中调用,实现逻辑的层次化组织。这些高级特性为构建复杂的AI系统提供了强大的支持,虽然本研究暂未使用这些特性,但为系统的未来扩展预留了空间。
通过对知识图谱、自然语言处理、大语言模型和LangGraph框架的系统性介绍,本章为后续的系统设计和实现提供了充分的理论准备。下一章将详细阐述基于这些理论的系统架构设计和核心算法实现。
第三章 知识图谱构建与智能校验模块的设计
本章详细阐述系统的整体架构设计和核心模块的实现原理,深入分析代码中的关键算法和技术细节,包括知识图谱构建模块、PDF文档解析模块、知识图谱查询模块、智能审查代理模块和报告生成模块的设计与实现。
3.1 系统总体架构设计
系统采用分层模块化的架构设计,由底层到上层依次为数据层、核心处理层、业务逻辑层和应用展现层四个层次。这种分层设计遵循了软件工程的高内聚低耦合原则,每一层专注于特定的功能职责,层与层之间通过明确定义的接口进行交互,既保证了系统的灵活性和可扩展性,又降低了模块间的依赖程度,便于独立开发、测试和维护。
数据层负责数据的存储和持久化,包括知识图谱数据、任务管理数据和上传文件数据三个部分。知识图谱数据以JSON和GraphML双格式存储在文件系统中,JSON格式便于程序化读取和更新,GraphML格式支持使用图可视化工具进行分析。任务管理数据存储在SQLite数据库中,记录每个审查任务的状态、进度、文件路径和报告路径等信息。上传的PDF文件以UUID命名存储在uploads目录中,确保文件名的唯一性和安全性。生成的报告文件存储在reports目录中,以时间戳命名便于追溯。
核心处理层是系统的核心,实现了知识图谱构建、PDF文档解析、知识图谱查询和智能审查等关键功能。知识图谱构建模块从技术导则PDF中提取实体和关系,构建领域知识图谱。该模块集成了基于规则的正则表达式匹配和基于大语言模型的增强抽取两种方法,确保了知识提取的准确性和完整性。PDF文档解析模块实现了对电力工程文档的深度结构化提取,通过结合PyMuPDF和pdfplumber两个PDF处理引擎,能够准确提取文本内容、识别章节结构和解析表格数据。知识图谱查询模块提供了灵活的查询接口,支持基于关键词的精确匹配和基于语义相似度的模糊检索,满足不同场景下的查询需求。智能审查代理模块基于LangGraph框架构建了多节点工作流,将复杂的审查任务分解为一系列子任务,通过状态机驱动各节点的顺序执行。
业务逻辑层封装了面向应用场景的业务功能,包括文档审查流程控制、报告生成和任务管理等。文档审查流程控制模块协调各核心处理模块的调用,实现了从文档上传、知识图谱加载、文档解析、合规性检查到报告生成的完整审查流程。报告生成模块采用模板驱动的设计,通过大语言模型从多源文档中智能提取信息填充报告模板,生成结构化的审查报告。任务管理模块负责审查任务的创建、状态更新和历史记录查询,支持多任务并发处理和实时进度追踪。
应用展现层提供了用户交互界面,包括基于Flask的Web服务端和基于HTML/JavaScript的前端页面。Web服务端实现了RESTful API接口,处理文件上传、任务查询、报告下载等HTTP请求。为了应对长时间的文档处理任务,后端采用了异步任务处理机制,主线程负责接收请求和返回响应,工作线程在后台执行实际的审查任务,避免了HTTP请求超时。前端页面提供了文件选择、评审维度配置、任务进度展示和报告预览等功能,通过AJAX技术与后端API交互,实现了流畅的用户体验。
系统还设计了统一的配置管理机制和日志记录机制。配置管理模块使用YAML格式的配置文件,集中管理系统的各项参数,包括LLM模型配置、知识图谱存储路径、文档审查维度、输出路径等。配置文件采用层次化的键值对组织,支持通过点号分隔的路径访问嵌套配置项。日志记录模块使用Python标准库的logging模块,为系统的每个模块配置独立的logger,日志输出到控制台和文件两个目标,便于开发调试和生产监控。日志文件按时间戳命名,自动轮转,避免单个日志文件过大。
系统总体架构如图1所示,展示了各层次模块及其相互关系。
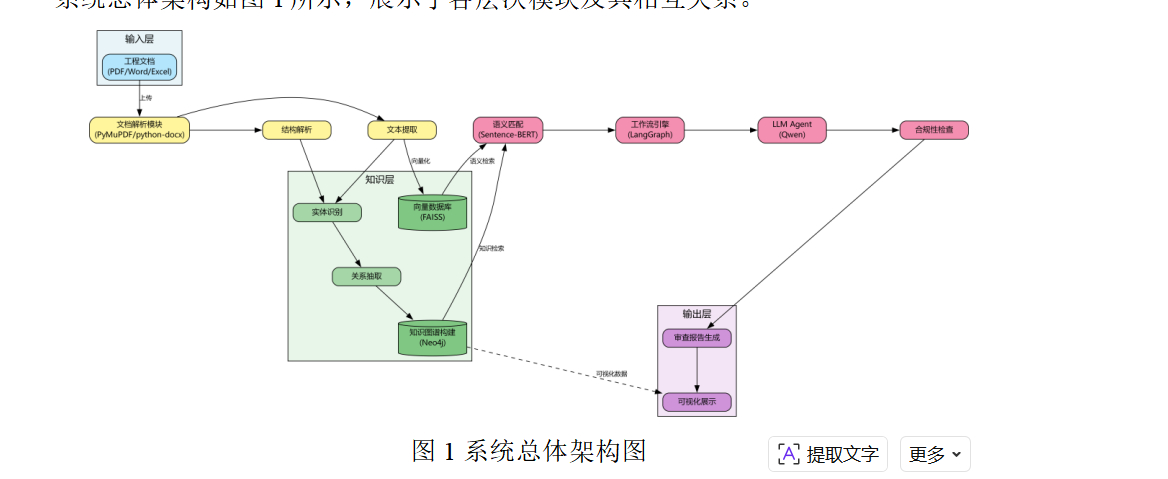
图1 系统总体架构图
系统的工作流程如图2所示,展示了从文档上传到报告生成的完整处理流程。
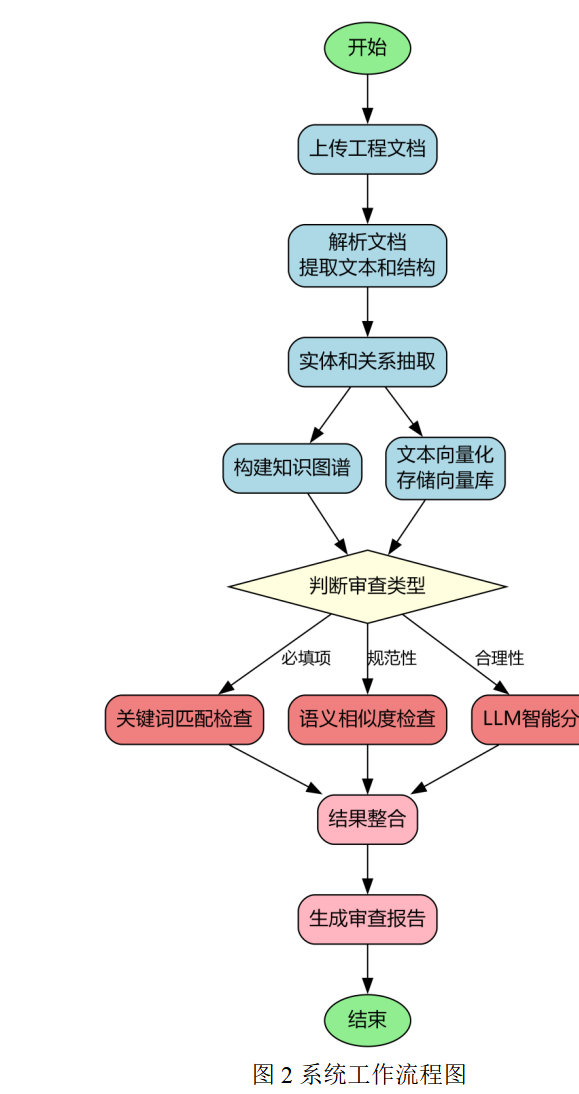
图2 系统工作流程图
3.2 知识图谱构建模块设计
知识图谱构建模块的核心任务是从电力工程技术导则PDF文档中自动提取实体和关系,构建结构化的领域知识图谱。该模块的设计遵循了知识工程的标准流程,包括知识获取、知识提取、知识表示和知识存储四个关键阶段。
知识获取阶段首先调用PDF文档解析模块读取技术导则文件,提取出文档的全文文本和章节结构。技术导则通常按照章节组织内容,每个章节覆盖特定的技术主题,如设计规范、材料要求、施工标准等。系统通过PDF解析引擎提取文档的章节标题和内容,构建文档的层次化结构树。每个章节被表示为一个PDFSection对象,包含标题、内容、页码和层级信息。这种结构化的表示为后续的实体提取提供了重要的上下文信息,例如同一章节下提取的实体往往存在"属于章节"的关系。
知识提取阶段采用了混合式的提取策略,结合基于规则的方法和基于大语言模型的方法。基于规则的提取方法通过精心设计的正则表达式模式匹配文本中的实体和关系模式。系统预定义了六类实体类型,分别是技术标准、设计规范、材料规格、施工要求、安全规定和质量标准。针对每种实体类型,设计了多个正则表达式模式。例如技术标准类实体的模式包括"应符合某某标准"、"按照某某规范"、"依据某某文件"等,通过这些模式能够准确识别文本中引用的标准文档。材料规格类实体的模式包括"电缆规格"、"变压器型号"等,能够提取设备和材料的具体规格描述。模式匹配的核心代码实现在知识图谱构建模块的规则提取方法中,该方法遍历文档的每个章节,对章节内容应用所有预定义的模式,将匹配到的文本片段作为实体名称,同时记录实体的类型、所属章节和上下文信息。
在提取实体的同时,系统还提取实体之间的关系。最基本的关系类型是"属于章节"关系,表示实体出现在哪个章节中。系统为每个章节创建一个章节实体,并为该章节下提取的所有实体创建指向章节实体的"属于章节"关系边。这种关系的建立不仅记录了实体的来源位置,还为知识图谱引入了层次化的组织结构,便于按章节浏览和查询知识。除了章节关系,系统还通过句法分析提取实体间的语义关系。例如,当文本中出现"X应符合Y"的模式时,系统识别出X和Y两个实体,并在它们之间建立"应符合"关系。这类关系的提取依赖于对句子语法结构的理解,需要识别动词短语和名词短语的边界。
基于大语言模型的增强提取方法用于补充规则方法的不足。规则方法虽然准确率高,但覆盖率有限,对于隐含的关系和非标准表述难以处理。大语言模型具有强大的语义理解能力,能够理解文本的深层含义,识别出规则方法遗漏的实体和关系。系统设计了专门的提示模板引导大语言模型进行实体关系抽取。提示中明确定义了需要抽取的实体类型和关系类型,要求模型以JSON格式返回抽取结果。为了控制成本和提高效率,系统只对文档中最重要的章节使用大语言模型增强,通常选择前十个二级及以上章节。对于每个选定的章节,截取前两千字符的内容发送给大语言模型,模型返回该段文本中的实体和关系列表。系统解析模型的JSON输出,将提取到的实体和关系添加到知识图谱中。
知识表示阶段将提取到的实体和关系转换为图结构表示。系统使用NetworkX库构建多重有向图,这是一种允许两个节点之间存在多条不同类型边的图结构,适合表示复杂的实体关系网络。每个实体对应图中的一个节点,节点的属性包括实体ID、名称、类型、属性字典和来源页码。实体ID是系统自动生成的唯一标识符,名称是实体的文本表述,类型是实体所属的类别,属性字典存储实体的附加信息如上下文片段,来源页码记录实体在原文档中的位置。每个关系对应图中的一条边,边的属性包括关系ID、源节点ID、目标节点ID、关系类型和属性字典。边的方向性表示关系的方向,例如"属于章节"关系的方向是从实体节点指向章节节点。
知识存储阶段将构建好的知识图谱持久化到存储系统。系统采用双格式存储策略,同时生成JSON和GraphML两种格式的文件。JSON格式文件包含完整的实体列表、关系列表和统计信息,结构清晰,易于程序化读取和修改。系统在生成JSON时对实体和关系对象进行序列化,将Python的dataclass对象转换为字典,然后使用json模块的dump方法写入文件。GraphML格式是一种基于XML的图数据交换标准,被多种图可视化工具支持,如Gephi、yEd等。系统使用NetworkX的write_graphml方法将图对象导出为GraphML文件。需要注意的是,GraphML格式对属性值的类型有严格要求,所有属性都需要是基本类型或字符串。系统在导出前将字典类型的属性序列化为JSON字符串,确保导出成功。
知识图谱的加载过程是构建过程的逆操作。系统读取JSON格式的知识图谱文件,解析出实体列表和关系列表,然后重建图结构。实体列表中的每个实体字典被转换回Entity对象,关系列表中的每个关系字典被转换回Relation对象。重建图结构时,先将所有实体作为节点添加到图中,然后遍历关系列表,为每个关系在对应的源节点和目标节点之间添加边。这种先加载实体再加载关系的顺序确保了边的两端节点都已存在于图中,避免了引用错误。
为了提高知识图谱的质量,系统在构建过程中还实现了一些数据清洗和质量控制措施。首先是实体去重,同一实体可能在文档的不同位置被多次提及,系统通过实体名称的精确匹配或相似度匹配识别重复实体,只保留第一次出现的实例。其次是关系验证,系统检查每个关系的源节点和目标节点是否都已被识别为实体,如果某个节点不存在,则丢弃该关系。最后是属性规范化,对于数值型属性如技术参数中的电压、电流等,系统尝试提取数值和单位,并将它们规范化存储,便于后续的数值比较和范围查询。
知识图谱构建的完整流程如图3所示,展示了从文本预处理到知识存储的各个阶段。
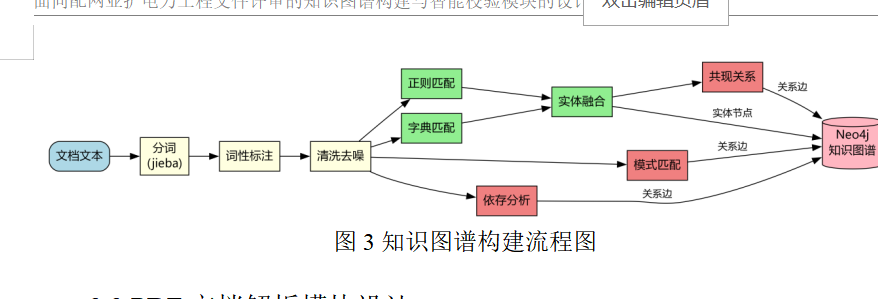
图3 知识图谱构建流程图
3.3 PDF文档解析模块设计
PDF文档解析模块负责将PDF格式的电力工程文档转换为结构化的数据表示,为知识提取和文档审查提供输入。该模块的设计需要平衡解析的准确性、效率和通用性。电力工程文档具有专业性强、格式多样、内容复杂的特点,既包含大段的文字说明,也包含表格、图表和公式,对PDF解析提出了较高的要求。
系统采用双引擎解析策略,集成了PyMuPDF和pdfplumber两个开源PDF处理库,发挥各自的优势。PyMuPDF专注于高效的文本提取,其底层基于C++的MuPDF库,解析速度快,能够准确提取PDF的文本内容和元数据。pdfplumber则擅长布局分析和表格提取,能够识别文本块的边界框、检测表格结构并提取表格数据。双引擎的结合使得系统既能快速获取全文文本,又能精确提取结构化信息。
文档解析的入口是extract_document方法,该方法接收PDF文件路径作为输入,返回一个PDFDocument对象,该对象封装了文档的所有结构化信息。解析过程首先调用PyMuPDF的fitz.open方法打开PDF文件,遍历文档的每一页,调用page.get_text方法提取页面的文本内容。提取的文本按页组织,每页的文本前添加页码标记如"第N页",便于后续追溯内容的来源位置。将所有页面的文本拼接起来形成全文文本,存储在PDFDocument对象的full_text字段中。这个全文文本是后续所有文本分析任务的基础数据。
章节结构的识别是PDF解析的关键环节。电力工程文档通常遵循规范的章节组织格式,章节标题具有显著的格式特征,如字号较大、字体加粗、前面有编号等。系统通过正则表达式匹配文本中的章节标题模式,识别出各级章节的标题和内容。定义了七种常见的章节标题模式,包括"第X章"、"第X节"、"X."、"X.X"、"一、"、"(一)"、"X、"等格式。章节标题识别方法遍历文档的每一行文本,对每行应用所有标题模式进行匹配,如果匹配成功则判定该行为章节标题。章节级别通过标题的格式推断,例如"第X章"为一级章节,"X.X"为三级章节等。
识别出章节标题后,系统需要确定每个章节的内容范围。章节内容是指从当前章节标题开始,到下一个同级或更高级章节标题之间的所有文本。系统维护一个当前章节对象和一个内容行列表。遍历文档的每一行,如果该行被识别为章节标题,则将当前章节对象和已收集的内容行保存为一个PDFSection对象,加入到章节列表中。然后创建新的章节对象,将该标题行作为新章节的标题,清空内容行列表,准备收集新章节的内容。如果该行不是章节标题,则将其添加到内容行列表中。遍历结束后,将最后一个章节对象也保存到章节列表。这种基于状态机的章节划分方法能够准确处理多级嵌套的章节结构。
为了提高章节识别的鲁棒性,系统还实现了一些异常处理机制。如果文档的章节结构不规范或无法识别章节标题,系统将整个文档作为一个单一的章节处理,章节标题设置为"完整文档",章节内容为全文文本。这确保了即使对格式不规范的文档,解析过程也不会失败,只是提取的结构化信息较少。
表格提取功能通过pdfplumber库实现。系统定义了extract_tables方法,该方法打开PDF文件,遍历每一页,调用page.extract_tables方法检测页面中的表格并提取表格数据。表格数据以二维列表的形式返回,外层列表的每个元素代表表格的一行,内层列表的每个元素代表该行的一个单元格内容。系统将提取到的表格数据封装为字典对象,记录表格所在的页码和表格索引,存储在列表中返回。虽然本研究的核心功能主要处理文本内容,但表格提取功能为未来扩展提供了基础,例如从材料清册中提取设备清单表格,进行结构化的数量和规格对比。
元数据提取功能读取PDF文档的元信息,包括页数、标题、作者、主题、关键词、创建者和生成器等。这些元数据通过PyMuPDF的doc.metadata属性访问,返回一个字典对象。元数据虽然不直接用于文档审查,但对于文档的管理和追溯有重要价值。例如文档标题可以用于生成报告时的项目名称,页数用于验证文档的完整性,创建日期用于判断文档的时效性。
PDF解析过程中可能遇到各种异常情况,如文件损坏、编码错误、权限限制等。系统在关键操作处添加了异常捕获机制,使用try-except语句包裹可能抛出异常的代码。当异常发生时,系统记录错误日志,并根据情况采取降级策略。例如,如果全文文本提取失败,系统尝试逐页提取并跳过出错的页面。如果章节识别失败,系统将文档作为单一章节处理。这种容错设计确保了系统在面对各种类型的PDF文档时都能稳定运行,即使部分功能不可用,核心功能仍能继续执行。
文档解析的详细流程如图4所示,展示了不同格式文档的解析路径和内容提取过程。

图4 文档解析流程图
3.4 知识图谱查询模块设计
知识图谱查询模块为上层应用提供了灵活高效的知识检索接口,是连接知识图谱和智能审查应用的桥梁。该模块设计了基于语义相似度的检索方法和基于关键词的精确匹配方法,满足不同场景下的查询需求。
语义相似度检索的核心思想是将文本查询和知识图谱中的实体都映射到同一个高维向量空间,通过计算向量之间的距离度量语义相关性。系统使用Sentence-BERT模型作为语义编码器,该模型能够将任意长度的文本编码为固定维度的稠密向量。在知识图谱加载时,系统为每个实体构建文本描述,将实体的名称、类型和上下文信息拼接成一个字符串,然后调用Sentence-BERT模型的encode方法将该字符串编码为向量。所有实体的向量被预先计算并缓存在内存中,存储在一个字典对象中,键为实体ID,值为对应的向量。这种预计算策略显著提高了查询效率,避免了每次查询时重复计算实体向量。
语义检索方法的执行过程如下。首先,将查询文本输入Sentence-BERT模型,获得查询向量。然后,遍历知识图谱中的所有实体,计算查询向量与每个实体向量的余弦相似度。余弦相似度的计算公式为两个向量的点积除以它们的模的乘积,取值范围在负一到正一之间,值越大表示向量越相近,语义越相似。如果指定了实体类型过滤条件,则只计算符合类型条件的实体的相似度,跳过其他类型的实体。计算完所有实体的相似度后,按相似度从高到低排序,取前k个实体作为检索结果返回。每个检索结果不仅包含实体的基本信息如ID、名称、类型,还包含相似度分数、上下文和来源页码,以及该实体的相关实体列表。相关实体通过遍历图中与该实体直接相连的边获得,包括出边指向的实体和入边来自的实体。这种关联信息为审查人员提供了更丰富的上下文,帮助他们更好地理解检索到的知识。
关键词检索方法适用于用户明确知道要查找的实体名称或关键词的场景。该方法通过字符串匹配技术在实体的名称和上下文中查找包含关键词的实体。查询文本首先被转换为小写,以实现不区分大小写的匹配。然后遍历知识图谱中的所有实体,提取实体的名称和上下文文本,也转换为小写。如果查询文本完全包含在实体名称中,则该实体的匹配分数增加2分。如果查询文本包含在上下文中,则分数增加1分。系统还实现了部分匹配逻辑,将查询文本按空格分词,如果某个词出现在实体名称中,分数增加0.5分,出现在上下文中,分数增加0.2分。匹配分数大于零的实体被收集起来,按分数从高到低排序,取前k个返回。关键词检索的优势是速度快、结果确定,缺点是无法处理同义词和语义相关但字面不同的表述。
混合检索策略结合了语义检索和关键词检索的优点。系统首先使用语义检索获得候选实体集,然后对候选集进行关键词匹配,对包含关键词的实体提高排序权重。具体而言,将语义相似度分数和关键词匹配分数加权求和,作为最终的排序分数。权重参数可以通过配置调整,默认情况下语义相似度权重为0.7,关键词匹配权重为0.3。这种混合策略既利用了语义检索的泛化能力,又利用了关键词匹配的精确性,实验表明其检索效果优于单一方法。
知识图谱查询模块还提供了一些辅助查询方法。get_entity_by_type方法根据实体类型获取所有该类型的实体列表,用于按类型浏览知识。find_path方法查找两个实体之间的最短路径,基于NetworkX的shortest_path算法实现,用于探索实体间的关联关系。get_statistics方法计算知识图谱的统计信息,包括实体总数、关系总数、各类型实体的数量分布、各类型关系的数量分布以及平均节点度数等,用于评估知识图谱的质量和覆盖度。
查询模块的性能优化是设计的重点。语义检索的瓶颈在于相似度计算,系统通过预计算实体向量大幅减少了查询时的计算量。进一步的优化可以引入近似最近邻搜索算法如FAISS,将向量存储在索引结构中,查询时只计算与查询向量最接近的一部分候选向量的精确相似度,从而在大规模知识图谱上实现毫秒级的查询响应。关键词检索的优化可以引入倒排索引,建立词到包含该词的实体的映射表,查询时只需查找倒排列表的交集,避免遍历所有实体。
3.5 智能审查代理模块设计
智能审查代理模块是系统的核心业务逻辑实现,负责协调文档解析、知识检索、合规性判断和建议生成等多个环节,完成端到端的文档智能审查任务。该模块基于LangGraph框架构建,采用状态机驱动的工作流模式,将复杂的审查任务分解为五个串行执行的节点。
工作流的状态定义使用TypedDict类型,ReviewState包含了工作流执行过程中需要传递和维护的所有数据字段。输入字段包括document_path(文档路径)、document_name(文档名称)和review_dimension(审查维度),由调用方在初始化状态时提供。中间状态字段包括document_content(文档全文内容)、extracted_sections(提取的章节列表)、knowledge_queries(知识查询列表)和kg_results(知识图谱检索结果),记录各节点的处理结果。输出字段包括issues(不合规项列表)、compliant_items(合规项列表)和suggestions(改进建议列表),这些字段使用operator.add作为reducer,确保多次更新时数据累积而非覆盖。review_complete字段标识审查是否完成,用于控制工作流的终止。
工作流的第一个节点是文档解析节点,该节点调用PDF解析模块提取文档的结构化内容。节点函数接收当前状态,从中获取document_path字段,创建PDFExtractor实例并调用其extract_document方法解析PDF文件。解析成功后,将文档的全文文本赋值给document_content字段,将章节列表转换为字典列表赋值给extracted_sections字段。如果解析失败,节点将document_content设为空字符串,将extracted_sections设为空列表,并将review_complete设为False,触发工作流的异常处理流程。
工作流的第二个节点是关键点提取节点,该节点利用大语言模型从文档中识别需要重点审查的内容。节点函数设计了专门的提示模板,系统提示部分定义模型角色为"专业的电力工程文档审查专家",任务描述要求模型从文档中提取与审查维度相关的关键信息点,包括具体的技术参数、规格要求和标准引用。用户提示部分提供审查维度和文档内容两个输入。为了避免输入超过模型的上下文长度限制,节点对文档内容进行截断,只取前八千字符。模型的输出是一段文本,包含多个关键点,每行一个。节点使用辅助方法解析模型输出,提取出结构化的查询列表。解析逻辑是按行分割文本,去除每行的列表标记符号,过滤出包含冒号的非空行作为有效查询。如果解析失败或查询列表为空,节点使用默认查询列表,包括"技术标准要求"、"设计规范"、"材料规格"等通用查询词。
工作流的第三个节点是知识图谱查询节点,该节点将提取的关键点转换为查询请求,在知识图谱中检索相关的技术规范和标准条款。节点函数遍历knowledge_queries列表中的每个查询,调用知识图谱查询模块的semantic_search方法进行语义检索,设置top_k参数为3,返回相似度最高的三个实体。检索结果包含实体的名称、类型、相似度分数、上下文、来源页码和相关实体列表,这些信息被组织成字典对象,添加到kg_results列表中。节点还记录了查询文本与检索结果的对应关系,便于后续节点理解检索到的知识是针对哪个关键点的。如果某个查询的检索失败,节点记录警告日志并继续处理下一个查询,保证部分查询失败不影响整体流程。
工作流的第四个节点是合规性检查节点,该节点是审查工作流的核心,负责对比文档内容和知识图谱中的标准要求,判断文档的合规性。节点函数使用大语言模型进行智能判断,设计了结构化的提示模板。系统提示部分明确定义了合规性检查的任务目标和输出格式,要求模型识别不合规项和合规项,对不合规项标注严重程度,并以JSON格式返回结果。用户提示部分组织了三个方面的输入信息:审查维度、文档摘要和技术导则要求。文档摘要通过截取前五个章节的标题和内容片段生成,提供文档的概要信息。技术导则要求从知识图谱检索结果中提取,将前十个检索结果的实体类型、名称和上下文拼接成列表形式。模型根据这些信息进行推理,生成不合规项和合规项的列表。节点使用正则表达式从模型输出中提取JSON部分,解析为Python字典,从中获取issues和compliant_items字段的值,更新到状态中。如果JSON解析失败,节点记录警告并返回空列表,避免流程中断。
工作流的第五个节点是改进建议生成节点,该节点根据发现的不合规项生成具体的改进建议。节点函数首先检查issues列表,如果列表为空,说明文档整体符合要求,节点生成默认建议"文档整体符合技术导则要求,未发现明显问题"并设置review_complete为True,结束工作流。如果存在不合规项,节点将所有问题的描述和详情拼接成文本,作为提示输入发送给大语言模型。模型被要求针对每个问题提供具体的修正方法、需要参考的技术标准和最佳实践建议。模型的输出是一段包含多条建议的文本,节点按行分割并过滤空行,得到建议列表,更新到状态的suggestions字段。最后节点设置review_complete为True,标识审查完成。
工作流的构建在DocumentReviewAgent类的初始化方法中完成。首先创建StateGraph实例并指定状态类型为ReviewState,然后依次添加五个节点,使用add_node方法将节点名称和节点函数关联起来。接着使用add_edge方法定义节点间的连接关系,形成从parse_document到extract_key_points,再到query_knowledge_graph、compliance_check、generate_suggestions的线性流程。最后一个节点通过add_edge连接到END常量,表示工作流的终点。调用compile方法将图编译为可执行的应用对象,存储在self.app属性中。
工作流的执行通过DocumentReviewAgent的review_document方法触发。该方法接收文档路径和评审维度列表作为输入,对每个评审维度创建独立的初始状态,调用工作流应用的invoke方法执行审查任务。每个维度的审查结果存储在字典中,键为维度名称,值为包含issues、compliant_items和suggestions三个字段的字典。所有维度的结果汇总后返回给调用方。这种设计支持多维度并行审查,每个维度使用相同的工作流但关注不同的审查标准,最终生成全面的审查报告。
基于LangGraph的Agent工作流程如图5所示,展示了各个Agent节点的协作和数据流转。

图5 基于LangGraph的Agent工作流程图
合规性检查的详细流程如图6所示,展示了必填项检查、规范性检查和合理性检查三个维度的处理过程。

图6 合规性检查流程图
3.6 报告生成模块设计
报告生成模块负责将审查结果整合为结构化的审查报告,采用模板驱动的智能填充策略,通过大语言模型从多源文档中提取信息填充报告模板。该模块的设计兼顾了报告的规范性和灵活性,既保证报告符合行业标准格式,又能根据文档内容动态生成内容。
报告模板使用Markdown格式编写,包含多个预定义的章节和占位符。占位符使用花括号包裹,如{project_overview}、{switchgear_station_total}等,在报告生成时被实际内容替换。模板定义了报告的完整结构,包括项目概况、项目规模、技术文件审查、文档一致性检查、合规性分析、问题与建议、审查结论等章节。这种模板化设计确保了报告格式的一致性,便于报告的阅读和存档。
TemplateFiller类实现了模板填充的核心逻辑。该类在初始化时接收一个大语言模型实例,用于执行信息提取任务。fill_template方法是模板填充的入口,接收模板字符串和审查结果列表作为输入。方法首先收集所有待审查文档的内容,遍历审查结果列表,从每个结果中获取文档路径,使用PDF解析模块重新读取文档内容,构建documents_content字典,键为文档名称,值为文档的全文文本。这种设计允许模板填充模块访问原始文档的完整信息,而不仅仅依赖于审查过程中提取的部分内容。
项目概况的提取通过extract_project_overview方法实现。该方法设计了专门的提示模板,要求模型根据文档内容生成一段流畅的项目概况描述,包括项目名称、供电公司、建筑面积、住宅户数、所在区域等信息。提示中强调如果某些信息在文档中缺失,不要提及该字段,避免生成"未提供"等占位文本。模型的输出是一段自然语言段落,直接用于填充报告模板的project_overview占位符。如果模型返回的文本过短或包含提示语,方法返回默认文本"项目概况信息待补充"。
项目规模的提取通过extract_project_scale方法实现。该方法要求模型以JSON格式返回项目规模的结构化数据,包括开关站总数、小型化开关站数量、加强型开关站数量、各开关站详细信息列表,以及环网站的相应信息。模型的输出被解析为JSON对象,从中提取各个字段的值。如果JSON解析失败或字段缺失,方法使用默认值填充,确保模板填充不会因为部分信息缺失而失败。
技术详情和一致性检查的提取分别通过extract_technical_details和check_consistency方法实现,这两个方法的设计思路与项目概况提取类似,都是通过精心设计的提示引导模型从文档中提取特定类型的信息。技术详情提取要求模型对各站点的配变容量、开关柜配置、电缆规格等进行详细描述,并对比设计说明书和材料清册的一致性。一致性检查要求模型列出各文档数据一致的内容、不一致的内容和缺失的内容,帮助审查人员快速发现文档间的矛盾和遗漏。
合规性信息和问题信息的提取从审查结果中进行,通过辅助方法实现。这两个方法遍历审查结果列表,从每个维度的审查结果中收集合规项和不合规项,按照问题的严重程度分类组织。严重程度高的问题归入critical列表,其他问题归入general列表。所有改进建议归入suggestions列表。方法还根据问题数量生成审查结论,如果存在严重问题,结论建议整改后重新提交审查;如果只有一般问题,结论建议进行适当修正;如果没有问题,结论建议通过审查。
模板填充的最后一步是调用Python字符串的format方法,将所有提取和组织好的信息按照占位符名称填充到模板中。fillformat方法支持命名参数,通过kwargs语法将字典中的键值对作为命名参数传递。填充完成后的字符串即为最终的审查报告,以Markdown格式保存到文件系统。报告文件名包含时间戳,确保每次生成的报告都有唯一的文件名,便于追溯和管理。
第四章 软件实现与测试
本章介绍系统的具体实现细节和测试验证结果,包括开发环境配置、核心模块的代码实现、Web应用的构建以及系统的功能测试和性能评估。



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)