向华为学习——详解华为2025 大模型训练精度问题定位案例 【附全文阅读】
·
华为在大模型训练精度问题定位上,提供了包括Checklist检查、问题复现、分场景定位等方法,并辅以MindSpore Insight工具和msprobe工具进行详细定位和调优[1][2]。
详答
一、精度问题概述与场景
大模型训练中的精度问题可归纳为以下核心场景:
-
场景分类
- 有标杆迁移场景:模型从其他框架或设备迁移至华为昇腾平台时,因算子实现差异、数据格式转换等问题导致精度偏差。例如,算子融合或拆分可能引发自有实现与业界标准(如TensorFlow/PyTorch)的运算结果偏差14。
- 无标杆原生开发场景:从头训练模型时,因数据分布、超参数设置或模型结构缺陷导致精度不达标。例如,数据未混洗或补齐方式错误可能引发训练偏差[12]。
-
典型现象
- Loss异常:跑飞(NaN、+/-INF、极大值)、不收敛、收敛慢或恒为0[3][8][11]。
- Metrics异常:准确率(Accuracy)、精确率(Precision)等指标低于预期3811。
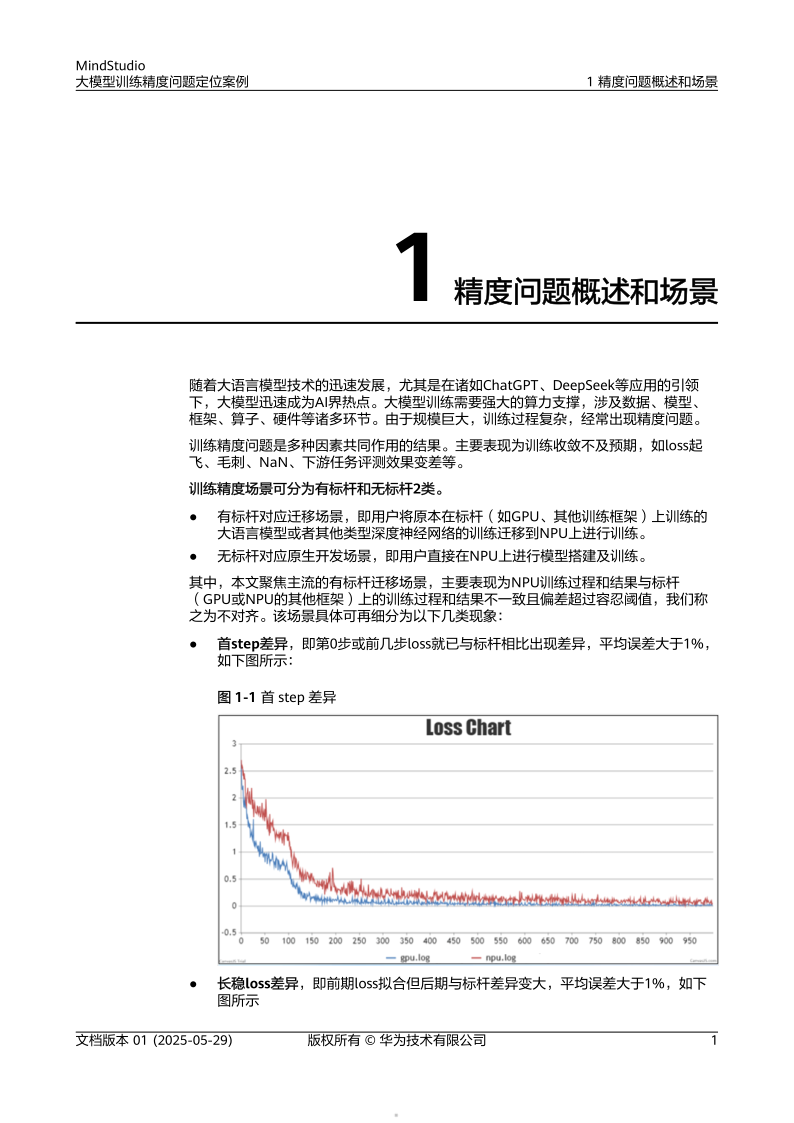
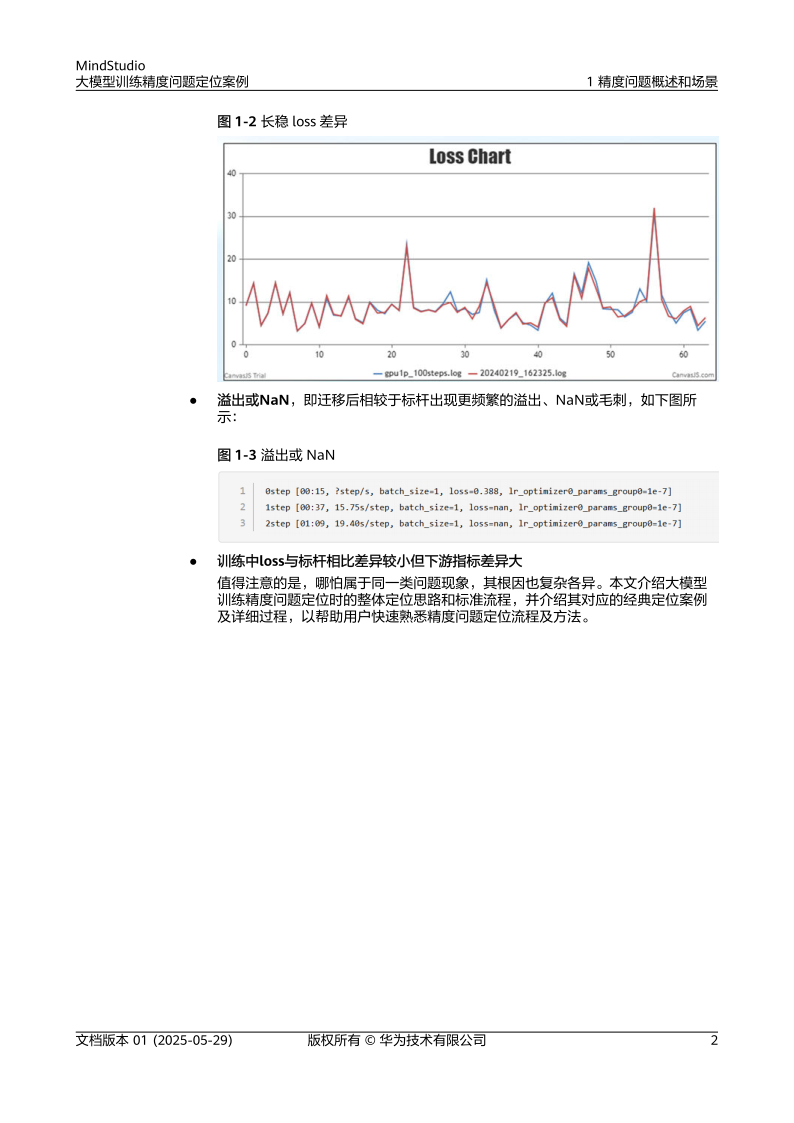
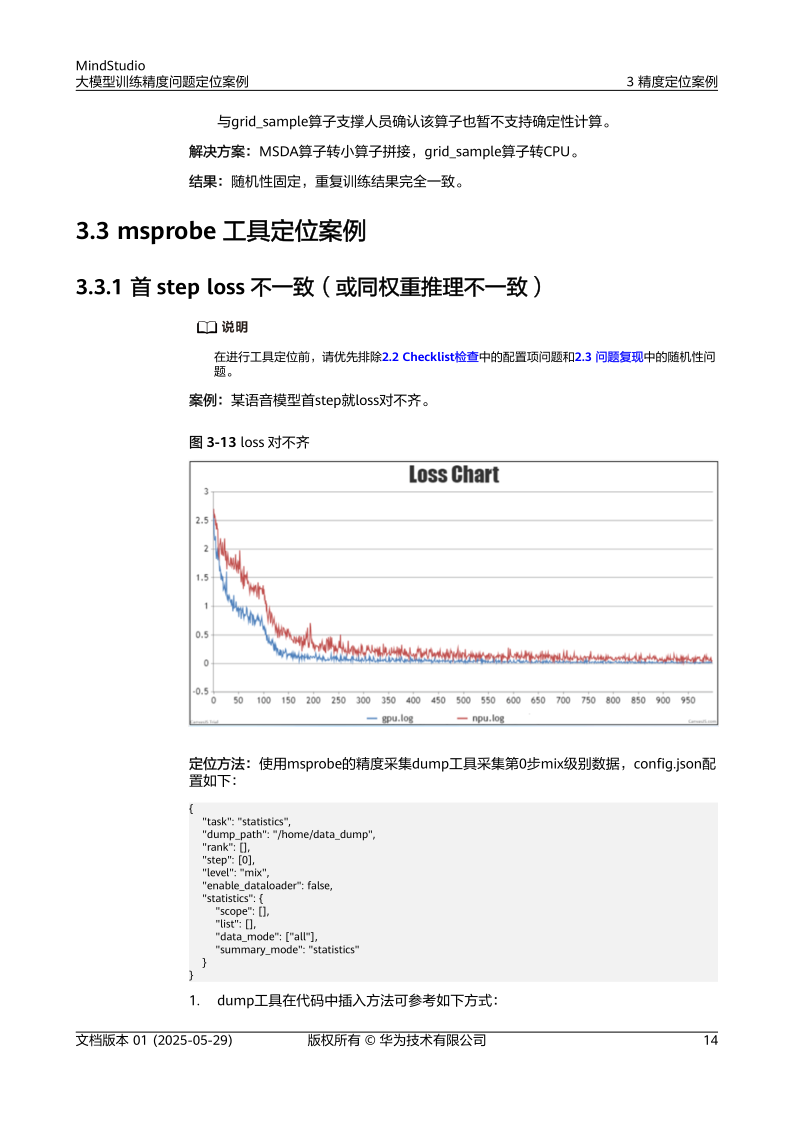
- 特殊表现:首step差异(初始迭代损失值突变)、长稳loss差异(训练后期损失值波动)[1][2]。
二、精度问题定位方法
华为提出系统化定位流程,结合工具链与分场景排查策略:
1. 定位流程
-
步骤1:Checklist检查 验证配置项、数据一致性及模型结构,例如:
- 配置项不一致:检查学习率、批次大小(batch size)、优化器参数等是否与预期一致[2]。
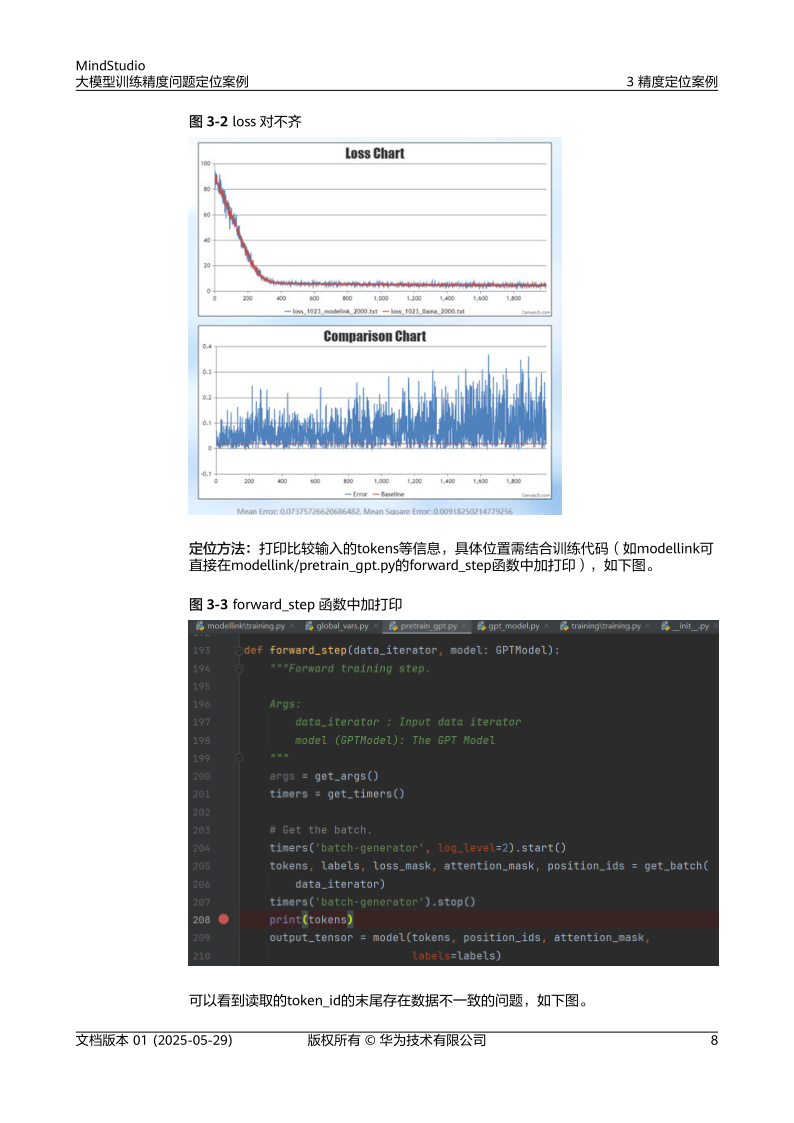
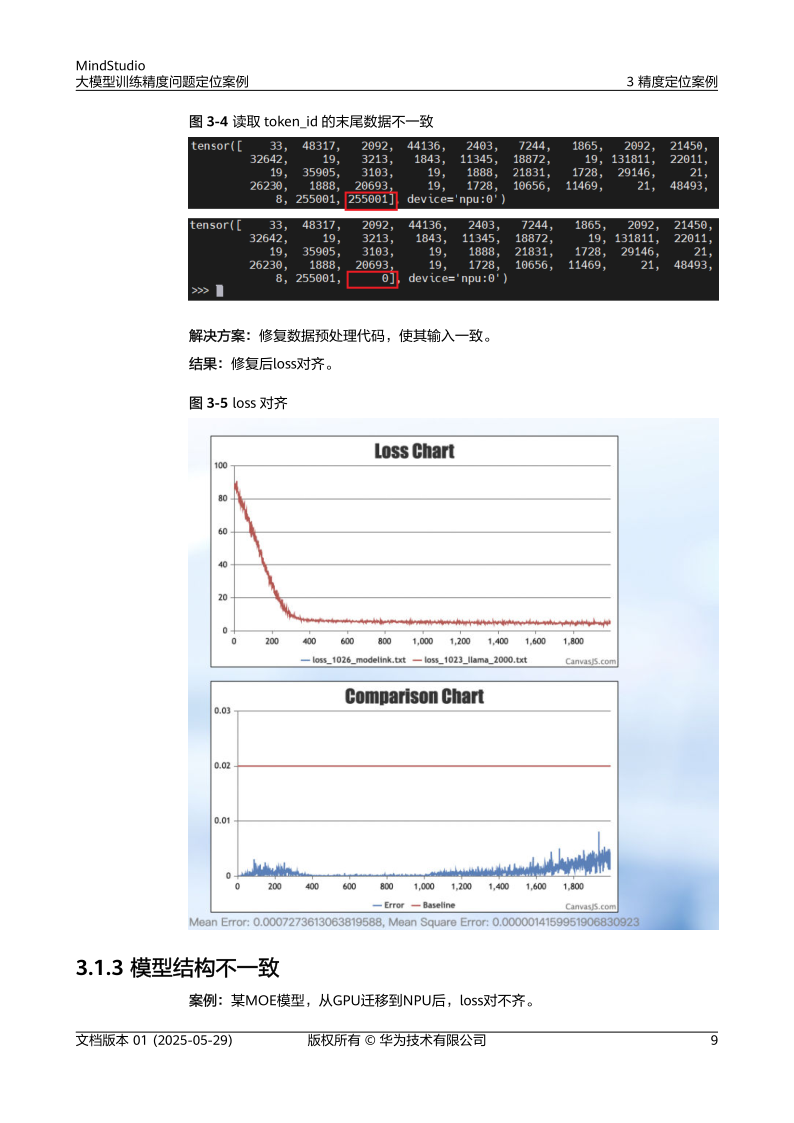
- 数据不一致:确认数据路径、预处理逻辑(如归一化)及分片方式是否正确[2]。
- 模型结构不一致:对比代码定义的模型结构与实际加载的模型参数,确保无版本差异[2][10]。
-
步骤2:问题复现 通过最小化复现代码定位问题根源,例如:
- 使用单卡训练替代多卡并行,排除通信开销干扰2。
- 固定随机种子(random seed),确保实验可复现10。
-
步骤3:分场景定位
- 有标杆迁移场景:
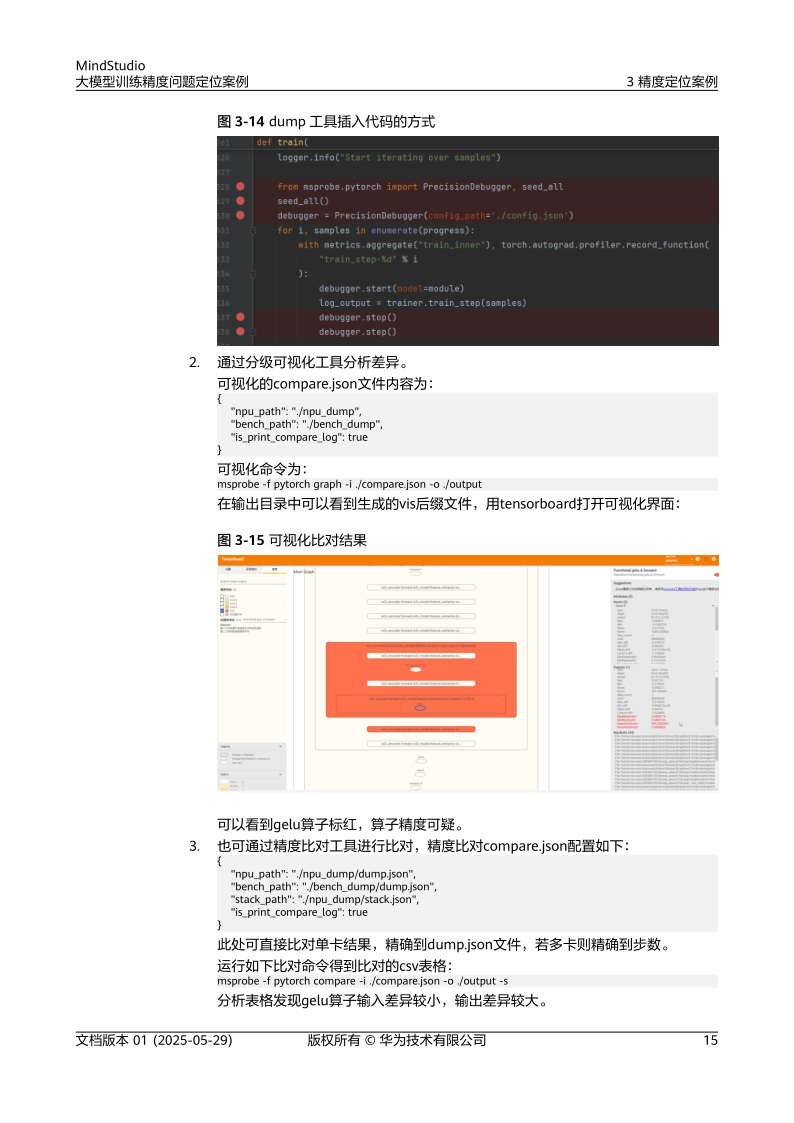
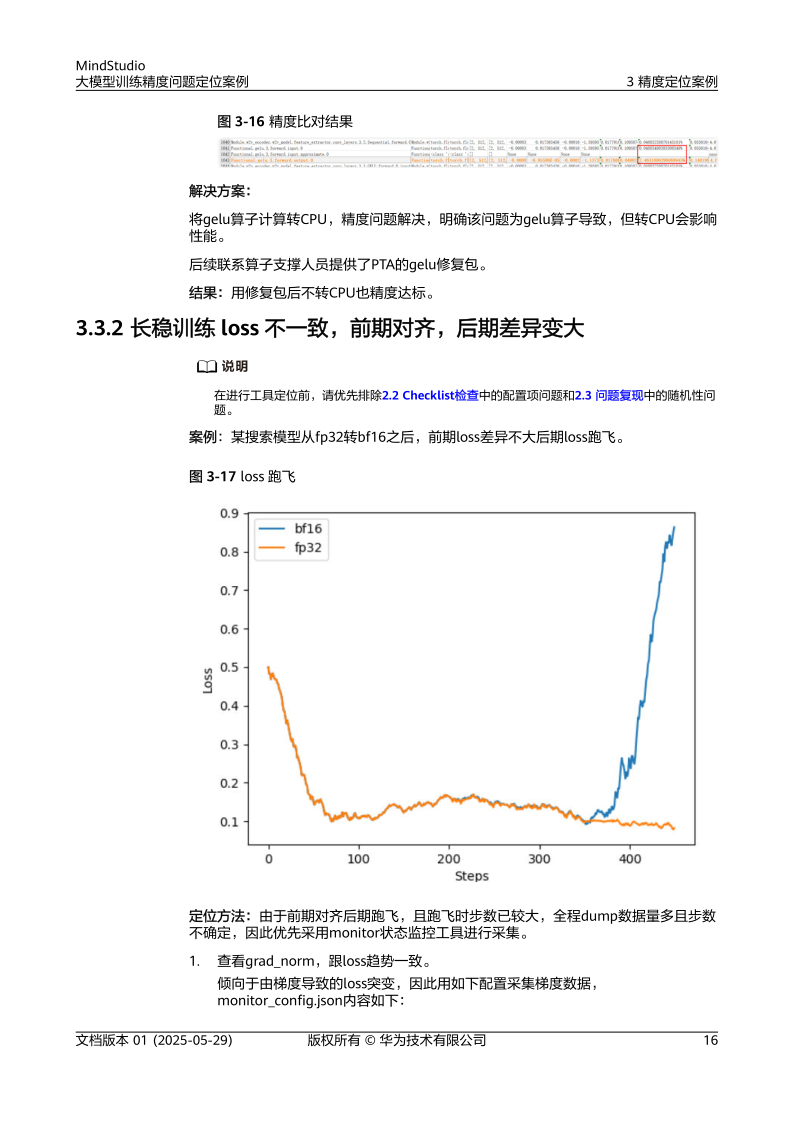
- 算子级比对:利用MindStudio工具对比自有算子与标准算子的输出差异,定位算子实现问题14。
- 精度模式调整:默认FP16模式可能引发数值不稳定,可切换至FP32提升精度(但需权衡性能)[6]。
- 无标杆原生开发场景:
- 超参调优:调整学习率、动量等参数,观察loss收敛曲线[12]。
- 数据审计:检查数据标签分布、缺失值处理及增强策略(如混洗、裁剪)[12]。
- 有标杆迁移场景:
-
步骤4:特殊情况排查
- 溢出或NaN问题:检查激活函数(如ReLU6)、梯度裁剪(gradient clipping)及权重初始化方式38。
- 硬件压测:通过压力测试验证硬件稳定性,排除因设备故障导致的精度波动[1]。
2. 工具链支持
- MindSpore Insight:
提供训练过程可视化分析,支持loss曲线监控、梯度分布统计及算子级性能剖析[10][11]。 - msprobe工具:
针对首step loss不一致问题,通过对比不同迭代步骤的中间结果,定位数据加载或模型初始化错误[2]。 - AscendPyTorchProfiler:
采集性能数据,结合MindStudio Insight定位通信瓶颈或计算资源浪费问题[5][13]。
三、华为典型案例解析
案例1:Checklist不一致导致精度偏差
- 问题现象:模型在昇腾设备上的准确率比预期低5%。
- 定位过程:
- 配置项检查:发现学习率设置错误(实际值比预期小10倍)。
- 数据审计:数据预处理未应用归一化,导致输入分布偏离训练集。
- 模型结构验证:代码中定义的层数与加载的模型参数不匹配。
- 解决方案:修正学习率、补全数据预处理逻辑并重新加载模型参数,精度恢复至预期水平[2]。
案例2:算子实现差异引发迁移问题
- 问题现象:迁移后的模型在特定输入下输出NaN。
- 定位过程:
- 算子比对:发现自定义算子在极端值输入下未实现饱和处理,而标准算子(如TensorFlow)通过ReLU6限制输出范围。
- 精度模式调整:切换至FP32模式后,NaN问题消失,但训练速度下降30%。
- 混合精度优化:对关键算子保留FP32计算,其余部分使用FP16,平衡精度与性能[6][14]。
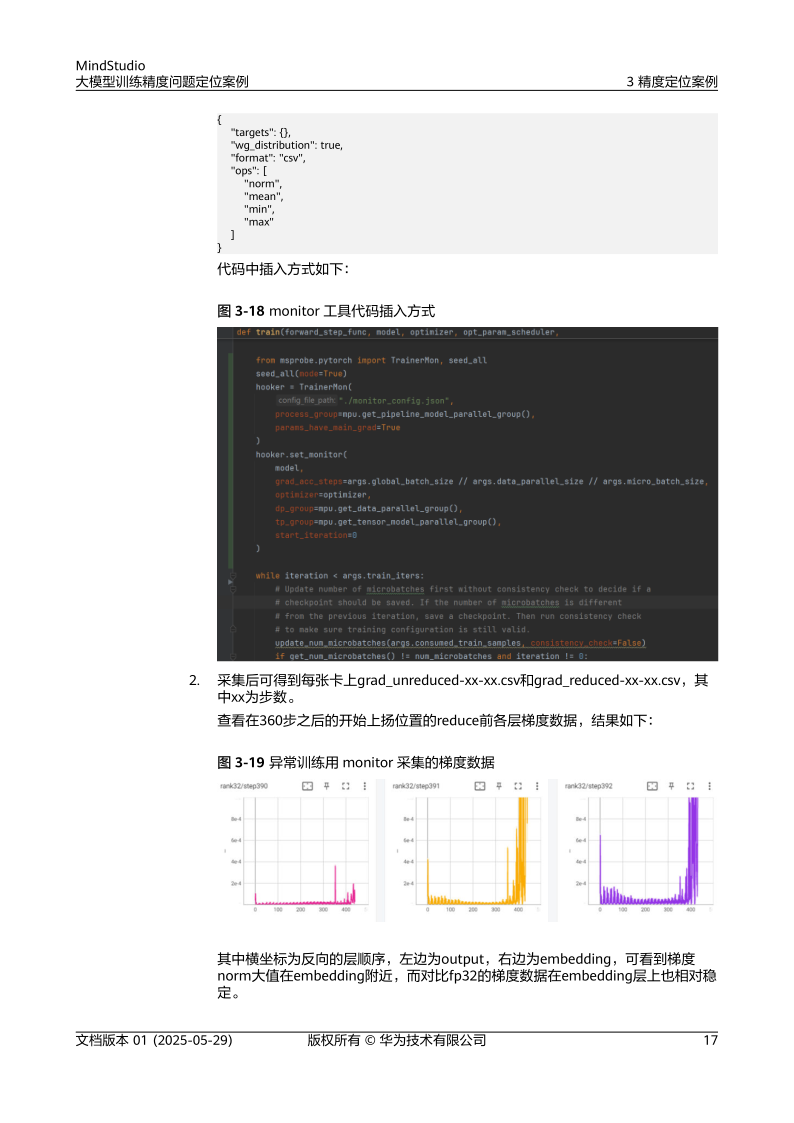
案例3:并行训练通信瓶颈导致长稳loss波动
- 问题现象:多卡训练时,loss在后期出现周期性波动。
- 定位过程:
- 性能数据采集:通过AscendPyTorchProfiler发现部分卡因通信等待闲置。
- 可视化分析:MindStudio Insight显示通信与计算重叠率低,存在资源浪费。
- 并行策略优化:调整数据分片方式,增加梯度聚合频率,减少通信开销[5][13]。
四、精度优化最佳实践
-
分层验证策略
- 代码层:检查脚本逻辑与API使用规范(如MindSpore与PyTorch的差异)[10][12]。
- 模型层:验证模型结构与参数加载一致性[2][10]。
- 训练层:监控loss曲线与梯度分布,结合超参调优提升收敛速度[3][8]。
-
混合精度训练
- 对计算密集型算子(如矩阵乘法)使用FP16加速,对数值敏感型算子(如Softmax)保留FP32[6][18]。
-
硬件协同优化
- 利用昇腾设备的NPU架构特性,优化算子实现(如算子融合、张量并行)[14][17]。
延展
- 查询建议:
- 若需了解具体工具使用,可补充查询“MindSpore Insight 教程”或“AscendPyTorchProfiler 实战案例”。
- 若关注硬件优化,可搜索“昇腾NPU 算子开发指南”。















AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)