卷积神经网络算法深度解析(非常详细),深度学习从入门到精通,收藏这一篇就够了!
今天给大家介绍一个强大的算法模型,卷积神经网络
卷积神经网络(CNN)是一种专门用于处理具有网格状拓扑结构数据的深度学习模型,最常用于图像和视频数据的分析。
CNN 模仿了生物视觉系统的工作方式,能够自动提取数据中的局部特征,从而在图像分类、目标检测、语义分割等任务中表现出色。
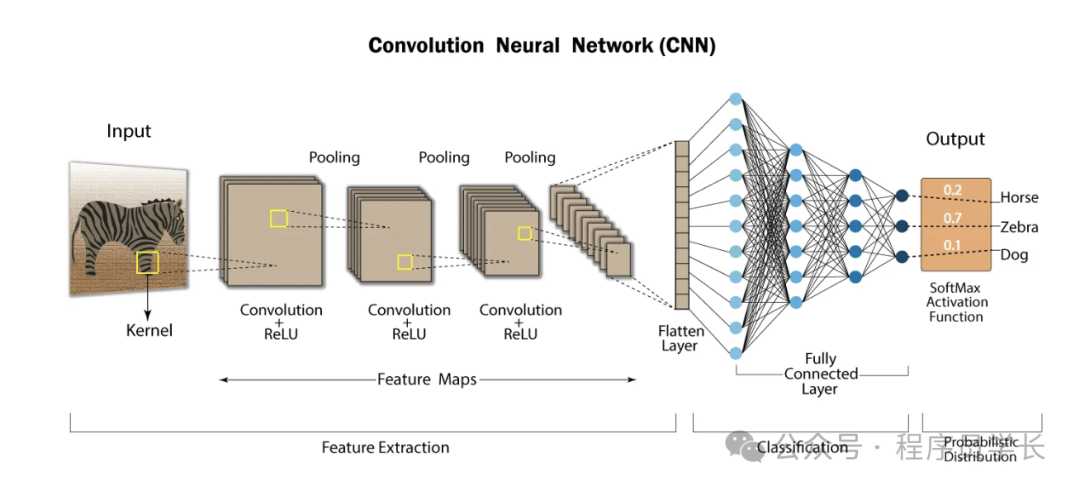
卷积神经网络的基本构成
CNN 通常由多个层组成,每层负责不同的任务。
1.卷积层
卷积层是 CNN 的核心层,它利用卷积操作对输入数据进行特征提取。
卷积操作的本质是将一个小尺寸的卷积核(也称为过滤器,通常是 或 )在输入数据上滑动,并通过点积运算生成特征映射(Feature Map)。
卷积层的主要作用是捕捉图像中的局部模式,比如边缘、角落等。
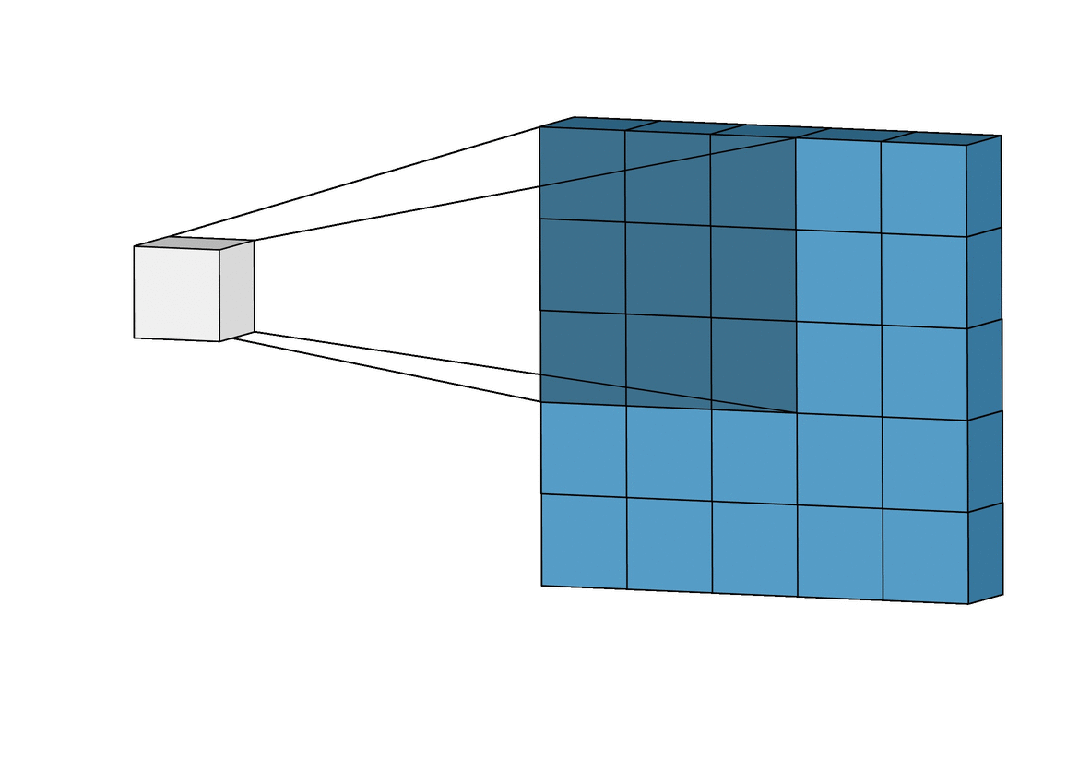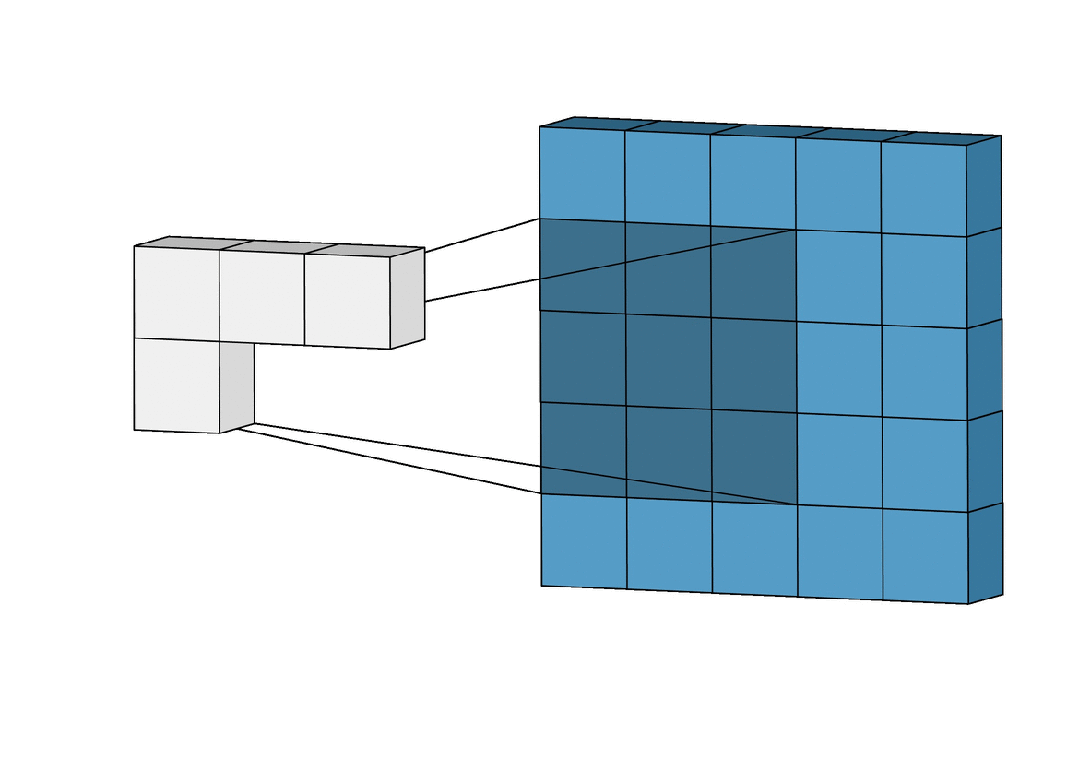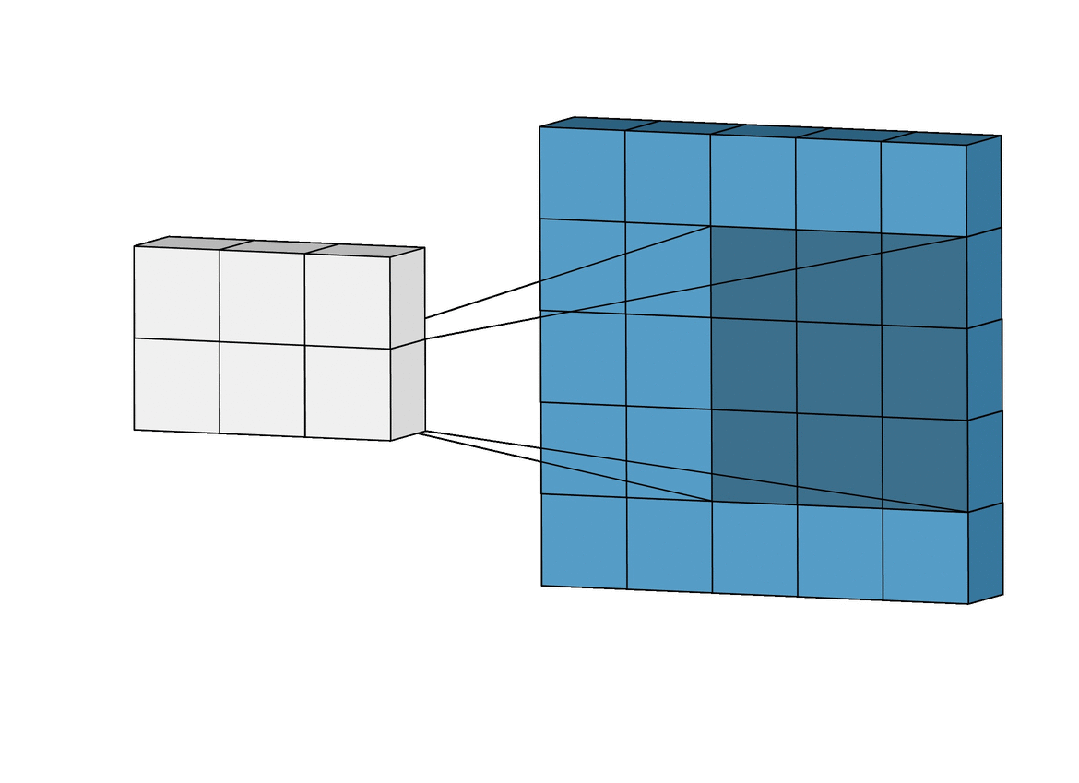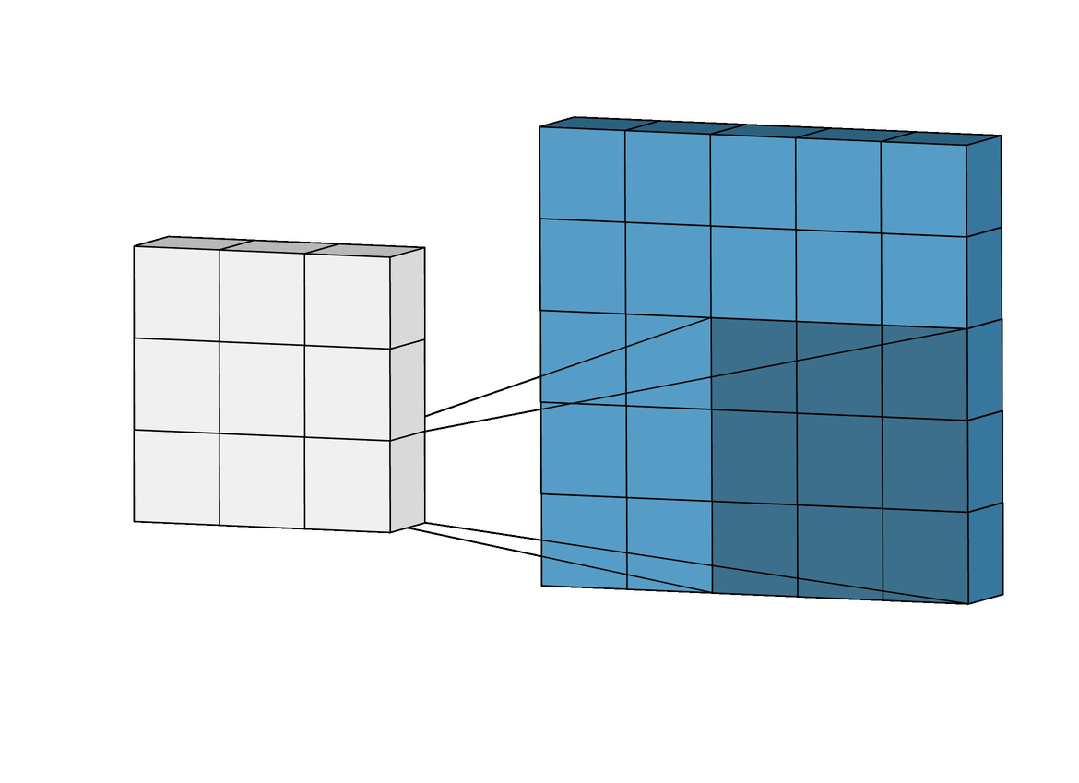
卷积层中的几个重要参数
-
卷积核
卷积核是一个小的矩阵,比如 或 。
-
步幅(Stride)
步幅是卷积核在输入图像上滑动的步长。它决定了卷积核在每次滑动时跳过多少个像素。
-
填充(Padding)
填充是指在输入图像的边界周围填充额外的像素值,通常填充值为0。
这可以帮助控制输出特征图的尺寸。
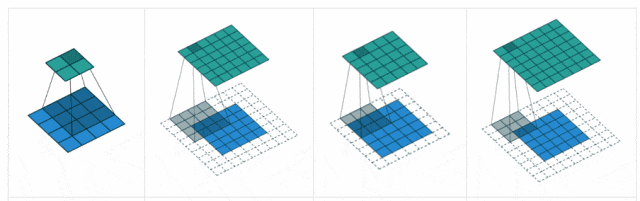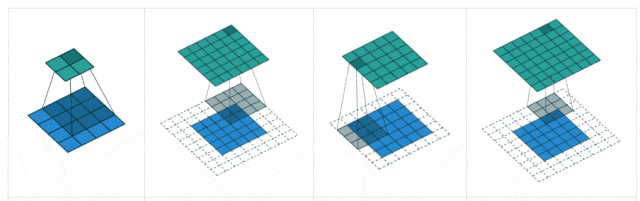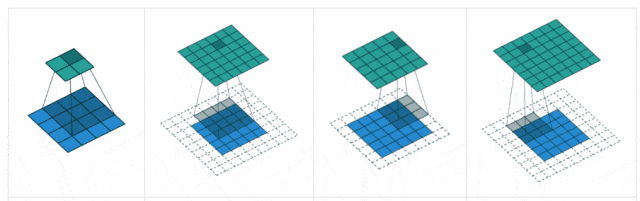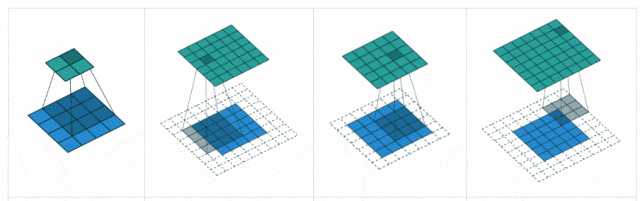
2.激活层
激活层通常位于卷积层之后,用于引入非线性因素,使得网络可以学习更复杂的特征。
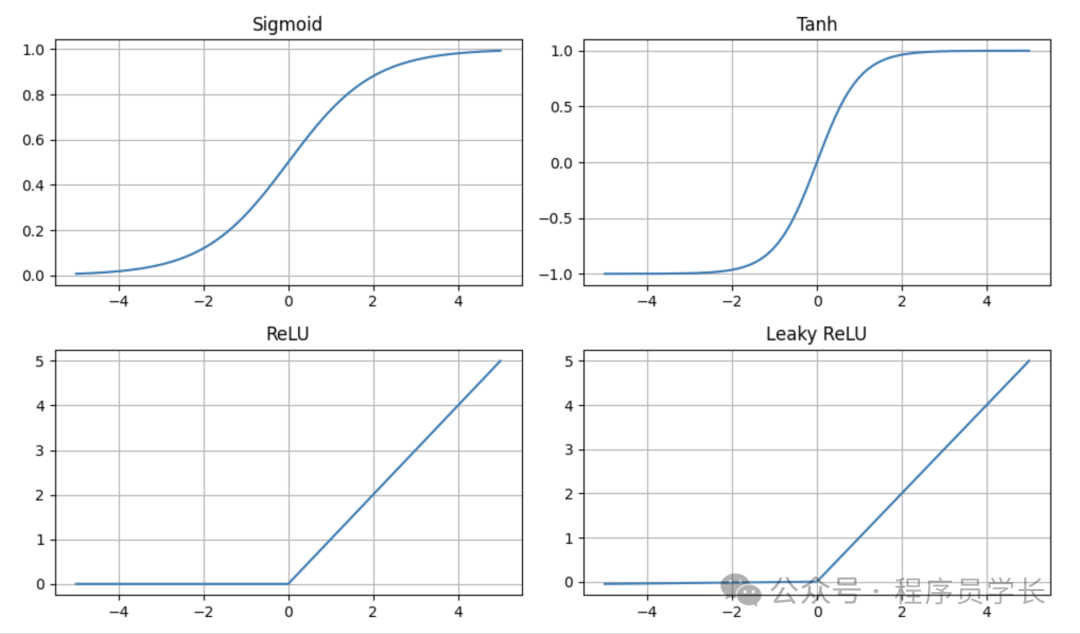
最常见的激活函数有
-
Sigmoid 函数
Sigmoid 函数的定义为
它将输入值映射到 0 和 1 之间,适合处理二分类问题。
-
Tanh 函数
Tanh 函数的定义为
它将输入值映射到 (-1, 1) 之间,相比 Sigmoid,Tanh 更适合对称数据处理。
-
ReLU 函数
ReLU 是目前最常用的激活函数。
它的定义为:
即当输入为正数时输出输入值本身,输入为负数时输出0。
ReLU 的非线性性质帮助网络学习到复杂的特征,同时其计算开销较小。
-
Leaky ReLU
Leaky ReLU 是 ReLU 的变种,避免了“死亡神经元”问题。
其定义为:
其中 是一个小的常数(如 0.01),保证当输入为负值时输出不会完全为零。
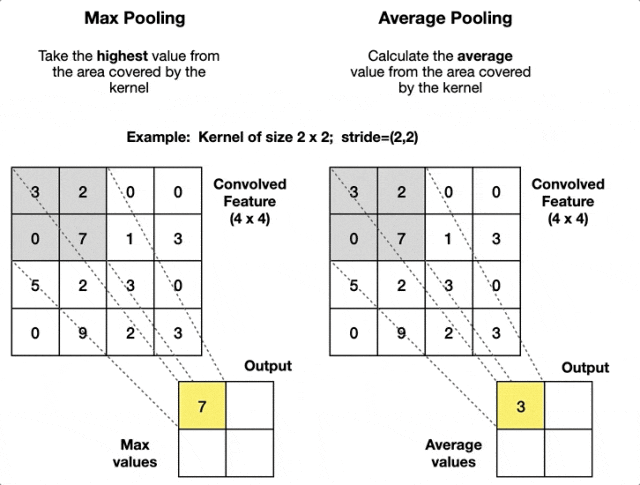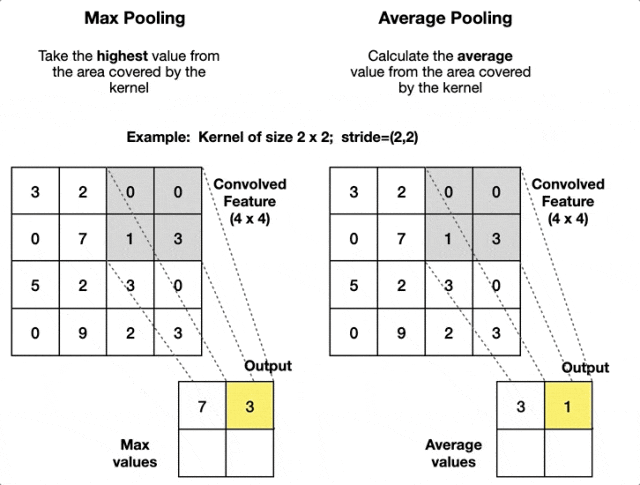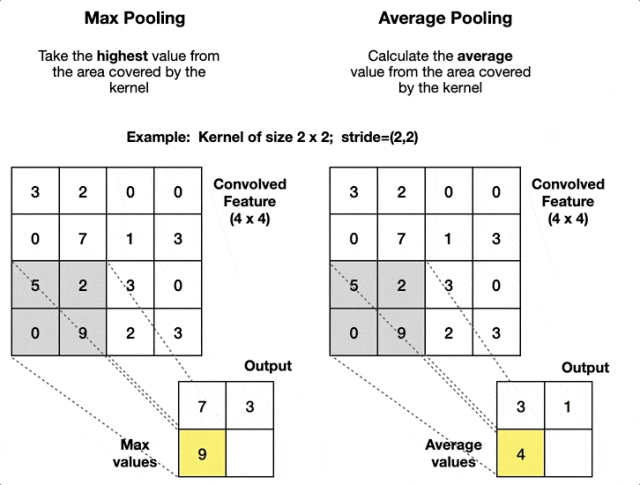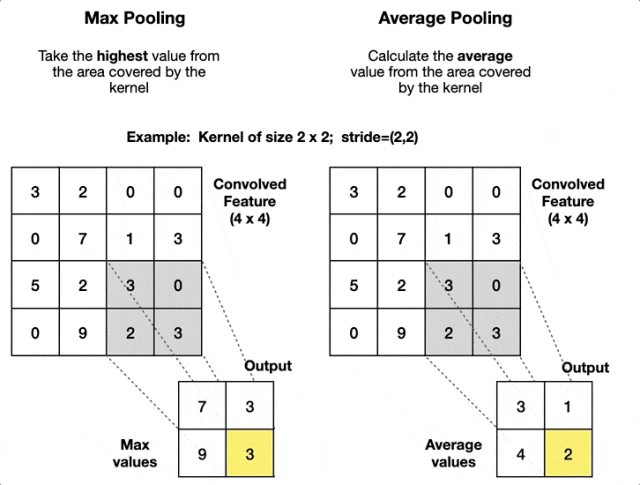
3. 池化层
池化层用于降低特征图的空间维度(高和宽),以减少参数数量和计算量并防止过拟合,同时保留一些重要特征。
最常用的池化操作是最大池化和平均池化,它们分别取区域内的最大值和平均值作为该区域的代表。
4. 全连接层
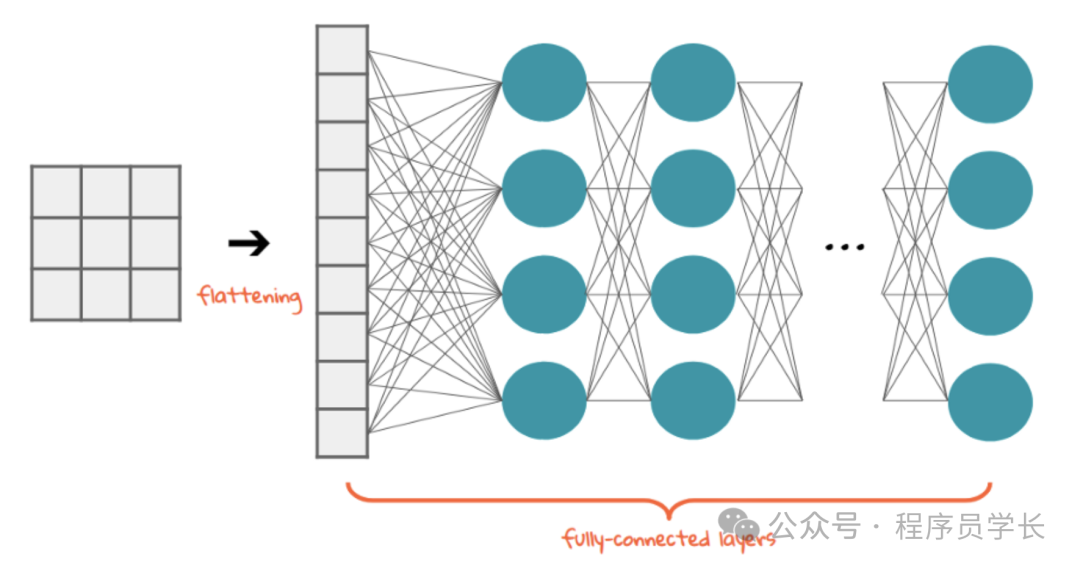
经过几个卷积层和池化层后,特征图被展平为一个向量。该向量被传递到全连接层,其中每个神经元都连接到前一层的所有神经元。
全连接层的主要任务是将通过卷积和池化层提取的特征进行整合和学习,并生成最终的分类或回归输出。
CNN 的特点
-
参数共享
卷积核在输入的不同位置滑动,多个像素点共享同一个卷积核参数。
这极大减少了网络中的参数数量,避免了传统全连接网络在处理大尺寸输入时参数爆炸的问题。
-
稀疏连接
每个卷积核只与输入数据的一部分进行计算,而不是与所有输入进行连接。
这使得 CNN 更加高效,也提高了网络的泛化能力。
示例代码
下面是一个使用卷积神经网络进行手写数字识别的示例代码。
# 导入必要的库
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((train_images.shape[0], 28, 28, 1))
test_images = test_images.reshape((test_images.shape[0], 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 3. 构建 CNN 模型
model = models.Sequential()
# 第一层卷积层(32 个 3x3 的过滤器)
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
# 最大池化层
model.add(layers.MaxPooling2D((2, 2)))
# 第二层卷积层(64 个 3x3 的过滤器)
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 最大池化层
model.add(layers.MaxPooling2D((2, 2)))
# 第三层卷积层(64 个 3x3 的过滤器)
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 展平层,用于将三维特征图转换为一维特征向量
model.add(layers.Flatten())
# 全连接层,带有 64 个神经元
model.add(layers.Dense(64, activation='relu'))
# 输出层,带有 10 个神经元(对应 10 个数字类)
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_split=0.2)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')
# 7. 可视化模型预测结果
num_test_samples = 10
random_indices = np.random.choice(test_images.shape[0], num_test_samples, replace=False)
sample_images = test_images[random_indices]
sample_labels = test_labels[random_indices]
predictions = model.predict(sample_images)
plt.figure(figsize=(10, 5))
for i in range(num_test_samples):
plt.subplot(2, 5, i + 1)
plt.imshow(sample_images[i].reshape(28, 28), cmap=plt.cm.binary)
predicted_label = np.argmax(predictions[i])
true_label = np.argmax(sample_labels[i])
plt.title(f'Pred: {predicted_label}\nTrue: {true_label}')
plt.axis('off')
plt.show()

写在最后
LLM Agent 的诞生,为我们提供了一个极具想象空间的技术路线,它将传统模型的强大语言理解能力,与外部工具的实际动手能力相结合,创造出无限可能的应用空间。希望这篇文章能够启发你进一步探索和创新,用有限的代码,创造出更加强大、高效且安全的智能体,推动人工智能真正落地到更多场景,惠及更多人群。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)