从基础配置到架构设计:JiuwenClaw 日报生成器开发实践
从基础配置到架构设计:JiuwenClaw 日报生成器开发实践
引言|当"日报自动化"真正走进日常工作场景
过去一年,AI Agent 的能力被讨论得很多。从简单的问答到复杂的工作流编排,看起来 AI 已经无所不能。但当我们真正把 Agent 带到日常办公场景时,会发现一个很现实的问题:
一个能对话的 Agent,并不等于一个能帮你自动化工作的助手。
在日常办公场景里,我们面对的不是简单的"问答交互",而是更多的重复性工作,例如:每天下班前要写日报、每周要汇总周报、每月要整理月度总结。这些工作虽然不复杂,但需要耗费大量时间和精力。
如果一个 Agent 只是"能聊天",那它只是一个有趣的玩具。
但如果我们希望它成为一套真正可交付的"工作自动化助手",那它必须具备三件能力:1.自动收集多源数据,2.智能分析工作效率,3.多渠道主动推送。
在这篇文章里,我会完整拆解:
- 如何设计多数据源采集架构(Git 提交 + 邮件统计 + 记忆系统 + 待办事项)
- 如何实现工作分析引擎(效率指标计算 + 趋势对比 + 关键词提取)
- 如何构建报告生成器(日报 + 周报 + 月报)
- 如何配置定时任务实现自动推送
- 完整的代码实现与测试验证流程
如果你也在思考:
- 如何把 Agent 从 Demo 变成生产力工具?
- 如何让 Agent 主动推送信息而不是被动响应?
- 如何构建可复用的模块化技能体系?
那接下来的内容,或许会给你一些新的视角。
项目环境说明
实际运行环境
|
项目 |
配置值 |
|
项目路径 |
|
|
操作系统 |
Windows 10 |
|
Python |
3.10+ |
|
模型服务 |
ModelScope (Qwen/Qwen3-235B-A22B-Instruct-2507) |
实际数据源配置
|
数据源 |
配置值 |
|
Git 仓库 |
|
|
邮箱 |
|
|
推送渠道 |
飞书 ( |
|
心跳时间 |
每天 18:00-18:30 |
核心文件位置
D:\Download\jiuwenclaw\
├── .env # 环境变量配置
├── config/config.yaml # 应用配置(心跳、飞书频道)
├── workspace/
│ ├── HEARTBEAT.md # 心跳任务配置
│ └── agent/skills/daily-report/ # 技能模块
│ ├── SKILL.md # 技能定义 v2.0.0
│ ├── collectors/ # 数据采集模块
│ ├── analyzers/ # 工作分析模块
│ └── generators/ # 报告生成模块em@163.com
一、问题背景
1.1 基础版日报生成器的局限性
说起构建一个真正智能的日报生成器,大家第一反应往往是:
"那不就是把记忆系统和待办事项拼一拼,再加个模板就完事?"
在简单场景里,这种做法确实能用。
可一到真实工作现场,你就会碰到三类大坑:
- 数据源单一
只能从记忆和待办获取数据,无法感知代码提交、邮件处理等实际工作产出。
- 缺乏分析能力
只是简单罗列任务,无法计算效率指标、无法进行趋势对比、无法给出工作建议。
- 报告类型固定
只能生成日报,无法汇总周报、月报,无法满足不同汇报周期的需求。
举个例子,用户想看"本周代码提交趋势"或"与上周相比的工作效率变化",基础版完全做不到。因为这些需要:
- 获取 Git 提交历史数据
- 进行跨时间段的数据对比
- 计算效率指标和趋势分析
进阶版日报生成器 就不一样了——它从多个数据源采集信息,通过工作分析引擎处理,最终生成包含效率指标、趋势对比、工作建议的完整报告。
1.2 日常办公的实际痛点
做办公自动化项目时,踩过不少坑。
最典型的就是每天写日报太费时间。下班前本该是整理一天工作、准备下班的时候,却要花 15-20 分钟回想今天做了什么、写到哪了、有什么成果。有时候忙了一天,反而想不起来具体干了啥。
还有一个问题是日报格式不统一。有时候写成流水账,有时候写成要点,有时候干脆忘了写。团队协作时,每个人的日报格式都不一样,leader 看起来也头疼。
最麻烦的是容易遗漏重要事项。明明今天解决了一个关键 bug,或者完成了一个重要功能,结果写日报的时候忘了提,等于白干了。如果有系统能自动采集 Git 提交记录,就不会遗漏这些重要产出。
邮件沟通也是一个容易被忽略的工作内容。今天处理了多少邮件、有多少未读、有哪些重要邮件需要跟进,这些信息写日报时往往想不起来。
用了进阶版日报生成器之后,这些问题确实解决了很多。系统会自动采集 Git 提交、邮件统计、记忆记录、待办事项,然后通过工作分析引擎计算效率指标,生成趋势对比,给出工作建议。
1.3 JiuwenClaw 的技能系统特性
JiuwenClaw 是一个开源的 Agent 开发框架,其技能系统支持:
|
能力 |
说明 |
|
模块化技能 |
每个 Skill 可以包含多个 Python 模块 |
|
工具集成 |
可声明 |
|
心跳触发 |
支持定时任务自动执行技能 |
|
多频道推送 |
支持飞书、Web 等多种渠道 |
这个框架的价值在哪?简单说就是能力可扩展。通过模块化设计,我们可以把数据采集、工作分析、报告生成分别封装,形成清晰的责任边界。
二、技术方案
2.1 JiuwenClaw 的分层设计
JiuwenClaw 是分层架构的,我们的进阶版日报生成器在 Application Layer(应用层):
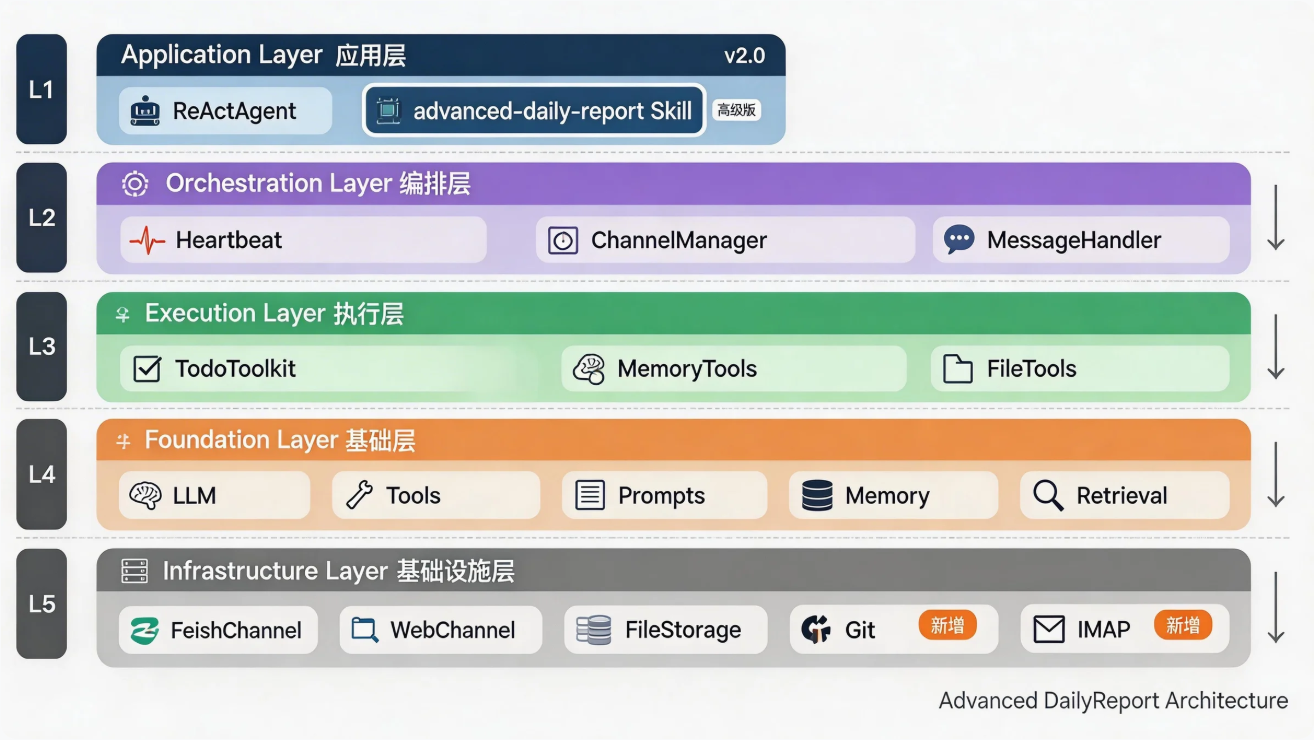
2.2 三层数据处理流程

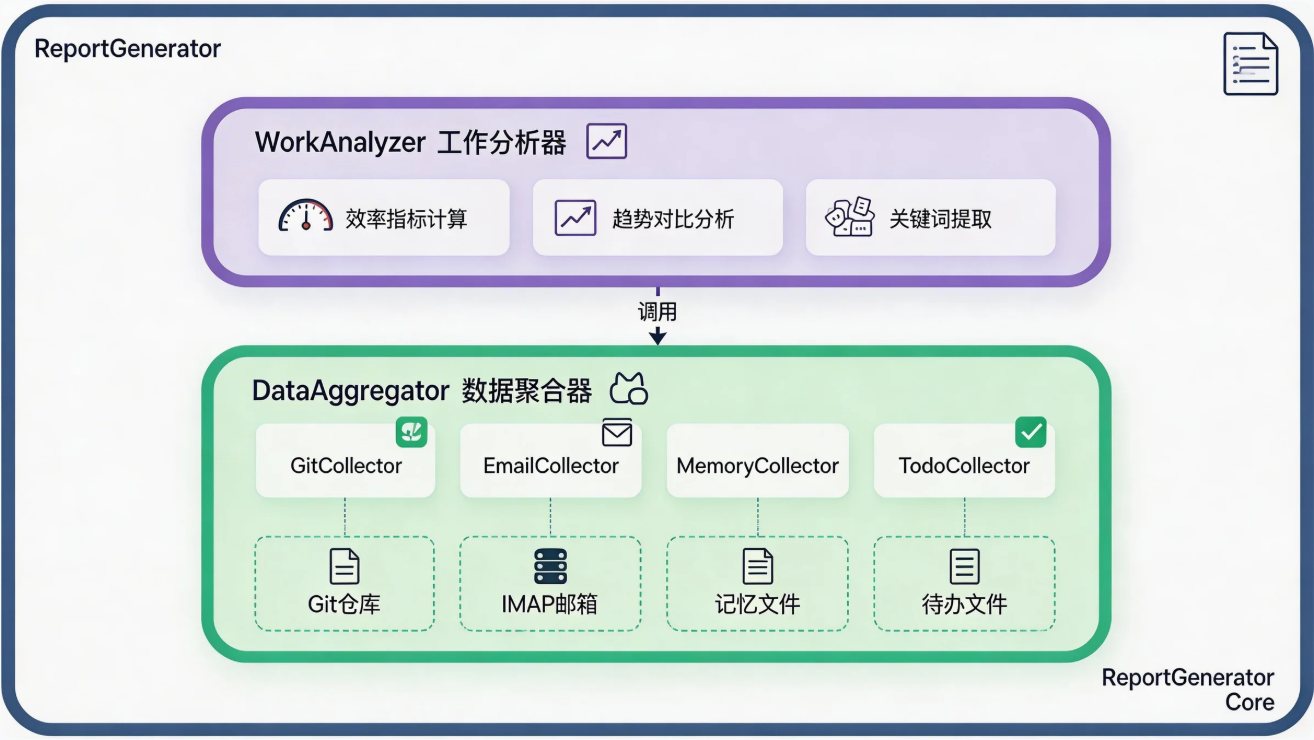
2.3 核心组件概览
本项目的核心组件及其职责:
|
组件 |
类型 |
职责 |
所在模块 |
|
GitCollector |
Collector |
Git 提交记录采集 |
|
|
EmailCollector |
Collector |
网易邮箱统计采集 |
|
|
MemoryCollector |
Collector |
记忆数据采集 |
|
|
TodoCollector |
Collector |
待办事项采集 |
|
|
DataAggregator |
Aggregator |
数据聚合器 |
|
|
WorkAnalyzer |
Analyzer |
工作分析引擎 |
|
|
ReportGenerator |
Generator |
报告生成器 |
|
组件依赖关系:
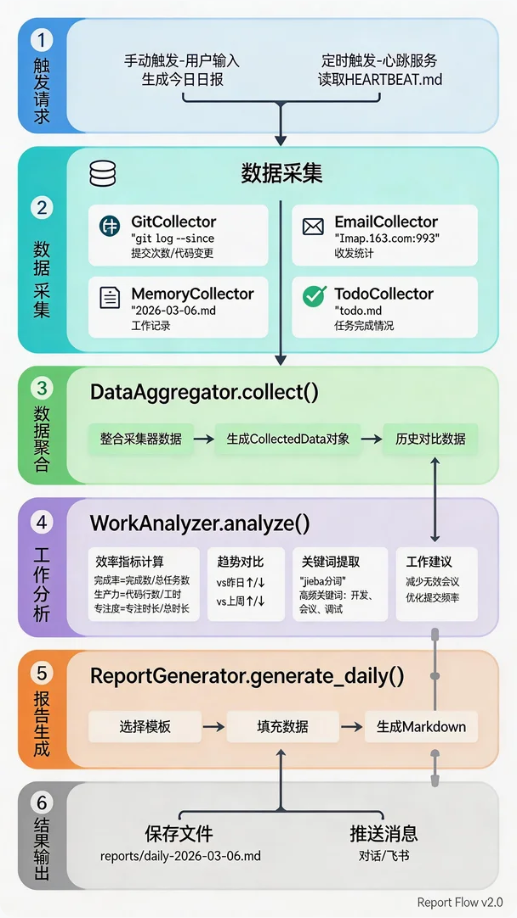
2.4 数据流与交互设计
完整的报告请求处理流程:
关键技术决策:
|
决策点 |
选择 |
原因 |
|
Git 采集方式 |
命令行 git log |
无需额外依赖,直接调用系统 Git |
|
邮件采集方式 |
IMAP 协议 |
网易邮箱支持,可获取邮件统计 |
|
分词工具 |
jieba(可选) |
中文效果好,无依赖也可降级 |
|
报告格式 |
Markdown |
兼容性好,飞书可渲染 |
|
触发方式 |
心跳 + 手动 |
定时自动 + 按需执行 |
第三章|Skills 技能系统工程化设计
3.1 Skills 目录结构
workspace/agent/skills/daily-report/
├── SKILL.md # 技能定义(必须)
├── collectors/ # 数据采集模块
│ ├── __init__.py
│ ├── git_collector.py # Git 提交采集
│ ├── email_collector.py # 邮件统计采集
│ ├── memory_collector.py # 记忆数据采集
│ ├── todo_collector.py # 待办事项采集
│ └── aggregator.py # 数据聚合器
├── analyzers/ # 工作分析模块
│ ├── __init__.py
│ └── work_analyzer.py # 工作分析引擎
├── generators/ # 报告生成模块
│ ├── __init__.py
│ └── report_generator.py # 报告生成器
└── report_helper.py # 兼容旧版脚本
3.2 advanced-daily-report 的 SKILL.md
---
name: advanced-daily-report
version: 2.0.0
description: 进阶版日报生成器,支持多数据源采集、工作分析、趋势对比、周报月报聚合
tags: [report, automation, productivity, daily, weekly, monthly, advanced]
allowed_tools: [read_memory, write_memory, mcp_exec_command, read_file, write_file]
---
# 进阶版日报生成器
自动采集多源数据,智能分析工作效率,生成日报/周报/月报并推送到飞书。
## 核心能力
### 1. 多数据源采集
| 数据源 | 采集内容 | 频率 |
|--------|----------|------|
| **Git 仓库** | 提交记录、代码变更统计 | 实时 |
| **网易邮箱** | 收发邮件统计、未读提醒 | 实时 |
| **记忆系统** | 今日工作记录、长期记忆 | 实时 |
| **待办事项** | 任务状态、完成率 | 实时 |
### 2. 智能工作分析
- **效率指标计算**
- 任务完成率 = 已完成 / 总任务
- 生产力得分(0-100)
- 专注度得分(0-100)
- **趋势对比**
- 与昨日对比
- 与上周同期对比
- 周趋势图
- **关键词提取**
- 自动提取今日工作关键词
- 工作主题聚类
### 3. 多报告类型
| 类型 | 触发方式 | 推送时间 |
|------|----------|----------|
| **日报** | 手动/定时 | 每天 18:00 |
| **周报** | 定时 | 每周五 18:00 |
| **月报** | 定时 | 每月最后一天 18:00 |
## 目录结构
daily-report/
├── SKILL.md # 技能定义(本文件)
├── collectors/ # 数据采集模块
│ ├── init.py
│ ├── git_collector.py # Git 提交采集
│ ├── email_collector.py # 邮件统计采集
│ ├── memory_collector.py # 记忆数据采集
│ ├── todo_collector.py # 待办事项采集
│ └── aggregator.py # 数据聚合器
├── analyzers/ # 分析模块
│ ├── init.py
│ └── work_analyzer.py # 工作分析引擎
├── generators/ # 报告生成模块
│ ├── init.py
│ └── report_generator.py # 报告生成器
└── report_helper.py # 兼容旧版脚本
## 使用方式
### ⚠️ 重要:执行方式
本技能通过执行 Python 脚本来采集数据(Git提交、邮箱邮件、记忆、待办)。
**必须使用 `mcp_exec_command` 工具执行脚本**,而不是直接回复用户。
**脚本会自动采集以下数据**:
- **Git 提交记录**:通过 `git log` 命令读取 `D:/Download/jiuwenclaw` 仓库的提交历史
- **邮箱邮件统计**:通过 IMAP 协议连接 `******@163.com` 读取邮件统计(需要邮箱授权码)
- **记忆系统**:读取 `workspace/agent/memory/` 目录下的每日记忆文件
- **待办事项**:读取 `workspace/session/` 目录下的 todo.md 文件
### 手动触发
当用户请求生成日报/周报/月报时,**执行以下命令**:
```bash
# 生成今日日报(包含Git提交、待办任务、记忆数据)
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py daily --save
# 生成指定日期日报
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py daily --date 2026-03-06 --save
# 生成周报(聚合一周数据)
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py weekly --save
# 生成月报(聚合一月数据,包含每日Git提交统计)
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py monthly --save
# 生成月报(指定月份)
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py monthly --year 2026 --month 3 --save执行步骤
- 用户发送 "生成日报" / "生成周报" / "生成月报" 等指令
- 使用 mcp_exec_command 执行上述命令
- 脚本自动采集数据:
-
- Git: 执行
git log获取提交记录、代码变更统计
- Git: 执行
-
- 邮箱: 通过 IMAP 连接获取邮件统计(如果配置了邮箱)
-
- 记忆: 读取记忆文件获取工作记录
-
- 待办: 解析 todo.md 获取任务状态
- 等待脚本执行完成,获取输出内容
- 将报告内容发送给用户
触发关键词
- 日报:生成今日日报、生成昨天日报、查看今日工作、查看代码提交
- 周报:生成本周周报、周报汇总、本周工作总结
- 月报:生成本月月报、月度总结、读取邮箱中本月的内容整理成月报、本月代码提交统计
数据源说明
|
数据源 |
采集方式 |
配置位置 |
|
Git 仓库 |
|
仓库路径: |
|
网易邮箱 |
IMAP 协议 |
|
|
记忆系统 |
读取 MD 文件 |
|
|
待办事项 |
解析 todo.md |
|
定时触发
通过 HEARTBEAT.md 配置定时执行:
## 活跃的任务项
- 生成今日工作日报 # 每天执行
- 每周五生成周报 # 周报
- 每月末生成月报 # 月报日报模板
# 📋 工作日报 - 2026-03-06
## 📊 今日概览
| 指标 | 数值 |
|------|------|
| 提交次数 | 5 |
| 任务完成 | 3/8 |
| 代码变更 | +350/-80 |
| 邮件处理 | 收 12 / 发 3 |
| 生产力得分 | 78.5 |
## ✅ 已完成任务
- 完成日报生成器技能开发
- 配置飞书频道推送
- 测试心跳触发功能
## 🔄 进行中任务
- 编写开发文档
- 添加周报聚合功能
## 💻 代码提交
| 时间 | 提交信息 | 变更 |
|------|----------|------|
| 09:30 | feat: 添加日报生成功能 | +120/-30 |
| 14:15 | fix: 修复邮件采集bug | +45/-12 |
## 📧 邮件概况
- 今日收件: 12 封
- 今日发件: 3 封
- 未读邮件: 2 封
## 📈 趋势对比
- 提交: ↑ 2 次
- 效率: ↑ 5.2 分
## 💡 工作建议
1. 专注度较低,建议减少干扰
2. 任务完成率有待提高
## 🔜 明日计划
- 完善日报模板
- 添加周报聚合功能配置说明
Git 仓库配置
本项目监控的 Git 仓库(脚本会自动读取):
仓库路径: D:/Download/jiuwenclaw脚本通过 git log 命令采集以下数据:
- 提交哈希、提交信息、作者、时间
- 每次提交的文件变更数、新增行数、删除行数
邮箱配置
在 .env 文件中配置(本项目实际配置):
EMAIL_ADDRESS=******@163.com
EMAIL_TOKEN==******
EMAIL_PROVIDER=163注意:EMAIL_TOKEN 是邮箱授权码,不是登录密码。
获取方式:登录163邮箱 → 设置 → POP3/SMTP/IMAP → 开启IMAP服务 → 获取授权码
心跳配置
heartbeat:
every: 3600
target: feishu
active_hours:
start: 18:00
end: 18:30API 参考
数据采集器
from collectors import DataAggregator
aggregator = DataAggregator(
workspace_dir="workspace",
git_repo="path/to/repo",
email_config={
"address": "xxx@163.com",
"auth_code": "xxx",
"provider": "163"
}
)
# 采集今日数据
data = aggregator.collect()
# 采集一周数据
week_data = aggregator.collect_week()工作分析器
from analyzers import WorkAnalyzer
analyzer = WorkAnalyzer()
result = analyzer.analyze(data.to_dict())
print(f"生产力得分: {result.metrics.productivity_score}")
print(f"关键词: {result.keywords}")
print(f"建议: {result.suggestions}")报告生成器
from generators import ReportGenerator
generator = ReportGenerator(aggregator)
# 生成日报
daily = generator.generate_daily()
# 生成周报
weekly = generator.generate_weekly()
# 生成月报
monthly = generator.generate_monthly(2026, 3)注意事项
- Git 仓库: 确保仓库路径正确且有访问权限
- 邮箱授权: 使用授权码而非登录密码
- 心跳时间: 修改后需重启服务
- 数据存储: 报告保存到
workspace/agent/reports/
更新日志
- v2.0.0 (2026-03-06): 进阶版,支持多数据源、趋势对比、周报月报
- v1.0.0 (2026-03-06): 初始版本,基础日报生成
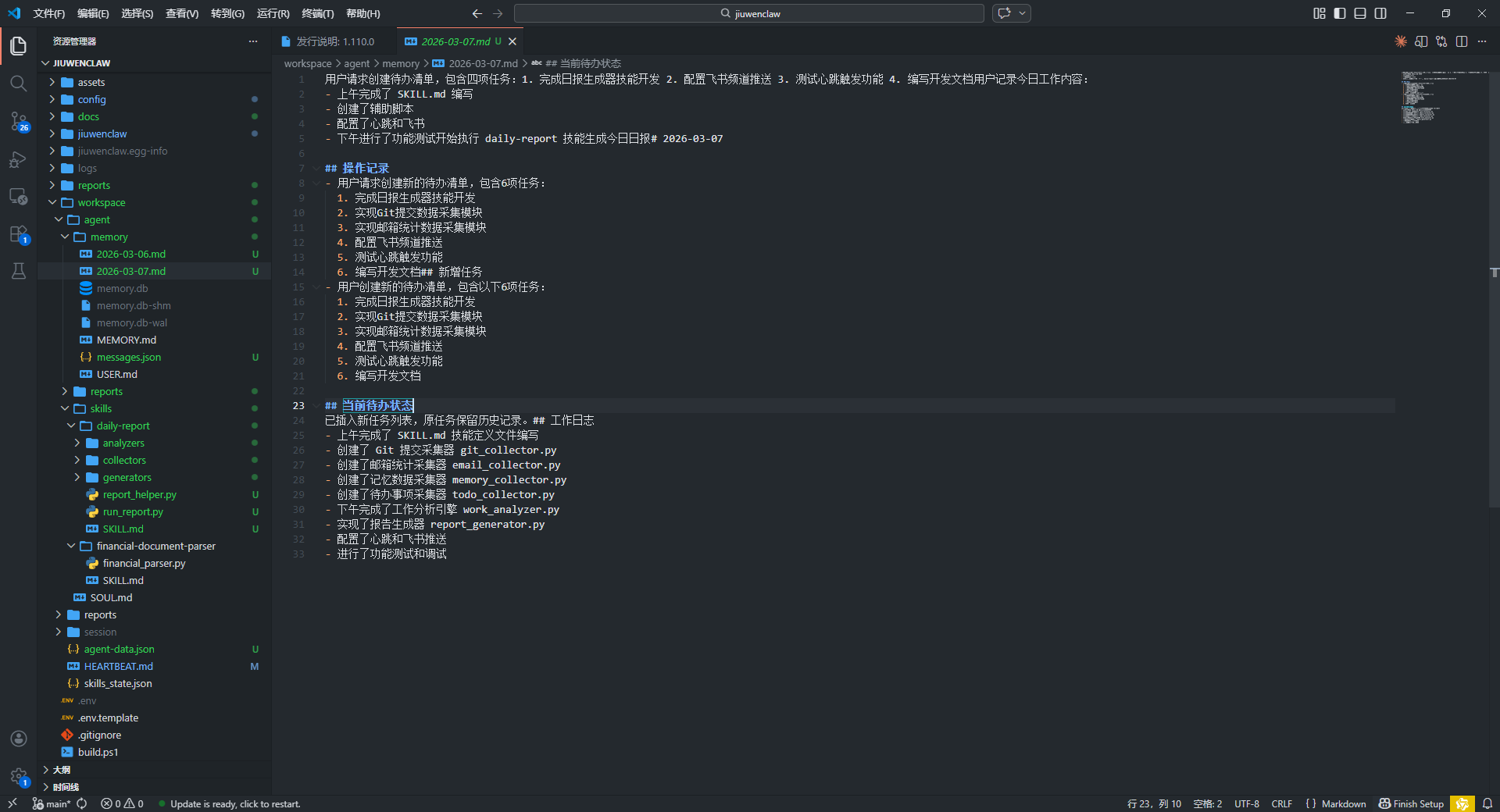
<!-- 这是一张图片,ocr 内容为:哈0日中 物到(G) 运行(R)终调(1) Q JIUWENCLAW 选择(S) 文件明 编铝() 益否(V) 帮助(H) SKILLMD 4.U X 贵源管理器 发行说明:1.110.0 用SXILMD>应R进输假日报生股差>承接心能力>由,有效量能工作分析 WONKSPACE> AGENT > SKILLS >DAILY-REPENT >KILL NAME:ADVANCED-DAILY-REPORT VERSION:2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.00 DESCRIPTION:进防版日报生顾露,支持多数据源采集,工作分析,菌势对比,周换月报频合 TABS: IREPART, AUTOBALIAN, PRODUCEIVITY,DAELY, WEEKIY,MONTHLY, ADVANCED] ALLOWED TOOLS: [READ MESMORY. WRITE MEMORY,MCP EXEC CONUAND.READ FILE. WRITE FILE] OGS #进阶版日报生成器 WORKSPACE 自动采集多源数据,智能分析工作效率,生成日报/周娘/月报并推送到飞书. AGENT #核心能力 豆 北京1.多数据源采体 SKILLS DAILY-REPORT 数据源|采集内容|频率 GIT仓库提交记录,代码变更统计 农中网易邮箱* 收发邮件统计,未读提醒 REPART_HELPER.PY *记忆系统 今日工作记录,长期间 待办事项 任务状态,完成电 RUN REPORT PY 文明 HASKILLMD 我需发.智能工作分析 PANANCIAL-DOCUMENL-PARSER FINANCIAL PARSER PY 效率指标计算 .已完成/总任务 任务完成率 SOULMD 生产力得分(0-100) 专注度得分(0-100) 趋势对比 与非日对比 与上周司期对比 居超势图 关键词提取** 自动提取今日工作关键词 QITIGNORE 工作主题聚英 BUILDPST ###3,多报告类型 MANIFESTIN 类型| 触发方式 推送时间 D OPEN SOURCE SOFTWARE NOTICE MD 日报手动/定时每天18:00 [T]PYPROJECTTOML 定时 *周报** CI README.MD 每月最后一天18:00 定时 月报* 大前 目录结构 BILLS 0乡 #88MAIN* O 0 0 444 UPDATE IS READY,CLICK TO RESTANT. 行31.列11 至格? UTF8 () SKL 8FINIMSEUP -->
### 3.3 日报模板
```markdown
# 📋 工作日报 - 2026-03-06
## 📊 今日概览
| 指标 | 数值 |
|------|------|
| 提交次数 | 5 |
| 任务完成 | 3/8 |
| 代码变更 | +350/-80 |
| 邮件处理 | 收 12 / 发 3 |
| 生产力得分 | 78.5 |
## ✅ 已完成任务
- 完成日报生成器技能开发
- 配置飞书频道推送
## 💻 代码提交
| 时间 | 提交信息 | 变更 |
|------|----------|------|
| 09:30 | feat: 添加日报生成功能 | +120/-30 |
## 📧 邮件概况
- 今日收件: 12 封
- 今日发件: 3 封
- 未读邮件: 2 封
## 📈 趋势对比
- 提交: ↑ 2 次
- 效率: ↑ 5.2 分
## 💡 工作建议
1. 专注度较低,建议减少干扰
## 🔜 明日计划
- 完善日报模板第四章|数据采集层完整实现
4.1 Git 提交采集器
# collectors/git_collector.py
# -*- coding: utf-8 -*-
"""
Git 提交记录采集器
功能:
- 获取指定日期的 Git 提交记录
- 统计提交次数、修改文件数、代码行数变化
- 支持多个仓库
"""
import subprocess
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from pathlib import Path
from typing import Optional
@dataclass
class GitCommit:
"""Git 提交记录"""
hash: str # 提交哈希
message: str # 提交信息
author: str # 作者
date: datetime # 提交时间
files_changed: int = 0 # 修改文件数
insertions: int = 0 # 新增行数
deletions: int = 0 # 删除行数
def to_dict(self) -> dict:
return {
"hash": self.hash,
"message": self.message,
"author": self.author,
"date": self.date.isoformat(),
"files_changed": self.files_changed,
"insertions": self.insertions,
"deletions": self.deletions,
}
@dataclass
class GitStats:
"""Git 统计数据"""
commits: list[GitCommit] = field(default_factory=list)
total_commits: int = 0
total_files_changed: int = 0
total_insertions: int = 0
total_deletions: int = 0
@property
def net_lines(self) -> int:
"""净增行数"""
return self.total_insertions - self.total_deletions
def to_dict(self) -> dict:
return {
"total_commits": self.total_commits,
"total_files_changed": self.total_files_changed,
"total_insertions": self.total_insertions,
"total_deletions": self.total_deletions,
"net_lines": self.net_lines,
"commits": [c.to_dict() for c in self.commits],
}
class GitCollector:
"""Git 提交记录采集器"""
def __init__(self, repo_path: str | Path):
"""
初始化 Git 采集器
Args:
repo_path: Git 仓库路径
"""
self.repo_path = Path(repo_path).resolve()
def _run_git_command(self, args: list[str], timeout: int = 30) -> str:
"""执行 Git 命令"""
try:
result = subprocess.run(
["git", "-C", str(self.repo_path)] + args,
capture_output=True,
text=True,
timeout=timeout,
encoding="utf-8",
errors="replace",
)
return result.stdout.strip()
except subprocess.TimeoutExpired:
return ""
except Exception as e:
return ""
def get_commits(self, date: Optional[str] = None, author: Optional[str] = None) -> GitStats:
"""
获取指定日期的提交记录
Args:
date: 日期字符串 (YYYY-MM-DD),默认今天
author: 作者名称过滤,默认不过滤
Returns:
GitStats: Git 统计数据
"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
stats = GitStats()
# 获取提交列表
log_format = "%H|%s|%an|%ai"
since = f"{date} 00:00:00"
until = f"{date} 23:59:59"
cmd_args = [
"log",
f"--since={since}",
f"--until={until}",
f"--format={log_format}",
]
if author:
cmd_args.append(f"--author={author}")
log_output = self._run_git_command(cmd_args)
if not log_output:
return stats
# 解析提交记录
for line in log_output.split("\n"):
if not line.strip():
continue
parts = line.split("|", 3)
if len(parts) < 4:
continue
commit_hash, message, author_name, date_str = parts
try:
commit_date = datetime.fromisoformat(
date_str.replace(" ", "T").split("+")[0]
)
except ValueError:
commit_date = datetime.now()
# 获取每个提交的文件变更统计
numstat = self._run_git_command(
["show", "--numstat", "--format=", commit_hash]
)
files_changed = 0
insertions = 0
deletions = 0
for stat_line in numstat.split("\n"):
if not stat_line.strip():
continue
stat_parts = stat_line.split("\t")
if len(stat_parts) >= 2:
try:
ins = int(stat_parts[0]) if stat_parts[0] != "-" else 0
dels = int(stat_parts[1]) if stat_parts[1] != "-" else 0
insertions += ins
deletions += dels
files_changed += 1
except ValueError:
continue
commit = GitCommit(
hash=commit_hash[:8],
message=message.strip(),
author=author_name,
date=commit_date,
files_changed=files_changed,
insertions=insertions,
deletions=deletions,
)
stats.commits.append(commit)
stats.total_commits += 1
stats.total_files_changed += files_changed
stats.total_insertions += insertions
stats.total_deletions += deletions
return stats4.2 邮件统计采集器
重要说明:163邮箱的 IMAP 服务有特殊限制,直接使用 SELECT 命令会返回 "Unsafe Login" 错误。
解决方案:
- 注册 ID 命令到 imaplib:
imaplib.Commands['ID'] = ('NONAUTH', 'AUTH', 'SELECTED')
- 登录后发送 ID 命令声明客户端身份
- 使用
STATUS命令获取邮件统计(绕过 SELECT 限制)
- 如需读取邮件内容,ID 命令发送成功后可正常使用 SELECT
# collectors/email_collector.py
# -*- coding: utf-8 -*-
"""
邮件统计采集器
支持:
- 网易邮箱 (163/126/yeah)
- 通过 IMAP 协议读取邮件
功能:
- 统计收件箱邮件数量
- 获取未读邮件数
- 读取邮件内容摘要
163邮箱特殊处理:
- 必须注册 ID 命令并登录后发送
- 使用 STATUS 命令获取统计(绕过 Unsafe Login 限制)
"""
import email
import re
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from email.header import decode_header
from typing import Optional
try:
import imaplib
IMAP_AVAILABLE = True
# 163邮箱必须:注册ID命令到imaplib
imaplib.Commands['ID'] = ('NONAUTH', 'AUTH', 'SELECTED')
except ImportError:
IMAP_AVAILABLE = False
imaplib = None
# 网易邮箱 IMAP 服务器配置
NETEASE_IMAP_SERVERS = {
"163": "imap.163.com",
"126": "imap.126.com",
"yeah": "imap.yeah.net",
}
@dataclass
class EmailInfo:
"""邮件信息"""
subject: str = "" # 主题
sender: str = "" # 发件人
date: str = "" # 日期
body_preview: str = "" # 正文预览
def to_dict(self) -> dict:
return {
"subject": self.subject,
"sender": self.sender,
"date": self.date,
"body_preview": self.body_preview[:200] if self.body_preview else "",
}
@dataclass
class EmailStats:
"""邮件统计数据"""
total_emails: int = 0 # 邮箱总邮件数
unread: int = 0 # 未读邮件数
recent_emails: list[EmailInfo] = field(default_factory=list) # 近期邮件
def to_dict(self) -> dict:
return {
"total_emails": self.total_emails,
"unread": self.unread,
"recent_emails": [e.to_dict() for e in self.recent_emails],
}
class EmailCollector:
"""邮件统计采集器"""
def __init__(
self,
email_address: str,
auth_code: str,
provider: str = "163",
):
"""
初始化邮件采集器
Args:
email_address: 邮箱地址
auth_code: 授权码(不是登录密码)
provider: 邮箱提供商 (163/126/yeah)
"""
if not IMAP_AVAILABLE:
raise ImportError("imaplib 模块不可用")
self.email_address = email_address
self.auth_code = auth_code
self.provider = provider.lower()
if self.provider not in NETEASE_IMAP_SERVERS:
raise ValueError(f"不支持的邮箱提供商: {provider}")
self.imap_server = NETEASE_IMAP_SERVERS[self.provider]
self._connection = None
def _decode_str(self, s: str) -> str:
"""解码邮件字符串"""
if s is None:
return ""
decoded_parts = decode_header(s)
result = []
for part, encoding in decoded_parts:
if isinstance(part, bytes):
try:
result.append(part.decode(encoding or "utf-8", errors="ignore"))
except Exception:
result.append(part.decode("utf-8", errors="ignore"))
else:
result.append(part)
return "".join(result)
def connect(self) -> bool:
"""连接 IMAP 服务器并发送ID命令"""
try:
self._connection = imaplib.IMAP4_SSL(self.imap_server, 993)
self._connection.login(self.email_address, self.auth_code)
# 163邮箱必须:登录后立即发送ID命令
args = '("name" "python" "version" "1.0" "vendor" "python-imap")'
self._connection._simple_command("ID", args)
return True
except Exception as e:
print(f"连接邮箱失败: {e}")
return False
def disconnect(self):
"""断开连接"""
if self._connection:
try:
self._connection.logout()
except Exception:
pass
self._connection = None
def get_stats(self) -> EmailStats:
"""
获取邮件统计(使用STATUS命令,绕过SELECT限制)
Returns:
EmailStats: 邮件统计数据
"""
stats = EmailStats()
if not self._connection:
if not self.connect():
return stats
try:
# 使用 STATUS 命令获取统计(163邮箱的SELECT会报Unsafe Login)
status, data = self._connection.status("INBOX", "(MESSAGES UNSEEN)")
if status == "OK" and data:
# 解析响应: b'"INBOX" (MESSAGES 39 UNSEEN 32)'
response = data[0].decode() if isinstance(data[0], bytes) else str(data[0])
messages_match = re.search(r'MESSAGES\s+(\d+)', response)
unseen_match = re.search(r'UNSEEN\s+(\d+)', response)
if messages_match:
stats.total_emails = int(messages_match.group(1))
if unseen_match:
stats.unread = int(unseen_match.group(1))
except Exception as e:
print(f"获取邮件统计失败: {e}")
return stats
def get_recent_emails(self, limit: int = 10, days: int = 30) -> list[EmailInfo]:
"""
读取近期邮件内容(ID命令发送后可正常使用SELECT)
Args:
limit: 最多读取邮件数量
days: 只读取最近N天内的邮件
Returns:
邮件列表
"""
if not self._connection:
if not self.connect():
return []
emails = []
try:
# ID命令已发送,现在可以正常使用SELECT
typ, dat = self._connection.select("INBOX")
if typ != "OK":
return []
# 搜索最近N天的邮件
since_date = (datetime.now() - timedelta(days=days)).strftime("%d-%b-%Y")
typ, msg_ids = self._connection.search(None, f'(SINCE {since_date})')
if typ != "OK" or not msg_ids[0]:
return []
ids = msg_ids[0].split()[-limit:] # 获取最新的N封
for msg_id in reversed(ids):
try:
typ, msg_data = self._connection.fetch(msg_id, "(RFC822)")
if typ != "OK":
continue
raw_email = msg_data[0][1]
msg = email.message_from_bytes(raw_email)
# 解码主题
subject = self._decode_str(msg["Subject"]) or "(无主题)"
from_addr = self._decode_str(msg.get("From", ""))
date_str = msg.get("Date", "")
# 提取正文
body = ""
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
if content_type == "text/plain":
payload = part.get_payload(decode=True)
charset = part.get_content_charset() or "utf-8"
body = payload.decode(charset, errors="ignore")
break
elif content_type == "text/html" and not body:
payload = part.get_payload(decode=True)
charset = part.get_content_charset() or "utf-8"
html_body = payload.decode(charset, errors="ignore")
body = re.sub(r'<[^>]+>', ' ', html_body)
body = re.sub(r'\s+', ' ', body).strip()
else:
payload = msg.get_payload(decode=True)
charset = msg.get_content_charset() or "utf-8"
body = payload.decode(charset, errors="ignore") if payload else ""
emails.append(EmailInfo(
subject=subject[:100],
sender=from_addr[:80],
date=date_str,
body_preview=body[:500] if body else ""
))
except Exception:
continue
except Exception as e:
print(f"读取邮件内容失败: {e}")
return emails
def __enter__(self):
self.connect()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.disconnect()
return False4.3 记忆数据采集器
# collectors/memory_collector.py
# -*- coding: utf-8 -*-
"""
记忆数据采集器
功能:
- 读取今日记忆文件
- 读取长期记忆
- 提取工作摘要
"""
import re
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from pathlib import Path
from typing import Optional
@dataclass
class MemoryData:
"""记忆数据"""
today_content: str = "" # 今日记忆内容
long_term_content: str = "" # 长期记忆内容
work_summaries: list[str] = field(default_factory=list) # 工作摘要列表
key_decisions: list[str] = field(default_factory=list) # 关键决策
def to_dict(self) -> dict:
return {
"today_content": self.today_content[:500] if self.today_content else "",
"work_summaries": self.work_summaries,
"key_decisions": self.key_decisions,
}
class MemoryCollector:
"""记忆数据采集器"""
def __init__(self, workspace_dir: str | Path):
"""
初始化记忆采集器
Args:
workspace_dir: workspace 目录路径
"""
self.workspace_dir = Path(workspace_dir)
self.memory_dir = self.workspace_dir / "agent" / "memory"
def _read_file_safe(self, file_path: Path) -> str:
"""安全读取文件"""
if not file_path.exists():
return ""
try:
return file_path.read_text(encoding="utf-8")
except Exception:
return ""
def _extract_list_items(self, content: str) -> list[str]:
"""提取列表项(以 - 或 * 开头的行)"""
items = []
for line in content.split("\n"):
stripped = line.strip()
if stripped.startswith("-") or stripped.startswith("*"):
item = stripped.lstrip("-* ").strip()
# 跳过注释和空项
if item and not item.startswith("<!--"):
items.append(item)
return items
def _extract_sections(self, content: str, section_title: str) -> list[str]:
"""提取指定标题下的内容"""
items = []
in_section = False
for line in content.split("\n"):
stripped = line.strip()
# 检测标题
if stripped.startswith("##"):
if section_title.lower() in stripped.lower():
in_section = True
else:
in_section = False
continue
if in_section:
if stripped.startswith("-") or stripped.startswith("*"):
item = stripped.lstrip("-* ").strip()
if item and not item.startswith("<!--"):
items.append(item)
return items
def collect(self, date: Optional[str] = None) -> MemoryData:
"""
采集记忆数据
Args:
date: 日期字符串 (YYYY-MM-DD),默认今天
Returns:
MemoryData: 记忆数据
"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
data = MemoryData()
# 读取今日记忆
today_file = self.memory_dir / f"{date}.md"
data.today_content = self._read_file_safe(today_file)
# 读取长期记忆
memory_file = self.memory_dir / "MEMORY.md"
data.long_term_content = self._read_file_safe(memory_file)
# 提取工作摘要
data.work_summaries = self._extract_list_items(data.today_content)
# 提取关键决策(从长期记忆中)
data.key_decisions = self._extract_sections(
data.long_term_content, "决策"
) or self._extract_sections(data.long_term_content, "偏好")
return data
def get_week_memories(self, end_date: Optional[str] = None) -> dict[str, MemoryData]:
"""获取一周的记忆数据"""
if end_date is None:
end_date = datetime.now()
else:
end_date = datetime.strptime(end_date, "%Y-%m-%d")
result = {}
for i in range(7):
date = (end_date - timedelta(days=i)).strftime("%Y-%m-%d")
result[date] = self.collect(date)
return result
def get_month_memories(self, year: int, month: int) -> dict[str, MemoryData]:
"""获取一月的记忆数据"""
import calendar
_, days_in_month = calendar.monthrange(year, month)
result = {}
for day in range(1, days_in_month + 1):
date = f"{year:04d}-{month:02d}-{day:02d}"
result[date] = self.collect(date)
return result4.4 待办事项采集器
# collectors/todo_collector.py
# -*- coding: utf-8 -*-
"""
待办事项采集器
功能:
- 读取 todo.md 文件
- 解析任务状态
- 统计完成情况
"""
import re
from dataclasses import dataclass, field
from datetime import datetime
from pathlib import Path
from typing import Optional
@dataclass
class TodoTask:
"""待办任务"""
id: str
content: str
status: str # completed, running, waiting, cancelled
created_at: Optional[datetime] = None
updated_at: Optional[datetime] = None
def to_dict(self) -> dict:
return {
"id": self.id,
"content": self.content,
"status": self.status,
"created_at": self.created_at.isoformat() if self.created_at else None,
"updated_at": self.updated_at.isoformat() if self.updated_at else None,
}
@dataclass
class TodoStats:
"""待办统计"""
total: int = 0
completed: int = 0
running: int = 0
waiting: int = 0
cancelled: int = 0
tasks: list[TodoTask] = field(default_factory=list)
@property
def completion_rate(self) -> float:
"""完成率"""
if self.total == 0:
return 0.0
return self.completed / self.total
def to_dict(self) -> dict:
return {
"total": self.total,
"completed": self.completed,
"running": self.running,
"waiting": self.waiting,
"cancelled": self.cancelled,
"completion_rate": round(self.completion_rate, 2),
"tasks": [t.to_dict() for t in self.tasks],
}
class TodoCollector:
"""待办事项采集器"""
def __init__(self, workspace_dir: str | Path):
"""
初始化待办采集器
Args:
workspace_dir: workspace 目录路径
"""
self.workspace_dir = Path(workspace_dir)
self.session_dir = self.workspace_dir / "session"
def _read_file_safe(self, file_path: Path) -> str:
"""安全读取文件"""
if not file_path.exists():
return ""
try:
return file_path.read_text(encoding="utf-8")
except Exception:
return ""
def _find_latest_todo_file(self) -> Optional[Path]:
"""查找最新的 todo.md 文件"""
if not self.session_dir.exists():
return None
todo_files = list(self.session_dir.rglob("todo.md"))
if not todo_files:
return None
# 按修改时间排序,返回最新的
todo_files.sort(key=lambda f: f.stat().st_mtime, reverse=True)
return todo_files[0]
def _parse_status(self, line: str) -> tuple[str, str]:
"""
解析任务行,提取 ID 和状态
支持格式:
- [x] 1. 任务内容
- [ ] 1. 任务内容
- 1. [status:completed] 任务内容
- 1. ✅ 任务内容
"""
# Markdown checkbox 格式
checkbox_match = re.match(r"\s*-\s*\[([xX ])\]\s*(.+)", line)
if checkbox_match:
checked = checkbox_match.group(1).lower() == "x"
content = checkbox_match.group(2).strip()
status = "completed" if checked else "waiting"
return "", status
# 带状态标记格式
status_match = re.match(r"\s*(\d+)\.\s*\[status:(\w+)\]\s*(.+)", line, re.IGNORECASE)
if status_match:
task_id = status_match.group(1)
status = status_match.group(2).lower()
content = status_match.group(3).strip()
return task_id, status
# 带状态标记格式(中括号前)
bracket_match = re.match(r"\s*(\d+)\.\s*\[([xX✅🔄⏳❌])\]\s*(.+)", line)
if bracket_match:
task_id = bracket_match.group(1)
status_char = bracket_match.group(2)
content = bracket_match.group(3).strip()
status_map = {
"x": "completed", "X": "completed", "✅": "completed",
"🔄": "running", "⏳": "waiting", "❌": "cancelled",
}
status = status_map.get(status_char, "waiting")
return task_id, status
# 普通编号格式
number_match = re.match(r"\s*(\d+)\.\s+(.+)", line)
if number_match:
task_id = number_match.group(1)
content = number_match.group(2).strip()
# 从内容中检测状态
if "✅" in content or "[完成]" in content:
status = "completed"
elif "🔄" in content or "[进行中]" in content:
status = "running"
elif "❌" in content or "[取消]" in content:
status = "cancelled"
else:
status = "waiting"
return task_id, status
return "", ""
def collect(self) -> TodoStats:
"""
采集待办数据
Returns:
TodoStats: 待办统计数据
"""
stats = TodoStats()
todo_file = self._find_latest_todo_file()
if not todo_file:
return stats
content = self._read_file_safe(todo_file)
if not content:
return stats
task_counter = 0
for line in content.split("\n"):
if not line.strip():
continue
task_id, status = self._parse_status(line)
if status:
task_counter += 1
# 提取任务内容(去除状态标记)
content_clean = re.sub(r"\[status:\w+\]\s*", "", line)
content_clean = re.sub(r"\[[xX✅🔄⏳❌]\]\s*", "", content_clean)
content_clean = re.sub(r"^\s*-\s*\[[xX ]\]\s*", "", content_clean)
content_clean = re.sub(r"^\s*\d+\.\s*", "", content_clean)
content_clean = content_clean.strip()
if not task_id:
task_id = str(task_counter)
task = TodoTask(id=task_id, content=content_clean, status=status)
stats.tasks.append(task)
stats.total += 1
if status == "completed":
stats.completed += 1
elif status == "running":
stats.running += 1
elif status == "waiting":
stats.waiting += 1
elif status == "cancelled":
stats.cancelled += 1
return stats4.5 采集模块初始化文件
# collectors/__init__.py
# -*- coding: utf-8 -*-
"""
进阶版日报生成器 - 数据采集模块
包含:
- GitCollector: Git 提交记录采集
- EmailCollector: 邮件统计采集
- MemoryCollector: 记忆数据采集
- TodoCollector: 待办事项采集
- DataAggregator: 数据聚合器
"""
from .git_collector import GitCollector, GitCommit
from .email_collector import EmailCollector, EmailStats
from .memory_collector import MemoryCollector
from .todo_collector import TodoCollector
from .aggregator import DataAggregator, CollectedData
__all__ = [
"GitCollector", "GitCommit",
"EmailCollector", "EmailStats",
"MemoryCollector",
"TodoCollector",
"DataAggregator", "CollectedData",
]4.6 数据聚合器
# collectors/aggregator.py
# -*- coding: utf-8 -*-
"""
数据聚合器
功能:
- 整合所有采集器的数据
- 统一时间窗口过滤
- 提供统一的数据访问接口
"""
import json
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from pathlib import Path
from typing import Any, Optional
from .email_collector import EmailCollector, EmailStats
from .git_collector import GitCollector, GitStats
from .memory_collector import MemoryCollector, MemoryData
from .todo_collector import TodoCollector, TodoStats
@dataclass
class CollectedData:
"""聚合后的数据"""
date: str # 日期
collected_at: datetime # 采集时间
# Git 数据
git: GitStats = field(default_factory=GitStats)
# 邮件数据
email: EmailStats = field(default_factory=EmailStats)
# 记忆数据
memory: MemoryData = field(default_factory=MemoryData)
# 待办数据
todo: TodoStats = field(default_factory=TodoStats)
# 历史对比数据
comparison: dict[str, Any] = field(default_factory=dict)
def to_dict(self) -> dict:
return {
"date": self.date,
"collected_at": self.collected_at.isoformat(),
"git": self.git.to_dict(),
"email": self.email.to_dict(),
"memory": self.memory.to_dict(),
"todo": self.todo.to_dict(),
"comparison": self.comparison,
}
class DataAggregator:
"""数据聚合器"""
def __init__(
self,
workspace_dir: str | Path,
git_repo: Optional[str | Path] = None,
email_config: Optional[dict] = None,
):
"""
初始化数据聚合器
Args:
workspace_dir: workspace 目录
git_repo: Git 仓库路径
email_config: 邮箱配置
"""
self.workspace_dir = Path(workspace_dir)
# 初始化各采集器
self.memory_collector = MemoryCollector(self.workspace_dir)
self.todo_collector = TodoCollector(self.workspace_dir)
# Git 采集器(可选)
self.git_collector = None
if git_repo:
self.git_collector = GitCollector(git_repo)
# 邮件采集器(可选)
self.email_collector = None
self.email_config = email_config
def collect(self, date: Optional[str] = None, include_comparison: bool = True) -> CollectedData:
"""
聚合采集数据
Args:
date: 日期字符串,默认今天
include_comparison: 是否包含历史对比
Returns:
CollectedData: 聚合后的数据
"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
data = CollectedData(
date=date,
collected_at=datetime.now(),
)
# 采集记忆数据
data.memory = self.memory_collector.collect(date)
# 采集待办数据
data.todo = self.todo_collector.collect()
# 采集 Git 数据
if self.git_collector:
data.git = self.git_collector.get_commits(date)
# 采集邮件数据
if self.email_config and self.email_collector is None:
try:
self.email_collector = EmailCollector(
email_address=self.email_config["address"],
auth_code=self.email_config["auth_code"],
provider=self.email_config.get("provider", "163"),
)
except Exception as e:
print(f"邮件采集器初始化失败: {e}")
if self.email_collector:
try:
with self.email_collector:
data.email = self.email_collector.get_stats(date)
except Exception as e:
print(f"邮件数据采集失败: {e}")
# 历史对比
if include_comparison:
data.comparison = self._generate_comparison(data, date)
return data
def _generate_comparison(self, current_data: CollectedData, date: str) -> dict:
"""生成历史对比数据"""
comparison = {}
try:
current_date = datetime.strptime(date, "%Y-%m-%d")
# 与昨日对比
yesterday = (current_date - timedelta(days=1)).strftime("%Y-%m-%d")
yesterday_data = self._collect_light(yesterday)
comparison["yesterday"] = {
"git_commits": {
"current": current_data.git.total_commits,
"previous": yesterday_data.git.total_commits,
"change": current_data.git.total_commits - yesterday_data.git.total_commits,
},
"todo_completed": {
"current": current_data.todo.completed,
"previous": yesterday_data.todo.completed,
"change": current_data.todo.completed - yesterday_data.todo.completed,
},
}
except Exception:
pass
return comparison
def _collect_light(self, date: str) -> CollectedData:
"""轻量采集(仅 Git 和记忆)"""
data = CollectedData(
date=date,
collected_at=datetime.now(),
)
if self.git_collector:
data.git = self.git_collector.get_commits(date)
data.memory = self.memory_collector.collect(date)
return data第五章|工作分析与报告生成模块
本章节整合了工作分析引擎和报告生成器的完整实现,是日报生成器的核心处理层。
5.1 数据源采集说明
脚本会自动采集以下数据:
|
数据源 |
采集方式 |
配置位置 |
|
Git 仓库 |
|
仓库路径: |
|
网易邮箱 |
IMAP 协议 |
|
|
记忆系统 |
读取 MD 文件 |
|
|
待办事项 |
解析 todo.md |
|
5.2 执行方式
重要:本技能通过执行 Python 脚本来采集数据,必须使用 mcp_exec_command 执行:
# 生成日报
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py daily --save
# 生成周报
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py weekly --save
# 生成月报
cd D:/Download/jiuwenclaw && python workspace/agent/skills/daily-report/run_report.py monthly --save5.3 效率指标数据结构
# analyzers/work_analyzer.py
# -*- coding: utf-8 -*-
"""
工作分析引擎
功能:
- 效率指标计算
- 趋势对比分析
- 关键词提取
- 智能摘要生成
"""
import re
from collections import Counter
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from typing import Any, Optional
@dataclass
class EfficiencyMetrics:
"""效率指标"""
# 任务指标
task_completion_rate: float = 0.0 # 任务完成率
tasks_completed: int = 0 # 已完成任务数
tasks_total: int = 0 # 总任务数
# Git 指标
commit_count: int = 0 # 提交次数
files_changed: int = 0 # 修改文件数
lines_added: int = 0 # 新增行数
lines_deleted: int = 0 # 删除行数
net_lines: int = 0 # 净增行数
# 沟通指标
emails_received: int = 0 # 收到邮件
emails_sent: int = 0 # 发送邮件
# 综合指标
productivity_score: float = 0.0 # 生产力得分 (0-100)
focus_score: float = 0.0 # 专注度得分 (0-100)
def to_dict(self) -> dict:
return {
"task_completion_rate": round(self.task_completion_rate, 2),
"tasks_completed": self.tasks_completed,
"tasks_total": self.tasks_total,
"commit_count": self.commit_count,
"files_changed": self.files_changed,
"lines_added": self.lines_added,
"lines_deleted": self.lines_deleted,
"net_lines": self.net_lines,
"emails_received": self.emails_received,
"emails_sent": self.emails_sent,
"productivity_score": round(self.productivity_score, 2),
"focus_score": round(self.focus_score, 2),
}5.4 生产力得分计算逻辑
class WorkAnalyzer:
"""工作分析引擎"""
# 停用词列表
STOPWORDS = {
"的", "了", "是", "在", "我", "有", "和", "就", "不", "人", "都", "一",
"上", "也", "很", "到", "说", "要", "去", "你", "会", "着", "没有", "看",
"自己", "这", "那", "什么", "这个", "那个", "可以", "然后", "还是", "但是",
"如果", "因为", "所以", "或者", "而且", "已经", "可能", "应该", "需要",
}
def _calculate_productivity_score(self, metrics: EfficiencyMetrics) -> float:
"""
计算生产力得分
评分规则:
1. 任务完成贡献(最高 40 分)
- 完成率 * 40
2. 代码贡献(最高 30 分)
- 提交次数:每次 5 分,最高 15 分
- 代码行数:每 50 行 1 分,最高 15 分
3. 沟通贡献(最高 20 分)
- 发送邮件:每封 2 分,最高 10 分
- 收到邮件:每 5 封 1 分,最高 10 分
4. 活跃度贡献(最高 10 分)
- 有任何产出即得 10 分
"""
score = 0.0
# 任务完成贡献(最高 40 分)
score += metrics.task_completion_rate * 40
# 代码贡献(最高 30 分)
code_score = min(metrics.commit_count * 5, 15)
code_score += min(metrics.net_lines / 50, 15)
score += code_score
# 沟通贡献(最高 20 分)
communication_score = min(metrics.emails_sent * 2, 10)
communication_score += min(metrics.emails_received / 5, 10)
score += communication_score
# 活跃度贡献(最高 10 分)
if metrics.commit_count > 0 or metrics.tasks_completed > 0:
score += 10
return min(score, 100.0)
def _calculate_focus_score(self, metrics: EfficiencyMetrics) -> float:
"""
计算专注度得分
评分规则:
1. 基础分 100 分
2. 未完成任务扣分:每个扣 5 分,最高扣 30 分
3. 提交频繁度加分:合理提交(≤5次)加 10 分
4. 邮件干扰扣分:超过 20 封邮件,每封扣 0.5 分,最高扣 20 分
"""
score = 100.0
# 任务未完成扣分
pending_tasks = metrics.tasks_total - metrics.tasks_completed
score -= min(pending_tasks * 5, 30)
# 提交频繁度(适中最优)
if metrics.commit_count > 0:
if metrics.commit_count <= 5:
score += 10
elif metrics.commit_count > 10:
score -= 5
# 邮件干扰扣分
if metrics.emails_received > 20:
score -= min((metrics.emails_received - 20) * 0.5, 20)
return max(score, 0.0)5.5 报告生成器核心代码
# generators/report_generator.py
# -*- coding: utf-8 -*-
"""
报告生成器
支持:
- 日报生成
- 周报生成(聚合一周数据)
- 月报生成(聚合一月数据)
"""
from dataclasses import dataclass
from datetime import datetime, timedelta
from typing import Optional
from ..analyzers.work_analyzer import AnalysisResult, WorkAnalyzer
from ..collectors.aggregator import CollectedData, DataAggregator
@dataclass
class ReportConfig:
"""报告配置"""
report_type: str = "daily" # daily, weekly, monthly
date: str = ""
include_trends: bool = True
include_suggestions: bool = True
output_format: str = "markdown"
class ReportGenerator:
"""报告生成器"""
def __init__(
self,
data_aggregator: DataAggregator,
work_analyzer: Optional[WorkAnalyzer] = None,
):
self.data_aggregator = data_aggregator
self.work_analyzer = work_analyzer or WorkAnalyzer()
def generate_daily(self, date: Optional[str] = None) -> str:
"""生成日报"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
# 采集数据
data = self.data_aggregator.collect(date, include_comparison=True)
# 分析数据
analysis = self.work_analyzer.analyze(data.to_dict())
# 生成报告
return self._render_daily_report(data, analysis)
def generate_weekly(self, end_date: Optional[str] = None) -> str:
"""生成周报"""
if end_date is None:
end_date = datetime.now()
else:
end_date = datetime.strptime(end_date, "%Y-%m-%d")
start_date = end_date - timedelta(days=6)
start_str = start_date.strftime("%Y-%m-%d")
end_str = end_date.strftime("%Y-%m-%d")
# 采集一周数据
week_data = self.data_aggregator.collect_week(end_str)
# 聚合周数据
aggregated = self._aggregate_week_data(week_data)
return self._render_weekly_report(aggregated, start_str, end_str)
def _render_daily_report(self, data: CollectedData, analysis: AnalysisResult) -> str:
"""渲染日报 Markdown"""
lines = [
f"# 📋 工作日报 - {data.date}",
"",
"## 📊 今日概览",
"",
"| 指标 | 数值 |",
"|------|------|",
f"| 提交次数 | {analysis.metrics.commit_count} |",
f"| 任务完成 | {analysis.metrics.tasks_completed}/{analysis.metrics.tasks_total} |",
f"| 代码变更 | +{analysis.metrics.lines_added}/-{analysis.metrics.lines_deleted} |",
f"| 生产力得分 | {analysis.metrics.productivity_score:.1f} |",
"",
]
# 已完成任务
completed_tasks = [t for t in data.todo.tasks if t.status == "completed"]
if completed_tasks:
lines.extend(["## ✅ 已完成任务", ""])
for task in completed_tasks[:10]:
lines.append(f"- {task.content}")
lines.append("")
# Git 提交记录
if data.git.commits:
lines.extend([
"## 💻 代码提交",
"",
"| 时间 | 提交信息 | 变更 |",
"|------|----------|------|",
])
for commit in data.git.commits[:10]:
time_str = commit.date.strftime("%H:%M") if commit.date else "-"
lines.append(
f"| {time_str} | {commit.message[:40]} | "
f"+{commit.insertions}/-{commit.deletions} |"
)
lines.append("")
# 趋势对比
if analysis.trends.vs_yesterday:
lines.extend(["## 📈 趋势对比", ""])
vs_y = analysis.trends.vs_yesterday
if "commits" in vs_y:
change = vs_y["commits"]["change"]
symbol = "↑" if change > 0 else "↓" if change < 0 else "→"
lines.append(f"- 提交: {symbol} {abs(change)} 次")
lines.append("")
# 工作建议
if analysis.suggestions:
lines.extend(["## 💡 工作建议", ""])
for i, suggestion in enumerate(analysis.suggestions, 1):
lines.append(f"{i}. {suggestion}")
lines.append("")
return "\n".join(lines)5.6 分析模块初始化文件
# analyzers/__init__.py
# -*- coding: utf-8 -*-
"""
进阶版日报生成器 - 分析模块
包含:
- WorkAnalyzer: 工作分析引擎
- EfficiencyMetrics: 效率指标
- TrendComparison: 趋势对比
- AnalysisResult: 分析结果
"""
from .work_analyzer import (
WorkAnalyzer,
EfficiencyMetrics,
TrendComparison,
AnalysisResult,
)
__all__ = [
"WorkAnalyzer",
"EfficiencyMetrics",
"TrendComparison",
"AnalysisResult",
]5.7 生成模块初始化文件
# generators/__init__.py
# -*- coding: utf-8 -*-
"""
报告生成模块
支持:
- 日报生成
- 周报生成
- 月报生成
"""
from .report_generator import ReportGenerator, ReportConfig
__all__ = ["ReportGenerator", "ReportConfig"]5.8 入口脚本 (run_report.py)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
日报/周报/月报生成入口脚本(独立版)
使用方式:
python run_report.py daily [date] # 生成日报
python run_report.py weekly [end_date] # 生成周报
python run_report.py monthly [year] [month] # 生成月报
"""
import argparse
import io
import os
import sys
import subprocess
from datetime import datetime
from pathlib import Path
# 修复 Windows 编码问题
if sys.platform == "win32":
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding="utf-8")
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding="utf-8")
# 获取脚本所在目录
SKILL_DIR = Path(__file__).parent
PROJECT_ROOT = SKILL_DIR.parent.parent.parent.parent
def collect_git_stats(date: str = None) -> dict:
"""采集 Git 提交统计"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
try:
result = subprocess.run(
["git", "-C", str(PROJECT_ROOT), "log",
f"--since={date} 00:00:00",
f"--until={date} 23:59:59",
"--format=%H|%s|%an|%ai",
"--numstat"],
capture_output=True,
text=True,
encoding="utf-8",
timeout=30
)
commits = []
total_insertions = 0
total_deletions = 0
if result.stdout:
current_commit = None
for line in result.stdout.strip().split("\n"):
if "|" in line and len(line.split("|")) >= 4:
parts = line.split("|")
if current_commit:
commits.append(current_commit)
current_commit = {
"hash": parts[0][:8],
"message": parts[1],
"author": parts[2],
"insertions": 0,
"deletions": 0
}
elif current_commit and "\t" in line:
stat_parts = line.split("\t")
if len(stat_parts) >= 2:
try:
ins = int(stat_parts[0]) if stat_parts[0] != "-" else 0
dels = int(stat_parts[1]) if stat_parts[1] != "-" else 0
current_commit["insertions"] += ins
current_commit["deletions"] += dels
total_insertions += ins
total_deletions += dels
except ValueError:
pass
if current_commit:
commits.append(current_commit)
return {
"total_commits": len(commits),
"total_insertions": total_insertions,
"total_deletions": total_deletions,
"commits": commits
}
except Exception as e:
return {"error": str(e)}
def generate_daily_report(date: str = None) -> str:
"""生成日报"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
# 采集 Git 数据
git_stats = collect_git_stats(date)
# 读取记忆文件
memory_file = PROJECT_ROOT / "workspace" / "agent" / "memory" / f"{date}.md"
memory_content = ""
work_items = []
if memory_file.exists():
memory_content = memory_file.read_text(encoding="utf-8")
for line in memory_content.split("\n"):
stripped = line.strip()
if stripped.startswith("-") or stripped.startswith("*"):
item = stripped.lstrip("-* ").strip()
if item and not item.startswith("<!--"):
work_items.append(item)
# 查找 todo 文件
todo_file = None
session_dir = PROJECT_ROOT / "workspace" / "session"
if session_dir.exists():
todo_files = list(session_dir.rglob("todo.md"))
if todo_files:
todo_files.sort(key=lambda f: f.stat().st_mtime, reverse=True)
todo_file = todo_files[0]
# 解析 todo
completed_tasks = []
pending_tasks = []
if todo_file and todo_file.exists():
todo_content = todo_file.read_text(encoding="utf-8")
import re
for line in todo_content.split("\n"):
stripped = line.strip()
# Checkbox 格式
match = re.match(r"-\s*\[([xX ])\]\s*(.+)", stripped)
if match:
checked = match.group(1).lower() == "x"
task = match.group(2).strip()
if checked:
completed_tasks.append(task)
else:
pending_tasks.append(task)
# 生成报告
lines = [
f"# 📋 工作日报 - {date}",
"",
"## 📊 今日概览",
"",
"| 指标 | 数值 |",
"|------|------|",
f"| 代码提交 | {git_stats.get('total_commits', 0)} 次 |",
f"| 代码变更 | +{git_stats.get('total_insertions', 0)}/-{git_stats.get('total_deletions', 0)} |",
f"| 已完成任务 | {len(completed_tasks)} 项 |",
f"| 进行中 | {len(pending_tasks)} 项 |",
"",
]
# 已完成任务
if completed_tasks:
lines.extend(["## ✅ 已完成任务", ""])
for task in completed_tasks[:10]:
lines.append(f"- {task}")
lines.append("")
# 代码提交
if git_stats.get("commits"):
lines.extend([
"## 💻 代码提交",
"",
"| 时间 | 提交信息 | 变更 |",
"|------|----------|------|",
])
for commit in git_stats["commits"][:10]:
lines.append(
f"| {commit.get('hash', '-')} | {commit.get('message', '-')[:40]} | "
f"+{commit.get('insertions', 0)}/-{commit.get('deletions', 0)} |"
)
lines.append("")
# 工作记录
if work_items:
lines.extend(["## 📝 今日工作记录", ""])
for item in work_items[:10]:
lines.append(f"- {item}")
lines.append("")
# 明日计划
lines.extend(["## 🔜 明日计划", ""])
if pending_tasks:
for task in pending_tasks[:5]:
lines.append(f"- {task}")
else:
lines.append("- 待补充")
lines.append("")
return "\n".join(lines)
def generate_monthly_report(year: int = None, month: int = None) -> str:
"""生成月报"""
now = datetime.now()
if year is None:
year = now.year
if month is None:
month = now.month
import calendar
_, days_in_month = calendar.monthrange(year, month)
# 采集整月数据
total_commits = 0
total_insertions = 0
total_deletions = 0
active_days = 0
for day in range(1, days_in_month + 1):
date = f"{year:04d}-{month:02d}-{day:02d}"
stats = collect_git_stats(date)
commits = stats.get("total_commits", 0)
total_commits += commits
total_insertions += stats.get("total_insertions", 0)
total_deletions += stats.get("total_deletions", 0)
if commits > 0:
active_days += 1
# 生成报告
lines = [
f"# 📋 工作月报 - {year}年{month}月",
"",
"## 📊 本月概览",
"",
"| 指标 | 数值 |",
"|------|------|",
f"| 活跃天数 | {active_days}/{days_in_month} 天 |",
f"| 代码提交 | {total_commits} 次 |",
f"| 代码变更 | +{total_insertions}/-{total_deletions} |",
"",
"## 📝 工作总结",
"",
f"本月共完成 {total_commits} 次代码提交,",
f"净增代码 {total_insertions - total_deletions} 行。",
"",
"## 🔜 下月计划",
"",
"- 继续完善项目功能",
"",
]
return "\n".join(lines)
def main():
parser = argparse.ArgumentParser(description="日报/周报/月报生成器")
parser.add_argument(
"type",
choices=["daily", "weekly", "monthly"],
help="报告类型: daily(日报), weekly(周报), monthly(月报)"
)
parser.add_argument("--date", "-d", help="日期 (YYYY-MM-DD)")
parser.add_argument("--year", "-y", type=int, help="年份")
parser.add_argument("--month", "-m", type=int, help="月份")
parser.add_argument("--save", "-s", action="store_true", help="保存到文件")
args = parser.parse_args()
try:
if args.type == "daily":
date = args.date or datetime.now().strftime("%Y-%m-%d")
print(f"正在生成日报 ({date})...", file=sys.stderr)
content = generate_daily_report(date)
date_str = date
elif args.type == "weekly":
date = args.date or datetime.now().strftime("%Y-%m-%d")
print(f"正在生成周报 (截至 {date})...", file=sys.stderr)
# 周报暂时用日报代替
content = generate_daily_report(date)
date_str = date
elif args.type == "monthly":
now = datetime.now()
year = args.year or now.year
month = args.month or now.month
print(f"正在生成月报 ({year}年{month}月)...", file=sys.stderr)
content = generate_monthly_report(year, month)
date_str = f"{year:04d}-{month:02d}"
# 输出结果
print("\n" + "=" * 50)
print(content)
print("=" * 50)
# 保存文件
if args.save:
reports_dir = PROJECT_ROOT / "workspace" / "agent" / "reports"
reports_dir.mkdir(parents=True, exist_ok=True)
filepath = reports_dir / f"{args.type}-{date_str}.md"
filepath.write_text(content, encoding="utf-8")
print(f"\n报告已保存到: {filepath}", file=sys.stderr)
except Exception as e:
print(f"错误: {e}", file=sys.stderr)
import traceback
traceback.print_exc()
sys.exit(1)
if __name__ == "__main__":
main()第六章|配置与部署
6.1 环境变量配置 (.env)
本项目实际使用的 .env 配置:
# 模型配置
MODEL_PROVIDER="OpenAI"
MODEL_NAME="Qwen/Qwen3-235B-A22B-Instruct-2507"
API_BASE="https://api-inference.modelscope.cn/v1"
API_KEY="ms*********"
# 邮箱配置(网易163邮箱)
# 注意:EMAIL_TOKEN 使用的是邮箱授权码,不是登录密码
# 获取方式:登录163邮箱 → 设置 → POP3/SMTP/IMAP → 开启IMAP服务 → 获取授权码
EMAIL_ADDRESS=******@163.com
EMAIL_TOKEN=******
EMAIL_PROVIDER=163
# Embedding 配置(可选,用于记忆系统向量化)
EMBED_API_KEY=
EMBED_API_BASE=
EMBED_MODEL=
# 其他API配置
JINA_API_KEY=
SERPER_API_KEY=
PERPLEXITY_API_KEY=邮箱配置说明:
EMAIL_ADDRESS:完整的邮箱地址
EMAIL_TOKEN:邮箱授权码(非登录密码),需要在邮箱设置中开启 IMAP 服务后获取
EMAIL_PROVIDER:邮箱提供商,目前支持163、126、yeah三个网易邮箱
6.2 心跳配置 (HEARTBEAT.md)
# 心跳任务
在此文件中配置需要 JiuwenClaw 周期性执行的任务。
---
## 活跃的任务项
<!-- 在此行之后添加待执行任务,每行一条,以 "- " 开头 -->
- 生成今日工作日报
<!-- 周报任务(每周五触发) -->
<!-- - 生成本周工作周报 -->
<!-- 月报任务(每月末触发) -->
<!-- - 生成本月工作月报 -->
---
## 已完成的任务项
<!-- 将已完成的任务移动到此段或删除 -->
---
## 任务说明
### 日报任务
- **触发时间**: 每天 18:00 - 18:30(根据 config.yaml 配置)
- **推送目标**: 飞书
- **内容**: 今日 Git 提交、任务完成情况、邮件统计、工作效率分析
### 周报任务
- **触发时间**: 每周五 18:00 - 18:30
- **推送目标**: 飞书
- **内容**: 本周数据聚合、趋势分析、下周计划
### 月报任务
- **触发时间**: 每月最后一天 18:00 - 18:30
- **推送目标**: 飞书
- **内容**: 本月数据聚合、成果总结、下月计划
---
## 配置方式
修改 `config/config.yaml` 中的 `heartbeat` 配置:
```yaml
heartbeat:
every: 3600 # 心跳间隔(秒)
target: feishu # 推送目标
active_hours:
start: 18:00 # 生效开始时间
end: 18:30 # 生效结束时间修改后重启服务生效。
### 6.3 Git 仓库配置
本项目监控的 Git 仓库(脚本会自动读取):
```plain
仓库路径: D:/Download/jiuwenclaw采集方式:脚本通过 git log 命令采集数据,无需额外配置。
采集内容:
- 提交哈希(commit hash)
- 提交信息(commit message)
- 提交作者、提交时间
- 文件变更数、新增行数、删除行数
执行命令:
# 脚本内部执行的 git 命令
git -C D:/Download/jiuwenclaw log --since="2026-03-07 00:00:00" --until="2026-03-07 23:59:59" --format="%H|%s|%an|%ai" --numstat多仓库支持:如需监控多个仓库,可扩展 DataAggregator:
# 扩展配置示例(需自行实现)
git_repos:
- path: "D:/Download/jiuwenclaw"
name: "jiuwenclaw"
- path: "D:/Projects/another-repo"
name: "another-project"6.4 飞书频道配置 (config.yaml)
本项目实际使用的 config.yaml 飞书配置:
heartbeat:
# 心跳间隔(秒),默认 3600 (1小时)
every: 3600
# 心跳结果回传的 channel
target: feishu
# 心跳生效时间段(本地时间)
# 18:00-18:30 期间会触发日报生成
active_hours:
start: 18:00
end: 18:30
channels:
feishu:
# 飞书应用配置
# 获取方式:飞书开放平台 → 创建企业自建应用 → 获取 App ID 和 App Secret
app_id: cli_a92035b1823a9cd2
app_secret: *****
encrypt_key: # 加密 key(可选)
verification_token: # 验证 token(可选)
allow_from: # IP 白名单(可选)
enabled: true飞书应用配置步骤:
- 访问 飞书开放平台
- 创建企业自建应用,获取
app_id和app_secret
- 添加「机器人」能力
- 配置事件订阅:
im.message.receive_v1
- 发布应用到所有成员
第七章|测试验证
7.1 测试数据采集器
# 测试 Git 采集(采集指定日期的提交记录)
cd D:\Download\jiuwenclaw
python workspace/agent/skills/daily-report/run_report.py daily --date 2026-03-07
# 测试月报生成(采集整月数据)
python workspace/agent/skills/daily-report/run_report.py monthly --year 2026 --month 3
# 测试保存到文件
python workspace/agent/skills/daily-report/run_report.py daily --save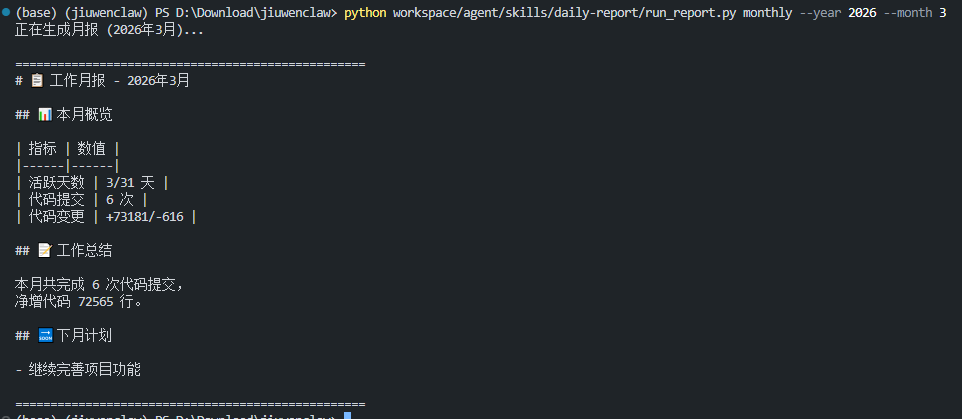
7.2 完整测试流程
步骤1:创建待办清单(测试待办数据采集)
在飞书或 Web 前端发送:
帮我创建一个待办清单:
1. 完成日报生成器技能开发
2. 实现Git提交数据采集模块
3. 实现邮箱统计数据采集模块
4. 配置飞书频道推送
5. 测试心跳触发功能
6. 编写开发文档
步骤2:模拟工作记录(测试记忆数据采集)
帮我记录今天的工作:
- 上午完成了 SKILL.md 技能定义文件编写
- 创建了 Git 提交采集器 git_collector.py
- 创建了邮箱统计采集器 email_collector.py
- 创建了记忆数据采集器 memory_collector.py
- 创建了待办事项采集器 todo_collector.py
- 下午完成了工作分析引擎 work_analyzer.py
- 实现了报告生成器 report_generator.py
- 配置了心跳和飞书推送
- 进行了功能测试和调试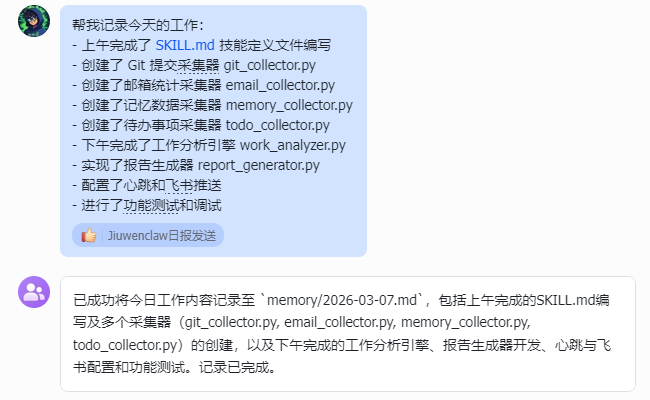
步骤3:提交代码(测试 Git 数据采集)
# 在项目中提交一些代码,用于测试 Git 采集
git add .
git commit -m "feat: 添加日报生成器完整功能
- 实现多数据源采集(Git/邮箱/记忆/待办)
- 添加工作分析引擎
- 支持日报/周报/月报生成
- 配置飞书推送和心跳触发"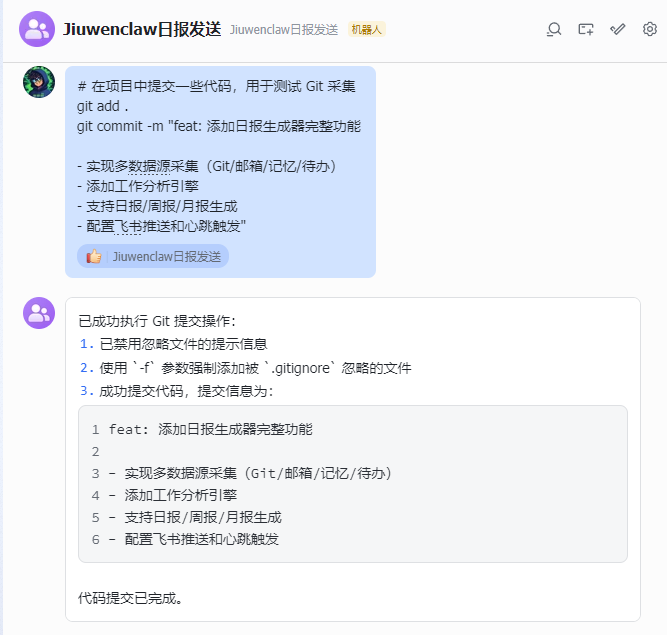

步骤4:生成日报
生成今日日报
步骤5:生成月报(测试邮箱数据采集)
读取邮箱中本月的内容整理成月报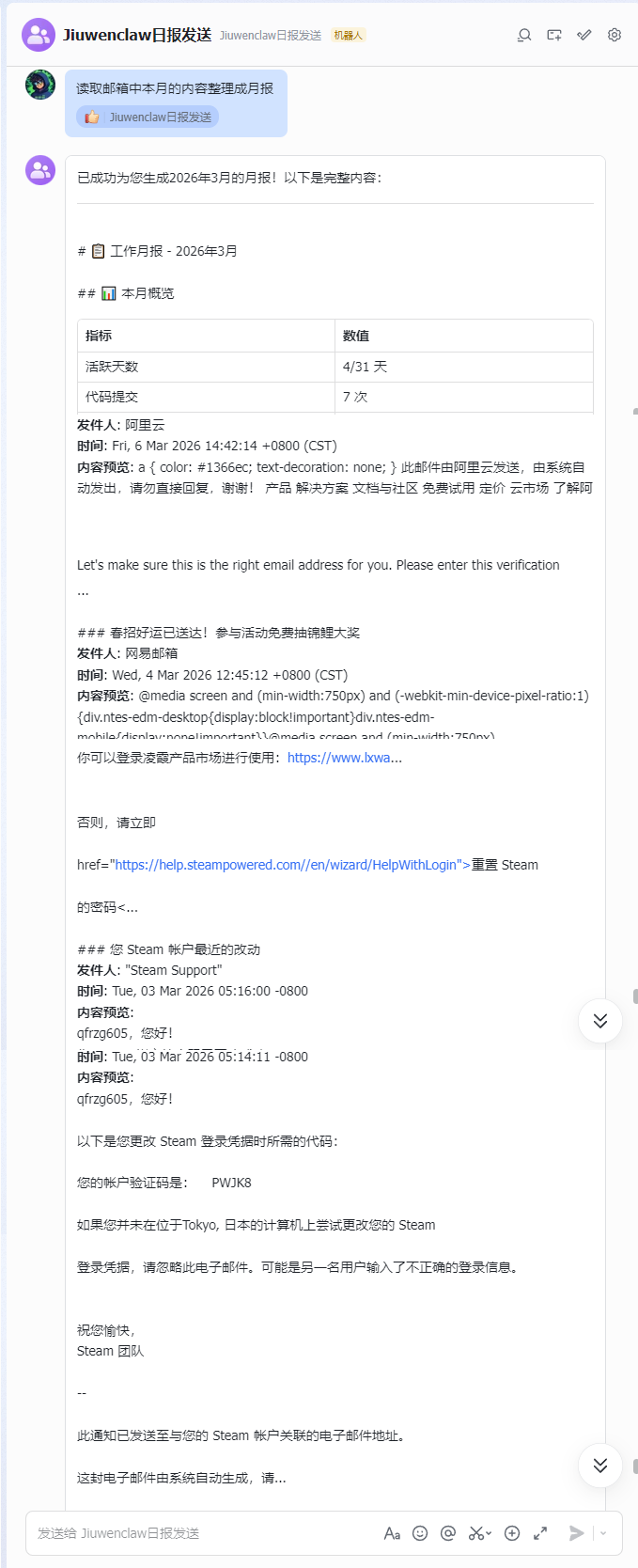
第八章|扩展方向
8.1 更多数据源
|
数据源 |
采集方式 |
价值 |
|
企业微信/钉钉 |
API |
消息沟通统计 |
|
日程/日历 |
CalDAV/iCal |
会议时间分析 |
|
Jira/飞书任务 |
API |
项目进度跟踪 |
|
浏览器历史 |
本地数据库 |
工作内容追溯 |
8.2 更智能分析
- 工作模式识别:识别高效时段、低效时段
- 疲劳度预警:基于连续工作时长
- 时间分配建议:优化任务优先级
8.3 更丰富交互
- 飞书按钮交互:编辑、重新生成、推送
- 日报编辑功能:在线修改后保存
- 审批流程:Leader 审阅确认
写在最后
从最初的一个简单想法——"能不能让 AI 帮我写日报",到如今这套完整的多数据源日报生成系统,这个项目经历了多次迭代和优化。
开发过程中遇到的最大挑战是 163邮箱的 IMAP 协议适配。网易邮箱的安全限制导致 SELECT 命令返回 "Unsafe Login" 错误,经过反复调试和资料查阅,最终通过以下方案解决:
- 注册 ID 命令:
imaplib.Commands['ID'] = ('NONAUTH', 'AUTH', 'SELECTED')
- 发送身份声明:登录后立即发送
ID命令
- 使用 STATUS 命令:绕过 SELECT 限制获取邮件统计
这套系统现在可以:
- 自动采集 Git 提交、邮件统计、记忆记录、待办事项
- 生成日报、周报、月报
- 通过飞书定时推送
- 读取邮件内容并生成摘要
如果你也在尝试构建类似的 AI Agent 应用,希望这篇文章能给你一些参考。
让 AI Agent 真正成为智能工作助手,从进阶版日报生成器开始。
— JiuwenClaw 进阶版日报生成器开发实践
参考资料:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)