小白从零开始勇闯人工智能:bert自然语言框架(3)
引言
在上篇文章中,我们深入学习了BERT的位置编码,明白了它如何通过三角函数为每个词注入位置信息,使模型能够捕捉语言的序列特性。然而,一个完整的Transformer编码器远不止于此。本文将延续这一探索,详细介绍BERT中不可或缺的残差连接与层归一化,并解读其预训练阶段的两大核心任务:掩码语言模型和下一句预测。
一、Add & Normalize:让深层网络训练更稳定
Transformer的每个子层(包括多头注意力和前馈网络)后面都紧跟着两个操作:Add 和 Norm。
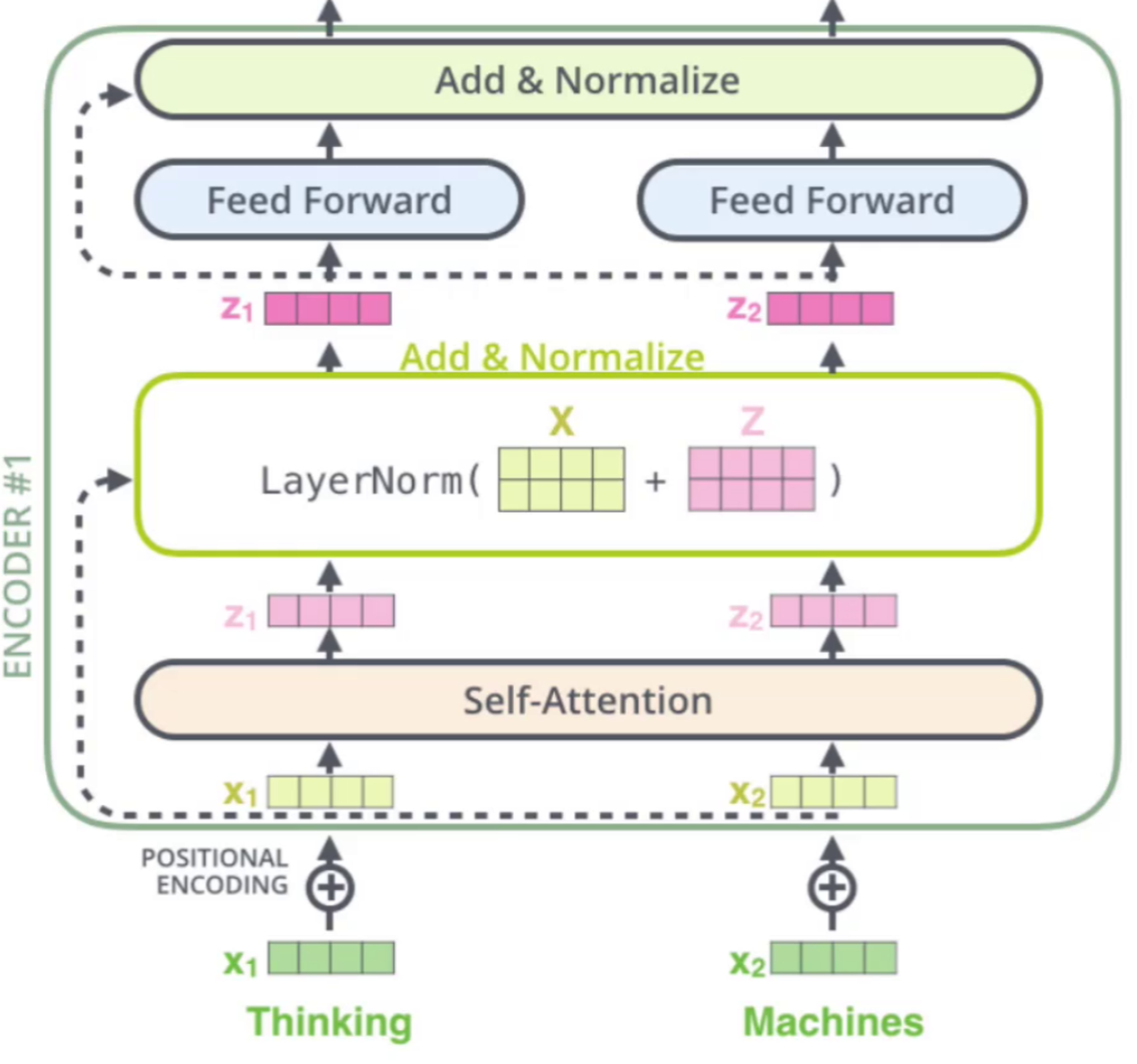
1、Add —— 残差连接
“Add”操作本质上指的是将子层的输入与其输出直接相加,即执行残差连接。具体而言,对于一个定义为Sublayer(x)的子层,其最终输出为x + Sublayer(x)。这一设计最早源自ResNet,其核心优势在于能够有效缓解深层神经网络中的梯度消失问题,梯度可以通过这种机制无损地回传到浅层。同时,这种结构使得信息能够在网络中顺畅流动,即便网络层数很深,优化过程也不会因信号衰减而变得困难,从而让模型更容易训练。
2、Normalize —— 层归一化
层归一化是对单个样本的所有特征维度进行标准化处理,与批归一化的跨样本统计方式不同。它首先为每个样本独立计算其所有特征的均值μ和标准差σ,然后将每个特征值减去μ除以σ,使该层输出保持稳定的分布。最后,通过引入可学习的缩放参数γ和偏移参数β,恢复模型可能需要的表达能力,公式为LayerNorm(x) = (x-μ)/σ * γ + β。
层归一化在Transformer中具有两大核心优势:一方面通过稳定每层输入的分布来加速模型收敛,另一方面不依赖批量大小,尤其适合序列长度多变的自然语言处理任务。每个子层的完整运算流程为:输入首先经过注意力等子层处理,随后通过残差连接将原始输入与子层输出相加,再执行层归一化,最终将结果传递至下一子层。这种“子层-残差-归一化”的设计有效保证了深层网络的信息流动与训练稳定性。
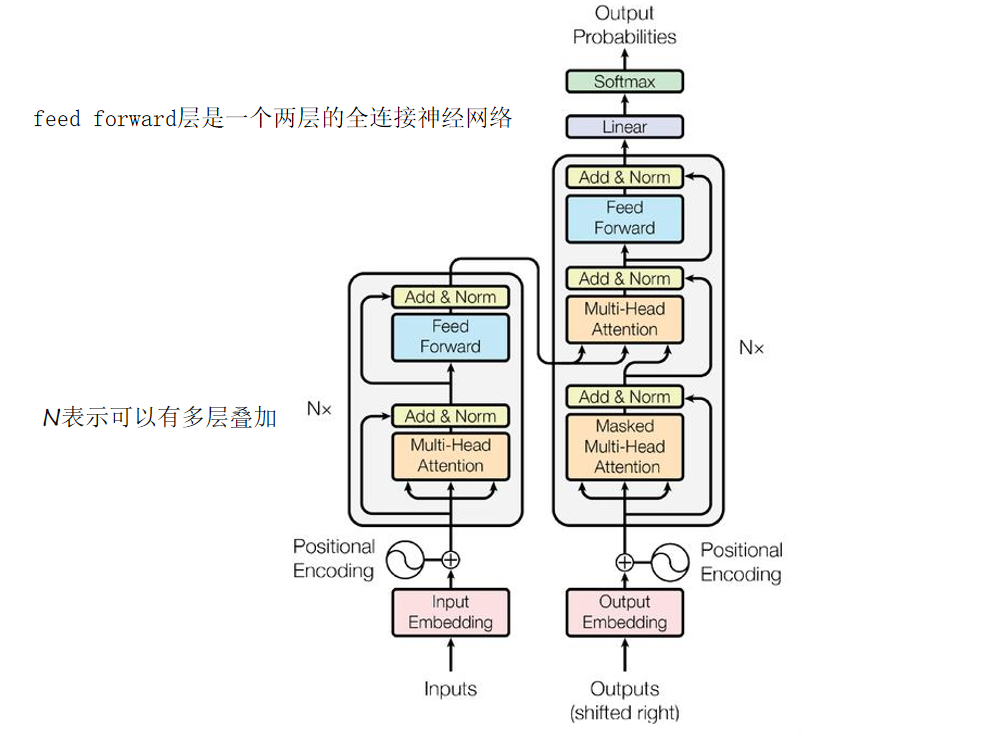
二、Transformer整体框架
完整的Transformer模型通常由编码器和解码器堆叠而成,BERT仅使用了其中的编码器部分。无论是编码器还是解码器,都由多个相同的层堆叠构成,每个编码器层包含两个核心子层:多头自注意力层和前馈神经网络层,且每个子层后都紧跟残差连接与层归一化(Add & Norm)。其中前馈神经网络是一个两层的全连接网络,先将输入向量升维,经ReLU激活后再降维回原尺寸。公式为:
它的作用是对注意力输出的每个位置向量进行独立的非线性变换,提取更深层特征。
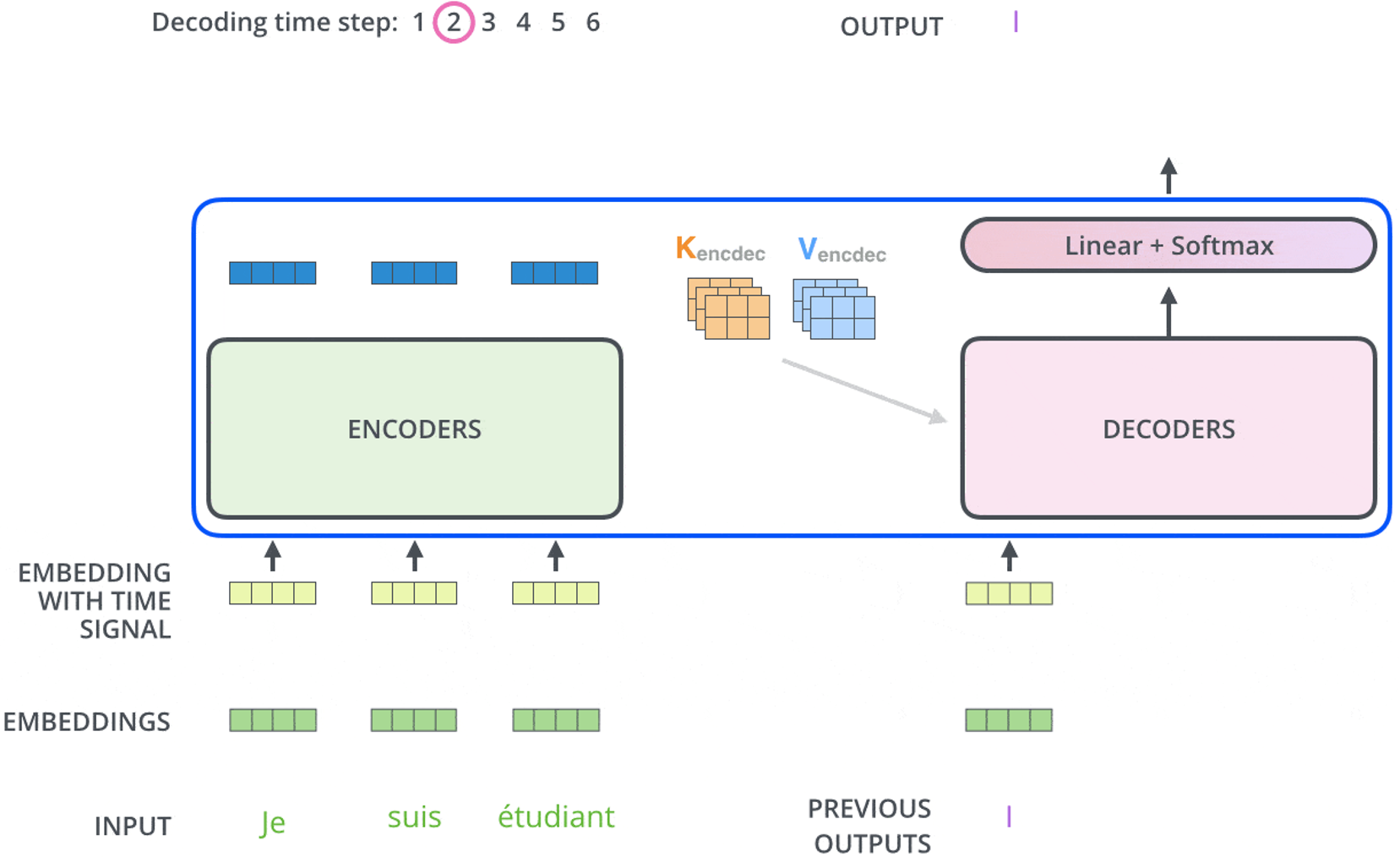
三、解码器中的“Outputs shifted right”
虽然BERT只用了编码器,但了解解码器的工作机制有助于理解生成任务。在训练时,解码器的输入有一个特殊操作:outputs shifted right(输出右移)。
1、什么是“shifted right”?
在训练解码器时,虽然我们已知完整的目标句子,但为了模拟生成过程,需要将目标句子向右移动一位,并在开头添加起始符<sos>作为输入。例如,目标句为“I love China”,则输入变为“<sos> I love China”,而期望的输出是原始目标句“I love China”,让模型在每个时间步根据已生成的前缀预测下一个词,从而学会逐词生成的能力。
2、为什么这么做?
在训练解码器时,为了实现自回归生成,需将目标句子向右移动一位并在开头添加起始符作为输入,同时利用掩码机制确保每个时间步只能看到已生成的前缀,而不能接触未来词。例如,对于源句“我爱中国”,目标句“I love China”被转换为输入“<sos> I love”,期望模型依次预测出“I”“love”“China”。这样模型便学会了根据已有序列逐步生成下一个词,使训练与推理时的生成方式保持一致。
四、BERT的训练数据
BERT的预训练基于两个任务,它们都不需要人工标注,可以从大量无标注文本中自动生成训练数据。
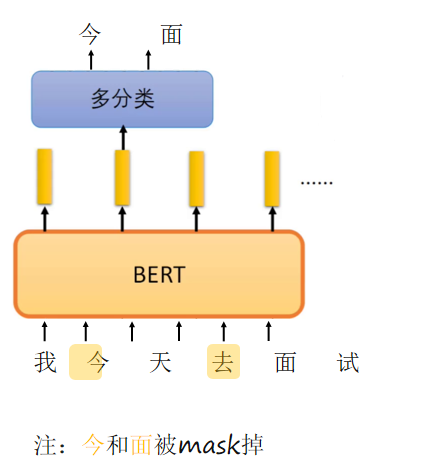
1、任务一:Masked Language Model (MLM)
随机遮蔽输入句子中15%的词,让模型预测被遮住的词。具体实现方法:
BERT采用掩码语言模型(MLM)进行预训练,随机遮蔽输入中15%的token(通常为字或子词)。其中80%替换为[MASK],10%替换为随机词,10%保持不变,这样既迫使模型利用上下文预测被遮词,又使其适应微调时无[MASK]的情况。遮蔽字而非整词是因为字数量有限,预测难度更合理。例如原句“我今天去面试”遮蔽“今”和“面”后变为“我[MASK]天去[MASK]试”,模型需准确预测这两个字,从而学习深层的语言表示。
2、任务二:Next Sentence Prediction (NSP)
让模型判断两个句子是否连续(即是否为原文中的前后句)。这有助于学习句子间的关系,对问答、推理等任务很重要。
正样本由语料中连续的两个句子A和B组成,标签为“是”;负样本则用随机选取的句子B替换原下文,标签为“否”。输入时,句子开头添加[CLS]用于分类,每个句子末尾添加[SEP]分隔。例如正例为“[CLS]我今天去面试[SEP]准备好了简历[SEP]”对应yes,负例为“[CLS]我今天去面试[SEP]中午吃了包子[SEP]”对应no。模型通过[CLS]的输出判断两句是否连贯,从而学习篇章级别的语义表示。
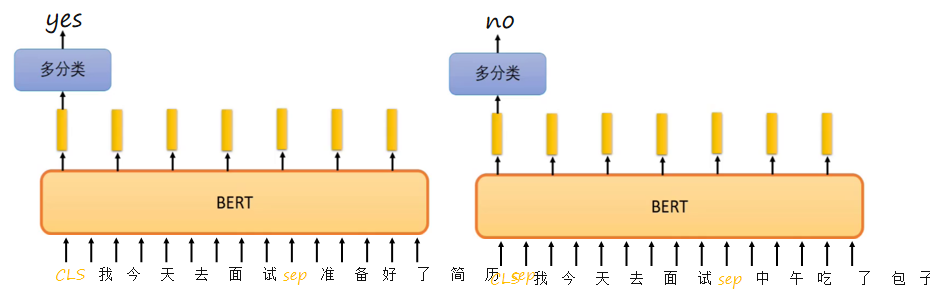
3、两个特殊标记的作用
在BERT中,[CLS]和[SEP]是两种特殊的输入标记。[CLS]被置于整个序列最前端,其经过多层Transformer后的最终输出向量能够聚合整个序列的表征,常用于下游分类任务,如判断句子关系或情感分析。在训练过程中,[CLS]与其他词一样参与注意力计算,学习融合上下文信息。[SEP]则用于分隔句子或标记句子结束,帮助模型明确句子边界,同样在训练中学习边界信息,从而更好地理解句子结构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)