NVQLink 、NVLink 和 NVSwitch 通信协议
1. 概述 NVLink 和 NVSwitch 通信协议
深入、系统地解析一下 NVLink 和 NVSwitch 的详细通信协议。这是一个从上到下、从硬件到软件的完整技术栈。
为了帮助你更直观地理解这个庞大体系的层次结构和核心组件,我们可以把整个协议栈看成一座由底层物理实现到顶层软件管理的 "技术大厦":
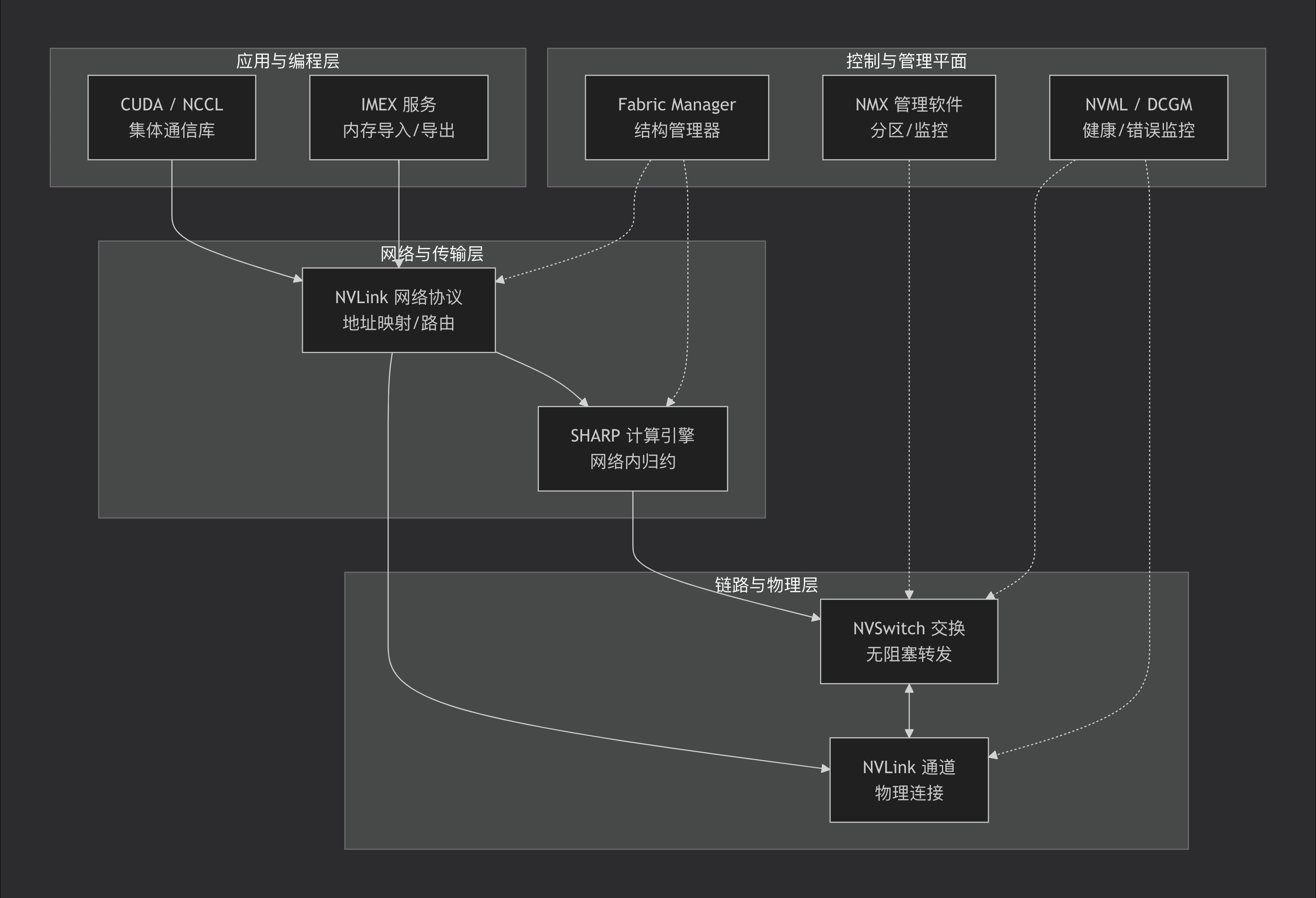
下面,我们将从基础概念开始,层层递进,详细拆解这张图中的每个部分。
1.1. 基础概念与设计哲学
在深入细节前,理解其设计初衷至关重要。NVLink 和 NVSwitch 不是简单的更快的PCIe,而是一个为了解决特定问题而生的全栈式协同设计系统。
1.2. 协议栈分层详解
1. 物理层与链路层 (Physical & Link Layer) - 极速的物理通道
这是整个协议栈的基石,负责在两个端点之间建立最基础的比特传输通道。
-
物理信号 (PHY):从第一代NVLink的NRZ信号,发展到最新的50 Gbaud PAM4信令(第四代NVLink开始),每个差分对的带宽达到100 Gbps-7。第六代NVLink为每个GPU提供了高达3.6 TB/s的惊人双向带宽,是PCIe Gen6的14倍以上-1。
-
链路构成 (Link):一条NVLink链路由多个差分信号对(通道)组成。例如,第一代NVLink的每条链路包含8对差分线,提供40GB/s的双向带宽-5。随着代际演进,GPU支持的链路数也大幅增加,从Pascal的4条发展到Blackwell的18条,Rubin平台更是达到了36条-1-3。
-
链路管理:链路的状态由硬件和固件管理,包括激活(Active)、休眠(Sleep)、非激活(Inactive)等,这可以通过NVML(NVIDIA Management Library)API进行查询和监控-2-6。在现代系统中,自主链路初始化(ALI)允许链路在硬件层面自动训练,无需软件干预-6。
-
NVSwitch:无阻塞的交换核心:NVSwitch芯片本身是一个巨大的、高带宽的交叉开关(Crossbar)。例如,第三代NVSwitch在64个端口上提供3.2 TB/s的全双工带宽,允许任意接入的GPU之间以线速进行通信,无需任何中间GPU跳转-3-7。
2. 网络层与传输层 (Network & Transport Layer) - 地址直通与计算内嵌
这一层是NVLink协议的灵魂,它将传统的网络概念与GPU的存储和计算特性深度融合。
-
基于物理地址的路由:NVLink通信的核心是使用物理地址。当数据需要传输时,发送端直接使用目标GPU内存的物理地址。NVSwitch负责维护复杂的路由表,确保数据包能根据物理地址快速准确地送达目的地-3。这要求整个结构(Fabric)中的每个GPU内存都能被唯一寻址。
-
NVLink网络(扩展到多节点):从Hopper架构开始,NVLink通过NVSwitch被扩展到服务器之间,形成了真正的NVLink网络-7。这引入了一套新的NVLink网络地址和协议,允许跨服务器的GPU直接通信-7。
-
网络内计算(SHARP技术):这是NVLink协议最具革命性的创新。NVSwitch内部集成了SHARP(可扩展分层聚合和归约协议)引擎,包含专用的SHARP控制器和算术逻辑单元(ALU)-7。其工作原理如下:
-
传统方式:执行AllReduce操作需要
2N-2步(N为GPU数量),数据在GPU间反复传输和计算。 -
SHARP方式:GPU只需将数据发送给NVSwitch,交换机内部的ALU直接完成归约计算(求和、最大值等),然后将最终结果返回给所有GPU。这能将操作步骤减少到仅 2步,极大地加速了集体通信-7。
-
3. 应用与编程层 (Application & Programming Layer) - 无缝的软件集成
对于程序员来说,NVLink的复杂性被巧妙地隐藏,通过标准的API和库来使用。
-
CUDA和NCCL的深度集成:开发者几乎不需要直接操作NVLink。NVIDIA的CUDA编程模型和NVIDIA集体通信库(NCCL) 自动利用了底层的NVLink连接。NCCL实现了丰富的多GPU和多节点集合基元(如AllReduce),并能根据拓扑结构选择最佳通信路径,自动利用NVSwitch的多播和SHARP能力进行加速-7。
-
内存共享与导入/导出服务(IMEX):在多节点NVLink网络中,IMEX服务是关键。它允许一个CUDA进程将自己分配的GPU内存“导出”为全局可访问的,另一个节点上的CUDA进程则可以“导入”这块内存,获得直接访问权限。这建立了从虚拟地址(VA)到物理地址(PA)再到结构地址(FA)的完整映射,实现了真正的跨节点内存共享-8。
4. 控制与管理平面 (Control & Management Plane) - 整个结构的“大脑”
如此复杂的结构必须有一个强大的控制平面来管理和监控,确保其高效、稳定地运行。
-
Fabric Manager (FM):这是NVSwitch系统管理的核心软件。它是一个特权进程(守护进程),负责-6:
-
配置路由:为整个NVLink结构计算并配置NVSwitch端口之间的路由表。
-
协调初始化:与GPU驱动协调,完成GPU在结构中的注册和NVLink链路的训练。
-
监控健康状态:持续监控结构中的NVLink和NVSwitch错误,并上报。
-
分区管理:支持将物理结构划分为多个逻辑分区(Partition),实现多租户隔离-8。
-
-
NVLink管理软件 (NMX):针对像GB200 NVL72这样的大型系统,NMX提供了更高级的管理功能,包括集中式监控(NMX-Manager)、遥测数据收集(NMX-Telemetry)和控制器(NMX-Controller),可以通过命令行(NVOS CLI)或API对NVLink分区进行创建、删除和配置-8。
-
监控接口 (NVML/DCGM):NVML(如
nvmlDeviceGetNvLinkState,nvmlDeviceGetNvLinkErrorCounter)和DCGM(数据中心GPU管理器)提供了丰富的API和命令行工具(如nvidia-smi),供系统管理员和运维软件查询NVLink链路的状态(Active/Inactive)、带宽、错误计数器(如误码率BER)以及GPU在结构中的注册状态-2-6。例如,可以通过nvidia-smi -q命令查看GPU的Fabric状态是否为 "Completed" 和 "Success"-6。
1.3. 总结:一张完整的协议栈视图
将以上所有层次综合起来,我们可以得到一张完整的NVLink/NVSwitch通信协议栈视图。这张图清晰地展示了从最底层的物理连接到最顶层的应用,以及贯穿始终的控制平面,是如何共同构成一个强大、高效的系统的。
NVLink/NVSwitch协议栈本质上是一个为AI和高性能计算(HPC)工作负载量身定制的、全栈式协同设计的、高性能互联系统。它通过简化协议、地址直通、网络内计算和强大的软件控制,将成千上万的GPU凝聚成一个强大的计算整体,是NVIDIA构建AI超级计算机的核心技术支柱。
这个协议栈的细节非常丰富,你对其中哪个部分(例如SHARP的内部实现、Fabric Manager的详细工作机制,或是NVLink-C2C的板级互联)更感兴趣?我们可以继续深入探讨。
2. 详细设计或者猜想构建:NVLink网络地址和协议
这是一个非常有深度的挑战。基于现有的公开资料、逆向工程线索以及NVIDIA的整体架构逻辑,我将尝试为你构建一个合理的、详细的NVLink网络地址与协议的技术猜想。
虽然NVIDIA没有公开其微架构级的网络协议细节,但我们可以从"它必须解决什么问题"和"它已知使用了哪些技术"出发,反推其设计。
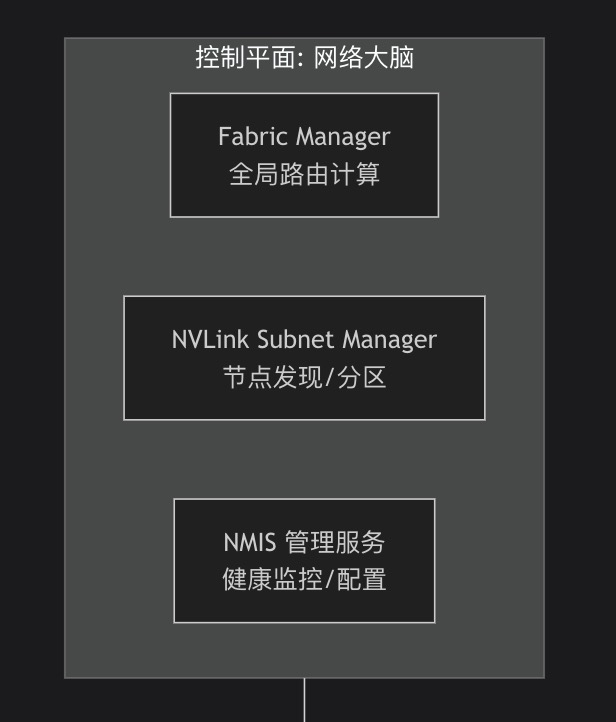
为了让观地理解这个庞大且层次分明的协议栈,我们先来看一张整体的架构图,然后再深入每个细节:



2.1. 核心挑战:什么是"网络地址"?
在设计NVLink网络之前,一个GPU只需要知道自己的显存地址。但在一个由256个GPU(如GB200 NVL72规模)组成的NVLink网络中-6,一个GPU需要能直接读写另一个GPU的显存。
这就要求有一个全局唯一的地址空间。我们的猜想从这里开始:
2.1.1 地址层次结构
我认为NVLink网络地址采用了一种分层结构,类似于PCIe但更扁平化:
-
结构地址(Fabric Address, FA):这是全局唯一的地址。格式猜想:
[Domain ID]:[Node ID]:[Chiplet ID]:[Memory Offset]-
Domain ID (8-bit):逻辑分区。在大型机柜中,可以将256个GPU划分为多个逻辑域,实现多租户隔离。这与NVIDIA文档中提到的"Use Default Partition"和分区管理功能相吻合-1。
-
Node ID (12-bit):物理设备标识。在256个GPU的规模下,需要8-bit才能覆盖,但加上NVSwitch本身也是节点,因此扩展到12-bit(4096个节点)是合理的,为未来扩展预留空间。
-
Chiplet ID (4-bit):针对未来的多芯片模组(MCM)GPU。如Rubin架构可能在一个物理封装内包含多个Chiplet,需要在内部寻址。
-
Memory Offset (64-bit):真正的内存地址偏移。总FA可达128-bit,足够覆盖未来EB级的内存寻址。
-
2.1.2 地址转换机制:IMEX的核心
在Mooncake的NVLink传输层实现中,我们看到了关键线索:CUDA IPC 和 Fabric Memory 两种模式-7。
-
CUDA IPC模式:传统单节点内,GPU通过
cudaIpcGetMemHandle获取一个64字节的句柄,其他进程打开该句柄获得访问权限-7。这本质上是一个本地句柄到物理地址的映射。 -
Fabric Memory模式(多节点):这是NVLink网络的关键。根据代码线索,流程为-7:
-
内存创建:必须通过
cuMemCreate()分配特殊的内存,而非普通的cudaMalloc()。这暗示该内存被标记为"结构可见"。 -
获取分配句柄:
cuMemRetainAllocationHandle()- 获取底层物理内存的句柄。 -
导出为可共享句柄:
cuMemExportToShareableHandle()withCU_MEM_HANDLE_TYPE_FABRIC- 这步至关重要。它将本地物理内存转换为一个包含结构地址(FA)的64字节CUmemFabricHandle结构-7。 -
导入与映射:远程节点通过
cuMemImportFromShareableHandle()导入该句柄,解析出FA,然后通过cuMemMap()将其映射到自己的虚拟地址空间-7。
-
我的猜想:CUmemFabricHandle 64字节不仅仅是一个随机ID,而是加密编码后的 {Domain ID, Node ID, Chiplet ID, Offset, 权限掩码, 安全签名}。这样,任何节点获得该句柄,就知道目标内存的全球唯一位置。
2.2. 网络层协议:基于源路由的极简设计
有了地址,数据如何送达?NVLink网络必须极端高效,不能像以太网那样每跳都查路由表。
2.2.1 路由机制:源路由(Source Routing)
NVSwitch被设计为非阻塞交换矩阵,不具备复杂的路由计算能力-2。路由计算全部集中在上层的Fabric Manager(FM)-1。
-
控制平面与数据平面分离:
-
Fabric Manager:作为整个网络的"大脑",运行在管理节点上。它通过OOB(带外)网络(如1G管理网络)与所有NVSwitch通信-1。FM掌握整个拓扑,为每条可能的通信路径计算出最优路径(如避免拥塞、负载均衡)。
-
路由注入:FM将计算好的路由表(转发表)预先配置到每个NVSwitch的硬件转发表中。
-
数据平面:当GPU A要向GPU B发送数据时,它发出的第一个数据包的头部就包含了目标地址。NVSwitch根据本地转发表进行无阻塞转发。由于FM已经确保了路径的有效性,交换机无需复杂的决策。
-
-
源路由(Source Routing)变体:在GB200级别的系统中,我猜测使用了更激进的源路由变体:
-
GPU A在发送数据前,通过FM或本地驱动获取到GPU B的完整路径矢量,例如
[SW1_Port3, SW2_Port7, SW5_Port2, ...]。 -
GPU A将这个路径矢量直接嵌入数据包的路由头中。
-
中间的NVSwitch只需读取路由头的下一个出口,弹出或索引指针,然后直接转发。这实现了单时钟周期转发,达到了极致的低延迟。
-
2.2.2 数据包格式猜想
结合WikiChip提供的NVLink 1.0/2.0的包格式-2-4,我们可以推断现代NVLink网络数据包的演进形态:
| 字段 | 长度(Bit) | 描述 |
|---|---|---|
| 路由头 | 64-128 | 新字段。包含路径矢量或下一跳索引。在大型网络中,这是扩展的关键。 |
| CRC | 25 | 沿用经典设计。用于错误检测,支持重传机制-2-4。 |
| 事务字段 | 83+ | 扩展。包含: • 请求类型:读、写、原子操作。NVLink 2.0开始支持原子操作-2。 • 结构地址(FA):目标的全局唯一地址。 • 流控标签:用于基于信用的流控。 • Tag ID:事务标识,用于匹配请求和响应。 |
| 数据链路字段 | 20+ | 扩展。包含: • 包长度:指示包含多少个Payload Flits。 • Sequence ID:用于排序和重传确认(ACK/NACK)-4。 • 虚拟通道(VC):用于区分请求、响应、监听等不同流量类型,避免死锁。 |
| 地址扩展(AE) | 0/128 | 可选。用于携带更长的地址或静态信息-2-4。 |
| 字节使能(BE) | 0/128 | 可选。用于部分写操作-2-4。 |
| 数据负载 | 0-2048 | 最多16个Payload Flits,每个128-bit,总计256字节-2。 |
设计哲学:头部足够小(128-bit基本头),转发够快;需要时再扩展,保持灵活性。
2.3. 传输层与可靠性:从链路重传到端到端
2.3.1 链路层可靠性(L0/L1)
NVLink在物理链路上提供了强大的可靠性机制-4:
-
CRC校验:25-bit CRC覆盖头部和前一个负载,能纠正5个随机错误或25个突发错误-4。
-
重传机制(Replay Buffer):发送端保存已发送包(Replay Buffer)。接收端收到包后,若CRC校验通过,返回一个正确认(ACK)。若超时未收到ACK,发送端启动重传,重传所有未被确认的后续包-4。这是一种Go-Back-N ARQ机制,确保了链路的无错传输。
2.3.2 端到端流控
NVLink网络不使用复杂的端到端拥塞控制(如TCP的慢启动),因为网络拓扑是经过FM精心规划的,理论上无阻塞。
它使用的是基于信用的流控(Credit-Based Flow Control):
-
每个接收端(GPU或NVSwitch的入口)会告诉发送端它有多少可用的接收缓冲区(Credits)。
-
发送端只有在自己有足够的Credits时,才发送数据。这从根本上避免了缓冲区溢出和丢包,保证了无损网络。
2.3.3 SHARP:网络内计算协议
这是NVLink网络协议中最具革命性的部分。它不仅仅是传输数据,而是在传输过程中处理数据-6。
-
协议扩展:SHARP协议在标准NVLink数据包的基础上,增加了计算操作码(OpCode),如
SUM、MAX、MIN、PROD。 -
交换机内执行:当NVSwitch收到来自多个源端的数据包,且这些包的目标地址相同(一个归约组),且操作码匹配时,交换机的SHARP引擎(集成了ALU)会:
-
拦截这些数据包。
-
将数据负载送入ALU执行指定的归约操作。
-
生成一个新的数据包(归约结果),继续向上游转发。
-
或者将结果广播回所有源端。
-
-
协议优势:将传统的多轮通信减少为2步(数据上传、结果下发),极大地加速了AllReduce等集体通信操作。
2.4. 控制平面协议:NMIS与Fabric Manager
所有上述机制都需要一个强大的控制平面来配置和管理。
2.4.1 管理协议栈
根据NVIDIA文档,NVSwitch运行NVOS(NVIDIA Operating System),并通过以下方式管理-1:
-
零接触配置(ZTP):新交换机上线后,通过DHCP获取IP,从配置服务器拉取
nvlink-nvos.json配置文件,自动完成固件升级、安全设置和应用配置-1。 -
NMIS(NVIDIA Management Interface):我猜测这是一个基于RESTful API或gRPC的内部管理协议,用于:
-
拓扑发现:FM通过NMIS发现新接入的GPU和交换机。
-
健康监控:FM实时查询交换机的温度、功耗、链路误码率(通过NVML/DCGM暴露)-1。
-
路由下发:FM计算好路由后,通过NMIS将转发表写入NVSwitch的硬件。
-
分区管理:通过NMIS创建、删除逻辑分区(Partition),隔离不同租户的流量。
-
2.4.2 分区(Partitioning)的协议含义
"Use Default Partition"暗示了NVLink网络支持虚拟化-1。在协议层面,这意味着:
-
每个数据包的路由头或事务字段中,可能包含一个 Partition Key(P_Key)。
-
NVSwitch在转发时,除了检查目标地址,还会检查P_Key。只有P_Key匹配的端口,才允许转发。这实现了硬件级别的安全隔离。
2.5. 总结:一张完整的NVLink网络协议栈
将上述所有猜想整合起来,我们得到一张层次清晰的NVLink网络协议栈视图:
| 层次 | 核心协议/技术 | 功能描述 |
|---|---|---|
| 软件/编程层 | CUDA, NCCL, IMEX | 提供cudaMemcpy抽象,自动选择IPC或Fabric Memory路径。 |
| 地址转换层 | IMEX, CUmemFabricHandle |
将本地虚拟地址(VA)转换为全局结构地址(FA),封装为64字节安全句柄。 |
| 传输层 | NVLink Packet, SHARP | 定义数据包格式(头+负载),支持信用流控、原子操作和网络内计算。 |
| 网络层 | 源路由,Fabric Manager | 控制平面集中计算路由,数据平面携带路径矢量,实现单周期转发。 |
| 链路层 | CRC, Replay, ACK/NACK | 提供相邻设备间的可靠传输和重传机制。 |
| 物理层 | SerDes, PAM4, NVLink Brick | 以50-100 Gbps/lane的速度传输原始比特流,支持链路反转等电气特性-2-6。 |
| 控制与管理 | NMIS, ZTP, NVOS | 负责设备发现、配置、路由下发、分区管理和健康监控。 |
这个协议栈的设计核心思想是:极简的数据平面 + 智能的控制平面。数据平面只做最核心的转发,甚至能做计算(SHARP);控制平面集中处理所有复杂性(路由计算、分区管理)。这正是支撑NVIDIA构建数万GPU超大集群的底层技术逻辑。
3. NVQLink 以太网技术
根据NVIDIA官方发布的架构信息,NVQLink在其当前的实现方案中,并没有使用名为"NVSwitch"的组件,而是采用了基于以太网的技术。
为了清晰地解答你的疑问,我将NVQLink的实际网络构成整理如下,并与你可能联想到的NVIDIA其他网络产品(如NVSwitch所属的InfiniBand体系)进行对比:
| 对比维度 | NVQLink 的实际网络构成 | 你可能联想到的 NVSwitch |
|---|---|---|
| 核心技术 | 基于融合以太网的远程直接内存访问技术,即RoCE-1-7。这是一种允许通过以太网进行高效内存访问的技术。 | InfiniBand -2-4。一种专为高性能计算设计的超高带宽、超低延迟互联技术。 |
| 使用的关键硬件 | - 网络接口卡 (NIC): NVIDIA ConnectX-7 -1。 - 交换机:未使用NVSwitch,而是利用了标准的、支持RoCE的以太网交换机基础设施-1。 |
NVSwitch 本身就是InfiniBand交换机产品线的名称-2-4。它用于构建大规模的GPU计算集群。 |
| 架构定位 | 作为连接量子处理器(QPU) 与经典超级计算机(GPU) 的桥梁,实现实时、低延迟的量子纠错(QEC)和控制-3-5-9。 | 用于连接GPU与GPU,构建大规模AI和高性能计算集群,以加速AI训练和科学模拟等任务-2-6。 |
从表格可以清晰地看到,NVQLink与NVSwitch虽然都是NVIDIA在互联技术领域的重要布局,但它们服务于不同的计算场景,采用了不同的技术路径。
3.1. 为什么是RoCE,而不是NVSwitch?
NVIDIA为NVQLink选择RoCE(以太网远程直接内存访问)而非InfiniBand和NVSwitch,主要是出于以下考虑:
-
开放性与兼容性:NVQLink被设计为一个开放平台架构-1-7。量子计算生态系统中有众多的量子系统控制器(QSC)制造商,它们的技术方案多样。采用广泛使用的以太网标准,可以更容易地被整个行业采纳,让不同厂商的量子硬件都能方便地与NVIDIA的GPU超算集成-1。
-
性能达标:NVQLink的性能需求非常苛刻。实验表明,基于RoCE的互联方案可以实现平均3.84微秒的端到端延迟-1,抖动极低。这个性能水平足以满足当前及未来容错量子纠错解码和其他实时控制任务的需求-1-7。
-
可扩展性:现代以太网设备已经非常成熟,能够支持400Gbps链路和大型交换网络-1。随着RoCE技术在大型AI和超算部署中持续进步,通过NVQLink集成的量子系统也能直接受益于这些技术发展-1。
总结来说,NVIDIA在设计NVQLink时,优先考虑的是打造一个能被广泛采用的开放标准,以连接新兴的量子计算生态和其强大的GPU计算生态。因此,它选择了开放、成熟且性能足够的RoCE以太网方案,而不是其专为GPU集群设计的InfiniBand(NVSwitch)方案。
4. NVQLink 中软件的角色
NVQLink提供了连接量子处理器(QPU)和GPU的硬件“高速公路”,而CUDA-Q就是在这条高速公路上运行的“操作系统”和“驾驶员”。它让开发者能用熟悉的编程语言,轻松指挥量子硬件和经典计算资源协同工作-2。
为了更清晰地展示CUDA-Q在NVQLink架构中的核心角色,我把它的主要作用梳理成了这张表:
🧠 CUDA-Q在NVQLink中的核心角色
| 维度 | CUDA-Q在NVQLink中的角色 | 关键技术与价值 | 最新实例:Quantinuum Helios项目-1-3-6 |
|---|---|---|---|
| 统一编程接口 | 为开发者提供单一的编程模型(C++/Python),将QPU、CPU和GPU视为对等的异构计算设备。 | cudaq::device_call API:允许在量子代码中直接调用GPU或CPU函数,实现微秒级的实时反馈,无需处理复杂的底层网络通信-3。 |
研究人员只需编写单一程序,就能定义量子纠错实验,并在GPU上实时处理从QPU采集到的“症状数据”。 |
| 实时纠错引擎 | 通过实时API,使GPU能够作为高速解码器,在量子比特退相干前完成错误识别和纠正。 | CUDA-Q QEC库:提供优化的量子纠错解码算法,如用于qLDPC码的nv-qldpc-decoder,可充分利用GPU的大规模并行能力-3。 |
在Helios项目中,CUDA-Q成功调度GPU运行解码算法,在仅67微秒内完成纠错,比量子比特的相干时间要求(2毫秒)快了32倍-1-4。 |
| 系统协调器 | 负责协调整个“逻辑QPU”的工作,包括任务分发、数据流管理和资源编排。 | 集成了NVIDIA Holoscan SDK和DOCA等库,与NVQLink网络层无缝对接,确保数据在FPGA(量子控制器)和GPU之间以<4微秒的极低延迟流动-2-3。 | CUDA-Q协调了整个纠错流程:从FPGA接收数据,启动GPU解码,并将纠错指令实时反馈回量子系统,形成一个完整的闭环。 |
简单来说,NVQLink(硬件)提供了从QPU到GPU的极速通道,而CUDA-Q(软件)则让这条通道变得可用、可编程,并直接用于解决量子计算最核心的纠错难题。它把量子处理器从需要缓慢、复杂API调用的“外围设备”,变成了超级计算机中一个能实时协同工作的“一等公民”-3。
你是对CUDA-Q中那个神奇的 cudaq::device_call API 的具体实现更感兴趣,还是想了解它支持的量子纠错算法(比如qLDPC码)的工作原理?
5 合作案例
NVIDIA与Quantinuum的合作,不仅仅是技术上的简单集成,而是围绕NVQLink硬件与CUDA-Q软件,在实时量子纠错这一核心难题上取得了实质性突破,为构建未来的量子-经典混合超算奠定了基石-6-7。
我将他们的合作内容,特别是围绕Helios项目的成果,整理成了下面的表格,这样看起来会更清晰:
🤝 NVIDIA × Quantinuum 合作案例核心解析
| 合作维度 | 具体内容与关键技术 | 实际成果与价值 |
|---|---|---|
| 🚀 核心硬件集成 | Quantinuum最新的Helios量子处理器(采用钡离子阱技术,98物理比特,双门保真度99.921% -3-8)与NVIDIA GB200 Grace Blackwell平台通过NVQLink进行集成-1-5。 | 构建了一个高性能的量子-经典混合计算节点,为复杂的混合算法提供物理基础。 |
| ⚡️ 实时量子纠错 (QEC) | 这是合作的核心突破点。利用NVQLink(400Gb/s吞吐量,<4微秒延迟-7-9)和CUDA-Q平台,将GPU作为实时解码器,在Helios的控制系统中运行qLDPC码的解码算法-4-6。 | 实现了67微秒的纠错反应时间,比Helios系统要求的2毫秒快了32倍-4-7。这是全球首次对qLDPC码进行可扩展的实时解码,并因此将量子操作的逻辑保真度提升了超过3% -1。 |
| 💻 软件与编程生态 | 开发者可以在统一的开发环境中,使用NVIDIA CUDA-Q平台和Quantinuum的Guppy语言,编写在单个程序中交织运行GPU加速的经典计算与量子计算的应用-1-8。 | 大大降低了混合编程的门槛,使开发者能轻松构建和测试量子纠错及量子-GPU协同应用的算法-7。 |
| 🧪 前沿应用探索 | ADAPT-GQE框架:双方与一家制药巨头合作开发的生成式量子AI方法。它使用生成式AI模型来高效合成化学分子基态所需的电路-1。 | 通过GPU加速,该方法在生成复杂分子(如丙咪嗪)的训练数据时,实现了234倍的加速,最终在Helios上成功运行,验证了其在药物研发中的潜力-1。 |
简单来说,这次合作展示了NVQLink + CUDA-Q这套组合拳的威力:它不仅从硬件上解决了量子处理器与经典超算的高速互联问题,更重要的是,它已经在真实量子硬件(Helios)上证明了其能够显著提升量子纠错的实时性和准确性——这是通往大规模容错量子计算必须跨越的门槛。
6. 纠错码
qLDPC码(量子低密度奇偶校验码)可以理解为更高效的量子纠错方案。如果说主流的表面码是用大量士兵(物理比特)组成一个方阵来保护一位将军(逻辑比特),那么qLDPC码就像是用特种部队——人数更少,但内部联系更紧密、战术更复杂,能保护多位将军-5-7-8。
它在NVIDIA与Quantinuum的合作中扮演了核心算法角色,是实现高效、实时量子纠错的关键。
🔑 qLDPC码的核心概念与优势
| 特性维度 | qLDPC码 | 传统表面码 | 优势说明 |
|---|---|---|---|
| 编码效率 | 高:一个码可保护多个逻辑量子比特,编码率 > 0 -1-7 | 低:一个码只保护一个逻辑比特,编码率趋近于0 -5-10 | 硬件效率:保护同数量逻辑比特,qLDPC码所需物理比特可减少10倍-5-8。 |
| 码距扩展性 | 优秀:码距随码长线性增长,理论上可超越√n屏障-1 |
普通:码距随码长平方根增长 | 指数级抑制:qLDPC码能指数级抑制错误,所需资源更少。 |
| 连接复杂度 | 高:常需长距离连接,对硬件架构是挑战-2-5 | 低:只需相邻量子比特连接,物理实现简单 | 硬件挑战:高复杂度是主要障碍,但通过NVQLink的高速互联可以解决。 |
🛠️ 解码挑战:从理论到实时
优异的理论性能需要高效的解码算法来实现。qLDPC码的解码面临两大挑战:
-
解码算法复杂:传统算法(如置信传播(BP))因代码的简并性(多个错误对应相同症状)和短环结构而效果不佳-2-5。更精确的BP-OSD(有序统计解码) 虽好,但其包含的高斯消元步骤计算量巨大(复杂度
O(m³)),难以满足实时要求-5-7。 -
实时性要求苛刻:解码必须在量子比特退相干前(约几微秒内)完成-6-7。这要求解码器既快又准。为此,研究者正探索多种路径:
🚀 实战案例:qLDPC在NVIDIA x Quantinuum合作中的应用
现在,我们可以清晰地看到qLDPC码在NVIDIA与Quantinuum合作中的具体作用了:
| 合作环节 | qLDPC码扮演的角色 | 实现的关键突破 |
|---|---|---|
| 选择qLDPC码 | 作为纠错方案,充分发挥其高编码效率的优势。 | 为实现低开销、大规模的量子纠错奠定了基础。 |
| 硬件支撑 | 利用NVQLink解决qLDPC码对高连接度的需求。 | 提供了<4微秒延迟、400Gb/s吞吐量的GPU-QPU高速通道。 |
| 实时解码 | 在CUDA-Q平台上,用GPU运行qLDPC解码算法(如优化的BP)。 | 最终实现67微秒的端到端纠错延迟,比Helios系统要求的2毫秒快了32倍,并提升了3%以上的逻辑保真度。 |
qLDPC码以其卓越的理论效率,加上NVQLink提供的硬件互联和CUDA-Q平台实现的实时解码算法,共同证明了构建实用化、大规模容错量子计算机的可行性。
GPU上运行的qLDPC解码算法(比如如何处理简并性问题)的具体原理,还有 IQM等公司为降低硬件复杂度开发的“Tile Codes”这类变种
Decoding Quantum Low Density Parity Check Codes with Diffusion
https://ar5iv.labs.arxiv.org/html/2509.22347https://meetiqm.com/blog/how-iqm-is-tackling-quantum-error-correction/http://globaltechmap.com/document/view?id=49346https://ar5iv.labs.arxiv.org/html/2509.22347
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)