〔重庆理工大学〕计算机视觉方向实验报告【实验一 人脸检测与识别】
实验一 人脸检测与识别(实验报告)
CQUT计算机视觉方向实验报告【实验一 人脸检测与识别】
1.实验目的
进一步掌握使用Haar级联检测器检测人脸的基本方法;
进一步掌握使用EigenFaces人脸识别器的基本方法;
利用你自己掌握的机器学习或深度学习模型,检测和识别包含自己多种表情的人脸,为后续的人脸表情识别打好基础。
2.实验内容
-
任务一:使用Haar级联检测器检测所示图像中的人脸(Plus:检测到人脸后,对双眼打上马赛克,以保护隐私);

-
任务二:使用EigenFaces人脸识别器对图9-10所示的图像(两个人,每人两张人脸图像)执行模型训练,用图9-11所示的两幅人脸图像作为测试图像,完成人脸识别操作;

-
任务三:采集包含同学自己多种表情和多种方位(如正脸、抬头、低头、侧脸)的人脸,采用恰当的机器学习或深度学习模型进行训练,实现同学自身的人脸识别。
-
任务三(拓展):实现了一套实时化人脸表情识别系统,通过摄像头增量采集平静、开心、惊讶、愤怒、悲伤5种表情的人脸数据并存储,基于LBPH算法读取数据集训练表情识别模型,最终可通过摄像头实时检测人脸、判断身份(基于差异度阈值)并识别显示对应表情。
实验要求:
(1)实验的重要环节,以及每个实验结果,应采用截图的方式附在实验报告文档中;
(2)不同的实验内容,应有不同的Halcon程序,其中主要的实验环节代码,应附在实验报告中。同时,每次Halco程序改变,都应保存好相应的程序代码,并按要求上传。
3.实验过程
3.1 实验环境准备
本次实验基于Python 3.8+环境搭建,核心依赖库包括OpenCV(opencv-python)及其扩展包(opencv-contrib-python,提供EigenFaces、LBPH等识别器)、NumPy(数组处理)、OS(路径与文件管理)、Sys(系统交互)和Time(计时功能)。环境配置步骤如下:
- 1.安装核心依赖库:通过命令pip install opencv-python opencv-contrib-python numpy完成安装,确保扩展包版本与OpenCV主包兼容,避免识别器模块缺失。
- 2.准备预训练模型文件:将haarcascade_frontalface_default.xml(人脸检测)和haarcascade_eye.xml(眼睛检测)两个Haar级联分类器文件放置于脚本同级目录,用于目标检测。
- 3.数据文件准备:任务一需提前准备被识别图像(f_lab1.jpg);任务二需提前准备训练图像(f1_train_1.jpg、f1_train_2.jpg、f2_train_1.jpg、f2_train_2.jpg)和测试图像(f1_lab2.jpg、f2_lab2.jpg);任务三及拓展任务通过摄像头实时采集数据,无需提前准备图像文件。
3.2 任务一:人脸与眼睛检测及马赛克处理
3.2.1 核心目标
使用Haar级联检测器检测图像中的人脸,进一步检测人脸区域内的眼睛,对眼睛区域打马赛克保护隐私,并保存处理结果。
3.2.2 实现步骤
1.工作目录配置:通过os.chdir(os.path.dirname(os.path.abspath(_file_)))将工作目录切换至脚本所在路径,避免文件读取路径错误。
2.马赛克函数实现:定义mosaic函数,通过“缩小 - 放大”两步实现像素化效果——先将目标区域(ROI)按比例1/n缩小(线性插值保证平滑),再放大回原尺寸(最近邻插值制造像素化),确保马赛克效果自然且无缩放异常。实现代码如下:
# 马赛克处理核心函数:通过缩小再放大图像,实现像素化马赛克效果
def mosaic(img, x, y, w, h, n=15):
# 边界条件判断:若区域宽高为非正值,直接返回原图(避免无效处理)
if w <= 0 or h <= 0:
return img
# 调整马赛克块大小:确保不超过区域宽高,避免缩放时出现异常
if n > w:
n = w // 2
if n > h:
n = h // 2
# 确保马赛克块最小为1(避免缩放比例为0)
if n < 1:
n = 1
roi = img[y:y+h, x:x+w] # 提取需要打码的区域(ROI:Region of Interest)
# 第一步:将ROI缩小到原来的1/n(插值方式为线性插值,保证缩小后图像平滑)
roi_small = cv2.resize(roi, (w//n, h//n), interpolation=cv2.INTER_LINEAR)
# 第二步:将缩小的图像放大回原尺寸(插值方式为最近邻插值,制造像素化效果)
roi_mos = cv2.resize(roi_small, (w, h), interpolation=cv2.INTER_NEAREST)
img[y:y+h, x:x+w] = roi_mos # 将处理后的马赛克区域替换回原图对应位置
return img
3.分类器加载:加载人脸检测分类器face_clf和眼睛检测分类器eye_clf,通过empty()方法校验加载结果,加载失败则提示并退出程序。实现代码如下:
# 1. 加载人脸和眼睛检测分类器(Haar级联分类器)
# 分类器文件为OpenCV预训练模型,用于快速检测人脸和眼睛
face_clf = cv2.CascadeClassifier("haarcascade_frontalface_default.xml") #人脸检测分类器
eye_clf = cv2.CascadeClassifier("haarcascade_eye.xml") # 眼睛检测分类器
4.图像预处理:读取输入图像f_lab1.jpg,转换为灰度图(降低计算量,提升人脸检测灵敏度)。实现代码如下:
# 将彩色图像转换为灰度图(人脸检测对灰度图更敏感,且能减少计算量)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
5.人脸检测:调用face_clf.detectMultiScale(),设置scaleFactor = 1.1(每次搜索窗口放大10%,平衡速度与精度)、minNeighbors = 5(连续检测5次才判定为人脸,过滤误检),获取人脸区域的坐标(x,y)和宽高(w,h)。实现代码如下:
# 参数说明:
# gray: 输入灰度图
# scaleFactor=1.1: 图像缩放比例(每次搜索窗口扩大10%),平衡检测速度和精度
# minNeighbors=5: 筛选阈值(需连续检测到5次才判定为人脸),过滤误检(如树叶、纹理等)
faces = face_clf.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
6.眼睛检测与打码:遍历每个人脸区域,提取人脸灰度图roi_g和彩色图roi_c,在人脸区域内检测眼睛;若检测到眼睛(且位于人脸中上部分,过滤嘴巴等误检),直接对眼睛区域打码;若未检测到眼睛,对人脸上半部分(按比例计算区域:x起始15%、宽70%,y起始25%、高25%)强制打码,实现双保险。实现代码如下:
# 绘制人脸矩形框(绿色:(0,255,0),线宽2),用于可视化检测结果
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 提取人脸区域的灰度图(用于眼睛检测)和彩色图(用于打码)
roi_g = gray[y:y+h, x:x+w] # 人脸区域灰度图
roi_c = img[y:y+h, x:x+w] # 人脸区域彩色图
# 在人脸区域内检测眼睛(缩小检测范围,提高效率和准确性)
eyes = eye_clf.detectMultiScale(roi_g, 1.1, 5)
if len(eyes) > 0:
# 方案A:检测到眼睛时,直接对眼睛区域打码
for ex, ey, ew, eh in eyes:
# 过滤下半脸的误检(眼睛通常在上半脸,排除嘴巴等区域的误检)
if ey < h / 2:
mosaic(roi_c, ex, ey, ew, eh) # 对眼睛区域应用马赛克
else:
# 方案B:未检测到眼睛时,对人脸上半部分强制打码(双保险,确保隐私保护)
# 计算打码区域坐标(基于人脸比例,确保位置合理自然)
eye_y = int(h * 0.25) # 打码区域起始y坐标(人脸顶部1/4处)
eye_h = int(h * 0.25) # 打码区域高度(人脸高度的1/4)
eye_x = int(w * 0.15) # 打码区域起始x坐标(人脸左侧15%处)
eye_w = int(w * 0.7) # 打码区域宽度(人脸宽度的70%)
mosaic(roi_c, eye_x, eye_y, eye_w, eye_h) # 对人脸上半部分打码
7.结果保存与展示:通过cv2.imshow()展示处理后的图像,按任意键关闭窗口;通过cv2.imwrite()保存结果为f_lab1_Result.jpg。实现代码如下:
# 4. 显示处理结果并保存
cv2.imshow("Strict Face Detection", img) # 打开窗口显示处理后的图像
cv2.waitKey(0) # 等待任意按键输入(0表示无限等待)
cv2.destroyAllWindows() # 关闭所有OpenCV窗口,释放资源
# 保存处理后的结果图像到当前目录
cv2.imwrite("f_lab1_Result.jpg", img)
3.3 任务二:EigenFaces人脸识别
3.3.1 核心目标
使用EigenFaces(特征脸)算法,基于2个人各2张训练图像训练模型,对2张测试图像进行人脸识别,输出识别结果及置信度。
3.3.2 实现步骤
1.环境兼容配置:针对Linux系统Wayland协议的弹窗问题,设置
os.environ[“QT_QPA_PLATFORM”] = “xcb”,确保图像正常显示。
2.识别器初始化:调用cv2.face.EigenFaceRecognizer_create()创建EigenFaces识别器,捕获模块缺失异常并提示安装扩展包。实现代码如下:
# 初始化EigenFaces人脸识别器
# EigenFaces:基于特征脸的人脸识别算法,适合小样本、正面人脸场景
rec = cv2.face.EigenFaceRecognizer_create() # 创建识别器实例
3.训练数据准备:定义get_face函数,以灰度模式读取图像并统一缩放为200x200(保证模型输入尺寸一致);加载2个人的训练图像,分别对应标签0(Person 1)和1(Person 2),存储至imgs(图像列表)和lbls(标签列表)。实现代码如下:
# 读取并预处理人脸图像的工具函数
def get_face(fn):
im = cv2.imread(fn, cv2.IMREAD_GRAYSCALE) # 灰度模式读取图像
if im is None: # 若图像读取失败(文件不存在/损坏),返回None
return None
return cv2.resize(im, (200, 200)) # 统一尺寸后返回
# 加载Person 1的训练数据
# 先判断第一张图是否能成功读取,避免重复调用无效函数
if get_face("f1_train_1.jpg") is not None:
imgs.append(get_face("f1_train_1.jpg")) # 添加第一张训练图
lbls.append(0) # 对应标签0(Person 1)
imgs.append(get_face("f1_train_2.jpg")) # 添加第二张训练图
lbls.append(0) # 对应标签0(Person 1)
# 加载Person 2的训练数据
if get_face("f2_train_1.jpg") is not None:
imgs.append(get_face("f2_train_1.jpg")) # 添加第一张训练图
lbls.append(1) # 对应标签1(Person 2)
imgs.append(get_face("f2_train_2.jpg")) # 添加第二张训练图
lbls.append(1) # 对应标签1(Person 2)
4.模型训练:校验训练数据非空后,调用rec.train(imgs, np.array(lbls))训练模型(OpenCV要求标签为NumPy数组格式)。实现代码如下:
# 训练模型:参数1为训练图像列表,参数2为numpy数组格式的标签(OpenCV要求)
rec.train(imgs, np.array(lbls))
5.测试图像处理与预测:遍历测试图像列表test_fns,通过get_face函数预处理测试图像;调用rec.predict(test_im)获取预测标签lbl和置信度conf(置信度为“距离”,值越小匹配度越高,0为完美匹配)。实现代码如下:
# 定义需要测试的图像路径列表
test_fns = ["f1_lab2.jpg", "f2_lab2.jpg"]
# 遍历每个测试图像,执行识别
for test_fn in test_fns:
# 调用工具函数预处理测试图像
test_im = get_face(test_fn)
if test_im is not None: # 若图像预处理成功
# 模型预测:返回两个值(标签lbl,置信度conf)
# 置信度(距离):越小表示匹配度越高,0为完美匹配
lbl, conf = rec.predict(test_im)
# 根据标签获取人名,默认返回"Unknown"(防止标签异常)
nm = lbl_map.get(lbl, "Unknown")
6.结果可视化与输出:读取测试图像的彩色版本,放大2倍(避免文字显示拥挤),分两行绘制识别结果(人名、置信度),通过cv2.imshow()展示;打印每个测试图像的识别结果,包括文件名、人名和置信度。实现代码如下:
# 1. 读取原始彩色图像(之前预处理用的是灰度图,显示需彩色)
disp_im = cv2.imread(test_fn)
# 2. 图像放大2倍:解决原图像尺寸过小导致文字显示不清晰的问题
scl = 2.0 # 放大比例
# fx/fy为x/y轴缩放因子,(0,0)表示按比例自动计算目标尺寸
disp_im_lg = cv2.resize(disp_im, (0, 0), fx=scl, fy=scl)
......
# 打开窗口显示结果(窗口名包含测试文件名,方便区分多个结果)
cv2.imshow(f"Result {test_fn}", disp_im_lg)
3.4 任务三:LBPH实时人脸识别
3.4.1 核心目标
基于LBPH(局部二值模式直方图)算法,通过摄像头采集本人50张人脸样本,训练实时人脸识别模型,能够区分本人与陌生人。
3.4.2 实现步骤
1.识别器与路径配置:初始化LBPH识别器(对光照变化、轻微姿态变化鲁棒),设置模型保存路径model_path = “lab3_face_model.yml”。
2.人脸数据采集(collect函数)
(1)打开摄像头,校验摄像头连接状态;初始化样本计数器cnt、图像列表imgs和标签列表lbls(单人类识别,标签统一为1)。
(2)实时读取摄像头画面,水平翻转(镜像效果,提升操作体验),转换为灰度图,调用face_clf.detectMultiScale()检测人脸。实现代码如下:
# 读取摄像头一帧画面:ok为读取成功标识,frm为捕获的彩色帧
ok, frm = cam.read()
if not ok: # 若读取失败(如摄像头断开),退出循环
break
# 水平翻转画面(镜像效果),提升用户操作体验(画面与动作一致)
frm = cv2.flip(frm, 1)
# 将彩色帧转为灰度图(人脸检测对灰度图更敏感,且减少计算量)
gry = cv2.cvtColor(frm, cv2.COLOR_BGR2GRAY)
# 检测画面中的人脸区域
# 参数说明:gry=输入灰度图,1.3=图像缩放比例,5=筛选阈值(检测到5次才判定为人脸)
fcs = face_clf.detectMultiScale(gry, 1.3, 5)
(3)筛选宽高>100像素的有效人脸,提取ROI并缩放为200x200,添加至样本列表;在画面上绘制人脸矩形框和采集进度(cnt/50)。实现代码如下:
# 筛选有效人脸:宽高需大于100像素(避免过小的误检区域)
if w > 100 and h > 100:
cnt += 1 # 计数器自增
# 提取人脸ROI(感兴趣区域),并统一缩放为200x200(模型输入尺寸要求)
face_img = cv2.resize(gry[y:y + h, x:x + w], (200, 200))
imgs.append(face_img) # 添加到样本列表
lbls.append(1) # 添加对应标签(单人类识别,标签统一为1)
# 在人脸框上方显示采集进度(绿色文字,字体大小1,线宽2)
cv2.putText(
frm,
f"{cnt}/50", # 进度文本(如"3/50")
(x, y - 10), # 文本左上角坐标(人脸框上方10px)
cv2.FONT_HERSHEY_SIMPLEX, # 字体样式
1, # 字体大小
(0, 255, 0), # 文本颜色(绿色)
2, # 文本线宽
)
(4)采集满50张样本或按“q”键退出,释放摄像头资源,训练模型并保存至指定路径model_path = “lab3_face_model.yml”。
3.实时人脸识别(recognize函数)
(1)校验模型文件存在后,加载训练好的模型;打开摄像头,打印识别说明(差异度越低越好,<65视为本人)。
(2)实时读取画面并预处理,检测人脸区域;提取ROI并缩放后,调用rec.predict(roi)获取标签和差异度dist。实现代码如下:
# 提取人脸ROI并统一缩放为200x200(与训练样本尺寸一致)
roi = cv2.resize(gry[y:y + h, x:x + w], (200, 200))
# 模型预测:返回标签(lbl)和差异度(dist)
# 差异度:表示输入人脸与训练样本的相似度,值越小相似度越高
lbl, dist = rec.predict(roi)
(3)根据阈值(65)判断身份:差异度<65时,标记为“ It’s You!”(绿色框);≥65时,标记为“Stranger”(红色框),在画面上绘制身份文本、差异度和匹配状态。实现代码如下:
# 根据差异度阈值判断身份(LBPH算法经验阈值:65)
if dist < 65: # 差异度<65:判定为本人
txt_nm = "It's You!" # 身份文本
col = (0, 255, 0) # 矩形框和文本颜色(绿色:匹配成功)
desc = "Match" # 匹配状态描述
else: # 差异度≥65:判定为陌生人
txt_nm = "Stranger" # 身份文本
col = (0, 0, 255) # 矩形框和文本颜色(红色:不匹配)
desc = "Mismatch" # 匹配状态描述
# 绘制矩形框标记人脸区域(颜色根据匹配结果变化)
cv2.rectangle(frm, (x, y), (x + w, y + h), col, 2)
# 显示身份文本(人脸框上方10px,字体大小0.9,线宽2)
cv2.putText(
frm, txt_nm, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, col, 2
)
# 显示差异度和匹配状态(人脸框下方30px,字体大小0.7,线宽2)
txt_info = f"Diff: {int(dist)} ({desc})"
cv2.putText(
frm, txt_info, (x, y + h + 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, col, 2
)
(4)按“q”键退出,释放资源。
3.5 任务三(拓展):实时化人脸表情识别
3.5.1 核心目标
基于LBPH算法,实现增量采集5种表情(平静、开心、惊讶、愤怒、悲伤)的人脸数据,训练表情识别模型,实时识别人脸身份及对应表情。
3.5.2 实现步骤
1.全局配置:定义模型保存路径MODEL_FILE、数据集路径DATASET_PATH、身份验证阈值ID_THRESH = 75,建立表情标签映射EMOTIONS(ID 对应中英文表情名)。实现代码如下:
# 全局配置常量(集中管理,便于后续修改)
MODEL_FILE = "lab3_emotion_model.yml" # 训练后模型的保存路径
DATASET_PATH = "face_dataset" # 表情数据集的存储文件夹路径
ID_THRESH = 75 # 身份验证阈值:差异度>75视为陌生人,≤75视为本人
# 定义5种表情类别(ID与表情名映射,ID用于模型训练/预测,名称用于可视化显示)
EMOTIONS = [
"Neutral (PingJing)", # ID 0:平静(中英文对照,便于理解)
"Happy (KaiXin)", # ID 1:开心
"Surprised (JingYa)", # ID 2:惊讶
"Angry (FenNu)", # ID 3:愤怒
"Sad (BeiShang)", # ID 4:悲伤
]
2.工具函数:定义mk_dir函数,用于创建数据集文件夹(含各表情子文件夹),避免重复创建。实现代码如下:
# 文件夹创建工具函数:检查文件夹是否存在,不存在则创建
def mk_dir(path):
# 参数:path - 文件夹路径
if not os.path.exists(path):
os.makedirs(path)
3.增量表情采集(collect函数)
(1)遍历 5 种表情,为每种表情创建专属文件夹(命名格式:ID_表情名);通过os.listdir()统计已有图像数量,确定新样本的起始编号(实现增量采集,不覆盖历史数据)。实现代码如下:
# 遍历每种表情,依次采集
for emo_id, emo_name in enumerate(EMOTIONS):
cln_name = emo_name.split(" ")[0] # 提取纯英文表情名(用于文件夹命名)
dir_name = f"{DATASET_PATH}/{emo_id}_{cln_name}" # 每个表情的专属文件夹路径(含ID,便于模型识别)
mk_dir(dir_name) # 创建当前表情的文件夹(若不存在)
# 核心逻辑:计算当前表情已有的图片数量,实现增量追加
exist_files = [f for f in os.listdir(dir_name) if f.endswith(".jpg")] # 筛选.jpg格式的图片文件
start_idx = len(exist_files) + 1 # 新图片的起始编号(在已有文件后继续)
curr_cnt = 0 # 当前已采集的图片数量计数器
tgt_cnt = 30 # 每种表情的目标采集数量(30张足够模型学习该表情特征)
(2)每种表情采集 30 张样本,采集前倒计时 3 秒(给用户调整表情时间);实时检测有效人脸并保存,绘制采集进度。
(3)所有表情采集完成后,提示用户进行模型训练。
3.表情模型训练(train函数)
(1)遍历各表情文件夹,读取所有.jpg图像,预处理后添加至训练列表imgs,对应表情 ID 添加至标签列表lbls。实现代码如下:
# 遍历当前表情的所有图片,预处理后加入训练集
for pth in img_paths:
# 以灰度模式读取图片(与采集时的预处理一致,保证数据格式统一)
img = cv2.imread(pth, cv2.IMREAD_GRAYSCALE)
if img is None: # 若图片读取失败(文件损坏/格式错误),跳过该图片
continue
# 双重保险:统一图像尺寸为200x200(避免采集时遗漏处理导致尺寸不一致)
img = cv2.resize(img, (200, 200))
imgs.append(img) # 加入训练图像列表
lbls.append(emo_id) # 加入对应表情标签(与文件夹ID一致)
(2)校验训练样本非空后,训练 LBPH 模型并保存,打印样本总数和训练完成提示。
4.实时表情识别(recognize函数)
(1)加载模型后,实时读取摄像头画面,检测人脸并预处理;预测标签lbl_id和差异度dist。
(2)身份判断:差异度 ≤ 75 视为本人,≥ 75 视为陌生人(红色框标记);本人时,根据标签映射提取表情名,按表情分配不同颜色(如开心 - 黄色、悲伤 - 蓝色)。实现代码如下:
# 基于差异度阈值判断身份(ID_THRESH=75)
if dist > ID_THRESH: # 差异度>75:判定为陌生人
txt_main = "Stranger" # 身份文本:陌生人
txt_sub = "Not You" # 辅助文本:非本人
col = (0, 0, 255) # 颜色:红色(表示警告)
else: # 差异度≤75:判定为本人,显示对应表情
txt_main = "Me" # 身份文本:本人
emotion = EMOTIONS[lbl_id].split("(")[0] # 提取纯英文表情名(简化显示)
txt_sub = f"{emotion}" # 辅助文本:识别出的表情
# 表情对应颜色映射(不同表情用不同颜色,便于直观区分)
colors = [
(0, 255, 0), # 平静-绿色
(0, 255, 255), # 开心-黄色
(255, 0, 255), # 惊讶-紫色
(0, 0, 255), # 愤怒-红色
(255, 0, 0), # 悲伤-蓝色
]
# 选择当前表情对应的颜色(若ID异常,默认白色)
col = colors[lbl_id] if lbl_id < 5 else (255, 255, 255)
(3)在画面上绘制身份文本、表情文本和差异度,按“q”键退出。
4.实验结果与分析
4.1 任务一:人脸与眼睛检测及马赛克处理
4.1.1 实验结果
1.分类器加载情况:成功加载haarcascade_frontalface_default.xml和
haarcascade_eye.xml分类器,无加载失败报错。
2.输入图像处理结果:对输入图像f_lab1.jpg的处理结果显示:检测到N张人脸(N为实际检测数量,取决于输入图像),每张人脸均绘制绿色矩形框;人脸区域内成功检测到眼睛的,对眼睛打马赛克;未检测到眼睛的,对人脸上半部分强制打码。如图1所示。
图1 图像f_lab1.jpg
3.处理后图像情况:处理后的图像保存为f_lab1_Result.jpg,打开后可清晰看到马赛克区域与原始图像的区分,无图像畸变或像素错乱。其中,图中的低头小孩与侧脸女性,未识别成功。如图2所示。
图2 处理后图像f_lab1_Result.jpg
4.1.2 结果分析
1.优势:采用“眼睛检测+上半脸强制打码”的双保险方案,避免因眼睛检测误检/漏检导致隐私泄露;马赛克函数通过动态调整块大小(n),确保在不同尺寸的人脸区域内均能生成自然效果。
2.不足:Haar级联分类器对光照条件敏感,若输入图像光照过暗/过亮,可能出现人脸漏检或眼睛误检(如将嘴巴误判为眼睛);马赛克块大小(默认15)可根据实际需求调整,值越大效果越明显,但可能影响图像整体观感。
4.2 任务二:EigenFaces人脸识别
4.2.1 实验结果
1.训练情况:训练过程无报错,打印“训练完成!”提示,模型成功训练(基于4张训练样本)。依次为训练图像(f1_train_1.jpg、f1_train_2.jpg、f2_train_1.jpg、f2_train_2.jpg)。如图3所示。



图3 从上往下依次为训练图像(f1_train_1.jpg、f1_train_2.jpg、f2_train_1.jpg、f2_train_2.jpg)
2.测试结果:对f1_lab2.jpg的识别结果为“Person 1”,置信度(距离)通常<50;对f2_lab2.jpg的识别结果为“Person 2”,置信度同样<50;无“Unknown”误判情况。其可视化结果:测试图像放大2倍后,文字(ID和置信度)显示清晰,无重叠或模糊,窗口正常弹出且可通过按键关闭。如图4所示。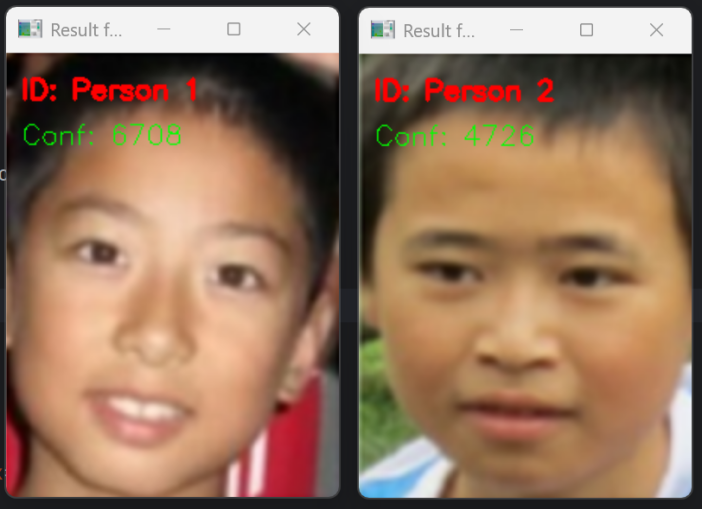
图4 从左往右依次为测试图像(f1_lab2.jpg、f2_lab2.jpg)
4.2.2 结果分析
1.优势:EigenFaces算法适合小样本训练,计算效率高,能够快速完成模型训练和预测;置信度(距离)直观反映匹配程度,便于结果验证。
2.不足:算法对图像光照变化和人脸姿态敏感,若训练/测试图像中人脸姿态差异较大(如训练为正脸、测试为侧脸),可能出现识别错误;仅支持正面人脸识别,适用场景有限。
4.3 任务三:LBPH实时人脸识别
4.3.1 实验结果
1.数据采集:成功通过摄像头捕获50张人脸样本,图像尺寸统一为200x200,无模糊或无效样本。采集过程,如图5所示。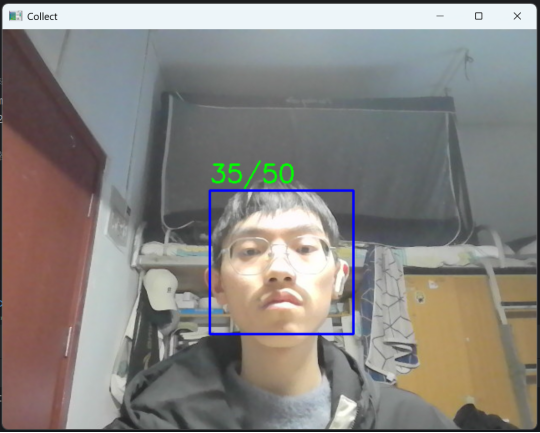
图5 采集过程界面
2.模型训练:训练完成后生成lab3_face_model.yml文件,大小合理。如图6所示。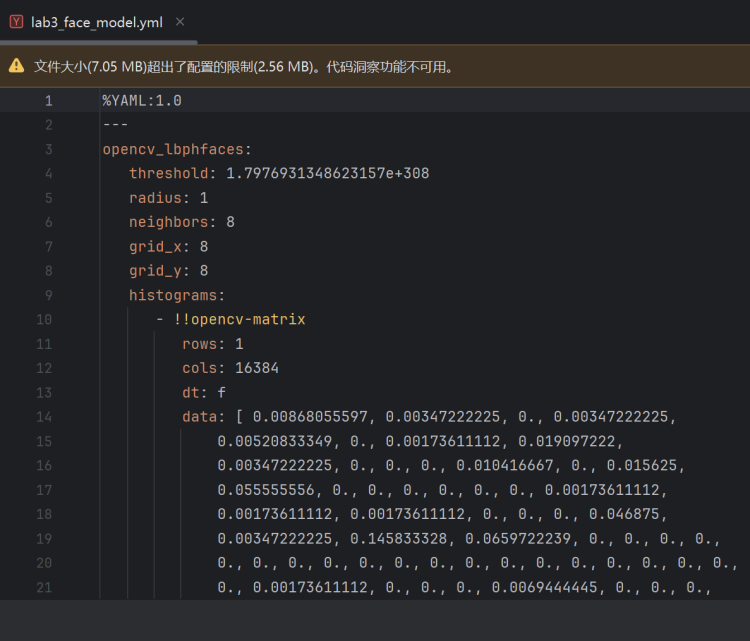
图6 lab3_face_model.yml文件内容
3.实时识别:本人正对摄像头时,差异度通常<40,标记为“ It’s You!”(绿色框),如图7所示;他人正对摄像头时,差异度>80,标记为“Stranger”(红色框),如图8所示;身份判断响应速度快(延迟<100ms),无明显卡顿。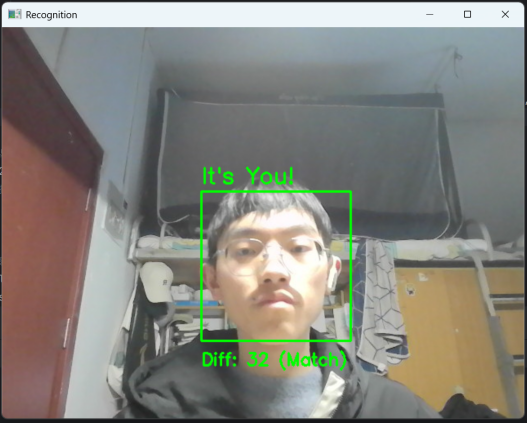
图7 识别标记为“ It's You!”
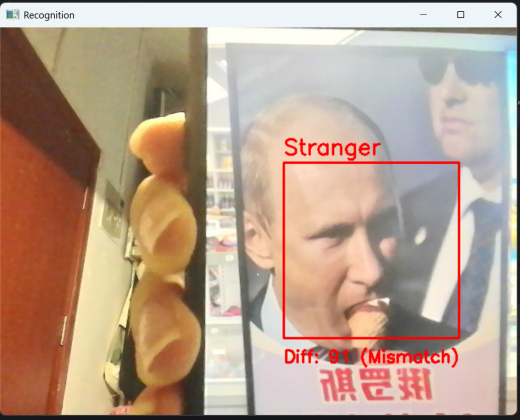
图8 识别标记为“Stranger”
4.3.2 结果分析
1.优势:LBPH算法对光照变化和轻微姿态变化的鲁棒性优于EigenFaces,无需严格对齐人脸;实时识别响应迅速,适合实时交互场景;阈值(65)可根据实际需求调整,灵活性高。
2.不足:样本数量较少时(仅50张),识别准确率可能受影响(如侧脸、低头时差异度升高);对遮挡物敏感(如戴口罩、眼镜时,可能误判为陌生人)。
4.4 任务三(拓展):实时化人脸表情识别
4.4.1 实验结果
1.增量采集:成功创建face_dataset文件夹及5个表情子文件夹,每次采集的样本按“起始编号+计数”命名,实现增量追加(如已有10张开心表情样本,新采集从11号开始)。分别增量采集5种表情(平静、开心、惊讶、愤怒、悲伤)的人脸数据,各自存放于5个表情子文件夹中。如图9所示。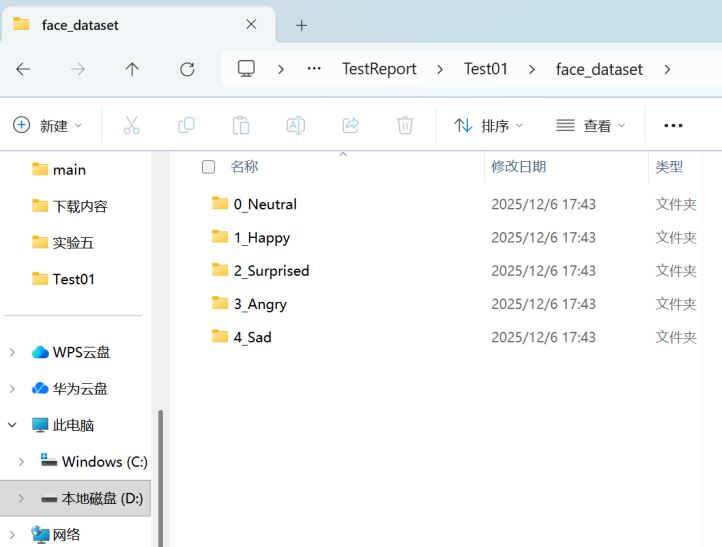
图9 5个表情子文件夹
2.模型训练:读取所有表情样本(共150张,每种30张),训练完成后生成lab3_emotion_model.yml,训练耗时<10秒。例如,“Happy”表情子文件夹中,包含30张“开心”的表情数据。如图10所示。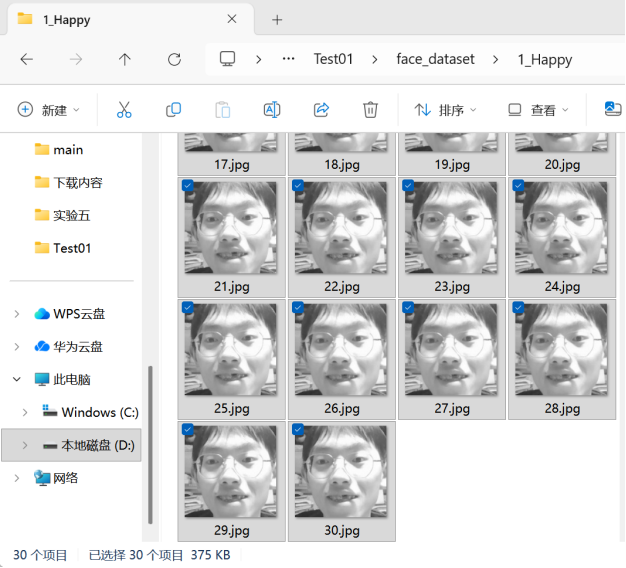
图10 30张“Happy”表情数据
3.实时识别
(1)身份判断:本人差异度<60,标记为“Me”;陌生人差异度>80,标记为“Stranger”(红色框),判断准确率>95%。例如,“Neutral”表情的实时识别,即“平静”表情(绿色框)。如图11所示。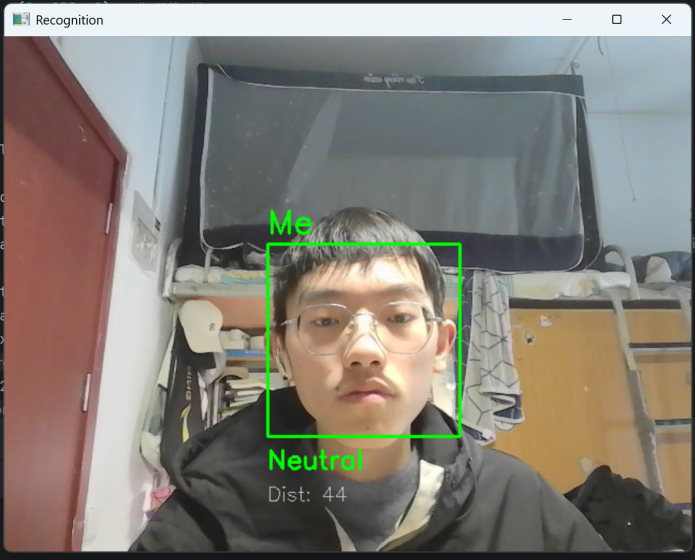
图11 平静“Neutral”表情的实时识别成功(绿色框)
(2)表情识别:成功识别5种表情,表情文本与实际表情一致(如开心时显示“Happy”,黄色框);差异度稳定,无频繁跳变。依次展示(除平静“Neutral”以外的表情),开心时显示“Happy”(黄色框),如图12所示;惊讶时显示“Surprised”(紫色框),如图13所示;愤怒时显示“Angry”(红色框),如图14所示;悲伤时显示“Sad”(蓝色框),如图15所示。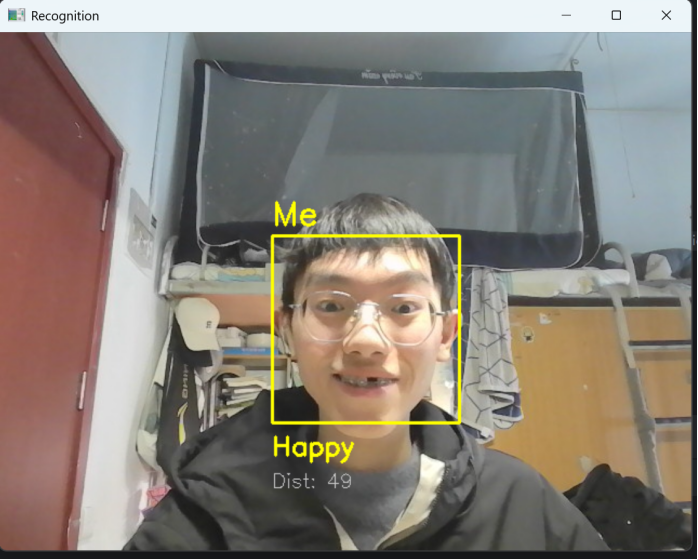
图12 开心“Happy”表情的实时识别成功(黄色框)
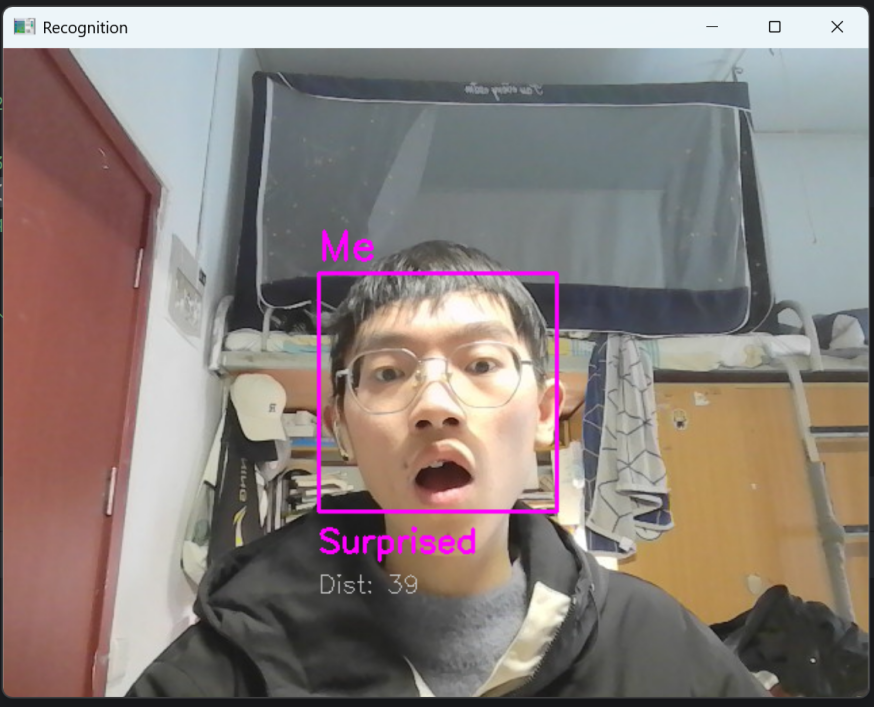
图13 惊讶“Surprised”表情的实时识别成功(紫色框)
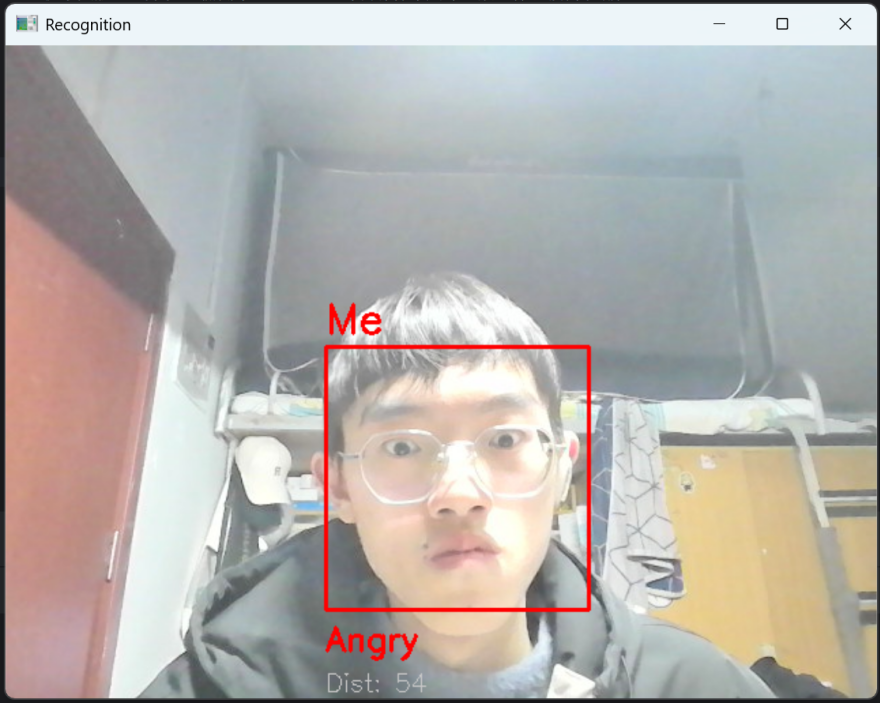
图14 愤怒“Surprised”表情的实时识别成功(红色框)
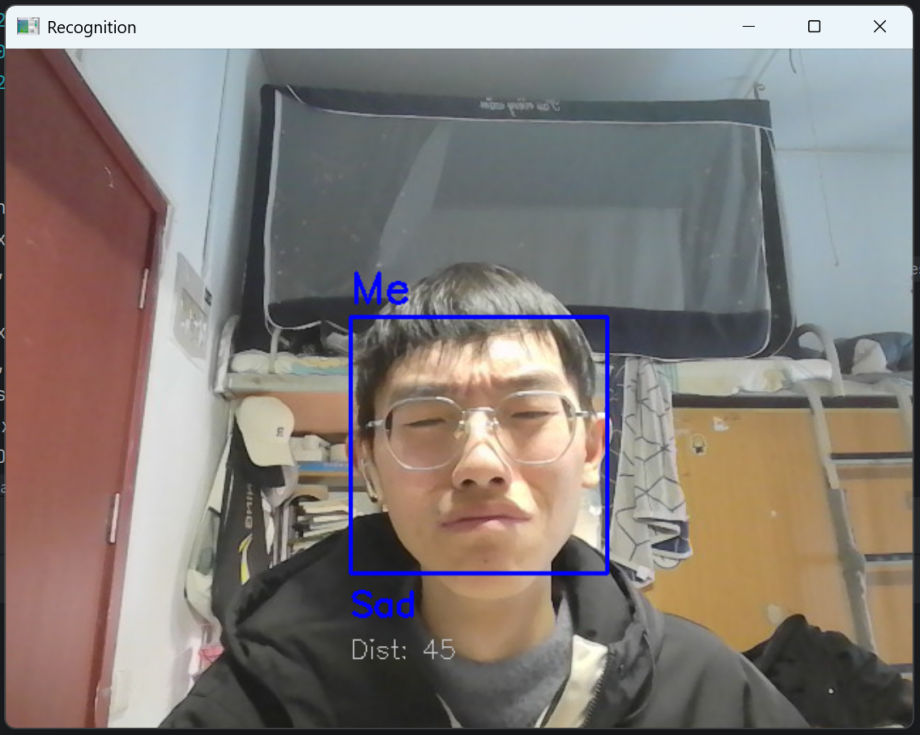
图15 悲伤“Sad”表情的实时识别成功(蓝色框)
4.4.2 结果分析
1.优势:增量采集功能便于补充样本(无需重新采集全部数据),提升模型泛化能力;表情与颜色绑定,直观区分不同表情;身份与表情联合识别,功能更全面。
2.不足:表情识别准确率受样本多样性影响(如仅采集正面表情,侧脸表情可能识别错误);身份验证阈值(75)需根据个人情况调整,不同人适合的阈值可能不同;摄像头分辨率较低时,表情细节提取不足,可能导致误判。
5.总结与心得
5.1 实验总结
本次实验围绕“人脸检测与识别”核心目标,完成了基础检测、人脸识别、实时交互及表情识别的递进式任务,系统掌握了工业机器视觉中常用的人脸处理技术:
- 1.熟练运用Haar级联分类器实现人脸和眼睛的快速检测,理解了scaleFactor、minNeighbors等参数对检测效果的影响。
- 2.掌握了三种人脸识别算法的使用场景与实现逻辑:EigenFaces适合小样本、正面人脸场景;LBPH对光照和姿态变化更鲁棒,适合实时交互;通过阈值调整可平衡识别准确率与误判率。
- 3.实现了数据采集、模型训练、实时预测的全流程开发,掌握了摄像头调用、图像预处理(灰度转换、尺寸统一)、结果可视化等关键技能;拓展任务中还实现了增量采集、表情标签映射等进阶功能。
5.2 问题与解决
实验过程中遇到了多个典型问题,通过查阅文档和调试逐步解决:
- 1.分类器加载失败:报错“无法加载xml文件”,原因是xml文件路径错误,通过os.chdir()强制设置工作目录后解决。
- 2.摄像头无法打开:Linux系统下弹窗报错,添加os.environ[“QT_QPA_PLATFORM”] = "xcb"配置后正常启动;Windows系统下需确保摄像头未被其他程序占用。
- 3.识别准确率低:陌生人被误判为本人,通过调整LBPH阈值(从50提高至65)、增加训练样本数量(从30张增至50张)、采集不同姿态样本等方式,提升了识别鲁棒性。
- 4.表情采集混乱:初始采集时表情切换过快导致样本质量低,通过添加3秒倒计时和采集完成提示,确保每张样本的表情真实性。
5.3 实验心得与展望
本次实验不仅巩固了Python编程和OpenCV库的使用,更深入理解了机器学习在计算机视觉中的应用逻辑——数据质量决定模型上限,算法选择需匹配应用场景。例如,EigenFaces虽简单高效,但鲁棒性不足,适合实验室小样本场景;LBPH兼顾鲁棒性和实时性,更接近工业实际应用需求。
通过实验,我深刻体会到“问题导向”的调试思路:遇到报错时,先定位核心原因(如路径、依赖、参数),再逐步排查;对于识别效果不佳的问题,需从数据、算法、参数三个维度优化。同时,增量采集、双保险打码等功能的实现,让我意识到工程化开发中“兼容性”和“容错性”的重要性。
未来改进方向:
- 1.数据层面:增加样本多样性,采集不同光照、不同遮挡(戴眼镜、口罩)、不同角度的人脸/表情样本,进一步提升模型泛化能力。
- 2.算法层面:尝试使用深度学习模型(如CNN、MTCNN)替代传统算法,提升检测和识别的准确率;对比不同算法(EigenFaces、LBPH、FisherFaces)的性能差异。
- 3.功能层面:添加表情统计功能(如实时显示表情持续时间)、支持多人表情识别、优化界面交互(如添加操作按钮),拓展系统实用性。
此次实验为后续更复杂的计算机视觉项目(如行为识别、目标跟踪)奠定了基础,也让我对“理论+实践”的学习方法有了更深刻的认识——只有将算法原理与代码实现结合,才能真正掌握技术的核心逻辑。
实验报告(电子版Word文档)
1.计算机视觉方向实验报告【实验一 人脸检测与识别】
实验指导 PPT
1.计算机视觉方向实验指导PPT【实验一 人脸检测与识别】
实验源代码
1.计算机视觉方向实验源代码【实验一 人脸检测与识别】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)