为什么顶级 Agent 模型换一套 harness 能力差出一个数量级?工程系统才是关键!
本文深入剖析了 Anthropic、OpenAI 等顶级 Agent 系统的架构与工程实践,揭示了“同一个模型,换一个 harness,能力就会差出一个数量级”的核心原因。文章指出,Agent 的挑战并非单纯提升模型智能,而是系统工程的重要性。通过分析 Claude 模型在不同 harness 下的性能差异,强调了 Context Engineering(上下文工程)的核心地位,以及如何通过工具设计、状态外置、验证闭环和恢复机制来提升 Agent 能力。文章还探讨了长运行 Agent 的工程挑战,提出 Agent 的能力是多个因素的乘法系统,并总结了顶级 Agent 系统的工程共识,强调工程设计对于 Agent 成熟与落地的重要性。
本文系统梳理了 Anthropic、OpenAI、Manus、Devin 等顶级 Agent 系统的架构与工程实践,回答一个核心问题:为什么同一个模型,换一个 harness,能力就会差出一个数量级?
直觉上,Agent 的核心挑战似乎是"怎么让模型更聪明"。但深入这些系统后会发现,这个问题本身就问偏了。
真正的问题是:同一个模型,为什么换一套工程框架,表现就会天差地别?
2026 年初,Anthropic 公开分享过一组数据:同一个 Claude 模型,在 Claude Code 的 harness 下得分 78%,换到另一家创业公司的 harness,只剩 42%。同一个"大脑",换一个"身体",能力几乎腰斩。这个差距不是 prompt 技巧能解释的,它指向更底层的东西:系统工程。
从这个视角回看过去一年 Agent 的跃迁,很多现象突然就能连起来:为什么 SWE-bench 会在短时间内大幅上升;为什么最强的团队都在回归极简架构;为什么大家不再执着于"写更强的 prompt",而开始讨论 context、memory、verifier、recovery;为什么真正能进生产环境的 Agent 仍然稀少。因为 Agent 的主要瓶颈,已经从"模型智能"转向"工程系统"。
核心结论如下。
- 顶级 Agent 系统在架构上高度收敛:单线程循环加工具调用,远比想象中朴素。
- Prompt Engineering 正在退居二线,Context Engineering 才是决定上限的核心能力。
- Agent 的能力不是线性叠加,而是乘法系统;工程因子一旦补齐,效果会突然跃迁。
- 真正拖住生产落地的,不是"会不会生成",而是可靠性、验证、恢复和长任务管理。
- 长运行 Agent 与科研自动化,正在成为下一阶段最重要的 frontier。
它们共同指向的更深判断:Agent 的竞争壁垒,已经不再主要来自模型,而是来自模型外面的系统。
一、为什么最先进的 Agent,反而越来越"笨"
Anthropic 在《Building Effective Agents》中对 Workflow 与 Agent 做过一个看似简单、实则关键的区分:Workflow 的路径由代码预定义,Agent 的路径由模型动态决定。
这不只是定义差异,而是两种完全不同的可靠性模型。
Workflow 牺牲一部分灵活性,换来可预测、可调试、可验证。Agent 换来更强的适应性,但也把系统彻底带入概率世界。很多团队并不是 Agent 做不好,而是本该用 Workflow 的地方,过早上了 Agent。他们以为选的是"更高级"的方案,实际选的是一个失败率层层放大的系统。
Anthropic 总结的五种工作流模式很值得记住:提示链、路由、并行化、orchestrator-workers、evaluator-optimizer。本质是在受控范围内逐步放开决策权。换句话说,真正的 Agent 应该是最后的选项,而不是默认的选项。
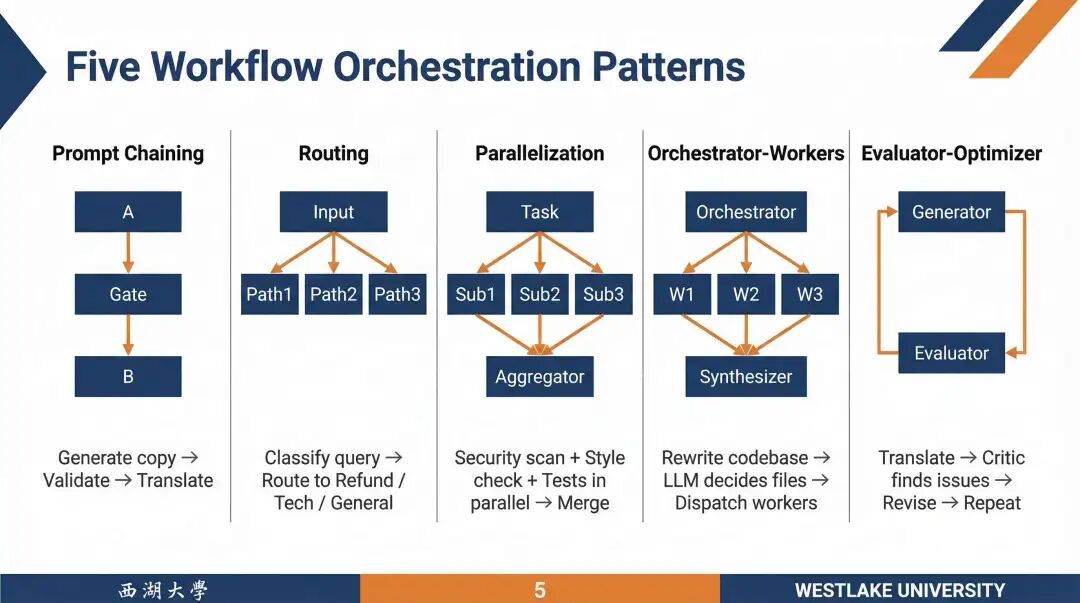
五种工作流编排模式
而当你真的走到 Agent 这一步,会发现它的核心循环极其简单:
while not done: observation = observe() action = llm.decide(observation) result = execute(action) done = evaluate(result)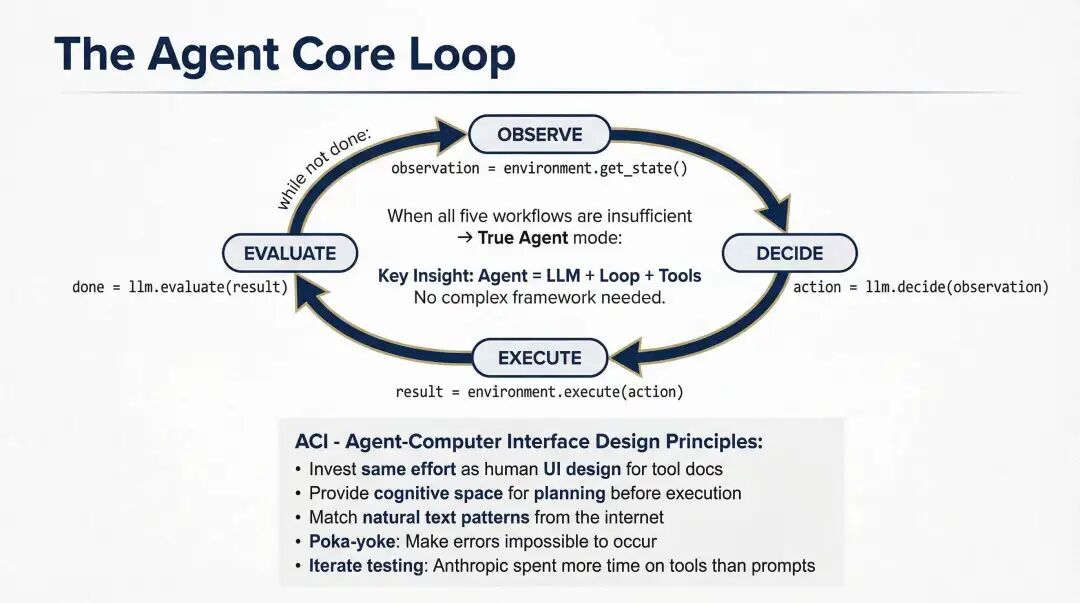
Agent 核心循环
关键不在这个 loop 本身——任何人都能写。真正决定效果的,是 loop 里的三件事:
- 模型此刻能看到什么。
- 模型此刻能调用什么。
- 模型做错之后,能收到什么样的反馈。
这也是为什么最强的系统在架构上都越来越朴素。复杂性没有消失,只是转移了。过去堆在"架构花样"上,现在放到了上下文组装、工具设计、状态外置、验证闭环这些更接近本质的地方。
Anthropic 提出的 ACI,Agent-Computer Interface,尤其值得重视。它的核心观点很直接:工具设计比 prompt 设计更重要。 工具描述、参数命名、错误信息、输入输出格式,不是边角料,而是给 LLM 做"用户体验设计"。过去 UX 为人设计界面;现在,很多 Agent 的关键工作是为模型设计界面。
这意味着工程重心正在从"如何把一句prompt写得更好"转向"如何把一个工作环境设计得更可用"。Poka-yoke 式的防错设计尤其典型:与其反复提醒模型"不要用相对路径",不如直接把系统改成只接受绝对路径,让错误无法发生。这不是在教育模型,而是在改造环境。
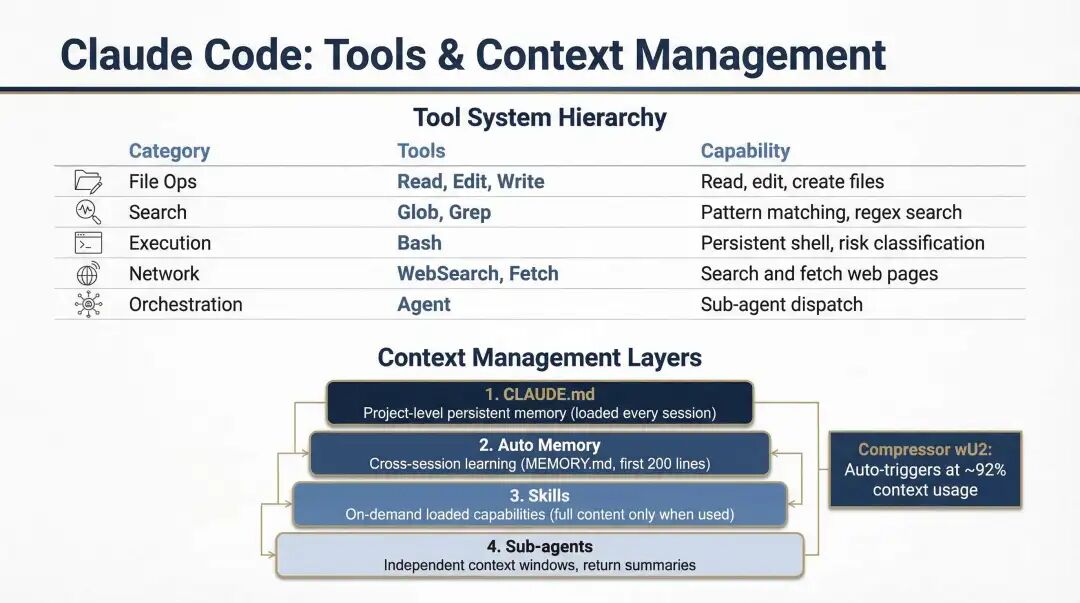
Claude Code 工具与上下文管理
Claude Code 和 Codex 的分歧,进一步说明了这一点。前者像坐在你身边的同事,直接在终端里干活,过程可见、可打断、可协作;后者像隔壁密封实验室的承包商,领了任务在隔离环境里独立完成,再交还结果。一个强调信任与协作,一个强调隔离与安全。表面是不同产品,本质是在回答同一个问题:怎样给同一个模型,配一个更强的工作系统。
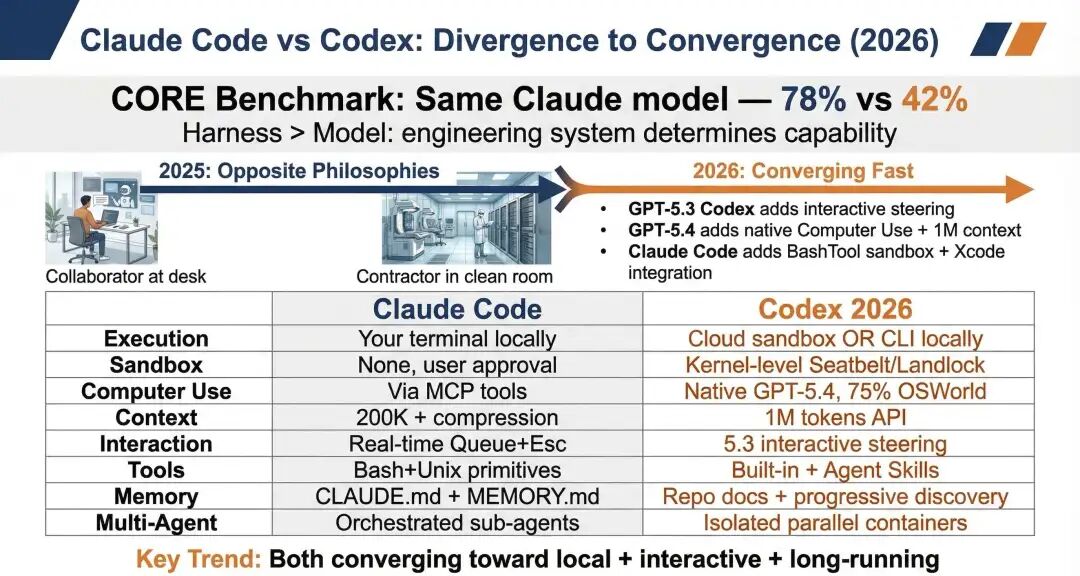
Claude Code vs Codex
也正因如此,harness 才会成为产品本身。模型通过 API 谁都能拿到,但工具链、上下文管理、权限控制、记忆系统、验证器与恢复机制,不是谁都能搭得好。你买的不是模型的聪明,而是让这份聪明真正发挥出来的那套工程。
Karpathy 把 Agent 比作操作系统,这个类比相当准确。LLM 是 CPU,工具调用像系统调用,子 Agent 像进程管理,而 Context Window 最像 RAM。一旦接受这个映射,你就会发现 Agent 系统最难的问题从来不是"算得更快",而是"内存怎么管"。什么该常驻、该换出、该压缩、该隔离——这决定了系统的稳定性与效率。
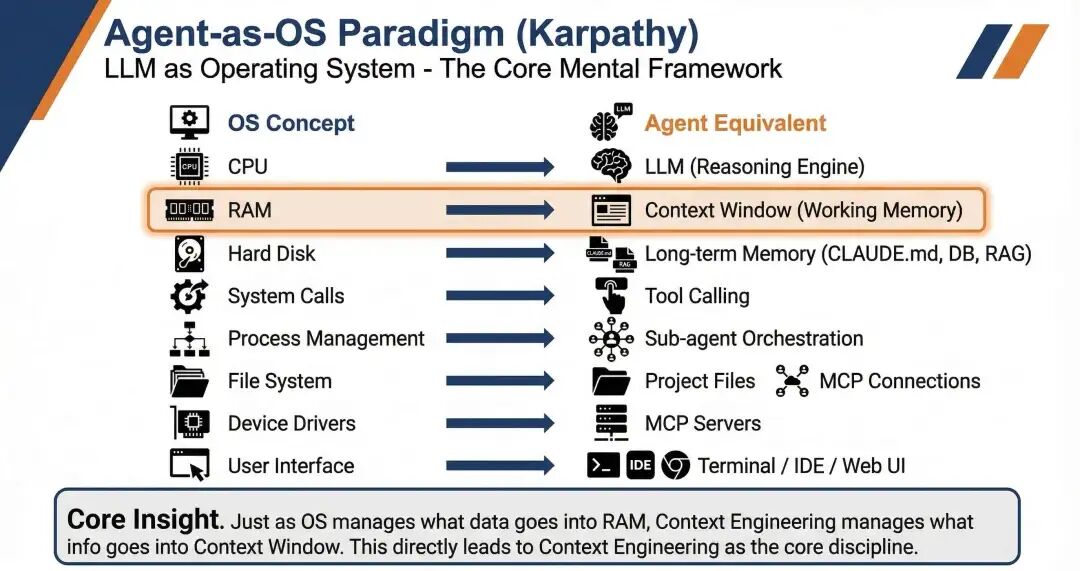
Agent-as-OS 范式
二、Context Engineering:Agent 时代真正的核心战场
Prompt Engineering 关注"怎么把话说对";Context Engineering 关注"怎么在模型开始思考之前,把它需要的信息准备好"。
这不是措辞上的升级,而是范式迁移。

Context Engineering 定义与起源
300 个聚焦的 token,往往胜过 113,000 个散乱的 token。 数据量差几百倍,更少的反而更好。这说明 Context Engineering 的本质不是容量管理,而是信噪比管理。
很多人以为更长的上下文窗口会自动解决问题,事实并非如此。上下文一旦过长,准确率会下降,推理能力会退化,中间位置的信息还会被"Lost in the Middle"效应吞掉。水管再粗,灌进去的是泥沙也没用。
这对 Agent 工程的意义很直接:你不是在给模型"喂更多信息",你是在给它分配有限注意力。 一旦这样理解,很多设计原则都会自然成立。
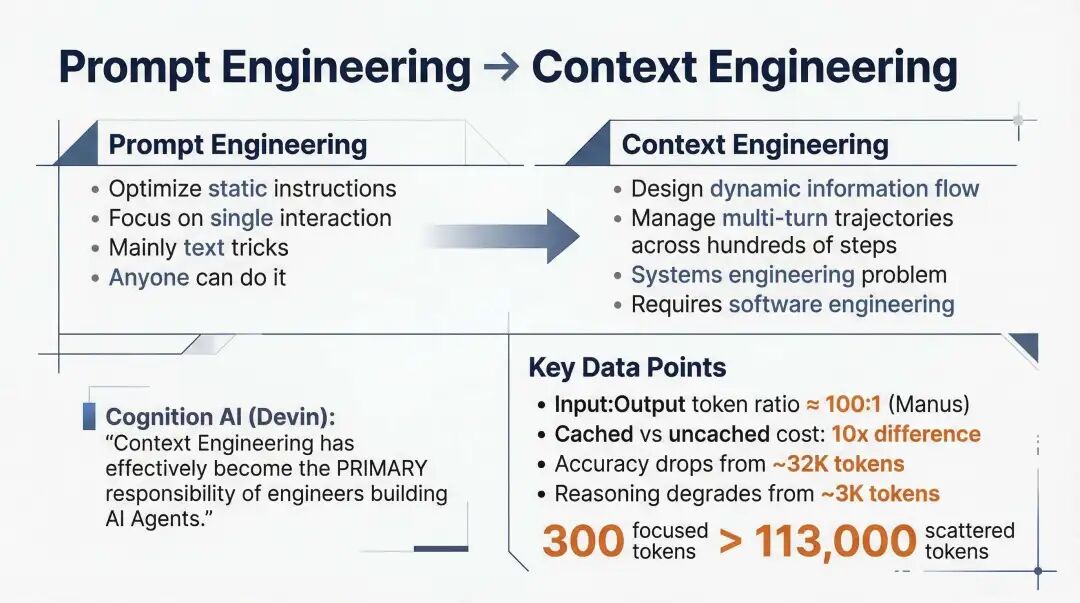
Prompt Engineering → Context Engineering
Context Engineering 可以归纳为四个基本动作。
- Write:把重要状态写到窗口外。不要指望模型"记住一切"。任务列表、进度文件、scratchpad、CLAUDE.md、运行日志,这些不是辅助物,是系统本身的一部分。
- Select:按需把信息拉回窗口。不是所有知识都该常驻,只有当前步骤真正相关的那部分信息,才值得占用注意力。
- Compress:主动压缩,而不是被动截断。压缩的关键不是删多少,而是保留什么,尤其是失败细节、约束条件与已验证结论。
- Isolate:把不同任务分给不同上下文。子 Agent 的价值不只是并行,更是隔离,不让局部复杂性污染全局上下文。

四大核心策略:Write & Select
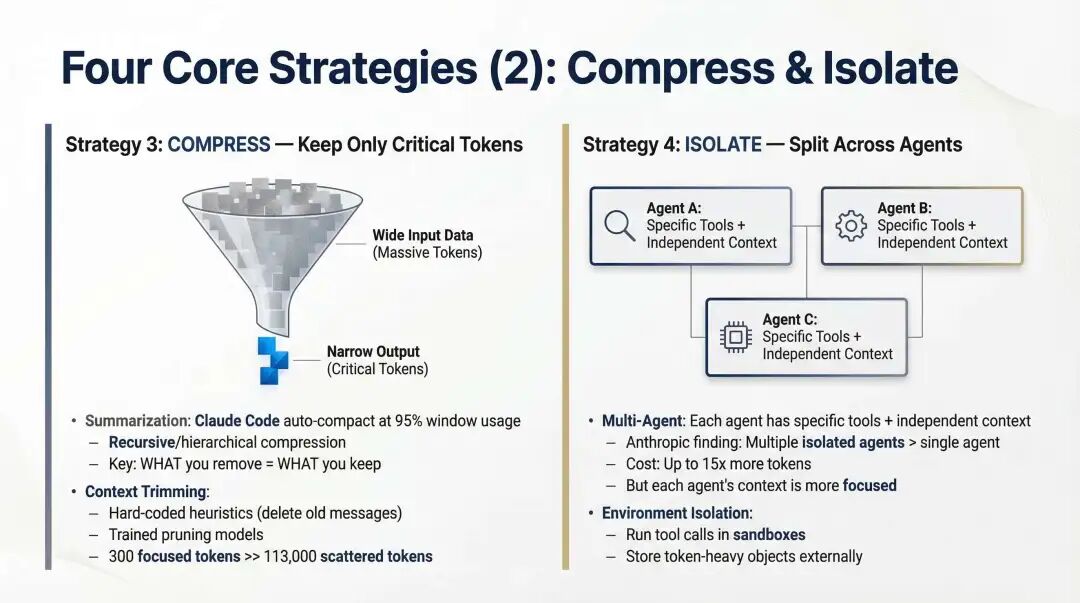
四大核心策略:Compress & Isolate
再往前一步,还有第五个动作:Salience Shaping,重要性塑造。 顶级系统不只管理信息流动,还主动操纵注意力显著度。Manus 反复重写 todo.md,不是因为计划变了,而是让当前目标持续出现在上下文末尾,利用 Transformer 的 recency bias,把模型注意力钉在当下最重要的事上。
由此引出一个更一般的判断:Agent 工程很大一部分工作,不是在教模型做什么,而是在管理模型把注意力放在哪里。
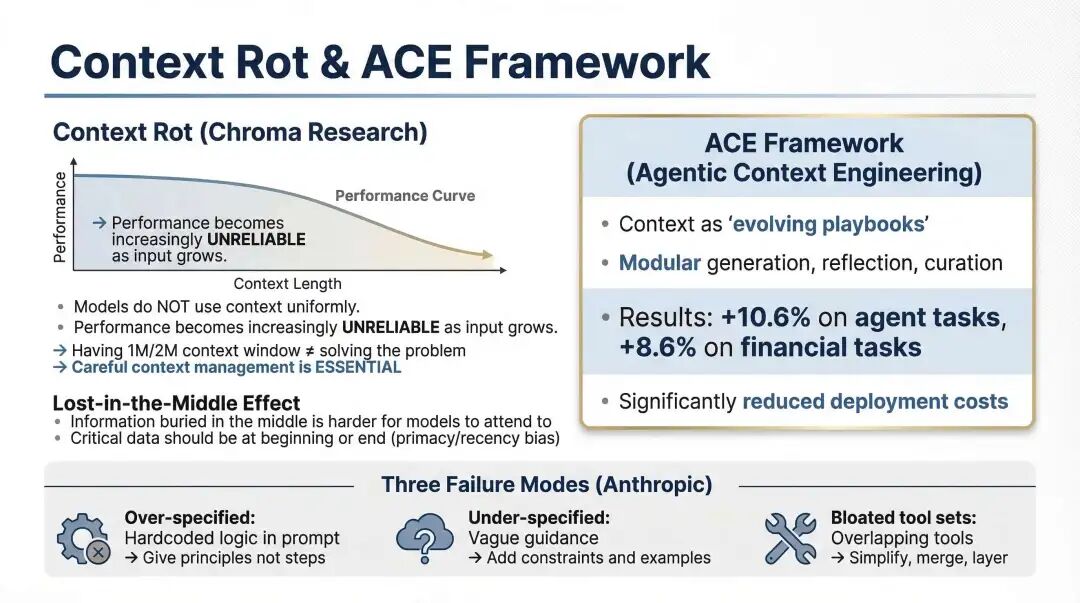
Context Rot 与 ACE 框架
关于长上下文,另一个必须正视的现象是 Context Rot,或者说"上下文腐化"。随着输入变长,系统不一定显得更笨,但会变得更不稳定、更不可预测。比这更危险的是 Context Collapse:让模型每轮重写整段 context,它会逐渐把丰富具体的上下文压缩成越来越短、越来越泛化的摘要。看起来"更整洁"了,实际能力却下降了。
ACE 框架的启发:解决方向不是"压缩得更聪明",而是改变数据结构。不要把上下文当成一整块文本反复改写,而要变成结构化条目,增量维护,只更新必要部分。换句话说,把记忆当数据库维护,而不是当作文档重写。
常见误区:把规则整理成更精炼的 CLAUDE.md 就算"优化上下文"。但没有明确的数据结构与更新规则,这种重写很可能导致更多的信息损失。
Context Engineering 要求重新理解 LLM:它不是完美的信息处理器,而是聪明但注意力有限的有界理性体。过度指定,是因为你不信它;指定不足,是因为你过度信它;工具过多,则是你根本没有把它当成一个注意力有限的执行者。很多上下文设计的失败,归结起来就一句话:设计者没有正确估计模型的认知负荷。
三、Agent 的真正门槛,不在生成,而在验证与恢复
很多人谈 Agent,第一反应是"它能不能想出来"。但进入生产环境后,更关键的问题往往是:它出了错之后,系统能不能发现,能不能回滚,能不能继续。
自我纠错不是 Agent 的高级能力,而是基础能力;是否有效,取决于有没有足够强的接地信号。
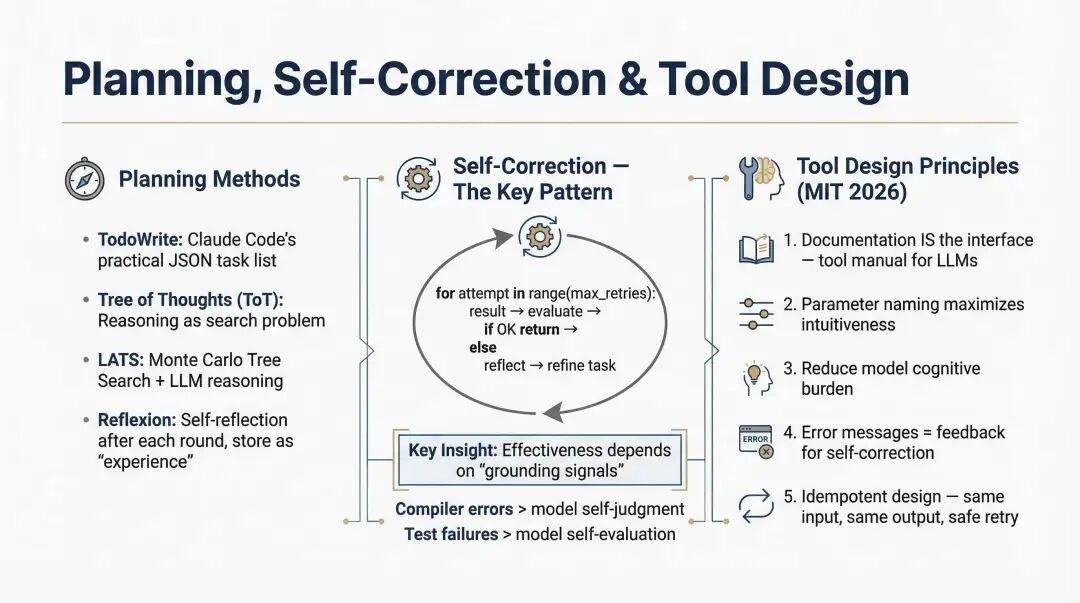
规划、自我纠错与工具设计
编译器报错,比模型"自我感觉良好"可靠得多。测试失败,比另一段漂亮的自我评价可靠得多。类型检查、schema 校验、数据库约束、端到端测试,都是接地信号,把 Agent 从"自言自语"拉回外部世界。
这解释了为什么 Coding Agent 最先成熟。编程天然拥有最强的验证器:编译器、解释器、测试框架、类型系统、lint、CI。模型不需要知道自己是否正确,环境会告诉它。而开放式写作、战略分析、创意设计,验证器弱得多,"自我纠错"很容易退化成自我说服。
判断一个领域的 Agent 能否成熟,有个比"模型够不够强"更实用的问题:这个领域有没有强验证器? 如果没有,能不能拆成一组有强验证器的子任务?这比打磨 prompt 更值得思考。

可靠性:概率性错误级联
可靠性还有一个残酷的现实:乘法规律。假设每一步成功率是 95%,连续 10 步全部成功的概率只有 60%,20 步只剩 36%。Agent 不是"差一点就能用"——链条足够长时,细小误差会迅速累积成整体失效。
更危险的不是显式崩溃,而是静默退化:看起来一直在工作,输出也不离谱,但质量悄悄滑坡。传统监控捕捉不了——CPU、延迟、接口状态都是绿的,出问题的是语义质量。
因此,真正成熟的 Agent 系统几乎都收敛到同一套工程共识:
- 状态必须外化。重要状态不能只存在于上下文里。
- 格式必须结构化。JSON、YAML、schema 化输出,比自然语言可靠得多。
- 进展必须增量化。一口气完成整个任务,几乎总是不可靠的。
- 验证必须闭环。没有验证器,就没有可用的自动化。
- 恢复必须可执行。重试、回退、检查点、失败分类,都要提前设计。
- 文件系统往往是最好的长期记忆。 它简单、稳定、可 diff、可回放、可审计。
这也是对"高级记忆架构"应保持谨慎的原因。学术界的记忆研究很精彩,但实际工程中,最有效的往往是最朴素的:CLAUDE.md、todo.md、progress.txt、Git 历史、结构化日志。不是缺乏想象力,而是文件系统有一种被低估的工程美德:稳定、透明、可恢复。
四、Agent 的能力为什么会突然爆发:因为它是乘法系统
用一句公式概括 Agent 的能力来源:
有效能力 = Base Model × Context Quality × Tool Affordance × Test-Time Compute × Verifier Quality × Memory/Recovery
核心命题:六个决定性杠杆
这条公式最重要的不是列了哪几个因子,而是乘法关系。
任何一项接近零,总能力就接近零。Agent 的增长从来不是平滑的。很多时候,你会感觉系统长期没有明显进步;但一旦某几个工程因子同时跨过临界点,效果会突然跃迁。这就是为什么某些 benchmark 一年内出现断崖式提升——不是模型一夜聪明了几十倍,而是上下文管理、工具设计、验证器、恢复机制这些缺失的乘法因子,短时间内被密集补齐。
这条公式还有一层实用含义:当你的 Agent 不好用时,不要先换模型,先找最短的那块板。 很多系统的问题根本不在 Base Model,而在验证器几乎为零、状态管理几乎为零、恢复机制几乎为零。补最弱项,收益远高于换更强的模型。

六个杠杆详细对比
Manus 是这个逻辑的一个典型代表。最值得学习的不只是 CodeAct,而是它把 Context Engineering 与 cache efficiency 提到了系统设计的第一层级。稳定的 system prompt、append-only 的上下文历史、固定的工具定义、确定性的序列化格式——这些"很工程"的细节,决定了缓存命中率、成本结构,也决定了系统能否跑得足够长、足够稳。
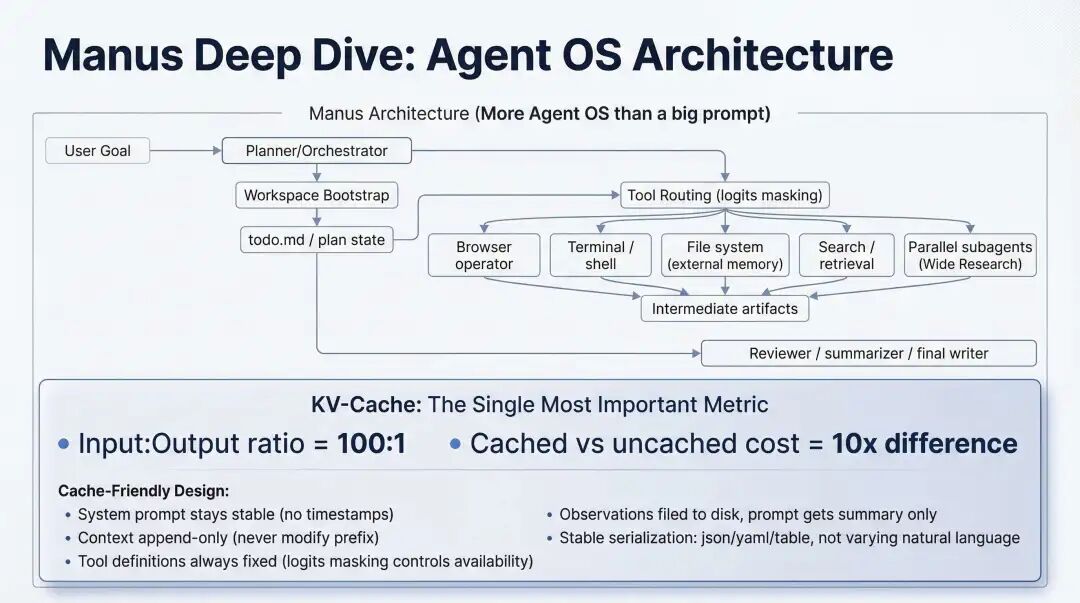
Manus 架构
更重要的是,Manus 的 todo.md 展示了一个精妙的观念:任务清单不只是项目管理工具,它还是注意力锚点。长轨迹执行中,Agent 最容易出的问题不是"不会做",而是"目标漂移"。把当前目标持续推到上下文尾部,就是用工程手段对抗注意力衰减。

Manus 文件记忆与注意力操纵
Anthropic 的双 Agent 架构,把长运行 Agent 的方法论推到了成熟的层次。一个 Initializer Agent 只做一次性的环境搭建、特性枚举与进度文件初始化;后续每个 Coding Agent session,只接手一个 failing feature,完成、验证、提交、记录,然后交班。这个架构最精彩的地方不是"更复杂",而是恰恰相反:它通过外部状态与任务分解,让单次会话变得足够简单。
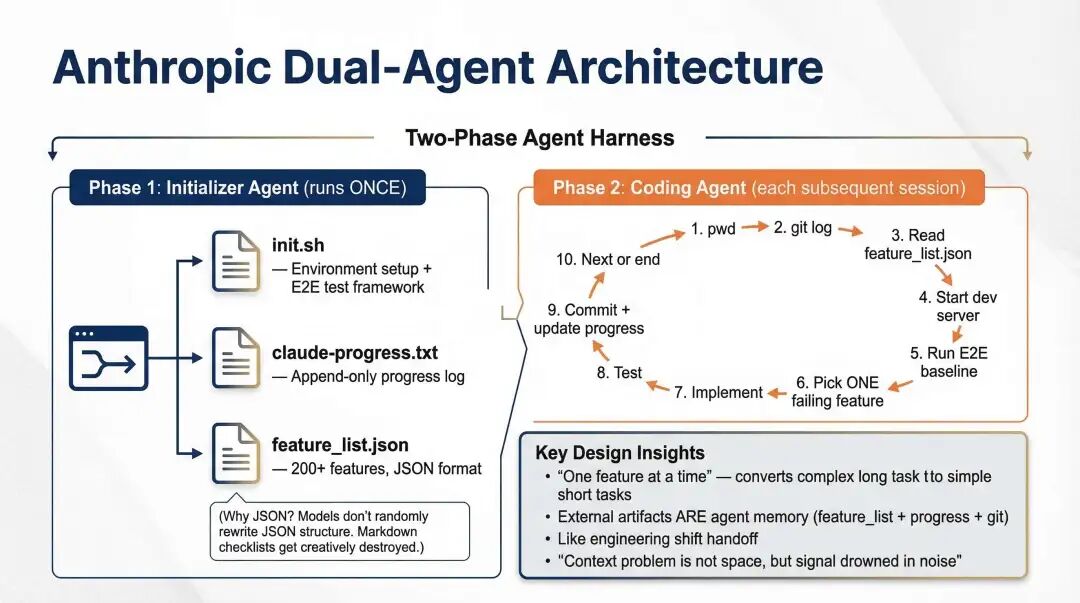
Anthropic 双 Agent 架构
这指向一个核心工程原则:允许 Agent 更笨的架构,往往比要求 Agent 更聪明的架构有用。 真正强的系统,不是要求超级 Agent 在超长上下文里一次搞定所有复杂性,而是把不可控的大任务拆成一连串可验证、可恢复、可交接的小任务。系统的价值不是给模型增加神秘能力,而是降低每次推理承担的复杂度。
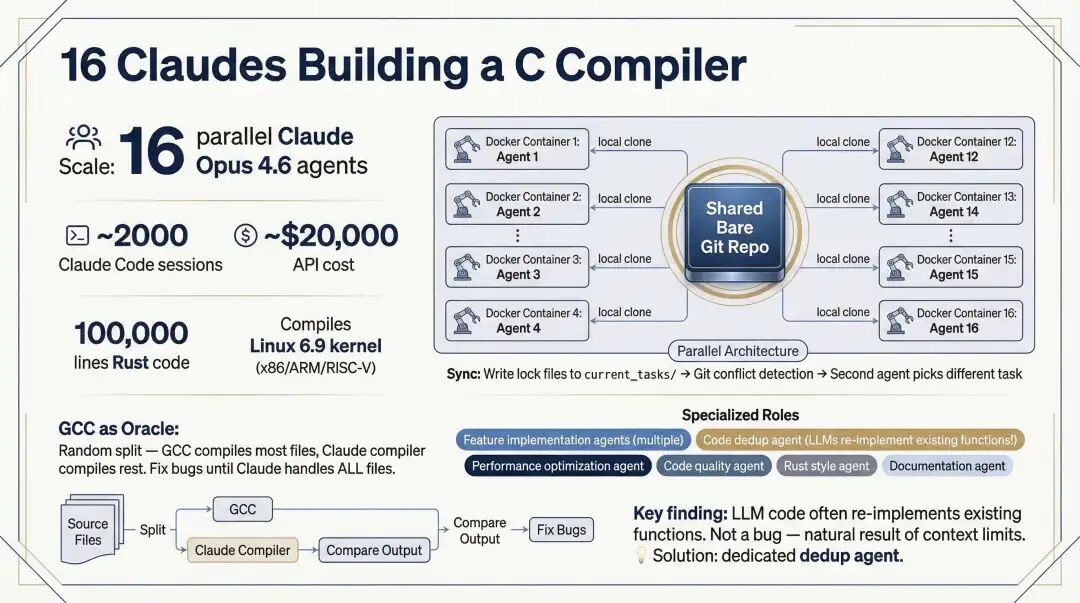
16 个 Claude 造编译器
“16 个 Claude 造编译器"的案例,把这个逻辑推到了更大的尺度。值得注意的是它暴露的一个典型问题:LLM 经常会重新实现已经存在的函数。常被归因于"模型不够聪明”,但更准确的理解是信息可达性问题。代码库大到一定程度,不可能全部塞进上下文。Agent 之所以重复劳动,往往不是不会判断,而是根本看不到相关信息。很多看似"能力问题"的失败,最后都能溯源到"信息架构问题"。
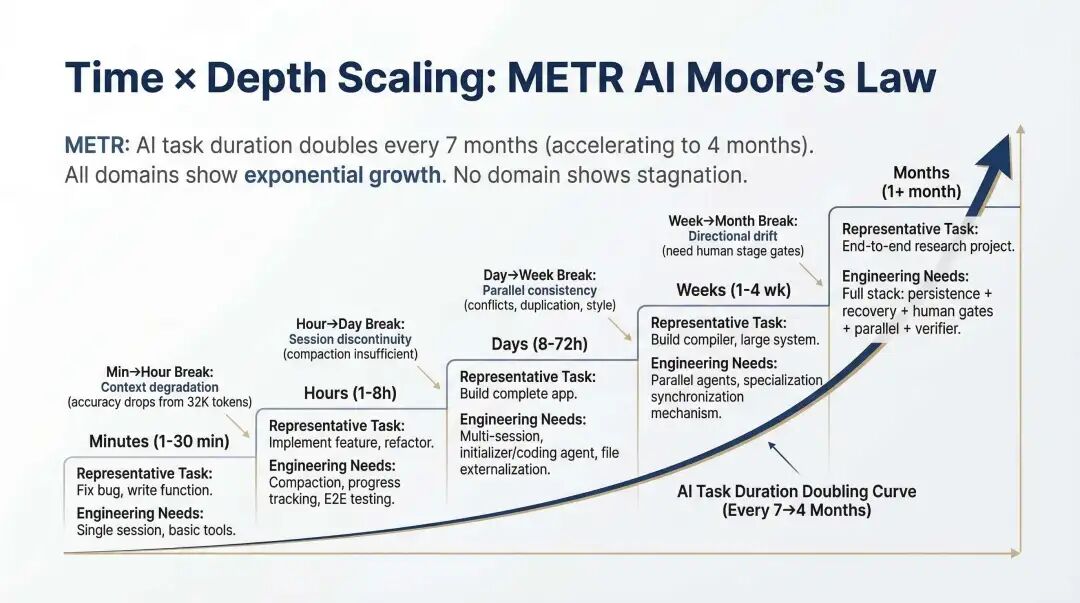
METR AI 摩尔定律
因此,长运行 Agent 的门槛不在模型,而在基础设施。分钟级任务和周级任务的差距,不只是上下文更长,而是是否具备会话交接、状态持久化、并行一致性、失败恢复、人类 stage gate 这些系统能力。任务时长每上一个量级,背后的工程系统就要升一个维度。
一旦基础设施成熟,科研自动化就不再是科幻。不是模型突然"变成了科学家",而是研究工作本身也能拆成检索、假设、实验、验证、记录、回退、复现这些可工程化的步骤。长运行 Agent 的意义不是多跑几小时,而是开始具备承载复杂知识工作的系统条件。
五、最重要的信号,不是某个产品领先,而是所有强者都在收敛
支撑这些判断的,不是某篇论文、某场发布会、某组 benchmark,而是一个更朴素的事实:Anthropic、OpenAI、Manus、Devin 这些最成功的团队,正在独立地收敛到同一组原则。
都在强调状态外化、结构化格式、增量执行、验证闭环、Git 检查点、文件系统记忆。产品形态不同,哲学立场不同,安全模型不同,但底层工程越走越像。

四大系统核心共识
这不是潮流,而是约束。
Agent 系统面对的是同一组基本事实:Context Window 有限,模型输出带有随机性,会话天然缺乏持久记忆。这三个约束下,很多"设计偏好"最终退化成"生存条件"。就像鲨鱼和海豚外形相似,不是互相模仿,而是水中高速移动的物理约束只允许有限解法。Agent 工程也一样。多个独立团队在没有协同的前提下走向同一结构,最合理的解释不是巧合,而是第一性约束。
回到开头那个问题:Agent 的工程差距,到底由什么构成?
答案可以压缩成三句话。
第一,Agent 的上限首先是工程上限。 模型当然重要,但拉开差距的往往是 harness、工具系统、上下文组织、验证器与恢复机制。
第二,Context Engineering 的本质不是塞进更多信息,而是用有限注意力换取更高信噪比。 300 个精准 token 胜过 113,000 个噪音 token,这不是技巧,而是规律。
第三,最好的系统不是让模型承担更多复杂度,而是让单次推理承担更少复杂度。 把大任务拆小、把状态写出去、把验证接进来、把恢复设计好,Agent 才会真正可用。
三个判断指向同一个方法论:不要把期望押在"下一代模型会更强"上,而要把系统设计成"用今天的模型也能稳定完成更小、但真实的工作单元"。
试着拿一个真实项目,补上最弱的乘法因子。多数时候,它不是模型能力,而是验证器、状态外置、上下文管理,或者恢复机制。只有真正做进系统,理解才会从"观点"变成"能力"。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)