MixerCSeg:一种通过解耦Mamba注意力机制实现裂缝分割的高效混合器架构
Zilong Zhao, Zhengming Ding, Pei Niu, Wenhao Sun, Feng Guo*
1 山东大学齐鲁交通学院,中国 2 美国杜兰大学计算机科学系
https://arxiv.org/pdf/2603.01361
摘要
特征编码器在像素级裂缝分割中起着关键作用,它们塑造了精细纹理和细微结构的表示。现有的基于CNN、Transformer和Mamba的模型各自只能捕捉所需空间或结构信息的一部分,在建模复杂裂缝模式方面存在明显差距。为了解决这个问题,我们提出了MixerCSeg,这是一种设计得像协调专家团队一样的混合器架构,其中类CNN通路专注于局部纹理,类Transformer通路捕捉全局依赖关系,而受Mamba启发的流则在单个编码器内对序列上下文进行建模。MixerCSeg的核心是TransMixer,它在探索Mamba潜在注意力行为的同时,建立了自然表达局部性和全局感知能力的专用通路。为了进一步增强结构保真度,我们引入了一种空间块处理策略和方向引导边缘门控卷积(DEGConv),以最小的计算开销增强不规则裂缝几何形状下的边缘敏感性。随后采用空间细化多级融合(SRF)模块来细化多尺度细节而不增加复杂度。在多个裂缝分割基准上的大量实验表明,MixerCSeg仅用2.05 GFLOPs和2.54 M参数就实现了最先进的性能,展示了其效率和强大的表示能力。代码可在 https://github.com/spiderforest/MixerCSeg 获取。
1. 引言
随着道路和桥梁等基础设施随时间老化和恶化,裂缝问题日益突出。作为监测和维护道路健康的关键技术,道路裂缝分割能够及时检测潜在的裂缝威胁。然而,由于裂缝具有相当大的形态多样性、不均匀的纹理分布以及与背景的低对比度[9],实现高精度像素级裂缝分割仍然是一个重大挑战。为了应对这一挑战,现有的裂缝分割模型主要基于三种架构:卷积神经网络(CNNs)、Transformers [24] 和 Mamba [6]。
由于在提取局部特征方面的强大能力和计算效率优势,研究人员提出了各种基于CNN的裂缝分割模型[14, 20, 23]。然而,它们有限的感受野使得难以有效建模长距离像素依赖关系,导致在处理复杂形态裂缝时性能不佳。Vision Transformer [5, 19] 成功地将Transformer架构引入视觉任务领域。通过利用注意力机制显式建模像素间的长距离依赖关系,它使得Crackmer [25] 和 DTrCNet [26] 等裂缝分割模型的性能超越了基于CNN的方法。然而,这也导致了计算复杂度的增加和推理效率的降低。近年来,Mamba [6] 架构作为一种具有线性计算复杂度的全局注意力机制被引入。SCSegamba [16] 设计了一种结构感知扫描策略以增强裂缝分割性能。尽管如此,这种渐进式数据处理机制限制了其在单次前向传播中捕捉和利用全局上下文的能力[12]。
最近,具有多样化架构的混合模型受到了越来越多的关注。MambaVision [12] 适配了Mamba结构,并首次提出了一种用于视觉任务的混合Mamba-Transformer架构。VAMBA [22] 针对长视频理解,通过整合自注意力、交叉注意力和Mamba模块构建了一个混合模型。RestorMixer [7] 通过提出结合CNN、Transformer和Mamba的混合模型改进了Mamba和自注意力[24],以增强图像恢复性能。尽管这些方法展示了性能提升的潜力,但它们只是以顺序或并行的方式简单地堆叠这些组件,而没有充分考虑架构之间固有的关系和差异。结果,多样化架构设计的全部优势并未得到充分利用[7, 12]。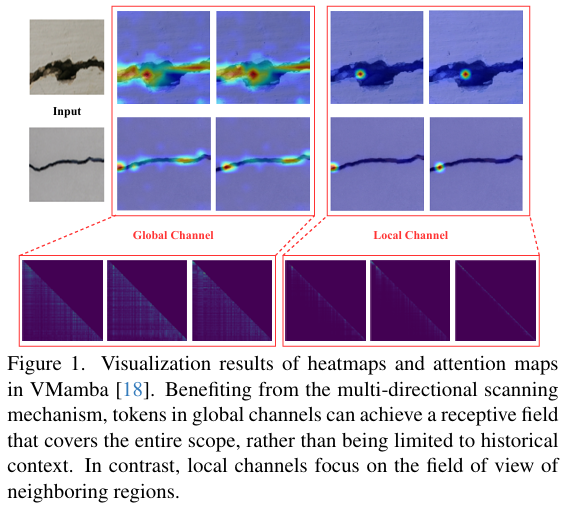
为了应对这一挑战,我们探索了Mamba潜在的注意力机制,并提出了一种名为MixerCSeg的新型混合架构模型,用于道路裂缝分割。具体而言,我们设计了一种名为TransMixer的混合器架构。它根据Mamba固有的注意力特性,沿通道维度将令牌解耦为全局令牌和局部令牌(如图1所示)。对于全局令牌,引入自注意力以进一步建模长距离依赖关系。对于局部令牌,设计了一个局部细化模块,通过卷积操作增强细粒度特征细节。此外,为了实现像素级裂缝分割,我们设计了一种方向引导边缘门控卷积(DEGConv)。它采用空间块处理并利用方向先验,在最小化计算开销的同时增强不规则裂缝几何形状下的边缘敏感性。最后,空间细化多级特征融合(SRF)模块通过跨尺度语义交互为低分辨率特征提供全局上下文指导,在不产生额外计算开销的情况下生成高精度分割结果。
总之,我们的主要贡献如下:
- 我们引入了TransMixer,这是一种新设计的特征编码结构,它为CNN、Transformer和Mamba通路分配了不同的角色,分别用于捕捉局部纹理、建模全局依赖关系和表达上下文流,从而形成一个协调的架构,而不是模块的简单堆叠混合。
- 我们开发了基于此编码器的裂缝分割模型MixerCSeg。它结合了DEGConv以增强方向感知的边缘建模,并结合SRF以最小的计算成本细化多尺度空间细节。
- 我们在多个裂缝分割基准上进行了广泛的实验,结果表明MixerCSeg以2.05 GFLOPs和2.54 M参数的高效设计实现了最先进的性能。
2. 相关工作
2.1. 道路裂缝分割
当前基于深度学习的道路裂缝分割方法主要可分为三类:基于CNN、基于Transformer和基于Mamba的方法。在基于CNN的方法中,DeepCrack [17] 建立了一个裂缝分割数据集和基准分割模型。SDDNet [4] 采用可分离卷积实现高效的实时裂缝分割。SFIAN [3] 通过设计选择性融合和不规则感知网络来提高分割精度。BARNet [10] 引入梯度先验,开发了一种结合图像特征与梯度信息的裂缝分割模型。然而,由于CNN在捕捉全局感受野方面的局限性,它们难以有效建模长距离依赖关系,这限制了像素级裂缝分割性能的进一步提升。
ViT [5] 成功地将注意力[24]机制引入视觉任务。利用注意力机制在长距离依赖建模方面的优势,STA [8] 利用Swin-Transformer [19] 提取细长裂缝特征;Crackmer [25] 设计了一种结合卷积和Transformer的并行分割架构,以增强裂缝细节的表征;CrackFormer [15] 提出了一种缩放注意力块以抑制非语义特征并锐化语义裂缝。尽管取得了这些进展,但二次方的计算复杂度带来了新的计算效率挑战。
Mamba [6] 模型利用其线性计算复杂度的优势,已被ViM [32] 和 VMamba [18] 等研究成功引入视觉领域,为道路裂缝分割提供了新的视角。MambaCrackNet [11] 结合了残差Mamba块以减少背景干扰并提高细微裂缝的检测率。CrackMamba [33] 和 SCSegamba [16] 分别设计了蛇形和结构感知扫描策略,增强了模型表征复杂裂缝特征的能力。
2.2. 混合架构模型
目前,常见的视觉下游任务通常采用Mamba-CNN或Transformer-CNN等架构,而Mamba-Transformer-CNN混合架构仍处于探索阶段。在视觉任务领域,MambaVision [12] 是第一个提出基于混合架构的主干网络,其性能超越了ViT [5] 和 VMamba [18]。RestorMixer [7] 是第一个为图像恢复任务引入混合模型的,旨在利用不同架构的优势。MambaFormer [28] 顺序堆叠Mamba和注意力机制,设计了一种用于时间序列预测的模型。VAMBA [22] 整合了交叉注意力、自注意力和Mamba,以增强长视频理解任务的性能。
然而,现有的混合模型往往只是简单地堆叠Mamba和Transformer模块,而没有针对不同架构之间的协同机制进行精细化设计。基于对Mamba内部隐藏注意力的深入分析,我们提出了一种新颖的混合架构。该架构旨在在适当的阶段利用每个模块的独特优势,从而有效增强裂缝特征提取的能力。
3. 方法
3.1. 预备知识:Mamba的隐藏注意力
给定输入序列 I=(x1,x2,...,xL)∈RL×dI = (x_{1}, x_{2}, ..., x_{L}) \in \mathbb{R}^{L \times d}I=(x1,x2,...,xL)∈RL×d,其中 LLL 表示令牌长度,ddd 表示通道数,Mamba块的计算过程可以表示为:
Z=σ1(Linear(I));X=Conv1D(Linear(I));Y=SSM(X);O=Linear(Y⊙Z), \begin{aligned} &Z = \sigma_{1}(Linear(I)); X = Conv1D(Linear(I)); \\ &\quad Y = SSM(X); \\ &\quad O = Linear(Y \odot Z), \end{aligned} Z=σ1(Linear(I));X=Conv1D(Linear(I));Y=SSM(X);O=Linear(Y⊙Z),
其中 σ1\sigma_{1}σ1 是SiLU激活函数,LinearLinearLinear 代表常规线性投影,⊙\odot⊙ 表示逐元素乘法,O∈RL×dO \in \mathbb{R}^{L \times d}O∈RL×d 是输出序列。SSM的离散状态转移方程和观测方程公式化为:
ht=Aˉtht−1+Bˉtxt;yt=Ctht,h_{t} = \bar{A}_{t}h_{t-1} + \bar{B}_{t}x_{t}; \quad y_{t} = C_{t}h_{t},ht=Aˉtht−1+Bˉtxt;yt=Ctht,
其中 xtx_{t}xt 是时间步 ttt 的输入,hth_{t}ht 是隐藏状态,Aˉt,Bˉt\bar{A}_{t}, \bar{B}_{t}Aˉt,Bˉt 和 CtC_{t}Ct 分别代表隐藏状态的衰减因子、控制隐藏状态的更新矩阵和输出的投影矩阵。它们的计算方式为:
Δt=Softplus(xt);Bˉt,Ct=LinearB/C(xt);Aˉt=exp(AΔt);Bˉt=BtΔt, \begin{array}{c} {\Delta_{t} = \operatorname{Softplus}(x_{t}); \quad \bar{B}_{t}, C_{t} = \operatorname{Linear}_{B/C}(x_{t});} \\ {\bar{A}_{t} = \exp(A \Delta_{t}); \quad \bar{B}_{t} = B_{t} \Delta_{t},} \end{array} Δt=Softplus(xt);Bˉt,Ct=LinearB/C(xt);Aˉt=exp(AΔt);Bˉt=BtΔt,
其中 AAA 是一个负的可学习矩阵,Δt\Delta_{t}Δt 是一个正因子,确保隐藏状态的衰减因子始终满足 0<Aˉt<10 < \bar{A}_{t} < 10<Aˉt<1 [30]。通过展开公式4中的递归计算步骤,我们将第 jjj 个令牌 xjx_{j}xj 对第 iii 个令牌 xix_{i}xi 的贡献量化为:
hi=Σj=1i(Πk=j+1iAˉk)⊙Bˉj⊙xj;yi=CiTΣj=1i(Πk=j+1iAˉk)⊙Bˉj⊙xj;=Σj=1iαi,j⊙xj, \begin{align*} h_{i} &= \Sigma_{j=1}^{i} \left( \Pi_{k=j+1}^{i} \bar{A}_{k} \right) \odot \bar{B}_{j} \odot x_{j}; \\ y_{i} &= C_{i}^{T} \Sigma_{j=1}^{i} \left( \Pi_{k=j+1}^{i} \bar{A}_{k} \right) \odot \bar{B}_{j} \odot x_{j}; \\ &= \Sigma_{j=1}^{i} \alpha_{i,j} \odot x_{j}, \end{align*} hiyi=Σj=1i(Πk=j+1iAˉk)⊙Bˉj⊙xj;=CiTΣj=1i(Πk=j+1iAˉk)⊙Bˉj⊙xj;=Σj=1iαi,j⊙xj,
其中 αi,j=CiT(Πk=j+1iAˉk)⊙Bˉj\alpha_{i,j} = C_{i}^{T} \left( \Pi_{k=j+1}^{i} \bar{A}_{k} \right) \odot \bar{B}_{j}αi,j=CiT(Πk=j+1iAˉk)⊙Bˉj 是一个权重因子,代表第 jjj 个令牌对第 iii 个令牌输出的贡献,类似于Transformer [1, 2, 30] 中的注意力分数。图1展示了该注意力分数的通道可视化。为了研究影响注意力分数的基本因素,我们进一步展开了公式4中的隐藏状态转移方程:
ht=Aˉtht−1+Bˉtxt=eAΔtht−1+ΔtBtxt,h_{t} = \bar{A}_{t}h_{t-1} + \bar{B}_{t}x_{t} = e^{A \Delta_{t}} h_{t-1} + \Delta_{t} B_{t} x_{t},ht=Aˉtht−1+Bˉtxt=eAΔtht−1+ΔtBtxt,
当 Δt→0\Delta_{t} \to 0Δt→0 时,当前令牌被丢弃,保留时间步 t−1t-1t−1 的令牌;当 Δt>0\Delta_{t} > 0Δt>0 时,时间 t−1t-1t−1 令牌的衰减结果被添加到当前时间步 ttt 的令牌中。因此,Δt\Delta_{t}Δt 决定了哪些令牌将影响未来的令牌 [2]。
3.2. 架构概述
图2展示了我们要提出的MixerCSeg模型,它由三个核心组件组成:TransMixer块、DEGConv模块和SRF模块。TransMixer块旨在提取像素级裂缝特征,DEGConv捕捉裂缝的纹理和拓扑线索,SRF实现高效的多级特征融合。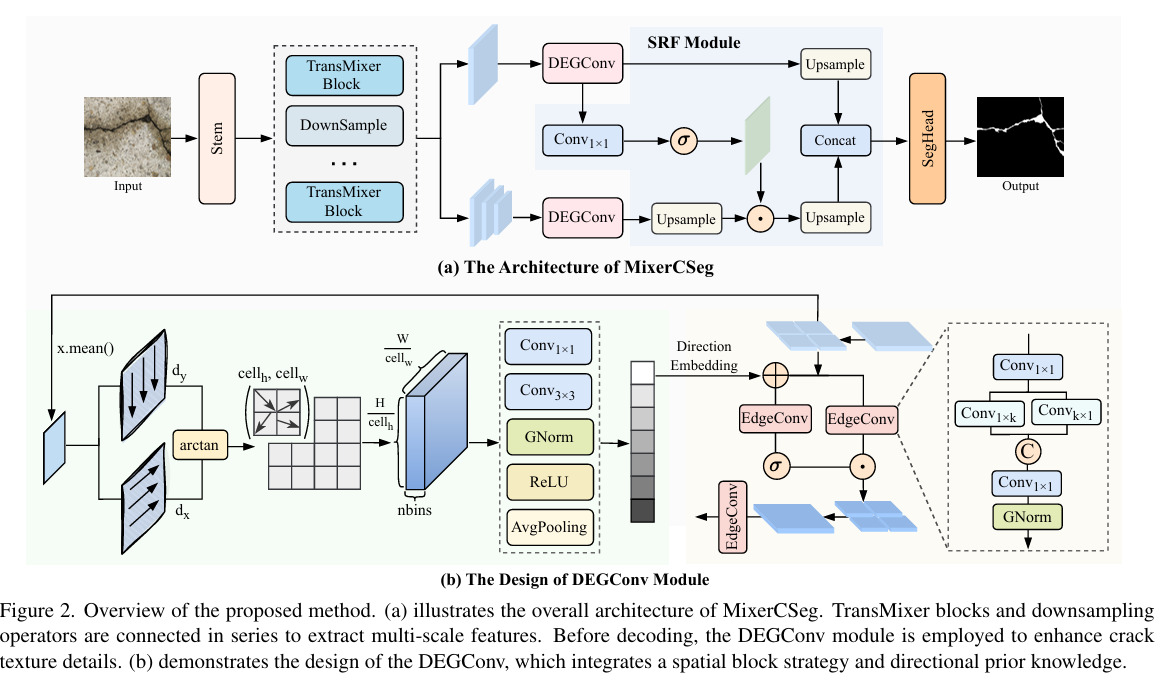
首先,对于输入图像 P∈R3×H×WP \in \mathbb{R}^{3 \times H \times W}P∈R3×H×W,通过茎层将其投影为视觉特征,并由TransMixer块处理以获得多尺度特征图 {F1,F2,F3,F4}\{F_{1}, F_{2}, F_{3}, F_{4}\}{F1,F2,F3,F4}。然后将这些特征输入到DEGConv模块中,应用空间块处理策略将方向先验嵌入引入特征图,从而增强模型对不同形态裂缝的纹理和语义特征的感知。最后,SRF模块整合多尺度特征图,分割头输出像素级裂缝分割结果 r∈R1×H×Wr \in \mathbb{R}^{1 \times H \times W}r∈R1×H×W。
3.3. TransMixer的设计
混合模型的设计意图是结合不同架构的优势,使它们互补。图3(a)展示了当前Transformer和Mamba混合模型的两种主要实现形式[12, 22],它们通过并行计算或顺序执行来整合Mamba和注意力机制。然而,这两种方法都有相同的局限性:它们只是以简单的方式堆叠模块,而没有深入分析其核心内部交互逻辑,从而限制了混合架构的全部潜力。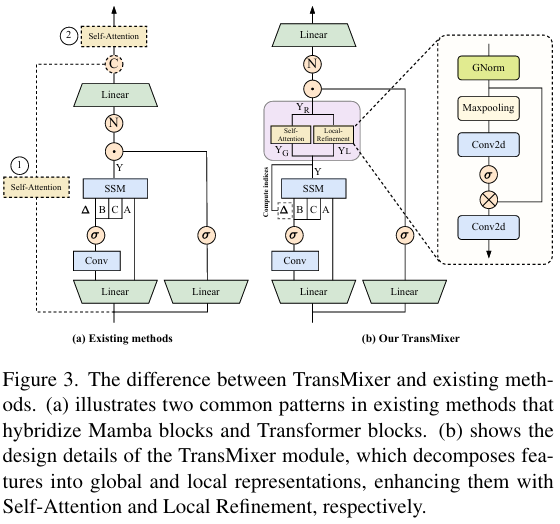
为了解决上述局限性,我们对Mamba模块内的注意力机制进行了深入分析,并据此提出了TransMixer模块,以更有效地捕捉视觉特征。该模块的整体设计如图3(b)所示。根据公式10,Δt\Delta_{t}Δt 决定了历史令牌对当前令牌的影响。基于此,我们沿通道维度对 Δt\Delta_{t}Δt 进行排序,选择前 dg=d⋅γd_{g} = d \cdot \gammadg=d⋅γ 个令牌作为全局令牌,其余 dl=d⋅(1−γ)d_{l} = d \cdot (1 - \gamma)dl=d⋅(1−γ) 个令牌作为局部令牌,对应的索引集记为 ggg 和 lll。
SSM执行完成后,我们获得输出 Y∈RL×dY \in \mathbb{R}^{L \times d}Y∈RL×d。随后,使用索引 ggg 和 lll 将其分解为全局表示 YG∈RL×dgY_{G} \in \mathbb{R}^{L \times d_{g}}YG∈RL×dg 和局部表示 YL∈RL×dlY_{L} \in \mathbb{R}^{L \times d_{l}}YL∈RL×dl。对于全局表示 YGY_{G}YG,我们将其输入自注意力模块以增强全局令牌之间的相关性,得到增强表示 YG′Y_{G}'YG′。对于局部表示 YLY_{L}YL,我们设计了一个简单的局部细化模块进行处理,其计算过程如下:
FL∈Rdl×H×W=Norm(Reshape(YL));FL′=σ2(Conv1×1(maxpool2d(Fl)))⊙FL;Yl′=Flatten(FL′), \begin{aligned} &F_{L} \in \mathbb{R}^{d_{l} \times H \times W} = \mathrm{Norm}(\mathrm{Reshape}(Y_{L})); \\ &F_{L}' = \sigma_{2}(\mathrm{Conv}_{1 \times 1}(\mathrm{maxpool2d}(F_{l}))) \odot F_{L}; \\ &\quad Y_{l}' = \mathrm{Flatten}(F_{L}'), \end{aligned} FL∈Rdl×H×W=Norm(Reshape(YL));FL′=σ2(Conv1×1(maxpool2d(Fl)))⊙FL;Yl′=Flatten(FL′),
其中 Norm\mathrm{Norm}Norm 表示归一化操作,σ2\sigma_{2}σ2 是sigmoid激活函数。
总体而言,TransMixer模块的完整计算工作流程如下:首先,执行公式1至公式2描述的操作以获得输出 YYY,然后执行:
g,l=findex(Δt);YG,YL=Y[:,g],Y[:,l];Y[:,g],Y[:,l]=fself−att(YG),frefine(YL), \begin{aligned} g, l &= f_{index}(\Delta_{t}); \\ Y_{G}, Y_{L} &= Y[:, g], Y[:, l]; \\ Y[:, g], Y[:, l] &= f_{self-att}(Y_{G}), f_{refine}(Y_{L}), \end{aligned} g,lYG,YLY[:,g],Y[:,l]=findex(Δt);=Y[:,g],Y[:,l];=fself−att(YG),frefine(YL),
最后,执行公式3以完成后续计算,获得特征图 Fi∈RCi×Hi×WiF_{i} \in \mathbb{R}^{C_{i} \times H_{i} \times W_{i}}Fi∈RCi×Hi×Wi。
3.4. 方向引导边缘门控卷积
与被动处理信息的普通卷积相比,门控卷积可以动态调节信息流,从而更有效地保留重要特征。在实际场景中,裂缝经常向多个方向延伸成分支,这对模型准确追踪这些相交和重叠的路径构成了重大挑战。为此,我们设计了一个方向引导边缘门控卷积(DEGConv)模块。该模块整合了多视角处理策略与方向先验,以精确建模复杂的裂缝结构,其处理流程如图2(b)所示。
重排。对于第 iii 层的特征图 Fi∈RCi×Hi×WiF_{i} \in \mathbb{R}^{C_{i} \times H_{i} \times W_{i}}Fi∈RCi×Hi×Wi,我们将其划分为 NNN 个大小为 hi×wih_{i} \times w_{i}hi×wi 的不重叠视图,记为 Fi={Fi1,Fi2,...,FiN}\mathcal{F}_{i} = \{F_{i}^{1}, F_{i}^{2}, ..., F_{i}^{N}\}Fi={Fi1,Fi2,...,FiN},其中 N=Hihi×WiwiN = \frac{H_{i}}{h_{i}} \times \frac{W_{i}}{w_{i}}N=hiHi×wiWi。Fij∈RCi×hi×wiF_{i}^{j} \in \mathbb{R}^{C_{i} \times h_{i} \times w_{i}}Fij∈RCi×hi×wi 表示第 jjj 个局部视图特征图。
方向嵌入生成。我们首先沿通道维度对输入 FijF_{i}^{j}Fij 取平均,得到 F~ij∈R1×hi×wi\tilde{F}_{i}^{j} \in \mathbb{R}^{1 \times h_{i} \times w_{i}}F~ij∈R1×hi×wi。随后,使用Sobel算子计算该视图的水平和垂直梯度 dxd_{x}dx 和 dyd_{y}dy。然后,通过反正切函数 θ=arctan(dydx)∈R1×hi×wi\theta = \arctan(\frac{d_y}{d_x}) \in \mathbb{R}^{1 \times h_i \times w_i}θ=arctan(dxdy)∈R1×hi×wi 计算每个像素的弧度值,并将结果约束在区间 [0,π][0, \pi][0,π] 内。
为了获得更紧凑的特征表示并减少个别异常像素的干扰,我们进一步将视图划分为大小为 (cellh,cellw)(cell_{h}, cell_{w})(cellh,cellw) 的单元格,并将弧度区间 [0,π][0, \pi][0,π] 均匀划分为 nnn 个箱(bins)。对于每个单元格 Ca,b(a=1,...,hicellh;b=1,...,wicellw)C_{a,b} (a = 1, ..., \frac{h_{i}}{cell_{h}}; b = 1, ..., \frac{w_{i}}{cell_{w}})Ca,b(a=1,...,cellhhi;b=1,...,cellwwi),我们计算每个像素弧度方向对应的箱索引,统计每个箱内的像素数量,并使用箱的中心角值对它们进行加权,以获得单元格的方向直方图特征。此过程可以表示为:
indexbin(u,v)=⌊θ(u,v)π/n⌋shifta,b(k)=∑(u,v)∈Ca,bI[indexbin(u,v)=k]pa,b,k=ck⋅shifta,b(k)∣Ca,b∣ \begin{aligned} \operatorname{index}_{bin}(u,v) &= \left\lfloor \frac{\theta(u,v)}{\pi/n} \right\rfloor \\ \operatorname{shift}_{a,b}(k) &= \sum_{(u,v) \in C_{a,b}} \mathbb{I}[\operatorname{index}_{bin}(u,v) = k] \\ p_{a,b,k} &= c_k \cdot \frac{\operatorname{shift}_{a,b}(k)}{|C_{a,b}|} \end{aligned} indexbin(u,v)shifta,b(k)pa,b,k=⌊π/nθ(u,v)⌋=(u,v)∈Ca,b∑I[indexbin(u,v)=k]=ck⋅∣Ca,b∣shifta,b(k)
其中 θ(u,v)∈[0,π]\theta(u,v) \in [0, \pi]θ(u,v)∈[0,π] 表示位置 (u,v)(u,v)(u,v) 处的方向弧度值,nnn 是箱的数量,k=0,...,n−1k = 0, ..., n-1k=0,...,n−1 是箱索引。I[⋅]\mathbb{I}[\cdot]I[⋅] 表示指示函数。ck=π2n+k⋅πnc_{k} = \frac{\pi}{2n} + k \cdot \frac{\pi}{n}ck=2nπ+k⋅nπ 是第 kkk 个箱的中心弧度值,∣Ca,b∣=cellh×cellw|C_{a,b}| = cell_{h} \times cell_{w}∣Ca,b∣=cellh×cellw 是单元格中的总像素数。最后,我们聚合所有单元格的特征以获得空间方向先验向量 p∈Rn×hicellh×wicellwp \in \mathbb{R}^{n \times \frac{h_{i}}{cell_{h}} \times \frac{w_{i}}{cell_{w}}}p∈Rn×cellhhi×cellwwi,然后将其转换为一维方向嵌入向量:
fp=Conv3×3(Conv1×1(p));ϵ=avgpool(Norm(ReLU(fp)))∈RCi \begin{aligned} f_{p} &= \mathrm{Conv}_{3 \times 3}(\mathrm{Conv}_{1 \times 1}(p)); \\ \epsilon &= \mathrm{avgpool}(\mathrm{Norm}(\mathrm{ReLU}(f_{p}))) \in \mathbb{R}^{C_{i}} \end{aligned} fpϵ=Conv3×3(Conv1×1(p));=avgpool(Norm(ReLU(fp)))∈RCi
这里,avgpool\mathrm{avgpool}avgpool 表示自适应平均池化操作,ϵ\epsilonϵ 是生成的方向嵌入向量。
边缘卷积。为了增强模型对裂缝纹理特征的感知,我们设计了一种轻量级边缘卷积。首先,我们采用逐点卷积将特征映射到低维空间,从而降低计算复杂度。随后,使用核大小为 1×k1 \times k1×k 和 k×1k \times 1k×1 的条带卷积分别提取沿水平和垂直方向的裂缝方向特征。最后,将两个方向的特征沿通道维度拼接,并使用深度卷积获得输出结果。
门控机制。如图2(b)所示,我们首先将方向嵌入特征添加到原始特征图中,使用EdgeConv和sigmoid函数生成门控权重,同时对原始特征应用EdgeConv,然后通过逐元素乘法将它们组合:
g=σ2(EdgeConv(Fij+ϵ));Fij′=g⊙EdgeConv(Fij) \begin{aligned} g &= \sigma_{2}(\mathrm{EdgeConv}(F^{j}_{i} + \epsilon)); \\ {F^{j}_{i}}' &= g \odot \mathrm{EdgeConv}(F^{j}_{i}) \end{aligned} gFij′=σ2(EdgeConv(Fij+ϵ));=g⊙EdgeConv(Fij)
最后,来自不同空间块的独立特征被重新排列以恢复图像的原始空间结构。为了进一步减轻重排可能引入的潜在边界不对齐问题,我们引入了一个额外的EdgeConv层进行后处理,最终获得优化的特征表示 Fi′F_{i}'Fi′。
3.5. 空间细化多级特征融合
直接上采样和融合多级特征不仅会因空间不一致导致分割边界错位,而且无法充分利用高分辨率特征中存在的细粒度空间信息。为了解决这个问题,我们设计了一个空间细化多级特征融合模块(SRF)。在高分辨率特征 F1′F_{1}'F1′ 丰富的空间细节指导下,该模块逐步上采样并融合较低级别的特征 {F2′,F3′,F4′}\{F_{2}', F_{3}', F_{4}'\}{F2′,F3′,F4′},从而将细粒度信息注入语义特征中,提高分割边界的准确性。
为了利用 F1′F_{1}'F1′ 的详细信息来指导融合过程,我们首先生成其空间注意力图。同时,将低分辨率特征 {F2′,F3′,F4′}\{F_{2}', F_{3}', F_{4}'\}{F2′,F3′,F4′} 上采样到与 F1′F_{1}'F1′ 相同的空间维度。随后,使用注意力图对每个上采样特征进行空间加权细化,公式化为:
α=σ2(Conv1×1(Fi′));Fiup=Upsample(Fi′,(H1,W1));Fi′′=α⊙Fiup, \begin{aligned} \alpha &= \sigma_{2}(\mathrm{Conv}_{1 \times 1}(F_{i}')); \\ F_{i}^{up} &= \mathrm{Upsample}(F_{i}', (H_{1}, W_{1})); \\ F_{i}'' &= \alpha \odot F_{i}^{up}, \end{aligned} αFiupFi′′=σ2(Conv1×1(Fi′));=Upsample(Fi′,(H1,W1));=α⊙Fiup,
其中 α\alphaα 表示空间注意力图,且 i∈{2,3,4}i \in \{2, 3, 4\}i∈{2,3,4}。接下来,我们将所有特征图上采样到输入图像大小,获得 {F1up,F2up,F3up,F4up}\{F_{1}^{up}, F_{2}^{up}, F_{3}^{up}, F_{4}^{up}\}{F1up,F2up,F3up,F4up}。然后将这些特征沿通道维度拼接并输入分割头,以预测像素级裂缝分割结果。此过程可以表示为:
r=μ([F1up;F2up;F3up;F4up])∈R1×H×W, \boldsymbol{r} = \mu([F_{1}^{up}; F_{2}^{up}; F_{3}^{up}; F_{4}^{up}]) \in \mathbb{R}^{1 \times H \times W}, r=μ([F1up;F2up;F3up;F4up])∈R1×H×W,
其中 μ\muμ 代表分割头,由一个 1×11 \times 11×1 卷积和一个MLP组成。
3.6. 损失函数
遵循[16],我们采用结合二元交叉熵(BCE)和Dice损失的混合损失函数,比例设置为1:5。
4. 实验
4.1. 数据集和指标
数据集。我们的实验在四个裂缝基准数据集上进行:DeepCrack [17]、Crack500 [29]、CamCrack789 [31] 和 CrackMap [13],分别包含537、336、789和120张裂缝图像。这些数据集涵盖了各种场景下的裂缝,包括墙壁、沥青路面和水泥表面,具有多样的形态和尺度。在数据处理阶段,所有图像都被调整为 512×512512 \times 512512×512 像素,并按7:1:2的比例随机分为训练集、验证集和测试集。
指标。为了评估模型性能,我们采用了广泛使用的评估指标,包括F1分数、最佳数据集尺度(ODS)、最佳图像尺度(OIS)和平均交并比(mIoU)。
4.2. 实现细节
所有实验均在单个NVIDIA A100 GPU上进行。模型训练50个epoch,批量大小为1,使用AdamW优化器进行优化,初始学习率为 5e−45e-45e−4。对于参数设置,TransMixer块中的超参数 γ\gammaγ 默认设置为0.5,DEGConv中的单元格大小配置为 8×88 \times 88×8。具体来说,对于DeepCrack、CrackMap和CamCrack789数据集,区间数 nnn 设置为180。相比之下,对于Crack500数据集,其主要挑战在于高背景噪声的干扰,且裂缝表现出平滑的曲率和较大的宽度,因此 nnn 设置为36。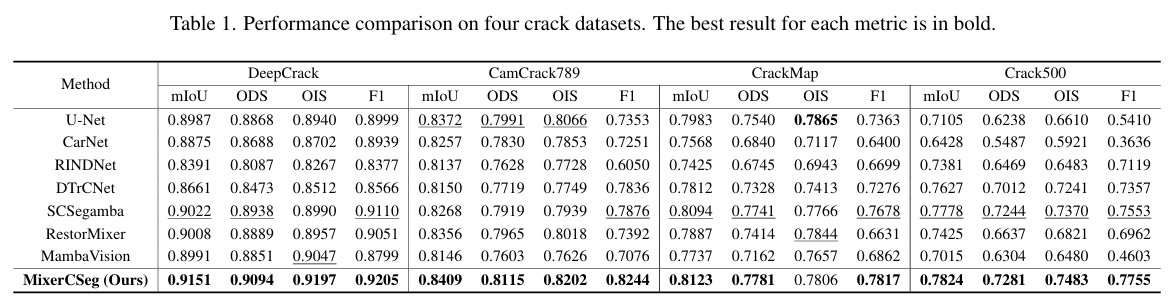
4.3. 与最先进方法的比较
定量评估。在表1中,我们将提出的MixerCSeg模型与7种用于图像和裂缝分割任务的SOTA模型进行了比较,包括UNet [23]、CarNet [14]、RINDNet [20]、DTrCNet [26]、RestorMixer [7]、SCSegamba [16] 和 MambaVision [12]。所有对比模型均训练50个epoch,输入大小为 512×512512 \times 512512×512,以确保实验公平性。如表所示,与现有的先进方法相比,我们的MixerCSeg在多个数据集上实现了更优越的性能指标。以DeepCrack [17] 数据集为例,MixerCSeg在mIoU和F1分数上分别比第二好的模型SCSegamba [16] 高出1.43%和1.04%,而与混合架构模型MambaVision相比,mIoU和F1分数分别提高了1.78%和4.61%。这些结果充分证明了我们所提出方法的有效性和优越性。
此外,表2展示了我们提出的方法与现有SOTA模型之间的计算效率比较。我们的方法需要2.54 M参数和2.05 GFLOPs,训练内存使用量为1190 MiB。与专为轻量级应用设计的SCSegMamba相比,我们的方法将参数量和计算成本分别降低了9.3%和88.7%,同时实现了1016 MiB的大幅内存减少。此外,与现有的混合架构MambaVision [12] 和 RestorMixer [7] 相比,MixerCSeg显示出显著更低的计算资源需求。这些结果充分验证了MixerCSeg的高效率及其在实际应用中的巨大潜力。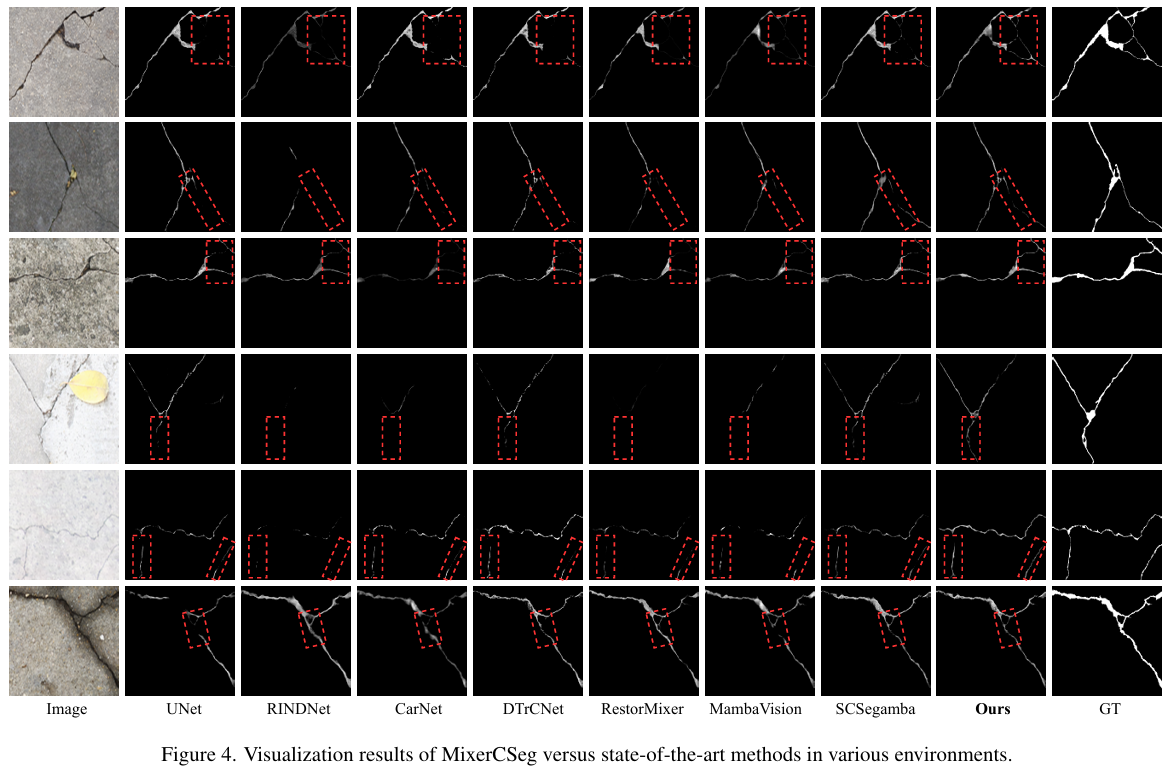
定性评估。为了直观地展示MixerCSeg的像素级分割结果,我们从测试集中选择了各种复杂环境下的裂缝图像进行可视化,如图4所示。当面对尺寸多变、形态多样和背景噪声干扰等挑战性场景时,MixerCSeg能够有效地捕捉裂缝区域。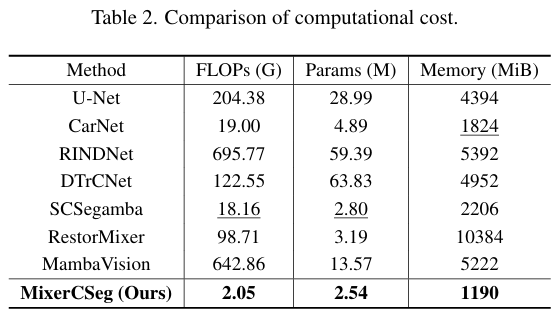
4.4. 消融实验
组件消融实验。我们使用VMamba [18] 作为编码器并集成Segformer [27] 解码器作为基线模型。消融实验结果如表3所示。我们依次引入TransMixer、DEGConv和SRF模块,裂缝分割性能均有不同程度的提高。这表明TransMixer模块能有效提取图像特征,DEGConv模块有助于捕捉裂缝的纹理和形态特征,SRF模块能生成准确的像素级裂缝表示。它们协同工作,实现了SOTA裂缝分割性能。
此外,在集成DEGConv模块后,模型的计算复杂度仅增加了0.08 GFLOPs,参数量增加了0.14 M。当用SRF模块替换SegFormer的解码器时,计算复杂度和GPU内存使用量显著下降,参数量也减少了0.1 M。这些结果充分证明了DEGConv和SRF模块的轻量级优势。
TransMixer的效果。为了验证我们混合架构的有效性,我们采用MambaVision [12] 和 RestorMixer [7] 作为编码器来提取多尺度特征,同时保持其他结构不变。如表3所示的实验结果表明,TransMixer实现了更优越的分割性能,从而验证了我们提出方法的有效性。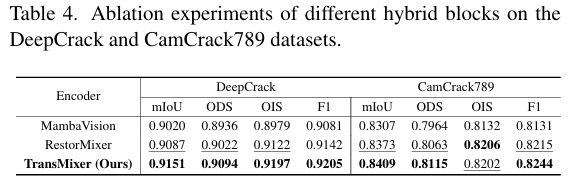
全局通道比例 γ\gammaγ。通过观察Mamba模块最后一层通道维度上的注意力权重,我们发现具有全局注意力的通道数量与仅具有局部注意力的通道数量相似。因此,我们将 γ\gammaγ 默认设置为0.5。为了验证此设置的合理性,我们通过将 γ\gammaγ 设置为0.3、0.7和0.9进行了对比实验。如表5第6-8行所示的结果表明,当 γ\gammaγ 偏离0.5时,模型性能均有不同程度的下降,表明默认值 γ=0.5\gamma = 0.5γ=0.5 是一个合理的配置。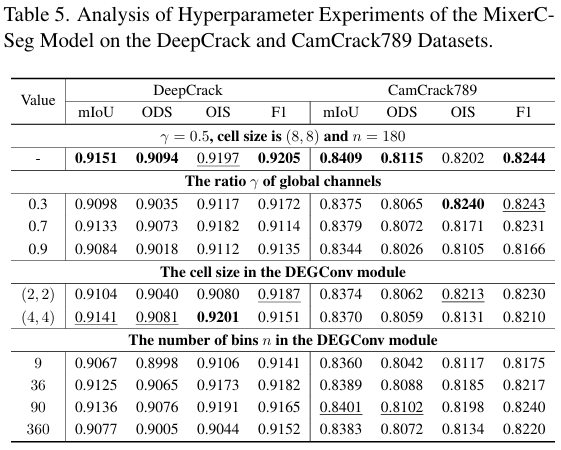
DEGConv模块中的单元格大小。在裂缝图像中,实际有效裂缝区域的比例较低,背景干扰显著。较小的单元格大小对噪声高度敏感,因此我们将默认单元格大小设置为 8×88 \times 88×8。为了验证此设置的合理性,我们另外设计了两种其他单元格大小(2×22 \times 22×2 和 4×44 \times 44×4)的对比实验。如表5第10-11行所示,较小的单元格大小对应最低的分割性能,这充分验证了我们默认设置的合理性。
DEGConv模块中的箱数 nnn。箱数直接影响方向嵌入的粒度,其默认值设为180。为了验证此配置的合理性,我们进行了如表5第13-16行所示的对比实验。结果表明,随着箱数的增加,模型性能呈现缓慢上升趋势,但当箱数过大时,性能反而下降。这是因为过细的区间划分导致每个箱只包含单个值,这与该参数设置的初衷相悖。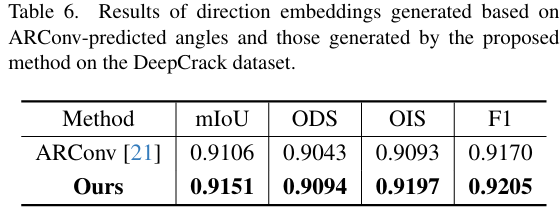
DEGConv模块中方向嵌入的效果。直接预测角度然后计算方向嵌入的方法[21] 受限于缺乏监督,难以确保方向嵌入的可靠性。相比之下,我们利用方向先验直接构建嵌入,赋予模型更合理的几何可解释性。表6的结果证实了该设计的有效性。
5. 结论
在本文中,我们提出了一种用于裂缝分割的混合模型MixerCSeg,该模型包含三个关键组件。首先,TransMixer模块充分利用了Mamba、Transformer和CNN的优势。它利用Mamba中的隐式注意力机制将令牌分为局部和全局令牌,自然地结合了Transformer和CNN框架,以高效捕捉多尺度裂缝特征。其次,DEGConv通过方向先验和门控机制以极小的成本增强了裂缝纹理细节和形态特征的表示。最后,SRF模块利用高分辨率信息细化低分辨率特征,实现像素级裂缝分割。在裂缝数据集上的大量实验验证表明,MixerCSeg在需要较低计算资源的同时,在裂缝分割方面实现了SOTA性能。
6. 致谢
本工作部分得到了国家自然科学基金(批准号:52308457)、山东省自然科学基金(批准号:ZR2023QE220)和中国博士后科学基金(批准号:2024M761811)的支持。
补充材料
7. 额外的消融实验
7.1. TransMixer 模块的消融研究
为了彻底调查 TransMixer 模块的有效性,我们针对该组件进行了全面的消融实验。具体而言,我们在三种条件下评估了模型性能:移除 TransMixer 模块、移除全局令牌(global tokens)以及移除局部令牌(local tokens)。如表 7 所示,当移除 TransMixer 模块时,模型在 DeepCrack [17] 和 CamCrack789 [31] 数据集上的性能分别下降了 0.76% 和 0.49%。同样,移除局部令牌或全局令牌的模型也表现出不同程度的性能下降。这些实验结果验证了 TransMixer 模块的有效性,表明每个子组件都发挥着特定且有意义的作用。
此外,我们将局部细化模块(Local Refinement module)中的最大池化(maxpooling)替换为平均池化(avgpooling)。如表 8 所示,与平均池化相比,最大池化在增强局部区域内最关键和最显著的裂缝特征方面更为有效。
表 7. 在 DeepCrack 和 CamCrack789 数据集上,TransMixer 模块中解码全局令牌和局部令牌的实验结果。
| 局部 | 全局 | DeepCrack (mIoU, ODS, OIS, F1) | CamCrack789 (mIoU, ODS, OIS, F1) |
|---|---|---|---|
| ✓ | 0.9082, 0.9009, 0.9054, 0.9155 | 0.8368, 0.8057, 0.8158, 0.8252 | |
| ✓ | 0.9120, 0.9057, 0.9138, 0.9206 | 0.8382, 0.8081, 0.8179, 0.8247 | |
| ✓ | ✓ | 0.9136, 0.9079, 0.9169, 0.9204 | 0.8384, 0.8076, 0.8200, 0.8275 |
| ✓ | ✓ | 0.9151, 0.9094, 0.9197, 0.9205 | 0.8409, 0.8115, 0.8202, 0.8244 |
| (注:最后一行表示同时保留局部和全局通道的完整 TransMixer) |
表 8. 在 DeepCrack 和 CamCrack789 数据集上,局部细化模块中不同池化操作的实验结果。
| 方法 | DeepCrack (mIoU, ODS, OIS, F1) | CamCrack789 (mIoU, ODS, OIS, F1) |
|---|---|---|
| Avgpooling | 0.9147, 0.9089, 0.9192, 0.9140 | 0.8399, 0.8100, 0.8227, 0.8273 |
| Maxpooling | 0.9151, 0.9094, 0.9197, 0.9205 | 0.8409, 0.8115, 0.8202, 0.8244 |
7.2. DEGConv 模块的消融研究
在 3.4 节中,DEGConv 模块由四个组件组成:重排(Rearrange)、方向嵌入生成(DEG)、边缘卷积(Edge Convolution)和门控机制(Gating)。为了系统地评估每个组件的必要性和贡献,我们进行了如表 9 所示的实验。结果表明,每个组件都有助于提高分割性能。特别是,DEG 操作带来了显著的性能提升,在 DeepCrack [17] 和 CamCrack789 [31] 数据集上分别实现了 0.36% 和 0.46% 的 mIoU 增长。虽然单独的重排操作带来的提升相对较小(在两个数据集上 mIoU 分别增长 0.24% 和 0.05%),但它通过空间块方法优化特征的空间排列,起到了关键作用。这导致了更结构化的特征输入,为后续的 DEG 和边缘卷积步骤奠定了坚实的基础,从而促进了模块整体性能的提升。
表 9. DEGConv 在 DeepCrack 和 CamCrack789 数据集上的消融实验结果,包括重排、DEG、边缘卷积和门控操作。
| 重排 | DEG | 边缘卷积 | 门控 | DeepCrack (mIoU, ODS, OIS, F1) | CamCrack789 (mIoU, ODS, OIS, F1) |
|---|---|---|---|---|---|
| 0.9052, 0.8980, 0.9042, 0.9052 | 0.8334, 0.8008, 0.8122, 0.8114 | ||||
| ✓ | 0.9074, 0.9004, 0.9127, 0.9130 | 0.8338, 0.8009, 0.8079, 0.8162 | |||
| ✓ | ✓ | 0.9107, 0.9044, 0.9143, 0.9174 | 0.8376, 0.8065, 0.8237, 0.8252 | ||
| ✓ | ✓ | ✓ | 0.9132, 0.9072, 0.9125, 0.9205 | 0.8398, 0.8092, 0.8193, 0.8254 | |
| ✓ | ✓ | ✓ | ✓ | 0.9151, 0.9094, 0.9197, 0.9205 | 0.8409, 0.8115, 0.8202, 0.8244 |
7.3. 层深度的影响
在 MixerCSeg 网络架构的设计中,为了平衡计算资源和性能,每个 TransMixer 块的深度设置为 1。我们通过表 10 中的对照实验定量分析了块深度对模型性能的影响。在保持其他参数不变的情况下,我们分别测试了 TransMixer 块深度为 2、4 和 6 层的配置方案。实验结果表明,当每层深度设置为 1 时,模型在消耗较低计算资源的同时表现出最佳的分割性能。相比之下,当网络深度增加到 2 层时,模型的计算负载为 3.51 GFLOPs,参数量为 4.76 M,内存使用量为 1550 MiB。这些数值代表计算量增加了 71.2%,参数量增加了 87.4%,内存使用量增加了 30.2%。然而,由于裂缝分割任务高度依赖于像素级裂缝形态和拓扑连续性等局部细粒度特征,深层网络中的细微细节可能会通过多层传播逐渐变得模糊。这可能导致边缘过平滑等问题。此外,参数优化的难度显著增加,导致性能下降。因此,将每个 TransMixer 块的深度设置为 1,不仅保证了裂缝分割的准确性,还有效地控制了模型复杂度,为在边缘设备上部署提供了可行性。
表 10. 在 DeepCrack 和 CamCrack789 数据集上不同层深度的实验。
| 深度 | FLOPs (G) | 参数量 (M) | 内存 (MiB) | DeepCrack (mIoU, ODS, OIS, F1) | CamCrack789 (mIoU, ODS, OIS, F1) |
|---|---|---|---|---|---|
| 1 | 2.05 | 2.54 | 1190 | 0.9151, 0.9094, 0.9197, 0.9205 | 0.8409, 0.8115, 0.8202, 0.8244 |
| 2 | 3.51 | 4.76 | 1550 | 0.9141, 0.9084, 0.9213, 0.9071 | 0.8381, 0.8069, 0.8222, 0.8208 |
| 4 | 6.42 | 9.20 | 2080 | 0.9126, 0.9065, 0.9166, 0.9173 | 0.8375, 0.8065, 0.8237, 0.8252 |
| 6 | 9.33 | 13.63 | 3818 | 0.9073, 0.9004, 0.9127, 0.9130 | 0.8336, 0.8005, 0.8134, 0.8203 |
7.4. 箱数(number of bins)对 Crack500 数据集的影响
在实验部分的 4.2 节中,我们提到在 Crack500 数据集上,箱数 nnn 设置为 36 而不是 180。为了系统地研究该参数的影响,我们在 Crack500 [29] 数据集上进行了详细的消融实验,如表 11 所示,分别评估了 nnn 设置为 9、18、36、90 和 180 时的模型性能。实验结果表明,当 n=36n=36n=36 时,模型取得了最佳性能。
为了进一步探索这一现象的内在原因,我们详细观察了 Crack500 数据集中的裂缝形态。如图 5 所示,大多数裂缝的特征是宽度大、曲率小,且背景噪声干扰显著,而少数裂缝(最后一张图)面临复杂拓扑结构的挑战,两者的比例接近 15:1。这一观察结果与 n=36n=36n=36 时达到最佳性能的现象一致。适中的 nnn 值不仅可以有效捕捉曲率平缓的裂缝特征,还能保持良好的宽裂缝表示能力,并且能够处理一小部分形态复杂的裂缝。
表 11. 在 Crack500 数据集上关于箱数 nnn 的消融研究。
| nnn | mIoU | ODS | OIS | F1 |
|---|---|---|---|---|
| 9 | 0.7805 | 0.7269 | 0.7467 | 0.7575 |
| 18 | 0.7814 | 0.7273 | 0.7441 | 0.7631 |
| 36 | 0.7824 | 0.7281 | 0.7483 | 0.7755 |
| 90 | 0.7813 | 0.7264 | 0.7455 | 0.7692 |
| 180 | 0.7774 | 0.7212 | 0.7409 | 0.7592 |

图 5. 来自 Crack500 数据集的代表性裂缝图像。
8. SRF 模块的定性分析
在表 3 展示的组件消融实验中,在用 SRF 模块替换 SegFormer [27] 的解码器后,模型的计算成本降低了 89.3%,参数量减少了 33.8%,GPU 内存使用量下降了 67.2%。同时,在两个裂缝分割基准数据集 DeepCrack [17] 和 CamCrack789 [31] 上,mIoU 分别提高了 0.59% 和 0.32%。
为了更深入地了解这种性能提升背后的机制,我们对原始多尺度特征图和经过 SRF 处理后的特征图进行了视觉分析。如图 6 所示,经过 SRF 模块处理后,不同尺度特征图中裂缝区域与背景之间的语义判别力显著增强。原始的 F4′F'_4F4′ 仅表现出微弱的纹理响应;然而,在经过 F1′F'_1F1′ 的细化后,裂缝区域的激活值大幅增强,形成了更清晰的语义边界。这种改进为分割头提供了更具判别力的线索。此外,优化后的特征与高分辨率细节的对齐能力得到增强,有效缓解了解码器中高层语义与低层细节融合不足的问题。最终,这些增强促成了分割精度的提高。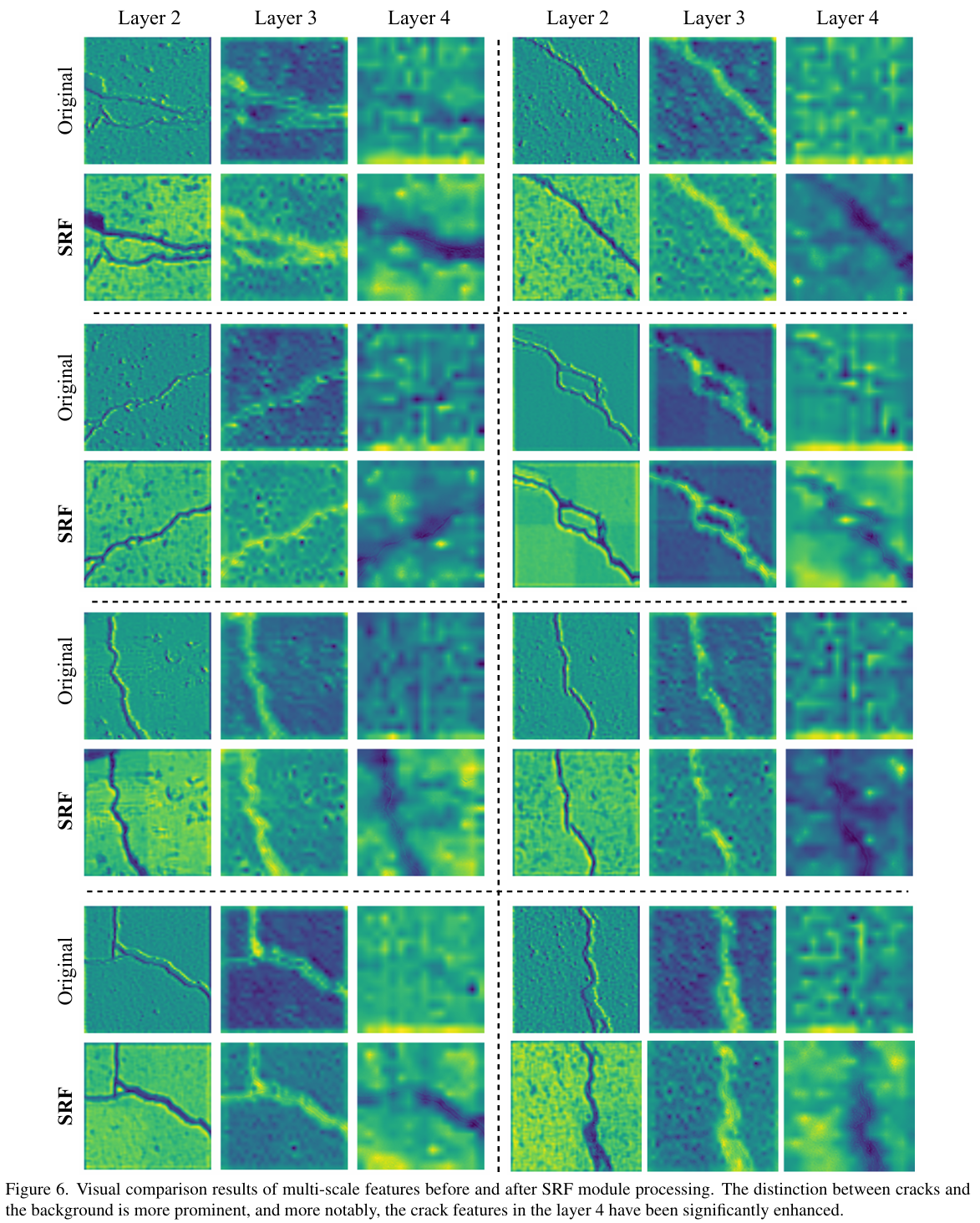
图 6. SRF 模块处理前后多尺度特征的视觉对比结果。裂缝与背景的区别更加突出,更值得注意的是,第 4 层的裂缝特征得到了显著增强。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)