areal异步技术分析
仅分析了感兴趣的一部分。
3.10
AREAL
https://arxiv.org/pdf/2505.24298
全异步强化学习系统,支持agent rl和在线rl训练。
如何做到全异步的?
生成rollout和训练training解耦。
- 流式生成:rollout workers持续不断生成新样本,不会等待一个批次的数据收集完毕,更新模型参数再继续生成下一批。
- 及时更新:trainning workers一旦收集到足够的样本就立即更新模型参数。
具体展示:

同步系统流程:等所有 rollout 序列全部生成完毕->训练->更新权重->下一批rollout 序列生成...
问题:不同序列的长度差异很大,意味着最快的 GPU 生成完之后就干等着,整个系统被最慢的那条序列拖住。
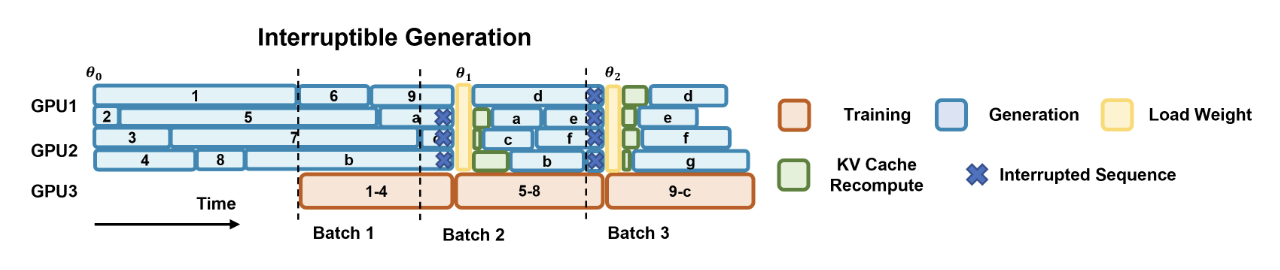
异步系统流程:gpu1、gpu2生成数据,放入buffer->gpu3从buffer收集到足够进行更新的一个batch的数据,进行模型训练->训练完中断生成rollout,加载新权重->新序列继续生成(蓝色);对旧序列已经生成的那部分 token 用新权重重新计算 KV Cache(绿色),新模型从断点继续生成接下来的内容->继续循环。
异步挑战如何解决?数据陈旧性+policy不一致问题
控制数据的"过期程度":有一个超参数 η 控制,如果生成端跑得太快、攒了太多数据而训练端还没消化,就拒绝新的生成请求,避免产出过于陈旧的数据。
Decoupled PPO:把行为策略和近端策略
进行解耦
标准PPO公式为:
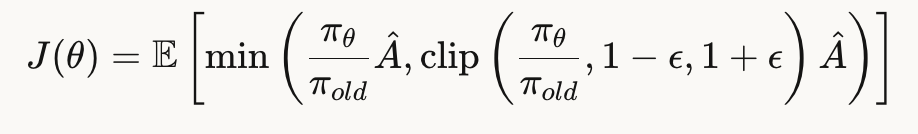
π_{old}扮演两个角色,生成数据的策略以及trust region 的中心(即 clip 的锚点)。
而在异步系统中,数据可能是生成的,而模型已经更新到了
,要求模型不要离一个落后的版本太远,相当于在拖后腿。所以Decoupled PPO选择把
两个角色拆给两个不同的策略,即行为策略
和近端策略
,修改后的目标函数如下
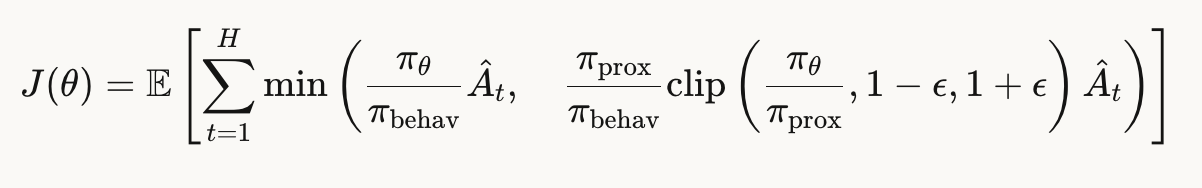
这里举例说明一下三个策略
假设当前训练到了第 10 版参数,而 buffer 里有一条轨迹是第 7 版
生成的。
-
:实际生成这条数据的旧策略
:一个较新的策略,作为 trust region 的中心(实践中取训练步开始前的参数)
:当前正在被优化的策略
第一项就是标准的重要性采样。数据是生成的,但我们要优化
,所以用比率
来修正分布偏移。这一项没有 clip,代表"无约束的策略梯度"。
第二项约束,分为两部分:
:约束
不要太偏离近端策略
,也就是真正训练前的那一版策略
,而不是距离太远的旧策略
。
:这是一个修正系数,因为数据实际来自来自
而不是
以 Decoupled PPO 本质上就是:在较新策略附近做标准 PPO 更新(约束范围),同时用重要性权重补偿数据来自旧策略这一事实(更正实际距离)。
半个句子用旧模型写,后半个用新模型写,这种数据为什么也能用来训练?拼接轨迹为什么也能用这个公式处理呢?
假设一条轨迹有 10 个 token,生成到第 4 个时被中断,换了新权重继续生成后面 6 个:
token 1-4: 由 生成
token 5-10: 由 生成
直觉上似乎 没法定义——它到底是
还是
?
那为什么能处理呢?因为Decoupled PPO 的公式中, 只出现在重要性权重
中,而且是逐 token 计算的。所以我们可以构造的
:
- token 1-4:
- token 5-10:
所以其实每一项都是可以被计算的。
而从理论上也是可以证明的,对于任何这样的拼接轨迹,一定存在一个等价的 ,使得从这个
中采样整条轨迹的概率,和拼接生成的概率完全相同。
因为自回归生成的概率可以分解为逐 token 的条件概率之积:
对于拼接轨迹:
现在我们构造一个 ,定义它在每个位置的条件概率为:
这个 虽然不对应任何真实的单一模型参数,但它是一个数学上合法的策略——在每个位置,给定上文,它输出一个合法的 token 概率分布。而且从它采样出这条轨迹的概率和拼接生成的概率完全一致。
参考论文《AREAL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning》感谢claude老师的指导

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)