【跨模态一致性增强模块+开源代码】定位与验证:一个提升深度伪造检测的双流网络
论文总结
1、有开源代码“https://github.com/sccsok/Locateand-Verify.” (Shuai 等, 2023, p. 1)
2、这篇论文主要是做深度伪造图片鉴别的,用到了RGB和SRM(Spatial Rich Model)残差两个数据,SRM用于捕获高频噪声和伪造残留。并且提出了交叉模态一致性增强、本地伪造引导注意力机制、多尺度补丁特征融合,并且根据同一图像块应该具有一致性,伪造区域块特征应该相似,提出了弱监督式补丁相似性学习。
3、交叉模态一致性增强部分,在做跨模态融合与对齐时,可以借鉴。但从数学公式上来看,它要求输入的两个模态具有相同的channel,height和width,以便于进行逐元素融合和一致性约束。这对于两个模态维度不一致时,可能不太适合。
4、提出了局部定位和验证真假两个阶段,防止模型只看背景,提升泛化能力,避免只依赖少数伪造区域。
摘要
深度伪造风靡全球,引发了信任危机。当前的深度伪造检测方法通常在泛化性方面不足,容易对图像内容如背景进行过拟合,而这些内容在训练数据集中虽然常见但相对不重要。此外,现有方法严重依赖少数主要伪造区域,可能忽略其他同样重要的区域,导致伪造线索的发现不足。本文旨在从三个方面解决这些不足:(1)我们提出创新的双流网络,有效扩大模型提取伪造证据的潜在区域。(2)我们设计了三个功能模块,以处理协作学习方案中的多流和多尺度特征。(3)面对获取伪造注释的挑战,我们提出一种半监督式补丁相似性学习策略,用于估算补丁级伪造位置标注。实证上,我们的方法显著提升了鲁棒性和泛化性,在六个基准测试中优于以往方法,并将深度伪造检测挑战预览CelebDF_v1数据集的帧级AUC从0.797提升至0.835,视频级AUC从0.811提升至0.847 。我们的代码实现在 https://github.com/sccsok/Locateand-Verify。
引言
在过去十年里,我们见证了深度学习在多个领域的成功[33, 50, 52, 54, 55],尤其是深度伪造技术作为激发创造性表达的重要催化剂。然而,这项技术的可及性,得益于众多现成工具,如Face2Face、FSGAN和SimSwap[5, 38, 49],也引发了人们对伪造虚假视频、伪造言行的滥用担忧[35, 39, 46]。例如,2022年3月,黑客制作了一段乌克兰总统泽连斯基发表演讲呼吁士兵投降的假视频,在美国总统选举期间,一段前总统奥巴马挑衅总统候选人特朗普的深度伪造视频被流传。这些事件远非普通的奇观,其潜在的社会政治和安全影响过于重大,无法忽视。毫无疑问,能够精确且自动识别假视频对于减轻这些威胁非常重要。深度伪造检测的核心是识别真实图像与合成图像之间的细微差别。第一类检测方法[15, 20, 28, 45, 57, 60]利用伪造的语义视觉线索,如异常混合边界[28]和面部不一致[20]。另一条研究路线[26, 32, 53]基于特定领域特征,例如频谱图中的上取样伪影[32],这些伪影会根据图像的真实性而变化。在仔细审视现有方法的已发布实现时,我们实证观察到现有方法仍存在两个问题:(1)随着深度伪造技术的进步,这些可感知的视觉伪影显著减弱,可能影响深度伪造检测的可靠性。(2)某些方法仅关注特定图像区域,如边界[28, 43]、口部和眼睛[13, 20, 34],可能忽略了伪造线索丰富的其他区域。此外,这些方法在未见数据集上的推广性不足,如深度伪造检测挑战预览基准数据集的低性能,凸显了该领域亟需进一步改进。表现最好的模型在 FaceForensics++ 数据集上训练时仅达到 0.797 帧级 AUC,仍有较大改进空间。合成面孔上的伪造线索通常分布不均,大多数区域保留了纯净的图像内容,伪造线索常出现在合成区域[14, 15, 28, 37]。因此,深度伪造检测的关键在于正确识别伪造区域。有趣的是,我们对Xception模型[41]提取的特征进行了显著性分析,该模型通常被用作深度伪造检测的骨干,如图1所示。我们发现Xception模型的响应普遍分布广泛,可能涵盖非伪造甚至非面部区域,适用于数据集内和跨数据集场景。然而,对于预测准确的情况,模型在成功揭露伪造时,无意中会关注控的区域。我们可以将现有深度伪造检测方法的缺点归因于它们倾向于专注于特定的视觉线索和领域特异性,而未能识别其他控的区域,从而无法最大限度地发现伪造证据。基于这些见解,我们建议明确定位伪造区域作为中间目标,指导伪造检测任务。我们采用两种输入流,分别是RGB图像和空间富裕模型[18](SRM)滤波图像,后者常作为RGB图像的补充输入,用于捕捉高频成分。我们提出一个跨模态一致性增强(CMCE)模块,协同学习结合表征并保留每种模态的信息特征[6, 16]。随后,这一组合特性会通过两个下游网络传递,即本地化分支模块用于检测所有可能的伪造区域,并有一个分类分支,基于检测到的伪造区域提取伪造线索,这得益于我们的本地伪造引导关注(LFGA)模块。由于伪造位置标注通常不可得,我们提出一种半监督式补丁相似性学习(SSPSL)策略来估算补丁级伪造位置标注。我们还设计了一个多尺度补丁特征融合(MPFF)模块,允许在两个下游网络的浅层捕捉显著伪影,同时保持每个图像补丁的位置一致性。我们的模型提取出的显著特征示例见图2,表明我们的方法能够定位重要的伪造区域。为了评估我们方法的有效性,我们在六个广泛使用的基准数据集上进行了大量实验,分别是FaceForensics++ [41]、两个版本的CelebDF [30, 31]、DeepFakeDetection [2]、Deepfake Detection Challenge 预览[11]和DeeperForensics 1.0 [23]。无论是否使用伪造位置标注,我们的方法表现良好,并且在对未见伪造的推广方面远胜以往方法。总结来说,本研究的主要贡献如下:• 我们提出了一个创新的深度伪造检测框架,有效聚焦于潜在伪造区域,以捕捉伪造检测所需的足够证据,同时对未见伪造进行了显著的推广。• 我们提出三个功能模块,充分利用RGB图像和SRM噪声残差,结合多模态特征和多尺度补丁特征。• 我们设计了一种半监督式斑块相似性学习策略,以有效监督伪造区域的检测,尽管此类注释不可得。
相关工作
深度伪造检测通常被视为二元分类任务,过拟合严重影响模型在未见数据集上的泛化性能。在此背景下,一些研究[17, 26, 32, 36, 37, 40, 47, 53]扩展了面部语义特征,并提出通过高频特征检测伪造伪造伪造,这些特征在纹理内容中难以识别。Das等人[10]提出了动态数据增强,以缓解对显著语义视觉伪影的过拟合问题。多注意力[56]将伪造检测表述为一个细粒度分类问题,并提出了多注意力机制以增强纹理和语义特征。Xception-Reg [9] 利用注意力机制突出显示信息区域,从而改进二元分类。尽管这些方法在数据集内取得了良好结果,但在跨数据集中的评估则不尽如人意。大量文献[15, 16, 19, 28, 43, 45, 57, 60]探讨了伪造的语义视觉线索,以弥补单一分类特征的局限性。《面部X光》[28]强调了混合作为面部交换中常见的作,并试图揭示融合的证据,以支持控行为。Chen 等人[4]通过分析面部特征(包括眼睛、鼻子和嘴巴)以及融合比例,更详细地探讨了基于融合的伪造。SBIs [43] 通过综合技术开发了自混合图像的专有数据集在[28]中进行方法,避免对作特定伪影的过拟合。[6, 19, 45, 57, 60] 通过识别图像中的不一致来确定图像真实性,并提出局部图像补丁的一致性丢失。此外,[8, 15, 22] 利用了被处理图像的身份不一致,SOLA [16] 通过增强局部斑块差异捕捉伪造异常。LipForensics [20] 提出一个时空网络,用于学习口腔运动中的高级语义不规则性。然而,复杂的合成和后处理方法可能会削弱这些伪影,同时专注于少数特定伪造区域,忽略了其他可能的伪造线索,从而降低了它们对特定数据集的适用性。我们的方法不同于上述方法,我们不局限于那些主要由早期深度伪造生成算法固有缺陷引起的固定伪影——如边界混合、补丁不一致、面部不一致、上采样伪影等。我们计划明确识别被处理图像中的潜在伪造区域,以便提取伪造证据,同时最大限度减少非伪造区域(如重复背景)的干扰。
方法论
我们通过有效识别所有潜在的伪造区域,解决构建通用面部伪造分类器的问题,从而发现足够的伪造物。通常,合成人脸的不同部分会因面部作技术产生的伪造伪造痕迹分布不均,有些区域包含大量伪造线索,而另一些区域则未被处理,保持了原始的图像内容。自然,有效定位潜在控区域对伪造检测非常有用。因此,我们提出明确建模此类区域的检测过程,设计一个由定位分支和分类分支组成的双流框架。定位分支判断图像补丁是否包含伪造,这为分类分支提供了一个注意力加权的指导,使其能够专注于更可能的伪造补丁,以揭示伪造线索。我们提出的框架概述见图3。首先,我们采用双重流输入,即RGB图像及其相关的空间富模型(SRM)[18]噪声残差,因为SRM更能捕捉对图像取证至关重要的高频特征。我们通过跨模态一致性增强(CMCE)模块将两种模态结合,获得组合特征表示。随后,该特征会经过两个下游网络,即检测图像补丁可能伪造的定位分支,以及分类分支,分类分支通过提取伪造线索来判断图像是否被篡改。我们提出了一个局部伪造引导注意力(LFGA)模块,该模块从位置分支推导出注意力图,以增强分类特征的提取。为了提升多尺度的信息保留,我们还为每个分支设计了多尺度补丁功能融合(MPFF)模块。此外,由于伪造位置注释短缺,我们还实施了半监督式补丁相似性学习(SSPSL)策略。接下来我们将讨论我们方法中每个关键组成部分的细节。
跨模态一致性增强
我们的CMCE模块通过协作学习,学习RGB和SRM模态的组合表示。与以往方法[6, 16, 37]不同,我们避免通过直接连接或注意力加权增强来合并两种模态。相反,我们力求确保两分支尽可能保留各自的特性,同时捕捉两者之间的相互作用与互动。具体来说,CMCE模块的输入包括RGB模态特征映射Fr ∈ Rc×h×w和SRM模态特征映射Fh ∈ Rc×h×w。我们通过逐元素的内积计算跨模态一致性映射:

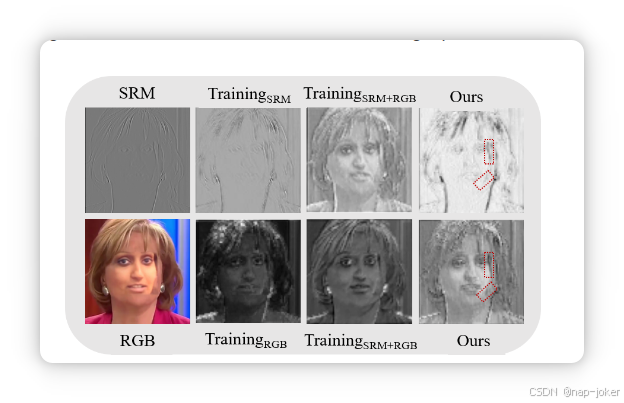
下图展示了原始图像、单模态输入的特征(TrainingSRM和TrainingRGB)、两种模态的直加特征(TrainingSRM+RGB)以及CMCE的特征。从图中我们可以观察到:(1)CMCE模块学习的伪造特征比单一模态更丰富。(2)它还保留了两种模态的独立且代表性的特征。SRM模态的差异更为明显,尤其是两种模态的直接求和会导致SRM和RGB特征非常相似。
本地伪造引导注意力
评估图像是否被篡改的关键在于有效收集证据。如引言所述,现有方法中常见的失败案例是这些模型大量依赖未作的图像区域来进行预测。因此,我们认为解决这一问题的有效方法是训练模型,提高信心地识别任何控的区域,从而更好地提取法医证据。为此,我们明确包含了一个定位可能伪造区域的本地化分支。我们采用本地伪造引导关注(LFGA)模块从位置特征来获得关注的映射,指导学习更稳健且信息丰富的分类特征。具体来说,我们将定位分支的中间特征映射记为Fl ∈ Rc ̃×h ̃×w ̃,分类分支的中间特征映射为Fc ∈ Rc ̃×h ̃×w ̃ 。我们首先学习自注意映射 Att ∈ Rh ̃w ̃ ×h ̃w ̃ 用于 Fl:
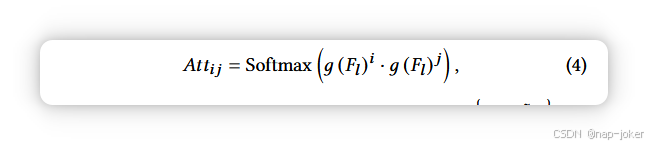
其中g表示线性变换,i、j ∈n 1、...、h ̃w ̃ o为指标。自注意映射Att识别具有相似特征的图像斑块,并对应伪造可能性的显著性表示。然后对分类特征图Fc施加变换h,然后与注意力图Att进行矩阵乘法,以增强分类特征的定位感知信息:
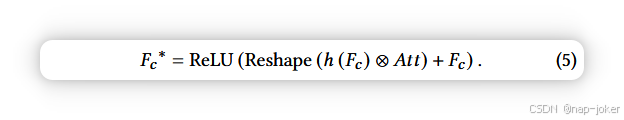
我们还对N = 3次应用LFGA模块。这使得对位置增强分类特征Fc ∗实现了多尺度学习。
多尺度补丁特征融合
许多现有的深度伪造检测研究未能利用伪造方法产生的伪影在浅层特征中更为突出的事实。例如,如图4所示,图像混合产生的痕迹在视觉上非常突出。以有力方式发现此类遗物的一种策略是对两个分支进行多重尺度的考察。总体而言,分类特征关注全局语义信息,定位特征关注局部空间细节。此外,必须为每个图像补丁保持位置信息,因为它在模型中起着关键作用。为此,我们设计了两个多尺度的补丁特征融合(MPFF)模块。对于局部化分支,我们将最后一层特征表示为Fl ∈ Rc1×h1×w1,中间特征映射为Fml ∈Rc2×h2×w2(h2 > h1,w2 > w1)。由于多层后感受野的扩展,Fl 可能失去对 局部区域的区分能力。因此,我们将 Fml 空间划分为 h1 × w1 个非重叠的片 Pk,且需要零填充,其中 k = {1, ..., h1w1}。然后我们计算不同尺度特征Fl和Fml的补片内一致性映射F ′ ml∈Rh² ×w²,具体如下:
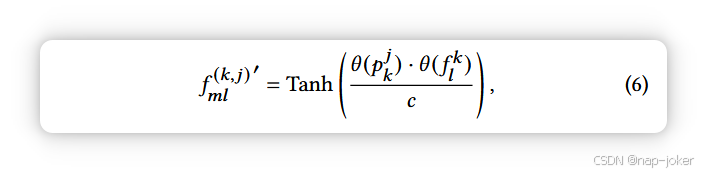
其中 p j k 是 Pk 的第 j 个特征向量,f k l 是 Fl 的第 k 个特征向量,θ 是由 1 × 1 个卷积实现的嵌入函数,c 是嵌入维数。F′ ml最终被重新塑形为与Fl相同的比例尺(h1,w1)。我们对所有中间特征进行作,并与 Fl 连接,得到最终的多尺度局部化特征 F ′ l 。最后,我们将F ′ l传递到由单个1x1卷积层组成的预测头。为保持不同尺度图像斑块间的空间关系,我们采用低秩双线性池化[24]来整合分类特征。分类流中的特征F∗c通过卷积块处理,所有浅层特征通过平均池化并串联,重新调整为与F ∗c相同的尺度,∈Rc∗ ×h∗ ×∗w,记为Fs∈Rcs ×h∗×w∗。我们得到一个最终分类特征为:
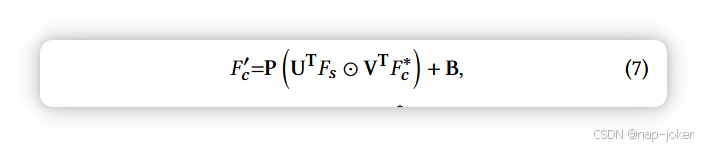
其中P∈Rn×m,U∈Rcs ×m,V∈Rc∗×m是学习型投影矩阵,B∈Rn×h∗×w∗是偏置映射。F ′ c 输入标准分类头以预测最终结果。
半监督式补丁相似性学习
由于大多数公开深度伪造数据集不包含伪造位置的注释,我们设计了一种半监督式补丁相似性学习(SSPSL)策略来训练本地化分支,灵感来源于 [12, 21]。真实图像的伪造位置图总是固定为所有零。对于假图片,我们可能无法获得伪造注释,但我们的分析可以确定鼻子、眼睛和嘴巴等特定面部区域控过,这些区域也被视为伪造检测的敏感区域。因此,我们可以近似地选择敏感面部斑块的特征,以表示控面部区域的分布。具体来说,我们首先利用面部标志来检测假图像的鼻子位置,并将一个矩形区域指定为作区域,如图5所示。我们将一批中所有真实图像视为正样本,将所有经过作的假图像区域视为负样本。我们表示 fr ∈ Rc×1×1,表示真实样本的平均锚点,fa ∈ Rc×1×1 表示假样本的平均锚点,Ff 表示假样本中的特征映射。然后我们通过逐元素内积得到 Ff 和 fr 之间的相似映射 Sf r:
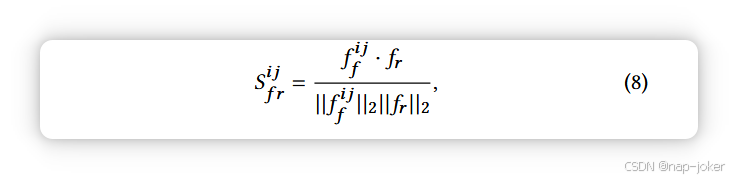
其中(i, j)索引Ff中的空间位置。同样地,我们通过对每个局部-全局对 f ij f 和 fa 执行相同的作,得到相似映射 Sf f。因此,对于假图像,我们将预测位置注释M ∈ Rh1×w1定义为二元比较映射。当 S ij f 靠近 fr 时,该补丁预测不含伪造;否则,它被视为含有伪造品。该过程形式化为:
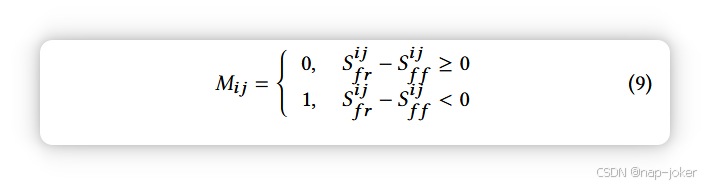
损失函数
对于分类流,我们使用交叉熵损失来监督最终预测概率,对于局部化流,注释可以通过前述小节中提出的SSPSL估计,或通过原始数据集给出的像素级注释M确定。对于后者,我们将 M 分为 h1 × w1 个不重叠的片块,然后通过对每个 patch Pk 的所有取值取平均得到对应的标签 Mk (k = 1, 2, ..., h1w1) :
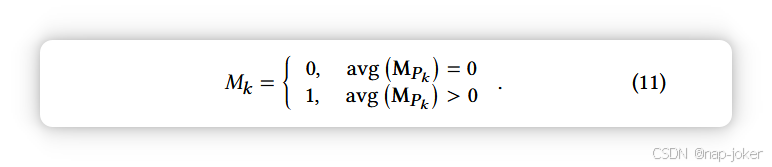
假设 ˆM 是预测位置图,预测的准确性通过交叉熵损失来衡量。最后,我们可以以端到端方式训练模型。
实验
数据集。我们在六个常见伪造数据集上评估模型:Faceforencis++ [41](FF++)、两个版本的Celeb-DF [30, 31](CD1和CD2)、DeepFake Detection Challenge Preview [11](DFDC_P)、DeepFakeDetection [2](DFD)和DeeperForensics-1.0 [23](DFo)。我们的实验使用了高质量版本(c23)的FF++,其中包含4000个伪造视频,由四个算法生成:DeepFakes [3](DF)、Face2Face[49](F2F)、FaceSwap[1](FS)和NeuralTextures [48](NT)。在数据预处理中,我们将FF++数据集的官方注释与原始视频对齐,并提取面部裁剪。实验中的所有面孔都裁剪为299×299,并统一归一化为[0, 1]。我们使用了一些常见的增强效果,比如翻转、对比和模糊。此外,我们使用随机裁剪来增加伪造区域的多样性,以确保注释与图像的对齐。训练方面,我们采用了预训练权重初始化的骨干Xception [7],并使用Adam [25]优化器,β值为0.9和0.999,以及ε 1e-8。初始学习率设定为5e −4,每五个时代衰减50%。由位置流预测的伪造地图大小设置为19 x 19。MPFF模块中的超参数m和n分别设置为2048和4096。所有实验均通过PyTorch在配备NVIDIA RTX 3090 24GB的平台上实现。
评估
数据集内性能。在数据集内评估中,我们将模型与FF++上最先进的方法进行基准对比。结果见表1,其中Ours-semi表示在训练过程中,SSPSL模块用于估计伪造注释。从第1页我们观察到,我们方法的结果优于之前已取得显著性能的方法。具体来说,我们的方法在AUC方面比最佳竞争对手DCL高出0.5%。我们的半监督获得了与监督模块类似的结果,部分证实了SSPSL模块的有效性。跨数据集性能。在跨数据集环境中评估泛化性能对于现实应用至关重要,因为图像可能源自未知或不确定的伪造方法。尽管现有方法在数据集内环境中取得了良好效果,但其鲁棒性和泛化性在跨数据集检测中仍是主要缺陷。首先,我们在DF、F2F、FS和NT上评估模型,我们的方法,包括采用SSPSL策略的较弱模型,在大多数情况下都优于竞争对手,尤其是在平均AUC方面。例如,我们的模型显示四个子数据集的平均AUC显著提升超过5%。我们还用最先进的深度伪造检测方法评估模型。我们的模型基于FF++训练,并在未见数据集上测试,包括CD1、CD2、DFD、DFDC_P和DFo。帧级和视频级AUC的实验结果见第3页。我们有两个观察:(1)现有深度伪造检测方法在未见数据集上的表现仍然不理想;(2)我们的方法在帧级和视频级评估中均优于最佳竞赛。例如,我们的方法将CD2的帧级AUC从0.857(ICT [15])提升到0.860,DFDC_P从0.799(Luo.et.al [36])提升到0835。我们还报告了方法的分类准确率(ACC),以提供全面的检测评估。我们进一步评估了SSPSL策略在跨数据集上的泛化表现,结果见标签4。如图所示,缺乏现成的伪造注释导致半监督方法性能下降,但其结果在CD1、DFDC_P和DFD上仍优于最先进方法。例如,我们在CD1相比LiSiam[51]改善了1.9%的(0.811),比CD1改善了2.2%,比 Luo.et CD1提升了2.2%。AL [36](0.797)关于DFDC_P。我们的半监督方法在CD2上获得的帧级AUC低于ICT [15](0.857),但ICT是在模拟伪造方法创建的私有数据集上训练的,而我们仅使用FF++数据集中的标准训练集。结果显示,虽然最先进的方法在跨数据集环境中可能很好地泛化到特定数据集,但它们无法在所有这些数据集上保持一致地实现效果。相比之下,我们的方法在五个跨域数据集中持续显示出整体改进,这充分证明了其可推广性。通过明确定位并引导注意力于伪造图像中控区域,我们的方法有助于识别足够的伪造证据,同时最小化非伪造区域的干扰,从而减轻模型的过度拟合。可视化。我们的研究还延伸到方法的可解释性。我们首先对位置分支进行了分析。数据集。该模型基于FF++训练,并在训练数据集和未见数据集(CD2、DFDC_P和DFD)上进行评估。请注意,我们使用了补丁内填充,以确保位置地图的大小与图像相匹配。结果提供了有意义的观察,表明位置分支能够有效预测假图像中控的区域,即使是对不熟悉的数据。这对我们的模型意义重大,因为它确保了分类分支能够更精确地引导到这些重要区域。 我们进一步可视化了模型的分类特征,该模型在两个子数据集(FS和NT)上训练,随后在剩余三个子数据集上进行评估。梯度加权类别激活映射[42](Grad-CAM)图见图7。我们观察到,无论是跨域还是域内评估,我们的方法都有效且精准地聚焦于图像中含有显著伪造痕迹的作区域。不考虑图像背景,这表明这些重要区域被最终分类器高度重视。在图8中,我们展示了由我们模型用SSPSL策略预测的伪造注释。该模型在四个训练子数据集和四个未见数据集上进行评估。我们的观察如下:(1)SSPSL模块有效区分原始背景和作区域之间的贴片嵌入。(2)预测的注释能够熟练地突出假人脸控的区域。这进一步展示了SSPSL在培训本地化分支中的有效性。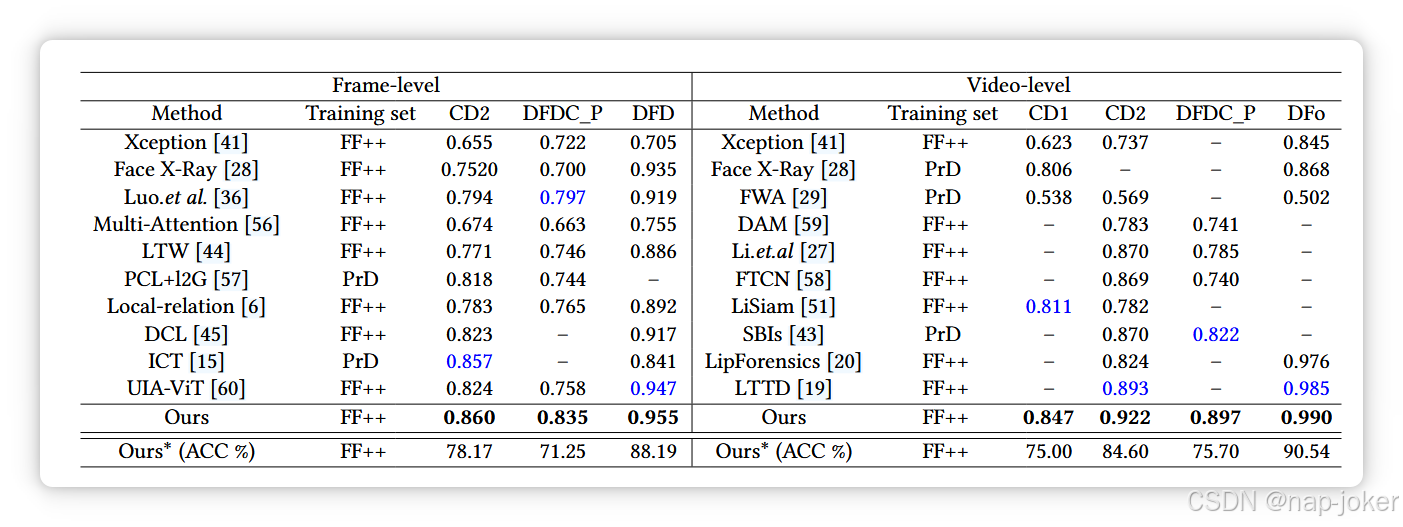
消融实验
我们首先评估模型中每个模块的效能,并开发了以下实验比较:1)RGB和SRM:Xception-Base带单模态输入;2)双流:双流模型,直接求和两种模态;3)双功率流:带有注意力加权模块的双流模型[6];4)我们模型中提出的CMCE、LFGA和MPFF模块。所有模型均在FF++数据集上训练,并在CD2和DFD数据集上进行评估。我们有以下关键观察:1)CMCE模块优于基础双流模型和基于注意力的模型。2)通过引入LFGA和MPFF模块,逐步增强了我们的模型性能。总体而言,与基础两流模型相比,我们的最终模型在CD2和DFD数据集上分别实现了2.0%和0.9%的AUC提升,ACC提升为3.56%和1.66%。我们进一步发展了SSPSL策略中选择的不同面部区域的实验。实验结果中,内面人脸被分配为由面部特征边界形成的矩形,FF++数据集中几乎所有像素都作。我们发现选择内面作为参考区域能获得更好的结果,但在处理未知数据集时,内面可能包含更多错误的实像素。因此,我们最终选择鼻子区域来表示控面部区域的分布。
结论
本文提出了一种创新的双流网络,对未见伪造进行了显著的推广,有效考虑模型从中提取足够伪造证据的潜在伪造区域。我们开发了三个创新模块:CME、LFGA和MPFF,以实现我们的目标。对于无伪造注释的数据集,我们还提出了半监督式补丁相似性学习策略以适应模型。大量实验表明,我们的方法在常用深度伪造数据集中优于其他竞争者,表明该方法在现实世界中是应对深度伪造潜在损害的可靠解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)