Agent 生态全解:厘清 Agent、MCP、Skill、RAG、LangChain 与 OpenClaw
本文所有内容均基于权威官方资料撰写,包括 OpenClaw 开源仓库、LangChain 官方文档、MCP 官方协议规范与相关顶会论文。全文以逻辑递进的技术链路为核心,从核心主体到外围组件逐层拆解,厘清各模块的本质定位、边界划分、协同逻辑,结合工程化伪代码具象化实现细节,同时澄清行业高频认知误区,为 Agent 落地开发提供清晰的参考。本文适合人群:大模型应用开发者、Agent 技术研究者、产品经理,以及想要系统了解 Agent 生态的技术从业者。
目录
- 引言:Agent 落地的核心痛点
- Agent:智能体系统的核心决策主体
- Skill:Agent 落地执行的原子能力单元
- MCP:Agent 生态的标准化通信桥梁
- RAG:Agent 决策与执行的知识增强引擎
- LangChain:Agent 开发的编排框架与工程化脚手架
- OpenClaw:开箱即用的全渠道 Agent 完整系统
- 全链路协同:复杂任务中的组件配合闭环
- 场景化选型建议与核心总结
- 参考文献
引言:Agent 落地的核心痛点
随着大语言模型(LLM)的能力边界从 “对话交互” 向 “复杂任务执行” 持续拓展,Agent(智能体)已经成为 LLM 落地产业场景的核心载体。不同于单一 LLM 的文本生成能力,Agent 的核心价值在于通过 “感知 - 决策 - 执行 - 反馈” 的闭环,自主完成用户指定的多步骤复杂任务。
但在工程落地过程中,开发者普遍面临核心概念模糊、组件边界不清、协同逻辑混乱的问题:Agent 与 LLM 的本质区别是什么?Skill 和 Tool 是否为同一概念?MCP 协议到底解决了什么不可替代的问题?LangChain 是 Agent 本身,还是开发工具?爆火的 OpenClaw 在 Agent 生态中到底处于什么位置?
这些问题并非孤立存在,而是存在严格的逻辑递进关系:从核心决策主体(Agent),到执行能力载体(Skill),到跨模块通信标准(MCP),到决策知识支撑(RAG),到工程化开发框架(LangChain),再到开箱即用的完整系统(OpenClaw)。本文将沿着这条技术链路,逐层拆解每个组件的核心逻辑,同时厘清模块间的协同关系与认知误区。
一、Agent:智能体系统的核心决策主体
要厘清 Agent 生态的所有组件,首先必须明确 Agent 的本质 —— 它是整个智能体系统的核心,所有其他组件都是为其服务的配套能力,而非 Agent 本身。
1.1 Agent 的本质与核心边界
很多开发者会陷入 “LLM 就是 Agent” 的认知误区,事实上,LLM 只是 Agent 的 “决策大脑”,而 Agent 是一套具备完整闭环能力的智能系统。单一 LLM 仅能完成文本生成与逻辑推理,无法自主调用外部工具、无法与物理世界 / 业务系统交互、无法形成执行 - 反馈的优化闭环;而 Agent 以 LLM 为核心,整合了记忆、规划、工具调用、反馈修正的全流程能力,核心目标是自主完成用户指定的复杂任务,而非仅输出文本响应。
一个可落地、可扩展的 Agent,必须具备四大核心模块,这也是其区别于单一 LLM 的核心标志:
- 推理规划模块:基于用户需求拆解任务为可执行的子步骤,动态调整执行策略,应对执行过程中的异常情况;
- 记忆模块:存储对话上下文、任务执行历史、外部知识,分为短期记忆(对话上下文)与长期记忆(业务知识库);
- 工具执行模块:对接外部能力,将 LLM 的决策落地为具体操作,弥补 LLM 的原生能力缺陷;
- 反馈闭环模块:基于工具执行结果、知识检索结果,修正决策逻辑,校验任务完成度,实现自主迭代优化。
1.2 Agent 核心执行逻辑的伪代码实现
以下伪代码抽象了 Agent 最经典的 ReAct 执行范式,清晰体现了 Agent 的闭环运行逻辑,以及与单一 LLM 的本质区别:
class BaseAgent:
def __init__(self, llm, memory_module, tool_manager):
self.llm = llm # 仅作为决策核心,不等同于Agent本身
self.memory = memory_module # 记忆模块:管理上下文与执行历史
self.tool_manager = tool_manager # 工具管理模块:对接外部执行能力
def run(self, user_query):
# 1. 初始化任务上下文,写入用户需求
self.memory.add_message(role="user", content=user_query)
task_completed = False
final_result = None
# 2. 核心执行闭环:推理-决策-执行-反馈
while not task_completed:
# 基于历史上下文,完成推理与下一步动作决策
context = self.memory.get_full_context()
thought = self.llm.generate_reasoning(context)
# 决策分支1:任务完成,输出最终结果
if thought["action_type"] == "finish":
task_completed = True
final_result = thought["content"]
self.memory.add_message(role="assistant", content=final_result)
# 决策分支2:需要调用工具,执行具体操作
elif thought["action_type"] == "tool_call":
tool_name = thought["tool_name"]
tool_params = thought["parameters"]
# 获取对应的工具并执行
tool = self.tool_manager.get_tool(tool_name)
execution_result = tool.execute(**tool_params)
# 执行结果写入记忆,形成反馈闭环,供下一轮推理使用
self.memory.add_message(
role="system",
content=f"工具{tool_name}执行结果:{execution_result}"
)
return final_result
1.3 高频认知误区澄清
- 误区 1:Agent 就是大模型,大模型就是 Agent纠正:LLM 是 Agent 的核心组件,但二者完全不等同。Agent 是一套完整的智能系统,LLM 只是其中的推理模块,脱离了记忆、工具、反馈闭环的大模型,无法实现 Agent 的任务执行能力。
- 误区 2:只有能无限自主循环的才叫 Agent纠正:Agent 的形态可根据业务场景伸缩,从单轮工具调用的轻量 Agent,到多轮自主规划的复杂 Agent,核心判断标准是是否具备 “决策 - 执行 - 反馈” 的闭环能力,而非执行轮次的多少。
明确了 Agent 作为决策主体的核心定位后,我们自然会遇到下一个问题:Agent 的决策规划,最终需要落地为具体的操作,而 LLM 本身无法直接与外部系统、设备、服务交互,这些支撑 Agent 执行能力的原子单元,到底是什么?
二、Skill:Agent 落地执行的原子能力单元
Agent 的核心是决策,而决策的落地必须依赖具体的执行能力,Skill 就是承载这些执行能力的最小单元,是 Agent 与外部世界交互的 “手脚”。
2.1 Skill 的核心定义与必备特征
Skill 是为 Agent 场景封装的、具备单一完整功能的、可被 LLM 标准化调用的原子执行模块。它的核心价值,是弥补 LLM 的原生能力缺陷 ——LLM 无法直接发送消息、控制浏览器、操作设备、调用业务接口,这些能力都需要通过封装好的 Skill 来实现。
基于 OpenClaw 等主流 Agent 系统的 Skill 体系设计,一个工程化可用的 Skill,必须具备三大核心特征:
- 单一职责原则:一个 Skill 仅完成一类明确的操作,比如 “发送飞书消息”“浏览器页面截图”“获取设备地理位置”,避免功能耦合导致的调用混乱;
- 标准化接口规范:包含清晰的功能描述、输入参数 Schema、输出格式规范,这些信息会被输入给 LLM,让大模型能自主判断是否调用、以及如何调用该 Skill;
- LLM 友好性:内置参数校验、异常处理、结果格式化逻辑,能将外部接口返回的异构数据,转换为 LLM 易于理解和处理的标准化内容,同时在出错时给出明确的修正提示。
2.2 Skill 与 Tool 的边界与关联
在 Agent 开发中,开发者经常会混淆 Skill 和 Tool 两个概念,二者并非对立关系,而是抽象与实现、框架层与业务层的对应关系,具体区别与关联如下:
| 对比维度 | Tool(工具) | Skill(技能) |
|---|---|---|
| 核心定位 | 框架层的抽象接口定义,是对外部能力的通用封装规范 | 业务层的具体功能实现,是适配 Agent 场景的完整能力单元 |
| 典型案例 | LangChain 中的BaseTool抽象类、OpenAI Function Call 的函数定义规范 |
OpenClaw 内置的browser_control技能、message_send技能、开发者自定义的业务技能 |
| 二者关联 | Tool 是 Skill 的上层抽象,定义了统一的调用规范 | 一个 Skill 可被封装为符合框架规范的 Tool,供 Agent 的决策层调用 |
2.3 工程化 Skill 的伪代码实现
以下伪代码贴合 OpenClaw 官方的 Skill 设计规范与 TypeScript 技术栈,展示了一个生产可用的 Skill 完整封装逻辑:
// Skill抽象基类,定义标准化的接口规范
export abstract class BaseSkill {
// 技能唯一标识,用于Agent调用时的定位
abstract get name(): string;
// 供LLM阅读的功能描述,直接决定LLM是否会调用该技能
abstract get description(): string;
// 标准化的输入参数Schema,符合JSON Schema规范,用于LLM生成调用参数
abstract get argsSchema(): Record<string, any>;
// 技能的核心执行逻辑
abstract execute(args: Record<string, any>): Promise<string>;
}
// 具体Skill实现:多渠道消息发送技能(贴合OpenClaw的核心多渠道能力)
export class MessageSendSkill extends BaseSkill {
get name(): string {
return "message_send";
}
get description(): string {
return "向指定渠道的联系人或群组发送文本消息,支持WhatsApp、Telegram、飞书、Slack、Discord主流通信渠道";
}
get argsSchema(): Record<string, any> {
return {
type: "object",
properties: {
channel: {
type: "string",
description: "消息发送渠道,可选值:whatsapp、telegram、feishu、slack、discord",
enum: ["whatsapp", "telegram", "feishu", "slack", "discord"]
},
target: {
type: "string",
description: "消息接收方标识,如手机号、用户ID、群组ID"
},
content: {
type: "string",
description: "需要发送的消息文本内容"
}
},
required: ["channel", "target", "content"]
};
}
async execute(args: Record<string, any>): Promise<string> {
const { channel, target, content } = args;
try {
// 1. 内置参数合法性校验,对LLM透明
this.validateArgs(args);
// 2. 对接底层渠道客户端执行发送操作
const channelClient = await this.getChannelClient(channel);
const sendResult = await channelClient.sendMessage(target, content);
// 3. 格式化返回结果,适配LLM的理解与后续推理
return `消息发送成功,渠道:${channel},接收方:${target},消息ID:${sendResult.messageId}`;
} catch (error) {
// 4. 标准化异常处理,返回LLM可理解的错误信息,辅助其修正调用方式
return `消息发送失败,错误原因:${error.message},请检查参数是否符合规范后重试`;
}
}
// 内部辅助方法,对LLM与Agent完全透明
private validateArgs(args: Record<string, any>): void {
// 实现参数合法性校验逻辑
}
private async getChannelClient(channel: string): Promise<any> {
// 对接OpenClaw Gateway的渠道管理模块,获取对应渠道的客户端实例
}
}
当 Agent 的 Skill 数量越来越多,来源越来越分散 —— 有的是本地封装的业务函数,有的是远程服务提供的能力,有的是跨设备的硬件操作接口,新的问题就会出现:不同 Skill 的接口规范不统一,集成需要编写大量重复的适配代码,Agent 无法动态发现可用的能力,这个集成碎片化的难题,该如何解决?这正是 MCP 协议的核心价值所在。
三、MCP:Agent 生态的标准化通信桥梁
在 Agent 的规模化落地中,异构能力的集成是核心痛点之一。不同框架、不同服务、不同设备提供的 Skill,接口规范、通信方式各不相同,开发者需要为每一个 Skill 编写单独的适配代码,开发与维护成本极高。而 MCP 协议的出现,正是为了解决这一行业共性问题。
3.1 MCP 的核心定义与定位
MCP 全称Model Context Protocol(模型上下文协议),是由 Anthropic 提出的开放标准化通信协议,它的定位是 Agent 生态的 “通用 USB 协议”。MCP 本身不提供任何具体的功能实现,而是定义了一套 Agent 与外部工具、服务、设备之间的标准化通信规则,让不同来源、不同类型的 Skill,都能通过统一的方式被 Agent 发现、调用与管理。
3.2 MCP 解决的三大核心痛点
- 动态能力发现:Agent 无需硬编码 Skill 列表,可在运行时通过 MCP 协议自动发现当前可用的所有 Skill,包括其功能描述、参数规范,无需重启服务或重新开发;
- 标准化交互流程:定义了统一的 “工具列表查询 - 工具调用 - 结果返回” 通信格式,无论 Skill 是本地函数、远程微服务,还是跨设备的硬件能力,Agent 的调用方式完全一致;
- 跨平台互操作性:打破了不同框架、不同系统之间的壁垒,比如基于 LangChain 开发的 Agent,可通过 MCP 协议直接调用 OpenClaw 的所有内置 Skill,无需单独做接口适配。
3.3 基于 MCP 的 Skill 调用伪代码实现
以下伪代码实现了 MCP 客户端的核心逻辑,以及 Agent 如何通过 MCP 协议完成异构 Skill 的统一调用,清晰体现其标准化能力:
import json
import asyncio
import websockets
class MCPClient:
"""MCP协议客户端实现,适配OpenClaw Gateway的WS通信规范"""
def __init__(self, gateway_url: str = "ws://127.0.0.1:18789"):
self.gateway_url = gateway_url
self.websocket = None
self.available_tools = {} # 存储动态发现的Skill列表
async def connect(self):
"""建立与MCP服务端的连接,动态发现所有可用Skill"""
self.websocket = await websockets.connect(self.gateway_url)
# 1. 按照MCP协议规范,发送工具列表查询请求
list_request = {
"jsonrpc": "2.0",
"id": 1,
"method": "tools/list"
}
await self.websocket.send(json.dumps(list_request))
# 2. 接收并解析可用Skill列表,完成动态发现
response = await self.websocket.recv()
tool_list = json.loads(response)
for tool in tool_list["result"]["tools"]:
self.available_tools[tool["name"]] = tool
print(f"通过MCP协议成功发现{len(self.available_tools)}个可用Skill")
async def call_tool(self, tool_name: str, arguments: dict) -> str:
"""通过MCP协议标准化调用Skill,无需关注Skill的底层实现与部署位置"""
if tool_name not in self.available_tools:
raise ValueError(f"Skill {tool_name} 未在MCP服务端中发现")
# 按照MCP标准格式,构造工具调用请求
call_request = {
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": {
"name": tool_name,
"arguments": arguments
}
}
await self.websocket.send(json.dumps(call_request))
response = await self.websocket.recv()
result = json.loads(response)
# 标准化返回结果,统一成功与异常场景的输出格式
if "error" in result:
return f"Skill调用失败:{result['error']['message']}"
return result["result"]["content"]
# ======================
# 集成MCP能力的Agent实现
# ======================
class MCPEnabledAgent(BaseAgent):
def __init__(self, llm, memory_module, mcp_client: MCPClient):
super().__init__(llm, memory_module, None)
self.mcp_client = mcp_client
# 将MCP发现的Skill规范同步给LLM,用于工具调用决策
self.llm.bind_tools(mcp_client.available_tools.values())
async def run(self, user_query):
# 重写工具执行逻辑,通过MCP协议完成统一的Skill调用
self.memory.add_message(role="user", content=user_query)
task_completed = False
final_result = None
while not task_completed:
context = self.memory.get_full_context()
thought = self.llm.generate_reasoning(context)
if thought["action_type"] == "finish":
task_completed = True
final_result = thought["content"]
elif thought["action_type"] == "tool_call":
# 无需关注Skill的底层实现,统一通过MCP调用
execution_result = await self.mcp_client.call_tool(
tool_name=thought["tool_name"],
arguments=thought["parameters"]
)
self.memory.add_message(role="system", content=execution_result)
return final_result
3.4 高频认知误区澄清
- 误区 1:MCP 是一个工具管理框架,和 LangChain 的功能重叠,二者二选一即可纠正:MCP 是通信协议标准,而非开发框架;LangChain 是 Agent 开发框架,二者是互补关系,而非竞争关系。基于 LangChain 开发的 Agent,可通过集成 MCP 协议,快速对接海量异构 Skill,大幅扩展自身的能力边界。
- 误区 2:MCP 只能用于工具调用,场景非常局限纠正:工具调用是 MCP 最核心的应用场景,但协议本身还支持上下文同步、事件推送、状态同步等能力,可实现 Agent 与多端设备、多服务之间的复杂交互,应用场景具备极强的扩展性。
解决了 Agent 的执行能力与标准化调用问题,下一个影响 Agent 落地效果的核心问题就会凸显:LLM 存在训练数据截止、专业知识不足、容易产生幻觉的缺陷,这些问题会直接导致 Agent 的任务规划错误、Skill 调用参数错误,如何为 Agent 的决策提供可靠的知识支撑?这就是 RAG 技术的核心定位。
四、RAG:Agent 决策与执行的知识增强引擎
Agent 的核心是决策,而准确的决策必须依赖可靠的知识支撑。LLM 的原生知识存在三大天然缺陷:训练数据有明确的截止日期,无法获取实时信息;无法覆盖企业内部的私有业务知识;在专业领域容易产生幻觉,输出错误信息。而 RAG 技术,正是为了解决这些问题而生。
4.1 RAG 的核心定义与在 Agent 体系中的定位
RAG 全称Retrieval-Augmented Generation(检索增强生成),是一套 “先检索外部知识库,再将检索到的相关知识注入 LLM 上下文,最终生成更准确结果” 的技术方案。
RAG核心流程示意图(引用自《Retrieval-Augmented Generation for Large Language Models》论文):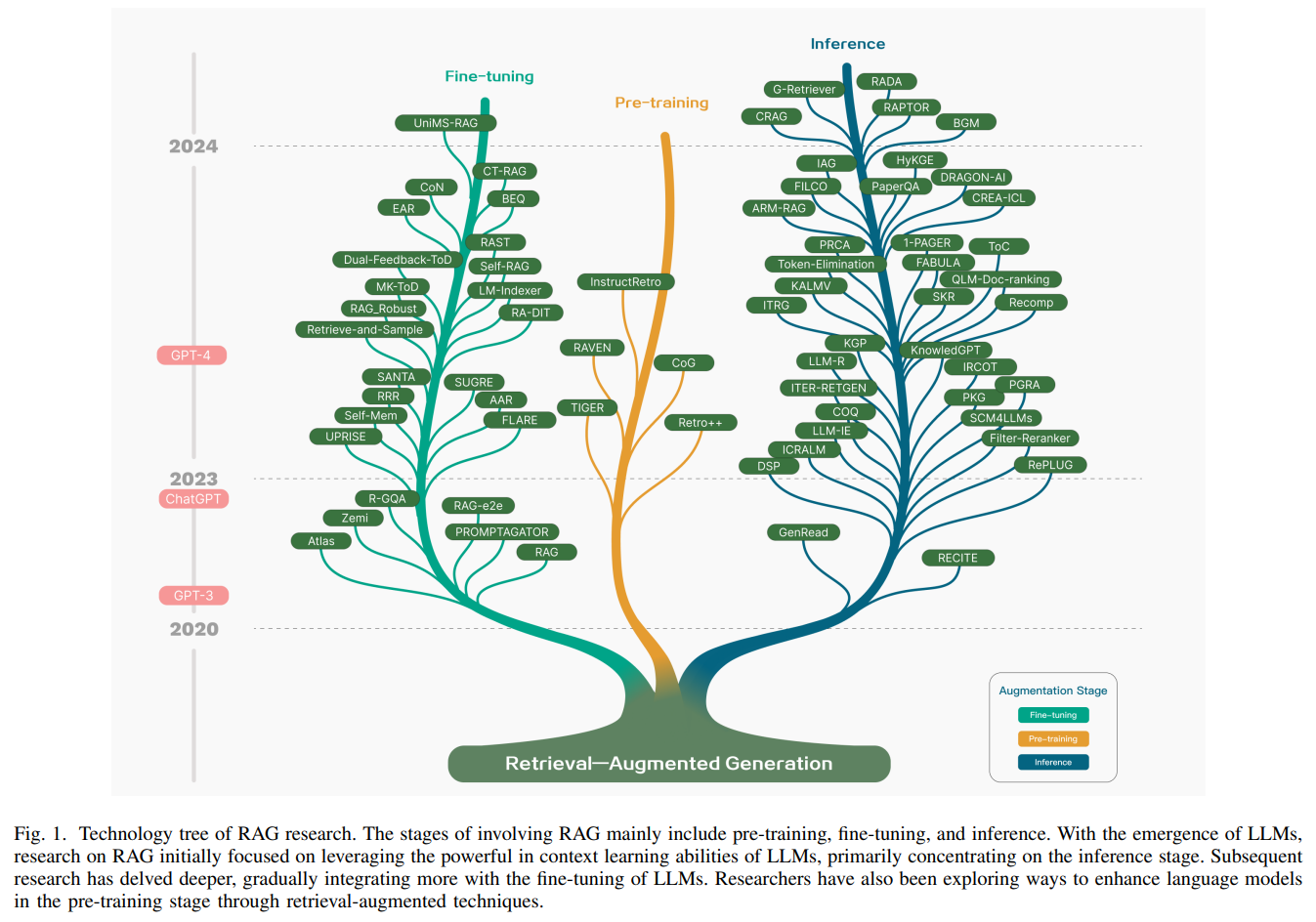
在 Agent 体系中,RAG 的定位是Agent 的长期记忆模块与决策增强引擎,而非一个独立的 Skill。它贯穿于 Agent 的全执行流程,为任务的规划、决策、执行、校验全环节提供可靠的知识支撑。
具体来说,RAG 在 Agent 中起到两个不可替代的核心作用:
- 优化任务规划与决策:为 LLM 提供专业领域知识、业务规则、历史执行经验,避免因知识缺失导致的任务拆解错误、决策方向偏离,从源头提升 Agent 的任务完成率;
- 辅助 Skill 的精准调用:提供 Skill 的使用规范、参数约束、异常处理方案、最佳实践,减少 LLM 的工具调用错误,降低执行异常的概率。
4.2 RAG 与 Agent 深度集成的伪代码实现
以下伪代码展示了如何将 RAG 引擎嵌入 Agent 的核心执行循环,在决策前完成知识检索与上下文增强,从根源上提升 Agent 的执行效果:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
class RAGEngine:
"""RAG检索引擎,为Agent提供知识增强能力"""
def __init__(self, embedding_model, vector_db_path: str):
self.embeddings = embedding_model
# 初始化向量数据库,存储业务知识库、工具规范、历史经验等
self.vector_db = Chroma(
persist_directory=vector_db_path,
embedding_function=self.embeddings
)
def retrieve_relevant_knowledge(self, query: str, top_k: int = 3) -> str:
"""检索与当前任务相关的知识,格式化为LLM易读的上下文"""
docs = self.vector_db.similarity_search(query, k=top_k)
if not docs:
return "无相关检索知识"
# 格式化检索结果,降低LLM的理解成本
formatted_context = "\n\n".join([
f"【相关知识{i+1}】:{doc.page_content}"
for i, doc in enumerate(docs)
])
return formatted_context
# ======================
# 集成RAG的增强型Agent
# ======================
class RAGEnhancedAgent(BaseAgent):
def __init__(self, llm, memory_module, tool_manager, rag_engine: RAGEngine):
super().__init__(llm, memory_module, tool_manager)
self.rag_engine = rag_engine
def run(self, user_query):
# 1. 任务启动前,先检索相关知识,为后续决策提供支撑
relevant_knowledge = self.rag_engine.retrieve_relevant_knowledge(user_query)
# 2. 将检索到的知识注入记忆模块,供LLM全程推理使用
self.memory.add_message(
role="system",
content=f"参考知识库信息:\n{relevant_knowledge}"
)
self.memory.add_message(role="user", content=user_query)
# 3. 核心执行闭环,LLM可基于增强后的上下文完成精准决策
task_completed = False
final_result = None
while not task_completed:
context = self.memory.get_full_context()
thought = self.llm.generate_reasoning(context)
if thought["action_type"] == "finish":
task_completed = True
final_result = thought["content"]
self.memory.add_message(role="assistant", content=final_result)
elif thought["action_type"] == "tool_call":
tool_name = thought["tool_name"]
tool_params = thought["parameters"]
tool = self.tool_manager.get_tool(tool_name)
execution_result = tool.execute(**tool_params)
self.memory.add_message(
role="system",
content=f"工具{tool_name}执行结果:{execution_result}"
)
return final_result
4.3 高频认知误区澄清
- 误区 1:RAG 和模型微调都能给 LLM 补充知识,二者可以互相替代纠正:二者是互补关系,而非替代关系,适用场景与核心能力完全不同,核心对比如下:
| 对比维度 | RAG | 模型微调 |
|---|---|---|
| 知识存储方式 | 存储在外部知识库,与模型完全解耦 | 写入模型权重,与模型深度绑定 |
| 知识更新成本 | 极低,新增知识直接存入知识库即可实时生效 | 高,需要准备训练数据、重新训练模型,周期长、算力成本高 |
| 幻觉控制能力 | 强,所有生成内容可溯源到知识库原文,能有效减少幻觉 | 弱,无法完全消除幻觉,且可能出现灾难性遗忘问题 |
| 核心适用场景 | 高频更新的业务知识、专业领域知识库、企业内部私有数据、实时性要求高的信息 | 通用能力优化、对话风格对齐、低频更新的基础常识与规则 |
- 误区 2:RAG 只能用于优化最终的文本生成,和 Skill 调用、任务规划无关纠正:RAG 的价值贯穿 Agent 执行的全流程。除了优化文本生成,还可以将业务流程规范、Skill 使用手册、历史异常处理案例存入知识库,Agent 在规划任务、调用工具、处理异常时,都能通过 RAG 获取对应的参考信息,大幅提升任务执行的稳定性与成功率。
现在,我们已经明确了 Agent 的核心逻辑,以及 Skill、MCP、RAG 这些核心组件的作用。但如果从零开始,把这些组件手动拼接成一个可用的 Agent 系统,需要编写大量的胶水代码,处理各种边界情况,开发与维护成本极高。有没有成熟的框架,能帮我们简化这个过程?这就是 LangChain 的核心价值。
五、LangChain:Agent 开发的编排框架与工程化脚手架
LangChain 是目前全球最主流的 LLM 应用与 Agent 开发开源框架,它的定位从来都不是 Agent 本身,而是Agent 开发的工程化脚手架与编排框架。它将 Agent 开发中的通用能力进行了标准化封装,让开发者无需从零实现底层逻辑,只需聚焦于业务场景的定制化开发,大幅降低 Agent 的落地门槛。
5.1 LangChain 的三大核心价值
基于 LangChain 官方的定位与工程实践,它的核心价值体现在三个方面:
- 统一的组件抽象:提供了跨模型、跨平台的标准化接口,一套代码可适配 OpenAI、Anthropic、通义千问等主流大模型,可对接 Chroma、Milvus、Pinecone 等主流向量数据库,无需为不同的底层服务编写适配代码;
- 开箱即用的能力封装:内置了成熟的 Agent 执行循环、多类型记忆模块、完整的 RAG 链路、标准化的工具调用逻辑,开发者无需手动实现 ReAct、Self-Ask 等经典 Agent 范式,几行代码就能搭建可用的 Agent;
- 完善的生态集成能力:原生支持 MCP 协议、OpenClaw 等第三方组件,以及数百种第三方工具、服务、平台的集成,大幅减少开发者的适配工作量,让 Agent 能快速对接各类业务系统。
5.2 基于 LangChain 快速组装完整 Agent 的伪代码实现
以下伪代码基于 LangChain 官方 API,快速组装一个集成了 LLM、RAG、MCP Skill 的完整 Agent,直观体现其作为开发框架的核心价值:
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools.retriever import create_retriever_tool
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.tools import Tool
# 1. 初始化核心组件,LangChain已完成底层逻辑的封装
llm = ChatOpenAI(model="gpt-4o", temperature=0)
embeddings = OpenAIEmbeddings()
# 2. 3行代码构建RAG检索能力,LangChain封装了完整的检索链路
vector_db = Chroma(persist_directory="./agent_knowledge", embedding_function=embeddings)
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
# 将RAG检索能力封装为Agent可调用的标准化Tool
rag_tool = create_retriever_tool(
retriever=retriever,
name="knowledge_base_retrieve",
description="用于检索企业内部知识库、业务规则、工具使用规范,当需要专业知识或操作规范时必须调用"
)
# 3. 对接MCP客户端,将OpenClaw的所有Skill一键转换为LangChain可用的Tool
mcp_client = MCPClient("ws://127.0.0.1:18789")
await mcp_client.connect()
# 自动将MCP发现的Skill转换为LangChain标准Tool,无需手动适配
mcp_tools = []
for tool_name, tool_spec in mcp_client.available_tools.items():
async def mcp_tool_wrapper(**kwargs):
return await mcp_client.call_tool(tool_name, kwargs)
mcp_tools.append(Tool(
name=tool_name,
func=mcp_tool_wrapper,
description=tool_spec["description"]
))
# 4. 合并所有可用工具
all_tools = [rag_tool] + mcp_tools
# 5. 定义Agent的提示词模板,LangChain提供了标准化的模板结构
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的智能助手,可调用工具完成用户的复杂任务,必须严格遵循知识库中的规范执行操作。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
# 6. 一行代码创建Agent,内置了完整的推理-执行循环
agent = create_openai_tools_agent(llm, all_tools, prompt)
# 7. 初始化Agent执行器,封装了记忆管理、异常处理、流式输出等能力
agent_executor = AgentExecutor(agent=agent, tools=all_tools, verbose=True)
# 8. 直接执行复杂任务,无需手动编写循环、上下文管理等底层代码
result = agent_executor.invoke({
"input": "检索2026年以来大模型推理优化方向的3篇顶会论文,整理成1500字的技术综述,生成可直接使用的PPT大纲,然后通过飞书把综述和PPT大纲发给算法组同事",
"chat_history": []
})
print(f"任务执行结果:{result['output']}")
5.3 高频认知误区澄清
- 误区 1:用了 LangChain 就是开发了 Agent,LangChain 就是 Agent纠正:LangChain 是开发 Agent 的工具,而非 Agent 本身。Agent 的核心是 “自主决策与执行闭环”,LangChain 只是帮开发者更快、更简单地实现这个闭环;即使不用 LangChain,开发者也可以从零编写代码实现符合业务需求的 Agent。
- 误区 2:LangChain 只能用于开发 Agent,场景非常局限纠正:Agent 开发是 LangChain 的核心应用场景之一,但它的能力不止于此。它也可用于开发非 Agent 的 LLM 应用,比如单纯的 RAG 问答系统、文本摘要工具、多轮对话机器人、翻译工具等,是通用的 LLM 应用开发框架。
LangChain 解决了 Agent 的工程化开发问题,让开发者可以快速组装定制化的 Agent。但对于很多场景,比如个人全渠道 AI 助理,用户并不需要从零开发定制化能力,而是需要一套开箱即用、功能完整的 Agent 系统,这正是近期爆火的 OpenClaw 的核心定位。
六、OpenClaw:开箱即用的全渠道 Agent 完整系统
OpenClaw 是近期开源社区热度极高的项目,很多开发者对它的定位存在模糊认知:它到底是一个 Skill 库?一个 Agent 框架?还是一个完整的产品?我们基于其官方开源仓库的核心定义,做完整的拆解。
6.1 OpenClaw 的核心定位
根据 OpenClaw 官方仓库的定义,它是一套本地优先、可自托管、全渠道覆盖的个人 AI 助理完整系统,而非单一的工具库或开发框架。它本身就内置了 Agent 运行所需的全套组件,是一个可直接安装、开箱即用的 Agent 产品,同时也可作为能力组件,融入企业级的 Agent 生态中。
6.2 OpenClaw 的核心架构拆解
基于官方仓库的架构说明,OpenClaw 的核心由五大模块组成,完整覆盖了 Agent 系统的全链路能力:
- Gateway 控制平面:整个系统的核心中枢,基于 WebSocket 的统一控制平面,管理会话、渠道、工具、事件,是所有能力的调度中心,同时也是 MCP 协议的服务端载体;
- 多渠道接入层:原生支持 WhatsApp、Telegram、飞书、Slack、微信等 20 + 主流通信渠道,实现一处部署、全渠道响应,这也是其最核心的特色能力之一;
- Pi Agent Runtime:内置的 Agent 运行时,支持工具流式调用、多轮推理、多档位思考模式调节,是 OpenClaw 的 Agent 决策核心;
- Skill 体系:完整的技能管理平台,内置浏览器控制、设备操作、定时任务、邮件处理等基础 Skill,支持开发者自定义 Skill,同时对接 ClawHub 社区技能仓库,可一键扩展能力;
- 多端节点能力:支持 macOS、iOS、Android 设备作为节点接入,提供摄像头、屏幕录制、系统命令、地理位置等设备级能力,实现跨设备的 Agent 执行。
6.3 OpenClaw 与其他核心组件的关系
根据不同的使用场景,OpenClaw 与其他组件的关系可分为两种模式:
-
作为独立的完整 Agent 系统使用这是 OpenClaw 的核心使用场景。它本身就是一个开箱即用的完整 Agent 产品,内置了 Agent runtime、Skill 体系、多渠道接入、记忆管理等所有核心能力。开发者无需依赖 LangChain 等开发框架,只需通过引导向导完成基础配置,再通过少量自定义 Skill 扩展个性化能力,就能搭建专属的个人 AI 助理。
官方推荐的基础安装与使用命令如下:
# 1. 安装OpenClaw(需Node ≥22环境) npm install -g openclaw@latest # 2. 运行引导向导,完成Gateway、渠道、模型的配置,自动安装守护进程 openclaw onboard --install-daemon # 3. 启动Gateway服务,默认监听127.0.0.1:18789 openclaw gateway --port 18789 --verbose # 4. 直接通过CLI调用Agent执行任务 openclaw agent --message "帮我整理本周的邮件,生成待办清单" --thinking high -
作为 Agent 生态的组件,融入现有系统OpenClaw 也可作为能力模块,与其他组件协同工作:
- 作为Skill 提供方:通过 Gateway 的 MCP 兼容接口,为基于 LangChain 开发的外部 Agent,提供丰富的内置 Skill、多渠道接入能力、多端设备操作能力;
- 作为Agent 运行载体:将基于 LangChain 开发的业务逻辑,封装为 OpenClaw 的自定义 Skill,复用其 Gateway、多渠道管理、节点调度等成熟能力;
- 与 RAG 结合:通过自定义 Skill 集成外部 RAG 引擎,为其内置 Agent 补充专业领域知识,拓展业务场景适配能力。
6.4 OpenClaw 自定义 Skill 开发示例
以下是贴合 OpenClaw 规范的自定义 Skill 开发示例,开发者可通过这种方式,快速扩展 OpenClaw 的业务能力:
// OpenClaw自定义Skill开发示例:周报生成Skill
import { BaseSkill } from "@openclaw/core";
export class WeeklyReportSkill extends BaseSkill {
get name(): string {
return "weekly_report_generate";
}
get description(): string {
return "基于用户的工作邮件、会议记录,生成标准化的个人周报";
}
get argsSchema(): Record<string, any> {
return {
type: "object",
properties: {
week: {
type: "string",
description: "周报所属周期,格式为YYYY-MM-DD至YYYY-MM-DD"
},
focus: {
type: "string",
description: "周报的重点内容方向,非必填"
}
},
required: ["week"]
};
}
async execute(args: Record<string, any>): Promise<string> {
try {
// 1. 调用OpenClaw内置的邮件Skill,获取对应周期的工作邮件
const emailSkill = this.context.getSkill("email_retrieve");
const emails = await emailSkill.execute({
date_range: args.week,
folder: "INBOX"
});
// 2. 调用系统内置的LLM生成周报内容
const llm = this.context.llm;
const report = await llm.generate({
prompt: `基于以下工作邮件内容,生成一份结构完整的个人周报,重点关注${args.focus || "核心工作进展、问题与后续计划"}:\n${emails}`
});
// 3. 返回标准化结果
return `周报生成完成,内容如下:\n${report.content}`;
} catch (error) {
return `周报生成失败,错误原因:${error.message}`;
}
}
}
6.5 高频认知误区澄清
- 误区 1:OpenClaw 只是一个 Skill 库,只能提供零散的工具能力纠正:Skill 体系只是 OpenClaw 的一部分,它是一个完整的、可独立运行的 Agent 系统,包含了从 Gateway 控制平面、Agent runtime、多渠道接入到多端设备管理的全链路能力,而非单纯的 Skill 集合。
- 误区 2:OpenClaw 和 LangChain 是竞争关系,开发时只能二选一纠正:二者的核心定位不同,是互补关系,而非竞争关系。LangChain 是通用的 Agent 开发框架,适合定制化开发复杂的业务 Agent;OpenClaw 是开箱即用的个人 AI 助理系统,适合快速搭建全渠道的个人助理场景。二者可深度集成,比如用 LangChain 开发业务专属的 Skill,再集成到 OpenClaw 中,复用其全渠道与多端能力。
七、全链路协同:复杂任务中的组件配合闭环
前面我们已经逐层拆解了每个组件的本质、定位与实现逻辑,现在我们通过一个真实的复杂业务任务,完整拆解全流程中各个组件的协同工作流程,让抽象的技术概念落地为具象的执行步骤,建立完整的 Agent 生态认知。
示例任务
用户需求:帮我检索 2026 年以来大模型推理优化方向的 3 篇顶会论文,整理成 1500 字的技术综述,生成可直接使用的 PPT 大纲,然后通过飞书把综述和 PPT 大纲发给算法组的同事。
全流程组件协同闭环
-
任务接收与初始化
- 用户通过 OpenClaw 接入的飞书渠道发送需求,OpenClaw 的 Gateway 接收消息,创建专属会话,初始化内置的 Agent Runtime 与记忆模块;
- Agent 的 LLM 核心理解用户需求,拆解为 5 个核心子任务:① 顶会论文检索;② 技术综述生成;③ PPT 大纲生成;④ 飞书文件发送;⑤ 任务结果校验。
-
知识检索与能力确认
- Agent 调用 RAG 引擎,检索顶会论文检索渠道的使用规范、技术综述的写作要求、飞书文件发送的 Skill 参数规范,为后续的决策与工具调用提供知识支撑;
- 同时,Agent 通过 MCP 协议,确认当前可用的 Skill 列表:学术论文检索 Skill、文档生成 Skill、PPT 大纲生成 Skill、飞书消息与文件发送 Skill,获取每个 Skill 的调用规范。
-
分步执行与反馈闭环
- 第一步:调用学术论文检索 Skill,获取 2026 年以来符合要求的 3 篇顶会论文的核心内容与摘要,将执行结果写入会话记忆,供后续生成使用;
- 第二步:LLM 基于检索到的论文内容,结合 RAG 获取的综述写作规范,生成 1500 字的技术综述,将生成结果写入记忆;
- 第三步:调用 PPT 大纲生成 Skill,基于综述内容生成标准化的 PPT 大纲,返回执行结果给 Agent;
- 第四步:调用飞书文件发送 Skill,将技术综述与 PPT 大纲作为附件,发送给算法组的指定群组,获取发送成功的回执信息。
-
结果校验与最终输出
- Agent 校验所有子任务的执行结果,确认全部完成且符合用户需求后,整理最终的执行反馈,通过 OpenClaw 的飞书渠道返回给用户,完成整个任务的闭环。
-
工程化支撑
- 整个流程中,LangChain 可用于快速开发自定义的论文检索、PPT 大纲生成 Skill,集成到 OpenClaw 的 Skill 体系中;
- MCP 协议实现了不同来源 Skill 的统一调用,无需为每个 Skill 单独开发适配代码;
- RAG 为内容生成与工具调用提供了可靠的知识支撑,有效减少幻觉与工具调用错误。
八、场景化选型建议与核心总结
8.1 核心组件层级关系总结
通过前文的逐层拆解,我们可以清晰梳理出 Agent 生态各组件的层级定位,从核心到外围可分为 5 个层级,每个层级各司其职,共同构成完整的 Agent 生态:
- 核心主体层:Agent,是整个系统的决策核心,所有其他组件都是为其服务的配套能力;
- 能力支撑层:Skill(执行能力)、RAG(知识能力),是 Agent 完成任务的核心支撑,分别解决 “怎么做” 和 “知道什么” 的问题;
- 协议标准层:MCP,是 Agent 与各类能力组件之间的标准化通信桥梁,解决异构能力的集成难题;
- 开发框架层:LangChain,是 Agent 开发的工程化脚手架,降低组件组装与定制化开发的门槛;
- 产品系统层:OpenClaw,是开箱即用的完整 Agent 系统,可独立部署使用,也可作为能力组件融入更大的生态。
8.2 高频认知误区汇总
这里我们汇总了 Agent 开发中最常见的认知误区,帮助开发者避开选型与开发中的坑:
- 混淆组件层级:把开发框架(LangChain)、通信协议(MCP)等同于 Agent 本身,忽略了 Agent 的核心是决策与执行闭环;
- 混淆抽象与实现:把 Tool 的接口定义规范,等同于 Skill 的具体业务功能实现,导致概念模糊、架构设计混乱;
- 混淆互补与替代:认为 RAG 与模型微调、LangChain 与 OpenClaw 是二选一的竞争关系,忽略了二者的互补价值与不同的适用场景;
- 混淆核心与附属:把 LLM 等同于 Agent,忽略了记忆、工具、反馈闭环对于智能体的核心价值,导致开发的 Agent 能力受限。
8.3 场景化选型建议
针对不同的业务场景与开发需求,我们给出对应的组件选型建议,避免过度设计或能力不足:
- 个人全渠道 AI 助理场景优先直接使用 OpenClaw,开箱即用,无需从零开发系统架构,通过简单的配置即可实现全渠道接入,通过自定义 Skill 快速扩展个性化能力,成本最低、落地最快。
- 企业级定制化业务 Agent 开发基于 LangChain 框架搭建核心架构,通过 MCP 协议对接各类异构工具与业务系统,基于 RAG 构建企业内部知识库,快速实现业务需求的定制化开发,同时保证系统的扩展性与可维护性。
- 多设备 / 多端协同的 Agent 场景以 OpenClaw 的 Gateway 为核心控制平面,复用其成熟的多端节点管理、设备能力接入能力,通过 LangChain 开发业务专属的 Agent 逻辑与自定义 Skill,兼顾系统成熟度与业务定制化需求。
- 轻量工具调用场景对于仅需单轮或少量工具调用的简单场景,无需引入复杂的框架与系统,直接基于 LLM 的 Function Call 能力,封装轻量的 Skill 即可实现,避免过度设计带来的维护成本。
最终总结
Agent 生态的核心逻辑,是 “以 LLM 为决策核心,通过标准化协议(MCP)整合原子执行能力(Skill)与外部知识(RAG),借助开发框架(LangChain)或成熟系统(OpenClaw)快速落地的智能闭环”。
理解每个组件的本质定位与边界,厘清它们之间的协同关系,不仅能帮助开发者避开认知误区,更能根据业务场景选择合适的技术方案,高效、稳定地落地 Agent 应用。随着 Agent 技术的持续发展,组件的标准化与协同性会进一步提升,但这套 “主体 - 能力 - 协议 - 框架” 的核心逻辑,仍将是 Agent 技术落地的核心框架。
参考文献
[1] OpenClaw Official Repository: https://github.com/openclaw/openclaw
[2] LangChain Official Website & Documentation: https://www.langchain.com/
[3] Model Context Protocol (MCP) : https://modelcontextprotocol.io/docs/getting-started/intro
[4] Yao S, Zhao J, Yu D, et al. ReAct: Synergizing Reasoning and Acting in Language Models[J]. International Conference on Learning Representations, 2023.
[5] Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)