【论文阅读】LingBot-VA:Causal World Modeling for Robot Control
·
快速了解部分
基础信息(英文):
1.题目: LingBot-VA:Causal World Modeling for Robot Control
2.时间: 2026.01
3.机构: Robbyant蚂蚁灵波
4.3个英文关键词: World Model, Robot Control, Video-Action Modeling
5.paper
1句话通俗总结本文干了什么事情
本文提出了一种名为LingBot-VA的机器人控制模型,通过“看视频想象未来”和“推算动作”同步进行的方式,让机器人能像人类一样根据想象的后果来实时调整动作,从而解决复杂长流程的任务。
研究痛点:现有研究不足 / 要解决的具体问题
- 反应式模型的局限:现有的VLA模型大多是“反应式”的,看到画面直接输出动作,缺乏对物理世界动态变化的理解,导致泛化能力差。
- 世界模型的“非因果”问题:现有的视频世界模型多采用双向注意力机制(能看到未来也能看到过去),这不符合物理世界“过去决定现在”的因果逻辑,导致在实际闭环控制中容易产生误差累积和漂移。
- 实时性难题:生成视频通常计算量大,难满足机器人控制的高频率实时性要求。
核心方法:关键技术、模型或研究设计(简要)
提出了LingBot-VA,一个自回归扩散世界模型。核心是将视频帧和动作 token 交织在一起,通过单向因果掩码进行预测,并设计了异步推理pipeline,在机器人执行当前动作时后台预测下一时刻的画面与动作。
深入了解部分
作者想要表达什么
要实现通用机器人控制,不能仅靠模仿学习(反应式),必须让机器人学会“想象”未来的视觉画面。这种基于视频的世界模型应当严格遵循因果关系(自回归),并且通过架构设计来解决计算延迟问题,从而实现既能“深思熟虑”又能“实时反应”的控制策略。
相比前人创新在哪里
- 因果一致性:不同于以往分块(chunk-based)生成视频的方法(块内双向注意力),本文采用严格的自回归方式,确保了物理时间的因果性,适合长视野任务。
- 统一的时空建模:将视频和动作放在同一个序列中通过 MoT架构联合建模,共享潜在空间,而不是将它们作为独立的模块。
- 异步双工机制:提出了异步推理策略,在机器人执行动作的同时后台预测未来,解决了生成模型推理慢的痛点。
解决方法/算法的通俗解释
可以把这个模型比作一个“实时剧本导演”。
- 想象练习:模型先看了大量人类操作视频和机器人数据,学会“做这个动作,画面会变成什么样”。
- 因果预测:它写剧本时,只能根据“上一幕”写“下一幕”,绝不允许“剧透”,保证了逻辑符合物理规律。
- 边演边写:在机器人实际操作时,模型不是等机器人做完一步再写下一步,而是利用机器人做动作的时间,提前在后台算好“如果我这么做,下一秒画面会怎样”以及“接下来该做什么”。
- 及时纠错:如果机器人实际看到的画面和模型想象的不一样(比如东西没抓起来),模型会立刻根据新看到的画面重新规划接下来的动作。
解决方法的具体做法
- 架构设计:使用双流 Mixture-of-Transformers (MoT) 架构。视频流基于预训练的 Wan2.2-5B 模型,动作流参数量较小。两者通过交叉注意力融合。
- 数据组织:将视频帧和动作 token 交织排列(如:帧1,动作1,动作2…,帧2),形成统一序列。
- 训练策略:
- 教师强制:训练时使用真实的历史数据来预测下一个 token。
- 噪声历史增强:在训练时故意给历史视频加噪声,强迫动作解码器学会在画面不清晰(或未完全生成)的情况下也能正确预测动作,从而实现推理时的“部分去噪”加速。
- 推理加速:
- KV Cache:缓存历史 key-value,避免重复计算。
- 异步流水线:执行当前动作块的同时,预测下一个动作块和对应的视觉画面。
基于前人的哪些方法
- 视频生成基础:基于 Wan2.2 的视频 VAE 和扩散模型架构。
- 流匹配 (Flow Matching):采用流匹配技术进行连续时间的生成建模。
- MoT 架构:借鉴了MoT思想,设计了针对不同模态(视频/动作)的混合 Transformer 块。
- VLA 范式:建立在VLA的基础上,增加了显式的视觉动态预测。
实验设置、数据、评估方式、结论
- 数据:整合了约 16,000 小时的机器人操作数据(包括 Agibot, RoboMind, InternData-A1, OXE, UMI Data, RoboCOIN)。
- 设置:
- 仿真:RoboTwin 2.0 (双臂操作) 和 LIBERO 套件。
- 真实世界:6个高难度任务(制作早餐、拆快递、插管子、捡螺丝、叠衣服、叠裤子),仅用 50 条真实世界演示数据进行微调。
- 评估方式:成功率 (Success Rate) 和 进度得分 (Progress Score)。
- 结论:
- 在 RoboTwin 2.0 上达到 92.9% 的平均成功率(远超 π0.5, X-VLA 等基线)。
- 在真实世界任务中,相比 π0.5 展现了更强的长视野任务处理能力和数据效率(仅需 50 条数据)。
提到的同类工作
- VLA类:RT-1, RT-2, π0 (π0.5), OpenVLA, X-VLA, GR-3, Octo.
- 世界模型/视频类:UniSim, UVA, UWM, Gen2Act, Act2Goal, Motus, 1X World Model.
和本文相关性最高的3个文献
- π0 / π0.5 (Physical Intelligence et al.):作为主要对比基线,代表了当前最先进的反应式 VLA 模型,本文旨在证明引入世界模型比纯反应式模型更优。
- Wan / Wan2.2 (WanTeam):本文模型视频流部分的骨干网络和预训练基础,提供了强大的视频生成先验。
- Motus (Bi et al.):同样是统一的潜在动作世界模型,属于同期的竞品工作,本文在架构上与其有相似之处但强调了不同的因果机制和异步推理。
我的
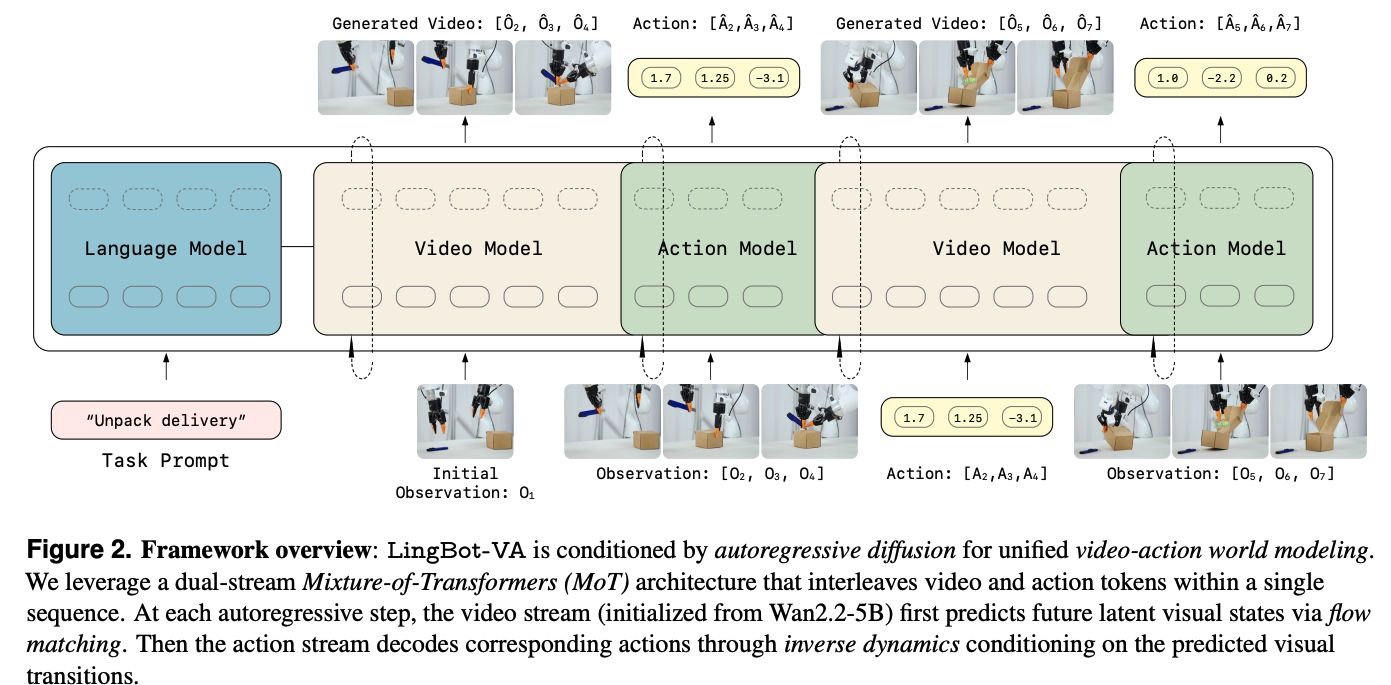
完全的自回归方式,生成一次视频,再生成一次action。用的wan作为视频生成backbone。
如果没有异步推理,速度会比较慢。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)