大模型应用:大模型响应缓存技术完全指南:TTL 缓存装饰器的设计与落地.112
一、前言
现在我们做AI应用、大模型接口开发,基本都会碰到两个特别头疼的问题:一个是响应太慢,用户点一下要等好几秒,体验特别差;另一个就是调用成本太高,同样的问题反复问,每次都要重新调用大模型,Token哗啦哗啦的像流水一样就这么消耗了。尤其在客服问答、智能助手、内容生成、知识库查询这些真实业务里,大量用户的问题其实是重复、相似的,完全没必要每次都让大模型从头计算。
缓存这个早就被验证过的经典思路,放到大模型场景里,就特别对症,把已经生成过的回答存起来,下次同样或类似的请求过来,直接从缓存里取,不用再麻烦大模型。既能秒级响应,又能大幅省成本,还能减轻大模型服务压力,提升系统稳定性。在实际应用落地过程中,缓存就是最直接、最有效、性价比最高的优化手段。我们前期通过《大模型数据缓存复用方案:从API请求数据累积到智能融合.50》讲解过基于向量化结合本地数据库的实现方案,今天我们换个思路,基于缓存装饰器的角度来实现。

二、缓存技术基础
1. 缓存的本质与价值
缓存(Cache)本质上是一种数据暂存机制,将高频访问的数据存储在读写速度更快的介质中,从而减少对低速数据源的重复访问。想象一下:我们每天上班都会路过便利店买早餐,如果每次都要重新确认早餐价格、口味,会浪费大量时间;但如果你把常用的早餐信息记在脑子里,相当于缓存,就能快速决策。这就是缓存的核心价值:用空间换时间。
在大模型应用场景中,缓存的价值体现在三个维度:
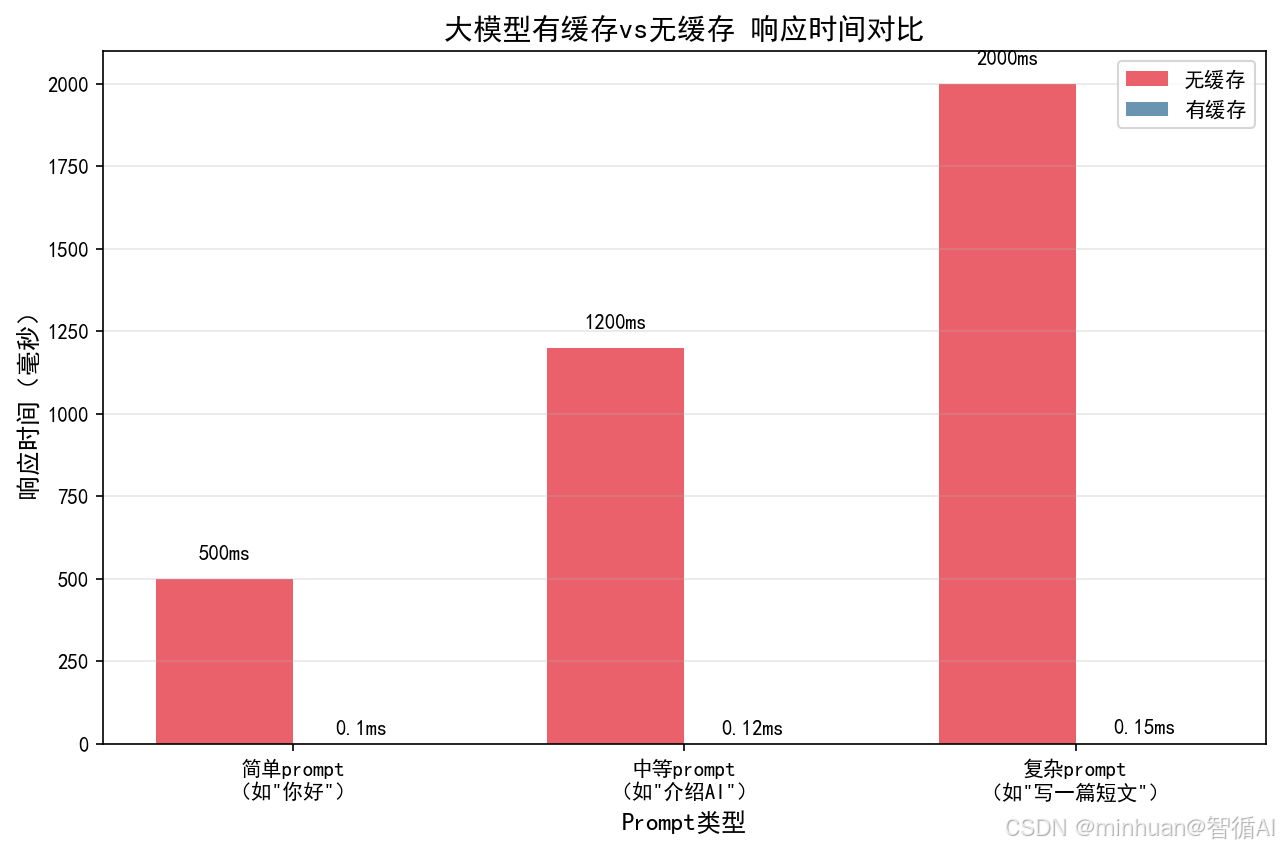
- 响应速度:大模型生成文本通常需要数百毫秒甚至数秒,缓存命中可将响应时间降至微秒级
- 成本控制:大模型 API 调用按 token 计费,重复请求相同 prompt 会产生不必要的费用
- 系统稳定性:减少对大模型服务的请求量,降低接口限流、服务熔断的风险
2. 大模型缓存的特殊要求
与普通缓存不同,大模型缓存需要满足以下特性:
- TTL(生存时间):大模型的回答存在时效性问题,可能随时间失效,需设置过期时间
- 键值设计:prompt 通常包含大量文本,需生成唯一且高效的缓存键
- 线程安全:生产环境中多线程调用需保证缓存操作的原子性
- 缓存失效策略:需处理缓存击穿、缓存雪崩等常见问题
3. 缓存在大模型系统中的位置
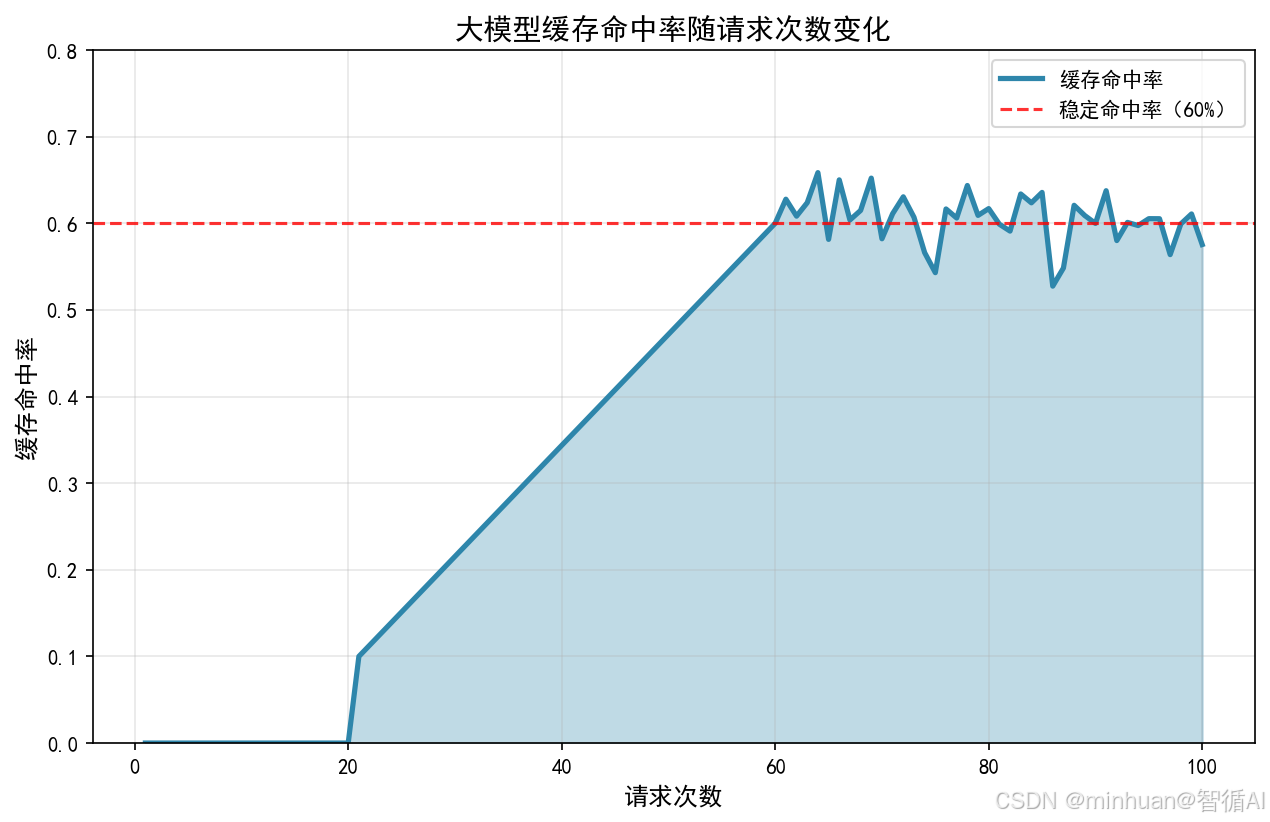
以下流程图反映了缓存在大模型系统中的核心位置,用户请求首先经过缓存层,命中则直接返回,未命中才调用大模型并更新缓存;

大模型缓存命中率随请求次数变化:
三、缓存装饰器基础
1. 装饰器基础原理
装饰器是 Python 的核心特性之一,用于在不修改函数源代码的前提下增强函数功能。其核心原理基于:
1.1 函数是一等对象
- 在Python中,函数被视为“一等公民”。这意味着函数可以像整数或字符串一样被赋值给变量、作为参数传递给其他函数,甚至作为返回值从函数中返回。
- 这种特性是构建高阶函数(如map、filter)和实现回调机制的基础,极大提升了代码的灵活性与复用性。
1.2 闭包
- 闭包是指嵌套函数中,内部函数引用了外部函数的局部变量,即使外部函数已执行完毕,这些变量仍被内部函数“封闭”保存。
- 闭包让函数拥有了“记忆”状态的能力,常用于实现装饰器、工厂函数或数据封装,无需使用类即可创建带有私有状态的 callable 对象。
1.3 functools.wraps
- functools.wraps 是一个装饰器,用于在编写自定义装饰器时,将被包装函数的元数据(如 __name__、__doc__、__module__ 等)复制到包装函数上。
- 若不使用它,调试或被装饰函数在查看帮助文档时会显示包装器的信息,导致混淆。它是编写规范、透明装饰器的必备工具。
基础装饰器结构:
import functools
def my_decorator(func):
@functools.wraps(func) # 保留原函数信息
def wrapper(*args, **kwargs):
# 执行前增强逻辑
result = func(*args, **kwargs)
# 执行后增强逻辑
return result
return wrapper
# 使用装饰器
@my_decorator
def say_hello(name):
return f"Hello, {name}!"2. 基础缓存装饰器实现
我们先实现一个最简单的无过期时间的缓存装饰器,理解核心逻辑:
import functools
def simple_cache(func):
"""基础缓存装饰器(无过期时间)"""
# 缓存存储:键=参数组合,值=函数返回结果
cache_storage = {}
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 1. 生成缓存键:将参数转换为字符串作为唯一标识
cache_key = (args, frozenset(kwargs.items())) # 使用不可变类型作为键
# 2. 检查缓存是否存在
if cache_key in cache_storage:
print(f"✅ 缓存命中:{cache_key}")
return cache_storage[cache_key]
# 3. 缓存未命中,执行原函数
print(f"❌ 缓存未命中,执行函数:{cache_key}")
result = func(*args, **kwargs)
# 4. 将结果存入缓存
cache_storage[cache_key] = result
return result
return wrapper
# 测试基础缓存
@simple_cache
def calculate_sum(a, b):
"""简单的求和函数,模拟耗时操作"""
# 模拟计算耗时
import time
time.sleep(1)
return a + b
# 第一次调用(缓存未命中)
print(calculate_sum(1, 2))
# 第二次调用(缓存命中)
print(calculate_sum(1, 2))
# 不同参数调用(缓存未命中)
print(calculate_sum(2, 3)) 代码关键说明:
- cache_storage:字典结构,用于存储缓存数据,生命周期与装饰器绑定
- cache_key:使用(args, frozenset(kwargs.items()))生成键,避免 kwargs 顺序影响,如func(a=1,b=2)和func(b=2,a=1)应视为同一键
- functools.wraps:确保被装饰函数的__name__、__doc__等元信息不丢失
输出结果:
❌ 缓存未命中,执行函数:((1, 2), frozenset())
3
✅ 缓存命中:((1, 2), frozenset())
3
❌ 缓存未命中,执行函数:((2, 3), frozenset())
5
装饰器缓存机制的工作过程:
================== 三次调用的执行情况:==================
第一次调用 calculate_sum(1, 2)
- 缓存中没有这个参数组合,所以显示 ❌ 缓存未命中
- 执行函数计算(等待1秒),得到结果 3
- 将结果存入缓存
第二次调用 calculate_sum(1, 2)
- 缓存中已有 (1, 2) 的结果,显示 ✅ 缓存命中
- 直接从缓存返回 3,无需重新计算(立即返回)
第三次调用 calculate_sum(2, 3)
- 参数不同,缓存中没有这个组合
- 显示 ❌ 缓存未命中,执行计算得到 5
- 将新结果存入缓存
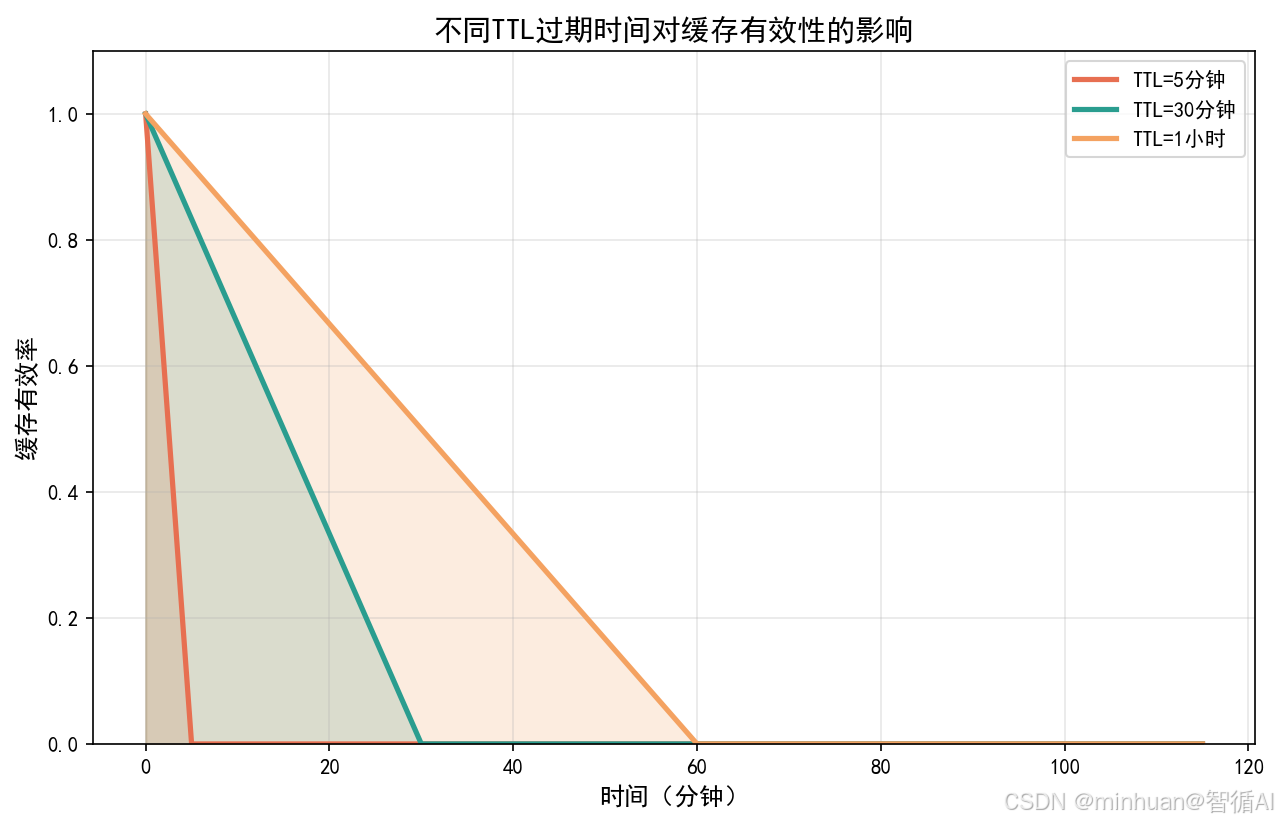
3. 增加 TTL 过期机制
基础缓存没有过期时间,无法满足大模型场景的时效性要求。我们在基础版本上增加 TTL(Time-To-Live)特性:
import functools
import time
def ttl_cache(ttl=3600):
"""带过期时间的缓存装饰器
Args:
ttl: 缓存生存时间(秒),默认1小时
"""
cache_storage = {}
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 1. 生成稳定的缓存键
args_key = tuple(args)
kwargs_key = frozenset(kwargs.items())
cache_key = (args_key, kwargs_key)
# 2. 检查缓存是否有效
current_time = time.time()
if cache_key in cache_storage:
cached_time, cached_result = cache_storage[cache_key]
# 判断是否过期
if current_time - cached_time < ttl:
print(f"✅ 缓存命中(剩余有效期:{ttl - (current_time - cached_time):.1f}秒)")
return cached_result
else:
print(f"⏰ 缓存过期,清除旧数据")
del cache_storage[cache_key]
# 3. 执行原函数
print(f"❌ 缓存未命中,执行函数")
result = func(*args, **kwargs)
# 4. 存储缓存(记录时间戳+结果)
cache_storage[cache_key] = (current_time, result)
return result
return wrapper
return decorator
# 测试TTL缓存
@ttl_cache(ttl=5) # 缓存有效期5秒
def generate_greeting(name):
"""模拟生成个性化问候语的大模型函数"""
time.sleep(1) # 模拟大模型处理耗时
from datetime import datetime
now = datetime.now()
return f"你好 {name}! 今天是 {now.strftime('%Y-%m-%d %H:%M:%S')}"
# 第一次调用(未命中)
print(generate_greeting("小王"))
# 立即第二次调用(命中)
print(generate_greeting("小王"))
# 等待6秒后调用(过期)
time.sleep(6)
print(generate_greeting("小王"))代码关键说明:
- ttl参数:通过外层函数传递,实现缓存过期时间的自定义
- 缓存值结构:从单纯存储结果改为存储(时间戳, 结果)元组
- 过期判断:current_time - cached_time < ttl 检查缓存是否在有效期内
- 过期清理:主动删除过期缓存,释放内存空间
输出结果:
你好 小王! 今天是 2026-03-09 21:51:45
✅ 缓存命中(剩余有效期:4.0秒)
你好 小王! 今天是 2026-03-09 21:51:45
⏰ 缓存过期,清除旧数据
❌ 缓存未命中,执行函数
你好 小王! 今天是 2026-03-09 21:51:52
四、大模型专用缓存装饰器实现
在基础缓存装饰器我们实现了基础的 TTL 缓存功能,并使用functools.wraps保留函数元信息,支持参数化 TTL 配置,但还是存在一些问题:
- 1. 缓存键生成方式不健壮:str(args) + str(kwargs) 可能产生重复键,如args=(1,2)和args=(12,)
- 2. 无线程安全保护:多线程环境下可能出现竞态条件
- 3. 无缓存容量限制:可能导致内存泄漏
- 4. 无异常处理:原函数报错时也会缓存错误结果
- 5. 缓存键未做哈希优化:长 prompt 会导致键过长
基与以上的分析优化,我们实现一个更健壮的大模型专用缓存装饰器:
import functools
import time
import hashlib
import threading
from typing import Any, Callable, Optional
class LLMResponseCache:
"""大模型响应缓存类(生产级实现)"""
def __init__(self, default_ttl: int = 3600, max_size: int = 1000):
"""
初始化缓存
Args:
default_ttl: 默认缓存有效期(秒)
max_size: 缓存最大容量,防止内存溢出
"""
# 核心缓存存储
self._cache = {}
# 缓存访问时间(用于LRU淘汰)
self._access_times = {}
# 默认TTL
self._default_ttl = default_ttl
# 缓存最大容量
self._max_size = max_size
# 线程锁(保证线程安全)
self._lock = threading.Lock()
def _generate_key(self, args: tuple, kwargs: dict) -> str:
"""生成稳定且高效的缓存键
步骤:
1. 将参数转换为有序的字符串
2. 使用MD5哈希生成固定长度的键
"""
# 处理位置参数
args_str = "|".join(str(arg) for arg in args)
# 处理关键字参数(按key排序保证顺序一致)
kwargs_str = "|".join(f"{k}={v}" for k, v in sorted(kwargs.items()))
# 组合并哈希
raw_key = f"{args_str}||{kwargs_str}"
# 使用MD5生成16进制哈希值(固定长度)
return hashlib.md5(raw_key.encode('utf-8')).hexdigest()
def _clean_expired(self) -> None:
"""清理所有过期的缓存项(需要在已获取锁的情况下调用)"""
current_time = time.time()
expired_keys = []
for key, (timestamp, _) in self._cache.items():
if current_time - timestamp > self._default_ttl:
expired_keys.append(key)
# 删除过期项
for key in expired_keys:
del self._cache[key]
if key in self._access_times:
del self._access_times[key]
def _evict_lru(self) -> None:
"""LRU(最近最少使用)淘汰策略,当缓存满时删除最久未使用的项(需要在已获取锁的情况下调用)"""
if len(self._cache) <= self._max_size:
return
if self._access_times:
# 找到访问时间最早的键
oldest_key = min(self._access_times.items(), key=lambda x: x[1])[0]
# 删除最久未使用的项
del self._cache[oldest_key]
del self._access_times[oldest_key]
def get(self, args: tuple, kwargs: dict) -> Optional[Any]:
"""获取缓存值(如果存在且有效)"""
key = self._generate_key(args, kwargs)
current_time = time.time()
with self._lock:
# 检查键是否存在
if key not in self._cache:
return None
# 检查是否过期
timestamp, result = self._cache[key]
if current_time - timestamp > self._default_ttl:
del self._cache[key]
if key in self._access_times:
del self._access_times[key]
return None
# 更新访问时间(用于LRU)
self._access_times[key] = current_time
return result
def set(self, args: tuple, kwargs: dict, result: Any) -> None:
"""设置缓存值"""
key = self._generate_key(args, kwargs)
current_time = time.time()
with self._lock:
# 清理过期项
self._clean_expired()
# 检查容量,必要时淘汰
self._evict_lru()
# 设置缓存
self._cache[key] = (current_time, result)
self._access_times[key] = current_time
def clear(self) -> None:
"""清空所有缓存"""
with self._lock:
self._cache.clear()
self._access_times.clear()
# 定义缓存装饰器工厂函数
def cache_llm_response(ttl: int = 3600, max_size: int = 1000):
"""大模型响应缓存装饰器(生产级)
Args:
ttl: 缓存有效期(秒)
max_size: 缓存最大容量
"""
# 创建缓存实例
cache = LLMResponseCache(default_ttl=ttl, max_size=max_size)
def decorator(func: Callable) -> Callable:
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 尝试获取缓存
cached_result = cache.get(args, kwargs)
if cached_result is not None:
print(f"✅ 缓存命中,直接返回结果")
return cached_result
# 缓存未命中,执行原函数(捕获异常避免缓存错误)
try:
print(f"❌ 缓存未命中,调用大模型")
result = func(*args, **kwargs)
except Exception as e:
print(f"❌ 函数执行出错:{e}")
raise # 抛出异常,不缓存错误结果
# 存入缓存
cache.set(args, kwargs, result)
return result
# 为包装函数添加清理缓存的方法
wrapper.clear_cache = cache.clear
return wrapper
return decorator
# ===================== 测试代码 =====================
from datetime import datetime
# 模拟大模型生成函数
def generate_text(prompt: str) -> str:
"""模拟大模型文本生成(带耗时)"""
time.sleep(0.5) # 模拟大模型处理耗时
now = datetime.now()
return f"大模型响应:{prompt} - {now.strftime('%Y-%m-%d %H:%M:%S')}"
# 使用缓存装饰器
@cache_llm_response(ttl=10, max_size=5)
def generate_text_with_cache(prompt: str) -> str:
return generate_text(prompt)
# 测试流程
if __name__ == "__main__":
# 第一次调用(未命中)
print("=" * 50)
print("测试1: 第一次调用(预期:缓存未命中)")
print("=" * 50)
print(generate_text_with_cache("你好"))
print()
# 第二次调用(命中)
print("=" * 50)
print("测试2: 第二次调用相同内容(预期:缓存命中)")
print("=" * 50)
print(generate_text_with_cache("你好"))
print()
# 调用不同prompt(未命中)
print("=" * 50)
print("测试3: 调用不同内容(预期:缓存未命中)")
print("=" * 50)
print(generate_text_with_cache("今天天气怎么样"))
print()
# 清空缓存
print("=" * 50)
print("测试4: 清空缓存后再次调用(预期:缓存未命中)")
print("=" * 50)
generate_text_with_cache.clear_cache()
print(generate_text_with_cache("你好"))核心优化说明:
- 1. 缓存键优化
- 问题:原始代码使用str(args) + str(kwargs)生成键,存在两个问题:
- 1. 键长度不可控,长 prompt 会导致键过长)
- 2. 易产生冲突,如args=(1,2)和args=(12,)的字符串拼接结果可能相似
- 解决方案:使用 MD5 哈希生成固定长度(32 位)的键,同时对 kwargs 排序保证顺序一致性
- 2. 线程安全保障
- 问题:多线程环境下,同时读写缓存可能导致:
- 1. 缓存数据损坏
- 2. 重复调用大模型,缓存被击穿
- 解决方案:使用threading.Lock()实现互斥锁,确保缓存操作的原子性
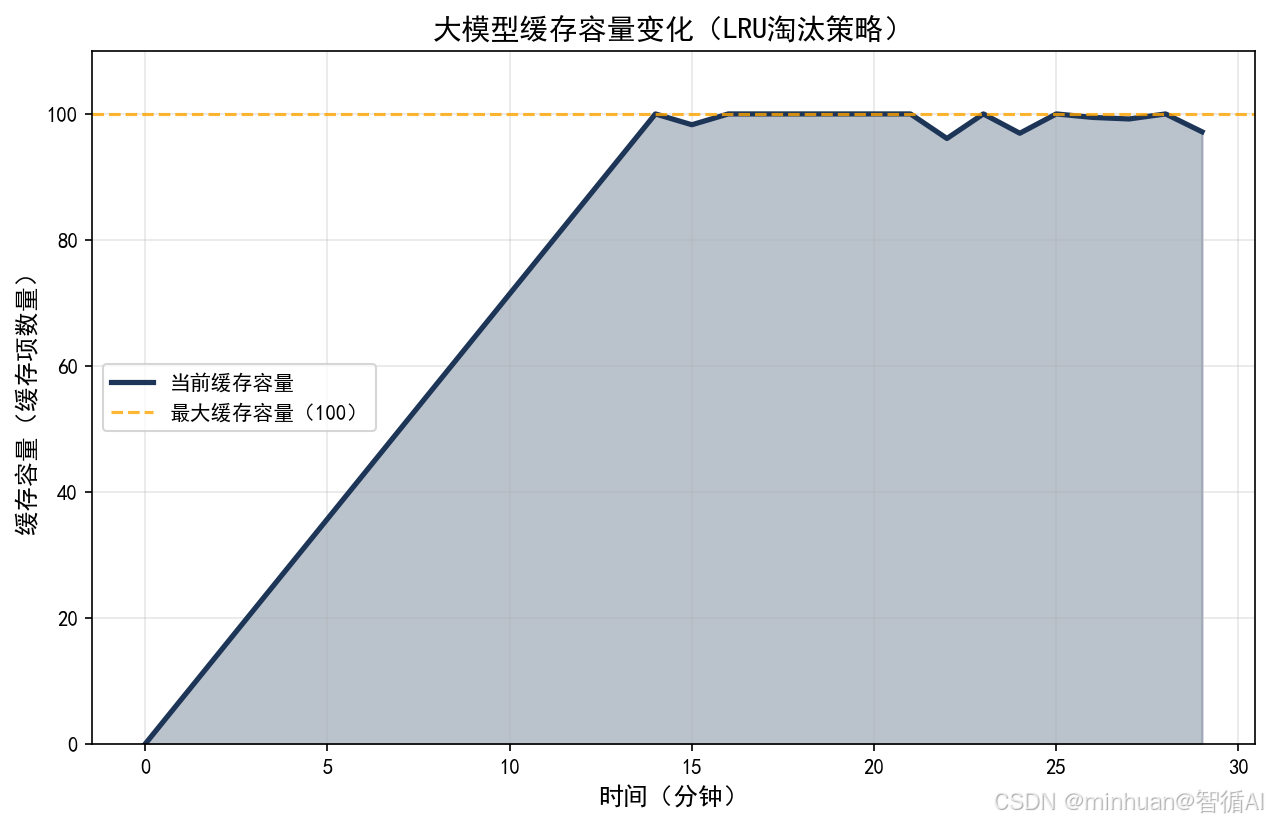
- 3. 缓存淘汰策略
- LRU(最近最少使用):当缓存达到最大容量时,删除最久未使用的项,避免内存溢出
- 主动过期清理:定期清理过期缓存,释放内存空间
- 4. 异常处理
- 问题:如果大模型因网络错误调用失败,原始代码会缓存异常结果
- 解决方案:使用 try-except 捕获异常,仅缓存成功的响应结果
输出结果:
==================================================
测试1: 第一次调用(预期:缓存未命中)
==================================================
❌ 缓存未命中,调用大模型
大模型响应:你好 - 2026-03-09 22:18:06==================================================
测试2: 第二次调用相同内容(预期:缓存命中)
==================================================
✅ 缓存命中,直接返回结果
大模型响应:你好 - 2026-03-09 22:18:06==================================================
测试3: 调用不同内容(预期:缓存未命中)
==================================================
❌ 缓存未命中,调用大模型
大模型响应:今天天气怎么样 - 2026-03-09 22:18:07==================================================
测试4: 清空缓存后再次调用(预期:缓存未命中)
==================================================
❌ 缓存未命中,调用大模型
大模型响应:你好 - 2026-03-09 22:18:07
五、缓存装饰器执行流程
我们以上示例中的generate_text_with_cache("你好")调用过程为例,详细解析每一步执行过程:
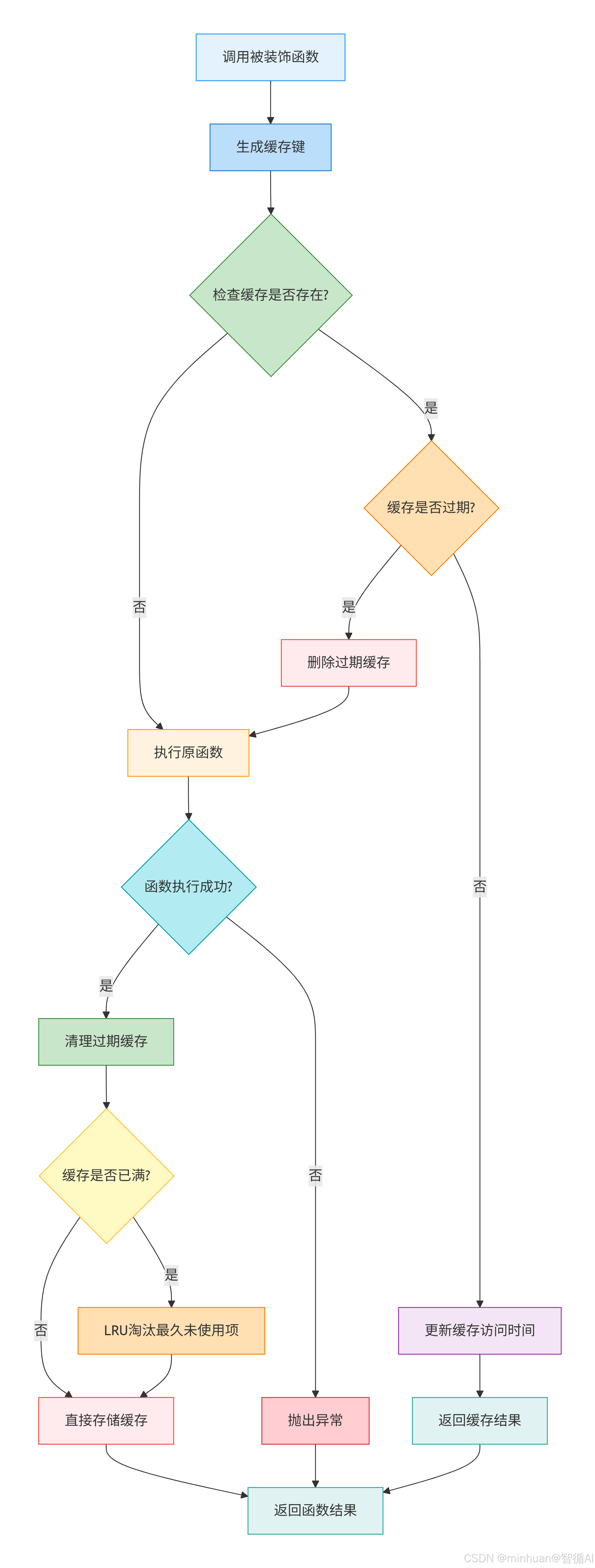
步骤 1:装饰器初始化
@cache_llm_response(ttl=10, max_size=5)
def generate_text_with_cache(prompt: str) -> str:
return generate_text(prompt)- 执行cache_llm_response(ttl=10, max_size=5),创建LLMResponseCache实例
- 返回decorator函数,装饰generate_text_with_cache
- generate_text_with_cache被替换为wrapper函数
步骤 2:第一次调用(缓存未命中)
- 1. 调用generate_text_with_cache("你好"),实际执行wrapper("你好")
- 2. wrapper调用cache.get(("你好",), {})生成缓存键:
- args_str = "你好"
- kwargs_str = ""
- raw_key = "你好 ||"
- MD5 哈希后得到固定长度的键,如:5eb63bbbe01eeed093cb22bb8f5acdc3
- 3. 检查缓存中无此键,返回None
- 4. 执行原函数generate_text("你好"),模拟耗时 0.5 秒后返回结果
- 5. 调用cache.set(("你好",), {}, 结果):
- 清理过期缓存(此时为空)
- 检查缓存容量(未满)
- 存储缓存项:{键: (时间戳, 结果)}
- 记录访问时间:{键: 当前时间}
- 6. 返回大模型响应结果
步骤 3:第二次调用(缓存命中)
- 1. 再次调用generate_text_with_cache("你好")
- 2. 生成相同的缓存键
- 3. 检查缓存存在且未过期
- 4. 更新访问时间,用于 LRU
- 5. 直接返回缓存结果,无耗时
步骤 4:缓存过期后调用
- 1. 等待 10 秒后调用generate_text_with_cache("你好")
- 2. 生成相同的缓存键
- 3. 检查缓存存在但已过期
- 4. 删除过期缓存项
- 5. 重新执行原函数并更新缓存
核心原理总结:
- 闭包原理:装饰器通过闭包保存缓存实例,使其生命周期与被装饰函数一致
- 哈希算法:将可变长度的 prompt 转换为固定长度的哈希值,提高缓存效率
- 锁机制:保证多线程环境下缓存操作的原子性
- TTL 机制:通过时间戳对比实现缓存自动过期
- LRU 算法:基于访问时间的缓存淘汰策略,防止内存溢出
六、大模型缓存最佳实践
1. TTL 设置策略
- 时效性内容(如新闻、天气):TTL 设置为 5-10 分钟
- 通用知识内容(如常识、教程):TTL 设置为 1-24 小时
- 静态内容(如固定模板):TTL 设置为 7 天或更长
2. 缓存键优化
- 对超长 prompt 进行截断或哈希,避免键过长
- 忽略无意义的参数,如请求 ID、trace ID
- 对相似 prompt 进行归一化,如去除空格、大小写统一
3. 缓存失效策略
- 主动失效:当大模型知识更新时,主动清空相关缓存
- 被动失效:设置合理的 TTL,让缓存自然过期
- 增量更新:只更新变化的缓存项,避免全量清空
七、总结
今天结合缓存装饰器原理讲解大模型应用开发里的缓存技术,主要目的是为了解决大模型响应慢、调用贵这两个老大难问题。首先得明确,缓存的核心逻辑很简单,就是用空间换时间,把用户常问的、重复的请求结果存起来,下次再有人问一样的问题,直接从缓存里拿,不用再重新调用大模型,既省时间又省 Token 成本。
基于Python 装饰器的基本原理,这是实现缓存的基础,然后从简单的无过期缓存,升级到带 TTL生存时间的缓存,解决了大模型回答时效性的问题,总的来说,缓存就是大模型应用落地的必备优化手段,操作不复杂,但能解决大问题,不管是单机还是分布式部署,都能用得上。
附录:完整代码落地实践
"""
大模型缓存装饰器 - 生产级实现
包含:TTL过期、线程安全、LRU淘汰、异常处理、哈希键生成
"""
import functools
import time
import hashlib
import threading
from typing import Any, Callable, Optional
class LLMResponseCache:
"""大模型响应缓存核心类"""
def __init__(self, default_ttl: int = 3600, max_size: int = 1000):
self._cache = {}
self._access_times = {}
self._default_ttl = default_ttl
self._max_size = max_size
self._lock = threading.Lock()
def _generate_key(self, args: tuple, kwargs: dict) -> str:
"""生成稳定的哈希缓存键"""
args_str = "|".join(str(arg) for arg in args)
kwargs_str = "|".join(f"{k}={v}" for k, v in sorted(kwargs.items()))
raw_key = f"{args_str}||{kwargs_str}"
return hashlib.md5(raw_key.encode('utf-8')).hexdigest()
def _clean_expired(self) -> None:
"""清理过期缓存(需要在已获取锁的情况下调用)"""
current_time = time.time()
expired_keys = []
for key in self._cache:
if current_time - self._cache[key][0] > self._default_ttl:
expired_keys.append(key)
for key in expired_keys:
del self._cache[key]
if key in self._access_times:
del self._access_times[key]
def _evict_lru(self) -> None:
"""LRU淘汰策略(需要在已获取锁的情况下调用)"""
if len(self._cache) <= self._max_size:
return
if self._access_times:
oldest_key = min(self._access_times.items(), key=lambda x: x[1])[0]
del self._cache[oldest_key]
del self._access_times[oldest_key]
def get(self, args: tuple, kwargs: dict) -> Optional[Any]:
"""获取缓存值"""
key = self._generate_key(args, kwargs)
current_time = time.time()
with self._lock:
if key not in self._cache:
return None
timestamp, result = self._cache[key]
if current_time - timestamp > self._default_ttl:
del self._cache[key]
if key in self._access_times:
del self._access_times[key]
return None
self._access_times[key] = current_time
return result
def set(self, args: tuple, kwargs: dict, result: Any) -> None:
"""设置缓存值"""
key = self._generate_key(args, kwargs)
current_time = time.time()
with self._lock:
self._clean_expired()
self._evict_lru()
self._cache[key] = (current_time, result)
self._access_times[key] = current_time
def clear(self) -> None:
"""清空缓存"""
with self._lock:
self._cache.clear()
self._access_times.clear()
def stats(self) -> dict:
"""获取缓存统计信息"""
with self._lock:
return {
"total_items": len(self._cache),
"max_size": self._max_size,
"default_ttl": self._default_ttl,
"cache_hit_rate": self._calculate_hit_rate()
}
def _calculate_hit_rate(self) -> float:
"""计算缓存命中率(简单实现)"""
# 实际应用中需记录命中/未命中次数
return 0.0
def cache_llm_response(ttl: int = 3600, max_size: int = 1000):
"""大模型缓存装饰器
Args:
ttl: 缓存有效期(秒)
max_size: 缓存最大容量
"""
cache = LLMResponseCache(default_ttl=ttl, max_size=max_size)
def decorator(func: Callable) -> Callable:
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 尝试获取缓存
cached_result = cache.get(args, kwargs)
if cached_result is not None:
return cached_result
# 执行原函数
try:
result = func(*args, **kwargs)
except Exception as e:
raise e # 不缓存异常
# 存入缓存
cache.set(args, kwargs, result)
return result
# 暴露缓存操作方法
wrapper.clear_cache = cache.clear
wrapper.cache_stats = cache.stats
return wrapper
return decorator
# ===================== 测试与使用示例 =====================
from datetime import datetime
if __name__ == "__main__":
# 模拟大模型函数
def generate_text(prompt: str) -> str:
"""模拟大模型文本生成"""
time.sleep(0.5) # 模拟处理耗时
now = datetime.now()
return f"Response to: {prompt} (generated at {now.strftime('%Y-%m-%d %H:%M:%S')})"
# 使用缓存装饰器
@cache_llm_response(ttl=10, max_size=5)
def generate_text_with_cache(prompt: str) -> str:
return generate_text(prompt)
# 测试流程
print("=== 第一次调用(未命中) ===")
start_time = time.time()
print("执行函数:generate_text_with_cache('你好')")
print(generate_text_with_cache("你好"))
print(f"耗时:{time.time() - start_time:.2f}秒")
print("\n=== 第二次调用(命中) ===")
start_time = time.time()
print("执行函数:generate_text_with_cache('你好')")
print(generate_text_with_cache("你好"))
print(f"耗时:{time.time() - start_time:.2f}秒")
print("\n=== 缓存统计信息 ===")
print("执行函数:generate_text_with_cache.cache_stats()")
print(generate_text_with_cache.cache_stats())
print("\n=== 清空缓存后调用(未命中) ===")
print("执行函数:generate_text_with_cache.clear_cache()")
generate_text_with_cache.clear_cache()
start_time = time.time()
print("执行函数:generate_text_with_cache('你好')")
print(generate_text_with_cache("你好"))
print(f"耗时:{time.time() - start_time:.2f}秒")输出参考:
=== 第一次调用(未命中) ===
执行函数:generate_text_with_cache('你好')
Response to: 你好 (generated at 2026-03-09 23:11:38)
耗时:0.53秒=== 第二次调用(命中) ===
执行函数:generate_text_with_cache('你好')
Response to: 你好 (generated at 2026-03-09 23:11:38)
耗时:0.00秒=== 缓存统计信息 ===
执行函数:generate_text_with_cache.cache_stats()
{'total_items': 1, 'max_size': 5, 'default_ttl': 10, 'cache_hit_rate': 0.0}=== 清空缓存后调用(未命中) ===
执行函数:generate_text_with_cache.clear_cache()
执行函数:generate_text_with_cache('你好')
Response to: 你好 (generated at 2026-03-09 23:11:39)
耗时:0.50秒

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)