惊艳!用Python绘制专业级混淆矩阵并计算分类指标(7x7+任意大小)
1. 引言:为什么要重视混淆矩阵?
在机器学习和深度学习项目中,模型评估是至关重要的一环。混淆矩阵(Confusion Matrix)作为分类任务中最直观、最全面的性能展示工具,不仅能呈现模型的预测结果分布,还能衍生出精确率、召回率、F1分数等核心指标。然而,很多开发者仅停留在调用sklearn.metrics.confusion_matrix的层面,缺乏对可视化细节和指标深入计算的理解。
本文将带你从零开始,用Python绘制一张专业级、可定制、功能强大的混淆矩阵图。代码支持任意大小的矩阵,内置精确率/召回率/F1计算,并提供宏平均、微平均、加权平均等总体统计,同时包含进度条可视化、归一化选项、表格化输出等高级特性。最终成品可直接用于论文、技术报告或商业演示。
2. 混淆矩阵基础回顾
对于一个二分类问题,混淆矩阵是一个2×2表格:
| 预测为正 | 预测为负 | |
|---|---|---|
| 实际为正 | TP | FN |
| 实际为负 | FP | TN |
-
TP:真正例,正确预测为正的样本数
-
FP:假正例,错误预测为正的样本数
-
FN:假反例,错误预测为负的样本数
-
TN:真反例,正确预测为负的样本数
基于此,可计算核心指标:
-
精确率 (Precision) = TP / (TP + FP) —— 预测为正的样本中有多少是真正的正类
-
召回率 (Recall) = TP / (TP + FN) —— 实际为正的样本中有多少被正确预测
-
F1分数 = 2 × (Precision × Recall) / (Precision + Recall) —— 精确率和召回率的调和平均
-
准确率 (Accuracy) = (TP + TN) / 总样本数
对于多分类问题,通常采用宏平均(每个类别指标简单平均)、微平均(全局统计计算)、加权平均(按各类样本数加权)来汇总性能。
3. 基础绘制:7x7混淆矩阵
我们先从一个简单的7x7混淆矩阵绘制开始,使用Matplotlib和Seaborn。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 示例7x7混淆矩阵(7个类别)
cm = np.array([
[85, 2, 1, 0, 0, 1, 3],
[1, 92, 0, 0, 2, 0, 0],
[0, 1, 78, 4, 0, 0, 0],
[0, 0, 3, 88, 1, 0, 0],
[1, 0, 0, 2, 82, 0, 0],
[2, 1, 0, 0, 0, 79, 1],
[1, 0, 0, 0, 0, 2, 91]
])
class_names = ['Action', 'Adventure', 'Comedy', 'Drama', 'Horror', 'Romance', 'Sci-Fi']
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()这段代码能生成一个带数值标签的热力图,但缺少指标信息,且样式较为朴素。下面我们将逐步增强。
4. 进阶美化:集成指标计算与专业配色
我们希望右侧直接显示每个类别的精确率和召回率,并采用统一的蓝色主题(文字黑色,确保打印清晰)。
4.1 指标计算函数
def calculate_metrics(cm):
n = cm.shape[0]
precision, recall, f1, support = [], [], [], []
total_tp = total_fp = total_fn = 0
for i in range(n):
tp = cm[i, i]
fp = cm[:, i].sum() - tp
fn = cm[i, :].sum() - tp
sup = cm[i, :].sum()
p = tp / (tp + fp) if (tp + fp) > 0 else np.nan
r = tp / (tp + fn) if (tp + fn) > 0 else np.nan
f = 2 * p * r / (p + r) if (p + r) > 0 else np.nan
precision.append(p)
recall.append(r)
f1.append(f)
support.append(sup)
total_tp += tp
total_fp += fp
total_fn += fn
accuracy = total_tp / cm.sum() if cm.sum() > 0 else np.nan
return precision, recall, f1, support, accuracy, total_tp, total_fp, total_fn4.2 右侧指标文本面板(早期版本)
早期版本中,我们使用ax.text在右侧垂直排列指标,并添加进度条(每个▇代表5%)。
# 生成指标文本
metrics_text = []
for cls, p, r in zip(class_names, precision, recall):
p_str = f"{p:.2%}" if not np.isnan(p) else "N/A"
r_str = f"{r:.2%}" if not np.isnan(r) else "N/A"
p_bars = "▇" * int(np.floor(p*20)) if not np.isnan(p) else ""
r_bars = "▇" * int(np.floor(r*20)) if not np.isnan(r) else ""
metrics_text.append(
f"{cls}\nPrecision: {p_str} {p_bars}\nRecall: {r_str} {r_bars}\n{'-'*30}"
)
# 在ax1上绘制...但这种方式在类别较多时易导致文本溢出或对齐问题。因此我们最终采用表格化布局。
5. 高级功能:表格化多指标展示
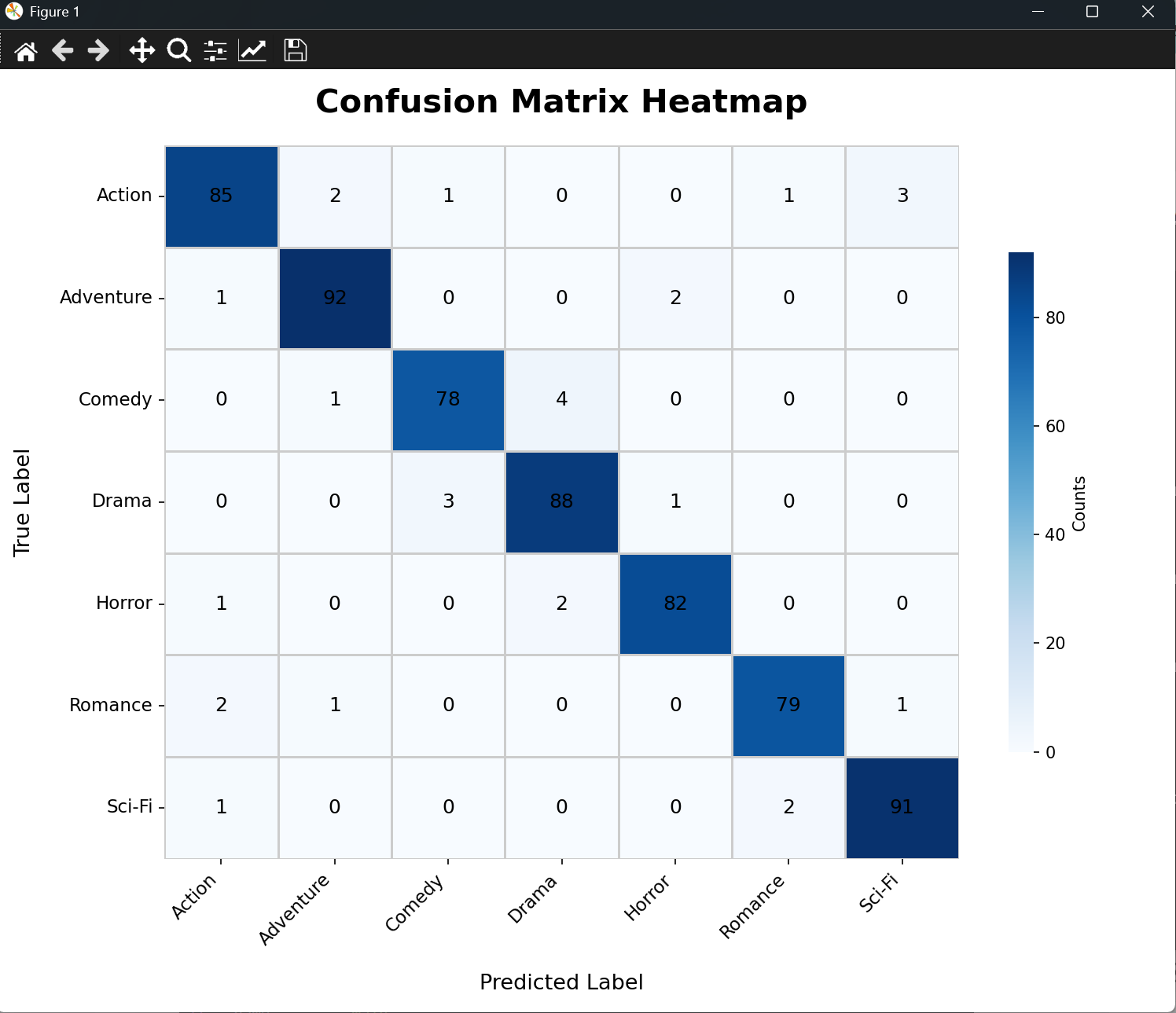
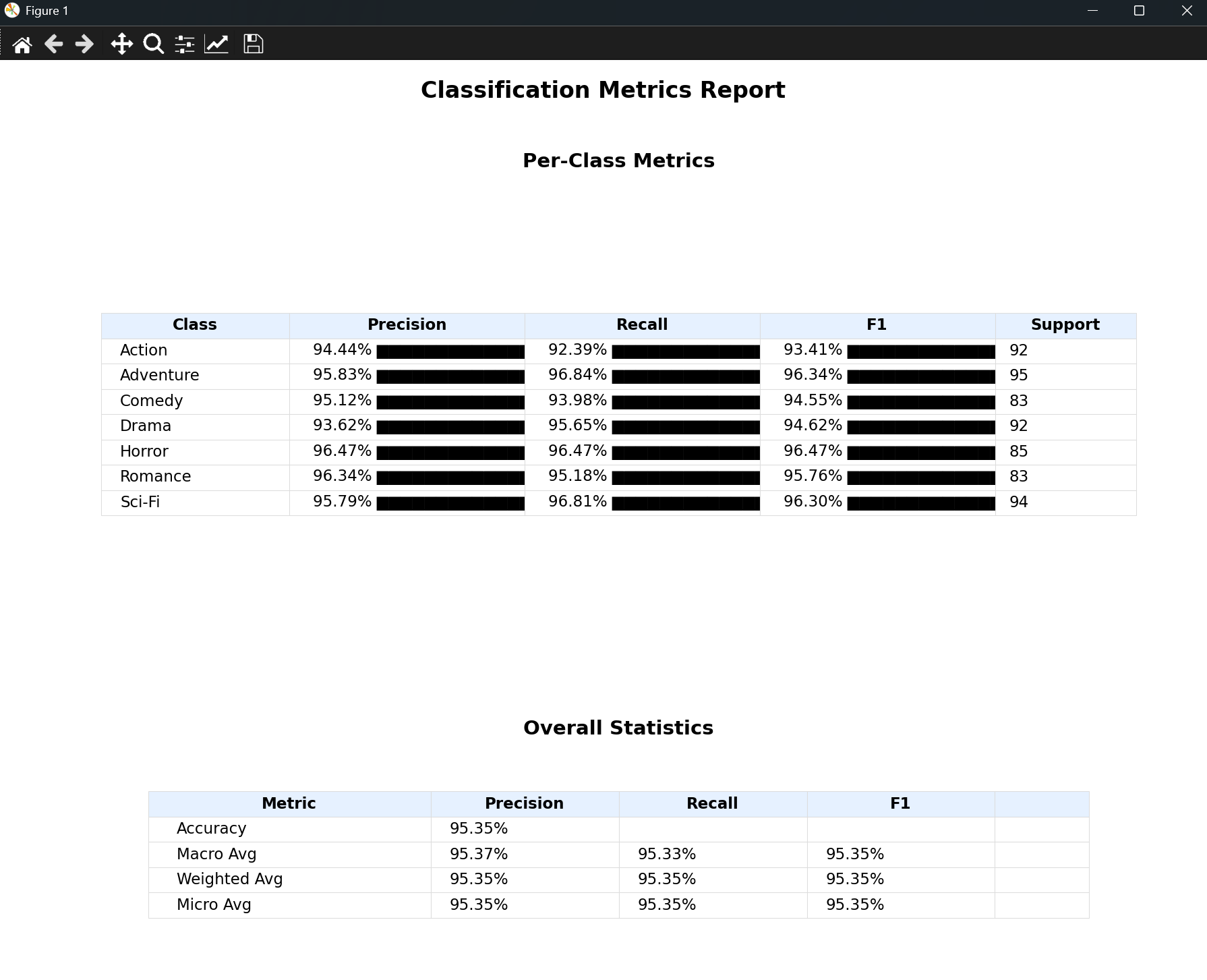
最终版代码:混淆矩阵热力图,两个表格(类别指标表 + 总体统计表)。支持以下特性:
-
任意大小的混淆矩阵(n×n),自动适配。
-
三类平均:宏平均、微平均、加权平均。
-
进度条:每个指标后附可视化进度条(可选)。
-
归一化:可选择显示行归一化百分比。
-
字体兼容:使用
sans-serif和monospace,避免字体缺失。 -
异常处理:除零或空值显示“N/A”。
-
保存图片:支持指定路径保存高清图。
6. 使用示例及效果展示
6.1 示例代码
if __name__ == "__main__":
# 7x7 混淆矩阵
cm = np.array([
[85, 2, 1, 0, 0, 1, 3],
[1, 92, 0, 0, 2, 0, 0],
[0, 1, 78, 4, 0, 0, 0],
[0, 0, 3, 88, 1, 0, 0],
[1, 0, 0, 2, 82, 0, 0],
[2, 1, 0, 0, 0, 79, 1],
[1, 0, 0, 0, 0, 2, 91]
])
class_names = ['Action', 'Adventure', 'Comedy', 'Drama', 'Horror', 'Romance', 'Sci-Fi']
advanced_confusion_matrix(
cm=cm,
classes=class_names,
normalize=False,
show_bars=True,
cmap='Blues',
title='Movie Genre Classification Performance',
figsize=(24, 12),
dpi=100,
save_path='confusion_matrix.png'
)6.2 输出效果描述
运行上述代码后,你将看到一幅结构清晰、信息丰富的图表:
-
左侧:蓝色渐变热力图,每个单元格显示原始计数,对角线深色表示正确分类。
-
右上:类别指标表,每行包含类名、精确率(带进度条)、召回率(带进度条)、F1分数(带进度条)、支持度(该类真实样本数)。进度条由“▇”组成,每个▇代表5%,直观反映指标高低。
-
右下:总体统计表,包含准确率、宏平均、加权平均、微平均的精确率/召回率/F1。空白列用于对齐。
-
底部:进度条图例说明。
所有文字均为黑色,表格边框为浅灰色,标题和表头有浅蓝色背景,整体风格专业、清晰。
7. 参数详解与自定义指南
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
cm |
numpy.ndarray | 必填 | 混淆矩阵,必须是方阵 |
classes |
list | 必填 | 类别名称列表,长度需等于矩阵阶数 |
normalize |
bool | False | 是否对混淆矩阵按行归一化(显示百分比) |
show_bars |
bool | True | 是否在指标后显示进度条 |
cmap |
str/cmap | 'Blues' | 热力图颜色映射,可选 'Blues','Greens','Oranges','Reds' 等 |
title |
str | 'Enhanced Confusion Matrix' | 图表主标题 |
figsize |
tuple | (22,12) | 画布尺寸,可根据类别数调整 |
dpi |
int | 100 | 输出图像分辨率 |
save_path |
str or None | None | 若提供路径,则保存图像到该文件 |
自定义建议:
-
对于类别较多的矩阵(>10),可适当增大
figsize,减小表格字体(代码中已有自适应,但可手动调整table.set_fontsize())。 -
如需修改颜色主题,可将
cmap更换为喜欢的配色,如'Reds'、'Purples'。 -
若不想显示进度条,设置
show_bars=False即可。
8. 常见问题及解决方案
Q1: 运行时出现 Font family 'Arial' not found.
原因:系统中未安装Arial字体。
解决:代码中已使用sans-serif和monospace通用字体族,无需指定具体字体。若仍有警告,可在代码开头添加:
plt.rcParams['font.family'] = 'sans-serif'Q2: 表格中的进度条显示不完整或过短
原因:进度条长度计算为int(p*20),即每5%一个块。如果指标值较低(如12%),将显示2个块,符合设计。
调整:如需改变粒度,修改代码中的乘数(如p*10为10%一个块)。
Q3: 混淆矩阵中有全零行或全零列,导致除零错误
解决:代码已使用np.nan处理,并最终显示“N/A”,不会崩溃。
Q4: 图像保存后文字模糊
解决:增加dpi参数,如dpi=300,同时确保figsize足够大。
9. 总结与展望
本文从零开始,逐步构建了一个功能全面、样式专业、健壮可靠的混淆矩阵可视化工具。它不仅支持7x7矩阵,也能无缝扩展到任意大小的分类任务。通过集成精确率、召回率、F1、支持度、宏/微/加权平均等指标,并以表格化+进度条的形式清晰展示,帮助开发者快速评估模型性能。
未来可扩展方向:
-
支持多输出(multi-output)混淆矩阵。
-
添加交互式功能(如鼠标悬停显示详细信息)。
-
集成到机器学习框架(如TensorBoard)中。
希望本文能成为你模型评估工具箱中的得力助手。如果你有任何改进建议或遇到问题,欢迎在评论区留言交流!
版权声明:本文为CSDN博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)