AI时代下企业数智化转型的思考与实践之3-2 建模派
导言
从记录系统到数字孪生系统的高纬度升级。也可称为数字孪生派。
| 骨架 | ERP | 规则基础 | 把SAP Hard coding的业务规则喂给AI? |
| 头脑 | 知识管理 | 事实基础 | 本体,OAG式决策节点和What-If沙盘模拟,支持决策逻辑和分析模型 |
| 手脚 | 专业外围系统 | 工具 | 触发对应系统操作,Ontology |
| API | |||
| 神经 | AI/Agent/Skill | 主体 | 基础能力 |
| 血液 | 业务流程 | 主体运行主要方式 | 多个智能体串联成工作流,通过共享本体上下文实现松耦合协作 |
Palantir产品体系
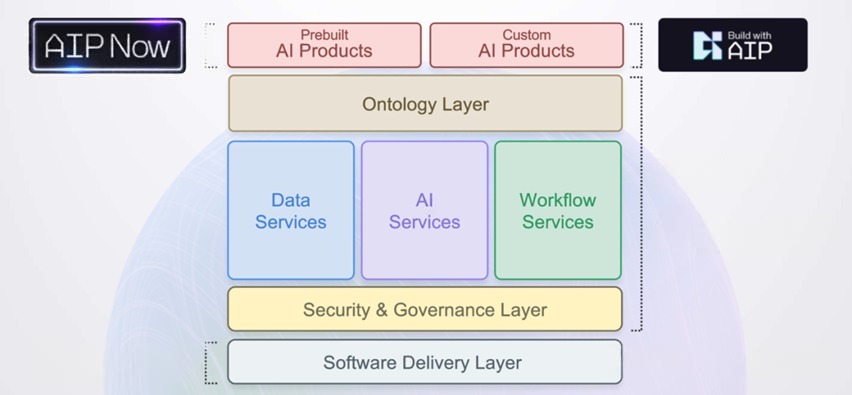
Foundry是底层通用操作系统,是Palantir的核心产品,它通过将数据从不同的系统中提取并整合,创建一个统一的数据平台。
Apollo则是Palantir的运营平台,提供自动化的数据处理和管理功能,更像DevOps交付层。
AIP(AI运营平台)则专注于AI的集成和应用,
思想
通过对象/属性/关系/行动的抽象,对现实世界进行有效抽象建模
以前是手工建模+人看(两层皮),现在是AI辅助建模+驱动AI (虚实结合)
在传统企业信息化中,ERP 等应用是核心,以流程为轴心,把业务固化为系统操作,数据只是随之沉淀的副产品,用于事后统计和审计,本质是“系统先于数据”
Palantir 则把数据提升为一等公民,成为组织的“操作对象”和“统一语境”,而应用只是数据的投影与使用方式。Palantir 将数据构造成跨部门、跨系统的统一底层,应用则像插件挂载其上。
将抽象的数据与真实业务场景深度结合,让用户获得类似“作战地图”的全局视角,可以像在沙盘上推演一样制定作战计划,供应链管理者则能如同观察神经网络般实时追踪订单、库存与运输节点的变化。
核心价值在于将数据分析与决策执行深度耦合,并直接下沉到一线作业场景,实现“数据—决策—行动”的闭环(企业统一大脑)
问题:1,规则管控:是一个外挂辅助工具,还是内置到本体定义中? 2,行动 除了工作流,还有其他实现方式吗?
Palantir 用“操作系统”来描述自己——它像是组织的数据内核,外接各种“设备驱动”(业务系统、数据库、API),然后在统一环境里运行“应用”(决策工作流、分析模块)
本体
重要思想是构建统一的本体模型(Ontology),对企业的人、事、物和流程及其关系进行标准化定义,让组织内的数据和业务逻辑在语义层面实现真正统一。是AI 时代的动态语境引擎。
Ontology通过语义实体化(Objectification),将异构数据源(ERP、CRM、传感器、Excel)抽象为对象(Objects),具备物理属性、财务价值和历史记录的“真实实体”
本体模型构建在现有系统之上,把来自不同系统的异构数据映射到统一的业务实体和关系语义中,让数据不仅是表格和字段,而是业务意义明确的对象网络。
这种语义层为跨系统的分析、关联和推理(如订单与运输、库存与生产、故障与维护的实时关联)提供了一个动态连贯的业务图景。
动态本体引擎支持“对象-属性-事件-关系-函数”五元组
Palantir 坚持把数值计算、约束校验放在 Functions,而不是交给大模型
好处
- 高维度建模
- 便于用户理解
- 本质是用低纬度的复杂工程替换高维度能力不足
- 便于大模型使用
限制
高度依赖建模能力和行业理解,不同客户的语义差异大,实施成本高
引申
关系型数据库虽然解决了事务的记录及条件约束问题
但事务发生时更新DB的对象,构建报表时从DB抽取的对象和条件,都是复杂的工程问题。
比如传统系统,信息分散在ERP,TMS,WMS,CRM等不同系统的复数表里。不管是数据更新,还是数据抽取,都要经过复杂的工程,导致系统构建与维护都很笨重。
本体与大模型
Ontology 能够把大量信息重组为语义化、结构化的知识网络,通过时间、关系、事件等维度压缩与语境化,从而为大模型提供高质量的上下文输入
大模型能够基于已有数据快速生成 Ontology 的初始框架或模板,大幅提升知识图谱与指数级图谱的建立效率,让语义层的搭建从“工匠式”转变为“自动化+校准”的范式。
举例
“订单(Order)” Ontology
业务对象(Entities)
- Order(订单):来自 ERP 系统(SAP/Oracle):订单号、客户 ID、产品、数量、价格、状态。
- Shipment(运输批次):来自 TMS 系统:承运商、卡车/司机、起点、终点、预计到达时间。
- Inventory(库存):来自 WMS 系统:仓库位置、可用库存、批次号。
- Sensor(传感器数据):来自 IoT 系统:温度、湿度、GPS、卡车位置。
- Customer(客户):来自 CRM:客户信息、信用等级、合同条款。
关系(Relationships)
Order → Shipment:一个订单可以被分配到多个运输批次(部分发货)。
Order → Inventory:订单关联仓库库存,用于判断是否可发货。
Shipment → Sensor:运输批次与卡车 IoT 数据绑定,用于实时监控。
Order → Customer:订单与客户绑定,支持信用风险控制。
Time Travel
订单状态从 创建 → 已发货 → 在途 → 签收 → 退货,每个变化在 Ontology 里都有版本号
可以回溯“订单 12345 在 2024/07/01 时,绑定的是哪个仓库、哪个司机、哪辆车”
架构
高度集成 —— 地理信息、实时数据、建模、工作流、安全体系在一个平台内无缝协同
安全与权限体系 —— 军事、情报、政府场景造就了极高门槛
直达一线执行 —— 很多产品只能“看”,Palantir 能“推演+执行”

数据处理
支持 时间回溯(Time Travel) 等机制,让用户能够像代码一样追踪、回滚和重现数据全生命周期
数据引入(Ingestion)
Foundry 支持多源数据接入(数据库、API、IoT 流、文件),并在入口就进行权限控制与日志记录。
每条数据的来源、时间戳、转换规则都会被自动记录(即所谓的 lineage 数据血缘)。
引入时可以配置 合规策略(如 GDPR、HIPAA),对敏感字段自动脱敏或加密。
存储(Storage & Modeling)
底层可连接客户已有的存储(Snowflake、S3、HDFS 等),Foundry 作为逻辑层而非“霸占数据”。
数据存储采用多层抽象:原始层(Raw)、清洗层(Refined)、语义层(Ontology)
每层数据都带有 版本控制(类似 Git for Data),保证修改可回溯
使用(Usage & Execution)
数据被用来驱动分析、可视化、建模和工作流
Ontology-augmented generation (OAG),智能体在本体层进行结构化推理
行动
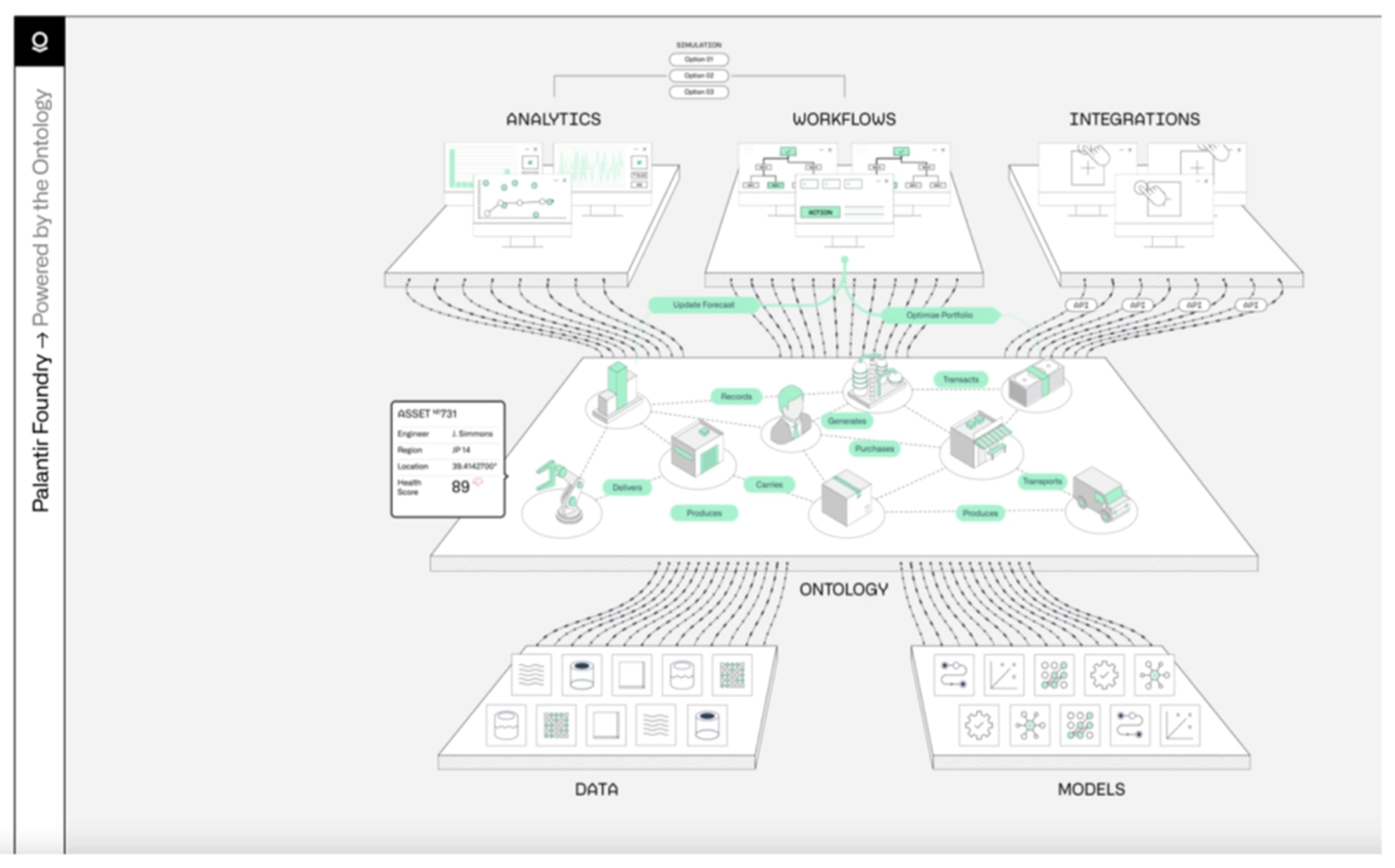
构建数字孪生,实现“感知-认知-行动”的闭环
就像SAP供应链自动触发财务记账一样,物理世界业务活动直接触发本体。在此基础上分析,再行动。
用本体实现数字孪生,实现输入 - 全局统筹 - 执行的闭环
沉淀下来的“人类行为数据”,并非简单的动作记录,而是被拆解为“问题场景- 应对逻辑- 执行结果” 的结构化信息—“本体”,成为训练人工智能模型的“养料”
当AI对业务逻辑的理解足够深入、对复杂场景的应对足够成熟后,便可直接接管那些标准化的工作流程。触发对应系统操作,实现AI输出到实际执行的闭环。如自动调整生产计划、下发风控指令或执行跨系统转账。
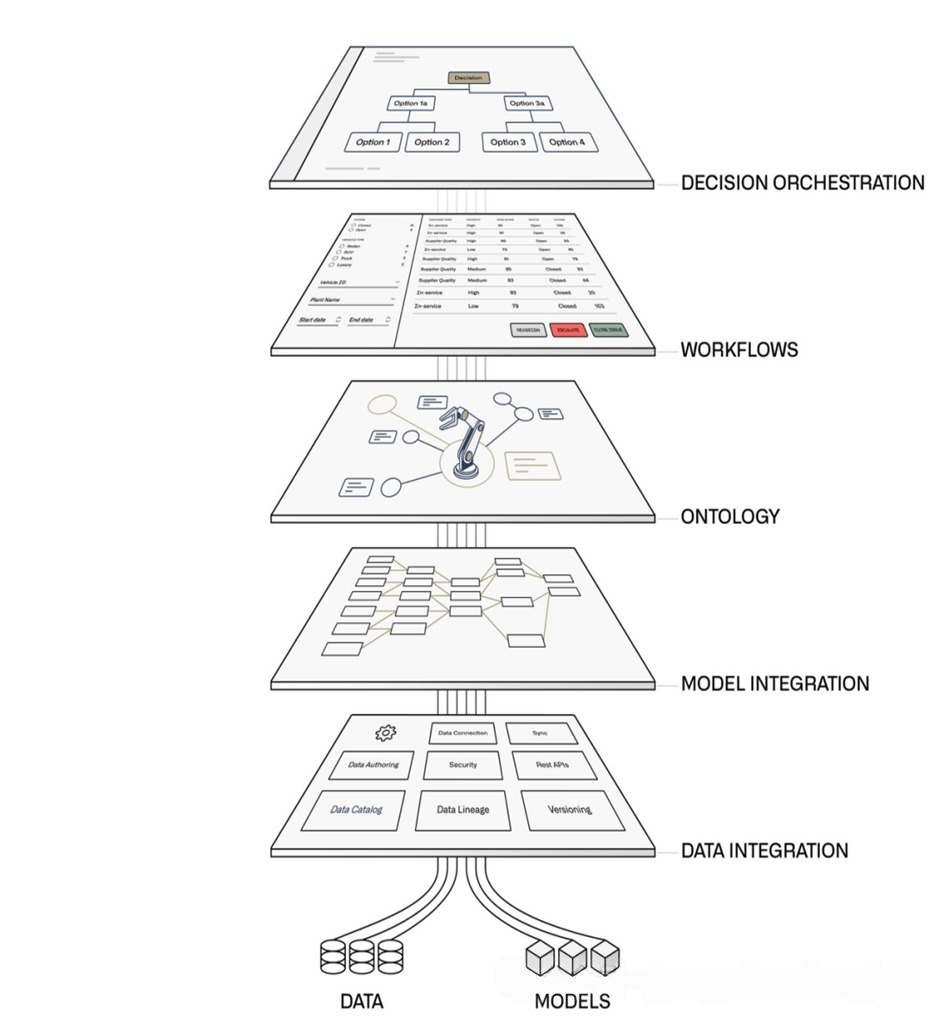
-
数据收集(通过ERP收集数据)
-
企业模型
-
将流程、资源、事件等建模为企业业务的语义(semantic),形成企业真实世界的“数字孪生”——“本体”(ontology)
计算出最优的行动方案,即决策(Decision)
-
将决策转化为一系列跨系统、跨部门的可执行步骤
工作流
支持跨系统编排(Orchestration),自动化数据流和决策执行。
通过 Saga 模式实现最终一致性(补偿事务、幂等、重试、死信队列)。
核心价值:让数据流不仅能“看”,还能“驱动执行”。
产品_Foundry
核心模块
建模:Ontology(数据本体建模):定义业务实体与关系。
数据:Data Lineage / Pipeline Studio:拖拽式数据管道编排。
分析:Code Workbooks:数据科学家可以直接写 Python、R、SQL,调用 Spark / ML 库。
UI:Visualization / Dashboards:BI 风格可视化,内嵌在 Foundry 界面中。
app:App Builder / Workshop:低代码构建行业应用。
前端(用户界面层)技术
TypeScript + React → Foundry 的主要 UI 框架,用于构建工作台、仪表盘、低代码应用界面
GraphQL / REST → 与后端的数据查询和交互
浏览器端低代码工具(App Builder、Workshop),封装了 React + 内部 DSL(领域专用语言)
后端(应用逻辑与计算层)技术
- Apollo → Palantir 自研的持续交付与多云部署系统,确保 Foundry 能在 AWS、Azure、GCP 或本地数据中心一致运行
- 关系数据库:Postgres、Oracle 等,用于事务型与元数据管理
- Graph 数据存储:内部有知识图谱/本体管理,早期 Gotham 用过 Titan/Neo4j 等,Foundry 更可能采用自研或基于分布式 KV
权限控制
-
源数据层:传统的行/列/表权限(类似数据库 ACL)。
-
Ontology 层:以业务对象为中心(例如 Order、Customer、Warehouse)。
-
属性级别:某些敏感字段(例如客户身份证号) → “可见/不可见/脱敏”。
-
实例级别(Row-level Security):例如“销售 A 只能看到自己负责区域的订单”,通过 Ontology 映射规则实现。
-
操作级别:不仅是“看”,还能限制“能不能触发某个动作”,例如:
可以查看订单状态
但不能触发“取消订单” 或 “重新分配库存”的操作
可定义“业务动作权限”,如 cancelOrder、approvePayment、rerouteTruck
沙箱
支持沙箱演练(基于历史数据回放)、小范围灰度执行、全量推广。
可以在 Ontology 对象上模拟业务策略(如改派订单),避免大规模混乱
用户交互
通过统一的语义层/本体模型,让用户的交互行为能够直接访问、调用和组合数据模型、知识图谱及智能分析功能。
用户在看似直观的查询、自然语言交互、假设分析或模拟推演过程中,实际上是在与统一语义模型协同工作,从而大幅提升分析效率与一致性。
开发者、数据科学家、分析师、业务人员可以在同一 Ontology 层协作
客户案例
待补充
业务增长结果怎么样?
商业模式
项目采取定制化高级服务加实施咨询配套
不仅仅提供工具,而是从整体上提供一个全局化的数据分析与决策视角。Palantir 的模式介于“软件公司”和“咨询公司”之间,强调产品平台 + 咨询交付。
全域语义底座:跨系统数据融合与治理
操作系统级AI应用:让大模型拥有“业务常识”
端到端决策分析与仿真
- 当发生区域封锁或物流中断时,智能体通过本体拓扑关系,秒级识别受影响的订单、零部件及下游客户
- 实时模拟替代供应商、航线变更及资源调拨方案,并精准预计算各种方案对销售预测和利润的影响,产出最优决策路线图
- 根据最优策略,自动匹配技术员技能、调度备件库存并调整生产排班,实现预测性维护的全流程闭环。
与ERP关联
2025年5月,SAP与Palantir宣布深化战略合作,双方结合创造了一种全新的企业AI协同模型
不能仅仅把SAP ERP/Joule定位在手脚,而要定位于基座
SAP补充本体,Palantir补充基座与交互
ERP:关系型数据库基础上,业务规则硬编码
Palantir:本体基础上,业务规则内置在本体?

参考
https://zhuanlan.zhihu.com/p/720949824
https://www.palantir.com/careers/
https://mp.weixin.qq.com/s/SXPfiqh0-Mw9nNBDs4QfKg (mp.weixin.qq.com in Bing)
https://baijiahao.baidu.com/s?id=1849345119806720283&wfr=spider&for=pc (baijiahao.baidu.com in Bing)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)