Iceoryx(冰羚):所有权转移设计详解
理解Chunk
| 低地址 高地址 | |||
| ChunkHeader (元数据) |
UserHeader (可选,自定义) |
back_offset (4字节,反查用) |
UserPayload (业务数据T) |
chunk 是共享内存池中一段 连续的内存,也是Publisher和Subscriber发送和接受数据的 传输单元
设计1: 内存分布
ChunkHeader 就是“信封”,UserPayload 就是“信的内容”。
信封记录了发件人(originId)、序号(sequenceNumber)、内容的大小和位置
// chunk_header.hpp:153-171
uint32_t m_userHeaderSize; // user-header 大小
uint8_t m_chunkHeaderVersion; // 版本号(兼容性检测)
uint16_t m_userHeaderId; // user-header 类型标识
UniquePortId m_originId; // 谁发的(publisher ID)
uint64_t m_sequenceNumber; // 消息序列号
uint64_t m_chunkSize; // 整个 chunk 的总大小
uint64_t m_userPayloadSize; // 用户数据部分的大小
uint32_t m_userPayloadAlignment; // 用户数据的对齐要求
UserPayloadOffset_t m_userPayloadOffset; // 从 ChunkHeader 起始到 payload 的偏移量
设计2: 正查和反查
正查:从 ChunkHeader指针 >>> userPayload指针
反查:从 userPayload指针 >>> ChunkHeader指针(用backOffset反推)
源码实现:
// 正查:从信封找到信的内容
void* ChunkHeader::userPayload() {
return reinterpret_cast<void*>(
reinterpret_cast<uint64_t>(this) + m_userPayloadOffset // this + 偏移量
);
}
// 反查:从信的内容找回信封
ChunkHeader* ChunkHeader::fromUserPayload(void* userPayload) {
auto backOffset = reinterpret_cast<UserPayloadOffset_t*>(
userPayloadAddress - sizeof(UserPayloadOffset_t) // payload 前面 4 字节
);
return reinterpret_cast<ChunkHeader*>(
userPayloadAddress - *backOffset // 往回跳
);
}使用场景:
所有权转移设计核心:引用计数
1. publisher 和 subscriber 的所有权转移过程
loan() ---- 所有权:内存池 -> Sample(用户) 用户端持有
publish() ---- 所有权:Sample(用户) → subscriber 发送者不再持有,订阅者持有
不publish ---- 所有权:Sample(用户) → 内存池 出定义域范围,析构归还
2. 引用计数设计
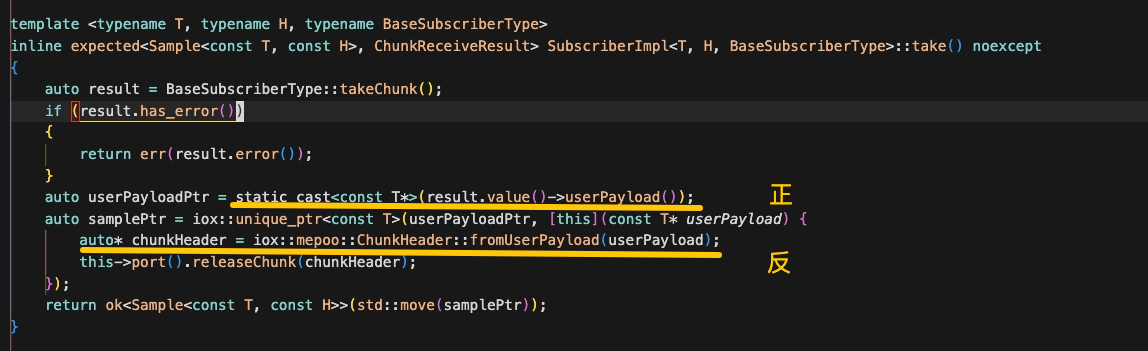
struct ChunkManagement { RelativePointer<ChunkHeader> m_chunkHeader; // 指向 ChunkHeader
referenceCounter_t m_referenceCounter{1U}; // ← 引用计数在这里
RelativePointer<MemPool> m_mempool; // chunk 内存来自哪个池
RelativePointer<MemPool> m_chunkManagementPool; // 自身来自哪个池
};
ChunkManagement 和 ChunkHeader 都是共享内存中的数据,分别从不同的MemPool分配
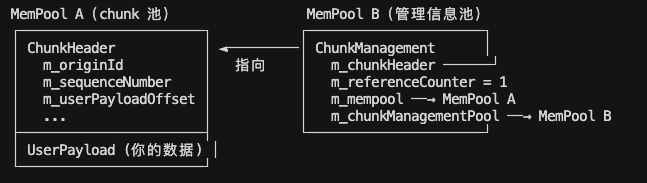
引用计数通过 SharedChunk 自动增加和释放,但与用户无关。用户拿到的是共享内存数据地址。
class SharedChunk {
ChunkManagement* m_chunkManagement; // 不是 ChunkHeader*// 拷贝时 +1
void incrementReferenceCounter() { m_chunkManagement->m_referenceCounter++; }
// 析构时 -1,归零则归还两块内存
void decrementReferenceCounter() { m_chunkManagement->m_referenceCounter--; }
};
3. 引用计数变化逻辑
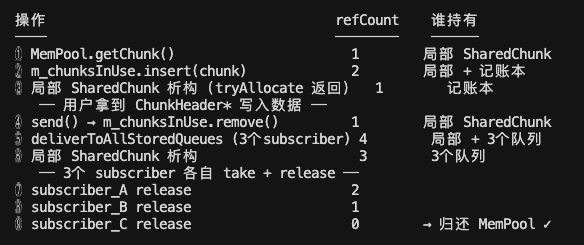
4. 使用 ChunkManagement 管理引用计数的原因
- 引用计数需要Subscriber 和 Publisher 根据不同场景使用,所以 必须放在共享内存中
- 为什么不放在ChunkHeader中:ChunkHeader是为了用户准备的传输数据的部分,如过引用计数放在里面,Publisher和Subscriber可能会进行修改,而影响内存管理
- 分开管理的好处:关注点分离


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)