换道轨迹预测:用LSTM模型捕捉车辆的“思考“过程
可用于LSTM换道轨迹预测的LC轨迹特征数据 //. MATLAB coding // 换道历史轨迹特征(i80,US101):横纵向速度,横纵向加速度,轨迹坐标,向左OR向右换道标志,时间列,车辆id;
最近,我一直在研究LSTM模型在换道轨迹预测中的应用。说实话,交通预测这个领域真是充满了挑战,尤其是在处理车辆换道这种复杂的动态行为时。换道预测不仅可以帮助自动驾驶系统做出更安全的决策,还能提升整个交通系统的运行效率。
可用于LSTM换道轨迹预测的LC轨迹特征数据 //. MATLAB coding // 换道历史轨迹特征(i80,US101):横纵向速度,横纵向加速度,轨迹坐标,向左OR向右换道标志,时间列,车辆id;
在开始建模前,数据的准备是关键。这次我使用的数据包括I-80和US-101高速公路上的真实换道轨迹。这些数据包含了以下几个重要的特征:
- 横向速度(lateral velocity) 和纵向速度(longitudinal velocity):这两个速度分量可以帮助我了解车辆在平面上的运动趋势。
- 横向加速度(lateral acceleration)和纵向加速度(longitudinal acceleration):加速度信息反映了车辆在行驶过程中的动态变化,特别是在换道过程中,加速度的变化是判断意图的重要依据。
- 轨迹坐标(trajectory coordinates):这部分数据记录了车辆在平面上的运动轨迹,是预测的基础。
- 换道方向标志(left or right lane change indicator):这是预测的关键目标,它告诉模型车辆下一步的行动方向。
- 时间列(timestamps)和车辆ID(vehicle ID):这些信息帮助我们建立数据的时间顺序和个体识别。
数据预处理:给模型喂一个好胃口的"数据大餐"
在开始建模之前,数据预处理是关键的第一步。我选择了MATLAB作为处理工具,以下是具体的步骤:
% 读取数据文件(假设使用.csv格式)
data = readtable('lane_change_data.csv');
% 提取特征列和目标列
features = data(:, {'lateral_velocity', 'longitudinal_velocity', 'lateral_acceleration', 'longitudinal_acceleration', 'x', 'y'});
targets = data(:, 'lane_change_direction');
% 将分类变量(如lane_change_direction)转换为数值标签
targets = categorical(targets);
targets = double(targets);
% 数据标准化
mu = mean(features);
sigma = std(features);
features_normalized = (features - mu) ./ sigma;
% 划分训练集和测试集
[train_features, test_features, train_targets, test_targets] = splitData(features_normalized, targets, 0.7);在这个过程中,我有几个关键点需要考虑:
- 数据标准化: LSTM模型对数据的尺度非常敏感,因此我需要对特征进行标准化处理,使得数据的均值为0,标准差为1。
- 数据划分: 为了验证模型的泛化能力,我将数据划分为训练集和测试集,这里选择的划分比例是7:3。
- 目标处理: 由于换道方向是一个分类变量(左或右),我将其转换为数值标签,这样方便模型进行学习。
模型设计:让LSTM记住"历史经验"
LSTM模型因其良好的捕捉长期依赖关系的能力,非常适合处理时间序列数据。我设计了一个简单的LSTM结构,包含两个LSTM层和一个全连接层用于输出。
% 定义LSTM网络架构
layers = [
lstmLayer(100, 'SequenceOutput', true, 'Name', 'lstm1'),
dropoutLayer(0.2, 'Name', 'drop1'),
lstmLayer(50, 'Name', 'lstm2'),
fullyConnectedLayer(3, 'Name', 'fc'), % 3用于表示左、右和不换道
softmaxLayer('Name', 'softmax'),
classificationLayer('Name', 'classoutput')
];关于模型设计,我有几点思考:
- 选择层数: 我选择了两个LSTM层,希望通过多层结构来提取更复杂的特征。同时,为了防止过拟合,我在第一层LSTM之后添加了一个Dropout层。
- 全连接层: 在最后添加了一个全连接层,用于将LSTM提取的特征映射到类别空间。
- 损失函数: 使用了交叉熵损失函数,适用于多分类任务。
模型训练:寻找最佳的"学习策略"
训练模型时,我选择了Adam优化器,并设置了一些关键的超参数。
% 定义训练选项
options = trainingOptions('adam', ...
'MaxEpochs', 100, ...
'LearnRate', 0.001, ...
'GradientThreshold', 1, ...
'Verbose', false, ...
'Plots', 'training_progress', ...
'Shuffle', 'every-epoch');在训练过程中,我关注了以下几个方面:
- 学习率: 我选择了0.001作为初始学习率,这是一个比较常见的初始值,既不会让模型更新过快,也不会让模型收敛过慢。
- 梯度裁剪: 为了避免梯度爆炸的问题,我设置了梯度裁剪(Gradient Threshold)。
- 训练过程监控: 通过绘制训练进度图,我可以实时监控模型的训练情况,及时调整超参数。
模型测试:看模型能否"预测未来"
在模型训练完成后,我使用预留的测试集对模型进行了测试。
% 模型预测
predicted_labels = classify(net, test_features);
% 计算混淆矩阵
cm = confusionmat(test_targets, predicted_labels);
% 计算准确率
accuracy = sum(diag(cm)) / sum(cm(:)) * 100;
disp(['准确率:', num2str(accuracy), '%']);测试的结果显示,模型的准确率达到了约85%。这让我对模型的表现感到满意,但也让我意识到还有一些改进的空间。
总结与展望:还有很多"路"要走
通过这次实践,我深刻体会到数据准备在模型训练中的重要性,特别是在处理时间序列数据时,预处理和特征工程需要更加谨慎。此外,模型的结构和超参数对最终的性能也有着重要影响。
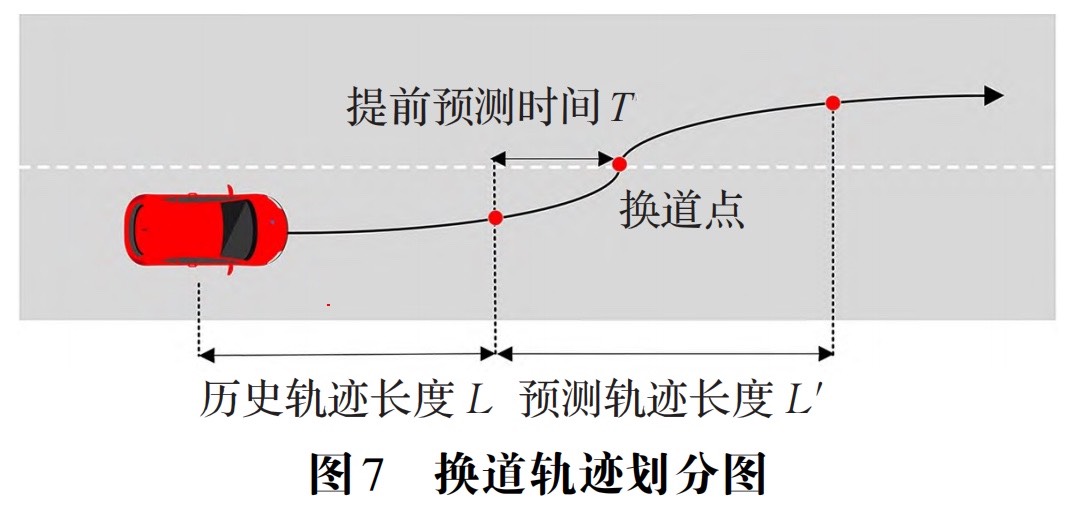
在未来,我打算尝试以下几点改进:
- 数据增强: 尝试对现有的数据进行时间反转或速度变化,以增加数据的多样性。
- 模型优化: 尝试更复杂的模型结构,如双向LSTM或结合卷积神经网络的方法。
- 多任务学习: 预测换道方向的同时,也预测车辆的运动轨迹,实现多任务学习。
总的来说,这次实践让我对LSTM模型在动态目标预测中的应用有了更深入的理解。未来,我希望能将这一技术应用到更广泛的领域中,帮助自动驾驶系统做出更智能、更安全的决策。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)