ML-1.线性回归(Linear Regression)
·
第一课:线性回归(Linear Regression)
核心思想一句话: 在所有点中间画一条"最中庸"的直线——不让任何一个点太委屈,也不特别讨好某个点。
# ========== 1. 导入必要的库 ==========
import pandas as pd # 数据处理
import numpy as np # 数值计算
from sklearn.datasets import fetch_california_housing # 加载数据集
from sklearn.model_selection import train_test_split # 划分训练/测试集
from sklearn.linear_model import LinearRegression # 线性回归模型
from sklearn.metrics import mean_squared_error, r2_score # 评估指标
import matplotlib.pyplot as plt # 数据可视化
# 1. 加载数据
housing = fetch_california_housing()
#pd.DataFrame() 将 numpy 数组转换为 pandas 表格
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target # 房价中位数(十万美金)
print("特征名称:", housing.feature_names)
print("\n数据集大小:", X.shape)
print("\n前3行数据:\n", X.head(3))
2.📐 核心概念:线性回归在算什么?
房价 = w₀ + w₁×收入 + w₂×房龄 + w₃×卧室数 + ... + w₈×经度
↑ ↑ ↑
截距(bias) 各特征的权重(weights)
模型目标:找到一组w,让预测值和真实房价的差距最小
这个"差距"叫损失函数(Loss),通常用均方误差MSE:
MSE = 平均( (真实房价 - 预测房价)² )
2.1📝 数学公式详解
MSE=1n∑i=1n(yi−y^i)2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
| 符号 | 含义 | 示例 |
|---|---|---|
| nnn | 样本数量 | 1000 套房子 |
| yiy_iyi | 第 iii 个真实值 | 实际房价 50万 |
| y^i\hat{y}_iy^i | 第 iii 个预测值 | 模型预测 55万 |
| (yi−y^i)(y_i - \hat{y}_i)(yi−y^i) | 残差/误差 | -5万 |
| ∑\sum∑ | 求和 | 所有样本误差平方相加 |
| 1n\frac{1}{n}n1 | 取平均 | 除以样本数 |
2.2🔄 相关变体
| 指标 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
| RMSE | MSE\sqrt{\text{MSE}}MSE | 开根号,单位与原始数据一致 | 更直观的误差度量 |
| MAE | 1n∑∣yi−y^i∣\frac{1}{n}\sum|y_i - \hat{y}_i|n1∑∣yi−y^i∣ | 绝对值,不放大误差 | 异常值较多时更稳健 |
| R² | 1−MSE方差1 - \frac{\text{MSE}}{\text{方差}}1−方差MSE | 标准化到 0~1 | 衡量模型解释力 |
3.继续代码:训练与评估
| 变量 | 含义 | 类比 |
|---|---|---|
X_train |
训练用特征(80%房子的8个属性) | 学生的练习题 |
y_train |
训练用答案(80%房子的真实房价) | 练习题的标准答案 |
X_test |
测试用特征(20%房子的8个属性) | 期末考试卷 |
y_test |
测试用答案(20%房子的真实房价) | 考试卷的正确答案(考后才看) |
原始数据 X, y
↓
[2] 数据拆分 ──→ X_train, y_train (80%) 用于学习
└──→ X_test, y_test (20%) 用于考试
↓
[3] 创建模型 → 训练(fit) → 预测(predict)
↓
[4] 评估模型表现(R², RMSE)
↓
[5] 解释模型(哪个特征最重要)
# 2. 拆分数据:80%训练,20%测试
#random_state=42 = 随机数种子,让每次"抽签"结果相同,保证实验可重复
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 创建模型 → 训练 → 预测
model = LinearRegression()
model.fit(X_train, y_train) # 训练:自动找最优的w₀, w₁, w₂...
y_pred = model.predict(X_test) # 预测
# 4. 评估
print(f"R²得分: {r2_score(y_test, y_pred):.3f}") # 解释度,1.0满分
print(f"RMSE: {np.sqrt(mean_squared_error(y_test, y_pred)):.3f}") # 平均误差(十万美金)
# 5. 看模型学到了什么权重
importance = pd.DataFrame({
'特征': housing.feature_names,
'权重': model.coef_
}).sort_values('权重', key=abs, ascending=False)
print("\n特征权重(影响力):\n", importance)
4.从线性回归到多项式回归
核心思想: 如果直线不够弯,那就允许曲线!
把原始特征平方、立方,让模型能拟合弯曲的趋势:
线性: 房价 = w₀ + w₁×收入
二次: 房价 = w₀ + w₁×收入 + w₂×收入²
三次: 房价 = w₀ + w₁×收入 + w₂×收入² + w₃×收入³
4.1曲线拟合非线性数据
原始数据 X 经过 Pipeline 处理
│ │
▼ ▼
┌─────┐ ┌─────────────┐ ┌───────────── ┐
│ 1 │ ──poly.fit──→│ [1, 1] │ │ │
│ 2 │ transform │ [2, 4] │ ───→ │ LinearRegression.fit() │
│ 3 │ │ [3, 9] │ │ │
│ 4 │ │ [4, 16] │ │ 学习 w₁, w₂, w₀ │
└─────┘ └─────────────┘ └───────────── ┘
(4,1) (4,2) │
▼
曲线模型 y = w₀ + w₁x + w₂x²
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures #自动将低次特征转换成高次特征,让线性模型能拟合非线性关系
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline #把多个处理步骤串联成"生产线",一键完成数据转换 → 模型训练 → 预测
from sklearn.metrics import r2_score
# 1. 生成模拟数据(非线性关系:y = x² + 噪声)
np.random.seed(42)
#np.linspace(-3, 3, 100).reshape(-1, 1)
# └─────┬─────┘ └──┬──┘
# 生成数据 改变形状
# .reshape(行数, 列数)
# -1: 自动计算(根据总数推断)
# 1: 固定1列
X = np.linspace(-3, 3, 100).reshape(-1, 1) # 特征:-3到3之间100个点
y = X.ravel()**2 + np.random.randn(100) * 0.5 # 真实关系:y = x² + 噪声
# 2. 普通线性回归(直线)
linear_model = LinearRegression()
linear_model.fit(X, y)
y_linear_pred = linear_model.predict(X)
# 3. 多项式回归(二次曲线)
# Pipeline = 先把X变成[X, X²],再线性回归
poly_model = Pipeline([
('poly', PolynomialFeatures(degree=2)), # 步骤1:特征工程,把X变成[X, X²]
('linear', LinearRegression()) # 步骤2:用新特征做线性回归
])
poly_model.fit(X, y)
y_poly_pred = poly_model.predict(X)
# 4. 对比可视化
plt.figure(figsize=(10, 6))
plt.scatter(X, y, alpha=0.5, label='真实数据')
plt.plot(X, y_linear_pred, 'r-', label=f'线性回归 (R²={r2_score(y, y_linear_pred):.3f})')
plt.plot(X, y_poly_pred, 'g-', linewidth=2, label=f'二次多项式 (R²={r2_score(y, y_poly_pred):.3f})')
plt.xlabel('X')
plt.ylabel('y')
plt.title('线性 vs 多项式回归对比')
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig('回归对比.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"线性回归R²: {r2_score(y, y_linear_pred):.3f}")
print(f"多项式回归R²: {r2_score(y, y_poly_pred):.3f}")
如果让曲线太灵活(degree太高)会过拟合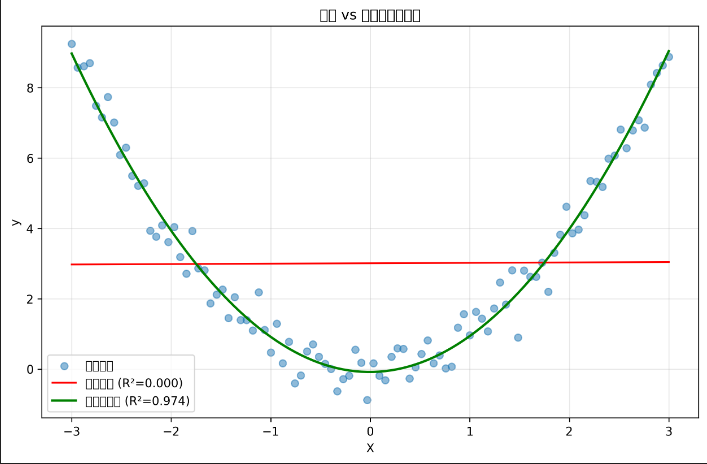
5.正则化
核心思想: 惩罚过大的权重,让模型"保守"一点
| 方法 | 名称 | 效果 |
|---|---|---|
| L1正则化 | Lasso | 把不重要的特征权重直接压成0(自动特征选择) |
| L2正则化 | Ridge | 让所有权重都变小,但不强制为0(更平滑) |
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.metrics import r2_score
# 设置中文字体(解决乱码)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# ==================== 1. 生成数据 ====================
np.random.seed(42)
X = np.linspace(-3, 3, 100).reshape(-1, 1)
# 真实关系:二次函数 + 线性趋势 + 噪声
y = 0.5 * X**2 + X + 2 + np.random.normal(0, 0.5, (100, 1))
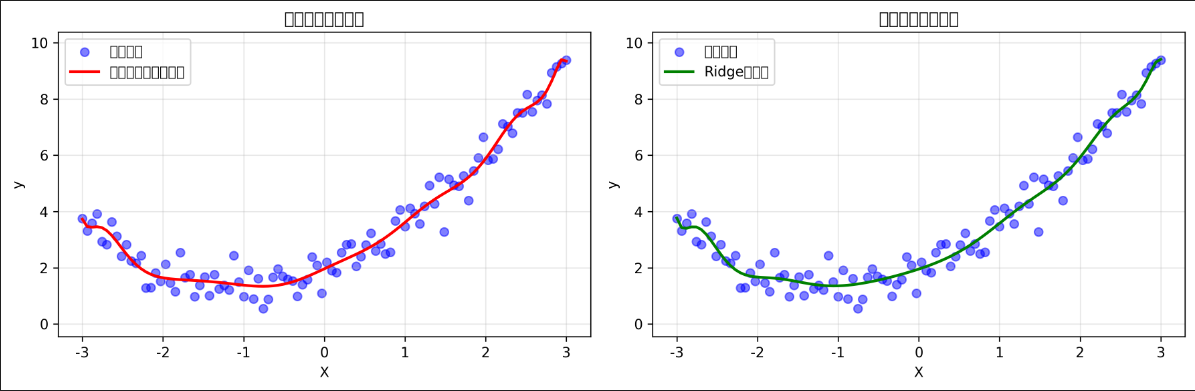
# ==================== 2. 无正则化模型(过拟合) ====================
overfit_model = Pipeline([
('poly', PolynomialFeatures(degree=15, include_bias=False)),
('linear', LinearRegression())
])
overfit_model.fit(X, y)
y_pred = overfit_model.predict(X) # 用于对比
# ==================== 3. Ridge正则化模型 ====================
ridge_model = Pipeline([
('poly', PolynomialFeatures(degree=15, include_bias=False)),
('ridge', Ridge(alpha=1.0)) # L2正则化,alpha越大越平滑
])
ridge_model.fit(X, y)
y_ridge_pred = ridge_model.predict(X)
# ==================== 4. 可视化对比 ====================
plt.figure(figsize=(12, 4))
# 左图:过拟合
plt.subplot(1, 2, 1)
plt.scatter(X, y, alpha=0.5, color='blue', label='真实数据')
plt.plot(X, y_pred, 'r-', linewidth=2, label='无正则化(过拟合)')
plt.ylim(y.min() - 1, y.max() + 1)
plt.xlabel('X')
plt.ylabel('y')
plt.title('过拟合:过度复杂')
plt.legend()
plt.grid(True, alpha=0.3)
# 右图:Ridge正则化
plt.subplot(1, 2, 2)
plt.scatter(X, y, alpha=0.5, color='blue', label='真实数据')
plt.plot(X, y_ridge_pred, 'g-', linewidth=2, label='Ridge正则化')
plt.ylim(y.min() - 1, y.max() + 1) # 相同Y轴范围方便对比
plt.xlabel('X')
plt.ylabel('y')
plt.title('正则化:平滑保守')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('正则化.png', dpi=300, bbox_inches='tight')
plt.show()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)