AI驱动的自动化自愈链路:从失败归因到自动修复
一、前言
在做自动化测试的时候,其实:
自动化脚本写出来并不难,难的是后续维护。
在项目里,很多自动化失败并不是真正的功能缺陷,而是一些高频、低难、重复性的脚本维护问题,比如:
-
locator 变化
-
按钮文案变化
-
placeholder 文本变化
-
文本断言不一致
这些问题单个看都不复杂,但数量一多,就会持续消耗测试时间,也会让自动化回归结果充满“假失败”,最后团队容易对自动化结果失去信任。
所以这次我没有继续围绕“AI 生成脚本”去做,而是换了一个更贴近测试日常的问题:
能不能让 AI 参与自动化测试维护流程,自动完成失败分析、问题归因、最小修复和回归验证?
这篇文章就记录这个过程的思路、结构和结果。
二、我想解决的,不是脚本生成,而是脚本维护
很多人聊 AI + 测试,第一反应是:
-
AI 写测试用例
-
AI 写自动化脚本
-
AI 帮忙补断言
这些方向当然有价值,但这次关注另一个问题:
自动化脚本已经存在了,怎么让它别越来越难维护?
因为在 UI 自动化测试中,真正让人头疼的,往往不是“不会写”,而是:
-
页面改了一点点,脚本就红了
-
功能没坏,但自动化全挂了
-
每天先花时间看哪些是真 Bug,哪些只是脚本脏了
-
改完 locator、改完文案、改完 placeholder,还得再跑一遍确认
这类问题的本质不是“测试设计能力不够”,是:
自动化维护成本太高。
所以我这次项目的目标围绕这个问题,设计一条更贴近实际测试场景的流程:
执行测试 → 读取失败日志 → 失败分类 → 生成修复策略 → 修改测试代码 → 回归验证
三、整体流程设计
环境:
-
Playwright:负责执行自动化测试
-
Codex App:负责读取代码、执行命令、分析失败日志、修改测试文件
-
VSCode:作为项目目录与代码编辑环境
核心流程:
Playwright 执行
↓
生成失败日志 / 报错信息
↓
AI 读取失败日志
↓
判断失败类型
↓
生成最小修复策略
↓
修改测试代码
↓
重新执行测试
↓
输出修复结果这里最关键的一点,不是“AI 能不能回答报错是什么”,而是:
AI 能不能真正进入自动化测试维护链路,完成分析、修复、回归这一整条闭环。
四、把这套流程拆成了四层
为了让这条链路更清楚,也方便后续扩展,把这次 AI 辅助自动化测试维护流程拆成了四层:
-
输入层
-
判断层
-
执行层
-
输出层
这四层为了让流程和职责更明确。
五、输入层:系统先拿到什么信息
输入层的职责,是给后面的归因和修复提供上下文。
在这次实践里,输入层主要接入的是以下几类信息:
-
Playwright 执行结果
-
失败日志 / 报错信息
-
失败用例名
-
当前测试文件内容
这一层不做判断,它只是把“发生了什么”先交给系统。
例如:
-
哪个测试失败了
-
报错发生在哪一行
-
是 locator 找不到,还是文本断言不一致
-
当前 spec 文件中对应代码是什么
这一步主要依赖文本型输入。
后续如果继续扩展,还可以再接入:
-
trace 信息
-
页面截图
-
DOM 片段
-
控件上下文
先把核心链路聚焦在日志和测试文件本身,没有再继续发散。
六、判断层:先归因,再决定怎么修
判断层是这次项目里很关键的一层。
因为自动化失败并不都适合自动修复。
如果一上来不做归因,AI 很容易乱改代码,甚至为了让测试通过,直接 skip、删断言、放宽 locator,这样结果虽然“绿了”,但测试价值就没了。
所以判断层的任务是:
先根据失败日志识别问题类型,再判断它是否属于适合自动修复的高频维护问题。
这次先收敛了 4 类典型场景:
-
Assertion Mismatch
-
Locator Changed
-
Placeholder Changed
-
Text Changed
对应的判断方式:
-
根据
getByRole(... name=xxx)超时,判断为Locator Changed -
根据
getByPlaceholder(...)找不到元素,判断为Placeholder Changed -
根据
toContainText或getByText的期望值与实际值不一致,判断为Text Changed或Assertion Mismatch
这里重要点:
判断层不仅要输出分类结果,还要给出判断依据。
如果只有一个标签,比如“locator changed”,但没有依据,那这个归因是很难让测试人员信任的。
七、执行层:不是让 AI 随便改,而是受控修复
执行层负责的事情:
-
根据失败归因生成修复策略
-
修改测试代码
-
重新执行测试完成回归验证
这一层真正的难点,不是“让 AI 改代码”,是:
怎么让它只做最小必要修复,而不是乱修。
所以给修复行为加了明确约束:
-
只修改测试代码
-
只改 1 处
-
不允许 skip 测试
-
不允许删除断言
-
不允许放宽定位或断言
-
保持最小必要修复
比如:
如果是 Locator Changed,那就只把错误的按钮名或文本 locator 改回合理值;
如果是 Placeholder Changed,那就只修对应 placeholder;
如果是 Assertion Mismatch,那就只恢复期望文本,不去碰业务逻辑。
这一层的重点,不是“为了通过而通过”,而是:
让修复行为可控、可解释、可回归验证。
八、输出层:最后不是一句“修好了”,而是结构化结果
输出层负责把整个自动修复过程整理成可复核的信息。
最终输出内容包括:
-
失败日志摘要
-
失败原因分类
-
判断依据
-
修复策略
-
修改 diff
-
回归结果
这一层的意义:
一方面方便测试人员快速复核;
另一方面也能把“执行—分析—修复—回归”的链路沉淀下来,后续写文章、做汇报、做项目包装时都更有依据。

九、做了哪些场景
没有一开始就追求复杂页面、批量修复、CI 集成,而是先围绕自动化维护里最常见、最适合 AI 介入的一批问题做覆盖。
这次跑通了 4 类高频场景:
1. Assertion Mismatch
修改断言期望值,制造文本断言失败。
随后由 Codex 读取失败日志,识别期望值与页面实际值不一致,完成归因、修复和回归。
2. Locator Changed
修改按钮文本 locator,制造元素找不到的失败。
随后由 Codex 根据报错信息判断为 locator 变化,并完成最小修复。
3. Placeholder Changed
通过修改 getByPlaceholder 中的 placeholder 文本,制造输入框定位失败。
随后由 Codex 完成 placeholder 级别归因与修复。
4. Text Changed
通过修改 getByText / toContainText 相关文本,制造文本变化导致的失败。
随后由 Codex 完成文本归因与修复。
这四类问题看起来都不大,但它们恰恰是 UI 自动化维护里最常见、最消耗时间的一批问题。
十、做了统一 workflow
如果只是做 4 类单独场景,还不够。
因为那更像“指定题”:我提前告诉系统这是 locator changed,它当然容易修。
所以后面又继续做了一步:
不预设失败类型,让系统自己制造 1 处最小故障,然后根据失败日志自行判断问题类型,再完成修复与回归。
这一轮实践更接近实际 workflow。
因为实际场景里,系统拿到的不是“标准答案”,而是失败日志本身。
这一步跑通后,说明这套流程已经不只是“按题作答”,而是具备了统一归因能力。
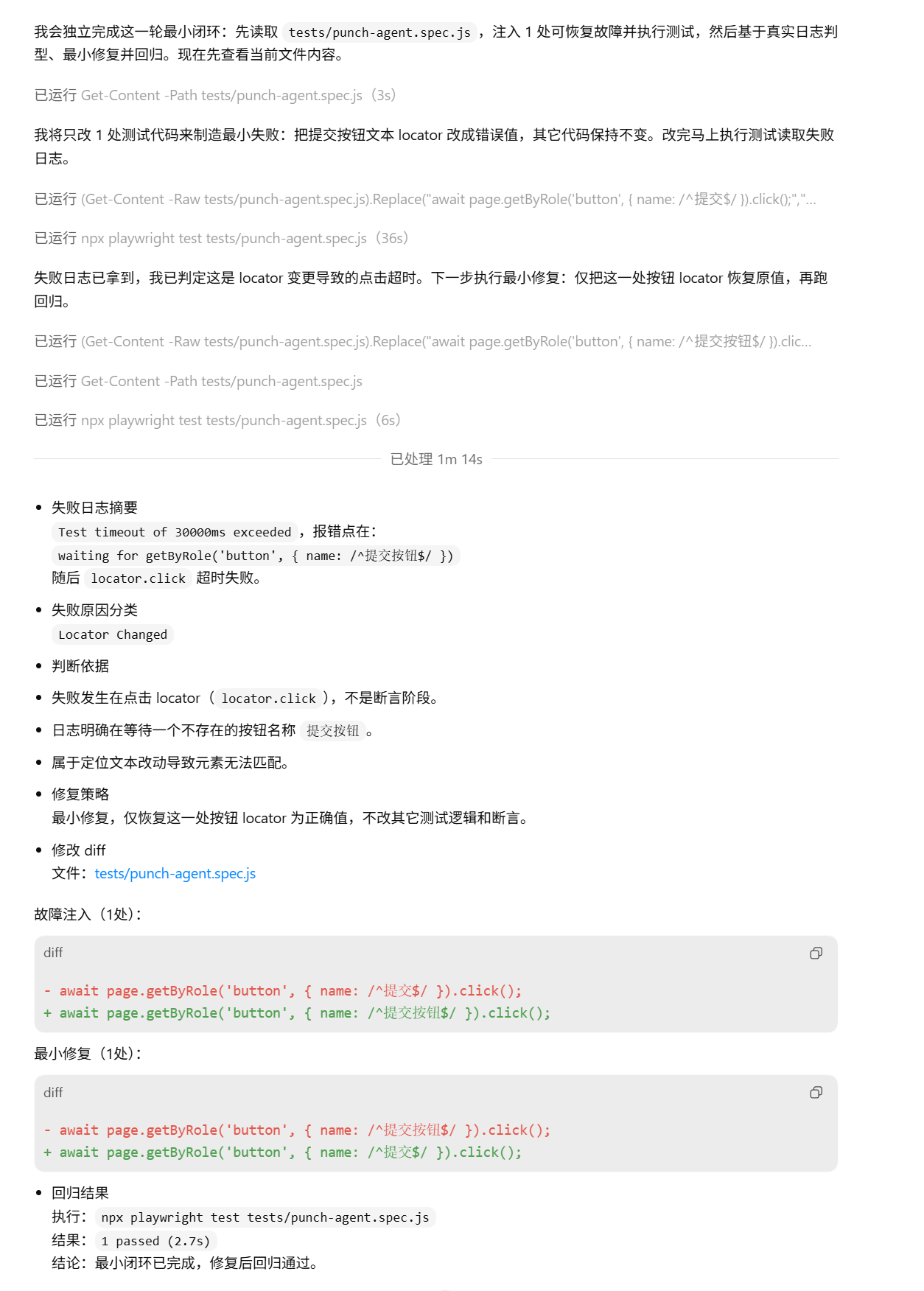
十一、连续两轮执行,确认不是碰巧成功
为了避免“一次成功只是偶然”,我又让这套统一 workflow 连续执行了两轮。
每一轮都要求它独立完成:
-
故障注入
-
执行测试
-
阅读日志
-
自主分类
-
最小修复
-
回归验证
最终两轮都能完成归因、修复和回归通过。
这一步虽然不算复杂,但很重要。
因为它至少说明,这条链路不是一次性的偶然结果,而是具备一定重复性。
十二、统一 workflow 提示词
在前面几轮定向跑完后,把整个流程收敛成了一版统一 workflow 提示词。
这版提示词本身,也可以看作可复用产物。
请在当前项目中完成一次自动化测试失败修复闭环。
目标:
针对 Playwright 执行失败的测试,用最小修复方式完成自动分析、归因、修改和回归。
执行要求:
1. 打开 tests/punch-agent.spec.js
2. 只修改 1 处测试代码,故意制造一个最小、可恢复的失败
3. 执行:
npx playwright test tests/punch-agent.spec.js
4. 阅读失败日志
5. 在以下四类中自行判断失败类型:
- Assertion Mismatch
- Locator Changed
- Placeholder Changed
- Text Changed
6. 给出判断依据
7. 给出最小修复策略
8. 修改测试代码
9. 重新执行:
npx playwright test tests/punch-agent.spec.js
10. 输出结构化结果:
- 失败日志摘要
- 失败原因分类
- 判断依据
- 修复策略
- 修改 diff
- 回归结果
约束:
- 不要提前假设失败类型
- 只改测试代码
- 只改 1 处
- 不要 skip
- 不要删除断言
- 不要放宽定位或断言
- 保持最小修复
- 不要改业务代码这版提示词的价值,不只是“方便复现”,更重要的是,它把这次流程里的关键约束都固化下来了。
十三、什么效果
最直接的效果,不是“AI 能自动修所有问题”,是:
已经把自动化测试维护里的核心链路打通了。
也就是说,在当前范围内,系统已经可以完成:
-
自动执行 Playwright
-
自动读取失败日志
-
自动判断失败类型
-
自动生成最小修复策略
-
自动修改测试代码
-
自动重新执行并完成回归验证
同时,已经实际覆盖了 4 类高频维护问题:
-
Assertion Mismatch
-
Locator Changed
-
Placeholder Changed
-
Text Changed
另外还完成了两项增强验证:
-
不预设失败类型的统一 workflow 跑通
-
连续两轮统一 workflow 可重复执行
最现实的价值不是“取代测试”,而是:
优先处理那批高频、低风险、机械性的自动化维护问题,降低假失败噪音和脚本维护成本。
十四、边界
这次虽然已经把核心链路打通了,但也很清楚它当前的边界。
目前已经完成:
-
单文件
-
单用例
-
单点故障
-
文本型高频维护问题
还没有继续扩展到:
-
多文件批量修复
-
多用例统一回归
-
trace / screenshot 辅助分析
-
复杂页面结构漂移
-
Jenkins / CI 接入
-
非文本类失败,如网络、权限、环境、时序问题
-
修复成功率 / 误修率的系统化统计
这些后面如果继续做,才会逐步往工程化方向走。
但在当前阶段,先把最核心、最贴近测试维护场景的那条链路做实。
十五、体会
最大的感受不是“AI 很神”,而是:
自动化真正难的,很多时候不是写出来,而是活下去。
以前聊自动化,容易把重点放在“覆盖了多少”“脚本写了多少”。
但真实项目里,如果维护成本太高,自动化很快就会变成负担。
所以:
不是为了做自动化而做自动化,
而是想办法让已经存在的自动化资产,持续产生价值。
而 AI 在这里最适合切入的,不一定是最花哨的部分,
反而是那批高频、低难、反复出现的维护问题。
十六、结语
这次并不是去做一个“大而全”的自愈测试平台,
而是围绕自动化脚本维护成本这个真实问题,完成了一条 AI 辅助测试维护流程的落地实践。
从结果看,这条链路已经能够支持:
执行测试 → 读取日志 → 失败归因 → 最小修复 → 回归验证
说明:
AI 已经可以从“给建议”进一步走向“参与自动化测试维护流程”。
后面如果继续扩展,我会更关注:
-
批量处理能力
-
更复杂页面场景
-
trace / screenshot 辅助判断
-
结果统计与工程化接入
但至少到这里,核心方向已经比较清楚了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)