一文搞懂RAG到底增强了什么?大模型落地的场景:RAG和Agent!
1、基于RAG开发的背景
大模型的产生伴随着两大问题:大模型知识冻结;大模型幻觉。
首先,大模型的训练基于语料知识库等,这些内容存在一定的时间壁垒,当越过这一节点再询问大模型,就会出现知识冻结现象;其次,LLM在针对自己陌生的领域答复能力有限,但是还是会给出用户一些自己“编撰”的答案,这就是幻觉问题。
RAG就可以非常精准的解决这两个问题。
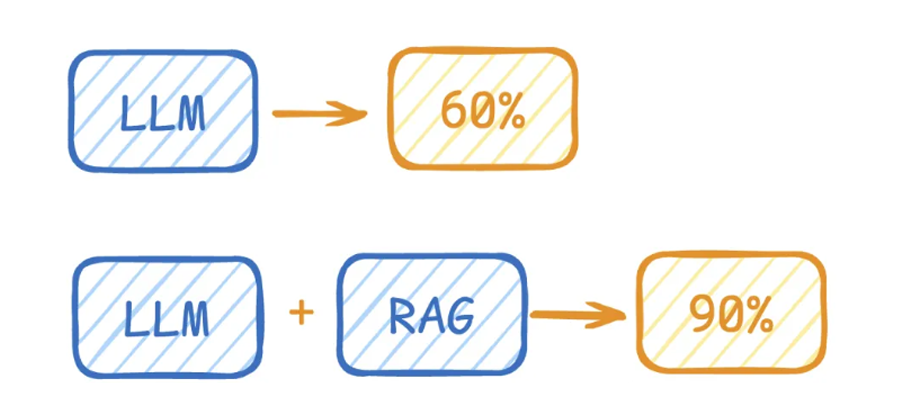
如果大模型只是根据自己训练数据进行回复,正确率可能仅为60%,此时RAG给出一些提示和思路,大模型就会往这个方向考虑,正确率或许会达到90%。
2、什么是RAG
RAG全写是 Retrieval-Augmented Generation(检索增强生成),下面通过一张图来说明:
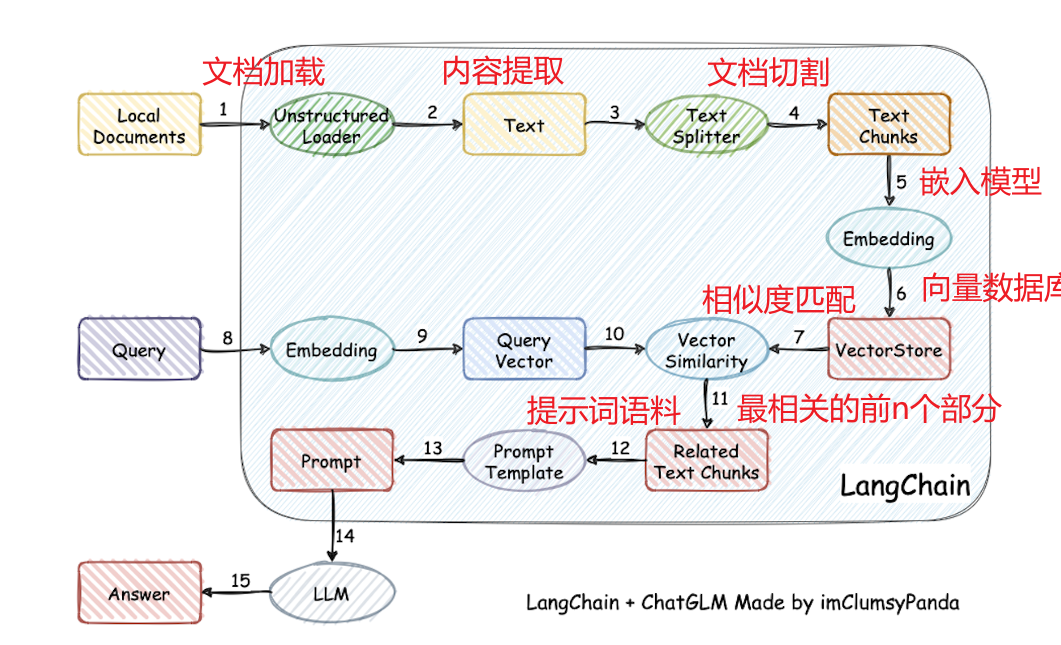
该图完整表示了检索-增强-生成的过程,第十步可以理解为检索,第十二步是增强,最后一步十五步是生成。以上过程有三个位置需要使用大模型:向量化时(Embedding Models)、重排序时(Rerank Models)、生成答案时(LLM)。
在此过程中文件解析、文件切割、知识检索、知识重排序是难点。
- 文件解析:格式多样复杂,PDF、图片等非结构化数据中的表格、多栏、页眉页脚极易解析错乱或信息丢失,导致后续处理的是垃圾信息;
- 文件切割:难在保证语义的完整,简单按长度切割会切断完整句子或者段落,导致检索到的片段语义残缺,大模型无法理解;
- 知识检索:难点在于语义鸿沟,用户的问题与文档用词可能完全不同(减肥和卡路里),只是依靠关键词或向量检索很难保证每次都能够精准命中用户的意图;
- 知识重排序:难在精准校准与效率的平衡,开始结果噪声多,要精细重排,而高质量的重排又会导致计算成本过高。
重排序的适用场景:
适合追求回答高精度和高相关的场景。例如专业知识库或客服系统等应用。不适合服务对响应时间要求高的场景,因为引入重排序会增加召回时间,增加检索延迟。
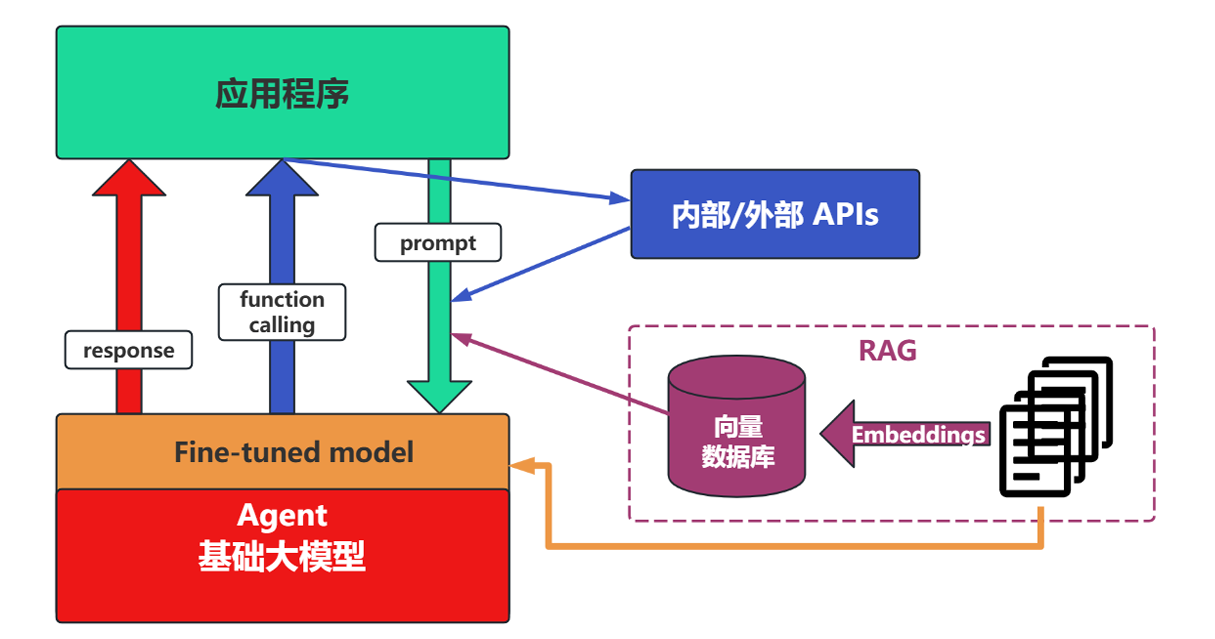
3、基于Agent架构的开发
该架构就是充分利用LLM的推理能力以及决策能力,通过增加规划、记忆、工具调用的能力,构造一个能够独立思考、逐步完成给定目标的智能体。
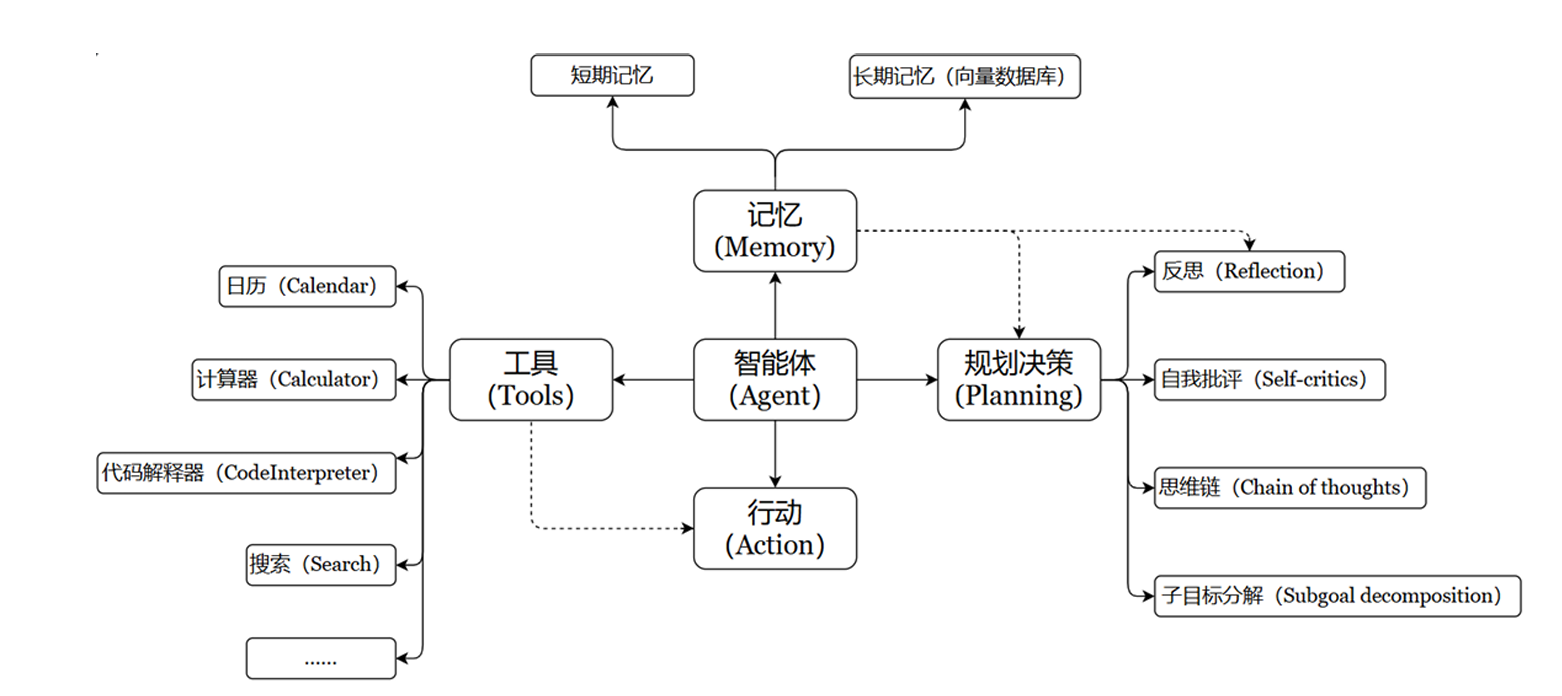
根据上图,用一个数学公式来表示Agent就是:
Agent = LLM + Memory + Tools + Planning + Action
- 大模型LLM:是智能体的大脑,提供推理、规划和知识理解能力,是决策中枢。
- 记忆Memory:使得智能体处理重复工作时调用之前的经验,避免用户进行大量重复交互;记忆又分为短期记忆(存储单次对话周期的上下文信息,属于临时信息存储机制,具体的长度受制于上下文窗口的长度)和长期记忆(可以跨越多个任务或时间周期,可存储并调用核心知识,非即时任务)。
- 工具使用Tools:调用外部工具(API、数据库)扩展能力边界。
- 规划决策Planning:通过任务分解、反思与自省框架实现复杂的任务处理,例如:思维链拆解难题。
- 行动Action:实际执行决策的模版,包含软件接口操作(点外卖)以及物理交互(机器人搬运东西)。
对于长期记忆,可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库(相似性检索)的方式实现。
4、大模型开发的场景
(1)纯Prompt
用户问一句,模型回答一句,prompt是操作大模型唯一接口。
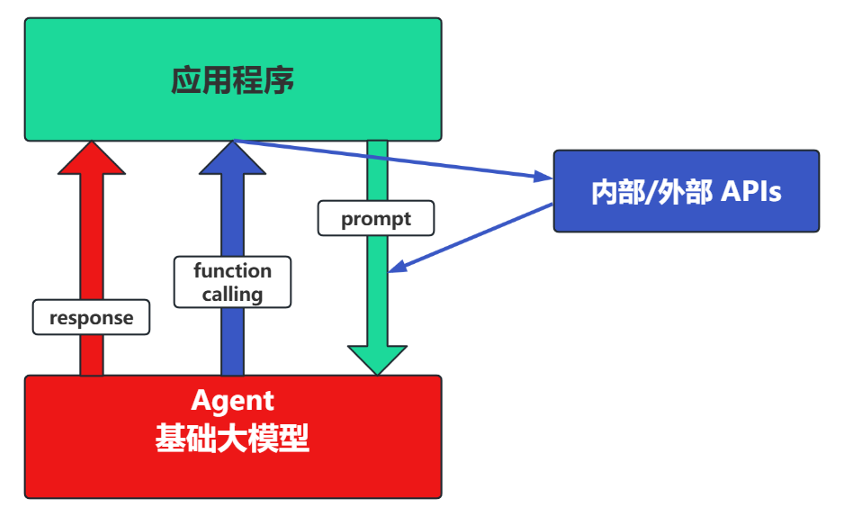
(2)Agent + Function Calling
- agent:AI提出要求;
- Function Calling:需要对接外部系统时,AI要求执行某个函数;
- 举例:你问模型明条要求某地出差,需不需要带伞?模型会先调用外部接口查看是否会下雨在回答你是否需要带伞。
(3)RAG
在需要补充领域知识时使用,智能客服上应用最大,好比开卷考试一样。
![]()
(4)Fing-tuning(精调、微调)
举例:努力学习考试内容,形成长期记忆,活学活用。他和RAG区别就是前者属于外挂知识库,它属于将知识写入到模型自身。
缺点:成本过高

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)