AI辅助实现心得分享 - RDMA优化KVstore已有数据同步
一、背景
Github代码全开源 - kvstore 基于EPOLL的轻量级高性能kv存储项目,可对接博客存储、用户信息缓存、短连接系统后台应用。支持内存池,持久化和主从同步,特殊字符和大value兼容。可redis resp指令操作。
1.1 瓶颈
原本的对于已有数据的主从同步设计,依赖于RDB加载后在业务层kvs_executor中通过feed_slave这个入口函数来调用send发送编码好的RESP数据,从机通过复用协议层解析逻辑重新实现同步,我们之前以及实现了基于mmap的RDB内存映射加载替代了malloc拷贝式加载,然而,在高并发场景下,频繁send仍然有较高的系统调用开销。
1.2 优化
此篇博客比较详细地介绍了需要了解的关于RDMA的知识和概念,如果你此前从未接触RDMA,可以先读一下这篇博客。
使用RDMA优化已有数据同步的设计核心,PSYNC握手后,主机调用mmap将RDB映射内存,创建RDMA连接后主机通过rdma_send向从机发送同步数据,整个过程走网卡的,实现零拷贝。
二、需求分解与AI辅助实现
多说一点:关于AI编程
这里关于AI编程想多谈一点,我们学习某些东西的时候并不应该过度依赖使用AI,但是当项目需求出现的时候,AI是很好的帮助我们出成果的工具。AI的能力实际上是你个人能力的拓展,好的业务逻辑理解,好的需求分解,好的编程习惯,都会转化为好的prompt从而更好地驱动AI帮助我们。反之,不了解业务逻辑,无法分解需求,编程习惯糟糕会导致AI也变得糟糕。一言以蔽之,好的工程师喂养AI,写精确的prompt教会AI理解项目需求中每一步的上下文;坏的工程师迷信AI,写宽泛的prompt让AI自由自在、自说自话。
2.1 分解需求
RDMA这种文件传输的实现相比于tcp sendfile比较复杂,然而我们可以分解为以下几个小步骤:
- 连接建立:涉及创建QP,CQ,注册MR等资源
- 控制面:进行RDMA数据传递的元数据
- 数据面:RDMA进行实际的数据面传递
三个小步骤之间是递进的关系,我们一个基本的AI辅助思路,就是利用这种递进关系,及时分阶段测试与提交代码,确保我们在AI生成代码之后问题的复杂度不失控,并且可以迅速回滚。
2.2 技术方案 - 为AI搭建画板
技术方案是怎么样的?AI说了不算,你说了算。
AI理解上下文的窗口是有限的,目前LLM的注意力机制也决定了我们和AI的互动必须分重点。过于庞大的代码一次性发给AI,让它来做技术选型,很可能会有莫名其妙的幻觉出现。所以我们不得不去认真梳理已有的业务逻辑,做到自己先确定技术选型方向这个元问题。
万事开头难,RDMA的连接与tcp完全不同,它自成体系,在建立连接这简单一步之前,需要先考虑代码功能边界和文件目录管理,所以必须先确保对已有代码架构有充分理解。
- 连接的建立需要类似于服务器-客户端的逻辑,可以建立一个rdma_connection.c文件
- RDMA的数据同步模块与之前的replication模块关系不大,建立一个文件rdma_sync.c文件,RDMA传输状态机代码落在这里。
- 已有的replication模块需要调用RDMA模块中的函数,建立一个rdma.c文件存放它们以供接口调用。
至此,我们为AI搭建出了一个“画板”,即给AI提供了落代码的地方同时,进一步分解了需求,缩小了prompt的边界。
碎碎念:当然了,这部分代码功能边界和文件目录管理也可以尝试让AI给出方案,但是我的经验是,如果你自己不加入合适的理解进去,AI的方案一般不那么优雅(UNIX哲学),会有很多过度设计。
但是做到这一步后,AI的作为本博客的主角终于可以登场了!让AI按照模块边界在指定的工程文件里生成。或者,先让AI给出一份最小可运行的RDMA连接建立demo,还有简单的测试用例。这种复杂度的问题,AI应该不费吹灰之力就能完成,因为这部分代码一般都比较固定,就和tcp连接一样。
然而,接下来继续分解需求就进入深水区了——因为控制面和数据面的技术选型出现了分叉路,需要自己考虑trade-off。
2.3 技术选型一:控制与传输分离
考虑复用原有的TCP连接进行控制传输,主机和从机之间的PSYNC、FULLSYNC通过TCP传递,RDMA连接所依赖的元信息如rkey,tcp fd,rdma_conn id, size等也通过TCP传递。实际上的数据传输则通过RDMA连接传递。
通过AI将之前的PSYNC握手函数改为了新的样式(见下),附带还有些解析元数据的函数meta_data_parser等辅助函数。注意我让AI特别生成了与工程风格相适配的日志打印便于调BUG——提醒AI一句就好。
static int kvs_replication_send_rdma_metadata(int slave_fd) {
rdma_metadata_t meta;
char line[256];
int len = 0;
ssize_t sent;
LOG_DEBUG("[REPL] Sending RDMA metadata to slave fd=%d\n", slave_fd);
if (kvs_replication_build_rdma_metadata(&meta) != 0) {
LOG_WARN("[REPL] Failed to build RDMA metadata for slave fd=%d\n", slave_fd);
return -1;
}
LOG_DEBUG("[REPL] Encoding metadata: addr=0x%llx, rkey=%u, len=%u\n",
(unsigned long long)meta.remote_addr, meta.rkey, meta.length);
len = snprintf(line, sizeof(line), "+RDMAFULLSYNC %llu %u %u\r\n",
(unsigned long long)meta.remote_addr,
meta.rkey,
meta.length);
if (len <= 0 || len >= (int)sizeof(line)) {
LOG_WARN("[REPL] Failed to encode RDMA metadata for slave fd=%d (len=%d)\n", slave_fd, len);
return -1;
}
LOG_DEBUG("[REPL] Encoded metadata: %s", line);
sent = send(slave_fd, line, len, 0);
if (sent != len) {
LOG_WARN("[REPL] Failed to send RDMA metadata to slave fd=%d: sent=%zd, expected=%d, errno=%d (%s)\n",
slave_fd, sent, len, errno, strerror(errno));
return -1;
}
LOG_INFO("[REPL] Sent RDMA metadata to slave fd=%d: addr=0x%llx rkey=%u len=%u\n",
slave_fd,
(unsigned long long)meta.remote_addr,
meta.rkey,
meta.length);
LOG_DEBUG("[REPL] Metadata sent successfully, waiting for slave response...\n");
return 0;
}
为什么这样?
-
方案一:我们熟悉已有业务逻辑:我们成功实现了基于tcp send和recv的psync握手,基于tcp send和recv的主从同步,这部分连接已经做到了稳定——传递少量元数据游刃有余。
-
方案二:想要建立RDMA,我们也可以通过迭代刚才AI落的代码——RDMA连接。但是元数据虽然少,但是也是需要数据传递功能的,然而我们数据面都没做起来,谈何数据传递功能呢?
碎碎念:其实方案二也可以做,许多上线kv存储项目采用的就是方案二。但是问题是,我们不知道AI能不能做,因为这相当于一次性需要AI同时生成数据面和控制面的代码,甚至连接层面的代码也会还要改,更别提原先的业务逻辑和之后会提及的网络层改动。这些需求又混在一起了,按照经验,AI一次性无法处理这么多的需求。
2.4 技术选型二:单线程无锁设计
因为我了解我的kv存储项目——这是一个单线程的项目,在其他的模块保持着单线程也未加锁。但是在RDMA的数据传递中,常见的做法是用到cq_poll线程来轮询CQ,回收CQE。为了保持无锁设计,我决定将轮询CQ的逻辑落在网络层(reactor)的main loop中。
//reactor.c main loop
while (1) {
struct epoll_event events[1024] = {0};
int nready = epoll_wait(epfd, events, 1024, -1);
for (i = 0; i < nready; i++) {
/* call back logic */
//...
/* end call back logic*/
if (events[i].events & (EPOLLERR | EPOLLHUP)) {
close(connfd);
epoll_ctl(epfd, EPOLL_CTL_DEL, connfd, NULL);
}
}
/* Async persistence: submit buffered writes if buffer is full */
aof_buffer_t *aof_buf = kvs_get_aof_buffer();
if (aof_buf != NULL) {
kvs_persist_submit(aof_buf);
}
/* Check and flush buffer based on time interval */
kvs_persist_check_and_flush();
/* RDMA Non-blocking check for completed writes */
kvs_persist_peek_cqe();
#ifdef RDMA_ENABLE
rdma_server_poll_events();
rdma_poll();
#endif
}
return 0;
}
三、代码理解与AI辅助实现
我们用AI实现了连接建立和控制面代码。现在来到了数据面的实现。
关于AI辅助编程,多说一点:某篇研究AI辅助编程的文章如是说,AI的使用者分为如图这几类:
y坐标:学习所得(代码理解程度)
x坐标:项目交付时间
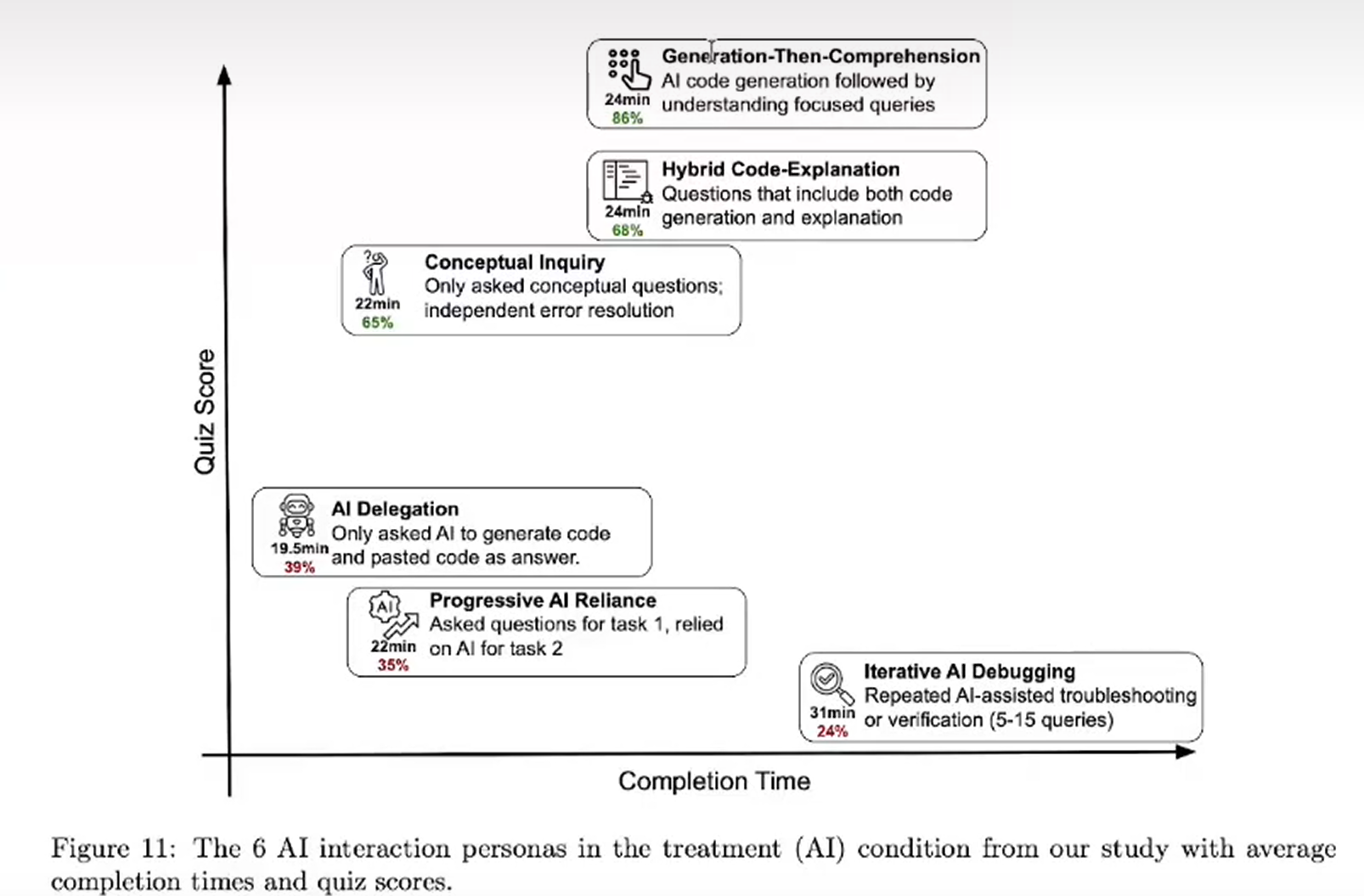
结论就是:生成并学着理解(Generation-Then-Comprehension)AI代码的人是收获最多、理解最深、交付也相对较快的,与之相对的,收获最少,交付最慢的是——Iterative AI Debugging,俗称Vibe Coding
与之前的连接层面和控制面的进展不同,做数据面AI辅助编程的时候,我遇到了不少问题。这时候,我不想进Vibe Coding然后一无所获(甚至也不知道能不能跑通)我主动问了AI一些问题,对照代码逻辑,比较容易将AI的代码调通,比较有代表性的总结如下:
Q:一字节的数据从服务器通过RDMA发往客户端,经历哪些步骤?
A:
- 双方创建QP和CQ,注册MR获取rkey
- 客户端创建RECV WR(包含rbuffer),调用ibv_post_recv将WR推入RQ
- 服务器创建SEND WR(包含元信息),调用ibv_post_send将WR推入SQ
- 服务器和客户端轮询处理SQ、RQ,RDMA内核旁路发送到客户端rbuffer
- 服务器和客户端轮询CQ,调用ibv_poll_cq获取CQE
// 步骤2: 客户端预接收 - rdma_sync.c
static void kvs_rdma_sync_slave_completion(struct ibv_wc *wc, void *arg) {
// 接收完成后重新post recv buffer,保持RQ始终有buffer可用
if (rdma_post_recv(state->conn) != 0) {
LOG_WARN("[RDMA_SYNC] Slave failed to repost receive buffer\n");
}
}
// 步骤3: 服务器创建SEND WR - rdma_sync.c
static int kvs_rdma_sync_send_next_chunk(void) {
size_t remaining = g_master_sync.length - g_master_sync.offset;
size_t chunk_len = remaining > RDMA_BUFFER_SIZE ? RDMA_BUFFER_SIZE : remaining;
// 创建SEND WR并推入SQ
if (rdma_post_send(g_master_sync.conn,
g_master_sync.data + g_master_sync.offset,
chunk_len) != 0) {
LOG_WARN("[RDMA_SYNC] Failed to post RDMA send\n");
return -1;
}
g_master_sync.offset += chunk_len;
g_master_sync.sending = 1;
return 0;
}
// 步骤4-5: 轮询CQ获取完成事件 - rdma_sync.c
static void kvs_rdma_sync_master_completion(struct ibv_wc *wc, void *arg) {
if (wc->status != IBV_WC_SUCCESS) {
LOG_WARN("[RDMA_SYNC] Master completion failed: %s\n",
ibv_wc_status_str(wc->status));
return;
}
if (wc->opcode == IBV_WC_SEND) {
// SEND操作完成
LOG_DEBUG("[RDMA_SYNC] Send completed, offset=%zu\n",
g_master_sync.offset);
} else if (wc->opcode == IBV_WC_RECV) {
// RECV操作完成,收到数据
LOG_INFO("[RDMA_SYNC] Received %u bytes\n", wc->byte_len);
}
}
Q:RDMA连接状态机转移过程是什么?
A:INIT → IDLE → ADDR_RESOLVING → ROUTE_RESOLVING → CONNECTING → ESTABLISHED → DATA_TRANSFER → DISCONNECTED → DEAD
// ADDR_RESOLVING: 解析服务器地址 - rdma_client.c
static int rdma_resolve_addr(struct rdma_cm_id *cm_id,
struct sockaddr *src_addr,
struct sockaddr *dst_addr,
int timeout_ms) {
// 客户端解析服务器IP地址
return rdma_resolve_addr(cm_id, src_addr, dst_addr, timeout_ms);
}
// ROUTE_RESOLVING: 解析路由路径 - rdma_client.c
static int rdma_resolve_route(struct rdma_cm_id *cm_id, int timeout_ms) {
// 解析RDMA路由路径,确定物理路径
return rdma_resolve_route(cm_id, timeout_ms);
}
// CONNECTING: 发起连接请求 - rdma_client.c
static int rdma_connect(struct rdma_cm_id *cm_id,
struct rdma_conn_param *conn_param) {
// 发送连接请求到服务器
return rdma_connect(cm_id, conn_param);
}
// ESTABLISHED: 连接建立完成 - rdma_server.c
static void on_connect_established(struct rdma_cm_id *cm_id) {
conn_manger_t *conn = (conn_manger_t *)cm_id->context;
// 连接已建立,设置完成回调
rdma_set_completion_handler(conn, on_completion, conn);
conn->connected = 1;
// 通知同步模块连接已就绪
kvs_rdma_sync_on_master_connected(conn);
LOG_INFO("[RDMA] Server RDMA connection established\n");
}
Q:Server状态机转移过程是什么?
A:INIT → IDLE → CONNECTING → ESTABLISHED → DATA_TRANSFER → DISCONNECTED → DEAD
// INIT → IDLE: 创建事件通道 - rdma_server.c
int rdma_server_init(const char *ip, int port) {
// 创建RDMA事件通道
g_rdma_server_ec = rdma_create_event_channel();
if (!g_rdma_server_ec) {
LOG_WARN("[RDMA] Failed to create server event channel\n");
return -1;
}
// 进入IDLE状态
g_rdma_server_started = 0;
}
// IDLE → CONNECTING: 绑定地址并监听 - rdma_server.c
int rdma_server_init(const char *ip, int port) {
// 创建监听ID
rdma_create_id(g_rdma_server_ec, &g_rdma_listen_id, NULL, RDMA_PS_TCP);
// 绑定地址
rdma_bind_addr(g_rdma_listen_id, (struct sockaddr *)&addr);
// 开始监听,进入CONNECTING状态
rdma_listen(g_rdma_listen_id, 8);
g_rdma_server_started = 1;
}
// CONNECTING → ESTABLISHED: 接受连接 - rdma_server.c
static void on_connection_request(struct rdma_cm_id *cm_id) {
// 初始化连接
rdma_init_connection(cm_id, on_completion, cm_id->context);
// 预接收buffer
rdma_post_recv(conn);
// 接受连接请求
rdma_accept(cm_id, &conn_param);
// 等待ESTABLISHED事件
}
// ESTABLISHED → DATA_TRANSFER: 开始数据传输 - rdma_server.c
static void on_connect_established(struct rdma_cm_id *cm_id) {
conn->connected = 1;
// 通知同步模块开始数据传输
kvs_rdma_sync_on_master_connected(conn);
// 进入DATA_TRANSFER状态
}
// DATA_TRANSFER: 处理数据传输 - rdma_server.c
static void on_completion(struct ibv_wc *wc, void *arg) {
if (wc->opcode == IBV_WC_RECV) {
// 收到数据,继续接收
LOG_INFO("[RDMA] Server received %u bytes from slave\n", wc->byte_len);
rdma_post_recv(conn); // 重新post,保持接收状态
}
}
// DATA_TRANSFER → DISCONNECTED → DEAD: 断开连接 - rdma_server.c
int rdma_server_poll_events(void) {
switch (event->event) {
case RDMA_CM_EVENT_DISCONNECTED:
LOG_INFO("[RDMA] Server RDMA connection disconnected\n");
rdma_destroy_connection(event->id); // 销毁连接
// 进入DEAD状态
break;
}
}
Q:Master同步状态机转移过程是什么?
A:INIT → IDLE → PREPARED → WAITING_READY → HAS_CREDIT → SENDING → WAITING_CREDIT → COMPLETED → DEAD
// INIT → IDLE → PREPARED: 准备快照数据 - rdma_sync.c
int kvs_rdma_sync_prepare_master(rdma_metadata_t *meta) {
// 重置状态,进入IDLE
kvs_rdma_sync_reset_master();
// 保存RDB快照
kvs_rdb_save();
// 读取RDB文件到内存
g_master_sync.data = kvs_malloc((size_t)st.st_size);
g_master_sync.length = (size_t)st.st_size;
g_master_sync.prepared = 1; // 进入PREPARED状态
meta->length = (uint32_t)g_master_sync.length;
return 0;
}
// PREPARED → WAITING_READY: 等待Slave就绪 - rdma_sync.c
void kvs_rdma_sync_on_master_connected(rdma_conn_t *conn) {
g_master_sync.conn = conn;
g_master_sync.credits = 0; // 初始信用为0
// 进入WAITING_READY状态,等待slave发送READY消息
LOG_INFO("[RDMA_SYNC] Master waiting for slave READY\n");
}
// WAITING_READY → HAS_CREDIT: 收到READY - rdma_sync.c
static void kvs_rdma_sync_master_completion(struct ibv_wc *wc, void *arg) {
if (wc->opcode == IBV_WC_RECV) {
if (strncmp(state->conn->recv_buffer, "READY", 5) == 0) {
state->credits++; // 获得信用,进入HAS_CREDIT状态
LOG_INFO("[RDMA_SYNC] Master received READY, credits=%d\n",
state->credits);
}
}
}
// HAS_CREDIT → SENDING: 发送数据块 - rdma_sync.c
static int kvs_rdma_sync_send_next_chunk(void) {
if (g_master_sync.credits <= 0) return -1; // 必须有信用
g_master_sync.credits--; // 消耗信用
rdma_post_send(g_master_sync.conn, data, chunk_len);
g_master_sync.sending = 1; // 进入SENDING状态
return 0;
}
// SENDING → WAITING_CREDIT: 等待新信用 - rdma_sync.c
static void kvs_rdma_sync_master_completion(struct ibv_wc *wc, void *arg) {
if (wc->opcode == IBV_WC_SEND) {
state->sending = 0;
if (state->offset < state->length && state->credits == 0) {
// 还有数据但无信用,进入WAITING_CREDIT状态
LOG_DEBUG("[RDMA_SYNC] Waiting for NEXT credit\n");
}
}
}
// WAITING_CREDIT → HAS_CREDIT: 收到NEXT信用 - rdma_sync.c
static void kvs_rdma_sync_master_completion(struct ibv_wc *wc, void *arg) {
if (strncmp(state->conn->recv_buffer, "NEXT", 4) == 0) {
state->credits++; // 获得新信用,回到HAS_CREDIT
if (!state->sending && state->prepared) {
kvs_rdma_sync_send_next_chunk(); // 继续发送
}
}
}
// SENDING → COMPLETED: 发送完成 - rdma_sync.c
static void kvs_rdma_sync_master_completion(struct ibv_wc *wc, void *arg) {
if (wc->opcode == IBV_WC_SEND) {
if (state->offset >= state->length) {
LOG_INFO("[RDMA_SYNC] Full sync completed\n");
kvs_rdma_sync_reset_master(); // 进入COMPLETED状态
}
}
}
Q:Slave同步状态机转移过程是什么?
A:INIT → IDLE → ACTIVE → WAITING_DATA → RECEIVING → WRITING → COMPLETED → DEAD
// INIT → IDLE → ACTIVE: 启动Slave接收 - rdma_sync.c
int kvs_rdma_sync_start_slave(rdma_conn_t *conn, const rdma_metadata_t *meta) {
// 重置状态,进入IDLE
kvs_rdma_sync_reset_slave();
g_slave_sync.conn = conn;
g_slave_sync.expected_length = meta->length;
g_slave_sync.active = 1; // 进入ACTIVE状态
// 创建临时文件
snprintf(g_slave_sync.tmp_path, sizeof(g_slave_sync.tmp_path),
"%s.rdma.tmp", g_config.rdb_file);
g_slave_sync.fd = open(g_slave_sync.tmp_path, O_CREAT | O_TRUNC | O_WRONLY, 0644);
// 发送READY通知master
rdma_post_send(conn, "READY", 5);
return 0;
}
// ACTIVE → WAITING_DATA: 等待数据 - rdma_sync.c
int kvs_rdma_sync_start_slave(rdma_conn_t *conn, const rdma_metadata_t *meta) {
// 注册完成回调
rdma_set_completion_handler(conn, kvs_rdma_sync_slave_completion, &g_slave_sync);
// 进入WAITING_DATA状态
LOG_INFO("[RDMA_SYNC] Slave waiting for data chunks\n");
}
// WAITING_DATA → RECEIVING → WRITING: 接收并写入 - rdma_sync.c
static void kvs_rdma_sync_slave_completion(struct ibv_wc *wc, void *arg) {
// 收到数据,进入RECEIVING状态
if (!state->active) return;
// 写入文件,进入WRITING状态
written = write(state->fd, state->conn->recv_buffer, wc->byte_len);
state->received_length += wc->byte_len;
LOG_INFO("[RDMA_SYNC] Slave received %u/%u bytes\n",
state->received_length, state->expected_length);
}
// WRITING → WAITING_DATA: 请求更多数据 - rdma_sync.c
static void kvs_rdma_sync_slave_completion(struct ibv_wc *wc, void *arg) {
if (state->received_length < state->expected_length) {
// 重新post接收buffer
rdma_post_recv(state->conn);
// 发送NEXT请求更多数据,回到WAITING_DATA状态
rdma_post_send(state->conn, "NEXT", 4);
}
}
// WRITING → COMPLETED: 接收完成 - rdma_sync.c
static void kvs_rdma_sync_slave_completion(struct ibv_wc *wc, void *arg) {
if (state->received_length == state->expected_length) {
// 所有数据接收完成,进入COMPLETED状态
kvs_rdma_sync_finalize_slave();
}
}
// COMPLETED → DEAD: 完成同步 - rdma_sync.c
static int kvs_rdma_sync_finalize_slave(void) {
// 关闭临时文件
close(g_slave_sync.fd);
// 原子替换RDB文件
rename(g_slave_sync.tmp_path, g_config.rdb_file);
// 加载RDB到哈希表
kvs_hash_destroy(&global_hash);
kvs_hash_create(&global_hash);
kvs_hash_load_rdb(&global_hash, g_config.rdb_file);
// 重置状态,进入DEAD
kvs_rdma_sync_reset_slave();
return 0;
}
四、尾声
方法总结
核心:好的业务理解 → 精确的prompt → 高质量的AI代码
- 分阶段推进:连接建立 → 控制面 → 数据面,每阶段测试后提交
- 技术选型由人决定:AI负责实现,不负责架构决策
- 主动学习AI代码:通过Q&A理解状态机转移,避免Vibe Coding陷阱

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)