AI大模型开发-实战精讲:从零构建 RFM 会员价值模型
前言
在你通往 AI 大模型开发的道路上,除了掌握复杂的神经网络算法,扎实的数据处理能力才是地基。大模型的训练本质上是海量数据的清洗、特征工程与价值挖掘。
今天我们要做的这个RFM 会员价值打分项目,虽然不涉及深度学习,但它完整演练了数据分析的核心流程:数据加载 -> 清洗 -> 特征提取 -> 量化评分 -> 可视化决策。这是每一位 AI 工程师在处理业务数据时必须具备的“基本功”。
本文将细致地,一步一步地拆解所有操作,不仅告诉你代码怎么写,更告诉你为什么要这么写,以及背后的业务逻辑是什么。
文章目录
🛠️ 第一步:环境准备与工具导入
任何数据项目的起点,都是准备好我们的“工具箱”。我们需要三个核心库:
numpy:数值计算的基础,处理数组高效。pandas:绝对主角。用于读取 Excel、清洗数据、分组聚合(GroupBy)。matplotlib:绘图库,将枯燥的数据变成直观的图表。
1.1 代码实操与详解
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
# 【关键设置】解决中文乱码
# Matplotlib 默认不支持中文,直接画图会显示方框。
# 这行代码指定使用 'SimHei' (黑体) 来渲染中文字符。
plt.rcParams['font.sans-serif'] = ['SimHei']
# 【额外提示】
# 读取 Excel 文件需要 openpyxl 引擎支持。
# 如果运行报错 "Missing optional dependency 'openpyxl'",
# 请在终端执行:pip install openpyxl
📝 操作要点:
- 养成好习惯,在代码开头就处理好编码和字体问题,否则后续画图时出现乱码会非常影响调试效率。
- 导入
os模块是为了后续能智能地处理文件路径,避免硬编码路径导致代码换台电脑就无法运行。
📂 第二步:智能加载数据
数据通常不会刚好放在脚本同级目录。为了代码的可移植性,我们需要动态获取当前脚本的位置,并据此拼接数据文件的路径。
2.1 代码实操与详解
# 1. 获取当前脚本所在的绝对目录
# __file__ 代表当前文件的路径,abspath 转为绝对路径,dirname 获取文件夹路径
script_dir = os.path.dirname(os.path.abspath(__file__))
# 2. 拼接数据文件的路径
# 假设数据文件位于上一级目录的 Data 文件夹下:../Data/sales_test.xlsx
data_path = os.path.join(script_dir, "../Data/sales_test.xlsx")
# 3. 读取 Excel 数据
# index_col='USERID':这是一个关键参数。
# 它直接将 'USERID' 列设为 DataFrame 的索引(Index)。
# 这样做的好处是,后续我们可以直接按用户 ID 进行分组操作,无需额外指定列名。
df = pd.read_excel(data_path, index_col='USERID')
# 4. 初步检查数据
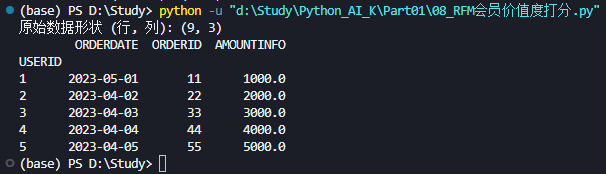
print(f"原始数据形状 (行, 列): {df.shape}")
# print(df.head()) # 实际开发中建议取消注释,查看前 5 行数据长什么样
📝 操作要点:
- 目录:
- 检查数据:
- 路径拼接:使用
os.path.join而不是手动写/或\,可以兼容 Windows 和 Mac/Linux 系统。 - 索引设定:
index_col参数非常重要。将用户 ID 设为索引后,数据天然就是“以用户为核心”的结构,这对后续的groupby操作至关重要。
🧹 第三步:数据预处理(清洗)
真实世界的数据往往是“脏”的:可能有空行、缺失值。如果不处理,计算时会报错或导致结果偏差。
3.1 代码实操与详解
# dropna(how='all'):只有当一行中【所有】列都为空时,才删除该行。
# 区别:
# how='any':只要有一个数据缺失就删除(太暴力,可能误删有效数据)。
# how='all':整行都没数据才删(比较安全,仅去除无效空行)。
sale_data = df.dropna(how='all')
print(f"清洗后数据形状: {sale_data.shape}")
print(f"列名信息: {sale_data.columns}")
📝 操作要点:
- 清洗后并输出列名信息:

- 对比变化:每次清洗后打印
shape,确认数据量变化是否符合预期。如果行数锐减,说明原数据质量很差,需要进一步排查。 - 策略选择:对于部分缺失的数据(例如有订单号但缺金额),在实际项目中可能需要填充平均值或删除该特定列,这里我们仅做最基础的全空行清理。
🧠 第四步:核心分析 - 计算 R、F、M 指标
这是项目的灵魂。我们需要把原始的“流水账”转换成每个用户的“三维画像”。
- R (Recency):最近一次消费时间(越近越好——来得多)
- F (Frequency):消费频率(越高越好——花得频繁)
- M (Monetary):消费金额(越高越好——花得多)
4.1 代码实操与详解
# groupby(sale_data.index):按用户 ID(索引)进行分组
# 因为我们在读取时设了 index_col='USERID'(第29行),所以这里直接按索引分组即可
# 1. 计算 R (Recency):找到每个用户最近一次购买时间
# 对 'ORDERDATE' 列取最大值 (max)。
# 注意:日期越大,代表时间越新(例如 2023-01-01 比 2022-01-01 大,也更近)。
R_data = sale_data.groupby(sale_data.index)['ORDERDATE'].max()
# 2. 计算 F (Frequency):统计每个用户下了多少单
# 对 'ORDERID' 列进行计数 (count)
F_data = sale_data.groupby(sale_data.index)['ORDERID'].count()
# 3. 计算 M (Monetary):统计每个用户花了多少钱
# 对 'AMOUNTINFO' 列进行求和 (sum)
M_data = sale_data.groupby(sale_data.index)['AMOUNTINFO'].sum()
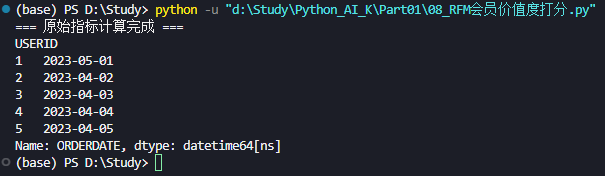
print("=== 原始指标计算完成 ===")
# print(R_data.head()) # 查看前几个用户的最近购买时间
📝 操作要点:
- 查看前几个用户的最近购买时间:
- GroupBy 逻辑:记住口诀**“先分组,后聚合”**。Pandas 会自动把同一个用户的所有订单归为一组,然后分别执行 count、sum、max 操作。
- R 的计算细节:这里取
max()是因为日期对象本身可比大小,最大的日期即代表“最近”。
📊 第五步:指标打分(离散化)
原始的 R/F/M 数值差异巨大(比如金额有 100 元也有 10000 元,天数有 1 天也有 300 天),直接相加没有意义。我们需要将它们标准化为 1-5 分。
5.1 核心工具:pd.cut
pd.cut 可以将连续数值切成几个区间(桶),并打上标签。
5.2 代码实操与详解
# 1. F 和 M 的打分:直接分为 5 等份,分数 1-5
# labels=[1, 2, 3, 4, 5] 表示:
# 数值最小的区间给 1 分,数值最大的区间给 5 分。
# 对于 F 和 M,数值越大越好,所以逻辑是匹配的。
F_score = pd.cut(F_data, 5, labels=[1, 2, 3, 4, 5])
M_score = pd.cut(M_data, 5, labels=[1, 2, 3, 4, 5])
# 2. R 的特殊处理 (关键逻辑修正)
# R 代表“最近一次时间”,业务逻辑是:时间越近(天数差越小),分数应该越高。
# 但 pd.cut 默认是按数值从小到大分箱的。
# 如果我们计算的是“距离基准日的天数”(R_days):
# - 天数小 (刚买过) -> 落入第 1 个箱子
# - 天数大 (很久没买) -> 落入第 5 个箱子
# 如果直接用 labels=[1, 2, 3, 4, 5],会导致“很久没买”的人得 5 分,“刚买过”的人得 1 分,这与业务逻辑相反!
# 设定一个基准时间(通常是数据集中最新的日期或当前日期)
base_date = pd.to_datetime("2022-05-14")
# 计算相差天数
R_days = (R_data - base_date).dt.days
# 【修正方案】:
# 为了让“天数小”的人得“高分”,我们需要将标签顺序倒过来:
# 第 1 个箱子 (天数最少) -> 给 5 分
# 第 5 个箱子 (天数最多) -> 给 1 分
R_score = pd.cut(R_days, 5, labels=[5, 4, 3, 2, 1])
print("=== 打分完成 ===")
⚠️ 重点逻辑解析:
很多初学者容易在这里犯错。请务必理解:
- F 和 M:数值越大越好 -> 分箱标签
[1, 2, 3, 4, 5](从小到大对应低分到高分)。 - R (基于天数):数值越小越好 -> 分箱标签
[5, 4, 3, 2, 1](从小到大对应高分到低分)。 - 如果不做这个反转,最终的 RFM 模型将完全失效,甚至得出“流失用户是高价值用户”的错误结论。
🔗 第六步:合并数据与加权计算
现在我们有三个独立的 Series(R_score, F_score, M_score),需要将它们拼成一张宽表,并根据业务重要性计算总分。
6.1 代码实操与详解
# 1. 准备数据列表
rfm_list = [R_score, F_score, M_score]
rfm_cols = ['r_score', 'f_score', 'm_score']
# 2. 转换与合并
# np.array(rfm_list) 会创建一个 (3, 用户数) 的数组
# .transpose() 将其转置为 (用户数, 3),符合 DataFrame 的行列表结构
# 最后放入 DataFrame,指定列名和索引 (保持用户 ID 不变)
rfm_df = pd.DataFrame(
np.array(rfm_list).transpose(),
dtype=np.int32,
columns=rfm_cols,
index=R_data.index
)
# 3. 加权得分
# 业务场景模拟:
# 老板认为“消费金额 (M)"最重要,权重给 60%;
# “最近购买时间 (R)"和“频率 (F)"各占 20%。
# 权重可以根据实际业务目标调整(如拉新期可能更看重 F)。
weights = {'r': 0.2, 'f': 0.2, 'm': 0.6}
rfm_df['rfm_w_score'] = (
rfm_df['r_score'] * weights['r'] +
rfm_df['f_score'] * weights['f'] +
rfm_df['m_score'] * weights['m']
)
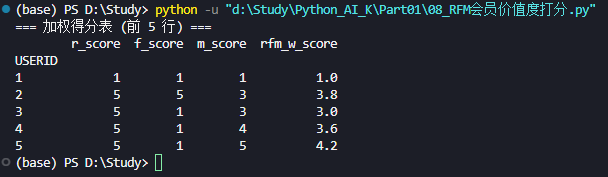
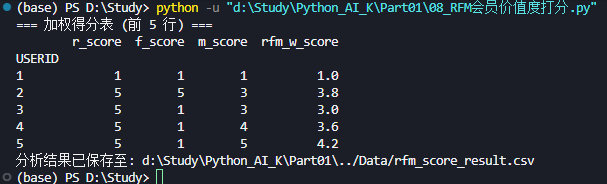
print("=== 加权得分表 (前 5 行) ===")
print(rfm_df.head())
📝 操作要点:
- 查看加权得分表:
- 数据对齐:Pandas 在创建 DataFrame 时会自动根据
index对齐数据,确保每个用户的 R、F、M 分数不会错位。 - 权重的意义:这是将数学模型转化为业务决策的关键一步。不同的权重组合代表了不同的运营战略。
🎨 第七步:用户分层与可视化
有了总分,我们怎么划分等级?通常使用**分箱(Binning)**技术,将连续的分數划分为“高、中、低”三个层级。
7.1 定义规则与绘图
# 1. 用户分层规则
# bins=[0, 2, 3, 5] 表示:
# (0, 2] 分 -> '低价值'
# (2, 3] 分 -> '中价值'
# (3, 5] 分 -> '高价值'
bins = [0, 2, 3, 5]
labels = ['低价值', '中价值', '高价值']
# 应用分层
rfm_df['客户分类'] = pd.cut(rfm_df['rfm_w_score'], bins=bins, labels=labels)
# 2. 可视化展示
plt.figure(figsize=(8, 6)) # 设置画布大小,单位英寸
# 统计各等级人数
# value_counts() 默认按数量降序排列
counts = rfm_df['客户分类'].value_counts()
# 为了图表顺序符合逻辑(低->中->高),我们手动重排索引
# fill_value=0 防止某个类别没人导致报错
counts = counts.reindex(['低价值', '中价值', '高价值'], fill_value=0)
# 绘制柱状图
counts.plot(
kind='bar',
color=['#FF6B6B', '#4ECDC4', '#FFE66D'], # 自定义颜色:红、绿、黄
edgecolor='black', # 柱子边框黑色
width=0.6
)
plt.title('RFM 客户价值分群统计', fontsize=16, pad=20)
plt.xlabel('会员等级', fontsize=12)
plt.ylabel('会员数量 (人)', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7) # 只显示 Y 轴虚线网格
# 【进阶技巧】在柱子上方显示具体数值
for i, v in enumerate(counts):
plt.text(i, v + 0.1, str(int(v)), ha='center', fontsize=12, fontweight='bold')
plt.tight_layout() # 自动调整布局,防止标签被截断
plt.show()
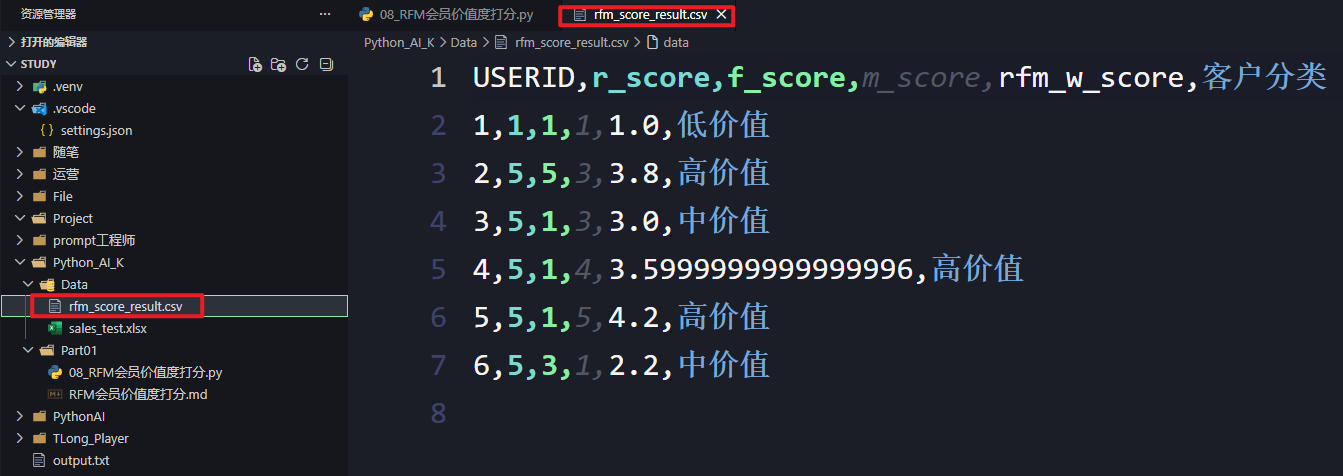
# 3. 保存结果到本地
# encoding='utf-8-sig' 是关键,它能防止 Excel 打开 CSV 时中文乱码
output_path = os.path.join(script_dir, "../Data/rfm_score_result.csv")
rfm_df.to_csv(output_path, encoding='utf-8-sig')
print(f"分析结果已保存至: {output_path}")
📝 操作要点:
- 分析结果:
- 同时,也可以把结果保存到本地:
- 重排索引:
value_counts默认按数量排序,这可能导致图表中“高价值”出现在最左边,“低价值”在最右边,不符合阅读习惯。使用reindex强制按业务逻辑排序。 - 编码格式:保存 CSV 给非技术人员(如运营同事)查看时,务必使用
utf-8-sig,这是 Excel 友好型编码。 - 图表美化:加上数值标签、清晰的标题和网格线,能让报告看起来更专业。
💡 总结与进阶思考
恭喜你!你已经独立完成了一个完整的数据闭环项目:
- 数据获取 (Load)
- 数据清洗 (Clean)
- 特征工程 (Feature Engineering - 计算 RFM)
- 建模评分 (Scoring)
- 业务洞察 (Visualization & Output)
这个项目虽然代码量不大,但它涵盖了 AI 数据工程中最核心的思维模式:将模糊的业务问题(谁是好客户?)转化为可计算的数学指标(RFM 分数),再通过数据驱动决策。
🚀 进阶挑战(留到下一篇博客讲)
如果你想进一步提升,可以尝试以下优化:
- 动态阈值:目前的
bins=[0, 2, 3, 5]是写死的。如果所有用户分数都很高怎么办?尝试改用百分位数(如前 20% 定义为高价值)来动态划分阈值。 - 精细化人群策略:
- 不要只看总分,尝试结合 R、F、M 的具体组合。
- 例如:R 低 F 低 M 高(新用户但买了一大单)vs R 高 F 高 M 高(老土豪最近不来了)。针对这两类人,你的营销策略应该完全不同。你能写出代码自动识别这 8 类细分人群吗?
- 自动化报告:尝试将绘图和文字分析整合成一个 HTML 报告,定时自动发送给运营团队。
希望这篇教程能帮你打通从“代码”到“业务”的任督二脉。在 AI 大模型的浪潮中,这种扎实的数据处理能力将是你最宝贵的财富。继续加油!
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
# 【关键设置】解决中文乱码
# Matplotlib 默认不支持中文,直接画图会显示方框。
# 这行代码指定使用 'SimHei' (黑体) 来渲染中文字符。
plt.rcParams['font.sans-serif'] = ['SimHei']
# 【额外提示】
# 读取 Excel 文件需要 openpyxl 引擎支持。
# 如果运行报错 "Missing optional dependency 'openpyxl'",
# 请在终端执行:pip install openpyxl
# 1. 获取当前脚本所在的绝对目录
# __file__ 代表当前文件的路径,abspath 转为绝对路径,dirname 获取文件夹路径
script_dir = os.path.dirname(os.path.abspath(__file__))
# 2. 拼接数据文件的路径
# 假设数据文件位于上一级目录的 Data 文件夹下:../Data/sales_test.xlsx
data_path = os.path.join(script_dir, "../Data/sales_test.xlsx")
# 3. 读取 Excel 数据
# index_col='USERID':这是一个关键参数。
# 它直接将 'USERID' 列设为 DataFrame 的索引(Index)。
# 这样做的好处是,后续我们可以直接按用户 ID 进行分组操作,无需额外指定列名。
df = pd.read_excel(data_path, index_col='USERID')
# 4. 初步检查数据
# print(f"原始数据形状 (行, 列): {df.shape}")
# print(df.head()) # 实际开发中建议取消注释,查看前 5 行数据长什么样
# dropna(how='all'):只有当一行中【所有】列都为空时,才删除该行。
# 区别:
# how='any':只要有一个数据缺失就删除(太暴力,可能误删有效数据)。
# how='all':整行都没数据才删(比较安全,仅去除无效空行)。
sale_data = df.dropna(how='all')
# print(f"清洗后数据形状: {sale_data.shape}")
# print(f"列名信息: {sale_data.columns}")
# groupby(sale_data.index):按用户 ID(索引)进行分组
# 因为我们在读取时设了 index_col='USERID'(第29行),所以这里直接按索引分组即可
# 1. 计算 R (Recency):找到每个用户最近一次购买时间
# 对 'ORDERDATE' 列取最大值 (max)。
# 注意:日期越大,代表时间越新(例如 2023-01-01 比 2022-01-01 大,也更近)。
R_data = sale_data.groupby(sale_data.index)['ORDERDATE'].max()
# 2. 计算 F (Frequency):统计每个用户下了多少单
# 对 'ORDERID' 列进行计数 (count)
F_data = sale_data.groupby(sale_data.index)['ORDERID'].count()
# 3. 计算 M (Monetary):统计每个用户花了多少钱
# 对 'AMOUNTINFO' 列进行求和 (sum)
M_data = sale_data.groupby(sale_data.index)['AMOUNTINFO'].sum()
# print("=== 原始指标计算完成 ===")
# print(R_data.head()) # 查看前几个用户的最近购买时间
# 1. F 和 M 的打分:直接分为 5 等份,分数 1-5
# labels=[1, 2, 3, 4, 5] 表示:
# 数值最小的区间给 1 分,数值最大的区间给 5 分。
# 对于 F 和 M,数值越大越好,所以逻辑是匹配的。
F_score = pd.cut(F_data, 5, labels=[1, 2, 3, 4, 5])
M_score = pd.cut(M_data, 5, labels=[1, 2, 3, 4, 5])
# 2. R 的特殊处理 (关键逻辑修正)
# R 代表“最近一次时间”,业务逻辑是:时间越近(天数差越小),分数应该越高。
# 但 pd.cut 默认是按数值从小到大分箱的。
# 如果我们计算的是“距离基准日的天数”(R_days):
# - 天数小 (刚买过) -> 落入第 1 个箱子
# - 天数大 (很久没买) -> 落入第 5 个箱子
# 如果直接用 labels=[1, 2, 3, 4, 5],会导致“很久没买”的人得 5 分,“刚买过”的人得 1 分,这与业务逻辑相反!
# 设定一个基准时间(通常是数据集中最新的日期或当前日期)
base_date = pd.to_datetime("2022-05-14")
# 计算相差天数
R_days = (R_data - base_date).dt.days
# 【修正方案】:
# 为了让“天数小”的人得“高分”,我们需要将标签顺序倒过来:
# 第 1 个箱子 (天数最少) -> 给 5 分
# 第 5 个箱子 (天数最多) -> 给 1 分
R_score = pd.cut(R_days, 5, labels=[5, 4, 3, 2, 1])
# print("=== 打分完成 ===")
# 1. 准备数据列表
rfm_list = [R_score, F_score, M_score]
rfm_cols = ['r_score', 'f_score', 'm_score']
# 2. 转换与合并
# np.array(rfm_list) 会创建一个 (3, 用户数) 的数组
# .transpose() 将其转置为 (用户数, 3),符合 DataFrame 的行列表结构
# 最后放入 DataFrame,指定列名和索引 (保持用户 ID 不变)
rfm_df = pd.DataFrame(
np.array(rfm_list).transpose(),
dtype=np.int32,
columns=rfm_cols,
index=R_data.index
)
# 3. 加权得分
# 业务场景模拟:
# 老板认为“消费金额 (M)"最重要,权重给 60%;
# “最近购买时间 (R)"和“频率 (F)"各占 20%。
# 权重可以根据实际业务目标调整(如拉新期可能更看重 F)。
weights = {'r': 0.2, 'f': 0.2, 'm': 0.6}
rfm_df['rfm_w_score'] = (
rfm_df['r_score'] * weights['r'] +
rfm_df['f_score'] * weights['f'] +
rfm_df['m_score'] * weights['m']
)
print("=== 加权得分表 (前 5 行) ===")
print(rfm_df.head())
# 1. 用户分层规则
# bins=[0, 2, 3, 5] 表示:
# (0, 2] 分 -> '低价值'
# (2, 3] 分 -> '中价值'
# (3, 5] 分 -> '高价值'
bins = [0, 2, 3, 5]
labels = ['低价值', '中价值', '高价值']
# 应用分层
rfm_df['客户分类'] = pd.cut(rfm_df['rfm_w_score'], bins=bins, labels=labels)
# 2. 可视化展示
plt.figure(figsize=(8, 6)) # 设置画布大小,单位英寸
# 统计各等级人数
# value_counts() 默认按数量降序排列
counts = rfm_df['客户分类'].value_counts()
# 为了图表顺序符合逻辑(低->中->高),我们手动重排索引
# fill_value=0 防止某个类别没人导致报错
counts = counts.reindex(['低价值', '中价值', '高价值'], fill_value=0)
# 绘制柱状图
counts.plot(
kind='bar',
color=['#FF6B6B', '#4ECDC4', '#FFE66D'], # 自定义颜色:红、绿、黄
edgecolor='black', # 柱子边框黑色
width=0.6
)
plt.title('RFM 客户价值分群统计', fontsize=16, pad=20)
plt.xlabel('会员等级', fontsize=12)
plt.ylabel('会员数量 (人)', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7) # 只显示 Y 轴虚线网格
# 【进阶技巧】在柱子上方显示具体数值
for i, v in enumerate(counts):
plt.text(i, v + 0.1, str(int(v)), ha='center', fontsize=12, fontweight='bold')
plt.tight_layout() # 自动调整布局,防止标签被截断
plt.show()
# 3. 保存结果到本地
# encoding='utf-8-sig' 是关键,它能防止 Excel 打开 CSV 时中文乱码
output_path = os.path.join(script_dir, "../Data/rfm_score_result.csv")
rfm_df.to_csv(output_path, encoding='utf-8-sig')
print(f"分析结果已保存至: {output_path}")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)