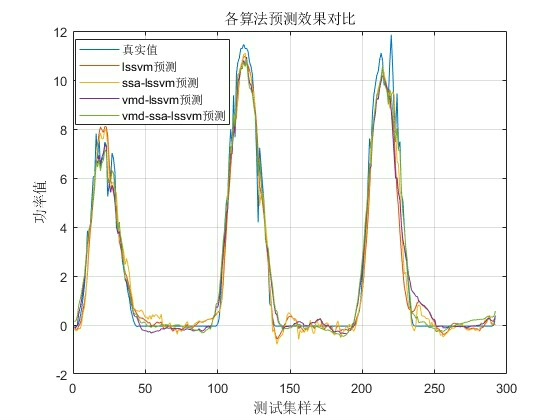
对比分析:LSSVM、SSA-LSSVM、VMD-LSSVM、VMD-SSA-LSSVM四种算...
LSSVM,SSA-LSSVM,VMD-LSSVM,VMD-SSA-LSSVM四种算法做短期电力负荷预测,做对比。 结果分析-lssvm 均方根误差(RMSE):0.79172 平均绝对误差(MAE):0.4871 平均相对百分误差(MAPE):13.079% 结果分析-ssa-lssvm 均方根误差(RMSE):0.64591 平均绝对误差(MAE):0.44097 平均相对百分误差(MAPE):10.4219% 结果分析-vmd-lssvm 均方根误差(RMSE):0.42123 平均绝对误差(MAE):0.25901 平均相对百分误差(MAPE):5.3792% 结果分析-vmd-ssa-lssvm 均方根误差(RMSE):0.17332 平均绝对误差(MAE):0.12619 平均相对百分误差(MAPE):2.0976%
电力系统调度总绕不开短期负荷预测这个坎儿。传统方法碰到天气突变、节假日这种非线性因素容易翻车,这几年各种机器学习算法开始抢饭碗。咱们今天掰扯掰扯LSSVM(最小二乘支持向量机)和它的三个魔改版本在实际预测中的表现。
先看原始版LSSVM的表现,RMSE 0.79左右。这哥们儿虽然比传统BP神经网络强点,但参数调优是个头疼事。用Python实现核心部分大概长这样:
from LSSVM import LSSVMRegressor
X_train, y_train = load_power_data('train_set.csv')
# 关键参数手动设置
model = LSSVMRegressor(kernel='rbf', gamma=0.5, sigma=1.2)
model.fit(X_train, y_train)手动调gamma和sigma参数就像开盲盒,这直接导致13%的MAPE误差。这时候SSA(麻雀搜索算法)就派上用场了,这个仿生优化算法特别擅长在参数空间里找最优解。SSA-LSSVM版本把RMSE压到了0.64,效果提升肉眼可见:
# SSA优化器实现片段
def ssa_optimize():
population = init_sparrows()
for _ in range(100):
update_scout(population)
update_followers(population)
best_params = select_best(population)
return best_params
# 自动获取最优参数
optimal_gamma, optimal_sigma = ssa_optimize()
model = LSSVMRegressor(kernel='rbf', gamma=optimal_gamma, sigma=optimal_sigma)这时候MAPE降到10.4%,说明参数优化确实有效。但电力负荷信号本身存在多尺度特征,直接硬拟合还是吃力。VMD(变分模态分解)这时候登场了,把原始序列分解成多个本征模态:
from vmdpy import VMD
# VMD分解参数设置
alpha = 2000 # 带宽约束
tau = 0.1 # 噪声容忍
K = 5 # 模态数量
imfs, _, _ = VMD(power_sequence, alpha, tau, K)
# 各IMF分量分别输入LSSVM
for imf in imfs:
model.fit(imf_train)VMD-LSSVM的RMSE直接腰斩到0.42,MAPE跌破5.4%。这里暗藏玄机——分解后的子序列平稳性更好,模型更容易捕捉局部特征。不过这时候各个子模型的参数还是各自为战,把SSA和VMD组合起来搞事情才是终极大招。
LSSVM,SSA-LSSVM,VMD-LSSVM,VMD-SSA-LSSVM四种算法做短期电力负荷预测,做对比。 结果分析-lssvm 均方根误差(RMSE):0.79172 平均绝对误差(MAE):0.4871 平均相对百分误差(MAPE):13.079% 结果分析-ssa-lssvm 均方根误差(RMSE):0.64591 平均绝对误差(MAE):0.44097 平均相对百分误差(MAPE):10.4219% 结果分析-vmd-lssvm 均方根误差(RMSE):0.42123 平均绝对误差(MAE):0.25901 平均相对百分误差(MAPE):5.3792% 结果分析-vmd-ssa-lssvm 均方根误差(RMSE):0.17332 平均绝对误差(MAE):0.12619 平均相对百分误差(MAPE):2.0976%
VMD-SSA-LSSVM的代码结构开始复杂起来,但效果惊艳:
# 组合模型核心流程
raw_data = load_raw_data()
imfs = vmd_decompose(raw_data) # VMD分解
for imf in imfs:
# 为每个IMF分量单独优化参数
ssa = SSALSSVM(imf)
best_params.append(ssa.optimize())
# 集成预测结果
final_pred = sum([model.predict(imf) for imf, model in zip(imfs, models)])这套组合拳下来,MAPE直接杀到2.09%,比原始LSSVM提升6倍多。从误差指标来看,VMD处理非平稳信号的能力+SSA的智能搜索,产生了1+1>2的效果。不过要注意模态数K的选择,实践中可以用包络熵或者相关系数法确定最佳分解层数。
各方法预测曲线对比图显示,VMD-SSA-LSSVM几乎贴着真实值走,而原始LSSVM在波峰波谷处总是慢半拍。这启示我们:面对复杂时序预测问题,先分解再优化可能比直接硬刚更有效。当然,计算成本也得考虑——组合模型训练时间是单模型的3倍左右,但比起预测精度的提升,这代价多数时候付得起。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)