基于CIFAR10 数据集的图像分类模型的优化
目录
前言
笔者跟随B站小土堆做完了一个完整的模型训练任务,具体参考基于CIFAR10的模型训练,但是笔者并不满足于当前的模型预测准确率,于是决定探究模型优化的方法
一、获取当前模型的最大预测准确率
以下为模型训练50轮之后的准确率:
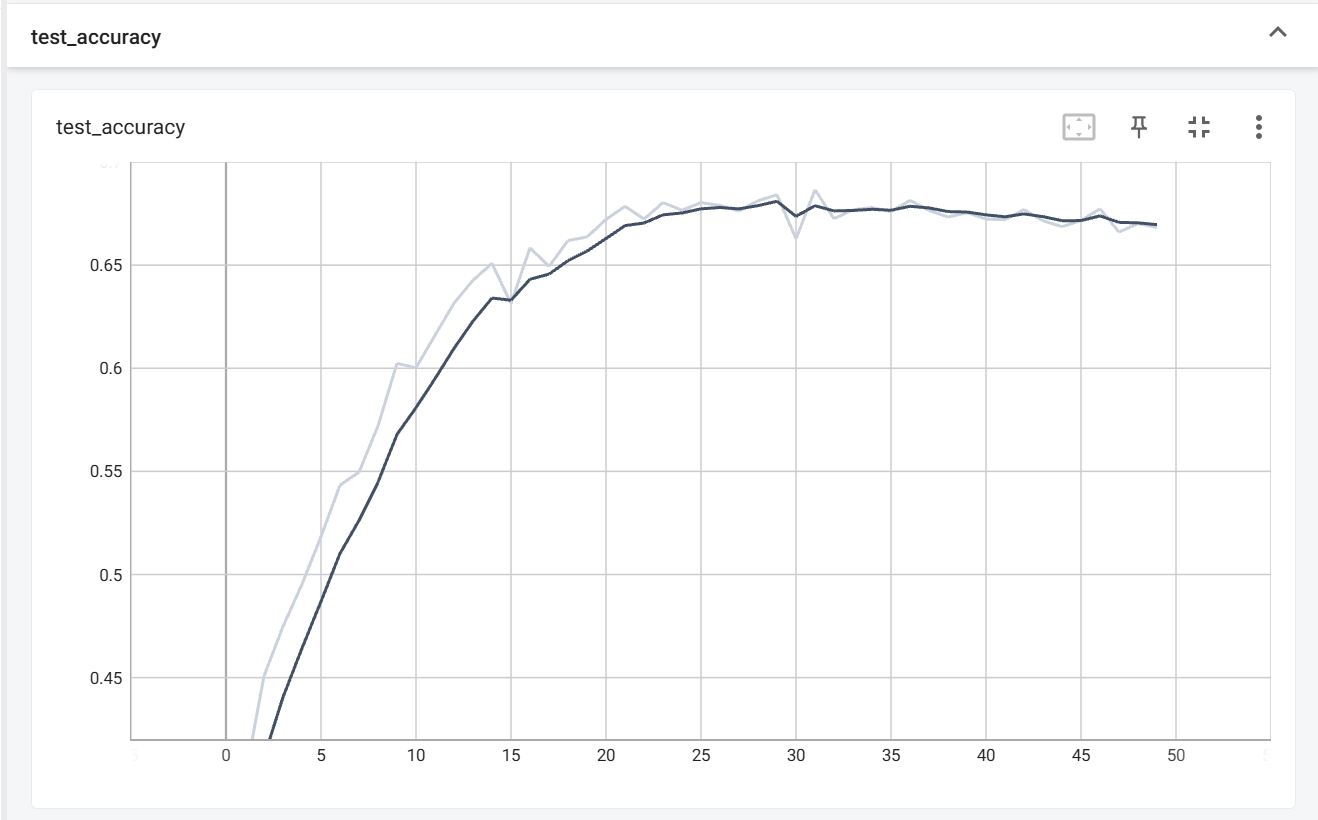
由图像可见,模型在训练20轮之后准确率逐渐趋于平缓,在29轮时取得最大值0.68,在30轮之后呈现下降趋势。
二、尝试通过优化参数的方式提高准确率
1.降低学习率
首先直接载入上面效果最好的模型,也就是第29轮训练的模型
model = torch.load("model_29.pth")然后分别将学习率改为1e-3和1e-4,分别训练10轮先看看效果如何(笔者没有英伟达GPU,只能用CPU训练,所以只训练10轮)
这是学习率为1e-3的结果
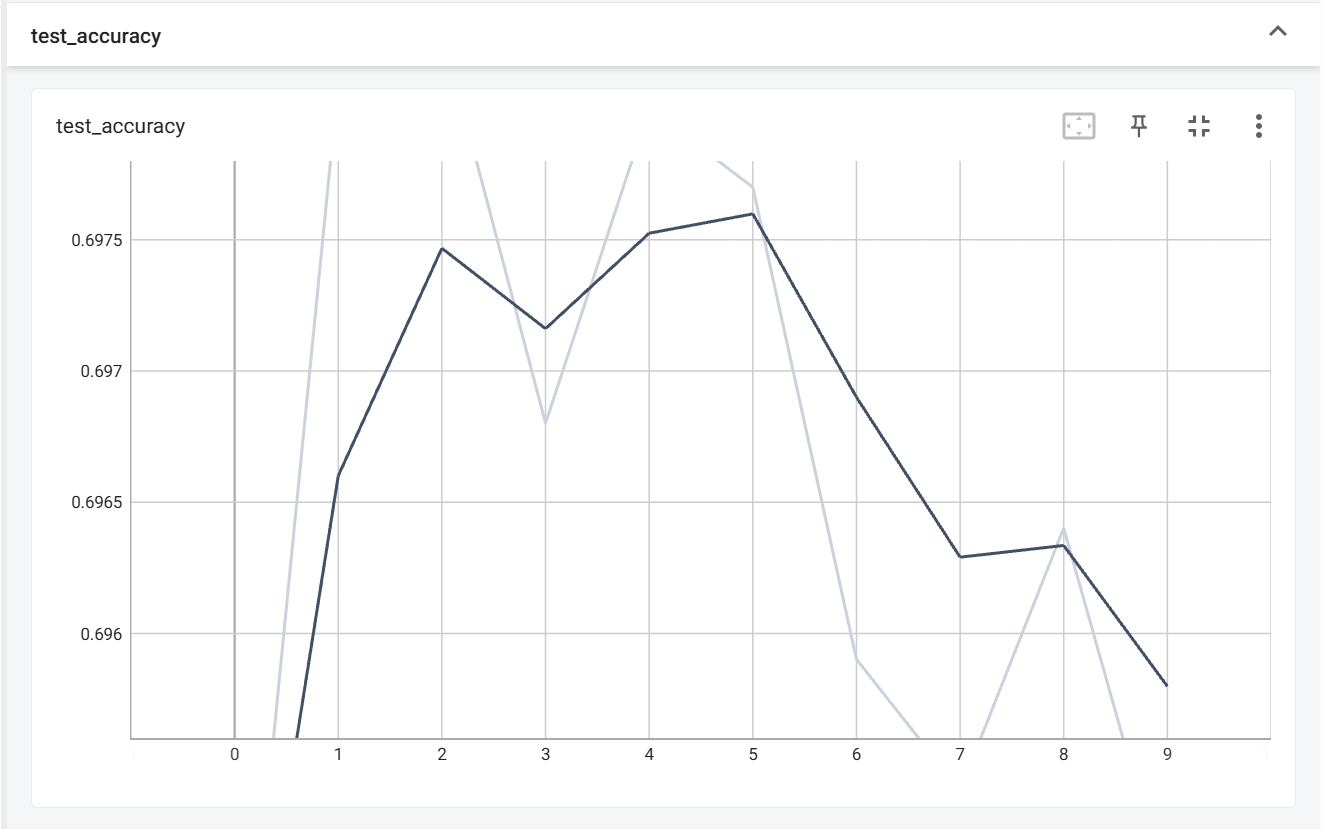
可以看见提升效果非常局限,最大值是在训练第5轮时,达到了0.6977,再试试把学习率降到1e-4吧
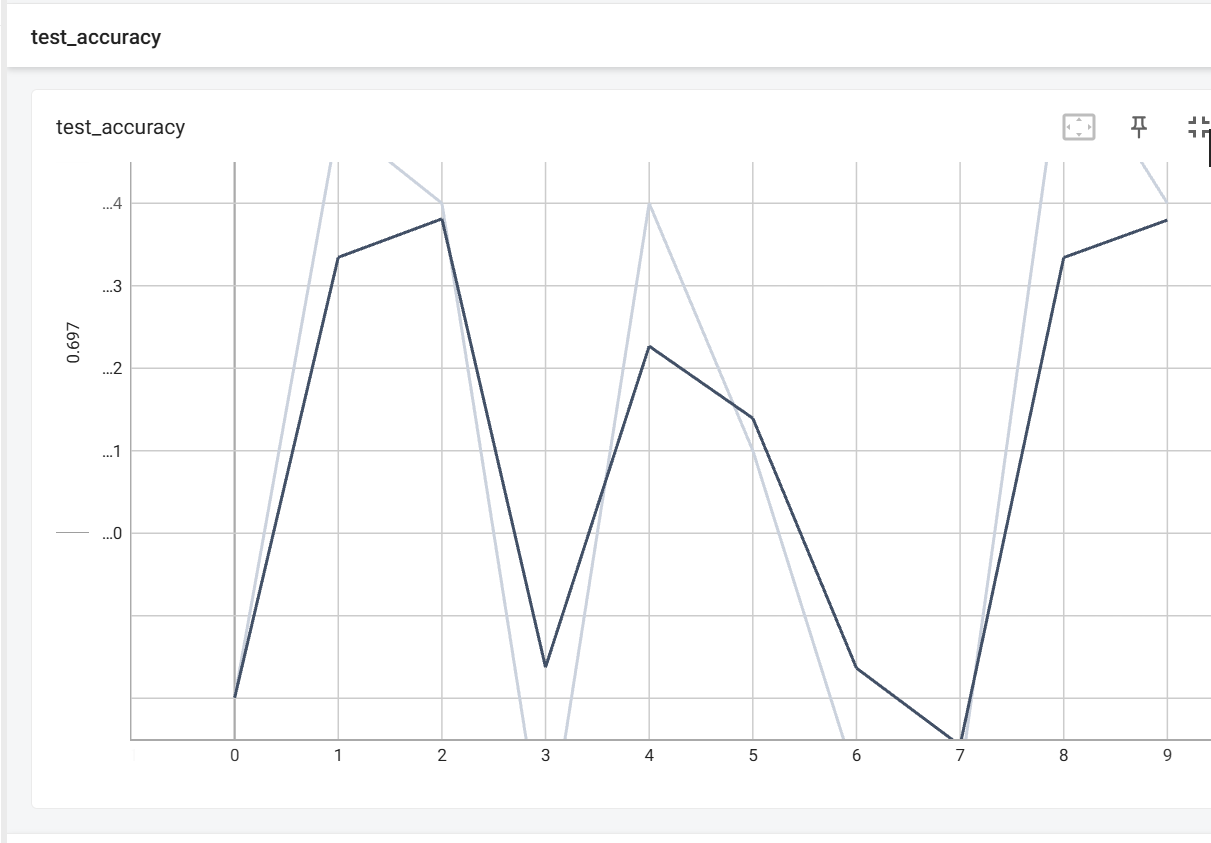
从结果上看完全没有长进,看来这条路走不通,再尝试换换别的方法
2.尝试从多方面修改
(1)数据增强
通过对数据进行预处理,以提高准确率,减少过拟合,增强鲁棒性
# 训练数据集的转换
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR10 均值和标准差
])(2)修改优化器并使用学习率调度
# 优化器
learning_rate = 1e-3
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=1e-4)
# 学习率调度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)(3)使用早停策略
提前设置best_accuracy用以记录最好的准确率,当准确率不再上升时停止训练
(4)在原本的神经网络的线性层中间加入非线性激活
class Neural_Network(nn.Module):
def __init__(self):
super().__init__()
self.mode1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
ReLU(), # 尝试加入非线性激活
Linear(64, 10)
)
def forward(self, x):
x=self.mode1(x)
return x先训练50轮看看效果
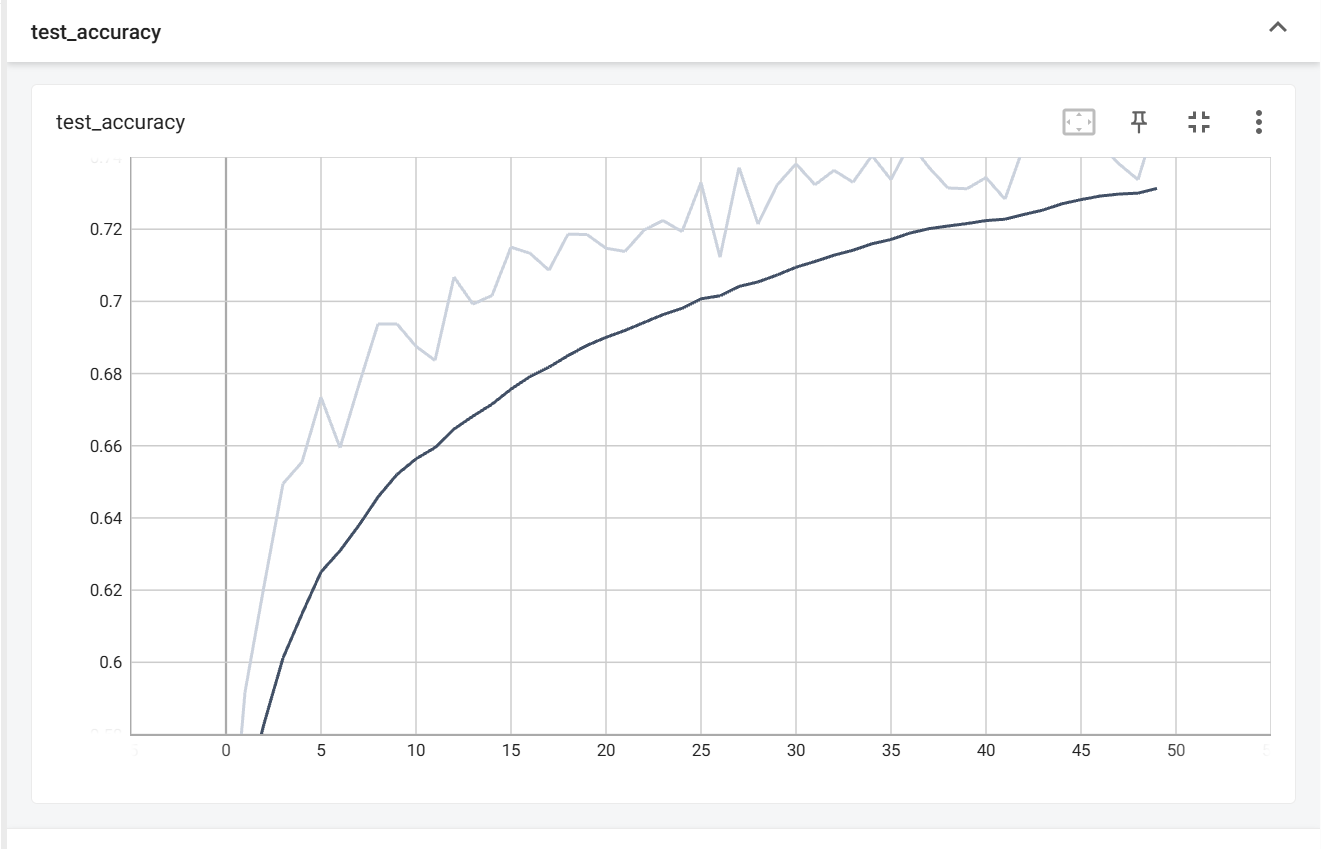
很明显准确率相较之前有所提升,但似乎还没有达到瓶颈,那我们在现有的基础上继续训练
(设置了早停机制但是epoch忘记改了)
结果如下
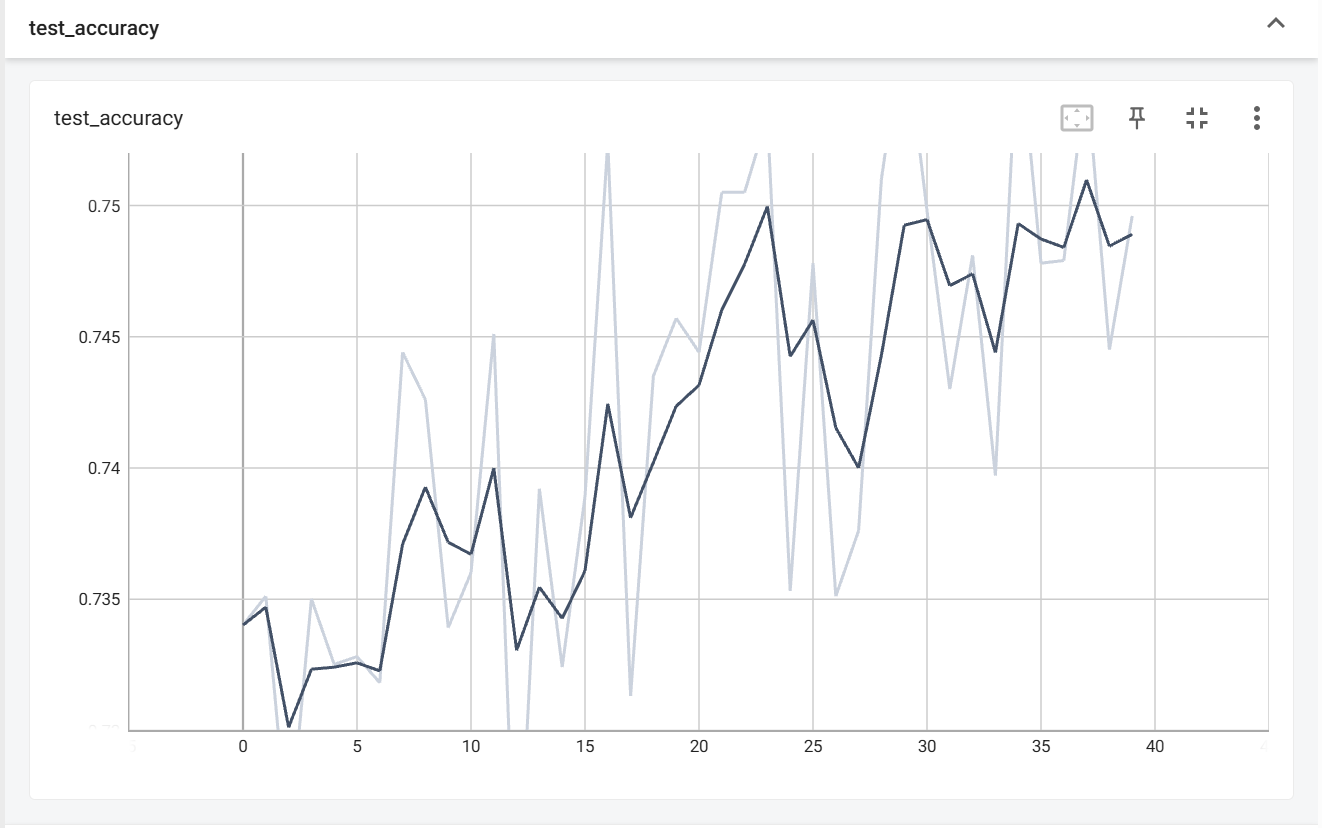
在第29步时达到最大准确率0.757,相较于一开始的状态提升了约8个百分点,只能说没白忙活,但我依旧不满足,有没有什么办法能得到更高的准确率呢
三.尝试通过更换神经网络来提高准确率
尝试使用ResNet18网络,在Trae的帮助下构造出ResNet18网络,写在new_model.py文件中
代码如下(new_model.py):
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, BatchNorm2d, ReLU, MaxPool2d, AdaptiveAvgPool2d, Linear, Dropout
# 基本残差块
class BasicBlock(nn.Module):
expansion = 1 # 扩展因子,用于计算输出通道数
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# 第一个卷积层
self.conv1 = Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = BatchNorm2d(out_channels) # 批归一化
self.relu = ReLU(inplace=True)
# 第二个卷积层
self.conv2 = Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = BatchNorm2d(out_channels) # 批归一化
# 下采样模块(用于调整通道数和特征图尺寸)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x # 跳跃连接的输入
# 主路径
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 如果需要下采样(通道数或尺寸不匹配)
if self.downsample is not None:
identity = self.downsample(x)
# 残差连接:将输入直接加到输出
out += identity
out = self.relu(out)
return out
# ResNet18 网络
class ResNet18(nn.Module):
def __init__(self, num_classes=10):
super(ResNet18, self).__init__()
self.in_channels = 64
# 初始卷积层
self.conv1 = Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) # CIFAR10 使用 3x3 卷积,步长 1
self.bn1 = BatchNorm2d(64)
self.relu = ReLU(inplace=True)
# 移除 maxpool,因为 CIFAR10 输入已经很小
# 残差层
self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1) # 第1阶段,2个残差块
self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2) # 第2阶段,步长2
self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2) # 第3阶段,步长2
self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2) # 第4阶段,步长2
# 全局平均池化
self.avgpool = AdaptiveAvgPool2d((1, 1))
# 全连接层,添加 Dropout 减少过拟合
self.dropout = Dropout(p=0.5) # Dropout 概率 0.5
self.fc = Linear(512 * BasicBlock.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
# 如果步长不等于1或输入通道不等于输出通道,需要下采样
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = Sequential(
Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
BatchNorm2d(out_channels * block.expansion)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
# 添加剩余的残差块
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return Sequential(*layers)
def forward(self, x):
# 初始卷积
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# 残差层
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 池化和全连接
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x) # 在全连接前添加 Dropout
x = self.fc(x)
return x
# 测试模型
if __name__ == "__main__":
model = ResNet18()
input = torch.ones((64, 3, 32, 32)) # CIFAR10 输入尺寸
output = model(input)
print(f"输入形状: {input.shape}")
print(f"输出形状: {output.shape}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters())}")看一下模型训练20轮之后的结果
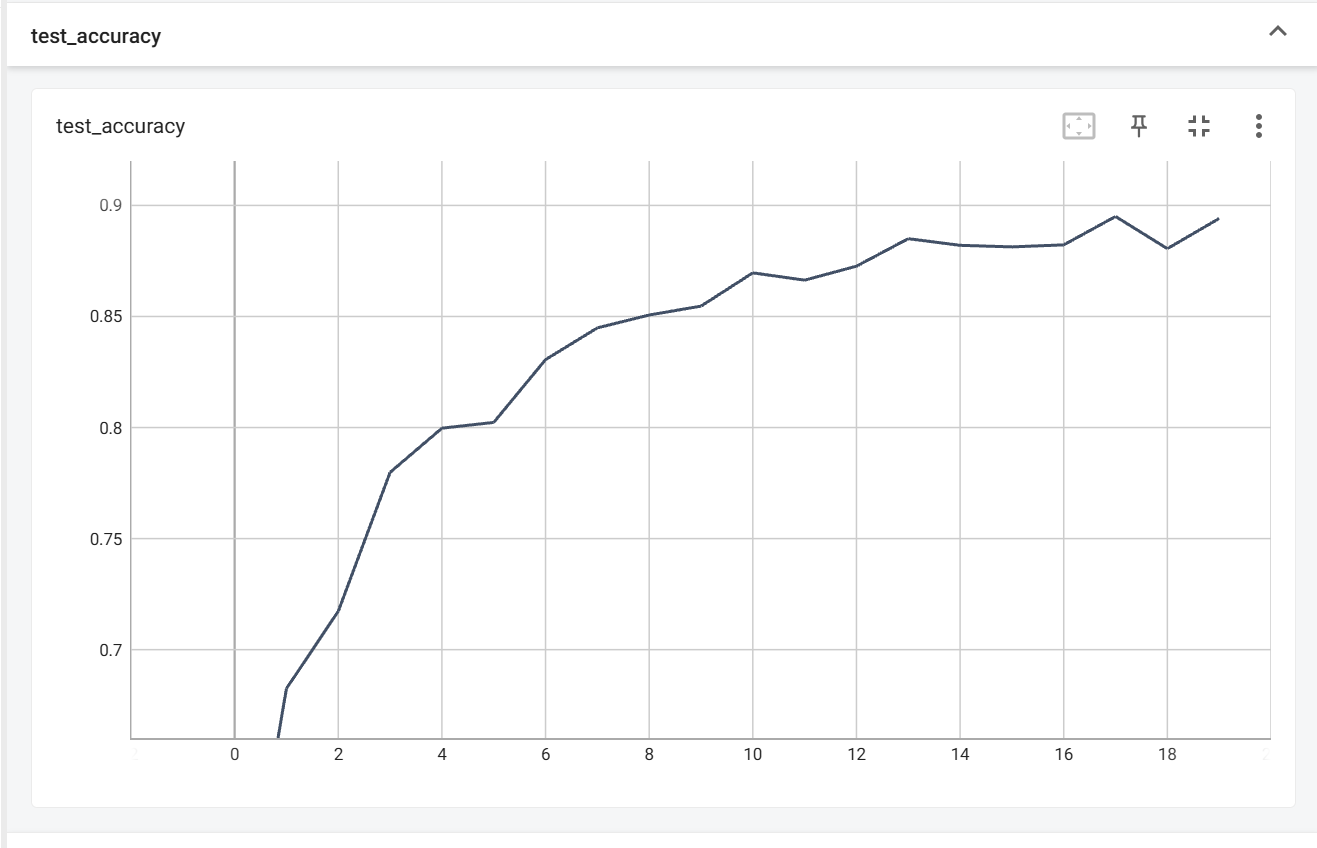
最高的准确率能达到0.895,相比一开始已经提升了许多(大约20个百分点),而且收敛速率也更快。(继续训练的话能突破0.9)
缺点:模型更复杂了,运行速率明显慢于初始版本,在没有GPU的情况下要跑好几个小时。
完整代码:
train.py
import torch
import torchvision
from torch import nn
from model import *
from torch.utils.tensorboard import SummaryWriter
from new_model import *
# 训练数据集的转换
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR10 均值和标准差
])
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=train_transform, download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=train_transform, download=True)
# 数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为:{train_data_size}")
print(f"测试数据集的长度为:{test_data_size}")
# 加载数据集
train_dataloader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
test_dataloader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
#构造网络模型
# model = torch.load("n_r18_model_17.pth")
model = New_ResNet18()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-3
# 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=1e-4)
# 学习率调度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)
# 设置训练的轮次
epoch = 100
# 添加tensorboard
writer = SummaryWriter("logs_train")
best_accuracy = 0
patience = 10
cnt = 0
for i in range(epoch):
print(f"-----第{i}轮训练开始-----")
# 训练步骤开始
model.train()
for step, (images, labels) in enumerate(train_dataloader):
output = model(images)
loss = loss_fn(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 100 == 0:
print(f"训练次数: {step}, loss: {loss.item()}")
writer.add_scalar("train_loss", loss.item(), step)
# 测试步骤开始
model.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 测试时不计算梯度
for images, labels in test_dataloader:
output = model(images)
loss = loss_fn(output, labels)
total_test_loss += loss.item()
accuracy = (output.argmax(1) == labels).sum() # 计算准确率
total_accuracy += accuracy
test_accuracy = total_accuracy/test_data_size
print(f"第{i}轮整体测试集上的测试损失为:{total_test_loss}")
print(f"第{i}轮整体测试集上的测试准确率为:{test_accuracy}")
writer.add_scalar("test_loss", total_test_loss, i)
writer.add_scalar("test_accuracy", test_accuracy, i)
# 保存模型
if test_accuracy > best_accuracy:
best_accuracy = test_accuracy
cnt=0
torch.save(model, f"n_r18_model_{i}.pth")
print(f"第{i}轮模型已保存")
else:
cnt+=1
if cnt>=patience:
print(f"第{i}轮未提升,已停止训练")
break
scheduler.step()
writer.close()new_model.py
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, BatchNorm2d, ReLU, MaxPool2d, AdaptiveAvgPool2d, Linear, Dropout
# 基本残差块
class BasicBlock(nn.Module):
expansion = 1 # 扩展因子,用于计算输出通道数
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# 第一个卷积层
self.conv1 = Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = BatchNorm2d(out_channels) # 批归一化
self.relu = ReLU(inplace=True)
# 第二个卷积层
self.conv2 = Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = BatchNorm2d(out_channels) # 批归一化
# 下采样模块(用于调整通道数和特征图尺寸)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x # 跳跃连接的输入
# 主路径
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 如果需要下采样(通道数或尺寸不匹配)
if self.downsample is not None:
identity = self.downsample(x)
# 残差连接:将输入直接加到输出
out += identity
out = self.relu(out)
return out
# ResNet18 网络
class ResNet18(nn.Module):
def __init__(self, num_classes=10):
super(ResNet18, self).__init__()
self.in_channels = 64
# 初始卷积层
self.conv1 = Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False) # CIFAR10 使用 3x3 卷积,步长 1
self.bn1 = BatchNorm2d(64)
self.relu = ReLU(inplace=True)
# 移除 maxpool,因为 CIFAR10 输入已经很小
# 残差层
self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1) # 第1阶段,2个残差块
self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2) # 第2阶段,步长2
self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2) # 第3阶段,步长2
self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2) # 第4阶段,步长2
# 全局平均池化
self.avgpool = AdaptiveAvgPool2d((1, 1))
# 全连接层,添加 Dropout 减少过拟合
self.dropout = Dropout(p=0.5) # Dropout 概率 0.5
self.fc = Linear(512 * BasicBlock.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
# 如果步长不等于1或输入通道不等于输出通道,需要下采样
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = Sequential(
Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
BatchNorm2d(out_channels * block.expansion)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
# 添加剩余的残差块
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return Sequential(*layers)
def forward(self, x):
# 初始卷积
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
# 残差层
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 池化和全连接
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x) # 在全连接前添加 Dropout
x = self.fc(x)
return x
# 测试模型
if __name__ == "__main__":
model = ResNet18()
input = torch.ones((64, 3, 32, 32)) # CIFAR10 输入尺寸
output = model(input)
print(f"输入形状: {input.shape}")
print(f"输出形状: {output.shape}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters())}")总结
本节内容是我在学完B站小土堆的视频之后的一个自我探究的过程,最终也是在一定程度上对原本的模型进行了一定程度的改进,当然最终正确率90%意味着模型仍有提升的空间,笔者也是初学,上述优化步骤也纯属个人探索,还望各位大佬不吝赐教。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)