DeepSeek-Coder-V2:打破闭源壁垒的代码智能模型
2026.03.12,Eric Huang
摘要
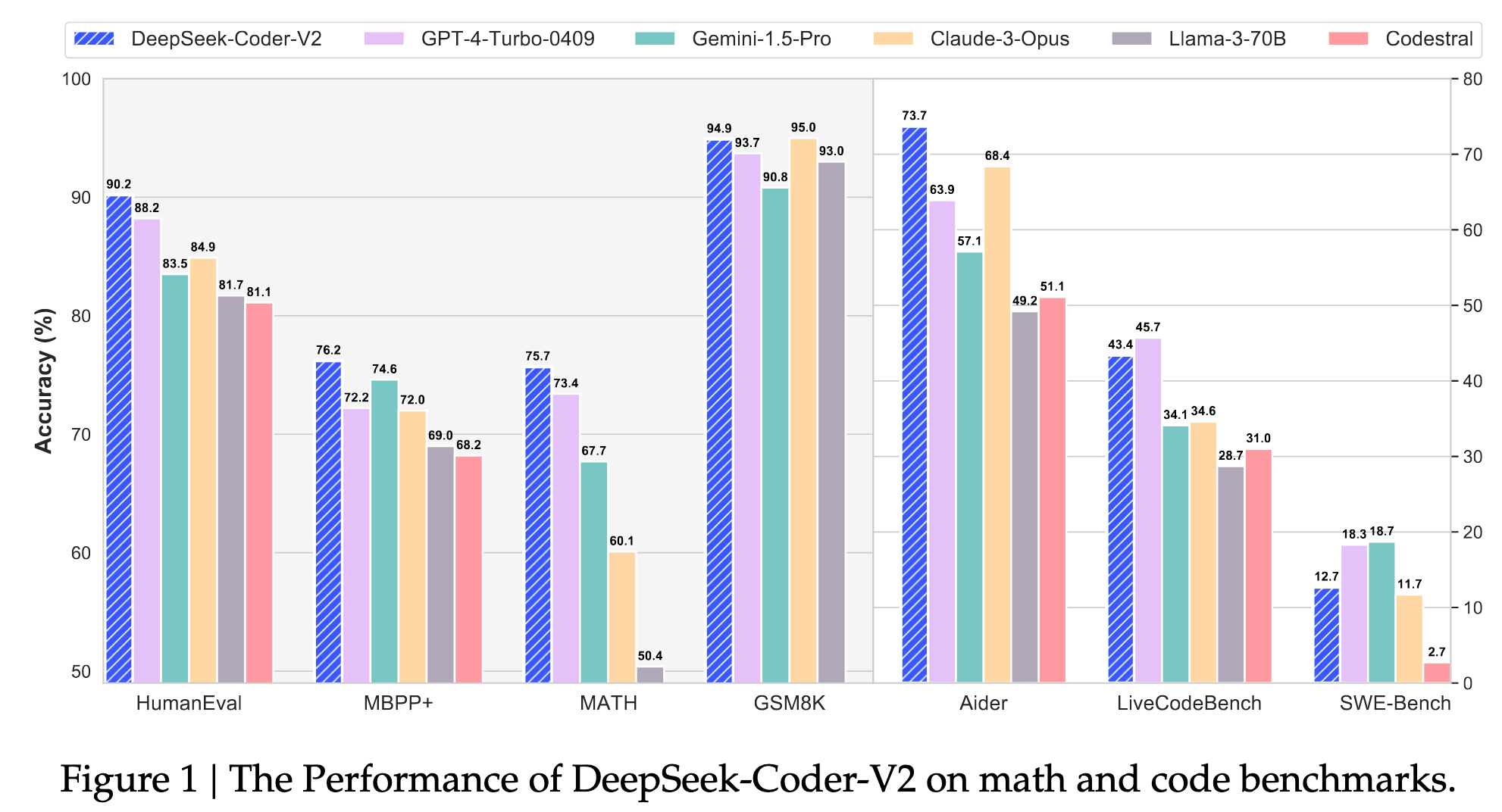
我们提出了 DeepSeek-Coder-V2,这是一个 开源的混合专家(MoE)代码语言模型,在代码相关任务中性能可与 GPT4-Turbo 相媲美。具体来说,DeepSeek-Coder-V2 是在 DeepSeek-V2 的中间检查点基础上,使用额外的 6 万亿个词元进行预训练而得到的。通过这种 持续的预训练,DeepSeek-Coder-V2 显著提升了 DeepSeek-V2 的编码和数学推理能力,同时在通用语言任务中保持了相当的性能。与 DeepSeekCoder-33B 相比,DeepSeek-Coder-V2 在代码相关任务的各个方面以及推理和通用能力方面都取得了显著进步。此外,DeepSeek-Coder-V2 支持的编程语言从 86 种扩展到 338 种,上下文长度也从 16K 扩展到 128K。在标准基准测试中,DeepSeek-Coder-V2 在编码和数学基准测试中取得了优于 GPT4-Turbo、Claude 3 Opus 和 Gemini 1.5 Pro 等闭源模型的性能。
1. Introduction
1.1 Pretraining Data 构建
DeepSeek-Coder-V2 基于 DeepSeek-V2 架构,在其原有数据基础上继续进行大规模代码导向预训练,并额外引入 6T tokens 新语料,以提升代码生成能力。
预训练数据的整体结构为:
- 60% Source Code
- 10% Math Corpus
- 30% Natural Language
这种设计体现了一个典型策略:以代码为核心,同时用数学和自然语言增强推理与理解能力。
在 代码语料方面,共收集 1170B code tokens,来源于 GitHub 与 CommonCrawl,数据清洗与构建流程沿用 DeepSeekMath pipeline。相比早期 DeepSeek-Coder 使用的代码数据,该语料的 编程语言覆盖范围从 86 种扩展到 338 种,显著提升代码多样性。
作者通过 1B 参数模型的消融实验验证了新代码语料的效果:
- HumanEval:30.5% → 37.2%(+6.7%)
- MBPP:44.6% → 54.0%(+9.4%)
说明扩展后的代码语料在代码生成任务上带来了明显收益。
在 数学语料方面,作者从 CommonCrawl 收集 221B math tokens,同样使用 DeepSeekMath 的构建 pipeline,这一规模约为 DeepSeekMath 原始 120B 数据的两倍。
在 自然语言语料方面,则直接从 DeepSeek-V2 原始训练数据中进行采样,以保持语言理解能力。
综合来看,DeepSeek-Coder-V2 的训练数据规模达到:
- 总计 10.2T tokens
- 4.2T 来自 DeepSeek-V2 原始数据
- 6T 来自新增 DeepSeek-Coder-V2 数据集
整体策略可以概括为:在通用 LLM 基础上,通过大规模代码语料与数学语料的强化预训练,构建更强的代码生成模型。
1.2 Evaluation Summary
DeepSeek-Coder-V2 在 代码生成、数学推理与自然语言理解 三个维度进行了系统评测,整体表现达到 开源模型 SOTA,并接近甚至部分超过闭源模型(如 GPT-4 系列、Claude、Gemini)。
(a)Code Generation
在主流代码生成 benchmark 上,DeepSeek-Coder-V2 全面领先开源模型,并接近顶级闭源模型(GPT-4-Turbo、Claude 3 Opus、Gemini 1.5 Pro)。
关键指标:
- HumanEval:90.2%
- MBPP:76.2%(EvalPlus pipeline 下新 SOTA)
- LiveCodeBench:43.4%(Dec 2023 – Jun 2024 题目)
- SWEBench:首个 超过 10% 的开源模型
说明模型不仅在 函数级代码生成(HumanEval/MBPP)表现强,也开始具备一定 真实软件工程任务能力(SWEBench)。
(b)Mathematical Reasoning
DeepSeek-Coder-V2 同时具备 强数学推理能力,在多个数学 benchmark 上接近或超过闭源模型(GPT-4o、Gemini 1.5 Pro、Claude 3 Opus)。
关键指标:
- GSM8K:基础数学推理 benchmark
- MATH:75.7%(接近 GPT-4o 的 76.6%)
- AIME 2024:超过 GPT-4o / Gemini / Claude
- Math Odyssey:高级竞赛级数学
说明其代码训练并未削弱数学能力,反而强化了 逻辑推理能力。
(c)Natural Language Ability
尽管模型以 code model 为主要目标,其 通用语言能力仍接近 DeepSeek-V2。
关键指标:
- MMLU:79.2%(OpenAI simple-eval)
- Arena-Hard(GPT-4 judge):65.0
- MT-Bench:8.77
- AlignBench:7.84
整体表现 显著优于其他 code-specific 模型,并接近通用开源 LLM。
* 核心结论
DeepSeek-Coder-V2 通过 大规模代码+数学数据预训练,实现了一个较少见的能力组合:
Code Generation SOTA + Strong Math Reasoning + Competitive General Language Ability
这使其成为当时 最接近闭源代码模型能力的开源方案之一。
2. Data Collection Pipeline
DeepSeek-Coder-V2 的预训练数据结构为 60% code / 10% math / 30% natural language。其中自然语言直接来自 DeepSeek-V2 dataset,因此该部分重点介绍 code 与 math 数据的构建流程与质量控制。
2.1. GitHub Code Data Collection
代码数据主要来自 GitHub(2023年11月之前的公开仓库)。数据清洗流程复用 DeepSeek-Coder pipeline,核心目标是 过滤低质量文件 + 去重(near-deduplication)。
主要过滤规则:
- 异常行长度过滤
- 平均行长 > 100 characters → 删除
- 最大行长 > 1000 characters → 删除
- 文本比例过滤
- 字母字符比例 < 25% → 删除
- XML 文件过滤
- 若文件前 100 字符包含
<?xml version=→ 删除 - (XSLT 语言除外)
- 若文件前 100 字符包含
- HTML 文件质量控制
- 可见文本占比 ≥ 20%
- 可见文本 ≥ 100 characters
- JSON / YAML 文件
- 保留字符数 50–5000 的文件
- 过滤大规模数据文件
经过过滤与去重后得到:
- 821B code tokens
- 185B code-related text tokens(Markdown、Issues 等)
覆盖 338 种编程语言(DeepSeek-Coder 为 86 种)。
数据工程 Insight:这一阶段本质上是在构建一个 高精度 seed corpus:通过严格过滤确保语料质量与分布可靠,为后续数据扩展提供稳定的统计先验。由于 GitHub 原始数据规模巨大且噪声较多,数据工程通常采取 precision-first 的策略,先建立高质量的基本盘,再逐步扩大数据召回范围。
2.2. CommonCrawl Code & Math Data Mining
为了扩展 代码相关文本与数学语料,作者在 CommonCrawl 上使用 DeepSeekMath pipeline 进行数据挖掘。
Step 1:构建 Seed Corpus
初始种子网站包括:
- 代码社区:StackOverflow
- 技术文档:PyTorch docs
- 数学社区:StackExchange
Step 2:fastText 领域识别
使用 seed corpus 训练 fastText classifier,用于从 CommonCrawl 中识别:
- code-related pages
- math-related pages
由于中文等语言没有空格分词,因此使用 DeepSeek-V2 的 BPE tokenizer 提升 fastText 召回率。
Step 3:Domain Expansion
对于每个 domain:
-
若 ≥10% 页面被识别为 code/math → 该 domain 被标记为 代码或数学领域站点
随后:
- 标注相关 URL
- 将未采集页面加入 seed corpus
- 进行 多轮迭代扩展
Step 4:Iterative Data Crawling
经过 3轮迭代,获得:
- 70B code-related tokens
- 221B math tokens
此外在 GitHub 上使用同样 pipeline 再进行 2轮数据扩展:
- 额外获得 94B source code
数据工程 Insight:这种数据构建过程体现了一种典型的大规模语料工程策略:高精度 seed → 分布学习 → 迭代扩展(bootstrapping expansion)。首先通过严格过滤获得高质量 seed corpus,然后利用其统计分布训练分类器或启发式规则,在更大的候选数据池中识别相似样本并逐步扩展语料规模。该过程通常仅进行 1–3轮迭代,因为随着轮数增加噪声会逐渐累积,边际收益快速下降。
DeepSeek 在 GitHub 上额外获得 94B source code tokens,虽然规模相较初始 821B code tokens 并不巨大,但这部分数据往往来自 长尾语言与技术生态,能够显著提升语料多样性与模型泛化能力。
2.3. Final Code Corpus
最终构建的代码语料:1,170B code-related tokens
来源:GitHub 和 CommonCrawl
Tokenizer:DeepSeek-V2 BPE tokenizer
数据 Insight:值得注意的是,DeepSeek-Coder-V2 在语料中专门加入 221B math tokens(约10%)。其作用并非训练数学模型,而是增强代码模型的 符号推理能力(symbolic reasoning)。代码生成与数学推导在结构上高度相似,都依赖变量绑定、符号操作与逐步求解过程;而数学文本通常具有 problem → step-by-step reasoning → solution 的结构,这与代码任务中的 问题理解 → 算法推理 → 程序实现 过程高度对应。因此数学语料能够强化模型的 Chain-of-Thought 推理能力、变量一致性追踪以及逻辑结构建模能力。此外,数学表达式具有更高的信息密度,使模型在较少 token 中学习到更丰富的结构关系,从而提升算法理解与复杂代码推理能力。
2.4. Code Corpus Ablation Study
作者通过 1B parameter model 验证新代码语料质量(Table 1)。
1B模型训练 1T tokens(DeepSeek-Coder 的语料 vs DeepSeek-Coder-V2 的语料):
- HumanEval:30.5 → 36.0 (+5.5)
- MBPP:44.6 → 49.0 (+4.4)
1B模型训练 2T tokens(1T vs 2T):
- HumanEval:36.0 → 37.2
- MBPP:49.0 → 54.0
结论:新构建的 code corpus 明显优于 DeepSeek-Coder 原始代码语料。
该实验表明,代码模型性能提升不仅来自模型结构改进,更重要的来源是 高质量数据工程:更好的语料分布与更高的信息密度可以显著提升代码生成能力。
* 核心总结
DeepSeek-Coder-V2 的数据构建策略可以概括为:
High-quality GitHub filtering + CommonCrawl domain mining + iterative corpus expansion
最终得到:
- 338 programming languages
- 1.17T code tokens
- 221B math tokens
并通过 ablation experiments 验证数据质量提升对代码生成性能的显著贡献。
3. Training Policy
3.1 Training Strategy
DeepSeek-Coder-V2 采用两种训练目标:
- Next Token Prediction (NTP):标准自回归语言建模目标
- Fill-in-the-Middle (FIM):代码补全训练目标
但不同规模模型的使用策略不同:
| Model | Training Objective |
|---|---|
| DeepSeek-Coder-V2-Lite (16B) | NTP + FIM |
| DeepSeek-Coder-V2 (236B) | NTP only |
FIM Training
FIM 用于提升 代码补全能力,采用 PSM (Prefix-Suffix-Middle) 结构:
<|fim_begin|> f_pre <|fim_hole|> f_suf <|fim_end|> f_middle <|eos_token|>
其中,f_pre 是前缀代码,f_suf 是后缀代码,f_middle 是需要预测的中间代码。
训练过程:
- FIM sampling rate = 0.5。也就是说,在数据 pipeline 中,每个代码文档首先进行 FIM sampling:以 0.5 的概率将该样本转换为 FIM 训练样本,否则保持为普通 NTP 样本;
- 在 document-level pre-packing 阶段构造 FIM 数据。在这里,sequence packing 指的是将多个文档拼接为固定长度训练序列
max_seq_len,以提高 GPU 利用率; - 学习目标与 PSM 框架一致:prefix + suffix → middle.
作用:增强模型在真实 IDE 场景中的中间补全能力。
训练 Insight:DeepSeek-Coder-V2 的一个有趣设计是,236B 模型仅使用 NTP 训练,而不加入 FIM 目标。这主要与模型规模带来的推理能力有关。当模型参数规模足够大时,其上下文建模能力显著增强,模型可以通过阅读 prefix 与 suffix 的语义约束,在推理阶段直接推断缺失代码。
此时,FIM 可以退化为一种 prompt-level inference capability,而不一定需要作为训练目标显式学习。此外,FIM 会改变代码 token 的自然顺序(prefix–suffix–middle),在超大模型训练中可能破坏真实代码分布,因此 DeepSeek 在 236B 模型中选择保留最稳定的 NTP 目标。
这种设计体现了一种经验规律:FIM 对中小规模 Code LLM 的 IDE 补全能力提升明显,但随着模型规模扩大,其收益会逐渐降低。
3.2. Model Architecture
模型架构 完全继承 DeepSeek-V2:
- 16B → 对应 DeepSeek-V2-Lite
- 236B → 对应 DeepSeek-V2
在训练过程中遇到了不稳定的现象,归因为 exponential normalization:
DeepSeek-V2 在 MoE routing 中引入了 exponential normalization,用指数函数放大 router score,从而使 expert 选择更加稀疏。然而在代码模型训练中,由于代码 token 分布本身较为尖锐,这种指数放大会导致 routing 权重过度集中(winner-takes-all),使梯度几乎全部流向少数 expert,从而产生 gradient spike 和训练不稳定问题。因此,DeepSeek-Coder-V2 最终回退到更稳定的传统 softmax normalization,以保证大规模训练过程的数值稳定性。
3.3 Training Hyperparameters
优化器为 AdamW,其中 β1 = 0.9,β2 = 0.95,weight decay = 0.1
学习率策略:
- Cosine decay scheduler
- 2000 warmup steps
- 最终 LR → 降至初始值的 10%
Batch size 与 LR 规模均与 DeepSeek-V2 的设置一致
Pretraining Continuation Strategy
DeepSeek-Coder-V2 并非从零训练,而是 从 DeepSeek-V2 的中间 checkpoint 继续训练。
该 checkpoint 已训练:4.2T tokens;随后在代码数据上继续训练:+6T tokens
最终:Total pretraining tokens = 10.2T
这样可以在保留 通用语言能力 的同时,重点强化 代码生成能力。
Table 2:Training Configuration
| Model | Total Params | Active Params | Pretrain Tokens | LR Scheduler | FIM |
|---|---|---|---|---|---|
| DeepSeek-Coder-V2-Lite | 16B | 2.4B | 4.2T + 6T | Cosine | Enable |
| DeepSeek-Coder-V2 | 236B | 21B | 4.2T + 6T | Cosine | Disable |
关键点:
- 两个模型 共享相同数据与训练流程
- 仅在 规模与 FIM 使用策略上存在差异。
3.4 Long Context Extension
为支持长上下文代码理解,DeepSeek-Coder-V2 继承 DeepSeek-V2 的方案,通过 YaRN(Yet another RoPE extensioN,ICLR 2024) 将上下文窗口扩展到 128K tokens。
(a)YaRN Context Scaling
使用 YaRN 对 RoPE 位置编码进行扩展,其关键超参数与 DeepSeek-V2 保持一致:
- scale s = 40,α = 1,β = 32
该方法能够在 不重新训练完整模型 的情况下扩展上下文长度(16K→128K),同时保持稳定性能。
(b)Two-Stage Long Context Training
为了让模型适应更长序列,作者进行了 两阶段继续训练:
Stage 1
- Sequence length:32K
- Batch size:1152 sequences
- Training steps:1000
Stage 2
- Sequence length:128K
- Batch size:288 sequences
- Training steps:1000
同时在该阶段 提高长上下文样本比例(long-context data upsampling),强化模型对长序列的建模能力。
(c)Long Context Evaluation
作者使用 Needle In A Haystack (NIAH) 测试验证长上下文检索能力。
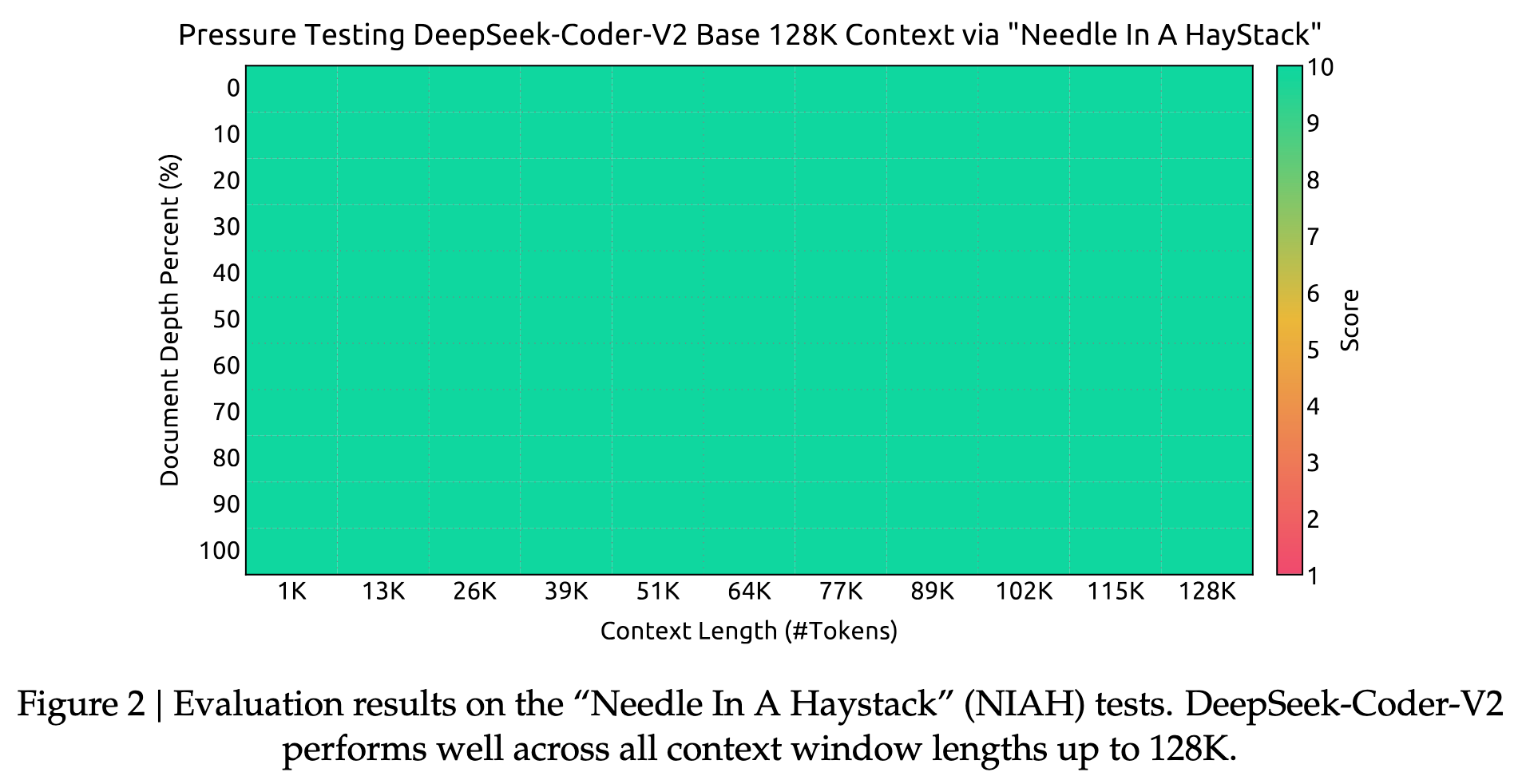
任务形式:
- 在长文本中插入一条 needle 信息
- 模型需要在 不同上下文长度与不同深度位置 找到该信息
实验结果(Figure 2)表明:
- 在 1K → 128K context length 范围内
- 不同 document depth(0–100%)
模型均能 稳定检索目标信息(score≈10)。
* 核心结论
通过 YaRN + 两阶段长序列训练 + 提高长上下文样本比例,DeepSeek-Coder-V2 成功将上下文窗口扩展至 128K tokens,并在 NIAH 测试中表现出 稳定的长上下文检索能力。
3.5 Alignment
为构建 DeepSeek-Coder-V2 Chat,作者采用 SFT + RL 两阶段对齐流程,并专门针对 代码与数学任务设计数据与奖励信号。
3.5.1. Supervised Fine-Tuning (SFT)
SFT 数据由 代码、数学、通用指令数据混合构成:
数据来源:
- 20k code instruction(来自 DeepSeek-Coder)
- 30k math instruction(来自 DeepSeek-Math)
- 部分 DeepSeek-V2 instruction data(保持通用能力)
最终 SFT 数据规模:300M tokens
训练设置:
- LR schedule:cosine decay
- warmup:100 steps
- initial LR:5e-6
- batch size:1M tokens
- total training tokens:1B
目标:在保持通用语言能力的同时,增强 代码生成 + 数学推理能力。
3.5.2. Reinforcement Learning (RL)
在 SFT 之后,作者进一步使用 RL 对齐模型能力。
(a)Prompt Dataset
从多种来源收集 code / math prompts,每个代码 prompt 都附带 test cases。
过滤后规模:≈ 40k prompts
(b)Reward Modeling
代码任务中存在一个天然信号:
compiler feedback
pass tests → 1
fail tests → 0
但作者发现:
- test cases 覆盖不完整
- compiler signal 噪声较大
因此采用方案:
训练 Reward Model(RM)来拟合 compiler feedback
优势:更 robust,更 generalizable
RL Signal Comparison
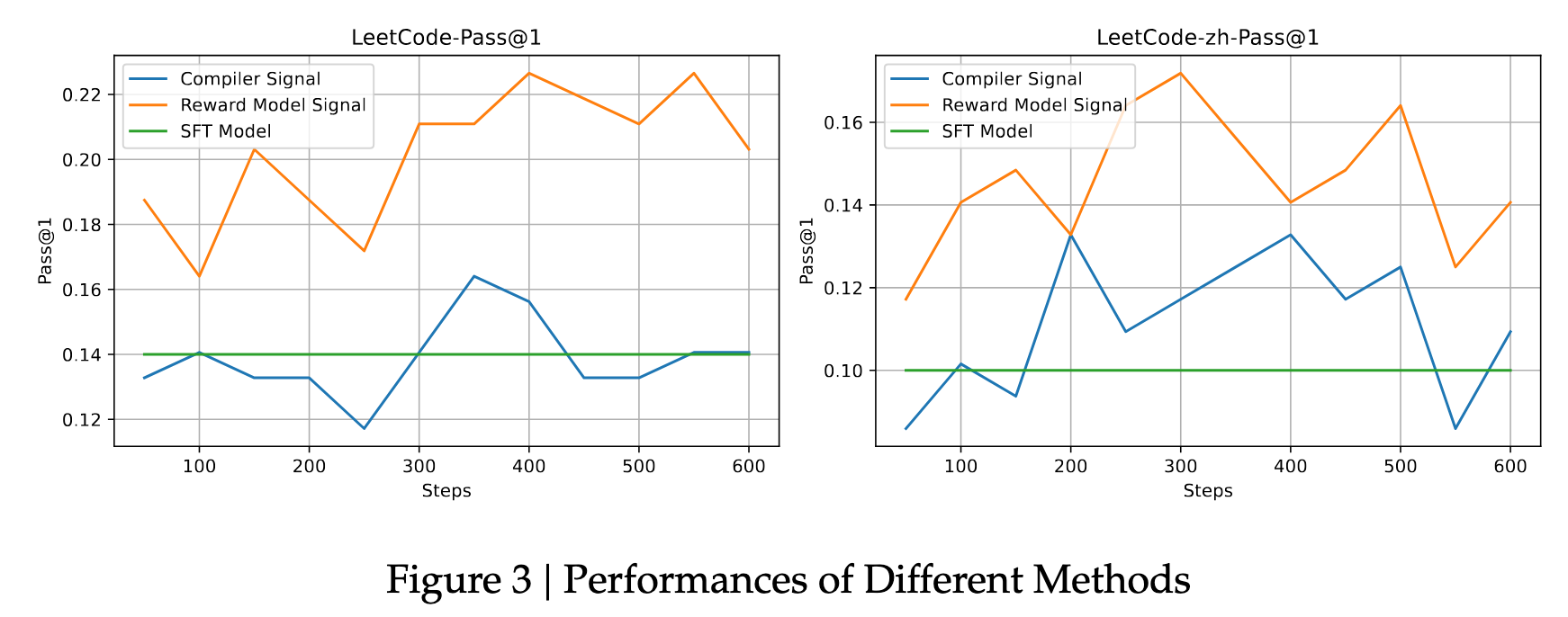
图3对比了三种训练信号:
- Compiler signal
- Reward model signal
- SFT baseline
评测任务:
- LeetCode Pass@1
- LeetCode-zh Pass@1
实验结果:Reward model signal > Compiler signal > SFT
说明直接使用 compiler 0-1 信号 不如 reward model 稳定有效。
因此,所有后续 RL 实验均使用 Reward Model signal。
(c)RL Algorithm
DeepSeek-Coder-V2 使用:GRPO (Group Relative Policy Optimization)
特点:
- DeepSeek-V2 同款算法
- 无需 critic model
- 相比 PPO 训练成本更低
核心思想:在 group sample 内进行相对优势比较,从而稳定策略更新。
* 核心总结
DeepSeek-Coder-V2 的对齐流程:
Pretraining
↓
SFT (code + math instruction)
↓
Reward Model Training
↓
GRPO Reinforcement Learning
关键设计:
- compiler feedback → reward model
- GRPO RL optimization
最终实现:更稳定、更泛化的代码生成能力提升。
4. Experimental Results
4.1 Code Generation
作者在代码生成任务上系统评估 DeepSeek-Coder-V2,并与主流 Code LLM 与通用 LLM 进行比较。对比对象包括 CodeLlama、StarCoder / StarCoder2、DeepSeek-Coder、Codestral 等代码模型,以及 GPT-4 系列、Claude-3-Opus、Gemini-1.5-Pro、Llama3-70B 等通用模型。尽管部分模型并非专门为代码训练,但在代码 benchmark 上通常具有较强表现,因此能够作为重要参考。
代码能力主要在 HumanEval 与 MBPP+ 上评测。HumanEval 包含 164 个 Python 编程任务,通过单元测试验证生成代码是否正确,并在 zero-shot setting 下评估模型能力。MBPP 使用 MBPP-Plus 版本以获得更稳定结果。为了测试跨语言能力,作者将 HumanEval 扩展到多种编程语言,包括 C++、Java、PHP、TypeScript、C#、Bash、JavaScript、Swift、R、Julia、D、Rust 与 Racket。所有模型均采用 greedy decoding + pass@1,并在统一脚本与环境下复现实验,确保比较公平。
从整体结果来看(Table 3),DeepSeek-Coder-V2-Instruct 的平均得分为 75.3%,在所有模型中排名第二,仅略低于 GPT-4o。
| Model | Avg Score |
|---|---|
| GPT-4o | 76.4% |
| DeepSeek-Coder-V2-Instruct | 75.3% |
| GPT-4-Turbo | 72.3% |
| Claude-3-Opus | 70.8% |
| Gemini-1.5-Pro | 68.9% |
这一结果表明 DeepSeek-Coder-V2 已经 打破闭源模型在代码 benchmark 上的长期优势格局,成为最具竞争力的开源代码模型之一。
在语言维度上,DeepSeek-Coder-V2 在多种主流语言上表现突出,例如 Java 与 PHP 取得最高分,在 Python、C++、C#、TypeScript 与 JavaScript 等语言上也保持接近最优水平,体现出较强的 跨语言代码生成能力。
| Model | Python | Java | C++ | C# | TypeScript | JavaScript | PHP |
|---|---|---|---|---|---|---|---|
| DS-Coder-V2 | 90.2% | 82.3% | 84.8% | 82.3% | 83.0% | 84.5% | 79.5% |
另一个值得注意的结果来自 DeepSeek-Coder-V2-Lite(16B)。尽管规模明显小于传统代码模型,但其 平均得分达到 65.6%,反而超过 DeepSeek-Coder-33B 的 61.9%,说明改进的数据构建、训练策略与模型设计显著提升了 参数效率。
| Model | Params | Avg |
|---|---|---|
| DeepSeek-Coder-33B | 33B | 61.9% |
| DeepSeek-Coder-V2-Lite | 16B | 65.6% |
总体而言,DeepSeek-Coder-V2 在代码生成 benchmark 上实现了 开源 SOTA,并逼近最强闭源模型 GPT-4o,同时在 多语言代码能力与模型效率方面展现出明显优势。
Competitive Programming Evaluation(LiveCodeBench / USACO)
为了评估模型在 真实竞赛级编程任务中的能力,作者进一步使用 LiveCodeBench (LCB) 与 USACO 两个 benchmark。相比 HumanEval 与 MBPP 这类函数级代码生成任务,这两个 benchmark 更接近真实算法竞赛环境,对模型的 算法设计能力、长推理能力与复杂代码实现能力要求更高。
LiveCodeBench 是一个严格控制数据污染的代码生成 benchmark,持续从 LeetCode、AtCoder、CodeForces 三个平台收集新的竞赛题目。由于 DeepSeek-Coder-V2 的训练数据截止时间为 2023年11月之前,实验中使用 2023-12 → 2024-06 的题目子集,以避免训练数据泄露。
USACO benchmark 则包含 307 道美国信息学奥林匹克竞赛题目,并提供高质量的 测试用例、参考代码与官方解析,用于评估模型在算法竞赛场景中的综合能力。
表4给出了各模型在 LiveCodeBench 与 USACO 上的表现。从整体结果来看:
| Model | LiveCodeBench Overall | USACO |
|---|---|---|
| GPT-4-Turbo-0409 | 45.7% | 12.3% |
| GPT-4o | 43.4% | 18.8% |
| DeepSeek-Coder-V2-Instruct | 43.4% | 12.1% |
| Claude-3-Opus | 34.6% | 7.8% |
| Gemini-1.5-Pro | 34.1% | 4.9% |
可以看到 DeepSeek-Coder-V2-Instruct 在 LiveCodeBench 上取得 43.4% 的 overall score,与 GPT-4o 持平,在所有模型中排名 第二,仅略低于 GPT-4-Turbo-0409(45.7%)。在 USACO 上虽然仍落后于 GPT-4o,但也显著领先大多数开源代码模型。
从难度维度来看,DeepSeek-Coder-V2 在 Easy 与 Medium 难度题目上表现尤为突出:
| Difficulty | DS-Coder-V2 |
|---|---|
| Easy | 84.1% |
| Medium | 29.9% |
| Hard | 5.3% |
整体而言,这些结果表明 DeepSeek-Coder-V2 不仅在标准代码 benchmark(HumanEval / MBPP)上表现优异,在 更接近真实算法竞赛环境的复杂编程任务中同样具备强竞争力,成为 最接近 GPT-4 系列能力的开源代码模型之一。
4.2 Code Completion
除了函数级代码生成,作者还评估模型在 代码补全(code completion) 场景下的能力,包括 repository-level completion 与 Fill-in-the-Middle (FIM) 两类任务。
4.2.1 Repository-Level Code Completion(RepoBench)
作者使用 RepoBench v1.1 评估模型在真实代码仓库环境中的补全能力。该数据集来自 真实开源 GitHub 仓库(Python / Java),为避免数据污染,仅使用 2023年12月创建的代码仓库(模型训练数据截止 2023年11月)。评测在 2k / 4k / 8k / 12k / 16k 五种上下文长度下进行,采用 greedy decoding,模型最多生成 64 tokens,并以生成的第一行有效代码作为预测结果。指标为 Exact Match Accuracy。
实验结果(Table 5)显示,DeepSeek-Coder-V2-Lite-Base 在小规模参数下仍能取得竞争力表现:
| Model | Active Params | Python Avg | Java Avg |
|---|---|---|---|
| DS-Coder-Base-33B | 33B | 39.1% | 44.8% |
| DS-Coder-V2-Lite-Base | 2.4B | 38.9% | 43.3% |
| Codestral | 22B | 46.1% | 45.7% |
尽管 V2-Lite 的 active parameters 仅 2.4B,其 Python completion 表现已接近 DeepSeek-Coder-33B,Java completion 接近 DeepSeek-Coder-7B。相比 Codestral 虽然性能略低,但由于 active parameters 更少(约十分之一),在实际 IDE 代码补全场景中具有明显的 推理速度优势。
4.2.2 Fill-in-the-Middle (FIM) Completion
DeepSeek-Coder-V2-Lite 在预训练阶段使用 FIM rate = 0.5 的训练策略,使模型能够根据 前后代码上下文(prefix + suffix)预测中间缺失代码。这种能力对 IDE 自动补全工具尤为重要,也是 SantaCoder、StarCoder、CodeLlama 等代码模型的关键训练机制。
作者在 Single-Line Infilling benchmark 上评估 FIM 能力,覆盖 Python / Java / JavaScript 三种语言,指标为 line exact match accuracy。结果(Table 6)如下:
| Model | Active Params | Python | Java | JS | Mean |
|---|---|---|---|---|---|
| StarCoder | 16B | 71.5% | 82.3% | 83.0% | 80.2% |
| DS-Coder-Base-33B | 33B | 80.5% | 88.4% | 86.6% | 86.4% |
| DS-Coder-V2-Lite-Base | 2.4B | 80.0% | 89.1% | 87.2% | 86.4% |
可以看到,DeepSeek-Coder-V2-Lite-Base 在仅 2.4B active parameters 的情况下达到 86.4% 的平均得分,与 DeepSeek-Coder-33B 基本持平,并在 Java 与 JavaScript 上取得最高分。这说明 FIM 训练策略显著增强了模型的 上下文补全能力,使小模型也能在代码补全任务中达到接近大模型的表现。
整体来看,DeepSeek-Coder-V2 在代码补全任务上展现出两个重要特点:
一方面,小规模模型 V2-Lite 在 repository-level completion 与 FIM 任务中都具有很强的 参数效率;另一方面,FIM 训练显著提升了模型在 真实 IDE 场景中的中间补全能力。
4.3 Code Fixing
为了评估模型在 自动程序修复(program repair) 场景中的能力,作者使用 Defects4J、SWE-bench 与 Aider 三个 benchmark。与前面的代码生成任务不同,这类任务要求模型理解真实代码库并生成 patch 修复 bug,因此对 长上下文理解、代码推理与编辑能力提出更高要求。
Defects4J 是软件工程领域经典的 bug 修复数据集,包含来自 Apache Commons、JFreeChart、Closure Compiler 等开源项目的真实 bug,并配有测试套件用于验证修复效果。由于原始任务可能涉及多个文件修改,作者筛选出 238 个只需修改单个方法的 bug 进行评测。
SWE-bench 则更接近真实软件开发场景:模型需要在完整代码仓库上下文中,根据 GitHub issue 生成 patch 来解决问题。
Aider benchmark 评估模型在 Python 文件编辑任务中的能力,共包含 133 个代码修改任务,重点测试模型是否能够按照 prompt 要求正确修改代码。
表7给出了各模型在软件修复 benchmark 上的表现:
| Model | Defects4J | SWE-Bench | Aider |
|---|---|---|---|
| GPT-4o | 26.1% | 26.7% | 72.9% |
| GPT-4-Turbo | 24.3% | 18.3% | 63.9% |
| Claude-3-Opus | 25.5% | 11.7% | 68.4% |
| DeepSeek-Coder-V2-Instruct | 21.0% | 12.7% | 73.7% |
可以看到,在 开源模型中 DeepSeek-Coder-V2-Instruct 表现最强:
- Defects4J:21.0%
- SWE-bench:12.7%
其性能已经接近部分闭源模型。同时在 Aider benchmark 上取得 73.7% 的最高分,甚至 超过 GPT-4o 与 Claude-3-Opus,说明模型在 代码编辑与自动修复任务中具有很强的实用能力。
4.4 Code Understanding and Reasoning
除了代码生成与修复能力,作者还评估模型在 代码理解与推理(code reasoning)方面的表现,使用 CRUXEval benchmark。
CRUXEval 包含 800 个 Python 函数,并配有输入输出示例,任务分为两个方向:
- CRUXEval-I:给定输入,预测函数输出
- CRUXEval-O:给定输出,反推可能输入
该设计同时测试模型的 正向执行理解与 逆向推理能力。评测指标为 COT(chain-of-thought)推理设置下的准确率。
表8展示了不同模型在 CRUXEval 上的表现:
| Model | CruxEval-I | CruxEval-O |
|---|---|---|
| GPT-4o | 77.4% | 88.7% |
| GPT-4-Turbo | 75.7% | 82.0% |
| Claude-3-Opus | 73.4% | 82.0% |
| DeepSeek-Coder-V2-Instruct | 70.0% | 75.1% |
在开源模型中,DeepSeek-Coder-V2-Instruct 明显领先其他模型,在 CRUXEval-I 与 CRUXEval-O 上分别达到 70.0% 与 75.1%。不过与 GPT-4o 等闭源模型相比仍存在一定差距。论文认为这一差距主要源于 模型规模差异:DeepSeek-Coder-V2 仅有 21B active parameters,远小于闭源模型,因此在复杂代码推理任务上仍有一定限制。
总体而言,这些实验表明 DeepSeek-Coder-V2 不仅在 代码生成任务上表现强劲,在 代码修复、代码编辑与代码理解推理等更复杂的软件工程任务中也具备竞争力,成为当时最强的开源代码模型之一。
4.5 Mathematical Reasoning
为了评估模型的数学推理能力,作者使用 GSM8K、MATH、AIME 2024 与 Math Odyssey 四个 benchmark,其中 GSM8K 属于基础数学推理任务,而 MATH 与 AIME、Math Odyssey 更接近竞赛级数学问题。实验统一采用 zero-shot chain-of-thought prompting,并使用 greedy decoding(不使用工具或 voting)。
表9显示 DeepSeek-Coder-V2 在数学任务上表现非常强:
| Model | GSM8K | MATH | AIME 2024 | Math Odyssey |
|---|---|---|---|---|
| GPT-4o | 95.8% | 76.6% | 2/30 | 53.2% |
| DeepSeek-Coder-V2 | 94.9% | 75.7% | 4/30 | 53.7% |
| Claude-3-Opus | 95.0% | 60.1% | 2/30 | 40.6% |
可以看到,DeepSeek-Coder-V2 在 MATH(75.7%)与 Math Odyssey(53.7%) 上几乎与 GPT-4o 持平,并在 AIME 2024 上解决了最多题目(4/30)。这一结果说明模型在 复杂数学推理任务上具备较强能力,而这种能力很可能来自其训练数据中较高比例的 代码与数学语料。
4.6 General Natural Language Ability
由于 DeepSeek-Coder-V2 是在 DeepSeek-V2 checkpoint 上继续训练得到的,因此仍然保留了较强的通用语言能力。作者将 DeepSeek-Coder-V2-Instruct 与 DeepSeek-V2-Chat 进行对比,在英语、中文以及开放式生成任务上进行评估。
评测 benchmark 包括:
- English reasoning / knowledge:BBH、MMLU、ARC、TriviaQA、NaturalQuestions、AGIEval
- Chinese benchmarks:CLUEWSC、C-Eval、CMMLU
- Open-ended evaluation:Arena-Hard、AlpacaEval 2.0、MT-Bench、AlignBench
部分代表性结果如下:
| Model | BBH | MMLU | Arena-Hard | MT-Bench |
|---|---|---|---|---|
| DeepSeek-V2 Chat | 79.7 | 78.1 | 41.6 | 8.97 |
| DeepSeek-Coder-V2 Instruct | 83.9 | 79.2 | 65.0 | 8.77 |
可以看到 DeepSeek-Coder-V2-Instruct 在 推理类 benchmark(BBH、Arena-Hard) 上明显优于 DeepSeek-V2 Chat,这与模型在训练过程中引入大量 代码与数学推理任务密切相关。Arena-Hard 本身包含大量代码与数学问题,因此 DeepSeek-Coder-V2 在该 benchmark 上优势尤为明显。
不过在 知识密集型任务(如 TriviaQA)以及部分开放式对话评测(MT-Bench、AlpacaEval、AlignBench)上,DeepSeek-V2 Chat 略占优势。论文认为原因在于 DeepSeek-Coder-V2 的训练数据中 Web text 比例较少,以及其对齐阶段更偏向 代码与推理任务。
总体来看,DeepSeek-Coder-V2 在保持较强通用语言能力的同时,在 推理相关任务(尤其是代码与数学推理)上表现更为突出。
5. Conclusion
本文介绍了一种名为 DeepSeek-Coder-V2 的模型,旨在进一步推进代码智能领域的发展。该模型基于 DeepSeek-V2 进行持续预训练,预训练数据来自一个包含 6T 个词元的高质量多源语料库。通过持续的预训练,我们发现 DeepSeek-Coder-V2 显著提升了模型在编码和数学推理方面的能力,同时保持了与 DeepSeek-V2 相当的通用语言性能。与 DeepSeek-Coder 相比,DeepSeek-Coder-V2 支持的编程语言数量大幅增加,从 86 种增至 338 种,并且最大上下文长度也从 16K 扩展到 128K 个词元。实验结果表明,在编码和数学相关的任务中,DeepSeek-Coder-V2 的性能与 GPT-4 Turbo、Claude 3 Opus 和 Gemini 1.5 Pro 等最先进的闭源模型相当。
尽管 DeepSeek-Coder-V2 在标准基准测试中取得了令人瞩目的成绩,但我们发现,与 GPT-4 Turbo 等当前最先进的模型相比,其指令遵循能力仍存在显著差距。这种差距导致其在 SWEbench 等复杂场景和任务中表现不佳。因此,我们认为,一个优秀的代码模型不仅需要强大的编码能力,还需要卓越的指令遵循能力才能应对现实世界中复杂的编程场景。未来,我们将更加专注于提升模型的指令遵循能力,以更好地处理现实世界中的复杂编程场景,并提高开发效率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)