Spring AI + RAG 从 0 到 1 落地:本地知识库 + 联网搜索,一套代码直接跑通
一、先搞懂:RAG 到底是什么?
不用啃复杂理论,一句话说清:RAG = 本地知识库检索 + AI 生成
核心流程:
- 把本地文档(PDF/Word)转成「向量」存到向量库(比如 Redis)
- 用户提问时,先把问题转成向量,去向量库找最相关的内容
- 把找到的内容 + 用户问题一起传给大模型
- 大模型基于“本地知识 + 自身能力”生成答案
优势:
- 解决大模型“知识过期”问题
- 保证答案和你的业务文档一致
- 不用训练大模型,成本低、落地快
二、环境准备:Docker 装 Redis 向量库
RAG 核心是向量存储,我们用 Redis(带 Redis Stack 插件,支持向量检索),Docker 一键部署:
1. 拉取redis-stack镜像
docker pull redis/redis-stack:latest
2. 启动 Redis 容器
以Docker方式启动:
docker run -d \ --name redis-stack \ -p 9379:6379 \ -e REDIS_ARGS="--requirepass 123456" \ redis/redis-stack-server:latest
```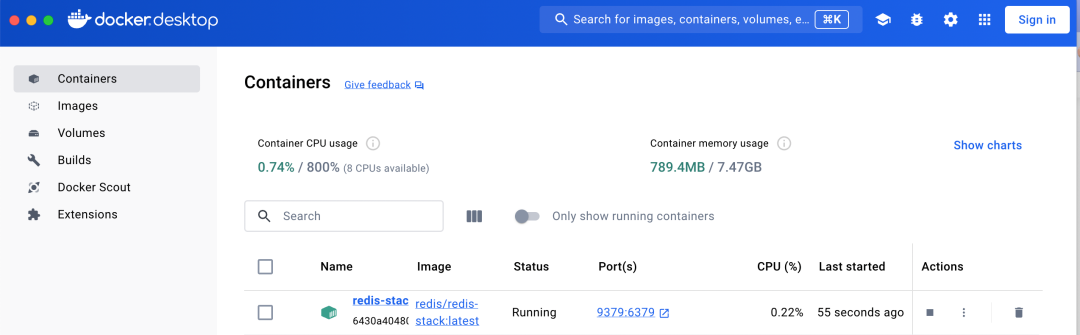
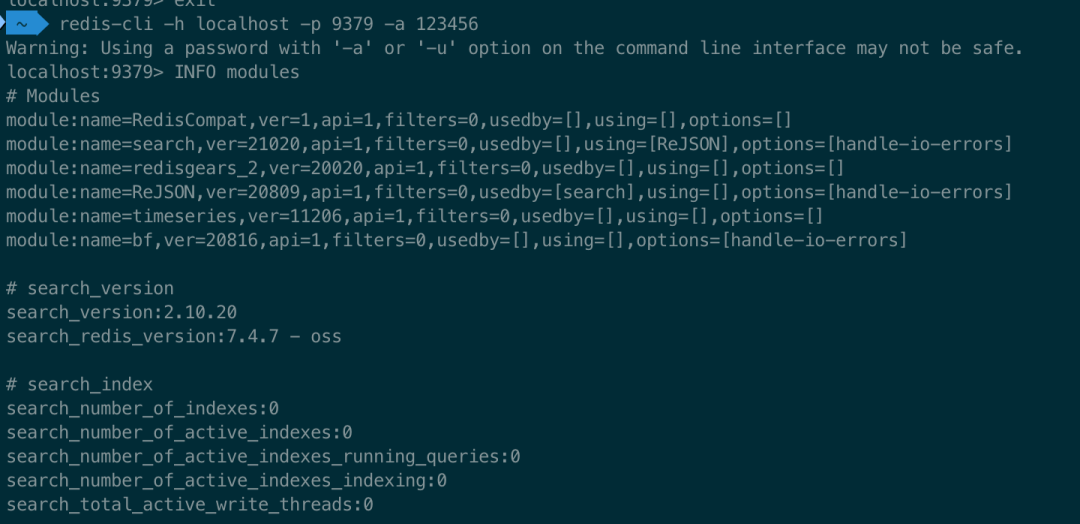
### 2. 验证安装
用 Redis CLI 连接,执行 `INFO modules`,能看到 `RedisSearch` 和 `RedisJSON` 模块,说明安装成功。
三、核心实战:Spring Boot 搭建 RAG 本地知识库
-------------------------------
全程基于 Spring Boot 3.x,代码可直接复制运行。
### 1. 引入核心依赖
```plaintext
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-advisors-vector-store</artifactId></dependency><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-transformers</artifactId></dependency><!--解析文档--><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-tika-document-reader</artifactId></dependency>
2. 配置文件(application.yml)
spring: data: redis: host:127.0.0.1 port:8379 password:123456# Spring AI 配置ai: openai: base-url:https://api.deepseek.com api-key:sk-xxxxxxxxxxxxxxx# 替换成你的 DeepSeek Key chat: options: model:deepseek-chat # 向量配置 vectorstore: redis: initialize-schema:true # 是否初始化所需的模式 index-name:rag-knowledge # 用于存储向量的索引名称 prefix:'rag:doc:' # Redis 键的前缀
3. 核心代码:PDF 解析 + 文本切分 + 向量存储
3.1 PDF 解析工具类
import org.springframework.ai.document.Document;import org.springframework.ai.reader.tika.TikaDocumentReader;import org.springframework.core.io.InputStreamResource;import org.springframework.stereotype.Component;import org.springframework.web.multipart.MultipartFile;import java.io.IOException;import java.util.List;@Componentpublicclass DocumentParserUtil { /** * 基于 Spring AI Tika 解析文档(支持PDF/Word/TXT等多格式) */ public List<Document> parseDocument(MultipartFile file) throws IOException { // 将MultipartFile转为InputStreamResource,适配TikaDocumentReader InputStreamResource resource = new InputStreamResource(file.getInputStream()); // 创建Tika解析器,自动识别文档格式并解析 TikaDocumentReader reader = new TikaDocumentReader(resource); // 解析文档并返回Document列表(Tika会自动按文档结构拆分基础片段) return reader.read(); }}
3.2 自定义文本切分器(通过换行符切分)
@Componentpublic class CustomTextSplitter extends TextSplitter { @Override protected List<String> splitText(String text) { return List.of(split(text)); } public String[] split(String text) { return text.split("\\s*\\R\\s*\\R\\s*"); }}
3.3 文档上传 + 向量存储接口
import cn.pottercoding.config.CustomTextSplitter;import cn.pottercoding.utils.DocumentParserUtil;import lombok.RequiredArgsConstructor;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.redis.RedisVectorStore;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import org.springframework.web.multipart.MultipartFile;import java.util.List;@RestController@RequestMapping("/rag")@RequiredArgsConstructorpublicclass RagController { privatefinal DocumentParserUtil documentParserUtil; privatefinal CustomTextSplitter customTextSplitter; privatefinal RedisVectorStore redisVectorStore; /** * 上传文档(PDF/Word/TXT等)并存储到Redis向量库 */ @PostMapping("/upload-doc") public String uploadDoc(@RequestParam("file") MultipartFile file) { try { List<Document> rawDocs = documentParserUtil.parseDocument(file); if (rawDocs.isEmpty()) { return"文档解析失败,无有效内容"; } List<Document> chunks = customTextSplitter.split(rawDocs); // 向量存储 redisVectorStore.add(chunks); return file.getOriginalFilename() + " 解析完成,共生成 " + chunks.size() + " 个文本块,已存入向量库"; } catch (Exception e) { return"上传失败:" + e.getMessage(); } }}
4. 核心代码:基于知识库的问答接口
/** * 基于本地知识库问答 */ @GetMapping("/qa") public Flux<String> ragQa(@RequestParam String question) { List<Document> similarDocs = redisVectorStore.similaritySearch(question); String context = ""; if (CollectionUtil.isNotEmpty(similarDocs)) { // 拼接检索到的上下文内容 context = similarDocs.stream() .map(Document::getText) .collect(Collectors.joining("\n")); } // 构造提示词(关键:限定大模型仅基于本地知识回答) String prompt = """ 请严格基于以下上下文回答问题,不要使用上下文外的信息,语言简洁准确: 上下文:%s 问题:%s """.formatted(context, question); // 调用DeepSeek大模型生成答案 return chatClient.prompt(prompt).stream().content(); }}
5. 测试本地知识库
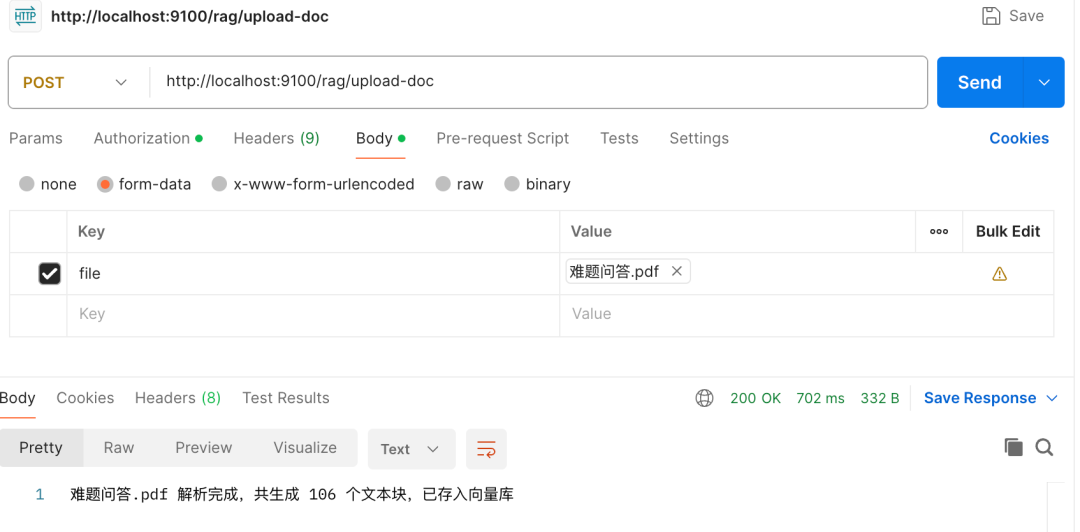
- 启动项目,上传 PDF 文件:```plaintext
POST http://localhost:8080/rag/upload-pdf参数:file(选一个本地PDF文件)
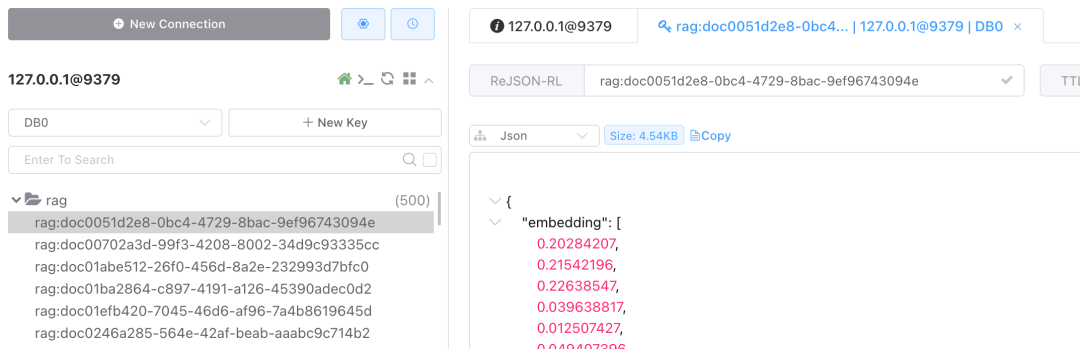
上传成功后,可以在redis管理工具中,看到我们存储的数据结构:
- 提问测试:```plaintext
GET http://localhost:8080/rag/qa?question=PDF里讲了什么内容?
四、进阶:集成 SearXNG 实现联网搜索
本地知识库解决了“私有知识”问题,但还有“实时信息”需求(比如查最新API、最新政策),我们集成 SearXNG 实现联网搜索。
1. 先搞懂:SearXNG 是什么?有什么用?
(1)SearXNG 是什么?
SearXNG 是一款 开源、无广告、去中心化的元搜索引擎(不是传统搜索引擎,而是 “搜索引擎的聚合器”)。
简单说:它不自己爬取数据,而是同时调用 Google、Bing、百度、必应等数十个搜索引擎的接口,把结果去重、排序后返回给你。
(2)为什么用 SearXNG 而不是直接调百度 / Google API?
- 无 API_KEY 限制:百度 / Google 等商用搜索 API 需要申请密钥、按调用量收费,SearXNG 无需密钥;
- 去中心化:避免依赖单一搜索引擎,某一个源挂了不影响整体;
- 隐私保护:不会把你的搜索关键词传给第三方,适合企业内部使用;
- 格式统一:把不同搜索引擎的返回结果标准化为 JSON,开发更简单;
- 可私有化部署:Docker 一键部署,数据不泄露,符合企业合规要求。
(3)在 RAG 场景中,SearXNG 的核心作用?
解决本地知识库 “知识过期” 和 “无实时信息” 的问题: 本地知识库:解决私有 / 历史知识问答(比如公司内部文档、产品手册);
SearXNG 联网搜索:解决实时 / 最新知识问答(比如 2026 年 Spring AI 新版本、最新政策)。
2. Docker 安装 SearXNG
先拉取searXNG镜像:docker pull searxng/searxng:latest
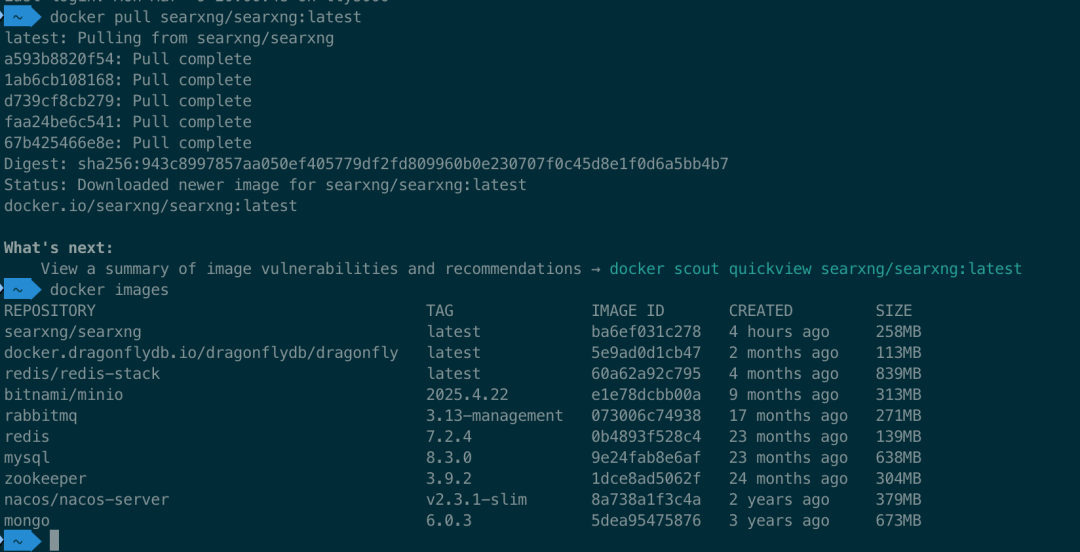
镜像拉取成功后,然后启动容器,启动docker命令如下:
docker run -p 8081:8080 \ --name searxng \ -d --restart=always \ -v "/Users/luckysun/docker/SearXNG:/etc/searxng" \ -e "BASE_URL=http://localhost:$PORT/" \ -e "INSTANCE_NAME=potter-instance" \ searxng/searxng
```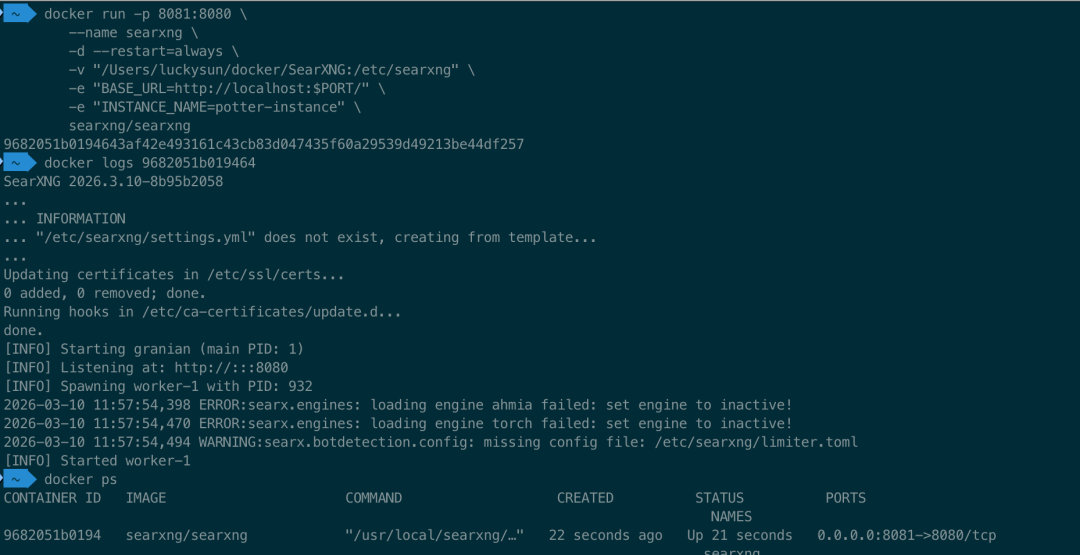
访问 `http://localhost:8081`,能看到 SearXNG 界面,说明安装成功。

### 3. OkHttp 实现联网搜索工具类
在`pom.xml`文件中引入`okhttp`工具包
```plaintext
<!-- OkHttp 联网搜索 --> <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.12.0</version> </dependency>
编写联网搜索工具类:
import okhttp3.OkHttpClient;import okhttp3.Request;import okhttp3.Response;import org.json.JSONArray;import org.json.JSONObject;import org.springframework.stereotype.Component;import java.io.IOException;import java.util.ArrayList;import java.util.List;import java.util.concurrent.TimeUnit;@Componentpublicclass SearchUtil { privatefinal OkHttpClient okHttpClient = new OkHttpClient.Builder() .connectTimeout(10, TimeUnit.SECONDS) .readTimeout(10, TimeUnit.SECONDS) .build(); /** * 联网搜索(限制返回Top5结果) */ public List<String> search(String query) { List<String> results = new ArrayList<>(); // SearXNG API地址 String url = "http://localhost:8081/search?q=" + query + "&format=json&count=5"; Request request = new Request.Builder() .url(url) .header("User-Agent", "Mozilla/5.0") .build(); try (Response response = okHttpClient.newCall(request).execute()) { if (response.isSuccessful() && response.body() != null) { String json = response.body().string(); JSONObject jsonObject = new JSONObject(json); JSONArray resultsArray = jsonObject.getJSONArray("results"); // 解析前5条结果 for (int i = 0; i < Math.min(resultsArray.length(), 5); i++) { JSONObject result = resultsArray.getJSONObject(i); String title = result.getString("title"); String content = result.getString("content"); results.add("标题:" + title + "\n内容:" + content); } } } catch (IOException e) { e.printStackTrace(); } return results; }}
4. 集成联网搜索的问答接口
import org.springframework.ai.chat.ChatClient;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.List;import java.util.stream.Collectors;@RestController@RequestMapping("/rag")@RequiredArgsConstructorpublicclass RagSearchController { privatefinal SearchUtil searchUtil; privatefinal ChatClient chatClient; /** * 基于联网搜索的智能问答 */ @GetMapping("/qa-search") public String ragSearchQa(@RequestParam String question) { // 1. 联网搜索(取Top5结果) List<String> searchResults = searchUtil.search(question); if (searchResults.isEmpty()) { return"未检索到相关信息"; } // 2. 拼接搜索结果 String searchContext = searchResults.stream() .collect(Collectors.joining("\n\n")); // 3. 构造提示词 String prompt = """ 请基于以下实时搜索结果回答问题,语言简洁、准确: 搜索结果:%s 问题:%s """.formatted(searchContext, question); // 4. 调用大模型 return chatClient.prompt(new Prompt(prompt)).call().content(); }}
5. 测试联网搜索
GET http://localhost:8080/rag/qa-search?question=2026年Spring
AI最新版本是什么?

此时返回的答案会基于实时联网结果,解决了大模型“知识过期”问题!
写在最后
LLM Agent 的诞生,为我们提供了一个极具想象空间的技术路线,它将传统模型的强大语言理解能力,与外部工具的实际动手能力相结合,创造出无限可能的应用空间。希望这篇文章能够启发你进一步探索和创新,用有限的代码,创造出更加强大、高效且安全的智能体,推动人工智能真正落地到更多场景,惠及更多人群。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)