PPT多模态RAG实现:图文并茂问答,打造企业级知识库新高度!
RAG应用的一大复杂性体现在其多样的原始知识结构与表示。特别在企业场景下,混合多种媒体形式且具有复杂布局的文档随处可见,比如一份PPT:

其中可能充满大量的文本、标注、图像与各种统计图表。那么如何对这样的文档构建有效的RAG管道?本文将为您介绍我们的实现过程。实验Notebook:
https://github.com/pingcy/multimodal_ppt_rag
先看效果
这里使用《中文大模型基准测评2025年3月报告》这份PPT来做测试,因为它的内容够丰富,且含有大量图表,非常适合用来回答问题。我们期望并达到的效果是,**能够图文****结合的回答PPT内容相关的问题。**比如:
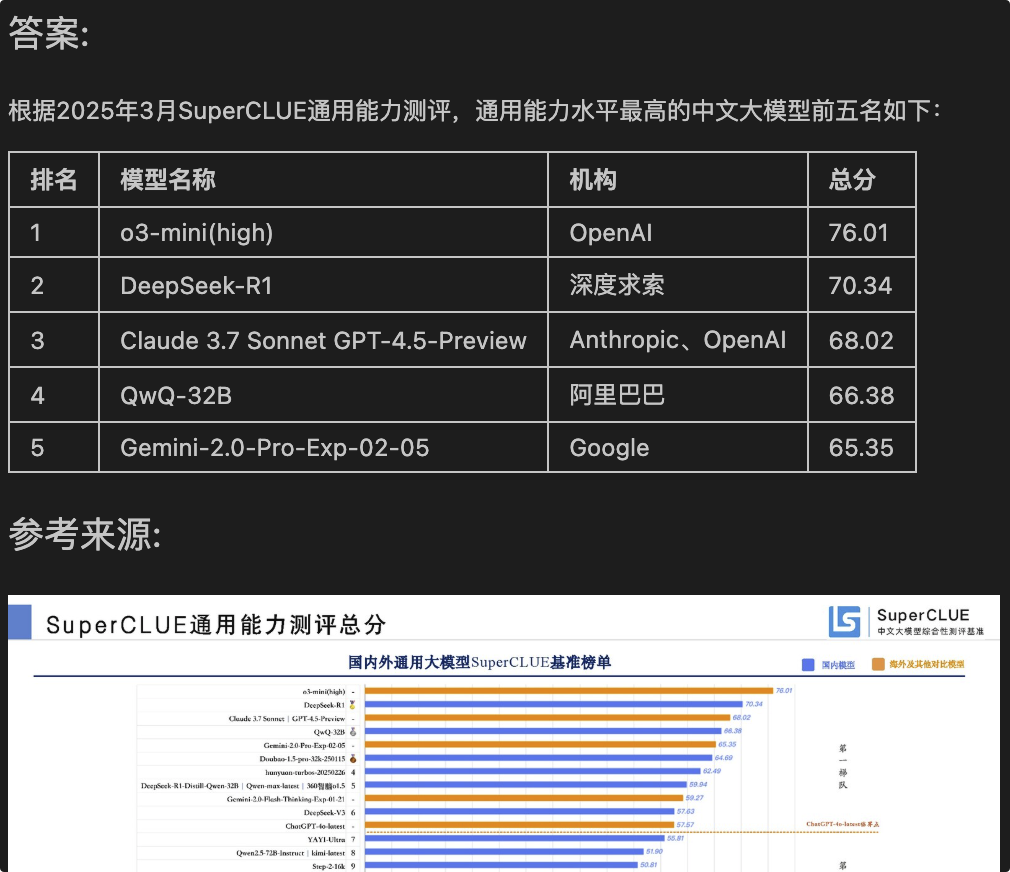
3月份中文大模型评测,通用能力水平最高的模型前五名是谁?
最后输出的答案如下:
通过对PPT相关的更多问题进行评估,效果基本达到了预期。
总体方案与工具
PPT文档(或者转成的PDF)的复杂之处在于:
- 没有固定的格式与布局
- 典型的图、文、表混排
- 相对于文本,更倾向用图表来表示信息
不过PPT文档也有一个优势:有天然的知识块分割,每一页即为一个Chunk。
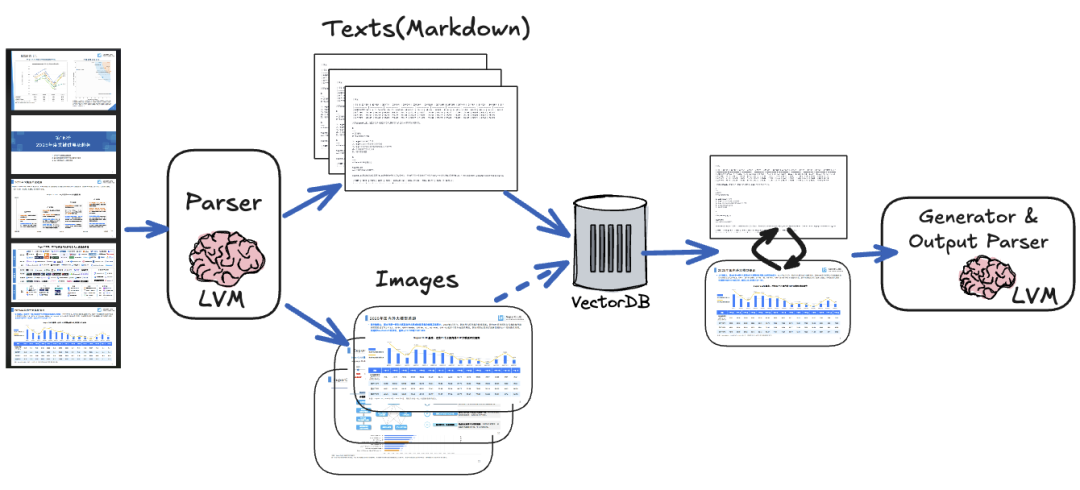
所以,简单的借助开源解析工具、OCR等做文本提取,然后按普通RAG流程处理,会丢失大量的语义信息。因此我们的方案是借助多模态的视觉大模型(LVM)在索引与生成阶段双管齐下:
- 索引阶段:对每一页截图,并生成尽可能丰富的文本表示做嵌入
- 生成阶段:将检索到的文本与关联的截图一起输入大模型用于生成
需要的工具有:
- 文档解析:豆包vision模型或开启vision的LlamaParse
- 向量库:本地Chroma
- 嵌入模型:阿里云Embedding-V3
- 生成模型:豆包vision模型
- 框架:LlamaIndex或LangChain
这里的每一步你都可以选择替代方案。
文档解析与索引
有很多解析PDF(PPT转化成PDF)文档的开源工具,如Markitdown,Marker,PyMuPDF4LLM等。不过经过测试,面对PPT这种复杂文档,效果最好的是借助视觉大模型。比如我们用豆包的视觉模型对这一页进行生成(提示词参考源代码):
它可以很好的提取文字,并对必要内容做整理转化:

当然在一些不清晰,或者元素过多与混乱的局部区域,会有一些误差。这也是为什么在生成时我们希望同时输出原图片来参考的原因。


在测试时为了方便,我们采用了LlamaIndex提供的云端解析服务LlamaParse(打开Vision功能,原理也是借助视觉大模型)来完成这一步。其好处是会帮你保留每一次解析结果:
[
[并可以在后台查看详细解析输出:
[Llama-Parse是收费服务,但最多可以每个月有2万免费Credit,足够测试使用。]

采用视觉大模型的解析与索引的处理流程:
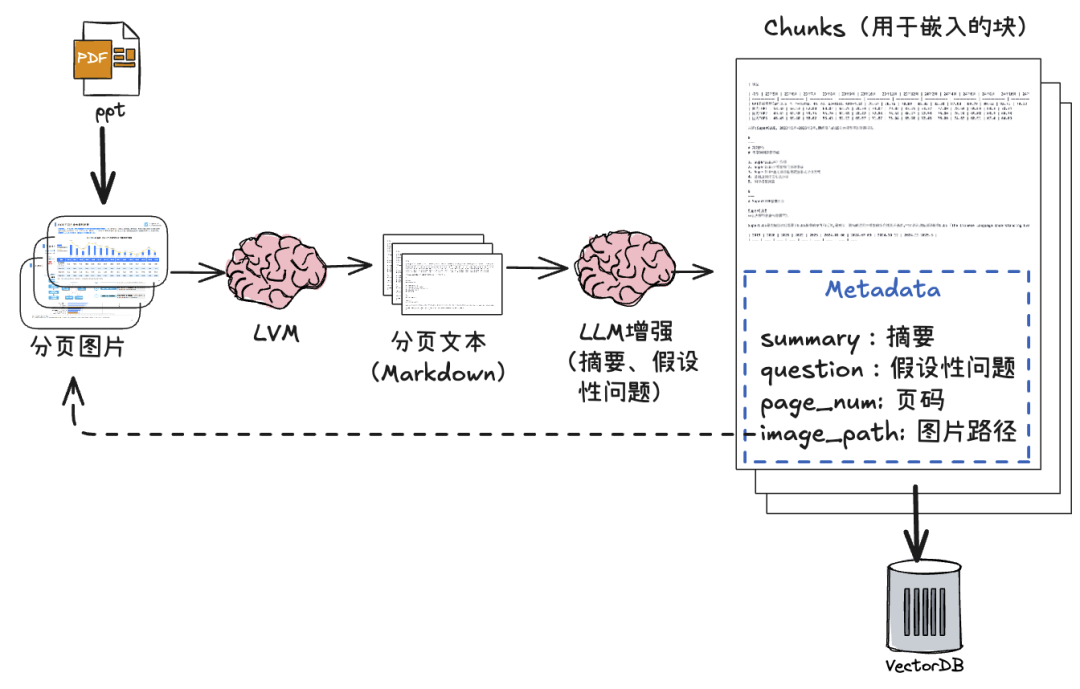
【流程说明】
- 原文档的每一页PPT转为图片,并借助多模态模型解析成每一页的Markdown文本(注意不是简单的文字提取)
- 【可选】借助LLM对生成的Markdown文本块做适当增强,我们做了两个动作:
- 生成该页的简单摘要
- 生成该页可以回答的5个假设性问题
- 将每一页的Markdown文本块作为一个Chunk,并根据页码与页面图片关联起来(保存图片路径在Chunk元数据);用来在检索时能够根据Chunk找到对应图片
- 嵌入这些文本Chunks,保存到向量库。注意这里不用做分割(Split)。
检索与生成
检索与生成阶段的流程如下:
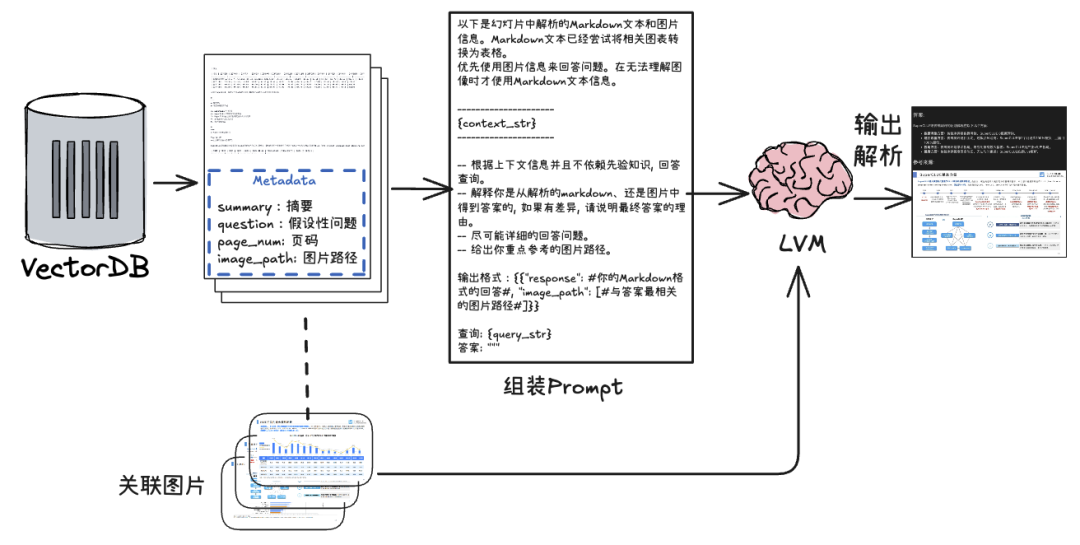
【流程说明】
- 从向量库检索关联的块,也就是前面对应到PPT页面的生成文本
- 根据这些块中的元数据(Image_path),找到对应的页面截图
- 将文本块组装成Prompt,与找到的图片一起输入多模态模型,等待响应
- 对响应做简单转换,以Markdown格式展示最终结果
【重点说明】
- 由于我们需要将关联的页面图片同时输入视觉模型,因此通常不能借助框架的高层抽象(比如LlamaIndex中的index.as_query_engine)来直接获得RAG引擎后查询。需要自定义一个查询过程,大致如下:
.....lvm = DoubaoVisionLLM(model_name='你的豆包模型名字')class MultimodalQueryEngine(CustomQueryEngine):... def custom_query(self, query_str: str): #检索关联chunk(nodes) nodes = recursive_retrieve(query_str) #组装prompt context_str = "\n\n".join( [r.get_content(metadata_mode=MetadataMode.LLM) + f'\n以上来自图片:{r.metadata['image_path']}' for r in nodes] ) fmt_prompt = self.qa_prompt.format(context_str=context_str, query_str=query_str) #输入提示和图片 response = self.multi_modal_llm.generate_response( prompt=fmt_prompt, image_paths = [n.metadata["image_path"] for n in nodes] )...multi_query_engine = MultimodalQueryEngine( multi_modal_llm=lvm)
这里简单封装了一个豆包的视觉大模型DoubaoVisionLLM,具体参考源码。
- 另一个技巧是关于输出。如何让输出结果用图文结合的方式来展示呢?我们在Prompt中给予了视觉大模型提示:
..输出格式:{{"response": #你的Markdown格式的回答#, "image_path": [#与答案最相关的图片路径#]}}...
然后对输出结果做简单转化:
...response_json = json.loads(response)answer = response_json.get("response", "")image_paths = response_json.get("image_path", []) markdown_output = f"### 答案:\n\n{answer}\n\n### 参考来源:\n"for image_path in image_paths: markdown_output += f"\n"
至此,对PPT构建的多模态RAG管道已经完成。我们用代码做测试:
response = multi_query_engine.query("这次评测中表现最好的开源模型有哪些?")from IPython.display import Markdowndisplay(Markdown(response.response))
得到如下答案:
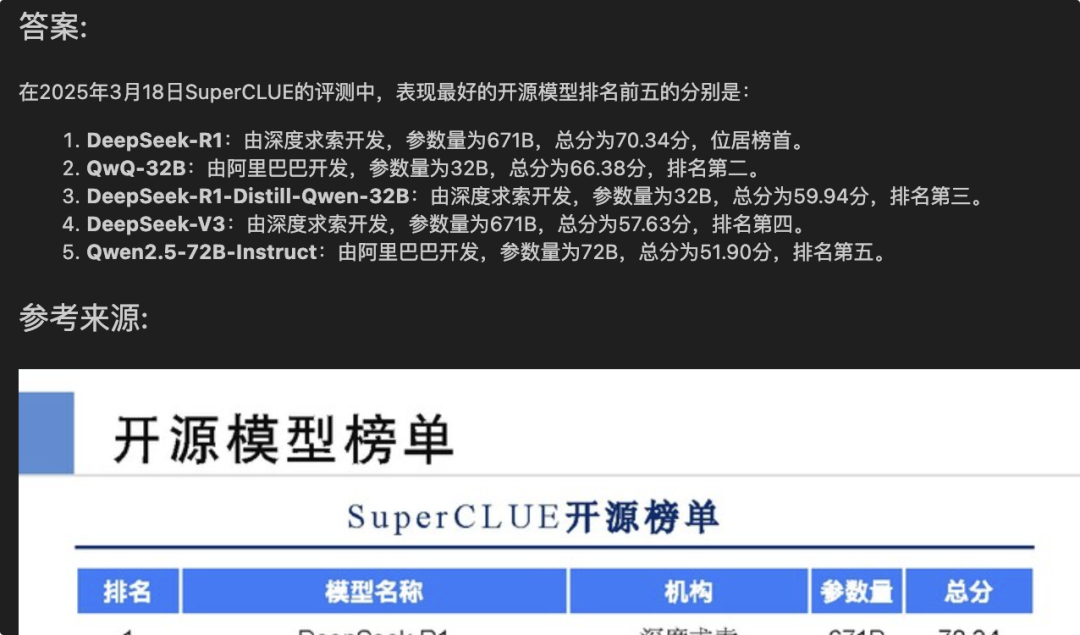
效果似乎还不错!
问题与优化
在测试过程中,我们也发现一些问题与可能优化的空间,包括:
- 尽管视觉模型已经很强大,但也并非完美,在一些图片解释上会发生少量偏差
- 多模态模型的使用,特别是在生成阶段,响应速度相对普通LLM会下降,且对Tokens消耗更大(但并非不可接受)。
- 如果PPT的页数或文档更多,在检索时精确度会下降,特别是输入问题较为模糊时。我们提供了两个优化实现,但未做评估验证:
- 对每个页面再次分割,减小Chunk的粒度,以提高检索精度;并在检索时查找到“父块”用于生成
- 尝试构建了关键词表索引,可结合向量索引进行融合检索。
此外,还可以考虑的一些优化有:
- 如果有大量PPT,可以借助元数据先做一次过滤
- 借助Agentic RAG回答不同类型的问题,比如总结性与细节性问题
- 测试多个向量模型与多模态模型,特别是向量模型对检索结果有较大影响
- 在实际应用中,生成的页面图片最好放在共享存储用URI访问
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献183条内容
已为社区贡献183条内容

所有评论(0)