MoGE:基于模型增强探索的离策略强化学习
清华大学团队发表于 NeurIPS 2025 的论文《Off-policy Reinforcement Learning with Model-based Exploration Augmentation》提出了MoGE(Modelic Generative Exploration) 框架,通过生成探索不足的关键状态并合成动力学一致的经验,解决了离策略强化学习中被动探索的样本多样性受限问题,大幅提升了复杂控制任务中的样本效率和最终性能。
原文链接:Off-policy Reinforcement Learning with Model-based Exploration Augmentation
代码链接:暂无
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心问题
1.1 强化学习探索的重要性
强化学习(RL)的核心是通过试错优化策略,其性能根本上依赖于与环境交互时收集样本的多样性和状态空间覆盖度。与模仿学习类似,RL 也面临分布外(OOD)问题,但 RL 通过探索能力突破训练数据的局限,抵达未访问的状态空间区域。因此,增强探索策略以收集多样化样本、实现更广泛的状态空间覆盖,是提升 RL 算法有效性和泛化性的关键。
1.2 现有探索方法的分类与缺陷
现有 RL 探索策略分为主动探索和被动探索两类,二者均存在显著局限性,也是本文的核心研究切入点:
(1)主动探索:基于策略的探索,高维环境表现拉胯
主动探索通过在策略中引入随机性(如 ε- 贪心)或添加探索奖励(如最大熵)实现,典型算法如 SAC、DSAC、MPO。其核心缺陷在于:
- 探索受智能体实际交互轨迹限制,受环境初始状态、有限的情节长度和当前策略约束,许多远离典型轨迹的关键区域始终无法被探索;
- 强行通过策略探索会分散奖励优化的注意力,导致学习次优;
- 在高维状态 / 动作空间中,策略驱动的随机探索效率极低,易陷入局部最优。
(2)被动探索:基于状态的探索,样本分布受限于历史数据
被动探索通过修改样本分布、优先利用有价值的经验实现,起源于优先经验回放(PER),后续衍生出 SER、PGR 等基于生成模型增强回放缓冲区的方法,以及结合世界模型模拟状态转移的方法。其核心缺陷在于:
- 即使是生成模型增强的方法,也仅能在观测数据附近扩展样本,无法脱离原始数据分布;
- 依赖策略条件转移的世界模型方法,生成样本的多样性有限;
- 高维状态空间中生成完整转移会导致合成数据的偏差呈指数级放大,破坏动力学一致性。
1.3 研究目标
针对被动探索的样本多样性受限问题,本文提出 MoGE 框架,核心目标是:
- 生成全状态空间内探索不足但对策略优化有关键作用的状态,突破历史经验的分布限制;
- 保证生成样本的状态空间合规性和动力学一致性,避免合成数据引入偏差;
- 设计模块化的框架,可无缝集成到现有离策略 RL 算法中,无需修改其核心结构。
二、预备知识
论文在方法设计前,明确了强化学习探索和扩散模型的核心基础概念,为后续 MoGE 的设计提供理论支撑。
2.1 强化学习与策略探索的核心定义
(1)马尔可夫决策过程(MDP)
RL 环境建模为![]() ,其中
,其中/
为状态 / 动作空间,
![]() 为转移动力学,
为转移动力学,![]() 为奖励函数,
为奖励函数,![]() 为折扣因子。
为折扣因子。
(2)占用测度(Occupancy Measure)
- 状态占用测度
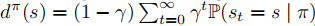 :表示策略
:表示策略 下状态
的访问频率;
- 状态 - 动作占用测度
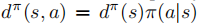 :表示策略
:表示策略 )的访问频率。
策略优化的目标是最大化累积期望奖励:
![]()
(3)值函数与 TD 误差
值函数通过最小化时间差分(TD)误差训练,以估计当前策略的价值:
![]()
其中![]() 为动作值函数,TD 误差反映了值函数对实际回报的近似误差,是衡量状态关键性的核心指标。
为动作值函数,TD 误差反映了值函数对实际回报的近似误差,是衡量状态关键性的核心指标。
(4)衡量状态关键性的两个核心指标
论文将策略熵和TD 误差作为判断状态是否为关键状态(对策略探索 / 优化有高价值)的核心依据,也是后续 MoGE 生成关键状态的效用函数:
- 策略熵:
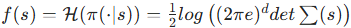 (高斯分布策略),高熵表示状态的动作选择随机性大,可能是访问不足或 MDP 关键决策点,探索此类状态可提升策略鲁棒性;
(高斯分布策略),高熵表示状态的动作选择随机性大,可能是访问不足或 MDP 关键决策点,探索此类状态可提升策略鲁棒性; - TD 误差:
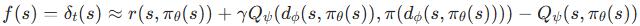 ,高 TD 误差表示值函数对该状态的回报估计误差大,对应高不确定性区域,优先学习可减少值偏差。
,高 TD 误差表示值函数对该状态的回报估计误差大,对应高不确定性区域,优先学习可减少值偏差。
2.2 生成任务的扩散模型基础
扩散模型是 MoGE 中关键状态生成器的核心,其通过模拟前向扩散和反向去噪两个互补过程,捕捉复杂的数据分布:
- 前向扩散:对原始数据
逐步添加高斯噪声,最终得到纯噪声
,过程为:
其中
为噪声调度。记
 ,
, ,则
,则 
- 反向去噪:通过参数化神经网络
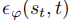 预测噪声项,从纯噪声中重构原始数据分布,近似后验分布为:
预测噪声项,从纯噪声中重构原始数据分布,近似后验分布为:
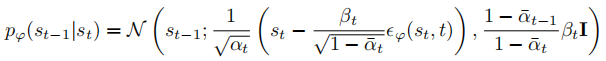
- 训练目标:最小化噪声预测误差,使模型能从标准高斯噪声中逐步去噪生成数据:
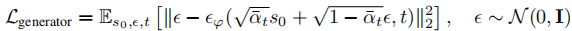
三、MoGE 框架的核心设计
MoGE 是一个模块化的生成式探索框架,专为离策略 RL 设计,核心由两个组件构成:基于扩散的关键状态生成器和一步想象世界模型,并设计了与离策略 RL 兼容的训练框架,实现生成样本与真实经验的融合学习。MoGE 的整体框架如图 1 所示。
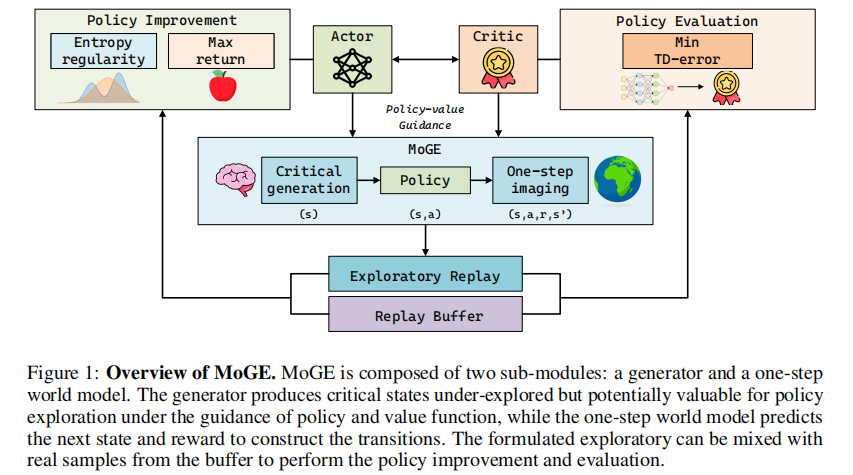
3.1 基于稳态占用测度对齐的关键状态生成
该模块是 MoGE 的核心创新点之一,解决了 “如何生成合规、有探索价值的关键状态” 的问题,分为生成器结构和理论保证两部分。
3.1.1 分类器引导的扩散生成器
MoGE 采用分类器引导的扩散模型![]() 作为效用条件生成器,合成对策略优化有高价值的关键状态,其核心是将无条件扩散梯度与分类器效用梯度结合,实现对生成方向的精准引导:扩散梯度分类器效用梯度其中:
作为效用条件生成器,合成对策略优化有高价值的关键状态,其核心是将无条件扩散梯度与分类器效用梯度结合,实现对生成方向的精准引导:扩散梯度分类器效用梯度其中:
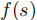 为效用函数,即前文的策略熵或TD 误差,用于衡量状态的探索价值;
为效用函数,即前文的策略熵或TD 误差,用于衡量状态的探索价值;为引导尺度,平衡无条件扩散的先验分布和目标效用函数的引导作用,控制生成状态向高探索价值区域的偏移程度。
无条件扩散模型学习合理状态的流形,保证生成状态的物理合规性;分类器引导则将生成方向转向高效用的关键区域,实现 “合规且有价值” 的状态生成。
3.1.2 稳态占用测度对齐的理论保证
生成式模型在 RL 中应用的核心挑战是:RL 的数分布随策略更新动态变化,难以确定稳定的目标分布,易导致生成状态脱离真实状态空间。为解决该问题,论文提出定理 1(稳态占用测度对齐定理),为生成状态的状态空间合规性提供严格的理论证明。
定理 1 :

定理 1 的核心意义
回放缓冲区中的行为策略随训练逐渐收敛,其诱导的占用测度![]() 渐近收敛到最优策略的稳态占用测度
渐近收敛到最优策略的稳态占用测度![]() 。将扩散生成器的训练分布与回放缓冲区的稳态占用测度对齐,可保证生成的关键状态与最优策略的占用测度共享支撑集,即生成状态始终处于真实的状态空间中,满足状态空间合规性。
。将扩散生成器的训练分布与回放缓冲区的稳态占用测度对齐,可保证生成的关键状态与最优策略的占用测度共享支撑集,即生成状态始终处于真实的状态空间中,满足状态空间合规性。
3.1.3 效用函数的选择
MoGE 选择策略熵和TD 误差作为效用函数,且针对不同的学习阶段有不同的适用场景:
- TD 误差:更适用于策略评估阶段,高 TD 误差区域是值函数估计的薄弱环节,优先学习可快速修正值偏差;
- 策略熵:更适用于策略改进阶段,高熵区域是访问不足或关键决策点,探索可提升策略的覆盖度和鲁棒性。
训练中可针对不同任务选择不同的效用信号,加速值函数的收敛和策略优化。
3.2 基于一步想象世界模型的转移合成
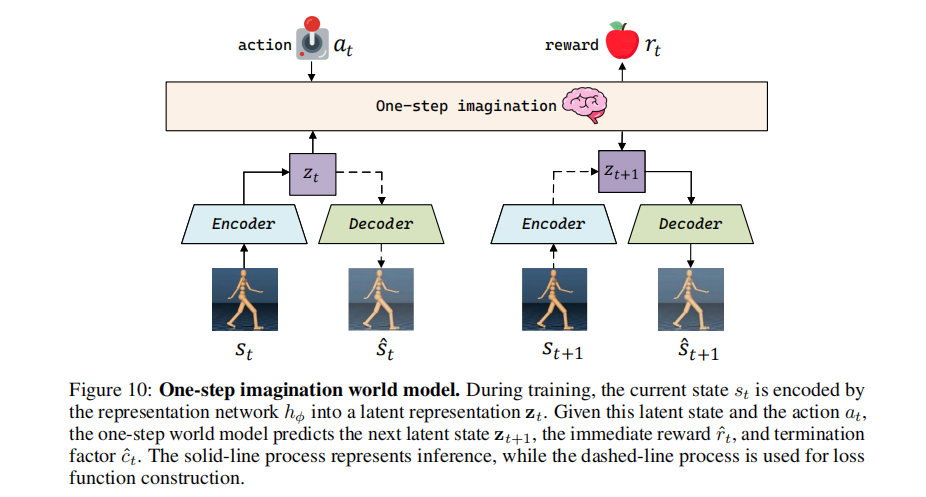
生成关键状态后,需要为其构建完整的状态转移(s→a→s′,r),才能作为训练经验用于 RL。论文设计了一步想象世界模型(One-step Imagination World Model)![]() ,解决了 “如何生成动力学一致的状态转移” 的问题,与传统世界模型相比,其在结构和训练上做了针对性优化,更适配离策略 RL 的探索需求。
,解决了 “如何生成动力学一致的状态转移” 的问题,与传统世界模型相比,其在结构和训练上做了针对性优化,更适配离策略 RL 的探索需求。
3.2.1 一步想象世界模型的核心设计思路
与传统世界模型追求长程预测精度不同,MoGE 的世界模型仅关注一步动力学预测,核心原因是:
- MoGE 的目标是为关键状态构建有效的一步转移,无需长程想象;
- 牺牲长程精度,可保证最优策略占用测度区域内的一步转移可靠性,避免高维空间中长程预测的偏差累积;
- 一步预测的训练更高效,可通过监督学习快速预训练,适配 RL 的在线训练过程。
3.2.2 模型结构
一步想象世界模型![]() 由5 个参数化组件构成,在隐空间中实现状态的编码、重构、动力学预测、奖励预测和终止预测,结构如图 10 所示。
由5 个参数化组件构成,在隐空间中实现状态的编码、重构、动力学预测、奖励预测和终止预测,结构如图 10 所示。
- 除隐动力学模块采用两层 Transformer 编码器(灵活处理序列和单步输入)外,其余模块均为标准 MLP;
- 采用隐空间建模的原因:捕捉任务相关的抽象特征,提升泛化性;隐空间动力学更平滑,预测精度更高;与策略网络共享编码器,实现统一的状态表示。
3.2.3 训练损失函数
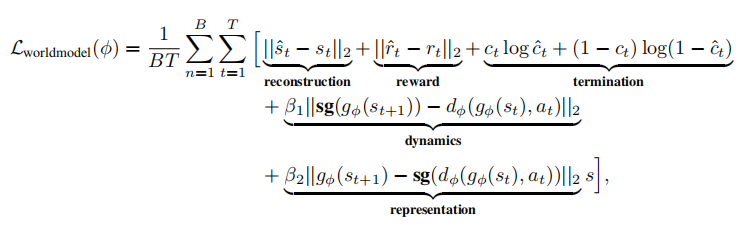
世界模型的训练损失为多任务损失,融合了重构损失、奖励损失、终止损失、动力学损失和表示损失,保证各模块的预测精度和一致性:
其中:
- β1=0.5,β2=0.1为损失系数;
- sg(⋅)为停止梯度算子,避免梯度回传导致的训练不稳定性;
- B为批次大小,T为转移长度,T=1时为单步预测(MoGE 的核心使用场景)。
所有模块均采用确定性网络实现,论文通过实验验证,确定性网络在一步预测中的性能已足够优秀,无需引入概率组件,简化了模型结构。
3.3 MoGE 与离策略 RL 的融合训练
MoGE 的核心定位是离策略 RL 的插件式探索模块,论文设计了专门的训练框架,实现生成的关键转移经验与回放缓冲区的真实经验的融合学习,并解决了生成样本与真实样本之间的分布偏移问题。本节分为生成样本的质量分析和具体训练框架两部分。
3.3.1 MoGE 生成样本的质量分析
生成样本的有效性是 MoGE 发挥作用的前提,论文从新颖性和动力学一致性两个核心维度,证明了 MoGE 生成样本优于现有被动探索方法。
(1)新颖性:解耦生成与历史行为策略
现有被动探索方法(如 PER、SER、PGR)的生成样本始终受历史行为策略 的覆盖偏差限制,无法脱离原始数据分布。而 MoGE 构建了与当前策略耦合的生成分布:
![]()
其中关键状态分布随效用函数动态更新:
![]()
由于效用函数 随当前策略
和值函数
的更新而动态变化,MoGE 的生成目标分布也会持续偏移,自适应地生成新的高价值探索区域,实现了生成过程与历史行为策略的解耦,保证了样本的持续新颖性。
(2)动力学一致性:保证贝尔曼有效性
新颖性需与动力学一致性结合,否则生成的样本会破坏 Markov 性,导致 TD 估计偏差。MoGE 通过一步想象世界模型,强制生成的转移满足环境的动力学核![]() :
:
![]()
其中 为真实环境动力学。该机制保证了生成样本的物理 / 因果转移关系,满足贝尔曼一致性:
![]()
其中![]() 为贝尔曼算子。而现有直接合成转移的方法,易引入虚假的
为贝尔曼算子。而现有直接合成转移的方法,易引入虚假的![]() 关联,破坏贝尔曼一致性,导致策略评估偏差。
关联,破坏贝尔曼一致性,导致策略评估偏差。
(3)总结
MoGE 通过动态效用引导的生成实现样本的持续新颖性,突破历史经验的分布限制;通过一步想象世界模型实现样本的动力学一致性,保证贝尔曼有效性。二者的结合,使 MoGE 能在不违反贝尔曼有效性的前提下,探索行为策略支撑集之外的区域,实现更有效的策略学习。
3.3.2 离策略 RL 的融合训练框架
论文以Actor-Critic为例,设计了 MoGE 与离策略 RL 的融合训练框架(如算法 1 所示),核心步骤包括预训练、数据收集、模型更新、关键样本生成和策略优化,并通过λ- 混合采样解决生成样本与真实样本的分布偏移问题。
算法 1:融合 MoGE 的离策略 RL 训练框架

核心问题解决:分布偏移与近似重要性采样
生成的关键样本与真实样本之间存在初始状态分布偏移,若直接融合会导致策略优化的偏差。由于扩散模型的分布无法显式表示,精确的重要性采样(IS) 难以实现,论文提出λ- 混合采样作为近似重要性采样方法,在有界误差下解决分布偏移问题。
- 策略评估:无需重要性采样,因为贝尔曼等式是逐点成立的,任意比例的生成样本与真实样本混合,值函数的平方 TD 误差损失的全局最小值仍为真实值函数
,分布偏移仅影响优化方差,不引入偏差;
- 策略改进:需要通过 λ- 混合采样平衡真实样本和生成样本,策略改进的损失为:
其中: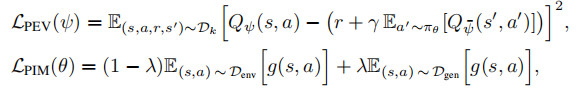
为真实样本分布,
为生成样本分布;
- g(s,a)为单步状态 - 动作对的回报;
- λ∈[0,1)为混合比例,需设置为较小值(论文实验中λ=0.2),以保证偏差可控。
论文通过引理 4(λ- 混合估计器偏差) 证明,该近似方法的偏差为![]() ,当 λ 足够小时,偏差可忽略。
,当 λ 足够小时,偏差可忽略。
此外,论文将样本混合比例 k(策略评估中生成样本的比例)设置为k=2λ,以减少训练方差。
四、实验验证
论文通过大量实验,从主实验性能对比、消融实验、补充实验三个维度,验证了 MoGE 的有效性、模块的必要性和泛化性。实验基于OpenAI Gym和DeepMind Control Suite (DMC) 两大经典连续控制基准,覆盖高维、复杂的机器人运动任务,充分验证了 MoGE 在样本效率和最终性能上的提升。
4.1 实验设置
(1)基线算法
- 离策略 RL 基线:DSAC(随机策略)、TD3(确定性策略),二者分别通过熵奖励和随机噪声实现主动探索;
- 被动探索基线:PER(经典优先经验回放)、PGR(当前 sota 的生成式被动探索方法,基于扩散模型生成回放样本)。
(2)实验基准
选择10 个具有挑战性的连续控制任务,分为 5 个 DMC 任务(Humanoid-walk/stand/run、Quadruped-run/walk)和 5 个 OpenAI Gym 任务(Walker2d-v3、Humanoid-v3、Ant-v3、Halfcheetah-v3、Swimmer-v3),涵盖高维状态 / 动作空间(如 Humanoid-v3 的 376 维状态、17 维动作)和复杂的动力学(如双足 / 四足机器人的平衡与协调)。
(3)实现细节
- MoGE 作为插件式模块,直接集成到基线算法中,未对基线算法做任何微调;
- 总训练步数为 150 万,所有结果均为3 个随机种子的平均值,保证统计显著性;
- 实验硬件:AMD Ryzen Threadripper 3960X CPU + NVIDIA GeForce RTX 4090 GPU;
- 为降低计算开销,MoGE 的训练每 10 步环境交互执行一次,平衡了探索性能和计算效率。
4.2 主实验结果:性能与样本效率的全面提升
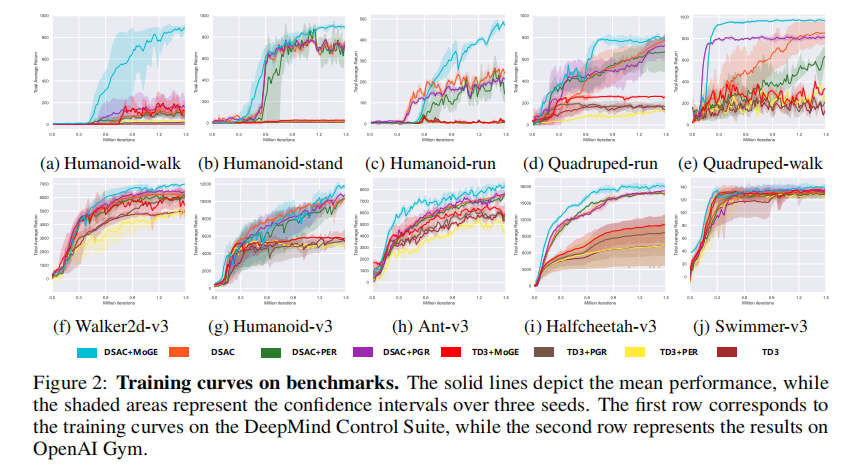
实验以总平均回报(Total Average Return, TAR) 为核心指标,训练曲线如图 2 所示:
详细数值如表 1 所示:
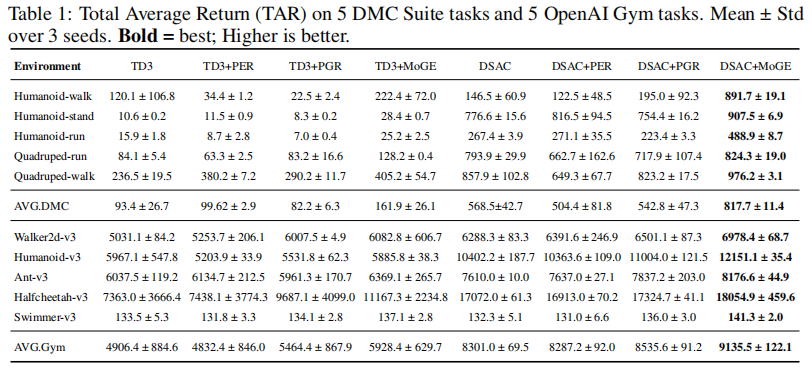
MoGE 在所有任务中均实现了显著的性能提升,且在高维、复杂任务中提升更明显,充分验证了其有效性。
核心实验结论:
- DMC 任务:MoGE 使 DSAC 的平均 TAR 从 568.5 提升至 817.7(+43.8%),TD3 的平均 TAR 从 93.4 提升至 161.9(+73.3%);在 Humanoid-walk 任务中,DSAC+MoGE 的 TAR 达到 891.7,较原始 DSAC(146.5)提升508.6%,提升效果极其显著;
- OpenAI Gym 任务:MoGE 使 DSAC 的平均 TAR 从 8301.0 提升至 9135.5(+10.0%),TD3 的平均 TAR 从 4906.4 提升至 5928.4(+20.8%);在 Humanoid-v3 任务中,DSAC+MoGE 的 TAR 达到 12151.1,较原始 DSAC(10402.2)提升16.8%;
- 对比现有被动探索方法:MoGE 显著优于 PER 和 PGR,证明了其生成的关键状态转移比传统的优先回放或近邻生成样本更有探索价值;
- 样本效率:MoGE 在训练早期即可实现回报的快速提升,说明生成的关键样本加速了策略的学习过程,大幅提升了样本效率。
4.3 消融实验:验证 MoGE 核心模块的必要性
论文在DMC 的 Humanoid-run 任务(高复杂度)上进行了消融实验,验证了效用函数选择、引导尺度ω、** 混合比例λ** 三个核心超参数 / 模块的必要性,消融曲线如图 3 所示。
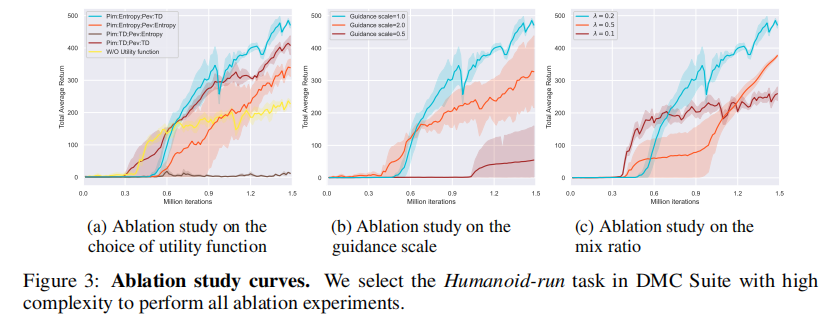
(1)效用函数的选择
对比策略熵和TD 误差在策略评估和改进中的作用,结论:
- TD 误差更适用于策略评估,能快速修正值函数的偏差;
- 策略熵更适用于策略改进,能鼓励更广泛的探索,避免高 TD 误差区域因环境估计不准确导致的不可靠评估。
(2)引导尺度ω的选择
引导尺度控制效用函数对生成器的引导强度,实验结果显示:
- ω=1为最优值,能有效平衡高探索价值状态的生成和状态可行性的保证,使生成的状态既具有高探索价值,又与最优策略的占用测度对齐。
(3)混合比例λ的选择
混合比例控制生成样本在策略改进中的占比,实验结果显示:
- **λ=0.2** 为最优值,能实现稳定的性能提升;
- λ 过小:生成的关键样本不足,无法有效提升探索效率;
- λ 过大:生成样本与真实样本的分布偏移加剧,导致策略优化的偏差增大,训练不稳定。
4.4 补充实验:验证 MoGE 的泛化性
为进一步验证 MoGE 的泛化性,论文进行了三类补充实验,分别与更多无模型 RL 算法、基于模型 RL 算法、改进型 Actor-Critic 算法和增强探索方法对比,结果均显示 MoGE 能持续提升基线算法的性能。
(1)与主流无模型 RL 算法对比
对比 DDPG、TRPO、PPO、SAC 等经典无模型 RL 算法,MoGE 集成到 DSAC 后,在 Walker2d-v3、Humanoid-v3、Halfcheetah-v3 任务上的平均 TAR 达到 12394.8,显著优于所有对比算法。
(2)与主流基于模型 RL 算法对比
对比 TD-MPC2、DreamerV3 等 sota 基于模型 RL 算法,MoGE 集成到 DSAC 后,在 DMC Humanoid 任务上的平均 TAR 达到 762.7,优于 TD-MPC2(635.9)和 DreamerV3(2.4),证明 MoGE 的生成式探索与基于模型 RL 的互补性。
(3)与改进型 Actor-Critic 算法对比
对比 REDQ、DroQ、BRO、Simba 等改进型 Actor-Critic 算法,MoGE 在除 Humanoid-stand(最简单任务)外的所有复杂任务中均取得最优性能,证明其在复杂任务中的优势。
(4)与增强探索方法对比
对比 Plan2Explore、MaxInfoRL、OMBRL 等 sota 增强探索方法,MoGE 在 DMC Humanoid 任务上的性能显著提升,核心原因是:
- 现有方法的探索信号(如预测误差、互信息)是任务无关的,易导致无意义的探索;
- MoGE 的效用函数(策略熵、TD 误差)是任务相关的,生成的状态直接对齐策略优化目标,且解耦了探索与奖励设计,训练更稳定。
五、相关工作
论文从主动探索和被动探索两个方向,梳理了 MoGE 与现有工作的关系,明确了 MoGE 的创新点:
5.1 主动探索
主动探索的研究集中在策略修改,如 ε- 贪心、熵正则化、计数法、内在动机、引导式 DQN 等。此类方法的缺陷是高维空间可扩展性差、探索与奖励优化冲突。MoGE 作为被动探索方法,无需修改策略,通过生成关键样本实现探索,避免了上述缺陷。
5.2 被动探索
被动探索的研究分为优先经验回放、生成式经验增强、基于模型的想象三类:
- 优先经验回放(PER、熵基采样):仅对历史样本重排序,无新样本生成;
- 生成式经验增强(SER、PGR):仅在历史样本附近生成,无法脱离原始分布;
- 基于模型的想象(Dreamer、TD-MPC):依赖策略条件转移,样本多样性有限,长程预测偏差大。
MoGE 的创新点在于:
- 基于稳态占用测度对齐,生成全状态空间的关键状态,突破历史分布限制;
- 设计一步想象世界模型,保证生成样本的动力学一致性,避免偏差累积;
- 解耦探索与策略优化,模块化设计可无缝集成到现有离策略 RL 算法中。
六、局限性与未来工作
6.1 局限性
尽管 MoGE 取得了显著的性能提升,但仍存在以下局限性:
- 计算开销:扩散生成器和一步世界模型的引入,增加了额外的计算开销,相比基线算法有轻微的耗时增加;
- 状态分布偏差:MoGE 假设生成器的训练分布与缓冲区的占用测度完全对齐,但实际训练中可能存在微小偏差,影响生成样本的质量;
- 仅适用于离策略 RL:当前 MoGE 的设计针对离策略 RL,无法直接应用于在线策略 RL,限制了其适用场景。
6.2 未来工作
论文提出了三个核心的未来研究方向:
- 与在线策略 RL 的融合:探索将 MoGE 集成到在线策略 RL 框架中,实现关键状态的实时生成,提升在线探索效率;
- 更具表达性的效用函数:设计更复杂的效用函数,结合多维度的状态关键性指标,进一步提升关键状态的生成质量;
- 动态采样策略:基于任务复杂度和训练进度,动态调整生成器的采样策略和混合比例 λ,提升 MoGE 的鲁棒性和泛化性;
- 更先进的生成模型:探索除扩散模型外的更先进生成模型(如流匹配、生成式对抗网络),提升关键状态的生成效率和质量。
七、论文核心创新点总结
本文提出的 MoGE 框架,是离策略强化学习中被动探索的一次重要创新,其核心贡献可总结为三个理论 / 方法创新和一个实验验证:
- 提出分类器引导的扩散关键状态生成器:结合策略熵 / TD 误差作为效用函数,实现高探索价值状态的生成,并通过稳态占用测度对齐定理,为生成状态的合规性提供严格理论证明;
- 设计一步想象世界模型:放弃长程预测精度,专注于一步动力学的可靠预测,保证生成转移的动力学一致性和贝尔曼有效性,适配离策略 RL 的在线训练;
- 设计插件式的离策略融合训练框架:通过λ- 混合近似重要性采样解决分布偏移问题,使 MoGE 可无缝集成到现有离策略 RL 算法中,无需修改其核心结构;
- 大量实验验证:在 OpenAI Gym 和 DMC 的 10 个复杂连续控制任务中,MoGE 显著提升了基线算法的样本效率和最终性能,且在高维、复杂任务中提升更明显,同时通过消融实验和补充实验验证了模块的必要性和泛化性。
MoGE 为强化学习的探索问题提供了新的思路,将生成式建模与模型基探索有机结合,突破了传统被动探索的样本分布限制,为复杂控制任务中的 RL 应用提供了更高效的探索方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)