计算机毕业设计源码:Spark淘宝商品数据可视化与销量预测系统 Hadoop Hive Django 可视化 线性回归 电商 商品 预测 大数据 大模型 agent 数据挖掘(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
项目介绍
技术栈:大数据技术、Spark、Hadoop、Hive、Python语言、Django后端框架、Vue前端框架、selenium爬虫技术、淘宝数据、Echarts可视化、DataV、机器学习线性回归预测模型、销量预测
功能模块:
· 商品销售数据分析大屏
· 机器学习线性回归预测模型销量预测
· spark大数据分析
本项目基于大数据技术与机器学习算法,设计并实现了一个商品销售分析预测系统。系统前端采用Vue框架进行数据展示与交互,后端使用Django框架处理业务逻辑,数据存储选用Hive数据库以支持海量数据的高效存储与查询。在数据采集层面,利用Selenium爬虫技术从淘宝获取实时商品数据;在数据处理层面,借助Spark与Hadoop进行分布式数据分析与计算;在预测功能层面,引入机器学习线性回归模型对未来销量进行科学预测;在可视化层面,通过Echarts与DataV实现多维度数据的直观展示。系统整体实现了从数据采集、清洗、存储、分析到预测与可视化的完整流程,能够为电商领域提供智能化的数据驱动决策支持,帮助运营人员把握市场动态并优化管理策略。
2、项目界面
(1)商品销售数据分析大屏
这是商品销售数据可视化平台的首页大屏,顶部显示时间与销量预测,页面通过数字仪表盘、地图、饼图、折线图、柱状图、条形图、排行榜、词云图等多种图表,实现总商品数等基础数据概览、商品省市分布、各类型销量占比、店铺/商品销量统计、优秀店铺TOP10、销量/销售额占比及商品词云等多维度数据可视化分析功能。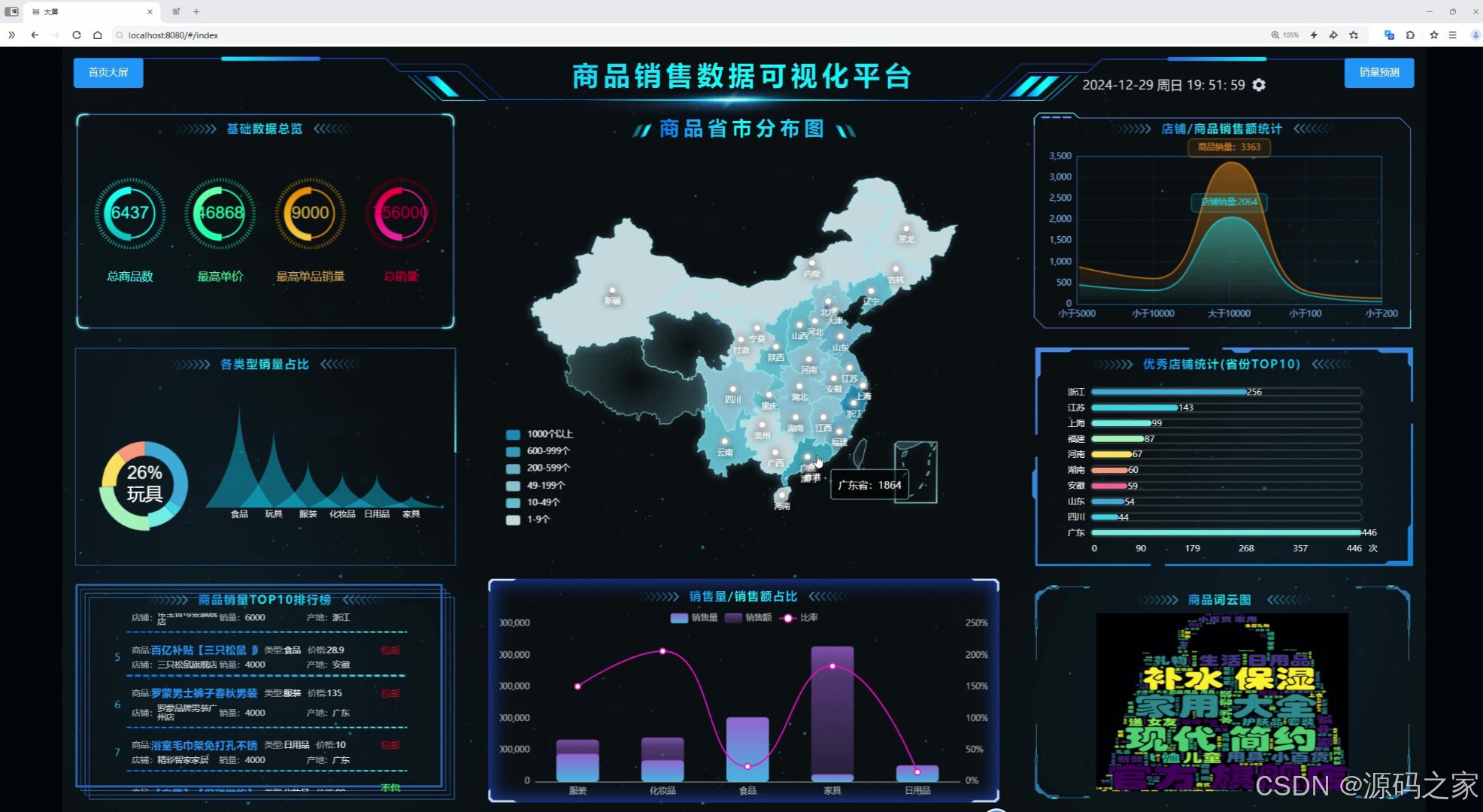
(2)机器学习线性回归预测模型销量预测
这是商品销售数据可视化平台的销量预测页面,顶部设有首页大屏入口与时间显示,页面提供商品种类、是否包邮、产地、价格等多维度条件筛选区域,搭配查看功能按钮,可根据用户选定的筛选条件生成并展示对应的销量预测结果。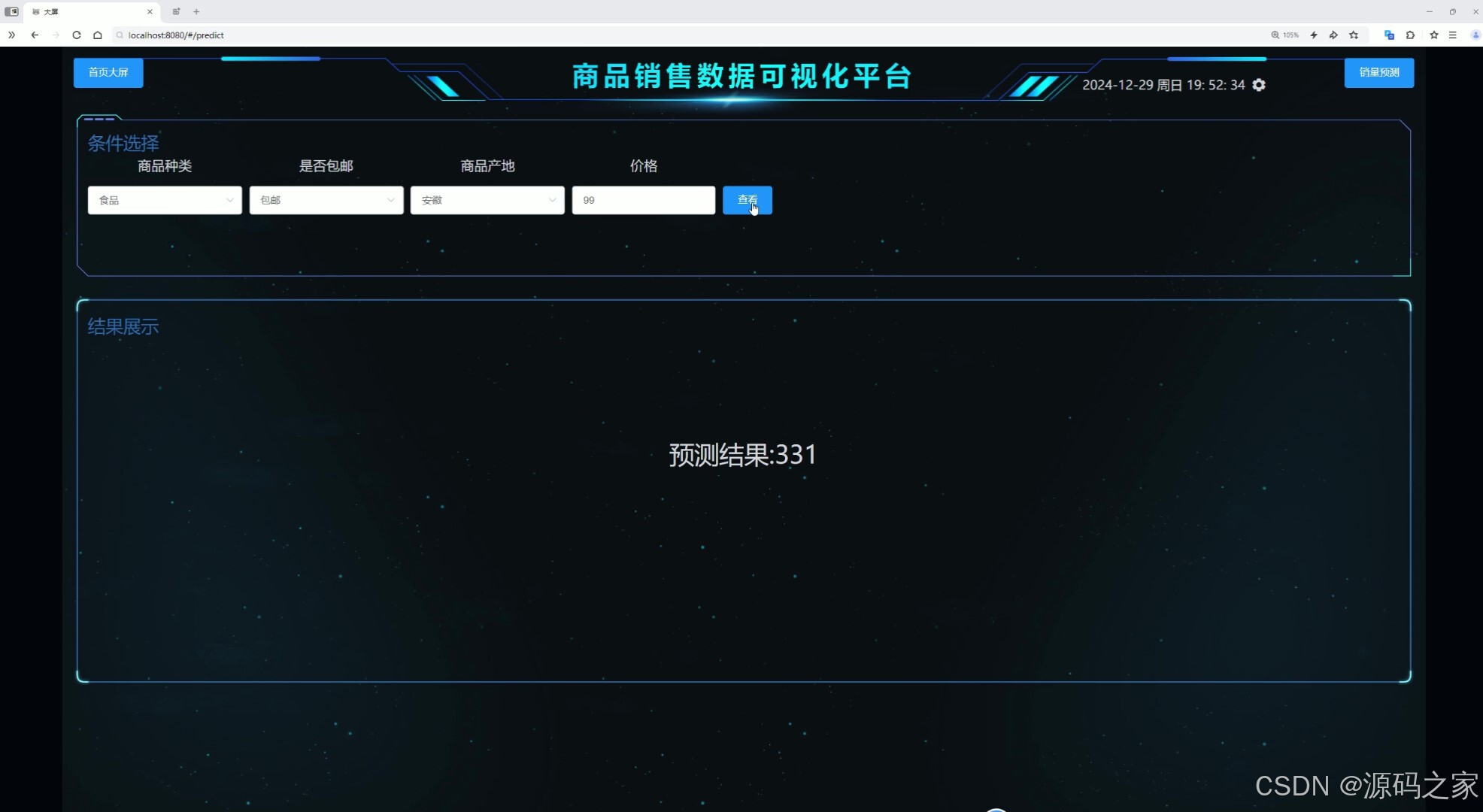
(3)spark大数据分析
这是大数据分析代码编辑与运行界面,左侧为项目文件导航栏,中间是代码编辑区,可编写Spark相关数据处理代码,实现读取商品数据、按地址分组统计、格式转换及数据写入数据库等操作,下方为运行日志与数据预览区,用于查看代码运行状态与数据内容。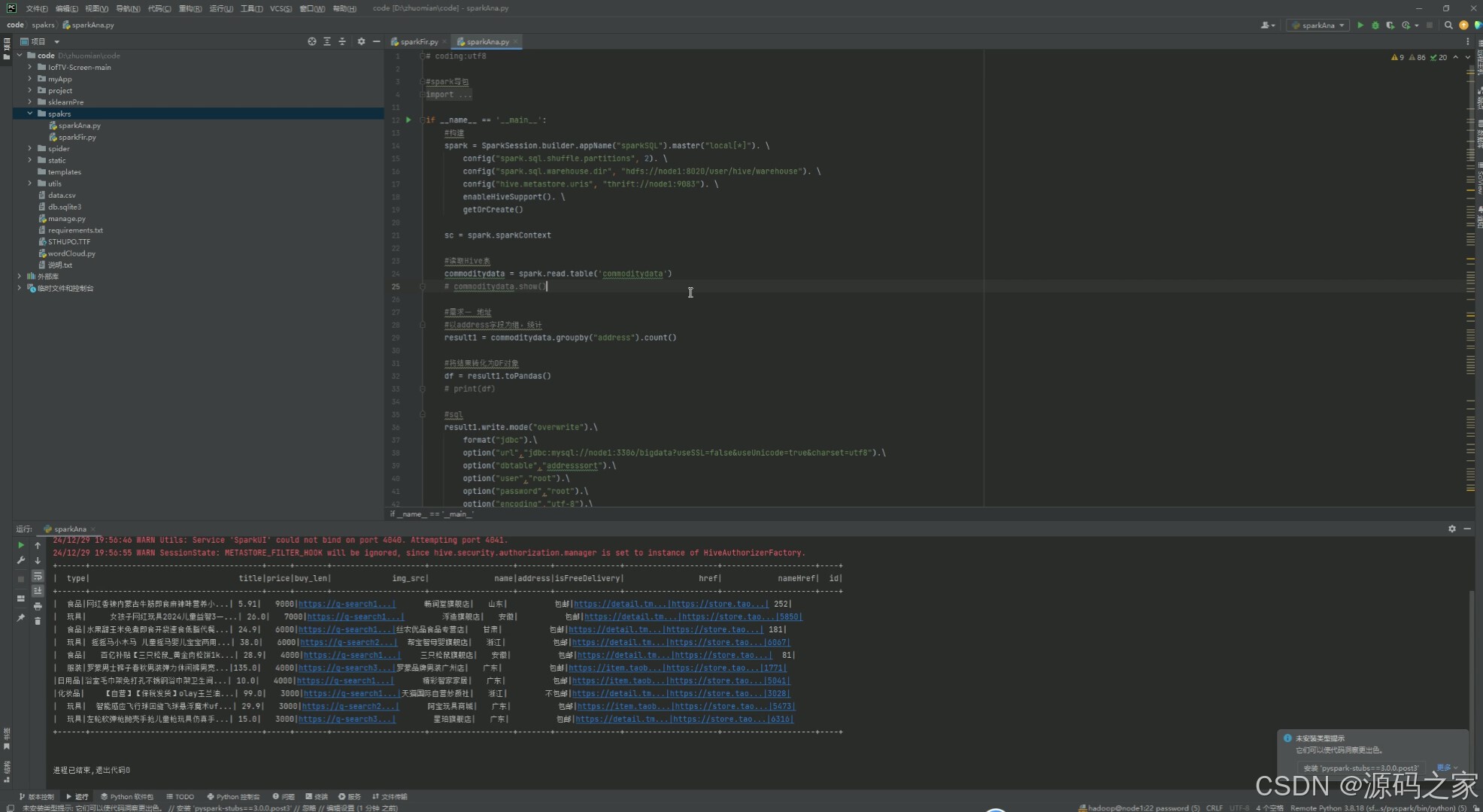
3、项目说明
一、技术栈简要说明
本系统采用前后端分离架构进行开发。后端基于Python语言的Django框架构建业务逻辑层,负责处理数据请求与业务响应。在大数据存储层面,选用Hive数据库作为数据仓库,支持海量商品数据的高效存储与查询分析。数据处理与计算环节引入Spark和Hadoop分布式框架,实现对大规模数据的并行处理与统计分析。前端采用Vue框架进行页面构建与交互设计,配合Echarts和DataV可视化库实现数据的多维度图表展示。在数据采集层面,利用Selenium爬虫技术从淘宝平台获取实时商品数据。在预测功能层面,引入机器学习线性回归模型,基于历史销售数据对未来销量进行科学预测。
二、功能模块详细介绍
· 商品销售数据分析大屏
数据分析大屏是系统核心的数据可视化展示模块。页面顶部设有时间显示与销量预测入口,主体区域采用网格化布局,嵌入了数字仪表盘、地图、饼图、折线图、柱状图、条形图、排行榜、词云图等多种可视化组件。这些图表从多个维度对商品销售数据进行解析,具体包括总商品数等基础指标概览、商品在全国各省市的分布情况、各类型商品销量占比、店铺与商品销量统计、优秀店铺TOP10排名、销量与销售额占比对比以及商品标题关键词云分析等功能。通过这一模块,管理者可以直观掌握整体销售状况与市场分布特征,为运营决策提供数据支撑。
· 机器学习线性回归预测模型销量预测
销量预测模块基于机器学习线性回归算法构建,旨在为用户提供科学的销量预测服务。页面顶部设有返回首页大屏的入口与当前时间显示,主体区域提供了多维度的条件筛选面板,包括商品种类选择、是否包邮筛选、产地选择、价格区间设定等筛选条件。用户根据实际需求设置筛选参数后,点击查看功能按钮,系统后台会调用训练好的线性回归模型,结合用户选定的条件特征进行计算,并生成对应的销量预测结果进行展示。该模块支持用户根据不同商品属性组合预估未来销售表现,为库存管理、采购计划和营销策略制定提供数据参考。
· spark大数据分析
Spark大数据分析模块是系统底层数据处理能力的集中体现。该模块提供了一个集成的代码编辑与运行环境,界面左侧为项目文件导航树,方便用户浏览和管理代码文件;中间区域为代码编辑器,支持用户编写和修改Spark相关数据处理代码,包括Scala或Python语言的Spark程序;下方区域分为运行日志面板和数据预览面板,实时显示代码执行状态、打印信息以及处理后的数据内容。用户可以通过编写Spark程序实现读取Hive中的商品数据、按地址字段进行分组统计、进行数据格式转换以及将分析结果写回数据库等操作。这一模块为数据分析师和技术人员提供了灵活的数据处理能力,支撑上层业务模块的数据需求,同时也可用于探索性数据分析和算法调试。
三、项目总结
本项目构建了一个基于大数据技术与机器学习算法的电商销售分析预测系统。系统前端采用Vue框架实现数据展示与用户交互,后端使用Django框架处理业务逻辑,数据存储选用Hive数据库支撑海量数据管理,数据处理依托Spark和Hadoop分布式框架实现高效并行计算。在数据采集层面,通过Selenium爬虫技术从淘宝获取实时商品数据;在预测功能层面,引入线性回归模型实现科学销量预测;在可视化层面,借助Echarts和DataV完成多维度数据的直观图表展示。系统在功能设计上形成了从数据采集、清洗、存储、分析到预测与可视化的完整业务闭环,能够为电商企业提供全面的数据洞察与决策支持,帮助运营人员准确把握市场动态、科学优化库存管理、精准制定营销策略,具有良好的应用价值和推广前景。
4、核心代码
# coding:utf8
#spark导包
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.functions import count
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType,StructField,IntegerType,StringType,FloatType
from pyspark.sql.functions import col,sum,when
from pyspark.sql.functions import desc,asc
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse"). \
config("hive.metastore.uris", "thrift://node1:9083"). \
enableHiveSupport(). \
getOrCreate()
sc = spark.sparkContext
#读取Hive表
commoditydata = spark.read.table('commoditydata')
# commoditydata.show()
#需求一 地址
#以address字段为组,统计
result1 = commoditydata.groupby("address").count()
#将结果转化为DF对象
df = result1.toPandas()
# print(df)
#sql
result1.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","addresssort").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#写入HIVE
result1.write.mode("overwrite").saveAsTable("addresssort","parquet")
# spark.sql("select * from addresssort").show()
#需求二:各类型销量占比
#以type为组
result2 = commoditydata.groupBy("type").sum("buy_len").withColumnRenamed("sum(buy_len)","total_bue_len")
#
df = result2.toPandas()
# print(df)
#sql
result2.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typesort").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#HIVE
result2.write.mode("overwrite").saveAsTable("typesort","parquet")
# spark.sql("select * from typesort").show()
#需求三:统计每个省市日销100+的店铺 TOP10
#province
#按“address",”name“为组
result3 = commoditydata.groupBy("address","name").\
agg({"buy_len":"sum"}).withColumnRenamed("sum(buy_len)","total_buy_len").\
filter("total_buy_len > 100").\
drop_duplicates(subset=["name"]).\
groupby("address").count()
result3 = result3.orderBy(col("count").desc()).limit(10)
df = result3.toPandas()
# print(df)
#sql
result3.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","provincesort").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#HIVE
result3.write.mode("overwrite").saveAsTable("provincesort","parquet")
# spark.sql("select * from provincesort").show()
#需求四:统计每种类型buy_len的总和以及buy_len与price的总和
result4 = commoditydata.groupBy("type").agg(
F.sum("buy_len").alias("total_buy_len"),
F.sum(F.col("buy_len") * F.col("price")).alias("sum_buy_len_price")
)
result4 = result4.withColumn("ration",F.col("sum_buy_len_price")/F.col("total_buy_len"))
df = result4.toPandas()
# print(df)
#sql
result4.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","salerate").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#HIVE
result4.write.mode("overwrite").saveAsTable("salerate","parquet")
# spark.sql("select * from salerate").show()
#需求五:店铺/商品销售额统计
resultDouble = commoditydata.withColumn("volume",when(col("buy_len") * col("price") < 100,"小于100")
.when(col("buy_len") * col("price") < 200,"小于200")
.when(col("buy_len") * col("price") < 500,"小于500")
.when(col("buy_len") * col("price") < 1000,"小于1000")
.when(col("buy_len") * col("price") < 5000,"小于5000")
.when(col("buy_len") * col("price") < 10000,"小于10000")
.otherwise("大于10000"))
result5 = resultDouble.drop_duplicates(["title"])
result5 = result5.groupby("volume").agg(count("title").alias("title_count"))
result6 = resultDouble.drop_duplicates(["name"])
result6 = result6.groupby("volume").agg(count("name").alias("name_count"))
# result5.show()
# result6.show()
result_cobine = result5.join(result6,"volume")
# result_cobine.show()
#sql
result_cobine.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","storeproduct").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#HIVE
result_cobine.write.mode("overwrite").saveAsTable("storeproduct","parquet")
# spark.sql("select * from storeproduct").show()
#需求6:商品销量top10
#productTop
resultList = commoditydata.orderBy("buy_len",ascending=False).limit(10)
# resultList.show()
#sql
resultList.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","productTop10").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
#HIVE
resultList.write.mode("overwrite").saveAsTable("productTop10","parquet")
spark.sql("select * from productTop10").show()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)