预训练&SFT&PPO训练大模型
一、大模型预训练
预训练大模型有两种情况,一种是从零开始的预训练,也就是训练开始时模型所有的参数都是随机初始化的这要通过大量的语料、大量的显卡,大量的时间才能训练出一个不错的大模型。还有一种情况是在开源已经预训练好的大模型的基础上,你针对特定的行业,比如金融或者医疗领域来加强训练,提升通用模型在特定领域的知识和能力。这是我们更常遇到的情况。
我们通过实际代码来看一下如何对一个大模型进行预训练。首先我们设定大模型的路径,这里我们指定的是lama 3.1的8b instruct模型,然后加载预训练大模型。接下来把模型放入显卡,定义一个优化器。我们输入的文本是今天天气不错,然后对输入文本进行分词,接着将分词后的input也放入显卡。这里的input是一个字典,包括了input和mask,我们再加入一项labels,让它等于input就可以,然后就可以利用大模型进行前向传播了。Hugin face大模型的输出里包含了loss,这是因为我们传入了label,所以它前向传播时会为我们自动计算loss,有了loss我们就可以进行后向传播,更新参数,最后保存模型了,这就是大模型训练最核心的代码,非常简单。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
from peft import TaskType, LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, LlamaConfig, LlamaForCausalLM,LlamaModel
import torch
model_path = '/data04/llama3/Meta-Llama-3.1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_path)
# # 1.从零开始训练大模型
# config = LlamaConfig() # 创建一个默认的Llama config
# config.num_hidden_layers = 12 # 配置网络结构
# config.hidden_size = 1024
# config.intermediate_size = 4096
# config.num_key_value_heads = 8
# # 用配置文件初始化一个大模型
# model = LlamaForCausalLM(config)
# 2.加载一个预训练的大模型
# # 4bit load
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
low_cpu_mem_usage=True,
quantization_config=bnb_config
)
# 构造Lora模型
peft_config = LoraConfig(
r=8,
target_modules=["q_proj",
"v_proj",
"k_proj",
"o_proj",
"gate_proj",
"down_proj",
"up_proj"
],
task_type=TaskType.CAUSAL_LM,
lora_alpha=16,
lora_dropout=0.05
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model.to("cuda")
optimizer = torch.optim.AdamW(model.parameters())
text = "今天天气不错。"
input = tokenizer(text, return_tensors="pt")
input = {k: v.to("cuda") for k, v in input.items()}
#设置labels和inputs一致
input["labels"] = input["input_ids"].clone()
output = model(**input)
#获取模型的loss
loss = output.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
#保存模型
model.save_pretrained("output_dir")第一个问题,一般情况下loss函数都是我们自己实现的。大模型训练时内部的loss是如何计算的呢?对于一个大模型,假如它的输入是今天天气不错,这句话被拆分为四个token。大模型根据今天这个输入的token输出第一个token。我们希望大模型输出的是 天气 这个token,实际上大模型输出的是对字典里所有token的一个概率分布。我们希望大模型输出天气这个token的概率尽可能的大,输出其他token的概率尽可能的小。这里实际上就是对多个可能的输出token进行分类。
接着大模型根据今天和天气这两个token输出对下一个token的概率,我们希望大模型输出的是 不错 这个。然后大模型根据今天天气不错这三个token输出下一个token的概率,我们希望大模型输出的是 句号 这个token,最后大模型根据今天天气不错和句号这四个token给出下一个token的概率。但是因为我们根据输入也不知道下一个token是什么,所以在训练时就丢弃最后输出的这个token,不对它进行loss计算。

这里是hugging face里llama model计算loss的代码。可以看到首先丢弃预测的最后一个token,不对它进行loss计算。然后因为之前传入的labels就是input,每个input的token加上他之前input的所有token,预测的是input的下一个token,所以需要把所有input都左移移位,形成最终的label。因为大模型预测下一个token实际上就是对词典里所有的token进行一个分类,所以这里用分类模型常用的交叉熵损失函数进行loss计算。
如果想从头训练一个大模型该怎么办呢?你可以通过llama config来初始化一个默认的lama的配置文件,然后根据你的需要来修改网络配置。比如修改decoder模块的个数,隐藏层的大小的,然后用这个初始化信息来构造一个新的模型。后边的训练和之前是一样的,再加上比如量化加载,LoRA训练等。所以这里我们再加上量化加载模型的代码,这里采用4比特加载。在模型加载时加上量化配置的信息,接下来我们再生成一个LoRA模型的配置。通过原始模型和LoRA的配置生成LoRA模型,大概率就可以训练模型了。
二、大模型微调(SFT)
下面来讨论一下大模型的指令微调,或者叫做监督微调,Supervised Fine-tuning。从三个方面来讨论。1、chat template对话模板,2、completions only只针对回答的微调,3、NEFtune给embedding增加噪音的微调。
2.1chat template
指令微调是在大模型预训练之后的微调过程,大模型几乎所有的能力都是在预训练时获得的,但是预训练后的模型还不知道如何表达自己的知识,它只会根据你提供的上文继续续写下文,比如你问他中国的首都在哪里,他可能接着续写美国的首都在哪里,而不是直接回答你的问题。指令微调阶段就是在预训练大模型的基础上,让大模型能更好的用自己学到的知识来回答人提出的问题。我们知道对于一个神经网络的训练,最重要的有三点,1、网络结构,2、loss函数,3、训练数据。指令微调和预训练没有本质上的不同,他们在网络结构上完全相同,loss函数基本相同,最大的不同就是训练数据的不同。
开源的大模型都会推出预训练版本和指令微调版本。他们在出厂前进行指令微调时,都会有自己格式的对话模板,叫做chat template。你想增强大模型在某个业务领域的能力,继续进行自己的指令微调时,必须和原厂的对话模板保持一致,才能获得最好的微调效果。下面我们看这个例子,比如你想问大模型为什么天空是蓝色的?希望大模型回答是,这是由于光的散射造成的。

虽然不知道为什么?但是这个chat template应该是提示词工程的起源。大模型在指令微调时都要加上一些特殊的token,来让大模型意识到现在是要回答问题,而且回答完毕时加上结束的token。比如这里是Llama3.1的chat template,可以看到他会在开始时加上序列开始符的token,把不同的角色放入I的ID中,每一个content结束时加上序列结束的token。上面这个list是hugging face所能接受的一个对话的数据结构,它是一个list,其中每个元素都是一个字典,其中有两项内容,一个是role,一个是content。一般的role用system用来对大模型进行系统设定,user表示用户输入,还有就是assistant用来表示大模型的回答。
下边这是把对话信息转化为输入给大模型的token。每个大模型和自己的tokenizer是唯一对应的,同时也和自己的chat template是唯一对应的。所以把这个chat template也放在了tokenizer的配置里面。比如这里是Llama 3.1的tokenizer_config json的配置文件。
具体的代码调用就是生成一个对话的列表,然后通过tokenizer的apply chat template的方法,把它转化为要输入给大模型的token序列。通过训练后的大模型,你只要提供问题,并且在生成聊天模板时将add generation prompt设置为true,那么它就会生成如下的token。
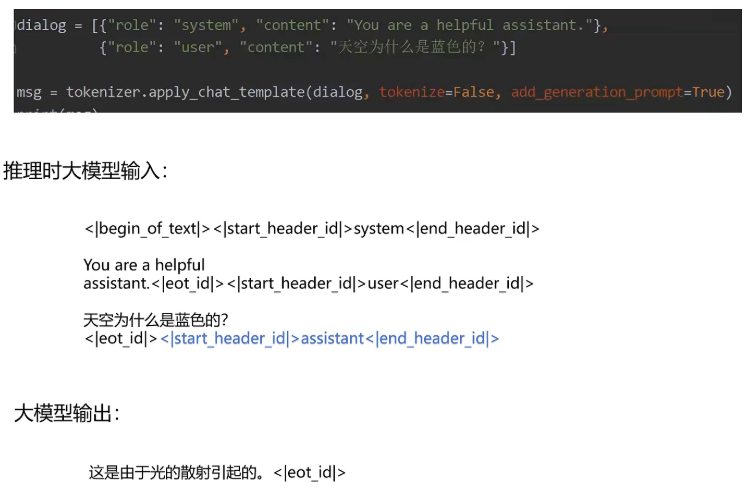
他会在后面加上标记为蓝色的这一部分,让大模型来生成接下来的答案。最终大模型输出答案和序列终止符。好的,我们来看一下最简单的指令微调的代码实现。首先加载tok niza和model定义优化器,然后生成一个对话数据,通过tokenizer应用chat template设置label等于input,然后模型前向传播获取loss,反向传播优化参数保存模型。
2.2completions only
指令微调的第二个技巧是completions only。我们输入给大模型的是整个对话,它会对整个对话的文本进行学习。刚才简单的训练过程,它会对每个输出的token计算loss。首先,对于系统提示部分,每个样本都是一样的,没有必要重复计算它的loss。另外为了让大模型把注意力都集中在怎么回答问题上,我们可以只对整个序列里面的答案部分计算loss,这就是completions only,这个是怎么做到的呢?比如这样输入一个分词后的token序列,大模型会根据当前的token和它之前的token序列预测出下一个token。比如这里根据监控和他前面的token预测出为什么这个token,根据为什么和他之间的token预测出是这个token。

我们需要生成一个loss mask,它来表示对哪些生成的token来计算loss,哪些不计算。需要计算loss的标志为1,不需要计算的标志为0。这样最后我们在计算loss时,每个位置的loss乘以loss mask就忽略掉了那些不需要计算loss token。
下面是具体的代码实现:
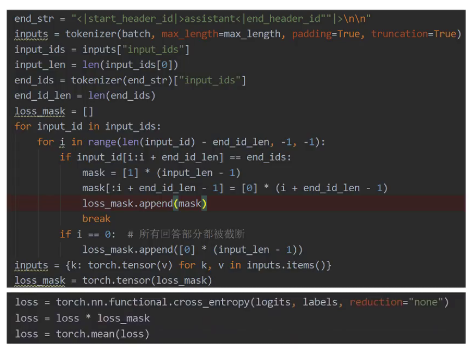
他根据开始回答部分的特殊token来确定需要计算loss的token的位置。比如这里对于Llama 3.1,他开始回答部分前面的token序列就是start header ID assistant,end header ID 两个换行符。根据这个特殊的token序列就可以找到回答的起始位置。其实位置后面的都是需要计算loss的token,loss mask为一。前面的都是不需要计算loss的token,loss mask为零。最后再计算出每个token的loss后乘以对应的loss mask,然后再取均值作为最终的loss。
我们看一下具体的代码实现。这个代码更复杂一些,接近实际运行的代码。首先我们看一下用来进行指令微调的数据,它一般包含两个部分,一个是query,一个是answer。
import functools
import json
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from torch.utils.data import DataLoader, Dataset
import torch
class SFTDataset(Dataset):
def __init__(self, file_path, tokenizer):
super().__init__()
self.file_path = file_path
self.examples = self._load_data(self.file_path)
self.tokenizer = tokenizer
@staticmethod
def _load_data(file_path):
items = []
with open(file_path, "r", encoding="utf8")as f:
for line in f:
item = json.loads(line)
items.append(item)
return items
def __getitem__(self, index):
example = self.examples[index]
dialog = [{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": example["query"]},
{"role": "assistant", "content": example["answer"]}]
chat = tokenizer.apply_chat_template(dialog, tokenize=False)
return chat
def __len__(self):
return len(self.examples)
model_path = r'D:\work\models\Meta-Llama-3.1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.padding_side = "right"
tokenizer.pad_token = tokenizer.eos_token
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_path, quantization_config=bnb_config)
peft_config = LoraConfig(
r=8,
target_modules=["q_proj",
"v_proj",
"k_proj",
"o_proj",
"gate_proj",
"down_proj",
"up_proj"
],
task_type=TaskType.CAUSAL_LM,
lora_alpha=16,
lora_dropout=0.05
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
model.to("cuda")
optimizer = torch.optim.AdamW(model.parameters())
def sft_collate(batch, tokenizer, end_str, max_length):
end_str = "<|start_header_id|>assistant<|end_header_id""|>\n\n"
inputs = tokenizer(batch, max_length=max_length, padding=True, truncation=True)
input_ids = inputs["input_ids"]
input_len = len(input_ids[0])
end_ids = tokenizer(end_str)["input_ids"]
end_id_len = len(end_ids)
loss_mask = []
for input_id in input_ids:
for i in range(len(input_id) - end_id_len, -1, -1):
if input_id[i:i + end_id_len] == end_ids:
mask = [1] * (input_len - 1)
mask[:i + end_id_len - 1] = [0] * (i + end_id_len - 1)
loss_mask.append(mask)
break
if i == 0: # 所有回答部分都被截断
loss_mask.append([0] * (input_len - 1))
inputs = {k: torch.tensor(v) for k, v in inputs.items()}
loss_mask = torch.tensor(loss_mask)
return inputs, loss_mask
collate_fn = functools.partial(sft_collate,
tokenizer=tokenizer,
end_str="<|start_header_id|>assistant<|end_header_id""|>\n\n",
max_length=50)
sft_dataset = SFTDataset("./data/sft_data.json", tokenizer)
data_loader = DataLoader(sft_dataset, batch_size=2, collate_fn=collate_fn, shuffle=True)
epoch = 10
for i in range(epoch):
for inputs, loss_mask in data_loader:
inputs = {k: v.to("cuda") for k, v in inputs.items()}
loss_mask = loss_mask.to("cuda")
logits = model(**inputs).logits[:, :-1, :]
labels = inputs["input_ids"][:, 1:]
logits = logits.reshape(-1, logits.size(-1))
labels = labels.reshape(-1)
loss_mask = loss_mask.reshape(-1)
loss = torch.nn.functional.cross_entropy(logits, labels, reduction="none")
loss = loss * loss_mask
loss = torch.mean(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss.item())首先定义一个pytorch里的dataset来加载数据。在get_item函数里,我们返回的是经过tokenizer添加chat template后的文本。然后我们用量化加载LoRA配置,获取LoRA模型。然后我们定义一个collate函数,它负责对一个batch的训练数据进行整理。它首先进行tokenize,然后按照我们刚才讲过的方法生成loss mask,然后进入训练循环。从data loader里加载的数据,它包含输入的input,同时包含输出token的loss mask。这里得到模型输出的logits。因为对于最后一个位置的输出我们没有label,所以去掉它,input左移一位得到label,然后计算loss,计算出loss后乘以loss mask求loss的均值,得到最终的loss反向传播优化参数。
2.3NEFT
第三,是NEFT,也就是noisy embedding fine turning。在计算机视觉领域,数据增强是一个很重要的过程。因为训练时总觉得数据不够多,可以通过对图片进行旋转、反转、调整亮度等手段生成更多的样本,提高模型的泛化性,增强模型的精度,指令微调的数据很多情况下都需要人手动构造采集,代价很大,对于大模型庞大的参数量来说就显得更少了。
有没有一种对于文本的数据增强的方法呢?在token进入大模型的第一步就是进行embedding。而我们知道在token embedding构成的向量空间里,比如漂亮和美丽,妻子和夫人这些意义相近的词,它们在向量空间里面的距离也是非常相近的。NEFT的思想就是给每个token的embedding随机加上一些噪声,而这些增加的噪声可能让原本句子里面的token变成和它相近的token。这样就相当于增加了你样本的丰富度,从而最终提高模型的精度和泛化性。
它的实现很简单,首先有一个噪声系数α,它可以调节增加噪声的强度,然后对input ID进行embedding计算序列的维度,就是序列的长度乘以每个token的维度,然后用噪音系数阿尔法除以序列维度的开方。这里为什么要除以序列维度的开方呢?你可以理解为最终是计算一个序列和加了噪音的序列,他们在空间里的欧式距离,而这个空间就是由序列维度构成的。辅以序列维度的开放,就是为了让不同序列长度的文本,他们和自己加了噪声的样本的欧式距离都是一样的,不会因为序列的长度不同而距离不同。最后把生成的噪声加到原来的embedding上就可以了。就是向量除以自己的模。
neftune_noise_alpha = 10
for i in range(epoch):
for inputs, loss_mask in data_loader:
input_ids = inputs.pop("input_ids")
input_embeddings = model.base_model.model.model.embed_tokens(input_ids)
dims = torch.tensor(input_embeddings.size(1) * input_embeddings.size(2))
mag_norm = neftune_noise_alpha / torch.sqrt(dims)
input_embeddings = input_embeddings + torch.zeros_like(input_embeddings).uniform_(-mag_norm, mag_norm)
inputs["inputs_embeds"] = input_embeddings作者在Llama 27B的模型上进行了测试通过,增加NEFT可以让模型的表现平均增加10%。它是我们刚才看的针对回答计算loss的代码上进行修改得到的。修改的代码也很少,就是增加了噪音系数。然后这里首先获取token的input ID,然后对他们进行embedding。接着计算序列维度,用噪音系数除以序序列维度的开方,生成随机数的范围,mag_norm,然后给原始的embedding每一位都随机加上从正的mag_norm到负的mag_norm之间的一个随机数,后面的代码基本不变。
上边这么多是为了了解大模型SFT的原理。实际上并不需要写这么多的代码。Hugging face的TRL库里面集成了SFTtrainer的,它集成了这些功能,你只需要通过简单的配置就可以实现,并且能够实配accelerator进行分布式训练。
三、大模型强化学习PPO
下面讨论如何使用PPO算法对大模型进行强化学习训练。首先看之前PPO推导才能理解这一章。大模型的训练首先是预训练阶段,接下来是监督微调。今天要讲的是强化学习的部分,它一般是在监督微调之后,而且PPO算法需要一个预先训练的reward模型,来为模型的输出进行打分,提供奖励信号。所以首先我们就从怎么训练一个reward模型讲起。

首先,训练一个reward模型需要的数据,是偏好数据。具体来说就是对同一个问题两个答案的比较数据。好的回答数据叫做chosen,不好的回答叫做rejected。比如这里的问题,什么是数据库大模型给了两个回答,我们在两个回答中选出更好的那个回答作为初始,较差的那个回答作为rejected。

相比于让我们给每个回答一个明确的打分,偏好数据更容易生成。虽然我们训练采用的是偏好数据,但是对于reward模型来说,最终它需要能针对一个问答序列给出明确的得分。Reward模型可以是多样的,只要它能接受一个问答,对序列输出一个得分值就可以。
可以使用reward模型或者采用大模型。因为在强化学习中奖励信号是非常重要的,它决定着模型的改进方向。可以认为reward模型就是当前大模型的老师,因此你不可能采用一个能力比当前大模型弱很多的模型来指导当前大模型该怎么改进,一般都采用和当前大模型差不多或者比当前大模型能力更高的大模型来训练reward模型和当前大模型差不多能力的大模型。为什么可以提供改进的监督信号呢?因为评价一个回答的好坏,总是比生成一个好的回答要容易很多。就比如你评判一篇文章写的是否好,总比让你自己写一篇好的文章要容易很多。而且实验发现随着模型输出能力的提升,它的评价能力也在提升。
那么这样是不是就可以一直无止境的提升大模型的能力呢?不是的,大模型的能力的极限是由大模型预训练时决定的。强化学习只是能让模型的能力尽可能地逼近极限。
那如何利用大模型来针对一个问答队给出得分呢?首先把问答拼接在一起作为输入。我们知道对于标准的大模型,每个token在大模型的输出层会通过LM head层。
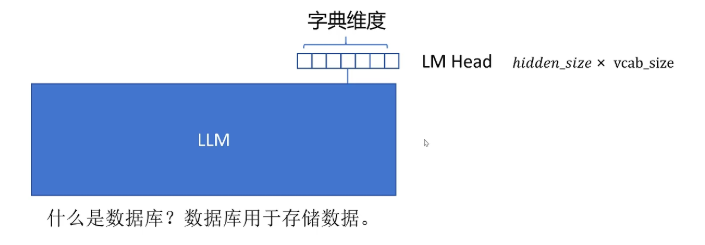
LM head层的输入维度是token的hidden size,输出的维度是字典的维度V。LM head的参数是所有token共享的,因为每个token的位置都需要预测下一个token。
当改造大模型作为一个reward模型时,需要一个score head。和LM head类似,它输入的维度是token的hidden size,但是输出维度只有1维,并且只对序列的最后一个token调用score hide。因为只有最后一个token,它能看到前面所有的序列,可以对整个序列进行评分。得到这个问答对的reward的值。

接下来我们继续讨论reward模型的loss。训练的数据集是一对比较数据,既包含chosen的回答也包含rejected回答。需要调用两次reward模型,分别得到模型对chosen和rejected的回答的得分,然后用chosen的得分减去rejected的得分,然后对差值调用log sigmoid函数作为loss值。
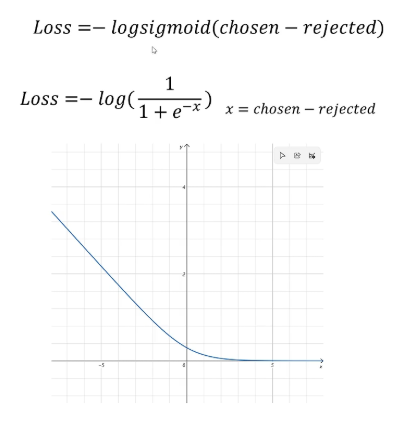
从log sigmoid函数的曲线可以看到,如果chosen的得分小于rejected的得分时,也就是差值为负时,损失值呈指数级增长。而当chosen的得分高于rejected的得分时,loss快速下降。
下边我们看一下如何利用hugging face TRL库里面的reward模型来训练一个reward模型。首先看一下数据,每一条数据都包含三个部分,question、chose、rejected。
{"question":"Python中的字典是什么?", "chosen":"Python中的字典是一种无序的可变容器,允许使用键-值对来存储数据。","rejected":"Python中的字典用于存储数据。"}
{"question":"什么是回归分析?", "chosen":"回归分析是一种统计方法,用于确定变量之间的关系,通常用于预测和模型拟合。","rejected":"回归分析是一种数据分析方法。"}
{"question":"如何优化机器学习模型?", "chosen":"优化机器学习模型可以通过调节超参数、选择合适的模型和特征工程来实现。","rejected":"优化模型可以提高性能。"}
{"question":"什么是机器学习?", "chosen":"机器学习是一种人工智能方法,通过算法和统计模型使计算机系统能够执行特定任务,而无需明确编程指令。","rejected":"机器学习是计算机科学的一个领域。"}
{"question":"Python的主要特点是什么?", "chosen":"Python的主要特点包括简洁的语法、强大的库支持以及跨平台的兼容性。","rejected":"Python是一种编程语言。"}
{"question":"如何进行数据清洗?", "chosen":"数据清洗通常包括处理缺失值、去除重复数据、标准化数据格式等步骤。","rejected":"数据清洗是数据处理的一部分。"}
{"question":"什么是数据库?", "chosen":"数据库是一个有组织的数据集合,允许高效的数据存储、检索和管理。","rejected":"数据库用于存储数据。"}
{"question":"深度学习和机器学习的区别是什么?", "chosen":"深度学习是机器学习的一个子集,主要通过神经网络处理数据,而传统机器学习算法不依赖于神经网络。","rejected":"深度学习是机器学习的一部分。"}
{"question":"如何使用Pandas加载CSV文件?", "chosen":"你可以使用Pandas的`read_csv()`函数来加载CSV文件,并将其转换为DataFrame。","rejected":"使用Pandas加载CSV文件。"}
{"question":"什么是自然语言处理?", "chosen":"自然语言处理是计算机科学与人工智能的一个子领域,专注于机器与人类语言的交互。","rejected":"自然语言处理是计算机科学的一部分。"}接下来看一下训练代码。首先是定义tokenize和model。注意这个模型的类型是序列分类模型——auto model for sequence classification。
import torch
from datasets import Dataset
import json
from peft import LoraConfig, TaskType, get_peft_model, prepare_model_for_kbit_training
from transformers import AutoTokenizer, BitsAndBytesConfig, AutoModelForSequenceClassification
from trl import RewardTrainer, RewardConfig
model_path = r'D:\work\models\Meta-Llama-3.1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.padding_side = "right"
tokenizer.pad_token = tokenizer.eos_token
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForSequenceClassification.from_pretrained(model_path,
num_labels=1,
quantization_config=bnb_config)
model.config.pad_token_id = tokenizer.pad_token_id
peft_config = LoraConfig(
r=8,
target_modules=["q_proj",
"v_proj",
"k_proj",
"o_proj",
"gate_proj",
"down_proj",
"up_proj"
],
task_type=TaskType.SEQ_CLS,
lora_alpha=16,
lora_dropout=0.05
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
items = []
with open("./data/preference.json", "r", encoding="utf8") as f:
for line in f:
item = json.loads(line)
items.append(item)
dataset = Dataset.from_list(items)
def process_func(example):
chosen = example["question"] + example["chosen"]
rejected = example["question"] + example["rejected"]
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
new_example = {}
new_example["input_ids_chosen"] = tokenized_chosen["input_ids"]
new_example["attention_mask_chosen"] = tokenized_chosen["attention_mask"]
new_example["input_ids_rejected"] = tokenized_rejected["input_ids"]
new_example["attention_mask_rejected"] = tokenized_rejected["attention_mask"]
return new_example
dataset = dataset.map(process_func, remove_columns=['question', 'chosen', 'rejected'])
print(dataset)
config = RewardConfig(output_dir="./reward_model")
config.num_train_epochs = 1
config.per_device_train_batch_size = 1
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
args=config,
train_dataset=dataset
)
trainer.train()
trainer.save_model("./reward_model")当分类为1时就是一个回归模型,可以输出单个连续值。以量化模型方式加载定义LoRA config。Config里需要指定训练的任务为sequence classification,然后为量化模型训练准备得到LoRA模型,然后是加载偏好数据,接着对数据进行处理。具体处理过程是将问题和回答拼接起来,包括chosen的回答和rejected的回答。然后分别对两个问答对进行分词,生成一个新的数据样本。这个数据样本里必须包含四项,分别是input_ids_chosen,attention_mask_chosen,input_ids_rejected,attention_mask_rejected。然后定义一个训练reward模型的config,这里可以指定模型输出的位置,训练的epoch,每个GPU上的batch size。然后定义一个reward trainer传入模型,tokenizer,reward config和训练数据集就可以调用trainer.train进行训练了。
接下来我们来讨论PPO模型的训练。首先讨论训练PPO时都涉及哪些模型。确切地说训练ppo时需要四个模型。

第一个是基准模型,一般是SFT之后的大模型作为基准。新训练的模型输出的概率分布不能和基准模型相差太大,基准模型输出是通过LM head,它的输入维度是token的hidden size输出是字典维度,然后根据概率抽样得到输出token。第二个是训练的模型,它的结构和基准模型是完全一致的。PPO训练的目标就是优化训练模型,同时模型输出的概率分布不能与基准模型相差太大。
第三个模型是reward模型,它来对一个问答序列进行评分,输出一个分数。它的输出是通过一个score head,输入维度是token的hidden size,输出维度是1,问答对序列的最后一个token的输出,通过score head计算后,得到的就是这个问答序列的得分。第四个模型是状态价值模型,它会对每个状态评估它的价值,也就是根据截止到目前的token序列,预测到序列生成结束后,这个问答序列它的期望回报是多少?它的输出是通过一个value head,输入维度是token hidden size,输出维度是1,和reward模型不同的是,它需要对每个token都输出截止到当前token期望的回报是多少,每个输出的token都共享这个value head的权重。
这四个模型除了各自最后一层的head不同,底层都是大模型。如果训练时同时加载四个大模型,那显存占用就太大了。我们之前讲过,LoRA训练它并不改变原始大模型权重,只是改变少量的LoRA参数来达到对模型的微调。每个LoRA模型都可以称为是原始大模型的一个adapt。这里可以通过只加载一个大模型多个adapt的技术,大大减少训练时对显存的占用。并且可以将训练的模型和状态价值模型合并,共用一套adapt的LoRA参数。它同时有两个头,分别是LM head和value head。通过这样的精简就达到只需要在显存里加载一个大模型和2个LoRA参数的adapt来训练ppo算法。
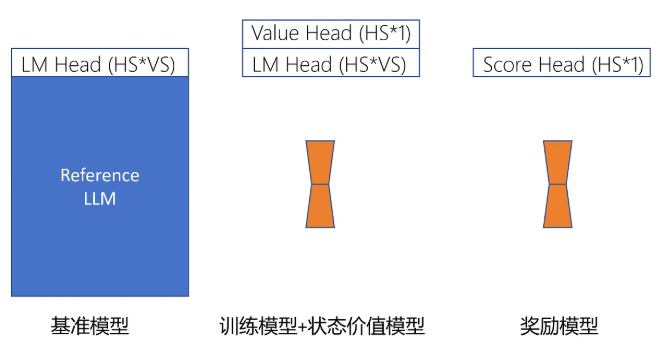
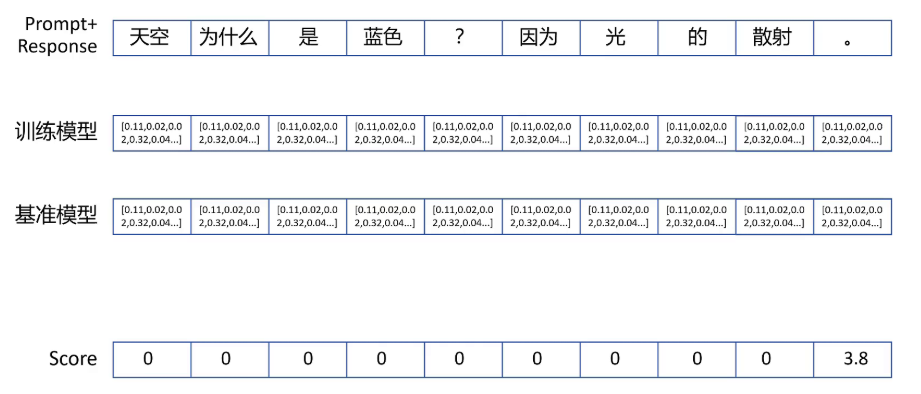
对于大模型输出的每一步而言,它的state就是截止到当前token的序列,action就是接下来输出的token。大模型就是那个策略函数,根据当前的state,也就是截止到当前的token序列做出action,也就是输出下一个token。但是reward的模型只针对完整输出给出一个得分,并不是对每个token都会给一个得分。所以score只是给最后一个token的,其他所有token的score都为零。
之前强化学习时我们讲过,reward是可以自己设定的,我们给每个token可以增加一个奖惩项,让它输出的概率分布和基准模型之间的KL散度相关。针对每个当前token,大模型通过LM head会输出字典里每个token作为输出的概率。在同样的state下,训练模型输出的action的概率分布如果如果和基准模型概率分布不一致,就会受到惩罚。分布越不一致惩罚越大。这里有一个调整系数,我们设置为-0.2。所以训练模型做出每一个action,也就是输出每一个token的reward,就等于它输出的概率分布相对于基准模型输出的概率分布的KL散度*-0.2,再+score。
接下来看一下GAE优势函数如何计算。这是我们在之前PPO视频里讲过的GAE函数的计算公式。它还有一种迭代表达方式,当前步的GAE等于当前步的delta加上gamma * lambda乘以下一步的GAE,这种迭代表达方式和上面的公式是完全等价的,但是更适合编程实现。

下面就是huggingface TRL库里计算GAE优势函数的代码,可以看到它是从后向前计算,计算每一步的delta,然后计算当前步的优势函数,它等于当前步的delta加上gamma * lambda乘以下一步的GAE。再来看训练的loss,要知道我们现在在同时训练两个模型,一个是做文本输出的大模型,一个是输出每个token状态价值的模型。
首先我们来看状态价值网络的loss。要计算状态价值网络的loss,首先需要知道状态价值的label是什么?
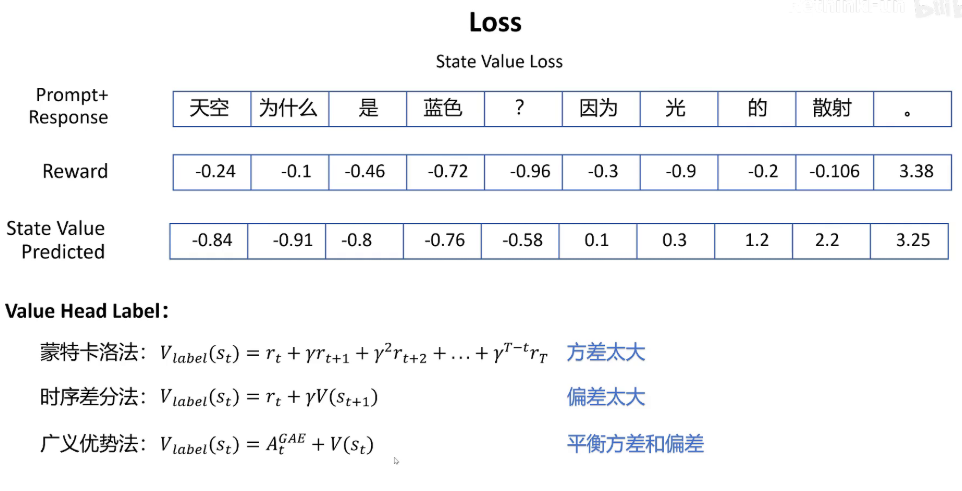
生成每个token状态价值的label有3种方式,第一种是蒙特卡洛法,他认为整个问答序列是一次随机采样,然后统计当前token后面序列的reward的衰减累积值作为label。因为这个序列是一次随机采样得到的,所以label值的方差很大。
第二种方法是时序差分法,它只采样一步,当前部状态的价值函数等于采样一步得到的reward + 衰减因子 * 下一步的状态价值。因为增加了一步采样的事实部分,所以它可以提供监督学习的信信号。采样一步的好处是减少了label的方差,但是依赖于当前状态价值网络的估计会带来大的偏差。
第三种方法就是广义优势法,它就是我们之前在讲PPO算法时讲到的GAE优势函数加上当前步的状态价值估计值。GAE优势函数表示每一步状态做出当前动作的期望回报减去当前状态的期望回报。所以GAE加上当前部的状态价值就等于当前部采样当前动作的期望回报。因为GAE计算当前动作的期望回报时,考虑了一步采样、两步采样到多步采样,所以它平衡了方差和偏差。Hugging face TRL库里对于状态价值网络的雷保值的计算就采用的是广义优势法。
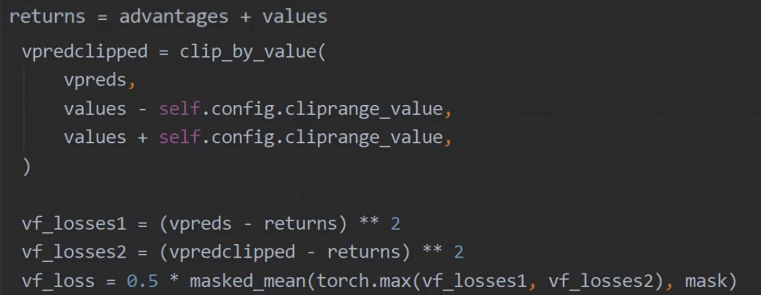
我们看一下具体的代码实现。首先计算每一步的期望回报等于advantage加上状态价值,用它作为每一步状态价值的label。首先看VF loss 1,它就是状态价值网络的预测值与label之间的误差的平方和。另外为了让训练稳定,引入了一个clip的截断值,就是预测状态价值不能和重要性采样网络预测的状态价值变化太大,变动必须在一个范围内,超过这个范围就截断,然后计算出VF loss 2的值。最终状态价值网络的loss就是loss 1和loss 2里按位取最大计算均值,再乘以0.5。这里乘以0.5是为了求导时和平方项的2约掉。
下面讨论一下PPO的loss。这是我们之前讲解PPO算法时的loss的公式。但实际代码实现里有两点不同。

第一点,进行重要性采样的模型可以和参考模型不一样。第二点,KL散度已经在reward里体现了,它已经通过reward进入了loss函数,所以可以去掉loss函数里面最后关于KL的这一项。所以最终代码里的PPO loss的公式如下,这里需要注意以下几个网络。
θ表示我们正在训练的网络模型。θ一撇是我们的基准模型,训练的模型输出概率分布不能和基准模型输出的概率分布相差太大。θ两撇是进行重要性采样的模型,它会在训练过程中逐步更新,一直保持和训练模型相差不大,这样才能更有效的训练我们的模型。我们之前讲PPO时讲过,重要性采样的模型不能和训练模型相差太大,否则训练网络就没有什么可以学习的。
最后看一下PPO loss的实现,首先计算训练网络与重要性采样网络输出概率的比值,然后乘以负的优势值,这就是PPO loss的值。同样为了训练的稳定,训练网络和重要性采样网络输出的概率比值不能相差太大,否则就进行裁剪,作为Pg loss 2,最后按位取Pg loss和Pg loss 2中较大的值计算均值作为最后的PPO loss。总的loss等于PPO loss加上状态价值网络的loss乘以一个调节系数。
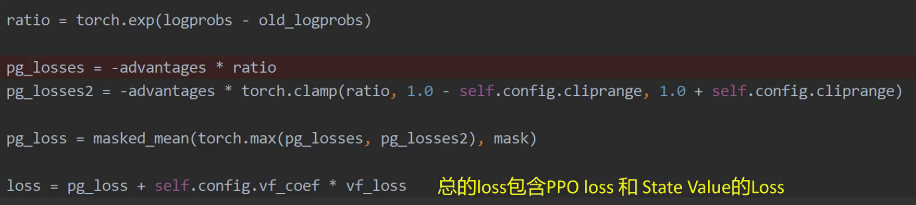
最后我们通过一个PPO的训练循环的伪代码再来梳理一下思路。为了伪代码看起来更简单,这里对loss部分做了简化。首先从prompt数据集里取出一个prompt data,然后利用重要性采样网络,也就是当前训练网络进行回答的生成。接着把问题和回答进行合并生成训练文本。利用reward模型对训练文本进行打分,接着用重要性采样网络计算,针对整个字典所有token的概率分布all probs,还有作为输出token的概率probs,以及每个token的状态价值。然后同样计算基准模型的all probs,probs,all values, 接着计算KL散度reward advantage returns,returns的值等于advantage的值加上重要性采样网络输出的状态价值。
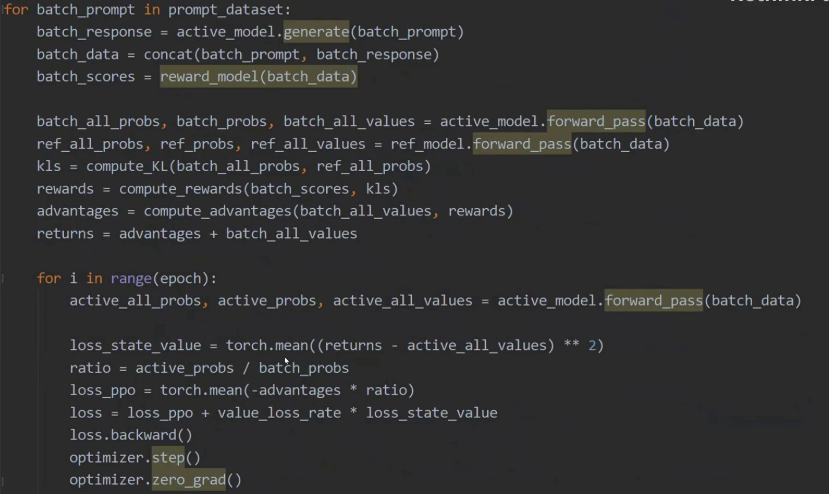
下面可以看到对于一个batch的数据要训练epoch。每一次训练都用训练网络生成all probs,probs,all values, 然后计算状态价值网络的loss,接着计算训练网络和重要性采样网络。在每个token的概率比值,比值乘以负的advantage就是PPO loss,最终的loss是状态价值网络的loss加上PPO的loss,进行反向传播更新参数。然后进入下一个batch数据的训练。
Batch数据是外循环,训练epoch是内循环。每次用当前训练的模型作为重要性采样的模型,计算advantage,然后利用这个advantage训练epoch模型,过程确实很复杂。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)