yolov8手势识别——detetction篇
·
训练代码(很简单):
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov8-starnet1-s.yaml')
# model = model.scales('s') # 显式切换到s规模
results = model.train(
data='./data.yaml',
epochs=600,
patience=500,
batch=128,
imgsz=320,
degrees=30,
optimizer='SGD',
mixup=0.2,
)
"""
yolov8n-starnet
nohup python det_train_starnet1.py > ./train_logs/det_train_starnet1.log 2>&1 &
"""
names:
0: hand
path: /home/sss/shoushi/0107data2
train: images/train
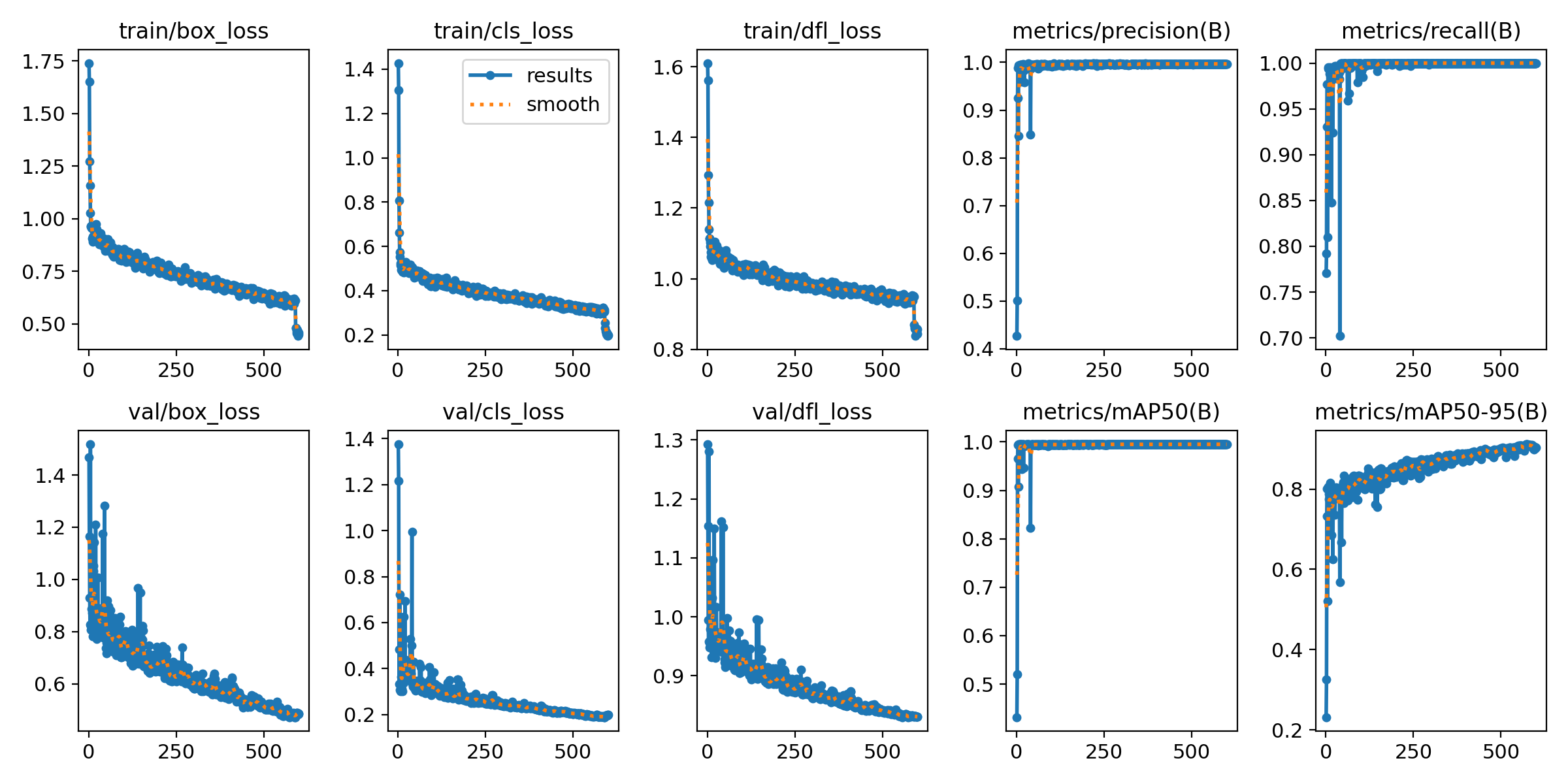
val: images/train训练结果在runs/train中
效果图:

接下来就是环境配置啦:
一、环境准备 🛠️
- Python 版本:推荐
Python 3.8 ~ 3.11,该版本区间与 YOLOv8、PyTorch 兼容性最佳。 - 虚拟环境(强烈推荐):
- 用
venv创建:python -m venv yolov8_hand # 激活环境 # Windows: yolov8_hand\Scripts\activate # Linux/Mac: source yolov8_hand/bin/activate - 用
conda创建:conda create -n yolov8_hand python=3.10 conda activate yolov8_hand
- 用
- GPU 加速(可选但必选):需提前安装 NVIDIA 驱动 + 对应版本的 CUDA Toolkit,否则只能用 CPU 训练(速度极慢)。
二、核心 pip 安装指令 📦
先安装 PyTorch(根据你的 CUDA 版本选择),再安装 YOLOv8 依赖:
# 1. 安装PyTorch(以CUDA 11.8为例,其他版本请查PyTorch官网)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 2. 安装YOLOv8官方库(包含所有训练/推理依赖)
pip install ultralytics
# 3. (可选)补装常用工具库(若运行时报缺库)
pip install opencv-python pyyaml matplotlib pillow tensorboard
若仅用 CPU 训练,可直接执行
pip install ultralytics,PyTorch 会自动安装 CPU 版本。
三、训练与配置注意事项 💡
1. 数据配置(data.yaml)
- 路径规范:
path必须是数据集根目录的绝对路径 / 相对路径,避免中文、空格或特殊字符。train/val需指向对应图像文件夹(示例中val误写为images/train,实际应单独划分验证集,建议比例 8:2)。
- 类别对齐:
names必须与数据集标注类别完全一致,示例中0: hand表示仅 1 类目标。yaml
names: 0: hand path: /home/sss/shoushi/0107data2 # 数据集根目录 train: images/train # 训练集路径(相对于path) val: images/val # 验证集路径(建议与训练集分开)
2. 模型配置(yolov8-starnet1-s.yaml)
- 若使用自定义 Starnet 结构,需确保该 yaml 文件与训练脚本同目录,或填写完整路径。
- 若仅用官方 YOLOv8s 模型,可直接替换为
yolov8s.pt(自动下载预训练权重)或yolov8s.yaml。
3. 训练参数调优
batch=128:若 GPU 显存≤16G,建议降至32/64,避免OOM(显存溢出)。epochs=600、patience=500:patience是早停阈值,若验证集损失 500 轮不下降则停止训练;小数据集可适当调小(如patience=100)。imgsz=320:手势识别任务 320×320 足够,若需更高精度可调至 640,但显存占用会翻倍。- 数据增强:
degrees=30(随机旋转 ±30°)、mixup=0.2(混合增强),可提升泛化能力;数据集过小时可适度增强。 optimizer='SGD':也可尝试Adam/AdamW,SGD 在小数据集上更稳定,Adam 收敛更快。
4. 后台运行与日志
- 指令解析:
nohup python det_train_starnet1.py > ./train_logs/det_train_starnet1.log 2>&1 &nohup:后台运行,断开 SSH 后仍继续训练。> ./train_logs/...log:将标准输出重定向到日志文件。2>&1:将错误输出也写入日志(方便排查报错)。&:放到后台执行。
- 注意:需先创建日志目录,否则会报错:
mkdir -p train_logs。
5. 训练结果与排查
- 结果路径:训练日志、权重文件、可视化结果均保存在
runs/train/目录下,weights/best.pt为最优模型。 - 常见问题:
- 显存 OOM:降低
batch、imgsz,或在model.train()中添加gradient_checkpointing=True。 - 验证集精度低:检查数据集划分是否合理、类别标注是否正确,或增加数据增强、延长训练轮数。
- 路径错误:确保所有路径(数据集、模型 yaml、日志目录)均存在且权限正常。
- 显存 OOM:降低
四、额外建议 ✨
- 数据集划分:务必将数据集按
train/val严格划分(如 8:2),避免用训练集做验证,否则会高估模型性能。 - 预训练权重:首次训练时加载 YOLOv8s 预训练权重(
model = YOLO('yolov8s.pt')),可加速收敛并提升精度。 - 训练监控:用
tensorboard --logdir runs/train启动 TensorBoard,实时查看损失、精度曲线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)