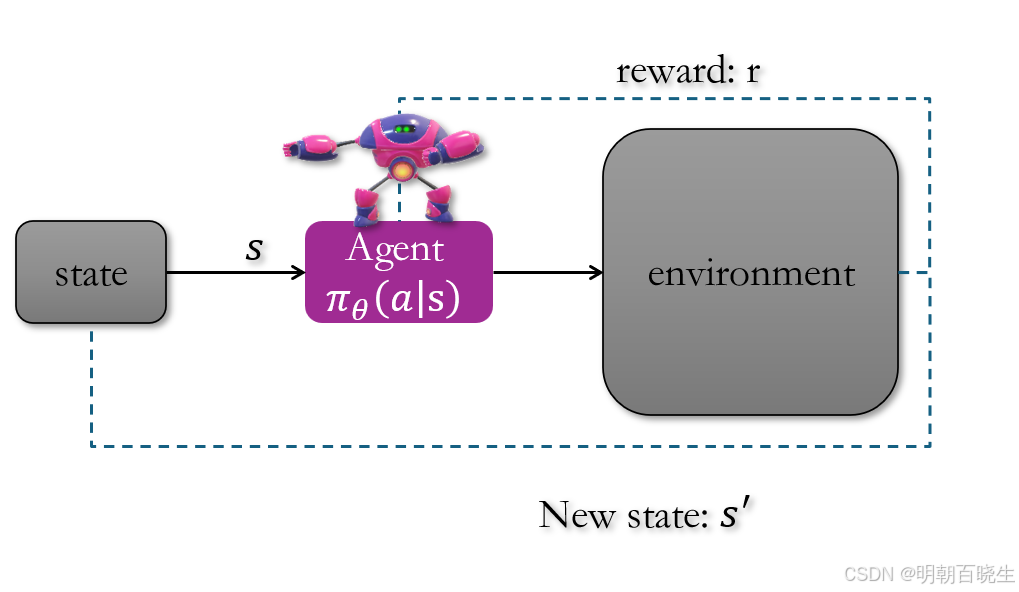
强化学习[chapter8] [page21]Policy Gradient3
目录:
- policy of actor
- 累计回报 R 对策略更新的影响
- TIP1 Add Baseline
- Tip2 :Assign suitable credit 分配适当的功劳
一 policy of actor
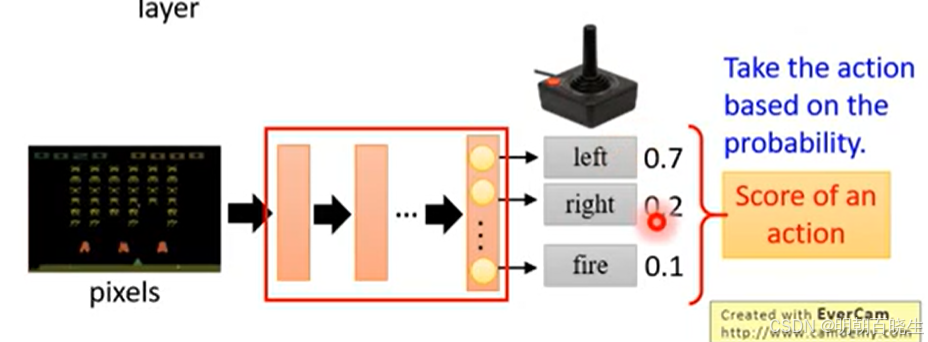
1 累计收益 R
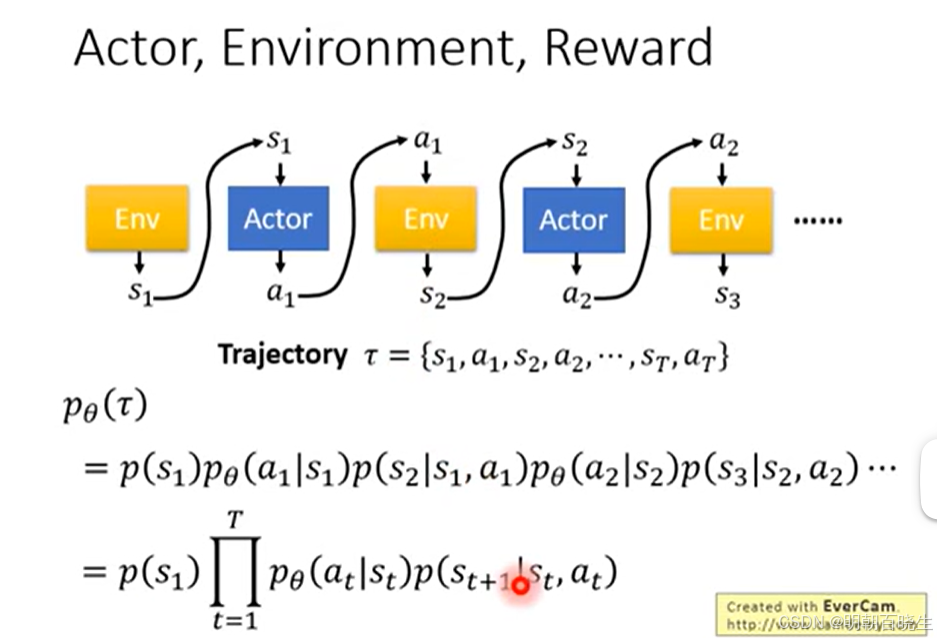
假设策略由一个参数为 θ 的神经网络进行参数化。通过该策略与环境交互,我们收集到一个长度为 T的轨迹
,其累积收益(总回报)为
2 该轨迹的概率为
当给定策略后,agent 与环境交互会形成不同的轨迹
某个特定的轨迹出现的概率记为
(也写作
)

3 Expected Reward
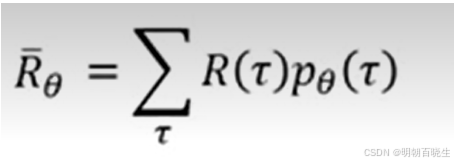
强化学习的目标就是使得该期望值最大。
: 为轨迹
出现的概率
4 求梯度

5 完整的实施方案
G: 等同于
: 等同于

二 累计回报 R 对策略更新的影响

上面主要问题是在某些强化学习应用中,累积奖赏总是正的导致其对应的策略一直提升
例子:
在淘宝、抖音、YouTube 等平台的推荐系统中,强化学习旨在优化用户的长期留存。其奖励信号通常来源于用户的行为,如点击、点赞、收藏、完播和购买。
原因在于反馈信号的不对称性。这些信号(点击、购买)本身就代表着正反馈;而用户如果对内容不感兴趣,通常只是简单划过(即“无操作”)。系统很难直接获取明确的“负反馈”,除非用户主动点击“不感兴趣”。
三 Tip1: Add BaseLine
policy gradient 训练技巧1

引入基线(Baseline)的主要原因有两个:
-
降低梯度估计的方差:在策略梯度中,如果累计回报R 总为正,会导致所有被采样到的动作概率都被推动上升。这相当于让模型去“增强”所有见过的动作,而没有明确指出哪些动作是“更好”的,哪些是“更差”的。减去基线 b 后,R—b变为有正有负,清晰地区分了“好”动作(优势为正)和“差”动作(优势为负),从而在保证梯度无偏的同时,显著降低了估计的方差。
-
缓解因采样不全导致的训练不稳定:在实际训练中,由于策略的探索性,智能体不可能访问所有状态-动作对。如果 GG 总是为正,那些被频繁采样到的状态-动作对的概率会被一味地推高,而那些未被采样到的动作(即使它们可能是潜在的最优动作)概率则会因 softmax 归一化效应而被动下降。这会导致模型过早收敛到次优策略,训练过程变得极不稳定。引入基线可以有效缓解这一问题,让梯度更新更关注动作之间的相对优劣。
四 Tip2 :Assign suitable credit 分配适当的功劳
在强化学习中,尤其是在使用蒙特卡洛(Monte Carlo)采样进行策略梯度更新时,我们面临一个根本性问题:如何将整条轨迹的总回报合理地归因于每一个状态-动作对?
假设根据当前策略采样到两条轨迹:
-
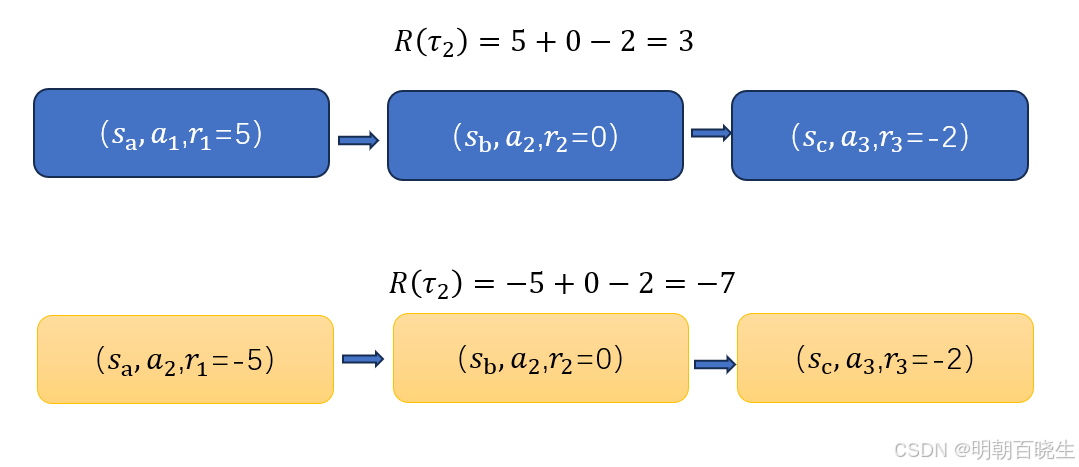
-
轨迹1: 整条轨迹累计奖励 +3
-
轨迹2:整条轨迹累计奖励 -7
问题所在:
在标准的蒙特卡洛策略梯度(REINFORCE)中,我们通常使用整条轨迹的累计奖励 R(τ) 来更新轨迹中每一个状态-动作对的概率。
这就导致了以下悖论:
-
同一个状态-动作对,不同的命运:在轨迹1中,状态 sb下执行动作 a2获得了正向的总回报(+3),因此这一行为会被鼓励。
-
而在轨迹2中,同样的状态 sb和执行同样的动作 a2,由于后续轨迹的不同(或环境随机性),导致总回报为负(-7),因此这一行为会被抑制。
根本原因:
这两个轨迹中,(sb,a2)本身可能是一个不错的动作选择,只是因为在轨迹2中,后续遭遇了糟糕的随机事件或探索到了一个不良的状态分支,从而“背锅”承担了负面的总回报。反之亦然,一个糟糕的动作也可能因为后续的运气好而被错误地奖励。
这凸显了单纯使用整条轨迹回报更新所有动作的缺陷:它混淆了“动作本身的好坏”与“后续轨迹的运气”,导致方差过大且学习不稳定。
解决方案导向:
为了解决这一问题,强化学习引入了信用分配机制:
-
引入基线(Baseline):减去一个基准值,降低方差。
-
计算R的时候,不是计算整个epsiode return ,而是计算当前时刻之后的return,比如上图最后都是-2,即累积奖赏R的计算方式发生变化,如下
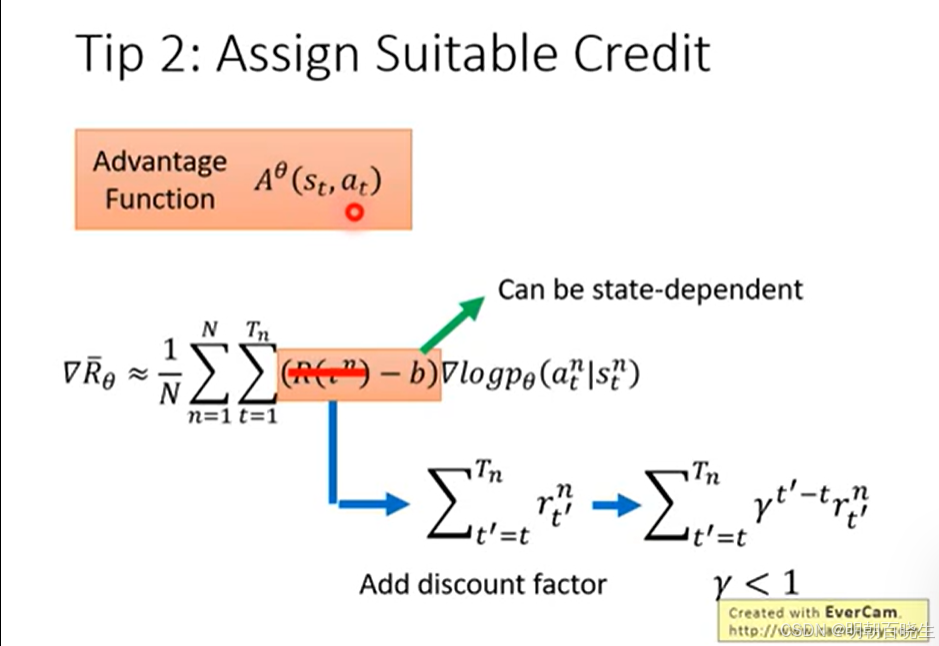
3 使用Critic网络(Actor-Critic):不直接用整条轨迹的总回报 R,而是使用优势函数 A(s,a)。这衡量的是“在这个状态下,选这个动作相对于平均表现到底好多少”,从而更精确地归因于当前动作本身,而非后续的整体轨迹。
https://www.bilibili.com/video/BV1D4411F7bB/?spm_id_from=333.337.search-card.all.click

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)