论文阅读笔记|OBIFlo-SAM: multi-task semantic recognition and segmentation of oraclebone inscription
文章主要提出了 OBIFlo‑SAM 框架,该框架融合了Florence‑2 模型与 SAM(Segment Anything Model),并采用加权 Focal Loss 微调策略,实现了高精度的语义生成、文本对齐、目标检测与零样本分割,有效应对了甲骨文数据稀缺、类别不平衡等问题。
一、研究背景
提出问题
1.甲骨文研究与识别的固有挑战
甲骨文是中华文明最早的成熟文字,由于出土甲骨的稀缺,拓片成为核心研究材料。其独特的象形结构与复杂的视觉 - 语义映射,加上拓片普遍存在的噪声干扰、画质模糊、字符边界不清、局部破损等问题,使得依赖局部特征提取与模板匹配的传统方法无法捕捉其细微结构,难以实现鲁棒的自动化识别与释读,阻碍了古文字精准数字化与文化遗产永续保存。
2.现有深度学习方法的局限
单任务与单模态缺陷:当前方法多为单任务、单模态范式,基于检测的模型能精准定位字符,但缺乏语义解读能力。基于语言的模型能解析语义内容,却又易受视觉噪声干扰。
跨模态融合不足:存在跨模态联合建模能力欠缺、当前方法难以将视觉特征与语言上下文进行有效对齐,破坏了甲骨文固有的“形-意”映射关系,无法在现实场景中同时实现精准定位、抗噪分割和语境敏感的语义推断。
解决方案
1.提出 OBIFlo-SAM 多任务协作框架,融合 Florence-2与 SAM实现互补优势:
(1)由 Florence-2 完成语义生成、文本对齐与字符区域检测。
(2)再由 SAM 基于 Florence-2 输出的字符边界框,进行像素级边界细化,实现噪声环境下的精准分割。
(3)构建级联架构,让语义理解指导空间定位,进而实现精细形态提取,协同完成视觉分割、目标检测与语义生成。
2.关键技术优化
采用加权 Focal Loss 微调预训练 Florence-2,解决 OBI 数据类别不平衡问题,强化低频 / 易混淆字符的学习;构建 OracleVQA 多模态问答数据集,支撑多任务协作训练;设计对象检测与零样本分割模块,基于 SAM 提升复杂场景下的泛化能力。
二、研究方法
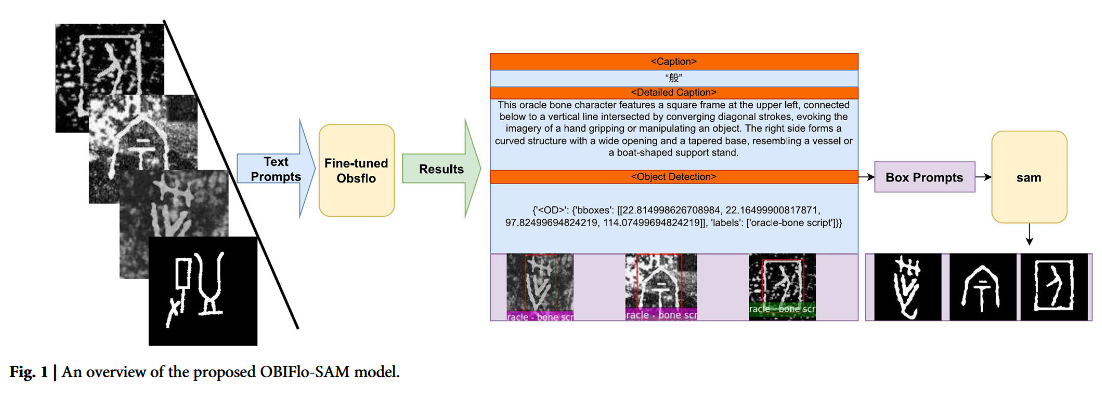
OBIFlo‑SAM 框架以甲骨文拓片图像与文本提示(Text Prompts)为输入,先经微调后的 Obsflo(基于 Florence‑2)模块处理,同步输出甲骨文字形的语义描述(含简要与详细 Caption)和目标检测结果(字符边界框与类别标签),再将检测得到的边界框作为 Box Prompts 输入 SAM 模型,完成分割以精准提取字符轮廓,最终整合语义解读、目标检测与分割结果,为甲骨文的智能识别、数字化保护与学术研究提供高效可靠的技术路径。该模型包含两条任务路径:一是视觉问答任务路径,针对清晰拓片,由微调后的 Florence 直接完成多模态处理并输出文本描述与字幕;二是目标检测与分割路径,针对噪声或低保真拓片,先由 OBIFlo 检测潜在字符区域,再经 SAM 完成像素级分割,为后续解密提供高保真输入。
OBI-Flo fine-tuning with the focal loss(带焦损失的微调)
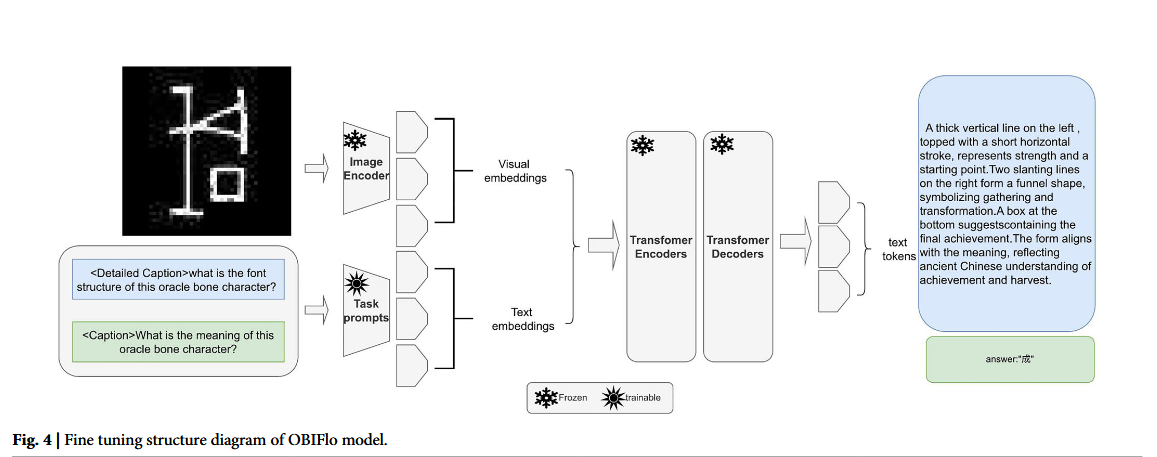
OBI-Flo 以预训练 Florence-2 为基础,采用加权 Focal Loss 微调策略,专门解决甲骨文识别中低频易混淆字符、类别不平衡的问题:
1.模型基础与输入处理
- 以 DaViT(双注意力视觉 Transformer)为视觉编码器,搭配 Transformer 解码器,完成跨模态任务。
- 输入阶段:甲骨文图像统一 resize 为 224×224 并做标准化,同时拼接任务前缀提示(如
<caption>),形成 “图像 + 任务提示” 的多模态输入;视觉编码器将图像转为视觉嵌入,文本编码器将提示转为文本嵌入,二者拼接后送入 Transformer 编码器 - 解码器结构。
2.加权 Focal Loss 设计
- 类别权重计算:根据 token 在训练集中的频率
计算类别权重
,为低频字符分配更高权重,缓解类别分布不均问题。
- 逐步损失定义:
,其中
为聚焦因子,降低易识别样本的损失权重,让模型更关注难识别字符。
- 序列损失:对长度为 N 的生成序列,取逐步损失的平均值作为最终损失
。
3.训练与收敛
对每个生成的 token 计算加权 Focal Loss,将 batch 内所有 token 的损失取平均后反向传播更新模型参数,使模型逐步收敛于甲骨文 caption 生成任务,最终提升对低频、易混淆甲骨文字形的识别与语义描述能力。
Zero-shot OBI image segmentation(零样本图像分割)
针对 Florence-2 在噪声多、边界模糊的甲骨文图像中分割鲁棒性不足的问题,该部分提出OBIFlo-SAM 零样本分割流水线,通过级联微调后的 OBIFlo 与 SAM 模型,实现噪声干扰下的甲骨文字符精准分割:联合微调 OBIFlo 与 SAM,将 “文本驱动的字符定位” 与 “像素级掩码生成” 结合,在无需大量人工标注的前提下,解决未知语义、复杂背景下的甲骨文字符分割问题。

两阶段实现
- 文本驱动检测阶段:输入甲骨文图像与文本查询,微调后的 OBIFlo 执行开放词汇目标检测任务,输出与提示语义对齐的候选字符区域(以边界框形式存储)。
- 掩码生成阶段:将检测得到的边界框作为 Box Prompts 输入 SAM 模型,结合原始图像,SAM 生成像素级分割掩码,将高层语义检测结果细化为精确的字符轮廓掩码,消除背景噪声干扰。
三、实验部分
数据集准备

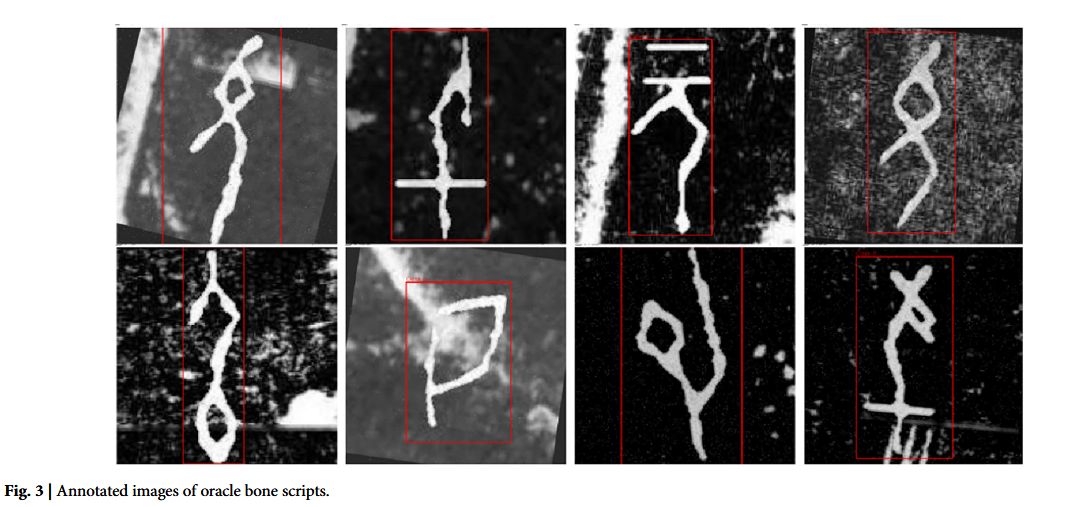
随着甲骨文(OBI)研究的深入,相关数据集已从单模态视觉分类向多模态、深度语义建模演进:从早期的 OBI-100 字符分类基础、Oracle-MNIST 标准化处理,到 HUST-OBC 实现图文对齐、EVOBC 融入字符演化时序信息,再到 OBIMD 整合图像、结构与语义的多模态信息,为跨模态预训练与应用开发提供了全面支撑。
在此基础上,本研究基于 OracleVQA 数据集,结合殷墟文渊数字平台与书法空间开源语料,构建了面向多任务甲骨文分析的专用数据集:采用分层标注策略,先依托 OBIMD 与 GPT-4o 完成字符结构初步推理与形态结构化标注,再由古文字专家团队进行语义丰富与交叉验证,最终形成 “语义含义” 与 “字符形态” 两组问答对,对应 OBIFLO 框架的相关字段。数据集共包含覆盖 372 个字符的 40,263 张训练图像与 10,066 张测试图像,并配套精心整理的语义标注。
为提升数据鲁棒性,研究采用了多种增强手段:引入专家手绘图像以保留真实书写风格多样性、图像翻转以增强模型对对称结构的适应性、局部遮挡以模拟甲骨断裂与磨损、图像倾斜等,确保模型在不同质量图像上的稳定表现。针对语义未知且含噪声的甲骨文拓片,还通过 Roboflow 平台精细标注了 1918 张噪声图像,同样以问答对格式呈现,用于训练 Florence 模型的目标检测模块,实现复杂背景下甲骨文区域的自动识别与定位,结合零样本分割技术完成单字符精准提取,有效解决了传统数据集在语义模糊图像标注上的局限,为甲骨文数字化保护与破译分析提供了关键数据支撑。
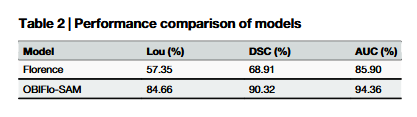
Analysis of fine-tuning strategies(微调策略分析)
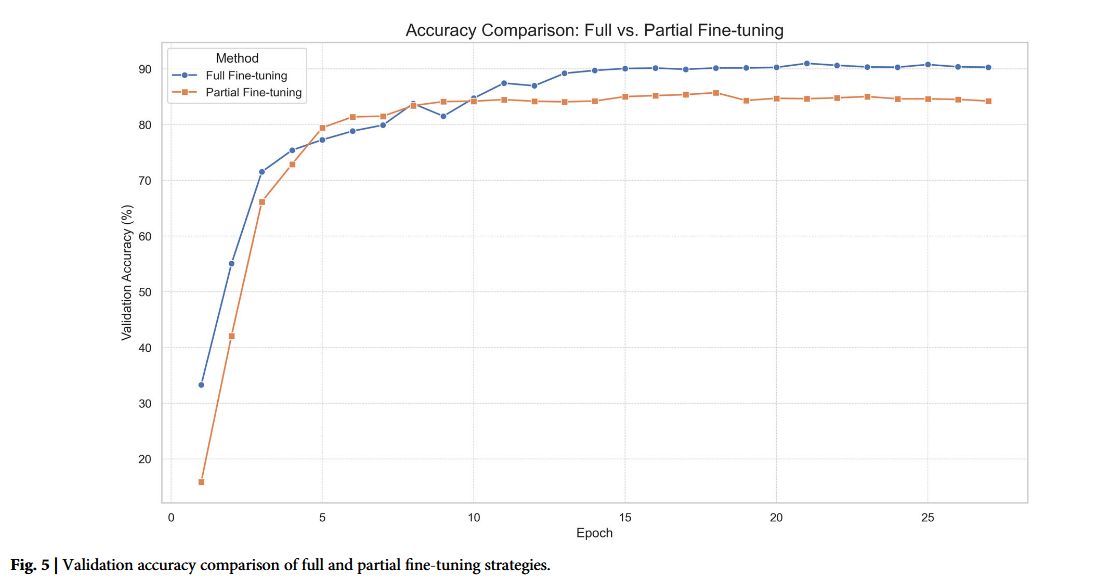
在 NVIDIA A100 上对比 Florence-2 的全量微调与部分微调(冻结 DaViT 视觉编码器)策略后发现,后者收敛更快且最终峰值精度(91.1%)较前者(85.74%)高,因此采用部分微调作为 OBIFlo 的最终配置。
OBI image recognition accuracy(OBI图像识别准确率)
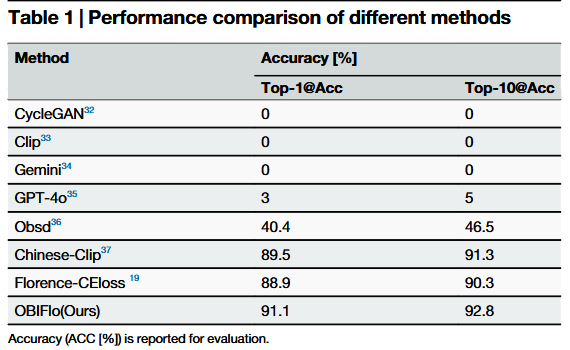
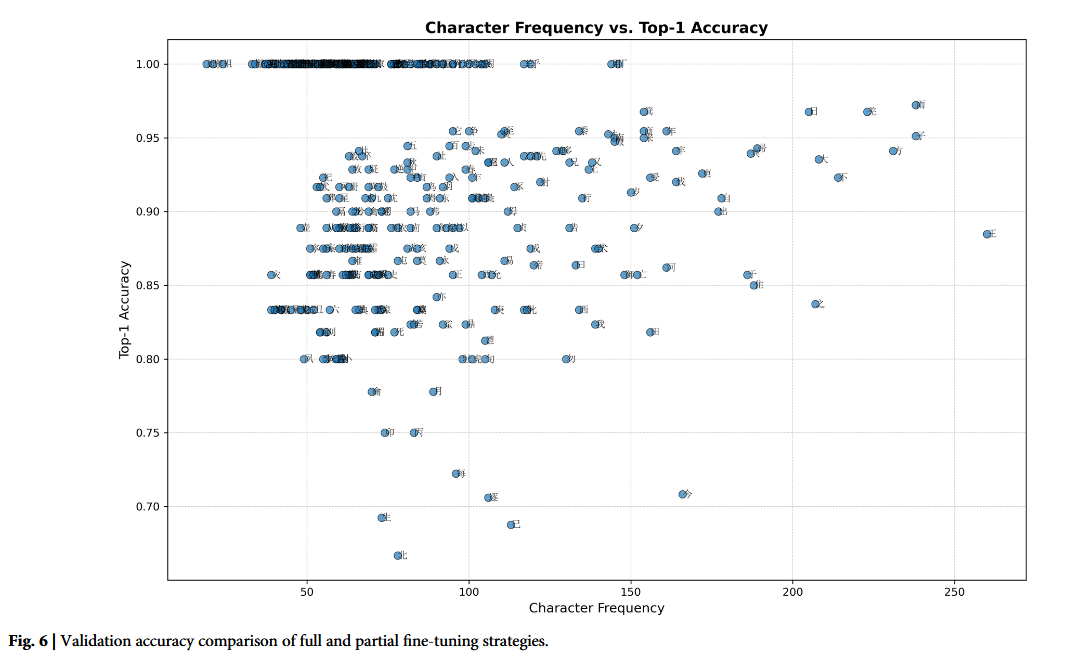
对比实验表明,现有方法在甲骨文语义识别中存在明显不足,而文章 OBIFlo 模型凭借多尺度视觉特征与跨模态对齐实现高精度识别,在高频常用字上准确率超 0.95,在低频稀有字上仍保持 0.85 以上准确率,不受字符出现频率影响,有效缓解了类别长尾不平衡问题,仅在图像严重退化与标注极少的稀有字上精度较低,整体展现出强大的细粒度语义识别能力与鲁棒性。
Qualitative analysis of performance on high-quality samples(高质量样本上的定性分析)
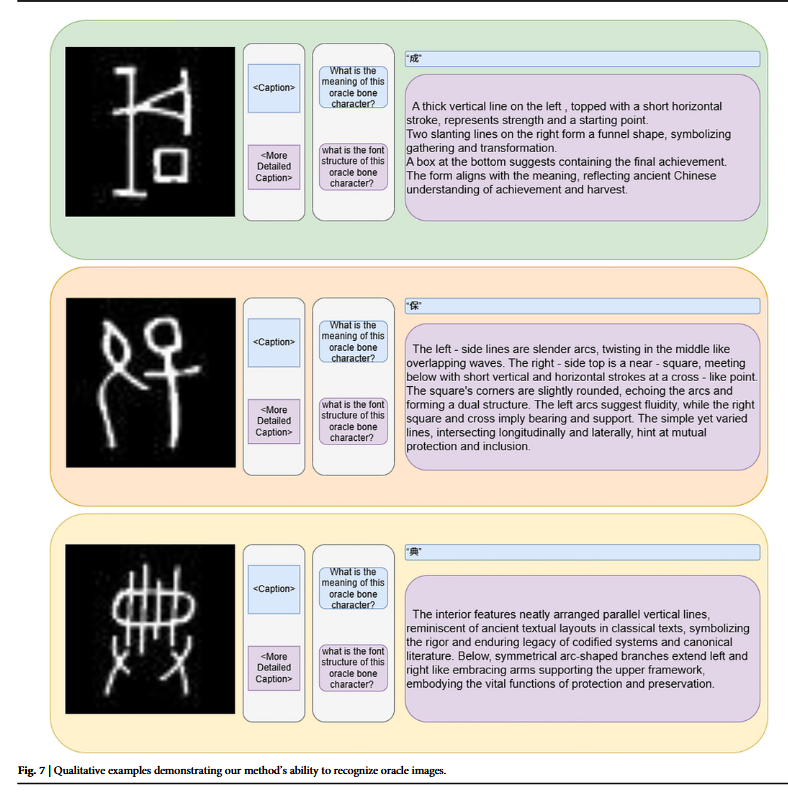
图中的三个示例表明,OBIFlo 模型可从空间布局与字形结构两方面对甲骨文进行精准解读,既能把握宏观分布与排列逻辑,又能精细分析字符轮廓与内部细节,全面展现了在古文字数字化保护与释读中的强鲁棒性与技术创新性。
Qualitative analysis of limitations on challenging cases(对挑战性案例的局限性进行定性分析)
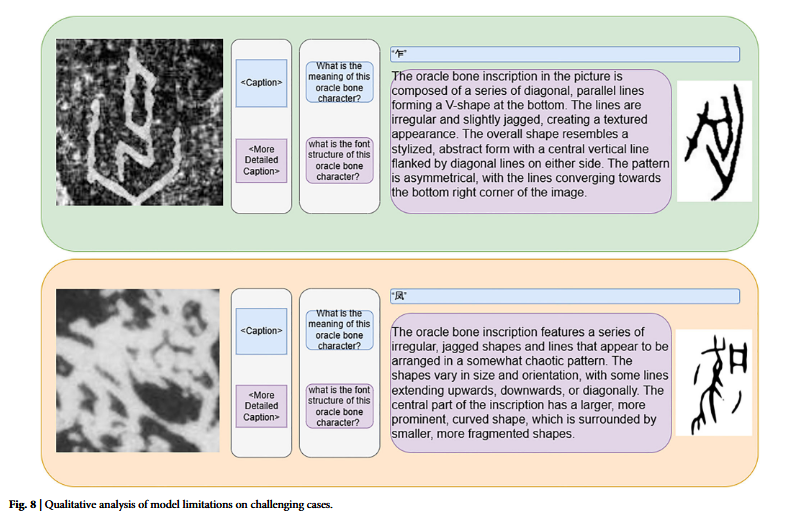
通过对低画质、存在严重噪声的甲骨文样本的定性分析发现,OBIFlo 模型在噪声干扰下描述能力会从语义识别降为几何分析,预测依赖结构最近邻匹配,虽存在局限,但可为古文字研究提供数据驱动的字形关联假设,未来可通过轻量化去噪模块提升性能。
Object detection performance analysis(目标检测性能分析)
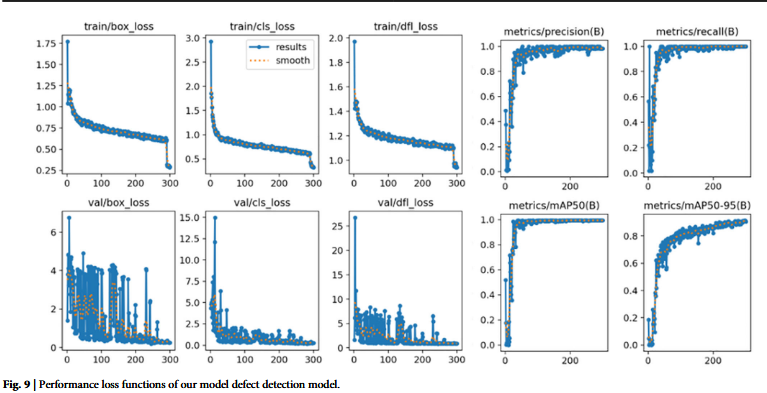
虽然OBIFlo模型在训练集上表现出了显著的检测精度和鲁棒性,但在处理随机采样、噪声丰富的OBI图像时,验证指标的波动暴露出了一定的不稳定性。这一观察强调,未来的研究需要纳入更大规模的数据增强,实施更严格的正则化策略,并开发更专业的检测模块。这些改进对于进一步增强模型在各种动态真实世界场景中的稳定性和泛化性能至关重要。
Zero-shot segmentation performance(零样本分割性能)
实验表明SAM模块的引入有效增强了模型对含噪图像中字符边界的解读能力,优化了伪分割掩膜的几何连续性和语义准确性。

对于定性评估,零样本条件下的代表性分割结果在文章图10中给出,其中输出结果与原始图像和相应的真实标注进行了比较。
四、总结与展望
文章提出的 OBIFlo‑SAM 在甲骨文自动识别与释读上取得突破,模型融合 Florence‑2 与 SAM 并采用加权 Focal Loss 微调,显著提升语义对齐、检测与零样本分割性能,为古文字数字化保护与学术研究提供了跨学科新范式。但仍面临数据集规模与标注质量受限、复杂场景下边界定位与语义细粒度不足、未能完整捕捉文字文化内涵、实际部署复杂度较高等局限;未来可从扩大并规范数据集、优化模型架构与多任务协作、拓展下游任务与跨文字系统应用三方面改进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)